Hallo habr
Ende des Jahres können wir Ihnen mitteilen, dass wir mit der Arbeit an der Bayesian Statistics the Fun Way von No Starch Press beginnen. Wir bieten eine Übersetzung eines ausführlichen Interviews mit dem Autor des Buches an. Der Text betrifft sowohl das Buch selbst und verwandte Themen als auch zusätzliche Lektüre.

Ich interessiere mich wie die meisten Entwickler sofort für viele Dinge: funktionale Programmierung, Betriebssysteme, Typsysteme, verteilte Systeme und Datenwissenschaft. Deshalb war ich so begeistert, dass
Will Kurt , der Autor von
Get Programming with Haskell , ein Buch über Bayes'sche Statistiken von No Starch Press schrieb. Es gibt nicht viele Leute, die Bücher zu verschiedenen Themen schreiben. Ich bin sicher, dass Will in seinem neuen Buch etwas mit den Lesern zu teilen hat - und nicht enttäuscht wurde. Das Buch ist ein ausgezeichnetes Einführungsmaterial, insbesondere für diejenigen, die nicht zu gut in der harten Mathematik sind, aber dennoch etwas auf dem Gebiet der Datenwissenschaft erreichen wollen. Ich empfehle, Kurts neues Buch nach Think Stats, aber vor Probabilistic Python Programming zu lesen: Bayesian Inference and Algorithms, Bayesian Analysis mit Python und Doing Bayesian Data Analysis.
1. Warum brauchen wir ein weiteres Statistikbuch?Fast alle der vielen derzeit existierenden Bücher zur Bayes'schen Statistik deuten darauf hin, dass der Leser entweder bereits eine allgemeine Vorstellung von Statistik und eine solide Grundlage in der Programmierung hat. Daher wird die Bayes'sche Statistik gegenwärtig häufig als eine fortgeschrittene Alternative zur klassischen Statistik (d. H. Frequenzstatistik) angesehen. Obwohl die Bayes'schen Statistiken immer beliebter werden, sind die Materialien hauptsächlich für Personen gedacht, die bereits über ein gutes quantitatives Training verfügen.
Wenn sich eine Person dazu entschließt, einfach "Statistik zu studieren", nimmt sie ein Einführungsbuch, in dem Statistiken aus Sicht der Häufigkeit vorgestellt werden, liest es vor, hat eine Reihe von Tests und Regeln zur Hälfte herausgefunden und ist der Meinung, dass dieses ganze Thema sehr verwirrend ist. Ich wollte ein solches Buch über Bayes'sche Statistik schreiben, das jeder lesen und lesen kann, um eine intuitive Vorstellung davon zu bekommen, was es heißt, statistisch zu denken und wie man mit Hilfe der Statistik echte Probleme löst. Ich sehe keinen Grund, warum die Bayes'sche Statistik für einen absoluten Anfänger nicht als erster Einführungskurs in dieses Thema dienen könnte.
Ich würde mich sehr freuen, wenn irgendwann mit dem Wort "Statistik" die Bayes'sche Statistik gemeint würde und die Frequenzstatistik nur eine der akademischen Nischen wäre. Hierfür werden mehr Bücher benötigt, in denen die Kenntnis der Statistik für einen breiten Kreis von Lesern mit Bayes'schen Methoden vorgeschlagen wird. Außerdem hat der Autor berücksichtigt, dass dies möglicherweise die erste Kenntnis der Statistik durch den Leser ist.
Ich dachte sofort daran, dieses Buch als „Statistik zum Spaß“ zu bezeichnen, aber ich dachte, ich würde wahrscheinlich ein paar verärgerte Briefe von Leuten bekommen, die ein solches Buch gekauft haben, um mich auf die Aufnahmeprüfung für die Statistik vorzubereiten - und fand dass es dort ganz anders ist! Ich hoffe, mein Buch ist ein kleiner Schritt in Richtung der Zeit, in der Bayes-Statistiken bei den Aufnahmeprüfungen abgefragt werden, und es ist ratsam, ein solches Buch auch für diejenigen zu lesen, die sich gerade auf die Prüfung vorbereiten.
2. Was ist die Zielgruppe des Buches? Kann eine Person es ohne mathematischen Hintergrund lesen?Bei der Arbeit an „Bayesian Statistics is great“ habe ich versucht, ein Buch zu erstellen, das im Prinzip für jeden verständlich ist, der Mathematik im Rahmen des Highschool-Programms gelernt hat. Auch wenn Sie sich nur vage an die Algebra erinnern, ist das Präsentationstempo in einem Buch so, dass Sie mithalten können. Die Bayes'schen Statistiken erfordern nur sehr wenige mathematische Analysen und sind mit ein wenig Software-Code-Unterstützung noch einfacher. Deshalb habe ich dem Buch zwei Anwendungen hinzugefügt, die die Grundlagen der R-Sprache erläutern so sehr, dass Sie alle Beispiele aus diesem Buch herausfinden können, wo es um Integrale geht. Ich verspreche jedoch, dass Sie keine Probleme auf dem Gebiet der mathematischen Analyse lösen müssen, um das Buch zu lesen.
Da ich hart gearbeitet habe, um die Menge an mathematischem Wissen zu minimieren, die zum Lesen eines Buches erforderlich ist, werden Sie beim Lesen allmählich anfangen, die mathematische Denkweise zu erlernen. Wenn Sie die Mathematik verstehen, mit der Sie richtig arbeiten, werden Sie sie noch besser verstehen. Deshalb habe ich nicht versucht, der echten Mathematik auszuweichen, sondern sie Schritt für Schritt zu erklären, damit Ihnen die ganze Mathematik allmählich klar wird. Wie viele glaubte ich einst, dass Mathematik eine komplizierte Wissenschaft ist und es schwierig ist, damit zu arbeiten. Mit der Zeit wurde ich überzeugt, dass Mathematik mit der richtigen Herangehensweise fast keine Schwierigkeiten verursacht. In der Mathematik kommt es in der Regel nur zu Verwirrungen, wenn versucht wird, das Material zu schnell durchzuarbeiten. Aus diesem Grund werden wichtige Schritte, die für das richtige Denken erforderlich sind, übersehen.
3. Warum sollte ein Programmierer Wahrscheinlichkeitstheorie und Statistik studieren?Ich bin der festen Überzeugung, dass sich jeder in gewissem Maße mit Wahrscheinlichkeitstheorie und Statistik befassen sollte, da dieses Wissen dazu beitragen wird, die Unsicherheit zu beurteilen, die uns überall im Leben umgibt. Was den Programmierer betrifft, wird er sich definitiv mit einigen typischen Aufgaben befassen müssen, bei denen es nützlich ist, Statistiken zu verstehen. Es ist sehr wahrscheinlich, dass Sie irgendwann in Ihrer beruflichen Laufbahn Code schreiben müssen, in dem einige Entscheidungen auf der Grundlage von a priori Fuzzy-Faktoren getroffen werden. Vielleicht ist dies ein Maß für die Konversion der Webseite, die Erzeugung von zufälligen Belohnungen im Spiel, die zufällige Verteilung von Benutzern in Gruppen oder sogar das Lesen von Informationen von einem Fuzzy-Sensor. In all diesen Fällen hilft Ihnen ein solides Verständnis der Wahrscheinlichkeitstheorie sehr. Meine eigene Praxis zeigt, dass der probabilistische Ansatz beim Debuggen vieler Fehler, die schwierig zu reproduzieren oder zu einem komplexen Problem aufzuspüren sind, sehr hilfreich ist. Wenn sich herausstellt, dass der Fehler durch unzureichenden Arbeitsspeicher verursacht wird, können Sie dann sicher sein, dass der Fehler häufiger auftritt, wenn der Arbeitsspeicher noch stärker gekürzt wird? Wenn ein komplexer Fehler auf zwei Arten erklärt werden kann, was ist dann die beste Gelegenheit, ihn zuerst zu untersuchen? In all diesen Fällen kann die Wahrscheinlichkeitstheorie helfen. Natürlich führt die Blütezeit des maschinellen Lernens und der Datenwissenschaft dazu, dass sich Ingenieure zunehmend mit Aufgaben beschäftigen müssen, bei denen die Programmierung eine direkte Arbeit mit Wahrscheinlichkeiten bietet.
4. Kann man den Unterschied zwischen dem Frequenz- und dem Bayes'schen Ansatz der Wahrscheinlichkeitstheorie kurz beschreiben?Bei der Frequenzinterpretation wird die Wahrscheinlichkeit als Aussage darüber interpretiert, wie oft ein Ereignis bei wiederholten Versuchen auftreten soll. Wenn man also eine Münze zweimal wirft, sollte man damit rechnen, dass sie einmal vom Adler fallen gelassen wird, da die Münze zwei Seiten hat und eine von ihnen einen Adler hat. In der Bayes'schen Interpretation wird Wahrscheinlichkeit als ein Merkmal unseres Wissens im Prinzip als Fortsetzung der Logik interpretiert. Die Wahrscheinlichkeit, eine Münze mit einem Adler zu werfen, beträgt 0,5, weil ich keinen Grund sehe, warum ein Adler häufiger als ein Schwanz fallen sollte. Im Falle eines Münzwurfs sind also beide Ansätze voll funktionsfähig. Wenn es jedoch um Dinge wie die Gewinnchancen Ihrer Lieblingsmannschaft bei der Weltmeisterschaft geht, wird der Vertrauensfaktor viel wichtiger. Dies bedeutet im Übrigen auch, dass die Bayes'schen Statistiken keine Aussagen über die Welt treffen, sondern über unser Verständnis der Welt. Da jeder die Welt ein wenig anders versteht, helfen uns Bayes-Statistiken, diese Unterschiede in unserer Analyse zu berücksichtigen. In vielerlei Hinsicht ist die Bayes'sche Analyse die Wissenschaft der Meinungsentwicklung.
5. Warum liegt der Schwerpunkt des Buches auf dem Bayes'schen Ansatz?Es gibt viele wirklich gute philosophische Gründe, sich auf die Bayes'sche Statistik zu konzentrieren, aber ich ließ mich von einem ganz praktischen Grund leiten: Mit dem Bayes'schen Ansatz wird alles logisch. Basierend auf einem relativ kleinen Satz intuitiver Regeln können Sie für fast jedes Problem, auf das Sie stoßen, eine Lösung entwickeln. Dies ist der Grund, warum Bayes-Statistiken so leistungsfähig und flexibel sind und warum sie so einfach zu erlernen sind. Ich denke, die bayesianische Denkweise passt genau zu Programmierern. Sie versuchen das Problem nicht mit Hilfe von spontanen Tests zu lösen, sondern überdenken es und finden nach und nach eine wirklich gerechtfertigte Lösung. Grundsätzlich Bayes'sche Statistik - das ist die Begründung. Sie stimmen der statischen Analyse nur zu, wenn sie für Sie wirklich logisch und überzeugend ist, und nicht, weil Ihr Test, der willkürlich aussieht, Ihnen einen ebenso unbegründeten Wert verleiht. Die Bayes'schen Statistiken erlauben es zudem, das Ergebnis qualitativ zu bezweifeln. In der alltäglichen Praxis kommt es häufig vor, dass zwei Personen dieselben Fakten präsentieren, ihre Schlussfolgerungen jedoch unterschiedlich sind. Die Bayes'sche Statistik ermöglicht es uns, solche Meinungsverschiedenheiten formal zu modellieren, damit wir selbst prüfen können, welche Fakten benötigt werden, um unsere Sichtweise zu ändern. Sie müssen den auf dem Papier angegebenen Ergebnissen nicht glauben, weil sie einen gewissen p-Wert haben. Sie glauben ihnen, weil sie Ihnen wirklich überzeugend erscheinen.
6. Wie Bayes'sche Statistiken sich auf maschinelles Lernen beziehenZu den Ähnlichkeiten zwischen maschinellem Lernen (insbesondere neuronalen Netzen) und Bayes'scher Statistik, über die ich nachgedacht habe, gehören die folgenden: In beiden Disziplinen kann die mathematische Analyse äußerst kompliziert sein. Maschinelles Lernen ist im Prinzip das Verstehen und Lösen sehr nicht-trivialer Derivate. Sie erhalten eine Funktion und dafür eine Verlustfunktion, berechnen dann (automatisch) die Ableitung und versuchen, ihr zu folgen, bis Sie zu den optimalen Parametern gelangen. Viele bemerken böswillig, dass Rückwärtspropagierung nur eine „Kettenregel“ ist, aber in fast allen komplexen Aufgaben im Zusammenhang mit maschinellem Lernen sehr erfolgreich eingesetzt wird.
Die Bayes'sche Statistik ist eine weitere Facette der mathematischen Analyse, die mit der Lösung wirklich komplexer Integrale verbunden ist. Michael Betancourt, der Autor von Stan, bemerkte perfekt, dass fast jede Bayesianische Analyse mit der Berechnung von Erwartungen, dh mit der Berechnung von Integralen, verbunden ist. Aufgrund der Bayes'schen Analyse haben Sie immer noch eine posteriore Verteilung, aber Sie können sie in keiner Weise verwenden, ohne sie zu integrieren und daher keine konkrete Antwort zu erhalten. Glücklicherweise macht niemand bösartige Kommentare zu den Integralen, da jeder weiß, dass selbst das trivialste Integral ziemlich kompliziert ist. So wird es in einem der xkcd-Comics aphoristisch formuliert:
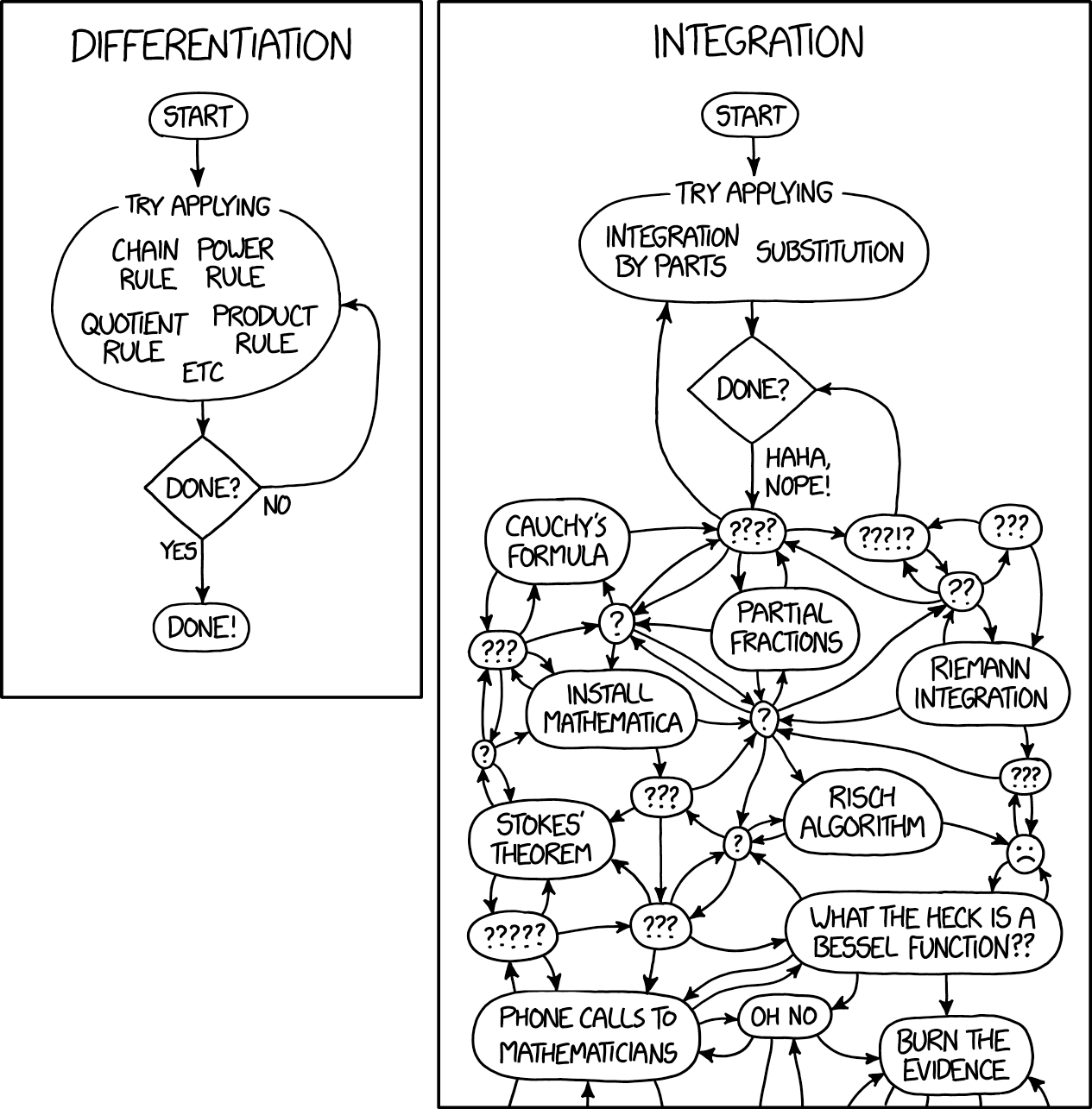
Das maschinelle Lernen und die Bayes'sche Statistik befinden sich heute in einem so merkwürdigen Zustand: Wir entwickeln die einfachsten Ideen der mathematischen Analyse zu einem Grad an Komplexität, der sich nur für Berechnungen eignet.
Diese Beziehung hebt auch einen wichtigen Punkt hervor. Wenn wir über Derivate sprechen, suchen wir nach einem bestimmten Punkt im Zusammenhang mit einer Funktion. Wenn Sie also die Position und die Zeit kennen, ist die Geschwindigkeit eine Ableitung, die bestimmen soll, wann Sie sich am schnellsten bewegen. Ein kleiner Schritt in Richtung Fortschritt in MO ist, wenn Sie herausfinden, dass eine einzelne Metrik besser ist als alle anderen. Integration ist die Summe des gesamten Prozesses. Wenn Sie den Ort und die Zeit kennen, ist das Integral die Entfernung, mit der Sie herausfinden können, wie weit Sie gekommen sind. Die Bayes'schen Statistiken sind eine Zusammenfassung von allem, was Sie über ein Problem wissen. Sie ermöglichen es Ihnen jedoch nicht nur, separate Prognosen zu erstellen, sondern auch den Grad des Vertrauens in unsere Prognosen zu charakterisieren, für die eine breite Palette von Optionen zur Verfügung steht. Fortschritte in der Bayes'schen Statistik sind ein Verständnis für immer komplexer werdende Informationssysteme.
7. Wenn die Leser das Thema des Buches näher kennenlernen möchten, welche Materialien (Bücher, Kurse, Blogs) werden Sie ihnen empfehlen?Ich habe mich maximal von I. T. Janes Buch "Probability Theory: the Logic of Science" inspirieren lassen. Insgeheim hoffe ich, dass mein Buch "Bayesian statistics is great" eine Analogie zu seinem Buch werden kann, sich aber an eine breite Leserschaft richtet. Die Arbeit mit dem Buch Janes ist keine leichte Aufgabe und stellt ein sehr radikales Ergebnis der Bayes'schen Statistik dar. Aubrey Clayton leistete seinen Lesern mit einer
Reihe von Vorlesungen zu den Kapiteln dieses Buches einen angemessenen Dienst.
Natürlich, wenn Ihnen das Buch gefällt, wird Ihnen mein Blog wahrscheinlich gefallen. Vor kurzem habe ich dort nicht so viel geschrieben, weil ich das Buch "Bayesian Statistics is great" und davor "Get Programming with Haskell" geschrieben habe, aber jetzt habe ich einen Kopf voller Ideen, und nicht alle widmen sich ausschließlich Bayesian Themen. In der Regel reflektiere ich ein Thema aus dem Bereich Statistik / Wahrscheinlichkeit und wähle aus dieser Idee sorgfältig einen neuen Artikel für den Blog aus.
8. Welches Konzept auf dem Gebiet der Wahrscheinlichkeitstheorie / Statistik ist Ihrer Erfahrung nach besonders schwer zu verstehen?Ehrlich gesagt ist der schwierigste Teil die Interpretation von Wahrscheinlichkeiten. Tatsächlich haben die Leute das Vertrauen in viele Bayesianer wie Nate Silver (und viele andere) verloren, als sie voraussagten, dass Hillary Clinton die Wahl 2016 mit einer Wahrscheinlichkeit von 80% gewinnen würde - und sie hat verloren. Die Leute dachten, jemand hätte sie betrogen, und jeder hatte Unrecht, aber die Wahrscheinlichkeit von 80% ist in der Tat nicht so groß. Wenn mir der Arzt sagt, dass meine Überlebenschancen 80% betragen, bin ich ernsthaft nervös.
In der Regel wird dieses Problem wie folgt gelöst: Wir geben die Wahrscheinlichkeiten als solche an und erklären, dass sie nicht geeignet sind, Unsicherheit auszudrücken. Um mit dieser Unannehmlichkeit fertig zu werden, muss man Koeffizienten oder Wahrscheinlichkeitsverhältnisse oder eine Art Dezibel-ähnliches System verwenden, wie das Jane-Konzept der „Beweise“. Nachdem ich jedoch lange über die Wahrscheinlichkeiten nachgedacht hatte, kam ich zu dem Schluss, dass es keinen eindeutig geeigneten Weg gibt, um Unsicherheit auszudrücken.
Die Essenz des Problems ist, dass jeder von uns tief in der Überzeugung ist, dass es Gewissheit auf der Welt gibt. Selbst erfahrene Experten für Wahrscheinlichkeitstheorie haben das Gefühl, dass Sie, wenn Sie die richtige Analyse durchführen, die erforderlichen A-priori-Daten herausfinden, Ihrem hierarchischen Modell eine weitere Ebene hinzufügen, Erfolg haben und die Unsicherheit beseitigen oder zumindest verringern . Wahrscheinlichkeiten sind für mich zum Teil attraktiv, weil diese beiden Faktoren bizarr kombiniert sind: der Wunsch, die Welt zu verstehen, und die Erkenntnis, dass die Welt Sie ohnehin überraschen wird, egal wie Sie es versuchen.
9. Was halten Sie von p-Werten als Maß für die statistische Signifikanz? Können Sie kurz beschreiben, was P-Hacking ist?Bei p-Werten werden häufig zwei Dinge missverstanden. Erstens wird eine intelligente Person nicht versuchen, Fragen mit p-Werten zu beantworten. Stellen Sie sich vor, wie das folgende Gespräch bei der Arbeit aussehen würde:
Manager: "Sie haben diesen Fehler behoben, wie wurde er Ihnen zugewiesen?"
Sie: "Nun, ich bin mehr als sicher, dass ich es nicht repariert habe ..."
Manager: "Wenn Sie es behoben haben, markieren Sie, dass Sie es behoben haben."
Sie: "Oh, nein, ich kann nur nicht sagen, dass ich es repariert habe ..."
Manager: "Nun, werden Sie es als" Ich werde es nicht reparieren "markieren?"
Sie: "Nein, nein, das ist natürlich überhaupt nicht so."
Die p-Werte von vielen sind verwirrt, da sie von Natur aus undurchsichtig sind. Die Bayes'schen Statistiken geben Ihnen eine hintere Wahrscheinlichkeit an, die eine positive Antwort auf eine Frage ist, die Sie nach Belieben formuliert haben. Im obigen Dialog sagt der Bayesianer: "Ich bin ziemlich sicher, dass der Fehler behoben wurde." Wenn der Manager möchte, dass Sie sicherer reagieren, kann der Bayesianer zusätzliche Informationen sammeln und sagen: "Ich bin im Prinzip sicher, dass dies behoben ist."
Das zweite Problem ist die tief verwurzelte Angewohnheit, 0.05 als eine Art magische, angeblich bedeutungsvolle Bedeutung zu wählen. Zurück zur vorherigen Frage zum Verständnis der Wahrscheinlichkeiten: Die Wahrscheinlichkeit von 5%, dass ein bestimmtes Ereignis eintritt, bedeutet nicht, dass dieses Ereignis selten ist. Sie haben eine Chance von 5%, 20 Punkte zu erhalten, wenn Sie einen 20-seitigen Würfel werfen. Jeder, der Dungeons and Dragons gespielt hat, weiß jedoch, dass dies alles andere als unmöglich ist. Über RPGs hinaus ist das Werfen eines Bones nicht das beste Werkzeug, um Wahrheit von Lügen zu unterscheiden.
Hier kommen wir zum P-Hacking. Stellen Sie sich vor, Sie spielen mit Ihren Freunden Dungeons and Dragons und werfen 20 Würfel gleichzeitig. Dann zeigen Sie auf denjenigen, auf den 20 Punkte gefallen sind, und erklären: "Es war dieser Knochen, den ich werfen wollte, und alle anderen waren Testknochen." Formal hast du wirklich 20 Punkte erzielt, aber das ist immer noch ein Betrug, wie du siehst. Dies ist die Essenz des P-Hacking. Sie führen die Analyse durch, bis Sie etwas „Wesentliches“ gefunden haben, und behaupten dann, dass Sie von Anfang an danach gesucht haben.
10. Abschließende Empfehlungen, welches Buch Sie nach Ihrem lesen sollten?, , , , . «Bayesian Analysis with Python» (, Not Monad Tutorial). , PyMC3. , . , — “Statistical Rethinking” . , .
. « – ». , «Doing Bayesian Data Analysis» .