
Vor Ihnen liegt wieder die Aufgabe, Objekte zu erkennen. Priorität - Geschwindigkeit mit akzeptabler Genauigkeit. Sie nehmen die Architektur von YOLOv3 und trainieren sie. Die Genauigkeit (mAp75) ist größer als 0,95. Aber die Laufgeschwindigkeit ist immer noch niedrig. Hölle
Heute werden wir die Quantisierung umgehen. Betrachten Sie unter dem Schnitt Model Pruning - Schneiden Sie redundante Netzwerkteile, um die Inferenz zu beschleunigen, ohne an Genauigkeit zu verlieren. Optisch - wo, wie viel und wie schneiden. Lassen Sie uns herausfinden, wie dies manuell erfolgt und wo Sie automatisieren können. Am Ende befindet sich ein Repository für Keras.
Einleitung
Am letzten Arbeitsplatz, Perm Macroscop, hatte ich die Angewohnheit, immer die Ausführungszeit der Algorithmen zu überwachen. Die Netzwerklaufzeit sollte immer über den Angemessenheitsfilter überprüft werden. Normalerweise besteht der Stand der Technik in der Produktion diesen Filter nicht, was mich zu Pruning führte.
Beschneiden ist ein altes Thema, über das in den Stanford-Vorlesungen 2017 gesprochen wurde. Die Hauptidee besteht darin, die Größe des trainierten Netzwerks zu reduzieren, ohne an Genauigkeit zu verlieren, indem verschiedene Knoten entfernt werden. Klingt cool, aber ich höre selten von seiner Verwendung. Wahrscheinlich gibt es nicht genug Implementierungen, es gibt keine russischsprachigen Artikel oder einfach jeder denkt darüber nach, das Know-how zu beschneiden und zu schweigen.
Aber geh auseinander nehmen
Ein Blick in die Biologie
Ich liebe es, wenn in Deep Learning Ideen aus der Biologie kommen. Man kann ihnen wie der Evolution vertrauen (wussten Sie, dass ReLU der Funktion der Aktivierung von Neuronen im Gehirn sehr ähnlich ist?)
Der Model-Pruning-Prozess ist auch der Biologie nahe. Die Netzwerkantwort kann hier mit der Plastizität des Gehirns verglichen werden. Ein paar interessante Beispiele sind in Norman Dodges Buch:
- Das Gehirn einer Frau, die von Geburt an nur eine Hälfte hatte, programmierte sich neu, um die Funktionen der fehlenden Hälfte zu erfüllen
- Der Typ hat sich den Teil des Gehirns erschossen, der für das Sehen verantwortlich ist. Im Laufe der Zeit übernahmen andere Teile des Gehirns diese Funktionen. (nicht noch einmal versuchen)
So können Sie aus Ihrem Modell einige der schwachen Bündel herausschneiden. In extremen Fällen können die verbleibenden Bündel die abgeschnittenen ersetzen.
Mögen Sie Transfer Learning oder lernen Sie von Grund auf neu?
Option Nummer eins. Sie verwenden Transfer Learning für Yolov3. Netzhaut, Maske-RCNN oder U-Netz. Meistens müssen wir jedoch nicht 80 Klassen von Objekten erkennen, wie dies bei COCO der Fall ist. In meiner Praxis ist alles auf 1-2 Stunden begrenzt. Es ist davon auszugehen, dass die Architektur für 80 Klassen hier redundant ist. Es ist der Gedanke, dass die Architektur reduziert werden muss. Darüber hinaus möchte ich dies tun, ohne die vorhandenen vortrainierten Gewichte zu verlieren.
Option Nummer zwei. Möglicherweise verfügen Sie über viele Daten- und Computerressourcen, oder Sie benötigen nur eine benutzerdefinierte Architektur. Nicht wichtig. Aber Sie lernen das Netzwerk von Grund auf. Die übliche Reihenfolge besteht darin, die Datenstruktur zu untersuchen, eine leistungsreduzierte Architektur auszuwählen und die Schulungsabbrecher von der Umschulung abzuhalten. Ich habe Aussetzer 0.6 gesehen, Carl.
In beiden Fällen kann das Netzwerk reduziert werden. Gefördert. Nun wollen wir herausfinden, welche Art von Beschneidung beschneiden
Allgemeiner Algorithmus
Wir beschlossen, die Faltung zu beseitigen. Es sieht sehr einfach aus:
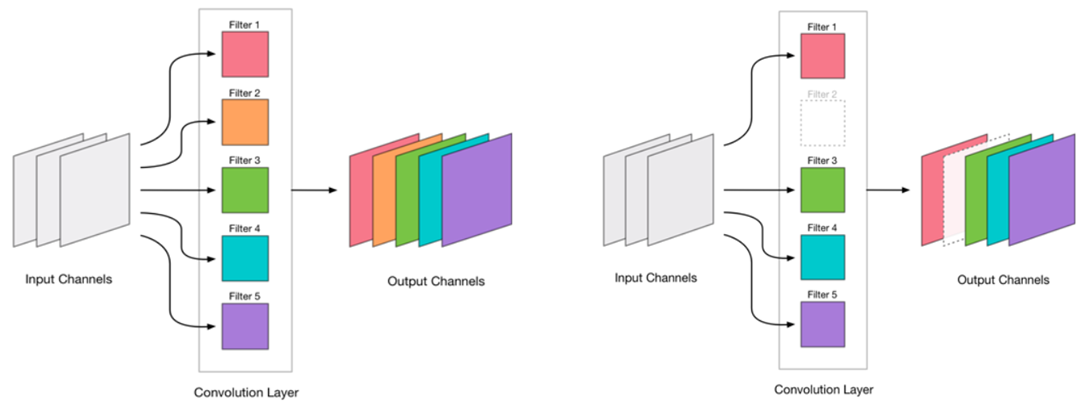
Das Entfernen von Faltungen ist eine Belastung für das Netzwerk, die normalerweise zu einer gewissen Zunahme der Fehler führt. Einerseits ist dieses Fehlerwachstum ein Indikator dafür, wie richtig wir die Faltung entfernen (z. B. zeigt ein großes Wachstum an, dass wir etwas falsch machen). Ein geringes Wachstum ist jedoch durchaus akzeptabel und wird häufig durch anschließendes leichtes Weiterbilden mit einem kleinen LR eliminiert. Wir fügen einen Schritt der Umschulung hinzu:
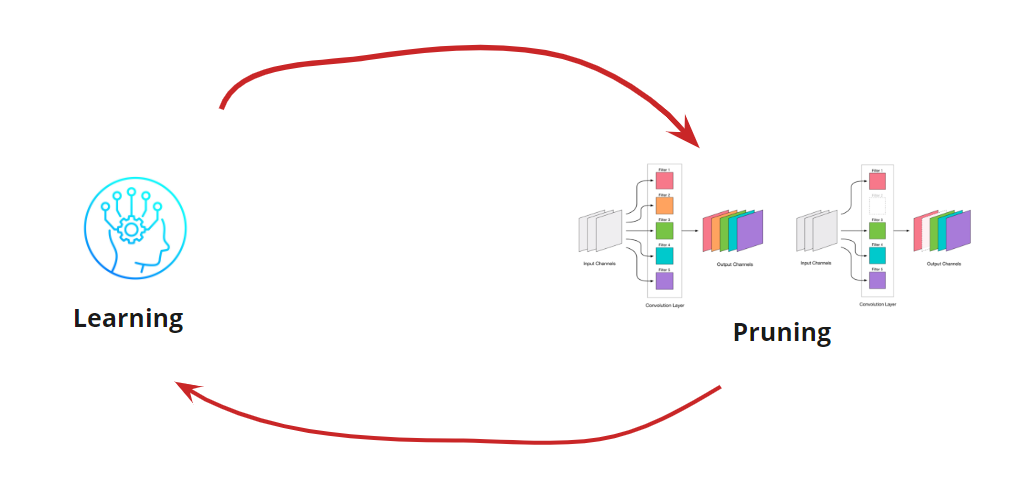
Jetzt müssen wir verstehen, wann wir unseren Lernzyklus <-> Beschneiden beenden möchten. Es kann exotische Optionen geben, wenn wir das Netzwerk auf eine bestimmte Größe und Geschwindigkeit reduzieren müssen (z. B. für mobile Geräte). Die häufigste Option ist jedoch, den Zyklus fortzusetzen, bis der Fehler höher als der zulässige ist. Bedingung hinzufügen:
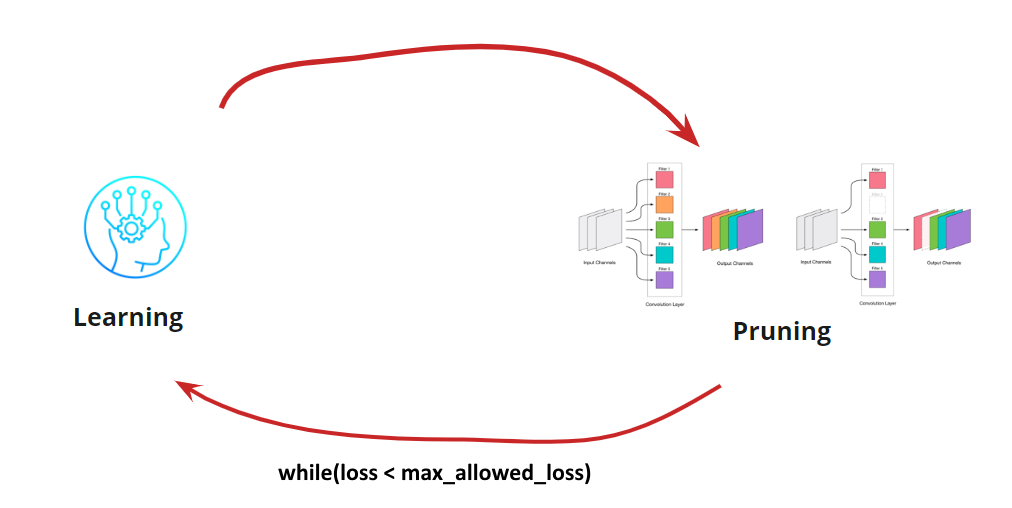
So wird der Algorithmus klar. Es bleibt zu zerlegen, wie die gelöschten Windungen zu bestimmen sind.
Suche nach Faltung, die gelöscht werden soll
Wir müssen einige Windungen entfernen. Es ist eine schlechte Idee, vorauszurennen und irgendetwas abzuschießen, obwohl es funktionieren wird. Aber wenn Sie einen Kopf haben, können Sie denken und versuchen, "schwache" Windungen zum Entfernen auszuwählen. Es gibt verschiedene Möglichkeiten:
- Das kleinste L1-Maß oder Low_magnitude_pruning . Die Idee, dass Windungen mit kleinen Gewichten einen kleinen Beitrag zur endgültigen Entscheidung leisten
- Das kleinste L1-Maß unter Berücksichtigung von Mittelwert und Standardabweichung. Wir ergänzen die Bewertung der Art der Verteilung.
- Maskieren von Windungen und Eliminieren der geringsten Beeinträchtigung der resultierenden Genauigkeit . Eine genauere Definition von unbedeutenden Windungen, aber sehr zeitaufwendig und ressourcenintensiv.
- Andere
Jede der Optionen hat das Recht auf Leben und ihre eigenen Implementierungsmerkmale. Hier betrachten wir die Variante mit dem kleinsten L1-Maß
Manueller Prozess für YOLOv3
Die ursprüngliche Architektur enthält Restblöcke. Aber egal wie cool sie für tiefe Netzwerke sind, sie werden uns etwas behindern. Die Schwierigkeit besteht darin, dass Sie in diesen Layern keine Abstimmungen mit verschiedenen Indizes löschen können:

Daher wählen wir die Ebenen aus, aus denen wir Abstimmungen frei entfernen können:
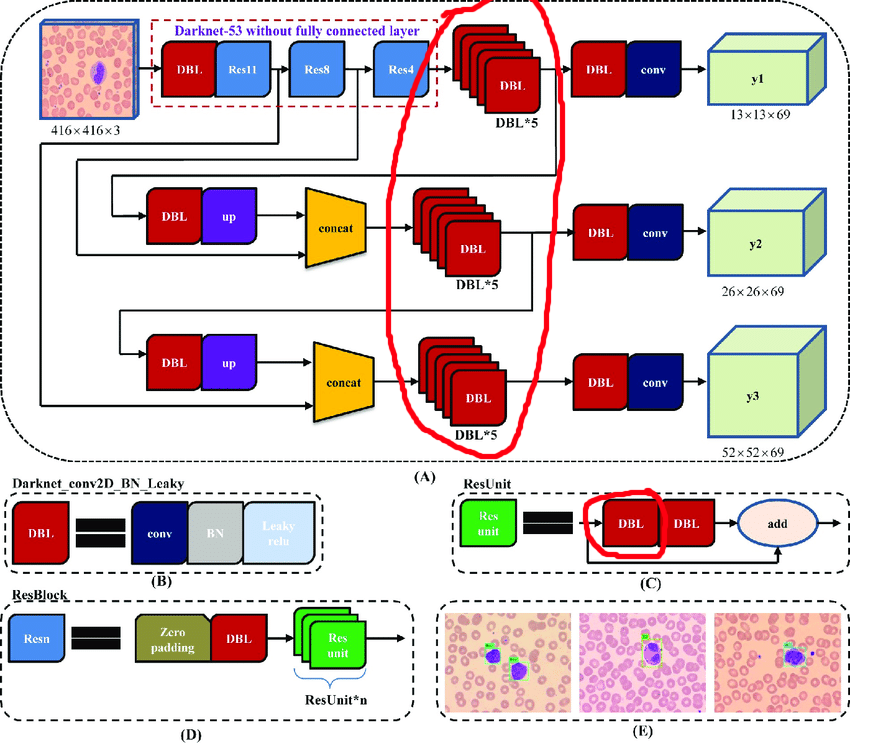
Bauen wir nun einen Arbeitszyklus auf:
- Aktivierung entladen
- Wir fragen uns, wie viel zu schneiden ist
- Ausschneiden
- Lernen Sie 10 Epochen mit LR = 1e-4
- Testen
Das Entladen von Windungen ist nützlich, um zu bewerten, welchen Teil wir in einem bestimmten Schritt entfernen können. Beispiele für das Entladen:

Wir sehen, dass fast überall 5% der Windungen eine sehr niedrige L1-Norm haben und wir sie entfernen können. Bei jedem Schritt wurde ein solches Entladen wiederholt, und es wurde bewertet, welche Schichten und wie viel geschnitten werden konnten.
Der gesamte Vorgang wurde in 4 Schritten abgeschlossen (hier und überall die Nummern für den RTX 2060 Super):
Zu Schritt 2 wurde ein positiver Effekt hinzugefügt - die Patchgröße 4 wurde gespeichert, was den Umschulungsprozess erheblich beschleunigte.
In Schritt 4 wurde der Prozess gestoppt, weil Selbst eine längere Weiterbildung hat den mAp75 nicht auf alte Werte angehoben.
Infolgedessen ist es uns gelungen, die Inferenz um 15% zu beschleunigen, die Größe um 35% zu reduzieren und nicht an Genauigkeit zu verlieren.
Automatisierung für einfachere Architekturen
Für einfachere Netzwerkarchitekturen (ohne bedingte Additions-, Concaternate- und Restblöcke) ist es durchaus möglich, sich auf die Verarbeitung aller Faltungsschichten zu konzentrieren und den Prozess des Schneidens von Faltungen zu automatisieren.
Ich habe diese Option hier implementiert.
Es ist ganz einfach: Sie haben nur eine Verlustfunktion, einen Optimierer und Batch-Generatoren:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
Bei Bedarf können Sie die Konfigurationsparameter ändern:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
Zusätzlich ist eine Einschränkung auf Basis der Standardabweichung implementiert. Das Ziel ist es, einen Teil der gelöschten zu begrenzen, ausgenommen Windungen mit bereits "ausreichenden" L1-Maßen:
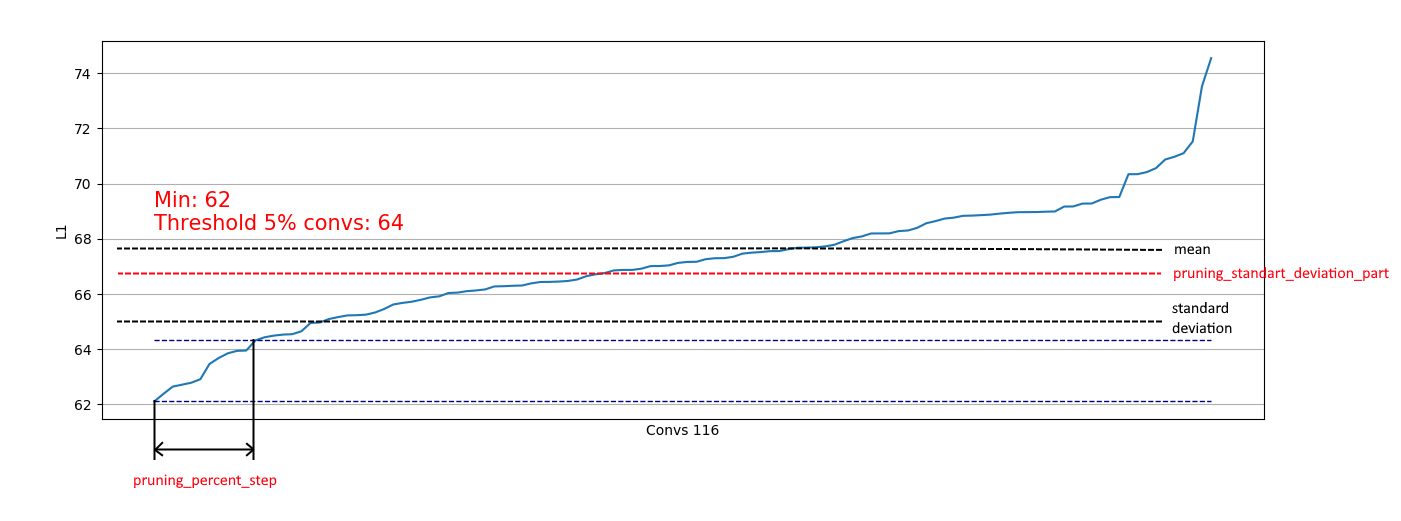
Daher können wir nur schwache Windungen aus Verteilungen entfernen, die der rechten ähnlich sind, und wir können die Entfernung aus Verteilungen wie der linken nicht beeinflussen:

Wenn sich die Verteilung normalisiert, kann der Koeffizient pruning_standart_deviation_part ausgewählt werden aus:

Ich empfehle eine 2-Sigma-Annahme. Oder Sie können sich nicht auf diese Funktion konzentrieren und den Wert <1,0 belassen.
Die Ausgabe ist ein Diagramm der Netzwerkgröße, des Netzwerkverlusts und der Netzwerklaufzeit für den gesamten Test, normalisiert auf 1,0. Zum Beispiel wurde hier die Netzwerkgröße ohne Qualitätsverlust um fast das 2-fache reduziert (ein kleines Faltungsnetzwerk für 100k-Gewichte):
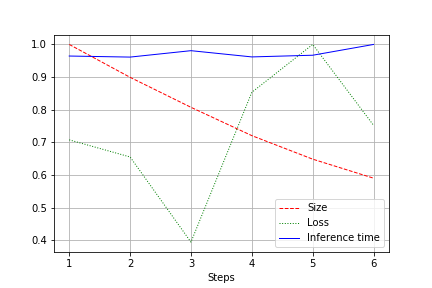
Die Laufgeschwindigkeit unterliegt normalen Schwankungen und hat sich nicht wesentlich geändert. Dafür gibt es eine Erklärung:
- Die Anzahl der Windungen ändert sich von bequem (32, 64, 128) zu nicht bequem für Grafikkarten - 27, 51 usw. Hier kann ich mich irren, aber höchstwahrscheinlich wirkt es sich aus.
- Die Architektur ist nicht breit, aber konsistent. Wenn wir die Breite reduzieren, berühren wir die Tiefe nicht. So reduzieren wir die Last, ändern aber nicht die Geschwindigkeit.
Daher äußerte sich die Verbesserung in einer Verringerung der CUDA-Belastung während des Laufs um 20 bis 30%, jedoch nicht in einer Verringerung der Laufzeit
Zusammenfassung
Nachdenken. Wir haben zwei Optionen für das Bereinigen in Betracht gezogen - für YOLOv3 (wenn Sie mit Ihren Händen arbeiten müssen) und für Netzwerke mit einfacheren Architekturen. Es ist zu erkennen, dass in beiden Fällen eine Reduzierung der Netzwerkgröße und -beschleunigung ohne Genauigkeitsverlust erreicht werden kann. Ergebnisse:
- Downsizing
- Beschleunigung ausführen
- CUDA-Lastreduzierung
- Infolgedessen Umweltfreundlichkeit (Wir optimieren den zukünftigen Einsatz von Computerressourcen. Irgendwo freut sich Greta Tunberg alleine)
Anhang
- Nach dem Bereinigungsschritt können Sie die Quantisierung auch verdrehen (z. B. mit TensorRT).
- Tensorflow bietet Funktionen für Low_Magnitude_Pruning . Es funktioniert
- Ich möchte das Repository weiterentwickeln und stehe Ihnen gerne zur Verfügung