In der IT ist ein gesundes Projekt ein System oder eine Dienstleistung, die einerseits von hoher Qualität ist, das heißt, sie erfüllt die Anforderungen und die Nutzer, die sie mögen. Andererseits macht es einen Gewinn, weil das Unternehmen immer wirklich Geld verdienen will. Ohne ein Bündel von Qualität und Geschäft wird nichts Gutes daraus.

Ruslan Ostropolsky wird Ihnen alles über Metriken erzählen, die Indikatoren für den Zustand von IT-Systemen sind. Er wird analysieren, was Metriken sind, wie sie sich im Verlauf des Projekts ändern, welche am besten in welchem Projekt verwendet werden. Erläutert, wie sich Qualität und Geschäft in Bezug auf Messdaten gegenseitig unterstützen und warum diese Zusammenarbeit erforderlich ist.
Über den Sprecher und das Unternehmen: Ruslan Ostropolsky in der IT seit 2010, das Hauptinteresse ist die Qualitätssicherung. In den letzten 5 Jahren arbeitete er bei DocDoc, einem Unternehmen, das medizinische Internetdienste entwickelt. Das Hauptprodukt ist ein Online-Termin bei einem Arzt, mehr als 2 Millionen Patienten haben sich über DocDoc für einen Arzt angemeldet, es gibt auch eine Reihe von Diagnose-, Telemedizin- und VHI-Versicherungen.
Wenn Qualität und Geschäft keine Freunde sind
Ohne Qualitätssicherung wird es für ein Unternehmen schwierig sein, auf lange Sicht Geld zu verdienen. Brauchen Sie eine Menge Qualität und Geschäft. Ist dies nicht der Fall, sind die folgenden Situationen möglich.
Erstens gibt es
Qualität zum Wohle der Qualität : Wenn alle bekannten Testarten in einem kleinen Startup verwendet werden. Sie können sofort über Automatisierung und Tests unter Last nachdenken, aber wenn Sie es übertreiben, erreicht das Produkt möglicherweise immer noch nicht die Produktion. Dafür benötigen Sie:
- Das Geschäft verstehen - was im Moment relevant ist: Geld verdienen, in den Markt eintreten oder schnell skalieren. Die Aufgabe des Unternehmens ist es, diese Ziele auf die technische Abteilung zu übertragen.
- Qualität am richtigen Ort und in der richtigen Menge. Manchmal können Sie Releases mit Fehlern veröffentlichen, aber die Risiken verstehen und dementsprechend berücksichtigen.
Zweitens gibt es einen anderen Fall - ein
Unternehmen ohne Qualität . Ein IT-Unternehmen verfügt möglicherweise sogar über eine Testabteilung. Wenn jedoch die Qualitätssicherung gering ist oder in Form von Affentests vorliegt, die die Regression einfach aufheben und dort aufhören, wird sich dies nicht wesentlich verbessern.
NB: Die Qualitätssicherung ist kein wirklicher Test, sondern ein allgemeiner Ansatz auf Unternehmensebene, wie Sie gute Produkte herstellen.
Wie können Sie verstehen, ob Sie qualitativ hochwertige Produkte entwickeln oder nicht?
Eine objektive Beurteilung erfordert Metriken, die Folgendes zeigen:
- Die Tatsache der Probleme. Dass Sie grundsätzlich Probleme haben und wenn es keine Probleme gibt, müssen Sie diese genauer suchen. Höchstwahrscheinlich sind sie irgendwo, nur sehen Sie sie immer noch nicht.
- Die Tatsache der Ergebnisse. Projekte werden erstellt, um Geld zu verdienen, in den Markt einzutreten und den Umsatz zu steigern. Diese Ergebnisse müssen nachverfolgt werden.
- Aktueller Zustand. Wo bist du auf dem Weg zu deinen Zielen, wie viele Bugs hast du gerade, schaffst du es zu sprinten, wie schnell bewegst du dich?
So wählen Sie Metriken aus
Sie können Metriken nach drei Prinzipien auswählen.
Wo es weh tut. Wenn ein Vorfall eintritt, muss er zerlegt, mit Kennzahlen gewichtet und auf den Schmerz untersucht werden: Wie läuft die Behandlung, welche Dynamik, ob Fehler behoben wurden.
Mit einem
gezielten Ansatz konzentrieren wir uns offensichtlich auf Ziele wie Beschleunigung und Automatisierung. Zuvor dauerte unser automatisiertes Testen zwei Stunden. Wir haben uns in 10 Minuten ein Ziel gesetzt und uns die Metriken angesehen, um festzustellen, ob wir uns diesem Wert nähern.
Es ist jedoch unmöglich, ein funktionsfähiges Projekt zu erhalten, wenn die Messdaten keinen Zusammenhang mit dem Unternehmen haben, nur technischer Natur sind und das Unternehmen keine Ergebnisse erzielt. Umgekehrt passiert etwas Seltsames, wenn es keine Bugs gibt und das Geschäft Geld verliert.
Es ist wichtig, sich daran zu erinnern, dass es verschiedene Unternehmen und verschiedene Phasen eines Projekts gibt. Ein Startup, ein wachsendes Unternehmen oder ein Expansionsprojekt benötigt andere Messgrößen. Es ist wie bei einer Krankheit - wenn Sie nur husten, können Sie die Temperatur messen, Ascorbinsäure trinken und alles wird vergehen. Wenn Sie den Verdacht auf eine Lungenentzündung haben, müssen Sie Fotos machen, sich untersuchen lassen und anders behandelt werden.
Metriken in verschiedenen Phasen des Projekts
Ich sage Ihnen, welche Metriken wir als Startup gemessen haben und dann angefangen haben, zu wachsen und zu expandieren.
Startup
Zu diesem Zeitpunkt steckt das Produkt erst in den Kinderschuhen. Sie testen eine Hypothese und untersuchen, ob Menschen sie benötigen.
In der Startphase eines Unternehmens ist es wichtig, dass die Ideen so schnell wie möglich an den Benutzer geliefert werden und dass sie überprüft werden können. Das heißt, Sie müssen die
Time-to-Market messen - die Geschwindigkeit, mit der die Ideen an die Benutzer geliefert werden (dh an die Produktion und nicht nur an die Veröffentlichung) und die
Anzahl der Kunden .
Im QA-Teil hatten wir nur 3-5 Metriken:
- Anzahl der Bugs aus der Schlacht;
- die Anzahl der Fehler, die die Veröffentlichung erreichen;
- Kritikalität von Fehlern.
Die Antwort auf die Frage, wie man Metriken sammelt, ist einfach: Es gibt Hände und es gibt Excel. Etwa einmal im Monat legen Sie Ihre Hände in die Datentabelle, das sollte reichen.
Wachsen
In der nächsten Phase haben wir bereits gelernt, auf den Beinen zu stehen, wir laufen ein wenig.
Die Geschäftsbedürfnisse entwickeln sich, es wird wichtig zu messen:
- Verkehr Als klar wurde, dass Benutzer das Produkt benötigen, wird so viel Verkehr wie möglich erzeugt, zum Beispiel erscheinen Partnerprogramme.
- Skalieren - so viel wie möglich, um sowohl von der Seite des Produkts als auch von der Seite der Entwicklung zu wachsen.
Die Qualitätssicherung wird bereits größer: 10-15 Metriken. Wenn wir zum Beispiel in einem Startup ein Produkt nach unseren Gefühlen kreiert haben, sagte der Gründer: „Ich möchte einen blauen Knopf“, und jeder hat es getan, jetzt gibt es die erste Statistik. Sie können Funktionen durch
A / B-Tests überspringen und die Ergebnisse nicht vergessen.
Automatisierung erscheint. Affentests reichen nicht mehr aus und es ist sinnvoll, in eine Erweiterung zu investieren. Zu diesem Zeitpunkt wird ein automatischer Test angezeigt, mit dem Regressionstests schneller durchgeführt werden können. Dementsprechend wird die
Geschwindigkeit der Freigabeprüfung gemessen
: Wie viel Automatisierung ist gerechtfertigt? Es ist traurig, dass die Automatisierung sechs Monate gedauert hat und sich die Releases aus irgendeinem Grund nicht beschleunigt haben.
Das
Release-Volumen wird auch gemessen, um festzustellen, ob beispielsweise anstelle von 5 Entwicklern das Release-Volumen auf 15 gestiegen ist, aber aus irgendeinem Grund ist das Release-Volumen nicht gewachsen.
Zur Erfassung von Metriken in der Wachstumsphase werden neben Händen und Excel auch spezialisierte Systeme angezeigt. Systeme sind alle Tools, die zur Erstellung eines Produkts beitragen. Wenn zuvor dieselben Testfälle in Google Text & Tabellen geschrieben wurden, werden sie hier angezeigt:
- Systemmanager, zum Beispiel TestRail;
- Google Analytics zum Sammeln von Benutzerdaten;
- Berichtsportal, Allure for automation.
Das System erstellt in sich zusätzliche Metriken und Berichte.
Fett
Wir wachsen weiter, "überwachsen mit Fett" - wir kommen nicht in die Büros, in denen wir saßen, und wir beginnen uns periodisch zu bewegen.
Was ist für das Geschäft wichtig?- LTV. Müssen Kunden halten. Wenn der Kunde früher einmal aufgenommen hat und gegangen ist, ist es jetzt offensichtlich notwendig, ihn zu behalten, um einen Benutzerdienst aufzubauen.
- Marke / Ruf. Wenn frühere Personen, die sich an DocDoc wenden, glauben, dass dies eine Klinik ist, wissen sie jetzt, dass sie in dem Dienst sind, der ihnen hilft.
- SLA Da die Mitarbeiter den Dienst ständig nutzen, wird die Verfügbarkeit des Dienstes kritisch, da sich Ausfallzeiten direkt auf das Geld auswirken.
- Daten. Es erscheinen die ersten Daten, sowohl Produkt- als auch Technik- und Benutzerdaten, die verarbeitet und gespeichert werden müssen. Es gibt eine Sicherheitsfrage.
- Umwandlung Auf der Stufe der Skalierung wird kein grundlegend neues Produkt erstellt, sondern das erstellte verbessert.
Die Qualitätssicherung umfasst bereits ca. 30-50 Messdaten. Wir messen:
- Laden: Backend, Server und Front und in verschiedenen Slices.
- Sicherheit
- Freigaberate.
- Automatisierungsgeschwindigkeit.
- Automatisierungsstabilität: Die Geschwindigkeit und Stabilität der Automatisierung wirken sich direkt auf die Geschwindigkeit der Releases aus, da die manuelle Regression zu diesem Zeitpunkt in der Entwicklung des Projekts noch nicht der Ort ist.
- Automatisierungsabdeckung.
Wir sammeln Daten wie zuvor, aber es werden mehr Systeme verwendet.
Schwierigkeiten
Es läuft nicht alles reibungslos und wir sind keine Ausnahme. Ich sage Ihnen, auf welche Schwierigkeiten wir gestoßen sind, als das Projekt ausreichend gewachsen ist.
Es gibt viele Systeme , sie müssen irgendwie verwaltet werden. Das Anschauen eines jeden Systems kostet mindestens viel Zeit.
Die Anzahl der Richtungen , sowohl Lebensmittelgeschäft als auch technische,
hat zugenommen . Darüber hinaus entwickelt sich jede Richtung anders, einige von ihnen werden als Startup gestartet, und es ist falsch, Metriken und Qualitätssicherung für alle zu verwenden.
Die Prozesse wurden komplizierter : Wenn früher 5 Personen an dem Projekt arbeiteten, war es einfach zu vereinbaren und entsprechend zu handeln, jetzt müssen wir die Prozesse überwachen. Zum Beispiel müssen neue Leute nach und nach eingeführt werden, sonst wird es für sie schwierig sein, die akkumulierte Anzahl von Systemen zu verstehen.
Daten und Berichte sind innerhalb des Dienstes
eindeutig . Dies ergibt sich aus der Tatsache, dass es viele Systeme gibt, und Sie müssen sie alle beobachten. Jeder Dienst generiert seine eigenen Berichte, und Sie müssen ihnen alle folgen. Darüber hinaus wird es schwieriger, sie selbst zu konfigurieren: Sie müssen sich entweder an den technischen Support wenden, um einen neuen Bericht zu erhalten, oder versuchen, ihn selbst mithilfe von Skripten zu konfigurieren.
Und wenn es viele Daten gibt,
hilft Excel nicht weiter . Vor allem, wenn Dutzende von Menschen anfangen, an einer Datei zu arbeiten, in der alles auf Formeln basiert - jemand hat etwas geändert, alles ist kaputt gegangen -, haben sie es in einer Woche gesehen.
Vielleicht sehen Analysten in Unternehmen so aus - besondere Personen, die Statistiken und Daten sammeln und pflegen, weil das Zusammenführen zu lange dauert.
Und natürlich wird es viel
schwieriger, Informationen zu analysieren , da es wieder viele Systeme gibt, verschiedene Daten, die Sie miteinander in Beziehung setzen möchten.
Behandle Traurigkeit
Sie können an das Meer gehen, sich entspannen, zurückkehren und die Erfahrungen anderer Unternehmen ansehen.
Die logische Lösung besteht darin, alles in Bezug auf Daten zusammenzustellen und in Metriken umzuwandeln.
Wir haben folgende Kriterien formuliert:
- Sammeln Sie automatisch, damit niemand irgendwo etwas in die Hand nimmt.
- Implementieren Sie verschiedene Darstellungen von Daten.
- Es sollte eine Reihe von Systemen geben: Wenn die Hälfte der Daten von Jira stammt, die andere Hälfte von TestRail, müssen sie in ein Sparschwein fallen, von dem dann ein eindeutiger Bericht erstellt wird.
- Alles sollte handlich und pflegeleicht sein. Dies bedeutet, dass die Mitarbeiter selbst die erforderlichen Berichte auf der Grundlage des Systems erstellen und selbst unterstützen können.
Dashboards
Wir haben viele Dashboards, nur aktive Techniker sind jetzt ungefähr 30 und insgesamt ungefähr 100.
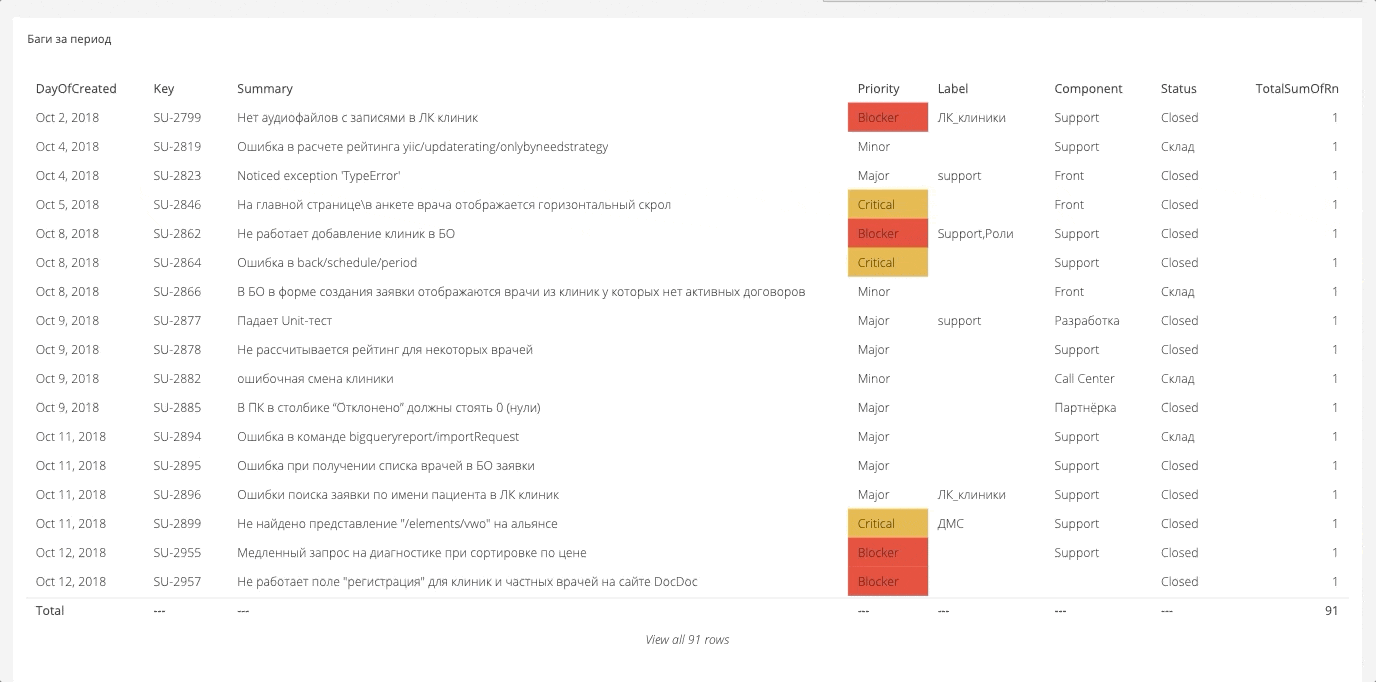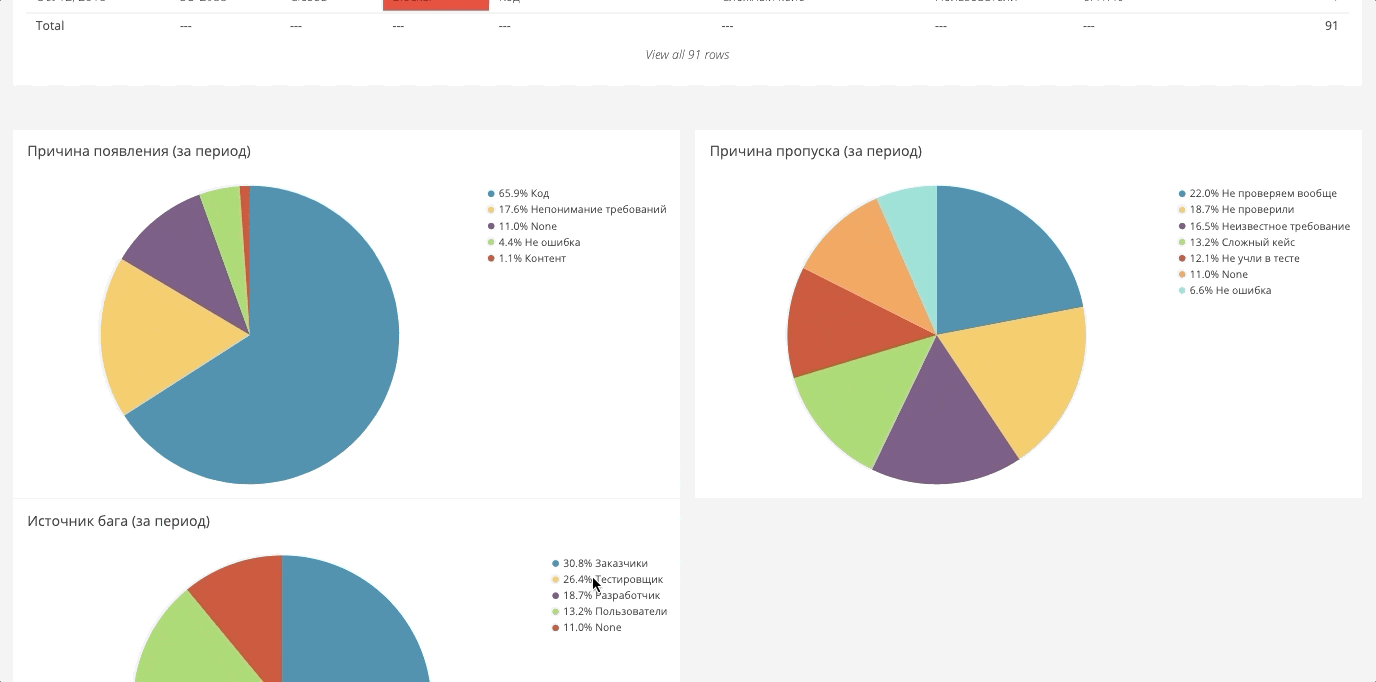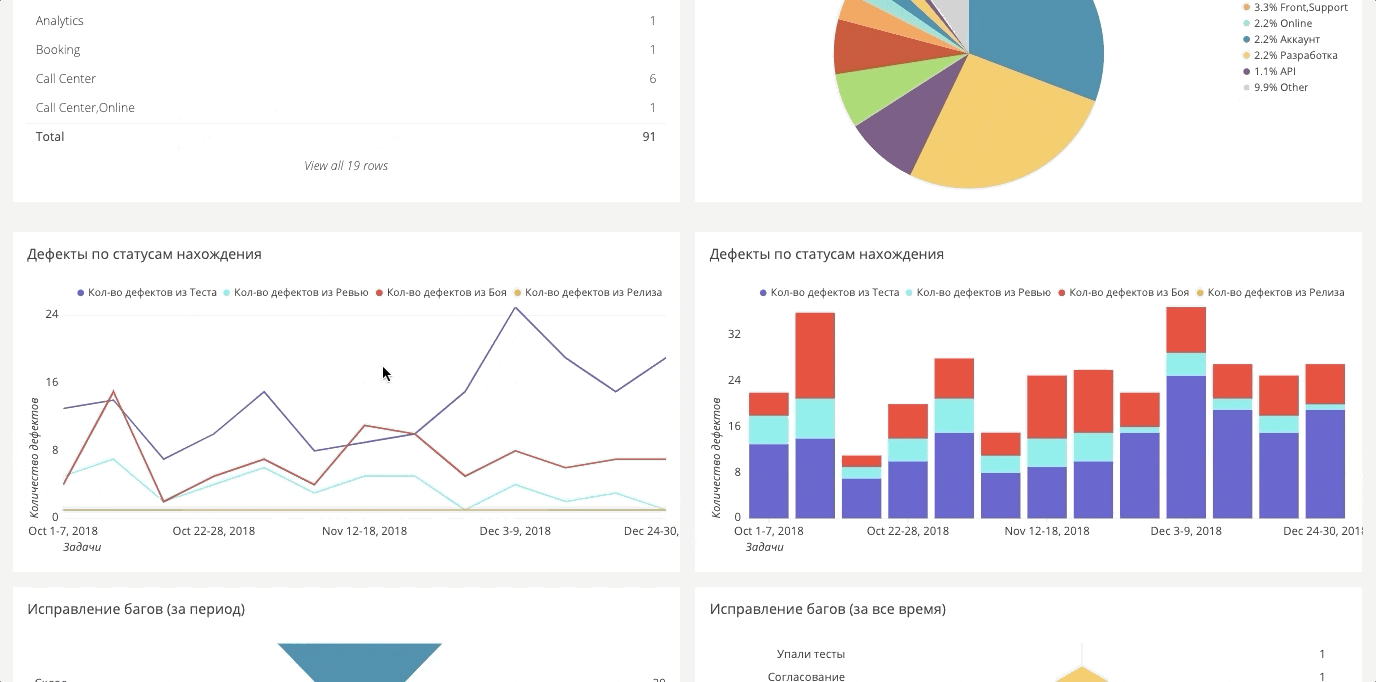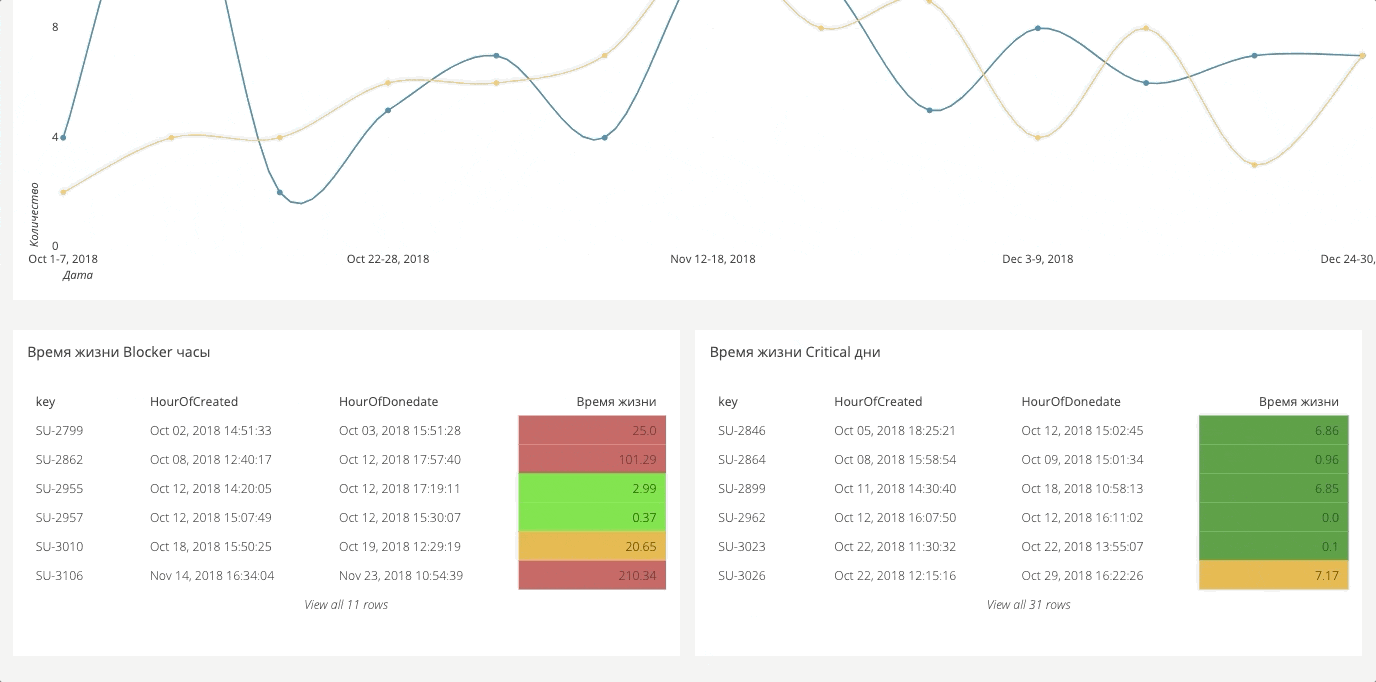
Daten für das Dashboard werden in der Regel von überall gesammelt. Es wird eine große Zeichenfläche angezeigt, aus der Sie die erforderlichen Berichte erstellen können. Nachfolgend einige Beispiele.
Aufschlüsselung der Kritikalitätsfehler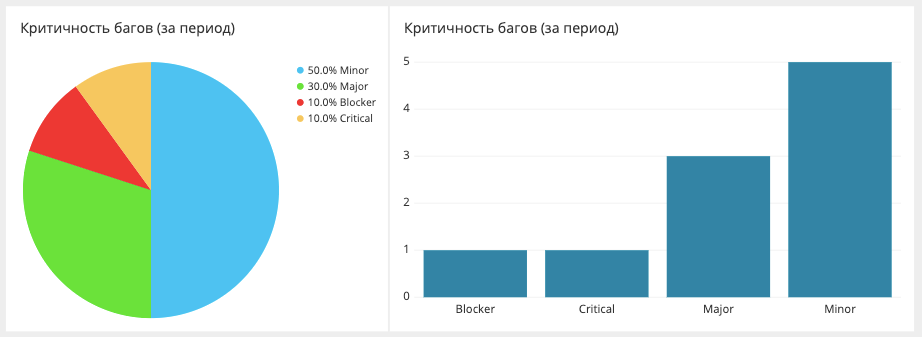
Hier messen wir die Anzahl der Fehler für einen bestimmten Zeitraum und zeigen an, wie kritisch sie waren. Daten werden aus Jira gezogen. Jira selbst kann wahrscheinlich einen solchen Bericht erstellen, aber nicht in einer sehr praktischen Form.
Aufschlüsselung der Fehler nach eigenen FeldernIn Jira können Sie beliebige benutzerdefinierte Felder packen. Diese Felder können Analysefelder sein, die auch in das allgemeine System geladen werden. Im Folgenden sind beispielsweise die Komponentenfehler aufgeführt.
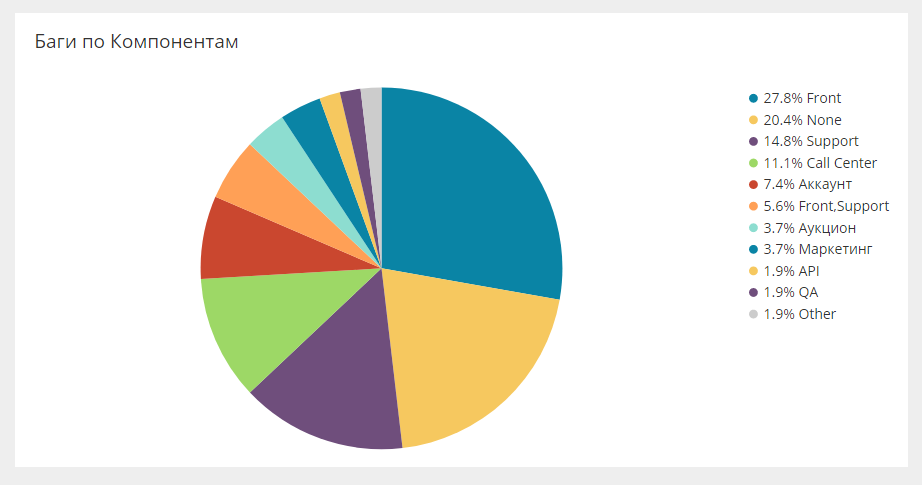
Es gibt den gleichen Schnitt für Teams, Leute und Richtungen. Auf diese Weise können Sie eine Vielzahl von Schnitten betrachten.
Das Verhältnis von neuen und geschlossenen FehlernWenn wir 20 Bugs erstellen und nur 5 schließen, werden wir uns irgendwann darin suhlen. Daher müssen Sie den Zahlen folgen und ein Verhältnis von 1 anstreben.
 Fehlertrend für den Zeitraum
Fehlertrend für den ZeitraumDas bequeme System, das wir eingeführt haben, ist, dass wir alle historischen Daten hochgeladen haben und die Dynamik sehen können.

In Jira ist das etwas kompliziert. Bei uns funktioniert alles automatisch. Sie können einen beliebigen Zeitraum auswählen und prüfen, ob Sie etwas verbessert haben und ob die eingeführten Prozesse und Ideen funktioniert haben.
Etappen des Findens von FehlernWenn wir früher nur Bugs im Kampf gemessen haben, bemühen wir uns jetzt sicherzustellen, dass es überhaupt keine Bugs im Kampf gibt, und wir bauen Slices in verschiedenen Phasen: Kampf, Release, Testen, Automatisierung, Überprüfung, Anforderungen.
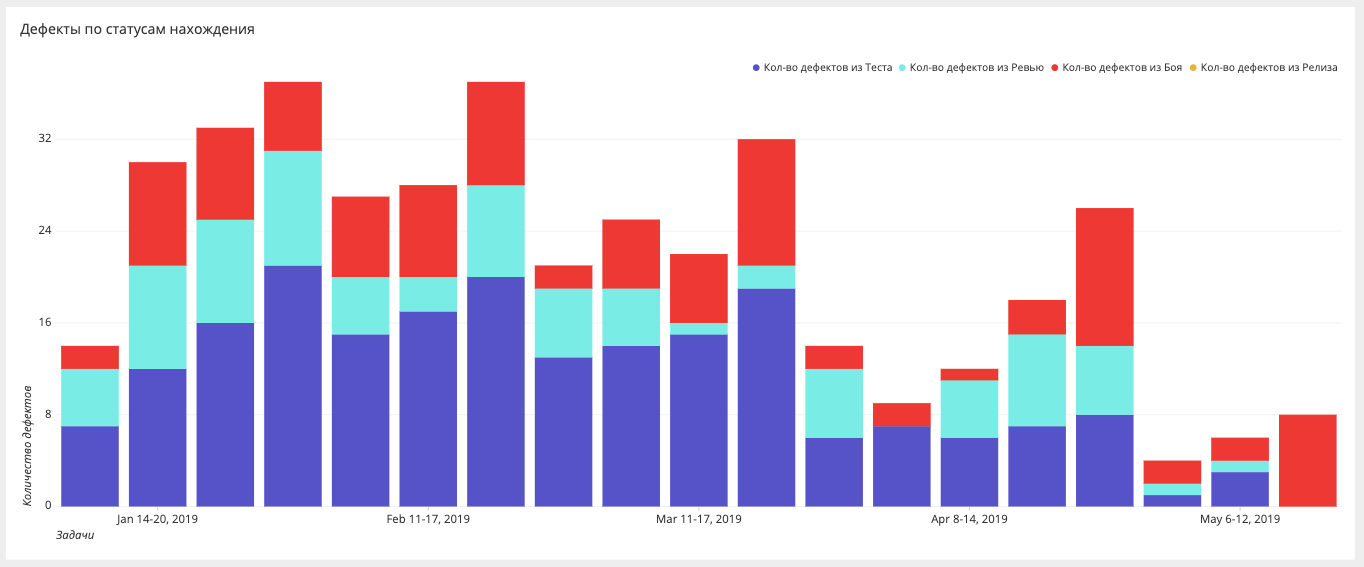 Automatisierungs-Dashboard
Automatisierungs-DashboardFür automatische Tests gibt es auch ein Dashboard. Es ist sehr groß, so dass sich unten zwei separate Fragmente befinden.

Es zeigt die Anzahl der verpassten Bugs an. Wenn Sie eine Abdeckung von 90% haben, aber tatsächlich die Hälfte der Fehler einfach auskommentiert oder übersprungen wird, ist dies sehr kritisch, da in Wirklichkeit nur 50% der Funktionen korrekt funktionieren.
Gleiches gilt für die Fehler: Wie viele Tests stürzen ab? In der Regel werden verschiedene Absturzursachen herausgegriffen: Systemabsturz, Fehlerabsturz, geänderte Funktionalität. Separat teilen wir Abstürze, die vom System und von der Umgebung abhingen und die nur auf Tests basierten. Das erste ist die Arbeit des Operationsteams, das zweite ist die Automatisierung.
Wir beschäftigen uns auch mit der Automatisierungsabdeckung. Wir nehmen alle Suiten von TestRial und können auch in die Funktionsblöcke eintauchen und beispielsweise feststellen, dass die Suche zu 30% abgedeckt ist.

Außerdem werden hier Daten zum Statusabbau wiedergegeben:
- Neu - neue Funktionalität.
- Korrektur erforderlich - Sie müssen den Fall aktualisieren.
- Nicht nötig - ich möchte mich nicht mit Automatisierung befassen.
- Fertig - Abgedeckt.
Kritikalität hat auch einen eigenen Schnitt.
Dashboard-LeistungWir erstellen dieses Dashboard in Grafana und laden die Metriken getrennt nach API, Frontend, Backend und Serverseite. Es gibt einen Block, der den aktuellen Ausschnitt der neuesten Version anzeigt. Dementsprechend können Sie in jede der Metriken fallen und die Dynamik sehen.

Es überlappt sich alles mit verschiedenen Funktionen, verschiedenen Seiten der Site.
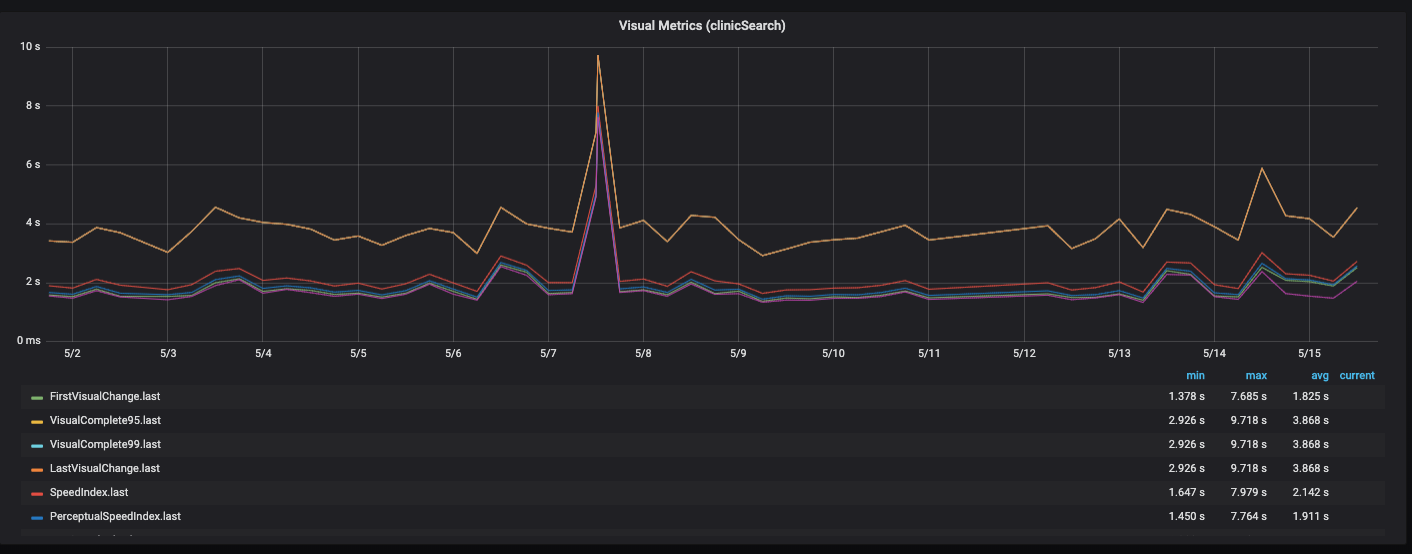
Flieg weiter
Es scheint, dass jetzt alles in Ordnung ist: Es sammelt sich und an einem Ort eine Reihe von Metriken. Sie können sicher weitermachen.
Aber es gibt neue Probleme auf dem Weg. Es gibt zu viele Graphen und daher werden sie seltener gesehen. Wenn es 5 Zeitpläne gibt, können diese jeden Tag leicht überprüft werden. Mit einer Zunahme ihrer Anzahl wird ein Regime von einmal pro Woche erhalten - auch gut. Und dann gab es plötzlich vor 3 Tagen ein Fakap, das niemand bemerkte. Daher wird die Reaktion lang und die Metriken und Dashboards können veraltet sein. Dafür gibt es verschiedene Gründe, die auch kämpfen müssen.
Wir müssen
aggregierte Diagramme erstellen : Von 10 erstellen wir ein
Diagramm , das den Zustand dieser 10 anzeigt. Außerdem ziehen wir die Hauptindikatoren nach oben. Sie öffnen das Dashboard und sehen sofort die gewünschten Werte und dann alles andere, was die Metriken detaillierter anzeigt.
Wir teilen: Geschäftsmetriken, Prozessmetriken, QS-Metriken (Web / Mobile, Manual / Automation, Performance).
So sieht das aggregierte Diagramm (NPS, CSAT) aus.
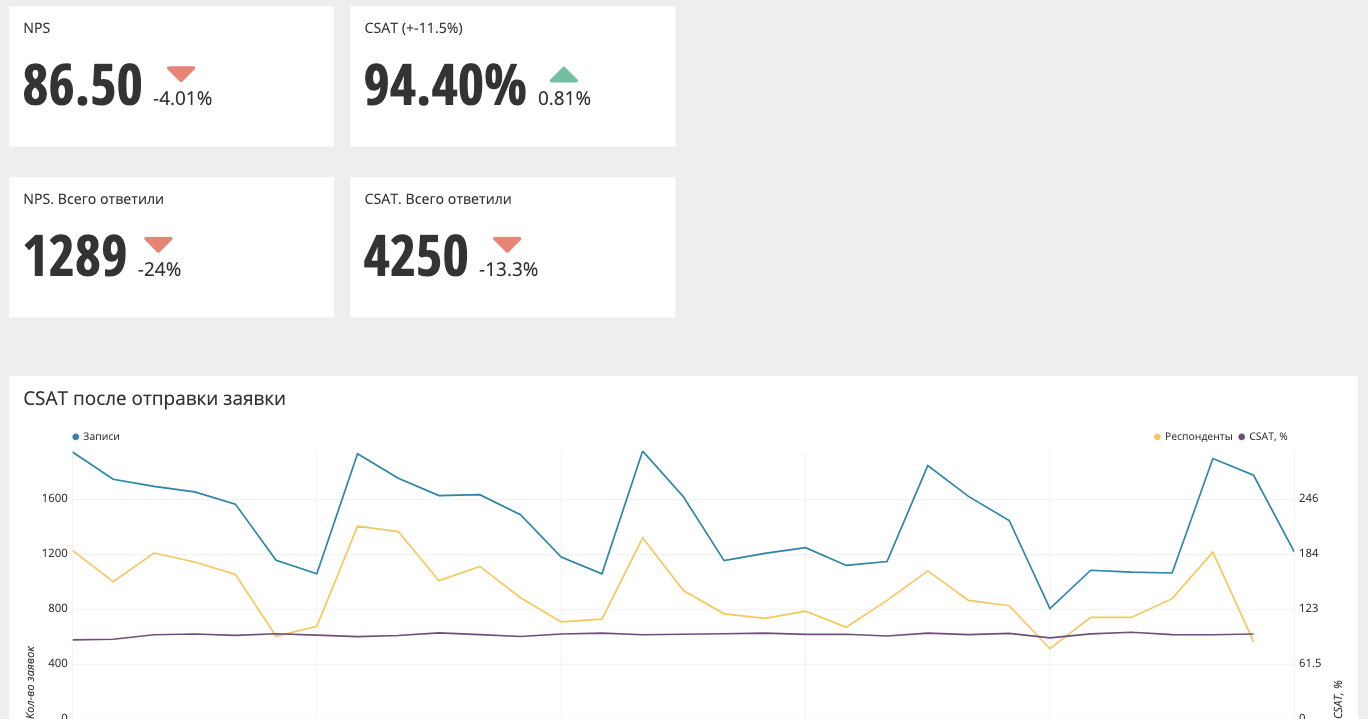
Oben stehen die Werte und das Delta im Vergleich zur Vorperiode. In diesem Fall müssen Sie, wenn der Pfeil rot ist, etwas tun, zumindest die Grafiken genauer betrachten. Wenn der Pfeil grün ist, ist alles in Ordnung und Sie können nicht reagieren.
Außerdem können die Grafiken
auf ein niedrigeres Niveau abgesenkt werden , ohne irgendwohin zu gelangen.

Bugs beziehen sich auf die Personen, die sie zugelassen haben (Tester oder Entwickler). Wenn Sie auf einen Tester separat klicken, wird eine separate Tabelle geöffnet - ein Bereich für Aufgaben.
Der nächste Schritt besteht darin, das Problem zu lösen, dass Graphen selten gesteuert werden. Wir werden das Schema der Arbeit mit Daten und Metriken erweitern: Fügen Sie den erforderlichen Metriken Benachrichtigungen hinzu.
Warnungen
Wir verwenden viele Warnungen. Ich werde Beispiele für Kategorien und spezifische Situationen geben:
- Leistung
- Autotests. Zum Beispiel, wenn der Prozentsatz verpasster Bugs zu hoch ist oder wenn zu viele neue Funktionen nicht durch Tests abgedeckt werden.
- Eingehende Fehler. In unserer Firma kann jeder einen Fehler im Ticketsystem bekommen. Zuvor wurde dies von einer Nachricht in PM begleitet, und jetzt gibt es einen Kanal für Benachrichtigungen über neue Bugs. Außerdem werden Bugs automatisch dem Executor zugewiesen. Die angegebene Person muss den Bug analysieren, sonst erinnert ihn der Bot alle 15 Minuten daran.
- Testgeschwindigkeit / Test anstehend. Wenn klar ist, dass sich eine Person in einer Aufgabe vergraben hat - es spielt keine Rolle, er hat sie codiert, eine Überprüfung durchgeführt und getestet -, sollte eine Warnung eingehen: "Sie erledigen bereits drei Aufgaben, vielleicht haben Sie sich vergraben, bitten Sie um Hilfe."
- Mängel an der Aufgabe / am Team.
- Überprüfung von Testfällen. Dies ist nur eine Automatisierung des Prozesses, um dies nicht von Hand zu tun.
Beispiele für Warnungen
Bei brennenden Aufgaben schreibt der Bot die Aufgabennummer, den Status, die Priorität, wie lange die Aufgabe bereits getestet wird und wer sie testet.

Eine Benachrichtigung in Form einer Zusammenfassung geht an eine Person, die prüft, welche Probleme sie hat. Hier ist ein Beispiel für Warnungen für den Testfall, den TestRial sendet.

Es zeigt an, welche Fälle wem mit welchem Status zugewiesen sind und wer überwacht werden muss.
Ein weiteres Beispiel ist der Yabeda-Bot, der Prozesse überwacht.

Dies war erforderlich, um den Prozess zum Verknüpfen des Fehlers und der Aufgabe zu konfigurieren. Der Entwickler, der den Fehler analysiert, muss die Aufgabe finden, bei der wir diesen Fehler verpasst haben, um weitere Analysen zu erhalten und zu erfahren, warum wir den Fehler verpasst haben. Dies ist eine Art Analyse des Vorfalls, jedoch mit Verzögerung.
Wie viele Benachrichtigungen benötigen Sie und wie oft?
Wenn es viele Warnungen geben wird, wird es viel Stress von ihnen geben. Aus diesem Grund haben wir für uns selbst Regeln für das Alert-Management festgelegt.
Zu viele Warnungen - reagieren nicht mehr. Bei 500 Benachrichtigungen pro Tag haben Sie definitiv keine Zeit mehr zum Durchsuchen, was bedeutet, dass Sie das Wichtige überspringen können.
Zu wenig - keine Probleme. Wenn zum Beispiel zu wenige Nachrichten vorhanden sind, werfen Sie die Hälfte weg. Möglicherweise sehen Sie keine Probleme.
Kein Problem - eine Zusammenfassung der Fakten. In Abwesenheit von Problemen sollten auch Warnmeldungen gesendet werden, jedoch in Form einer Zusammenfassung: Was ist während des Tages passiert, was hat funktioniert, welche Aufgaben waren, was ist passiert. Wenn Sie keine Zusammenfassung erstellen, denken Sie möglicherweise, dass alles kaputt gegangen ist, und Sie müssen herausfinden, welche Warnungen abgefallen sind.
Normalerweise wird die Warnung auf den Schwellenwert der Metrik festgelegt: Wenn die Metrik den Schwellenwert überschritten hat, wird eine Warnung ausgegeben. , , - , . ,
:
- — , .
- — , , . , , . .
- — , , , , .
,
:- — , , .
- / . , , .
- . , .
- . , . , . , , .
. , . . , , , , . , , : , .
, :
, , . . -, , , , , 15 , . -, , . . -, . , , , , , .
Online
. , . , . , .

QA
, QA .
: , , .
: , , .
:

— , X ( ), () (). , - , ( ) : , . , . , , . , , .
: — , , ( , , ).
: « ». , , , , . - . .
, , . , , . .
-
: , , . , .
: , , , .
, 10 , 500, . , .
. , , .

,
, , . , , . «5 », .
, , , .
Zusammenfassung
— , . , . , . , , , — , .
:. , , , . .
— . , . , , - .
. , .
:- ~ 50 QA 100 .
- ~ 30 .
- — , .
- .
- .
- QA must have.
, , , - ++ TechLead Conf. telegram- , , – , , , .