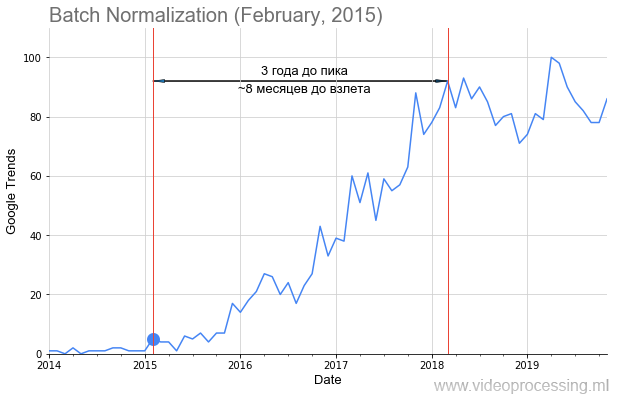
Das neue Jahr rückt näher, die 2010er werden bald enden und der Welt die sensationelle Renaissance neuronaler Netze bescheren. Ich war
durch einen einfachen Gedanken beunruhigt
und konnte nicht schlafen : „Wie können wir die Entwicklungsgeschwindigkeit neuronaler Netze rückblickend abschätzen?“ Für „Wer die Vergangenheit kennt, kennt die Zukunft“. Wie schnell haben sich verschiedene Algorithmen durchgesetzt? Wie kann man die Geschwindigkeit des Fortschritts in diesem Bereich einschätzen und die Geschwindigkeit des Fortschritts im nächsten Jahrzehnt abschätzen?

Es ist klar, dass Sie die Anzahl der Artikel in verschiedenen Bereichen grob berechnen können. Die Methode ist nicht ideal, Sie müssen Subdomains berücksichtigen, aber im Allgemeinen können Sie es versuchen. Ich gebe eine Idee, auf
Google Scholar (BatchNorm) ist es ganz real! Sie können neue Datensätze berücksichtigen, Sie können neue Kurse. Nachdem Ihr bescheidener Diener mehrere Optionen ausgewählt hatte, entschied er sich für
Google Trends (BatchNorm) .
Meine Kollegen und ich haben Anfragen von den wichtigsten ML / DL-Technologien, z. B.
Batch-Normalisierung, entgegengenommen , wie in der Abbildung oben dargestellt, das Veröffentlichungsdatum des Artikels in regelmäßigen Abständen hinzugefügt und einen recht guten Zeitplan für die Popularität des Themas erstellt. Aber nicht für alle, der
Weg ist mit Rosen übersät, der Start ist so offensichtlich und wunderschön wie beim Fledermaus. Einige Begriffe, z. B. Regularisierung oder Überspringen von Verbindungen, konnten aufgrund von Datenrauschen überhaupt nicht erstellt werden. Generell ist es uns jedoch gelungen, Trends zu sammeln.
Wen kümmert es, was passiert ist - willkommen beim Schnitt!
Anstatt einzuführen oder über Bilderkennung
Also! Die anfänglichen Daten waren ziemlich verrauscht, manchmal gab es scharfe Spitzen.
 Quelle: Andrei Karpaty twitter - Studenten stehen vor einem riesigen Publikum und hören einen Vortrag über Faltungsnetzwerke
Quelle: Andrei Karpaty twitter - Studenten stehen vor einem riesigen Publikum und hören einen Vortrag über FaltungsnetzwerkeKonventionell reichte es für
Andrey Karpaty , einen Vortrag über das legendäre
CS231n zu halten: Convolutional Neural Networks for Visual Recognition für 750 Personen mit der Popularisierung des Konzepts, wie ein scharfer Gipfel verläuft. Daher wurden die Daten mit einem einfachen
Box-Filter geglättet (alle geglätteten Outs sind auf der Achse als geglättet markiert). Da wir daran interessiert waren, die Wachstumsrate der Popularität zu vergleichen, wurden nach dem Glätten alle Daten normalisiert. Es ist ziemlich lustig geworden. Hier ist eine Grafik der Hauptarchitekturen, die auf ImageNet konkurrieren:
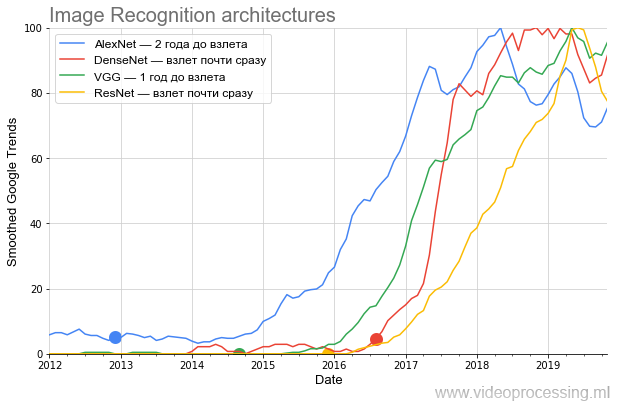 Quelle: Nachstehend - Berechnungen des Autors gemäß Google Trends
Quelle: Nachstehend - Berechnungen des Autors gemäß Google TrendsDie Grafik zeigt sehr deutlich, dass nach der sensationellen Publikation
AlexNet , die Ende 2012 den Brei des aktuellen Hype neuronaler Netze braute, für fast zwei Jahre
entgegen den Behauptungen des Haufens nur ein relativ enger Kreis von Spezialisten
hinzukam . Das Thema wurde erst im Winter 2014–2015 der Öffentlichkeit zugänglich gemacht. Achten Sie darauf, wie periodisch der Zeitplan ab 2017 wird: Weitere Spitzen jeden Frühling.
In der Psychiatrie spricht man von einer Verschärfung des Frühlings ... Dies ist ein sicheres Zeichen dafür, dass der Begriff derzeit hauptsächlich von Studenten verwendet wird und das Interesse an AlexNet im Vergleich zum Höhepunkt der Popularität im Durchschnitt abnimmt.
In der zweiten Jahreshälfte 2014 ist die
VGG hinzugekommen. Übrigens hat
VGG zusammen mit der
Studienleiterin meiner ehemaligen Studentin
Karen Simonyan geschrieben , die jetzt in Google DeepMind (
AlphaGo ,
AlphaZero usw.) arbeitet. Während ihres Studiums an der Moskauer Staatlichen Universität im 3. Jahr implementierte Karen einen guten
Algorithmus zur
Bewegungsschätzung , der seit 12 Jahren als Referenz für zweijährige Studenten dient. Außerdem sind die Aufgaben dort ziemlich ähnlich. Vergleichen Sie:
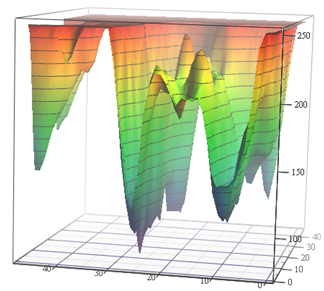
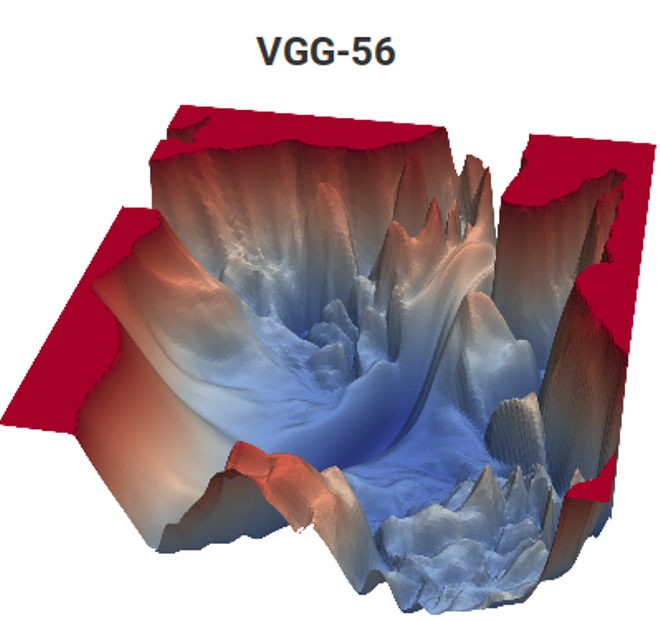 Quelle: Verlustfunktion für Bewegungsschätzungsaufgaben (Autorenmaterialien) und VGG-56
Quelle: Verlustfunktion für Bewegungsschätzungsaufgaben (Autorenmaterialien) und VGG-56Links müssen Sie den tiefsten Punkt in einer nichttrivialen Oberfläche in Abhängigkeit von den Eingabedaten für die minimale Anzahl von Messungen finden (viele lokale Minima sind möglich), und rechts müssen Sie einen niedrigeren Punkt mit minimalen Berechnungen finden (und auch eine Reihe von lokalen Minima, und die Oberfläche hängt auch von den Daten ab). . Links erhalten wir den vorhergesagten Bewegungsvektor und rechts das trainierte Netzwerk. Der Unterschied besteht darin, dass links nur eine implizite Messung des Farbraums erfolgt und rechts zwei Messungen von Hunderten von Millionen. Die rechnerische Komplexität auf der rechten Seite ist ungefähr 12 Größenordnungen (!) Höher. Ein bisschen wie das ... Aber das zweite Jahr, auch mit einer einfachen Aufgabe, schwankt wie ... [durch Zensur herausgeschnitten]. Und das Programmniveau der gestrigen Schüler ist aus unbekannten Gründen in den letzten 15 Jahren deutlich gesunken. Sie müssen sagen: "Du wirst es gut machen, sie werden dich zu DeepMind bringen!" Man könnte sagen "erfinde VGG", aber "sie werden zu DeepMind" motiviert aus irgendeinem Grund besser. Dies ist offensichtlich ein modernes, fortgeschrittenes Analogon des Klassikers "Sie werden Grieß essen, Sie werden Astronaut!". Wenn wir jedoch die Anzahl der Kinder im Land und die Größe des Kosmonauten-Corps zählen, sind die Chancen millionenfach höher, da zwei von uns bereits von unserem Labor aus bei DeepMind arbeiten.
Als nächstes kam
ResNet , das die Messlatte für die Anzahl der Schichten durchbrach und nach sechs Monaten zu starten begann. Und schließlich startete DenseNet, das zu Beginn des Hype stand
, fast sofort, sogar noch cooler als ResNet.
Wenn wir über Popularität sprechen, möchte ich einige Worte über die Eigenschaften des Netzwerks und die Leistung hinzufügen, von denen auch die Popularität abhängt. Wenn Sie sich ansehen, wie die
ImageNet- Klasse in Abhängigkeit von der Anzahl der Operationen im Netzwerk vorhergesagt wird, sieht das Layout folgendermaßen aus (höher und links - besser):
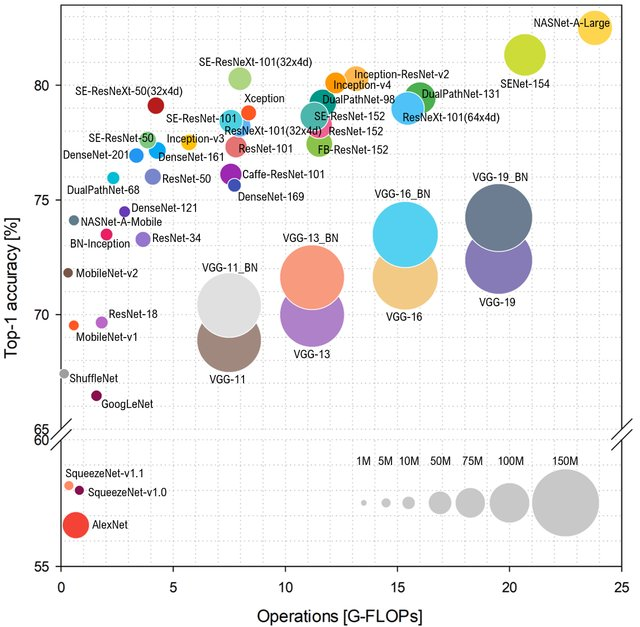 Quelle: Benchmark-Analyse repräsentativer Deep Neural Network-Architekturen
Quelle: Benchmark-Analyse repräsentativer Deep Neural Network-ArchitekturenTyp AlexNet ist kein Kinderspiel mehr und sie regieren Netzwerke, die auf ResNet basieren. Wenn Sie sich jedoch die praktische Bewertung von
FPS näher an meinem Herzen ansehen, können Sie deutlich erkennen, dass VGG hier näher am Optimum ist und sich die Ausrichtung im Allgemeinen merklich ändert. Einfügen von AlexNet unerwartet in die paretooptimale Hüllkurve (horizontale Skala ist logarithmisch, besser oben und rechts):
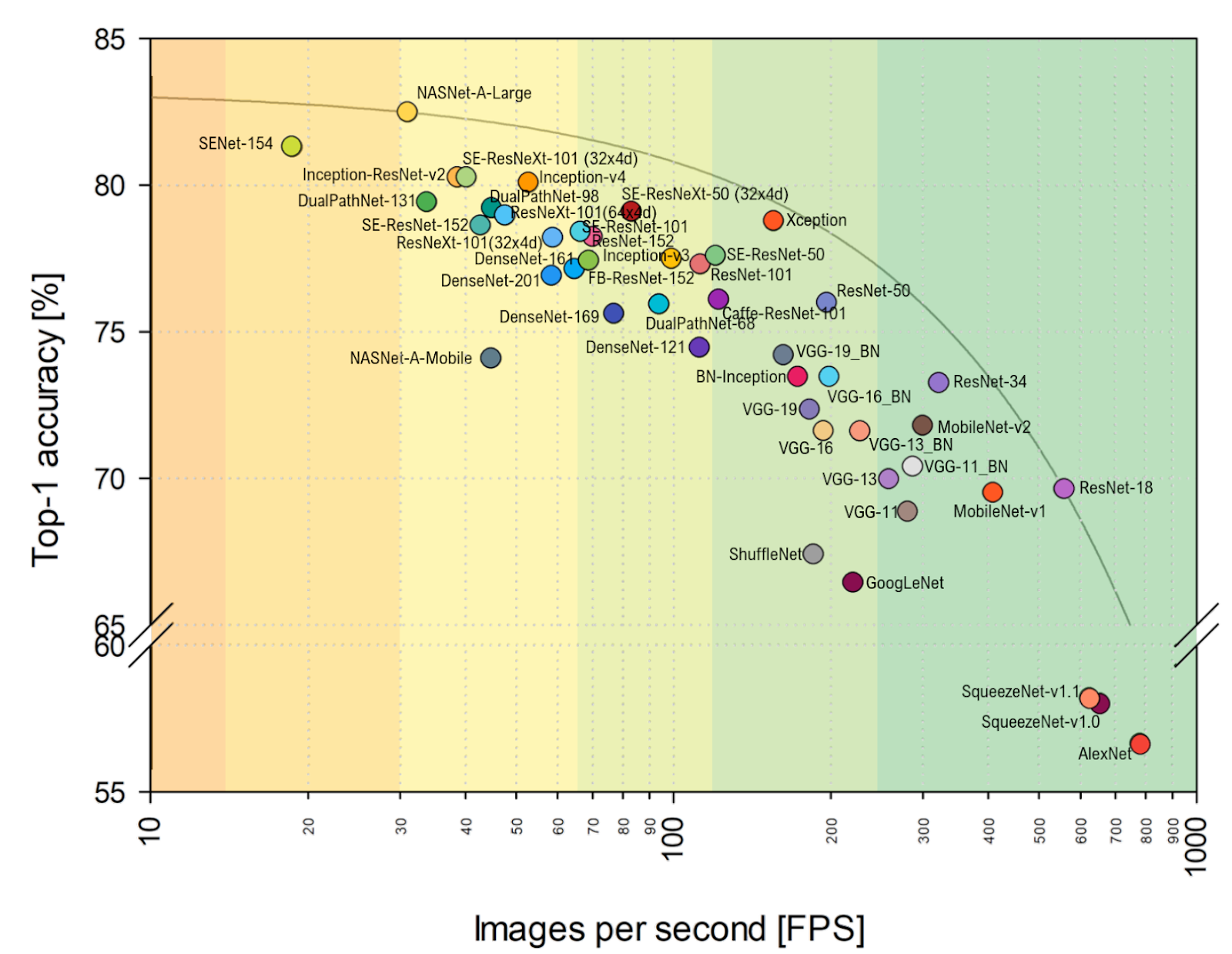 Quelle: Benchmark-Analyse repräsentativer Deep Neural Network-ArchitekturenGesamt:
Quelle: Benchmark-Analyse repräsentativer Deep Neural Network-ArchitekturenGesamt:
- In den kommenden Jahren wird sich die Ausrichtung von Architekturen mit hoher Wahrscheinlichkeit aufgrund des Fortschritts der Beschleuniger für neuronale Netze erheblich ändern, wenn einige Architekturen in Körbe gehen und andere plötzlich abheben, einfach weil es besser ist, sich auf neue Hardware zu legen. In dem erwähnten Artikel wird beispielsweise ein Vergleich zwischen dem NVIDIA Titan X Pascal und dem NVIDIA Jetson TX1-Board durchgeführt, und das Layout ändert sich merklich. Gleichzeitig hat der Fortschritt von TPU, NPU und anderen gerade erst begonnen.
- Als Praktiker kann ich nur bemerken, dass der Vergleich in ImageNet standardmäßig in ImageNet-1k und nicht in ImageNet-22k durchgeführt wird, einfach weil die meisten ihre Netzwerke in ImageNet-1k trainieren, wo es 22-mal weniger Klassen gibt (dies) einfacher und schneller). Der Wechsel zu ImageNet-22k, das für viele praktische Anwendungen relevanter ist, ändert auch die Ausrichtung (für diejenigen, die um 1k geschärft sind - viel).
Tiefer in Technologie und Architektur
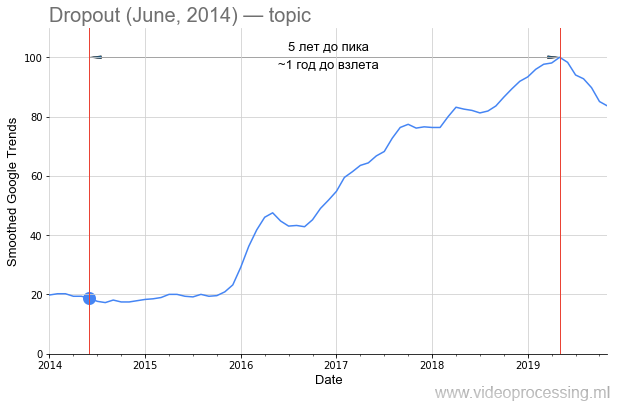
Zurück zur Technik. Der Begriff
Dropout als Suchwort ist ziemlich laut, aber das fünffache Wachstum ist eindeutig mit neuronalen Netzen verbunden. Und der Rückgang des Interesses daran ist höchstwahrscheinlich mit einem
Google-Patent und dem Aufkommen neuer Methoden verbunden. Bitte beachten Sie, dass von der Veröffentlichung des
Originalartikels ungefähr anderthalb Jahre vergangen sind, bis das Interesse an der Methode gewachsen ist:
Wenn wir jedoch über die Zeit vor dem Anstieg der Popularität sprechen, dann wird in DL einer der ersten Plätze eindeutig von
wiederkehrenden Netzwerken und
LSTM eingenommen :
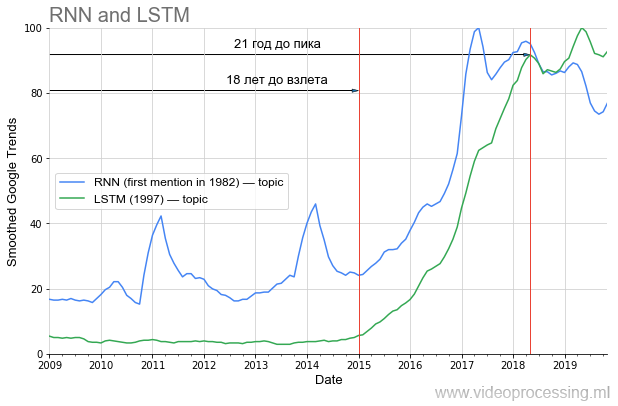
Lange vor 20 Jahren, vor dem Höhepunkt der Popularität, wurden die maschinellen Übersetzungen und die Genomanalysen jetzt radikal verbessert. In naher Zukunft wird der Netflix-Datenverkehr bei YouTube bei gleicher Bildqualität zweimal sinken. Wenn Sie die Lehren aus der Geschichte richtig ziehen, ist es offensichtlich, dass ein Teil der Ideen aus dem aktuellen Artikelschacht erst nach 20 Jahren „abhebt“. Führe einen gesunden Lebensstil, pass auf dich auf und du wirst es persönlich sehen!
Nun näher an dem versprochenen Hype.
So starteten die GANs :
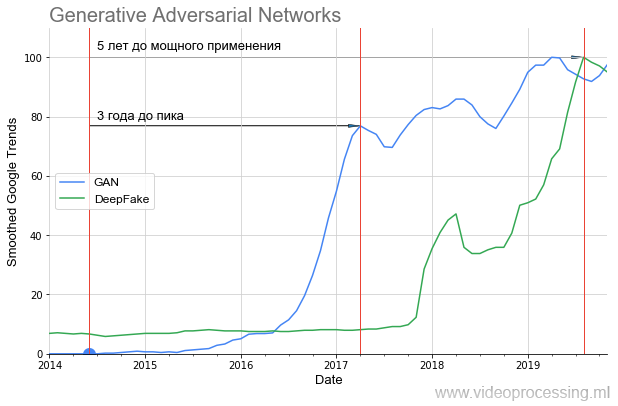
Es ist deutlich zu erkennen, dass es fast ein Jahr lang zu einer völligen Stille kam und erst 2016, nach 2 Jahren, ein starker Anstieg einsetzte (die Ergebnisse wurden spürbar verbessert). Dieser Start ein Jahr später brachte den sensationellen DeepFake, der jedoch auch 1,5 Jahre lang startete. Das heißt, selbst vielversprechende Technologien benötigen viel Zeit, um von einer Idee zu Anwendungen zu gelangen, die jeder nutzen kann.
Wenn Sie sich ansehen, welche Bilder die GAN im
Originalartikel erzeugt hat und was mit
StyleGAN erstellt werden kann , wird deutlich, warum es so still war. Im Jahr 2014 konnten nur Spezialisten bewerten, wie cool es war - im Wesentlichen ein weiteres Netzwerk als Verlustfunktion zu erstellen und gemeinsam zu trainieren. Und im Jahr 2019 konnte jedes Schulkind erkennen, wie cool das ist (ohne genau zu verstehen, wie das gemacht wird):

Heutzutage
gibt es viele verschiedene Probleme, die von neuronalen Netzen erfolgreich gelöst werden. Sie können die besten Netze verwenden und Beliebtheitsgraphen für jede Richtung erstellen, mit Rauschen und Spitzenwerten von Suchanfragen umgehen usw. Um meine Gedanken nicht über den Baum zu verbreiten, beenden wir diese Auswahl mit dem Thema Segmentierungsalgorithmen, bei denen sich die Ideen der
atrous / dilated Convolution und des
ASPP in den letzten eineinhalb Jahren
im Algorithmus-Benchmark ziemlich verbreitet haben:
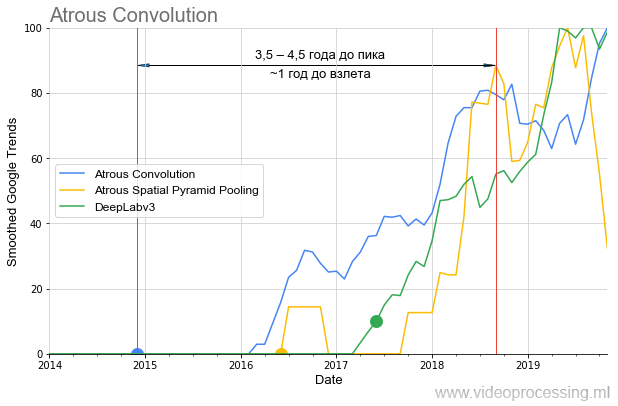
Es sollte auch beachtet werden, dass wenn
DeepLabv1 mehr als ein Jahr auf den Anstieg der Popularität „gewartet“ hat,
DeepLabv2 in einem Jahr
gestartet ist und
DeepLabv3 fast sofort. Das heißt Im Allgemeinen können wir über die Beschleunigung des Interessenswachstums im Laufe der Zeit sprechen (oder über die Beschleunigung des Interessenswachstums an Technologien renommierter Autoren).
All dies zusammen führte zur Entstehung des folgenden globalen Problems - einer explosionsartigen Zunahme der Veröffentlichungen zu diesem Thema:
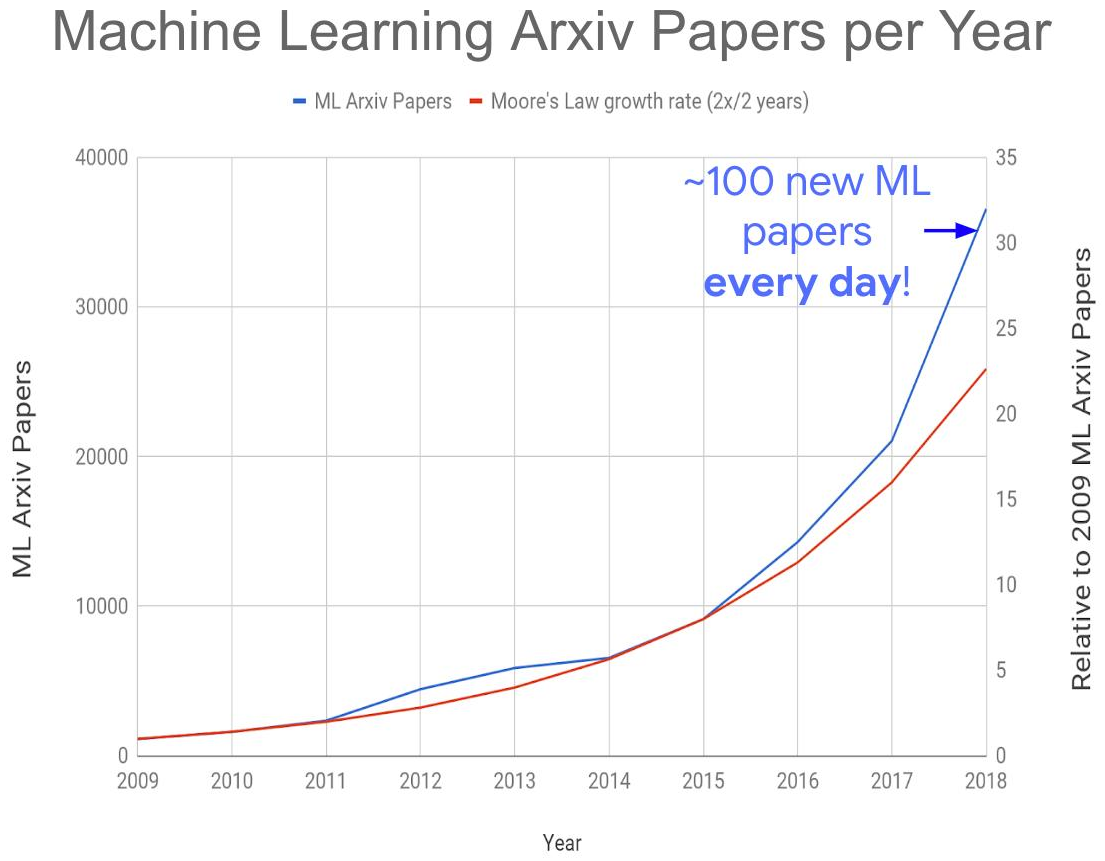 Quelle: Zu viele maschinelle Lernpapiere?
Quelle: Zu viele maschinelle Lernpapiere?In diesem Jahr erhalten wir ungefähr 150-200 Artikel pro Tag, da nicht alle auf arXiv-e veröffentlicht sind. Es ist heute völlig unmöglich, Artikel auch in ihrem eigenen Unterbereich zu lesen. Infolgedessen werden sicherlich viele interessante Ideen in den Trümmern neuer Veröffentlichungen vergraben sein, die sich auf den Zeitpunkt ihres „Starts“ auswirken werden. Aber auch der
explosionsartige Zuwachs an kompetenten Fachkräften in der Region lässt
wenig Hoffnung, das Problem zu bewältigen.
Gesamt:
- Zusätzlich zu ImageNet und der Geschichte hinter den Kulissen der Spieleerfolge von DeepMind haben GANs eine neue Welle der Popularisierung neuronaler Netze ausgelöst. Mit ihnen war es wirklich möglich, Schauspieler ohne Kamera zu „drehen“ . Und ob es noch mehr geben wird! Unter diesem Informationsrauschen werden weniger sonore, aber durchaus funktionierende Verarbeitungs- und Erkennungstechnologien finanziert.
- Da es zu viele Veröffentlichungen gibt, freuen wir uns auf die Entwicklung neuer neuronaler Netzwerkmethoden für die schnelle Analyse von Artikeln, denn nur sie werden uns retten (ein Witz mit einem Bruchteil eines Witzes!).
Arbeitsroboter, glücklicher Mann
AutoML erfreut sich seit 2 Jahren wachsender Beliebtheit
auf den Zeitungsseiten . Begonnen hat alles traditionell mit ImageNet, in dem er in Top-1 Accuracy die ersten Plätze fest einnahm:
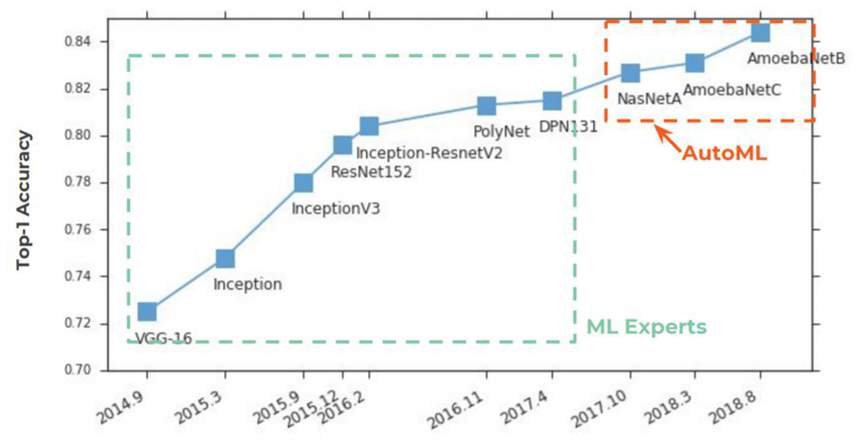
Die Essenz von AutoML ist sehr einfach, ein jahrhundertealter Traum von Datenwissenschaftlern ist darin wahr geworden - für ein neuronales Netzwerk zur Auswahl von Hyperparametern. Die Idee wurde mit einem Knall begrüßt:
Unten in der Grafik sehen wir eine eher seltene Situation, in der sie nach der Veröffentlichung von
Quellartikeln auf
NASNet und
AmoebaNet im
Vergleich zu früheren Ideen fast augenblicklich an Popularität gewinnen (ein großes Interesse am Thema wirkt sich aus):
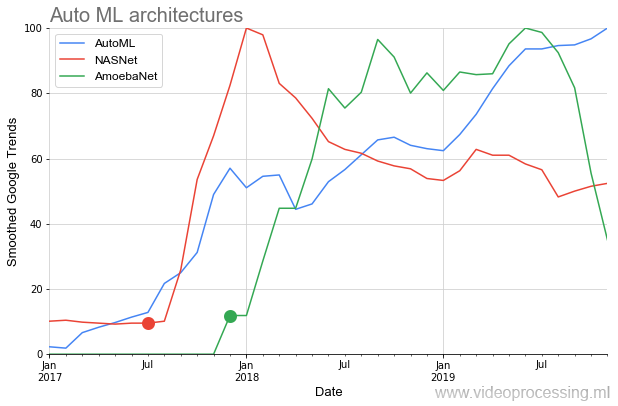
Das idyllische Bild wird durch zwei Punkte etwas verdorben. Erstens beginnt jedes Gespräch über AutoML mit dem Satz: "Wenn Sie ein GPU-Dofigalion haben ...". Und das ist das Problem. Google behauptet natürlich, dass dies mit seiner
Cloud AutoML leicht zu lösen ist.
Hauptsache, Sie haben genug Geld , aber nicht jeder stimmt diesem Ansatz zu. Zweitens funktioniert es soweit
unvollkommen . Auf der anderen Seite sind, unter Hinweis auf die GANs, noch keine fünf Jahre vergangen, und die Idee selbst sieht sehr vielversprechend aus.
In jedem Fall beginnt der Hauptstart von AutoML mit der nächsten Generation von Hardwarebeschleunigern für neuronale Netze und in der Tat mit verbesserten Algorithmen.
 Quelle: Bild von Dmitry Konovalchuk, Materialien des AutorsTotal: Tatsächlich werden Datenwissenschaftler natürlich keinen ewigen Urlaub haben, da die Daten für eine sehr lange Zeit große Kopfschmerzen bereiten werden. Aber warum nicht vor dem neuen Jahr und dem Beginn der 2020er Jahre träumen?
Quelle: Bild von Dmitry Konovalchuk, Materialien des AutorsTotal: Tatsächlich werden Datenwissenschaftler natürlich keinen ewigen Urlaub haben, da die Daten für eine sehr lange Zeit große Kopfschmerzen bereiten werden. Aber warum nicht vor dem neuen Jahr und dem Beginn der 2020er Jahre träumen?Ein paar Worte zu Werkzeugen
Die Wirksamkeit der Forschung hängt stark von den Instrumenten ab. Wenn Sie für die Programmierung von AlexNet nicht-triviale Programmierung benötigten, kann ein solches Netzwerk heute in mehreren Zeilen in neuen Frameworks gesammelt werden.
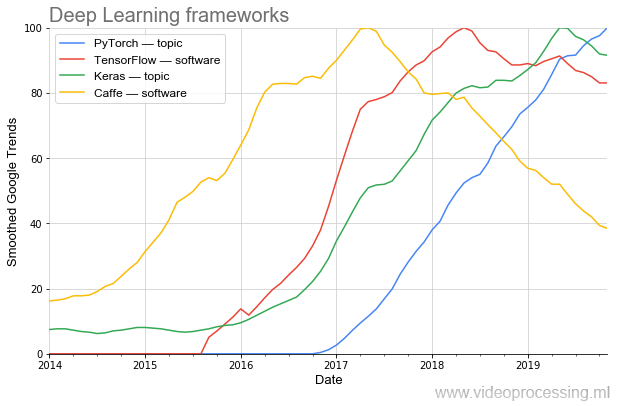
Es ist deutlich zu sehen, wie sich die Popularität in Wellen verändert. Heute ist
PyTorch das beliebteste (auch
laut PapersWithCode ). Und einmal verlässt der beliebte
Caffe wunderbar ganz reibungslos. (Hinweis: Thema und Software bedeuten, dass beim Plotten die Themenfilterung von Google verwendet wurde.)
Nun, da wir uns mit Entwicklungstools befasst haben, sollten Bibliotheken erwähnt werden, um die Netzwerkausführung zu beschleunigen:
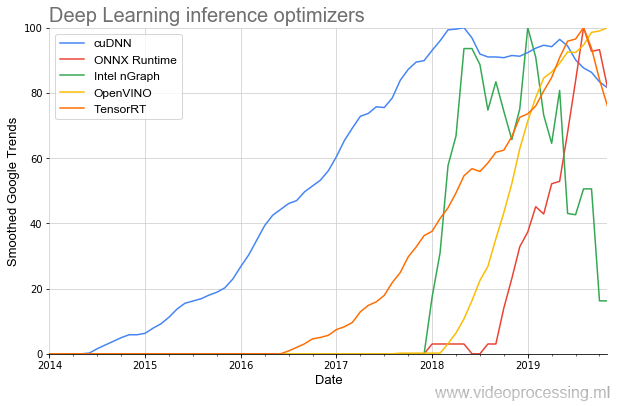
Das älteste Thema ist (in Bezug auf NVIDIA)
cuDNN , und zum Glück für Entwickler ist die Anzahl der Bibliotheken in den letzten Jahren um ein Vielfaches gestiegen, und der Beginn ihrer Beliebtheit ist deutlich steiler geworden. Und es scheint, dass dies alles nur der Anfang ist.
Insgesamt: Auch in den letzten 3 Jahren haben sich die Werkzeuge stark zum Besseren gewandelt. Und vor 3 Jahren waren sie nach heutigen Maßstäben überhaupt nicht. Der Fortschritt ist sehr gut!Versprochene Perspektiven für neuronale Netze
Aber der Spaß beginnt später. In diesem Sommer habe ich in einem
separaten großen Artikel ausführlich beschrieben, warum die CPU und sogar die GPU nicht effizient genug sind, um mit neuronalen Netzen zu arbeiten, warum Milliarden von Dollar in die Entwicklung neuer Chips fließen und welche Aussichten bestehen. Ich werde mich nicht wiederholen. Nachfolgend finden Sie eine Verallgemeinerung und Ergänzung des vorherigen Textes.
Zunächst müssen Sie die Unterschiede zwischen neuronalen Netzwerkberechnungen und Berechnungen in der bekannten von Neumann-Architektur verstehen (in der sie natürlich berechnet werden können, aber weniger effizient sind):
 Quelle: Bild von Dmitry Konovalchuk, Materialien des Autors
Quelle: Bild von Dmitry Konovalchuk, Materialien des AutorsBeim vorherigen Mal drehte sich die Hauptdiskussion um FPGA / ASIC, und ungenaue Berechnungen blieben fast unbemerkt. Lassen Sie uns daher näher darauf eingehen. Die enormen Aussichten für die Reduzierung der Chips der nächsten Generationen liegen genau in der Fähigkeit, ungenau zu lesen (und Koeffizientendaten lokal zu speichern). Tatsächlich wird die Vergröberung auch in der exakten Arithmetik verwendet, wenn die Netzwerkgewichte in ganze Zahlen umgewandelt und quantisiert werden, jedoch auf einer neuen Ebene. Betrachten Sie als Beispiel einen Einzelbit-Addierer (das Beispiel ist ziemlich abstrakt):
 Quelle: Ein 8-Bit-x-8-Bit-Multiplikator-Design mit hoher Geschwindigkeit und geringem Stromverbrauch unter Verwendung neuartiger 2-Transistor-XOR-Gatter
Quelle: Ein 8-Bit-x-8-Bit-Multiplikator-Design mit hoher Geschwindigkeit und geringem Stromverbrauch unter Verwendung neuartiger 2-Transistor-XOR-GatterEr braucht 6 Transistoren (es gibt verschiedene Ansätze, die Anzahl der benötigten Transistoren kann immer geringer sein, aber im Allgemeinen ungefähr so). Für 8 Bits sind ungefähr
48 Transistoren erforderlich. In diesem Fall benötigt der Analogaddierer nur 2 (zwei!) Transistoren, d.h. 24 mal weniger:
 Quelle: Analoge Multiplikatoren (Analyse und Entwurf analoger integrierter Schaltungen)
Quelle: Analoge Multiplikatoren (Analyse und Entwurf analoger integrierter Schaltungen)Wenn die Genauigkeit höher ist (z. B. entsprechend 10 oder 16 Bit), ist die Differenz noch größer. Noch interessanter ist die Situation mit der Multiplikation! Wenn ein digitaler 8-Bit-Multiplexer ungefähr
400 Transistoren benötigt , dann wird eine analoge 6, d.h. 67 mal (!) Weniger. Natürlich unterscheiden sich "analoge" und "digitale" Transistoren vom Standpunkt der Schaltung her erheblich, aber die Idee ist klar: Wenn es uns gelingt, die Genauigkeit analoger Berechnungen zu erhöhen, erreichen wir leicht die Situation, in der wir zwei Größenordnungen weniger Transistoren benötigen. Dabei geht es nicht so sehr um die Reduzierung der Größe (was im Zusammenhang mit der „Verlangsamung von Moores Gesetz“ wichtig ist), sondern um die Reduzierung des Stromverbrauchs, der für mobile Plattformen von entscheidender Bedeutung ist. Und für Rechenzentren wird es nicht überflüssig sein.
 Quelle: IBM denkt an analoge Chips, um das maschinelle Lernen zu beschleunigen
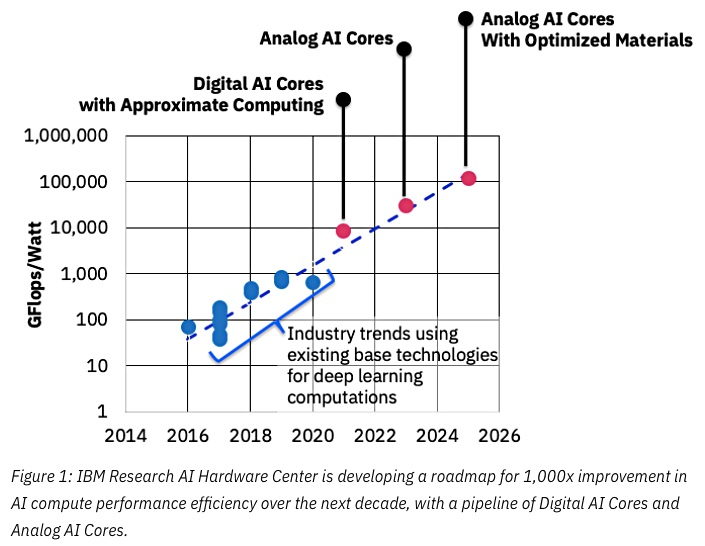
Quelle: IBM denkt an analoge Chips, um das maschinelle Lernen zu beschleunigenDer Schlüssel zum Erfolg wird hier eine Verringerung der Genauigkeit sein, und auch hier steht IBM an vorderster Front:
 Quelle: IBM Research Blog: 8-Bit-Präzision für das Training von Deep Learning-Systemen
Quelle: IBM Research Blog: 8-Bit-Präzision für das Training von Deep Learning-SystemenSie beschäftigen sich bereits mit spezialisierten ASICs für neuronale Netze, die eine mehr als 10-fache Überlegenheit gegenüber der GPU aufweisen, und planen, in den kommenden Jahren eine 100-fache Überlegenheit zu erreichen. Es sieht sehr ermutigend aus, wir freuen uns sehr darauf, denn ich wiederhole, dies wird ein Durchbruch für mobile Geräte sein.
Bisher ist die Situation nicht so magisch, obwohl es ernsthafte Erfolge gibt. Hier ist ein interessanter Test der aktuellen mobilen Hardwarebeschleuniger von neuronalen Netzen (das Bild ist anklickbar und das erwärmt die Seele des Autors erneut, auch in Bildern pro Sekunde):
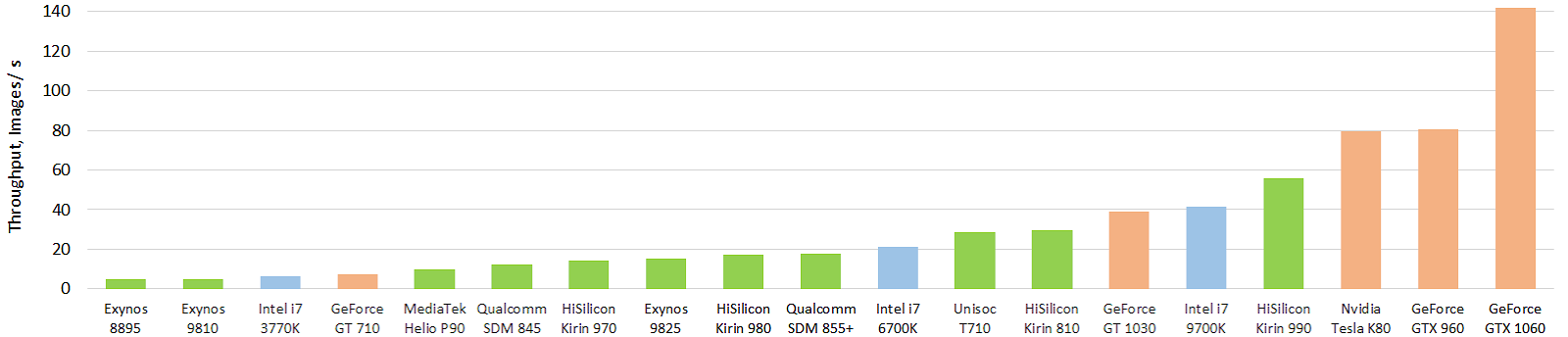 Quelle: Leistungsentwicklung mobiler AI-Beschleuniger: Bilddurchsatz für das Float-Inception-V3-Modell (FP16-Modell unter Verwendung von TensorFlow Lite und NNAPI)
Quelle: Leistungsentwicklung mobiler AI-Beschleuniger: Bilddurchsatz für das Float-Inception-V3-Modell (FP16-Modell unter Verwendung von TensorFlow Lite und NNAPI)Grün zeigt mobile Chips an, blau zeigt CPU an, orange zeigt GPU an. Es ist deutlich zu sehen, dass die aktuellen mobilen Chips und vor allem der Top-End-Chip von Huawei bereits die zehnfach größere CPU (und den zehnfach größeren Stromverbrauch) überholen. Und es ist stark! Mit der GPU ist bisher alles nicht so magisch, aber es wird noch etwas anderes geben. Sie können die Ergebnisse detaillierter auf einer separaten Website unter
http://ai-benchmark.com/ ansehen.
Beachten Sie den dortigen Testabschnitt. Sie haben eine gute Reihe von Algorithmen zum Vergleich ausgewählt.
Insgesamt: Der Fortschritt analoger Beschleuniger ist heute recht schwer zu bewerten. Es gibt ein Rennen. Die Produkte sind jedoch noch nicht erschienen, so dass es relativ wenige Veröffentlichungen gibt. Sie können Patente überwachen, die verzögert angezeigt werden (z. B. dichter Datenfluss von IBM ), oder nach seltenen Patenten anderer Hersteller suchen. Es scheint, dass dies eine sehr ernste Revolution sein wird, vor allem bei Smartphones und Server-TPUs.Anstelle einer Schlussfolgerung
ML / DL heißt heute eine neue Programmiertechnologie, wenn wir kein Programm schreiben, sondern einen Block einfügen und trainieren. Das heißt Wie anfangs gab es einen Assembler, dann C, dann C ++, und jetzt, nach langen 30 Jahren des Wartens, ist der nächste Schritt ML / DL:
Das macht Sinn. In jüngster Zeit werden in fortgeschrittenen Unternehmen Entscheidungsorte in Programmen durch neuronale Netze ersetzt. Das heißt « IF-» (!) , 3-5 . , , . ,
, , , , , . -!
, . , - , : « , !»
, , , , (, !) . : « , !» , . «» « !» ( ). . !
Als mathematisches Werkzeug ist ML / DL im Allgemeinen und neuronale Netze im Besonderen jedoch eindeutig mehr als die nächste Programmiertechnologie. Die gleichen neuronalen Netze werden jetzt einfach bei jedem Schritt gefunden:- Das Smartphone macht Bilder des Textes und erkennt ihn - das sind neuronale Netze,
- Ein Smartphone lässt sich im Handumdrehen von einer Sprache in eine andere übersetzen und spricht eine Übersetzung - neuronale Netze und wiederum neuronale Netze.
- Der Navigator und der intelligente Sprecher erkennen die Sprache recht gut - wieder neuronale Netze,
- Der Fernseher zeigt ein helles Kontrastbild von 8K aus dem eingegebenen 2K-Video - ebenfalls ein neuronales Netzwerk.
- Roboter in der Produktion wurden genauer, sie begannen, abnormale Situationen besser zu sehen und zu erkennen - wieder neuronale Netze,
- 10 ,
- — ,
- — - — ,
- Im Allgemeinen - neuronale Netze sind jetzt absolut überall! )

Es sind nur 4 Jahre vergangen, seit Menschen dank BatchNorm (2015) und Skip Connections (2015) in vielerlei Hinsicht gelernt haben, wirklich tiefe neuronale Netze zu trainieren, und 3 Jahre sind vergangen, seit sie „abgehoben“ haben, und wir lesen wirklich die Ergebnisse ihrer Arbeit habe nicht gesehen. Und jetzt werden sie die Produkte erreichen. Etwas sagt uns, dass in den kommenden Jahren viele interessante Dinge auf uns warten. Vor allem, wenn Beschleuniger "abheben" ...

Es war einmal, wenn sich jemand daran erinnert, dass Prometheus dem Olymp das Feuer gestohlen und es den Menschen übergeben hat. Der zornige Zeus mit anderen Göttern schuf die erste Schönheit einer Frau namens Pandora, die mit vielen wundervollen weiblichen Eigenschaften ausgestattet war
(mir wurde plötzlich klar, dass die politisch korrekte Nacherzählung einiger Mythen des antiken Griechenlands äußerst schwierig ist) . Pandora wurde zu Leuten geschickt, aber Prometheus, der vermutete, dass etwas nicht stimmte, widerstand ihrem Zauber und sein Bruder Epimetheus nicht. Als Geschenk für die Hochzeit sandte Zeus einen schönen Sarg mit Merkur und Merkur, eine gütige Seele, erfüllte den Befehl - er gab den Sarg Epimetheus, warnte ihn aber, ihn auf keinen Fall zu öffnen. Die neugierige Pandora hat ihrem Mann den Sarg gestohlen und geöffnet, aber es gab nur Sünden, Krankheiten, Kriege und andere Probleme der Menschheit. Sie versuchte den Sarg zu schließen, aber es war zu spät:
 Quelle: Künstler Frederick Stuart Church, Büchse der Pandora
Quelle: Künstler Frederick Stuart Church, Büchse der PandoraSeitdem ist der Ausdruck "Öffne die Büchse der Pandora" verschwunden, das heißt,
aus Neugier eine irreversible Handlung
auszuführen , deren Folgen möglicherweise nicht so schön sind wie die Verzierungen des Sarges auf der Außenseite.
Je tiefer ich in die neuronalen Netze eintauche, desto ausgeprägter ist das Gefühl, dass dies eine andere Büchse von Pandora ist. Die Menschheit hat jedoch die größte Erfahrung mit dem Öffnen solcher Kisten! Aus der jüngsten Vergangenheit - das ist Kernenergie und das Internet. Ich denke also, wir können zusammen fertig werden. Kein Wunder, dass ein Haufen rauer
Bärtiger unter den Eröffnern ist. Nun, ein Sarg ist wunderschön, stimme zu! Und es ist nicht wahr, dass es nur Probleme gibt, sie haben bereits ein paar gute Dinge. Deshalb kamen sie zusammen und ... wir öffnen weiter!
Gesamt:
- Der Artikel enthielt nicht viele interessante Themen, zum Beispiel klassische ML-Algorithmen, Transferlernen, Bestärkungslernen, die Beliebtheit von Datensätzen usw. (Meine Herren, Sie können das Thema fortsetzen!)
- Zur Frage zum Sarg: Ich persönlich finde die Google-Programmierer , die es Google ermöglicht haben, den 10-Milliarden-Dollar-Pentagon-Vertrag aufzugeben, großartig und ansehnlich. Sie respektieren und respektieren. Beachten Sie jedoch, dass jemand diese Hauptausschreibung gewonnen hat.
Lesen Sie auch:
- Hardwarebeschleunigung tiefer neuronaler Netze: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP und andere Briefe - der Autorentext über den aktuellen Stand und die Perspektiven der Hardwarebeschleunigung neuronaler Netze im Vergleich zu aktuellen Ansätzen.
- Deep Fake Science, die Krise der Reproduzierbarkeit und woher leere Repositories kommen - über die Probleme in der Wissenschaft, die durch ML / DL erzeugt werden.
- Street Magic Codec Vergleich. Wir enthüllen Geheimnisse - ein Beispiel für eine Fälschung, die auf neuronalen Netzen basiert.
Alles eine große Anzahl neuer interessanter Entdeckungen in den 2020er Jahren im Allgemeinen und im Neuen Jahr im Besonderen!
Danksagung
Ich möchte mich herzlich bedanken bei:
- Labor für Computergrafik und Multimedia VMK Moscow State University M.V. Lomonosov für seinen Beitrag zur Entwicklung des tiefen Lernens in Russland und nicht nur
- persönlich Konstantin Kozhemyakov und Dmitry Konovalchuk, die viel getan haben, um diesen Artikel besser und visueller zu machen,
- und zum Schluss vielen Dank an Kirill Malyshev, Jegor Sklyarov, Nikolai Oplachko, Andrej Moskalenko, Ivan Molodetsky, Evgeny Lyapustin, Roman Kazantsev, Alexander Yakovenko und Dmitry Klepikov für viele nützliche Kommentare und Korrekturen, die diesen Text viel besser gemacht haben!