
Wenn wir aufhören, die Größe der Tabelle zu steuern, wird das Verwalten und Bereitstellen von Daten zu einer nicht trivialen Aufgabe. Ich bin bereits auf ein solches Problem in der Produktion gestoßen, es gibt jeden Tag mehr Daten, die Tabelle passt nicht in den Speicher, die Server reagieren lange, aber es wurde eine Lösung gefunden.
Hallo habr Mein Name ist Diamond und jetzt möchte ich eine Methode teilen, die mir beim Implementieren der Partitionierung geholfen hat.
Partitionierung in PostgreSql
Partitionierung (oder, wie sie es nennen, Partitionierung) ist der Vorgang der Aufteilung einer großen logischen Tabelle in mehrere kleinere physische Abschnitte. Dies hilft uns bei der Verwaltung unserer Daten.
Beispiel: Wir haben eine „Verkaufstabelle“, die in Abständen von einem Monat unterteilt ist. Diese Abschnitte können nach Regionen in noch kleinere Unterabschnitte unterteilt werden.
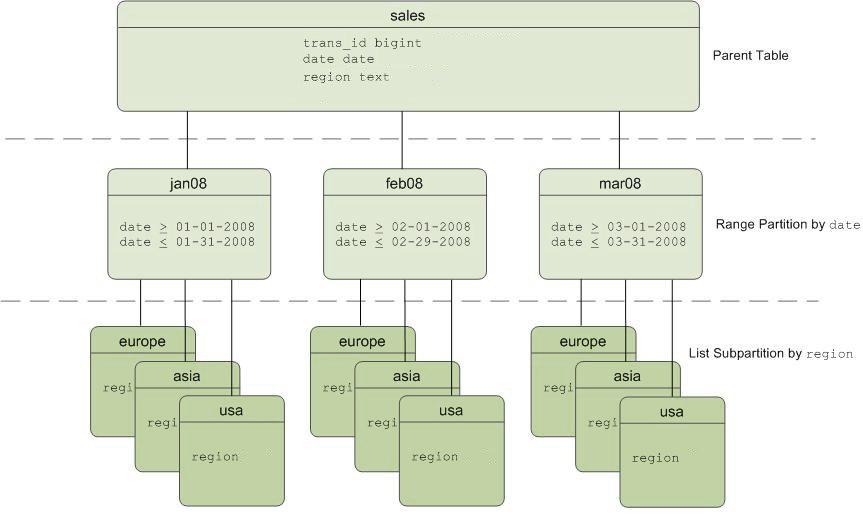 Schema der partitionierten Tabelle "sales"
Schema der partitionierten Tabelle "sales"Nachteile dieses Ansatzes:
- Komplizierte Datenbankstruktur. Jeder Abschnitt in den Datenbankdefinitionen ist eine Tabelle, obwohl er Teil einer logischen Entität ist.
- Sie können eine vorhandene Tabelle nicht in eine partitionierte Tabelle konvertieren und umgekehrt.
- Postgres Version 11 bietet keine vollständige Unterstützung.
Vorteile:
+ Leistung. In bestimmten Fällen können wir mit einer begrenzten Anzahl von Abschnitten arbeiten, ohne die gesamte Tabelle zu durchsuchen. Selbst die Indexsuche nach großen Tabellen ist langsamer. Erhöht die Datenverfügbarkeit.
+ Bulk-Upload und Löschen von Daten mit ATTACH / DETACH-Befehlen. Dies erspart uns den Overhead in Form von VACUUM. So können Sie die Datenbank effizienter verwalten.
+ Möglichkeit, TABLESPACE für den Abschnitt anzugeben. Dies gibt uns die Möglichkeit, Daten in andere Abschnitte zu übertragen, wir arbeiten jedoch in derselben Instanz und die Metadaten des Hauptverzeichnisses enthalten Informationen zu den Abschnitten. (Nicht zu verwechseln mit Sharding.)
2 Möglichkeiten, die Partitionierung in PostgreSql zu implementieren:
1. Vererbung von Tabellen (INHERITS)Beim Erstellen einer Tabelle sagen wir "von einer anderen (übergeordneten) Tabelle erben". Gleichzeitig fügen wir der Tabelle Einschränkungen für die Datenverwaltung hinzu. Dadurch unterstützen wir die Logik der Datenaufteilung, aber dies sind logisch unterschiedliche Tabellen.
An dieser Stelle sei auf die von Postgres Professional entwickelte Erweiterung pg_pathman hingewiesen, die die Partitionierung auch durch Tabellenvererbung implementiert.
CREATE TABLE orders_y2010 ( CHECK (log_date >= DATE '2010-01-01) ) INHERITS (orders);
2. Deklarativer Ansatz (PARTITION)Eine Tabelle ist deklarativ partitioniert. Diese Lösung erschien in Version 10 von PostgreSql.
CREATE TABLE orders (log_date date not null, …) PARTITION BY RANGE(log_date);
Ich habe einen deklarativen Ansatz gewählt. Dies gibt einen großen Vorteil - Ursprünglichkeit, mehr Funktionen werden vom Kernel unterstützt. Betrachten Sie die Entwicklung von PostgreSQL in diese Richtung:
 Quelle
QuellePostgreSql entwickelt sich jedoch weiter und Version 12 unterstützt die Verknüpfung mit einer partitionierten Tabelle. Dies ist ein großer Durchbruch.
Mein Weg
Vor diesem Hintergrund wurde ein
Skript in PL / pgSQL geschrieben, das eine partitionierte Tabelle basierend auf der vorhandenen erstellt und alle Verknüpfungen zu der neuen Tabelle „auslöst“. Auf diese Weise erhalten wir eine partitionierte Tabelle, die auf der vorhandenen Tabelle basiert, und arbeiten damit wie mit einer regulären Tabelle weiter.
Das Skript benötigt keine zusätzlichen Abhängigkeiten und wird in einer separaten Schaltung ausgeführt, die es selbst erstellt. Protokolliert auch Redo- und Undo-Aktionen. Dieses Skript löst zwei Hauptaufgaben: Es erstellt eine partitionierte Tabelle und implementiert externe Links zu dieser Tabelle über die Trigger-Trigger.
Skriptvoraussetzung: PostgreSql v.:11 und höher.
Gehen wir nun das Skript genauer durch. Die Oberfläche ist sehr einfach:
Es gibt zwei Verfahren, die die gesamte Arbeit erledigen.
1. Die Hauptherausforderung - In dieser Phase ändern wir nicht die Haupttabelle, aber alles, was zum Unterteilen erforderlich ist, wird in einem separaten Schema erstellt:
call partition_run();
2. Aufgeschobene Aufgaben aufrufen, die während der Hauptarbeit geplant wurden:
call partition_run_jobs();
Die Arbeit kann in mehreren Threads gestartet werden. Die optimale Anzahl der Threads liegt nahe an der Anzahl der partitionierten Tabellen.
Eingabeparameter
für das Skript (_pt Datensatz)

Das Drehbuch von innen, die wichtigsten Aktionen:
- Erstellen Sie eine partitionierte Tabelle
perform _partition_create_parent_table(_pt);
- Abschnitte erstellen
perform _partition_create_child_tables(_pt);
- Kopieren Sie die Daten in den Abschnitt
perform _partition_copy_data(_pt);
- Einschränkungen hinzufügen (Job)
perform _partition_add_constraints(_pt);
- Stellen Sie Verknüpfungen zu externen Tabellen wieder her
perform _partition_restore_referrences(_pt);
- Trigger wiederherstellen
perform _partition_restore_triggers(_pt);
- Erstellen Sie einen Ereignisauslöser
perform _partition_def_tr_on_delete(_pt);
- Indizes erstellen (Job)
perform _partition_create_index(_pt);
- Ansichten, Abschnittsverknüpfungen ersetzen (Job)
perform _partition_replace_view(_pt);
Die Laufzeit des Skripts hängt von vielen Faktoren ab, die wichtigsten sind jedoch die Größe der Zieltabellen, die Anzahl der Beziehungen, die Indizes und die Servereigenschaften. In meinem Fall war eine 300-GB-Tabelle in weniger als einer Stunde partitioniert.
Ergebnis
Was haben wir bekommen? Schauen wir uns den Abfrageplan an:
EXPLAIN ANALYZE select * from “sales” where dt BETWEEN '01.01.2019'::date and '14.01.2019'::date

Wir haben das Ergebnis aus der partitionierten Tabelle schneller erhalten und haben weniger Ressourcen unseres Servers im Vergleich zur Abfrage einer regulären Tabelle verwendet.
In diesem Beispiel befinden sich reguläre und partitionierte Tabellen auf derselben Basis und haben ungefähr 200 Millionen Datensätze. Dies ist ein gutes Ergebnis, da wir, ohne den Anwendungscode umzuschreiben, eine Beschleunigung erhalten haben. Abfragen in anderen Indizes funktionieren ebenfalls gut, aber denken Sie daran: Immer wenn wir einen Abschnitt bestimmen können, ist das Ergebnis um ein Vielfaches schneller, weil PostgreSql kann zusätzliche Abschnitte in der Anforderungsplanungsphase verwerfen (
enable_partition_pruning auf on setzen ).
Zusammenfassung
Ich konnte die Partitionierung in Tabellen implementieren, die viele Beziehungen aufweisen und die Datenbankintegrität gewährleisten. Das Skript ist unabhängig von bestimmten Datenstrukturen und kann wiederverwendet werden.
PostgreSQL ist die fortschrittlichste relationale Open-Source-Datenbank der Welt!Danke an alle!
Link zur Quelle