Neuronale Netze haben sich von einer akademischen Neugierde zu einer massiven Industrie entwickelt

In den letzten zehn Jahren haben Computer ihre Fähigkeit, die Welt um sie herum zu verstehen, erheblich verbessert. Software für Fotoausrüstung erkennt automatisch die Gesichter von Menschen. Smartphones wandeln Sprache in Text um. Robomobile erkennen Objekte auf der Straße und vermeiden Kollisionen mit ihnen.
Im Zentrum all dieser Durchbrüche steht die Technologie der künstlichen Intelligenz (KI), die als Deep Learning (GO) bezeichnet wird. GO basiert auf neuronalen Netzwerken (NS), Datenstrukturen, die von Netzwerken aus biologischen Neuronen inspiriert sind. NS sind in Schichten organisiert, und die Eingänge einer Schicht sind mit den Ausgängen der benachbarten verbunden.
Informatiker experimentieren seit den 1950er Jahren mit NS. Der Grundstein für die heutige große GO-Industrie wurde jedoch durch zwei wichtige Durchbrüche gelegt - einen 1986, den zweiten 2012. Der Durchbruch von 2012 - die Revolution von GO - war mit der Entdeckung verbunden, dass die Verwendung von NS mit einer großen Anzahl von Schichten es uns ermöglicht, deren Effizienz erheblich zu verbessern. Die Entdeckung wurde durch das wachsende Datenvolumen und die wachsende Rechenleistung erleichtert.
In diesem Artikel stellen wir Ihnen die Welt der Nationalversammlung vor. Wir werden erklären, was NS ist, wie sie arbeiten und woher sie kommen. Und wir werden untersuchen, warum NS - trotz jahrzehntelanger Forschung - erst 2012 zu etwas wirklich Nützlichem wurden.
Neuronale Netze tauchten bereits in den 1950er Jahren auf
 Frank Rosenblatt arbeitet an seinem Perzeptron - einem frühen NS-Modell
Frank Rosenblatt arbeitet an seinem Perzeptron - einem frühen NS-ModellDie Idee der Nationalversammlung ist ziemlich alt - zumindest im Vergleich zu den Standards der Informatik. Bereits 1957 veröffentlichte
Frank Rosenblatt von der Cornell University einen
Bericht über ein frühes NS-Konzept namens Perceptron. 1958 schuf er mit Unterstützung der US Navy ein primitives System, mit dem 20 x 20 Pixel analysiert und einfache geometrische Formen erkannt werden können.
Rosenblatts Hauptziel war es nicht, ein praktisches Bildklassifizierungssystem zu schaffen. Er versuchte zu verstehen, wie das menschliche Gehirn funktioniert, und schuf Computersysteme, die in seinem Bild organisiert waren. Dieses Konzept hat jedoch zu viel Begeisterung bei Dritten ausgelöst.
"Heute hat die US Navy der Welt den Keim eines elektronischen Computers offenbart, von dem erwartet wird, dass er in der Lage ist, zu gehen, zu sprechen, zu sehen, zu schreiben, sich selbst zu reproduzieren und sich seiner Existenz bewusst zu sein", schrieb die New York Times.
Tatsächlich ist jedes Neuron im NS nur eine mathematische Funktion. Jedes Neuron berechnet die gewichtete Summe der Eingabedaten. Je größer die Eingabegewichtung ist, desto stärker wirken sich diese Eingabedaten auf die Ausgabe des Neurons aus. Anschließend wird die gewichtete Summe der nichtlinearen Aktivierungsfunktion zugeführt. In diesem Schritt können NS komplexe nichtlineare Phänomene simulieren.
Die Fähigkeiten der frühen Perzeptrone, mit denen Rosenblatt experimentierte - und der NS im Allgemeinen - beruhen auf ihrer Fähigkeit, anhand von Beispielen "zu lernen". NS werden trainiert, indem die Eingabegewichte von Neuronen basierend auf den Ergebnissen des Netzwerks mit den zum Beispiel ausgewählten Eingabedaten abgestimmt werden. Wenn das Netzwerk das Bild korrekt klassifiziert, nehmen die zur richtigen Antwort beitragenden Gewichte zu, während andere abnehmen. Wenn das Netzwerk falsch ist, werden die Gewichte in die andere Richtung angepasst.
Ein solches Verfahren ermöglichte es frühen NS-Patienten, auf eine Art und Weise zu „lernen“, die an das Verhalten des menschlichen Nervensystems erinnert. Der Hype um diesen Ansatz hörte in den 1960er Jahren nicht auf. Das
einflussreiche Buch von 1969 der Autoren der Informatiker Marvin Minsky und Seymour Papert zeigte jedoch, dass diese frühen NA erhebliche Einschränkungen aufweisen.
Die frühen Rosenblatt-NS hatten nur ein oder zwei trainierte Schichten. Minsky und Papert zeigten, dass solche NS mathematisch nicht in der Lage sind, komplexe Phänomene der realen Welt zu modellieren.
Im Prinzip waren tiefere NS fähiger. Solche NS würden jedoch die elenden Computerressourcen, über die Computer zu dieser Zeit verfügten, überfordern. Die einfachsten
aufsteigenden Suchalgorithmen, die in den ersten NS verwendet wurden, waren für tiefere NS nicht skalierbar.
In der Folge verlor die Nationalversammlung in den 1970er und frühen 1980er Jahren jegliche Unterstützung - es war Teil der Ära des „Winters der KI“.
Durchbruchsalgorithmus
 Mein eigenes neuronales Netzwerk, das auf „Soft Equipment“ basiert, geht davon aus, dass die Wahrscheinlichkeit, auf diesem Foto einen Hot Dog zu haben, 1 beträgt. Wir werden reich!
Mein eigenes neuronales Netzwerk, das auf „Soft Equipment“ basiert, geht davon aus, dass die Wahrscheinlichkeit, auf diesem Foto einen Hot Dog zu haben, 1 beträgt. Wir werden reich!Das Glück wandte sich wieder der NS zu, dank des berühmten
Werks von 1986, das das Konzept der Rückenvermehrung einführte - eine praktische Methode, um NS zu unterrichten.
Angenommen, Sie arbeiten als Programmierer in einer imaginären Softwarefirma und wurden angewiesen, eine Anwendung zu erstellen, die feststellt, ob das Image einen Hot Dog enthält. Sie beginnen die Arbeit mit einer zufällig initialisierten NS, die ein Eingabebild aufnimmt und einen Wert von 0 bis 1 ausgibt. Dabei bedeutet 1 "Hot Dog" und 0 "Nicht-Hot Dog".
Um das Netzwerk zu trainieren, sammeln Sie Tausende von Bildern, unter denen sich jeweils ein Etikett befindet, das angibt, ob sich auf diesem Bild ein Hot Dog befindet. Sie füttern ihr das erste Bild - und es ist ein Hot Dog drauf - im neuronalen Netz. Es gibt einen Ausgabewert von 0,07, was "kein Hot Dog" bedeutet. Das ist die falsche Antwort; Das Netzwerk sollte eine Antwort nahe 1 zurückgegeben haben.
Der Backpropagation-Algorithmus dient dazu, die Eingabegewichte so anzupassen, dass das Netzwerk einen höheren Wert erzeugt, wenn es erneut dieses Bild erhält - und vorzugsweise andere Bilder, bei denen es Hot Dogs gibt. Hierzu untersucht der Backpropagation-Algorithmus zunächst die Eingangsneuronen der Ausgangsschicht. Jeder Wert hat eine Gewichtsvariable. Der Backpropagation-Algorithmus passt jedes Gewicht so an, dass der NS einen höheren Wert ergibt. Je höher der Eingabewert, desto stärker steigt sein Gewicht.
Bisher beschreibe ich den einfachsten Aufstieg an die Spitze, den Forscher in den 1960er Jahren kannten. Der Backpropagation-Durchbruch war der nächste Schritt: Der Algorithmus verwendet partielle Ableitungen, um den „Fehler“ für die fehlerhafte Ausgabe auf die Eingaben von Neuronen zu verteilen. Der Algorithmus berechnet, wie sich eine kleine Änderung in jedem Eingabewert auf die endgültige Ausgabe eines Neurons auswirkt und ob diese Änderung das Ergebnis näher an die richtige Antwort rückt oder umgekehrt.
Das Ergebnis ist eine Reihe von Fehlerwerten für jedes Neuron in der vorherigen Schicht - in der Tat ein Signal, das auswertet, ob der Wert jedes Neurons zu groß oder zu klein ist. Dann wiederholt der Algorithmus den Abstimmungsprozess für neue Neuronen von der zweiten [von der End-] Schicht. Dadurch werden die Eingabegewichte der einzelnen Neuronen geringfügig geändert, um das Netzwerk näher an die richtige Antwort heranzuführen.
Anschließend berechnet der Algorithmus anhand partieller Ableitungen erneut, wie sich der Wert jeder Eingabe der vorherigen Ebene auf die Ausgabefehler dieser Ebene auswirkt. Diese Fehler werden dann an die vorherige Ebene weitergegeben, wo der Vorgang erneut wiederholt wird.
Dies ist nur ein vereinfachtes Backpropagation-Modell. Wenn Sie detaillierte mathematische Details benötigen, empfehle ich das Buch von Michael Nielsen zu diesem Thema. transl.]. Für unsere Zwecke ist es ausreichend, dass die umgekehrte Verteilung den Bereich der trainierten NS radikal verändert. Die Menschen waren nicht länger auf einfache Netzwerke mit einer oder zwei Schichten beschränkt. Sie könnten Netzwerke mit fünf, zehn oder fünfzig Schichten erstellen, und diese Netzwerke könnten eine willkürlich komplexe interne Struktur aufweisen.
Die Erfindung der Backpropagation löste den zweiten Boom der Nationalversammlung aus, der praktische Ergebnisse hervorbrachte. Eine Gruppe von Forschern von AT & T hat 1998 gezeigt, wie mit neuronalen Netzen handschriftliche Zahlen erkannt werden können, wodurch die Scheckverarbeitung automatisiert werden konnte.
"Die Hauptbotschaft dieser Arbeit ist, dass wir verbesserte Systeme zum Erkennen von Mustern entwickeln können, die sich mehr auf automatisches Lernen und weniger auf manuell entwickelte Heuristiken stützen", schrieben die Autoren.
Und doch waren NS in dieser Phase nur eine von vielen Technologien, die Forschern des maschinellen Lernens zur Verfügung standen. Als ich 2008 in einem AI-Kurs am Institut studierte, waren neuronale Netze nur einer von neun MO-Algorithmen, aus denen wir die für die Aufgabe geeignete Option auswählen konnten. GO bereitete sich jedoch bereits darauf vor, den Rest der Technologie in den Schatten zu stellen.
Big Data zeigt die Kraft des Deep Learning
 Entspannung erkannt. Chance auf Strand 1.0. Wir beginnen mit der Anwendung von Mai Tai.
Entspannung erkannt. Chance auf Strand 1.0. Wir beginnen mit der Anwendung von Mai Tai.Backpropagation erleichterte den Prozess der NS-Berechnung, aber tiefere Netzwerke benötigten immer noch mehr Rechenressourcen als kleine. Die Ergebnisse der in den 1990er und 2000er Jahren durchgeführten Studien zeigten oft, dass es möglich war, von zusätzlichen Komplikationen der NS immer weniger Nutzen zu ziehen.
Dann wurde das Denken der Menschen durch das berühmte Werk von 2012 geändert, das die NS unter dem Namen AlexNet beschrieb, benannt nach dem führenden Forscher Alex Krizhevsky. Ähnlich wie tiefere Netzwerke können sie zu einer bahnbrechenden Effizienz führen, jedoch nur in Kombination mit einer Fülle an Computerleistung und einer enormen Datenmenge.
AlexNet hat ein Trio von Informatikern der Universität von Toronto für die Teilnahme am ImageNet-Wissenschaftswettbewerb entwickelt. Die Organisatoren des Wettbewerbs sammelten im Internet eine Million Bilder, die jeweils einer der Tausenden von Objektkategorien zugeordnet waren, beispielsweise „Kirsche“, „Containerschiff“ oder „Leopard“. KI-Forscher wurden gebeten, ihre MO-Programme auf Teile dieser Bilder zu trainieren und dann zu versuchen, die korrekten Bezeichnungen für andere Bilder anzubringen, auf die die Software zuvor noch nicht gestoßen war. Die Software musste für jedes Bild fünf mögliche Bezeichnungen auswählen, und der Versuch wurde als erfolgreich angesehen, wenn eine davon mit der tatsächlichen übereinstimmte.
Dies war eine schwierige Aufgabe, und bis 2012 waren die Ergebnisse nicht sehr gut. Für den Gewinner 2011 betrug die Fehlerquote 25%.
2012 übertraf das AlexNet-Team alle Mitbewerber, indem es Antworten mit 15% Fehlern gab. Für den engsten Wettbewerber lag dieser Wert bei 26%.
Forscher aus Toronto kombinierten verschiedene Techniken, um bahnbrechende Ergebnisse zu erzielen. Eine davon war die Verwendung von
Faltungsneurosen (
Convolutional Neuroses, SNS). Tatsächlich trainiert der SNA sozusagen kleine neuronale Netze - deren Eingangsdaten Quadrate mit einer Seite von 7 bis 11 Pixeln sind - und „überlagert“ sie dann auf einem größeren Bild.
"Es ist, als ob Sie eine kleine Vorlage oder Schablone genommen und versucht hätten, sie mit jedem Punkt im Bild zu vergleichen", sagte KI-Forscher Jie Tan im vergangenen Jahr. - Sie haben eine Schablone eines Hundes und hängen sie an das Bild an und prüfen, ob dort ein Hund ist? Wenn nicht, verschieben Sie die Schablone. Und so für das ganze Bild. Und egal wo der Hund auf dem Bild erscheint. Die Schablone wird damit übereinstimmen. Jeder Netzwerk-Unterabschnitt sollte kein separater Hundeklassifikator werden. “
Ein weiterer wichtiger Erfolgsfaktor für AlexNet war der Einsatz von Grafikkarten, um den Lernprozess zu beschleunigen. Grafikkarten verfügen über eine parallele Verarbeitungsleistung, die sich gut für das Repetitive Computing eignet, das zum Trainieren eines neuronalen Netzwerks erforderlich ist. Durch die Übertragung der Rechenlast auf zwei GPUs - die Nvidia GTX 580 mit jeweils 3 GB Arbeitsspeicher - konnten die Forscher ein extrem großes und komplexes Netzwerk aufbauen und trainieren. AlexNet hatte acht trainierbare Schichten, 650.000 Neuronen und 60 Millionen Parameter.
Der Erfolg von AlexNet wurde schließlich auch durch die Größe der ImageNet-Trainingsbilddatenbank sichergestellt: eine Million Teile. Für die Feinabstimmung von 60 Millionen Parametern sind viele Bilder erforderlich. Um einen entscheidenden Sieg zu erzielen, wurde AlexNet von einer Kombination aus einem komplexen Netzwerk und einem großen Datenbestand unterstützt.
Ich frage mich, warum so ein Durchbruch nicht früher stattgefunden hat:
- Das von AlexNet-Forschern verwendete GPU-Paar für Endverbraucher war weit davon entfernt, das leistungsstärkste Computergerät für 2012 zu sein. Fünf und sogar zehn Jahre zuvor gab es leistungsstärkere Computer. Darüber hinaus ist die Technologie zur Beschleunigung des Lernens von NS mit Grafikkarten seit mindestens 2004 bekannt.
- Die Basis von einer Million Bildern war 2012 für das Unterrichten von MO-Algorithmen ungewöhnlich groß. Das Sammeln solcher Daten war jedoch keine neue Technologie für dieses Jahr. Ein gut finanziertes Forschungsteam könnte leicht eine Datenbank dieser Größe vor fünf oder zehn Jahren zusammenstellen.
- Die in AlexNet verwendeten Hauptalgorithmen waren nicht neu. Der Backpropagation-Algorithmus von 2012 existierte bereits seit etwa einem Vierteljahrhundert. Schlüsselideen im Zusammenhang mit neuronalen Faltungsnetzen wurden in den 1980er und 1990er Jahren entwickelt.
So existierte jedes der Erfolgselemente von AlexNet lange vor dem Durchbruch für sich. Offensichtlich fiel niemandem ein, sie zu kombinieren - größtenteils, weil niemand wusste, wie mächtig diese Kombination sein würde.
Die Erhöhung der Tiefe der NS hat die Effizienz ihrer Arbeit praktisch nicht verbessert, wenn sie nicht genügend Trainingsdatensätze verwendet haben. Das Erweitern des Datensatzes hat die Leistung kleiner Netzwerke nicht verbessert. Um die Effizienzsteigerung zu sehen, benötigten wir sowohl tiefere Netzwerke als auch größere Datenmengen - und eine erhebliche Rechenleistung, die es uns ermöglichte, den Schulungsprozess in angemessener Zeit durchzuführen. Das AlexNet-Team brachte als erstes alle drei Elemente in einem Programm zusammen.
Der Boom des tiefen Lernens

Die Demonstration der ganzen Kraft von Deep NS, die durch eine ausreichende Menge an Trainingsdaten bereitgestellt wurde, wurde von vielen Menschen bemerkt - sowohl von Wissenschaftlern, Forschern als auch von Vertretern der Industrie.
Der erste ImageNet-Wettbewerb, der sich ändert. Bis 2012 verwendeten die meisten Teilnehmer andere Technologien als Deep Learning. Wie die Sponsoren feststellten, nutzte im Wettbewerb 2013 die Mehrheit der Teilnehmer GO.
Die Fehlerquote unter den Gewinnern ging allmählich zurück - von beeindruckenden 16% bei AlexNet im Jahr 2012 auf 2,3% im Jahr 2017:
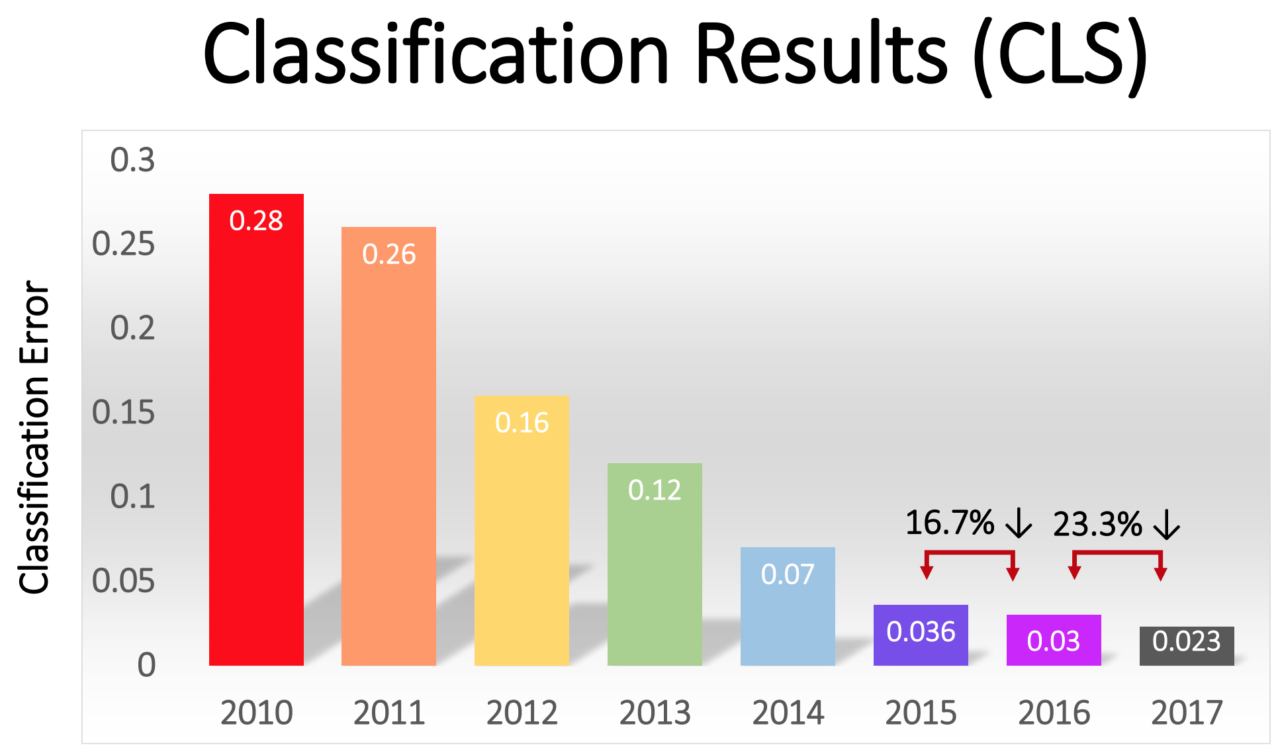
Die GO-Revolution breitete sich schnell in der Branche aus. 2013 erwarb Google ein Startup, das von den Autoren von AlexNet gegründet wurde, und nutzte seine Technologie als Grundlage für die Bildsuchfunktion in Google Fotos. Bis 2014 hat Facebook eine eigene Software beworben, die Bilder mit GO erkennt. Apple verwendet seit mindestens 2016 GO für die Gesichtserkennung unter iOS.
GO liegt auch der jüngsten Verbesserung der Spracherkennungstechnologie zugrunde. Siri von Apple, Alexa von Amazon, Cortana von Microsoft und Googles Assistent verwenden GO - entweder, um die Wörter einer Person zu verstehen oder um eine natürlichere Stimme zu erzeugen, oder beides.
In den letzten Jahren hat sich in der Branche ein sich selbst tragender Trend herausgebildet, bei dem sich die Zunahme von Rechenleistung, Datenvolumen und Netzwerktiefe gegenseitig stützen. Das AlexNet-Team nutzte die GPU, weil sie paralleles Rechnen zu einem vernünftigen Preis anbot. In den letzten Jahren haben jedoch immer mehr Unternehmen begonnen, eigene Chips zu entwickeln, die speziell für den Einsatz im MO-Bereich entwickelt wurden.
Google kündigte die Veröffentlichung des Tensor Processing Unit-Chips an, der speziell für den NS entwickelt wurde. Im selben Jahr kündigte Nvidia die Veröffentlichung einer neuen, für den NS optimierten GPU namens Tesla P100 an. Intel antwortete 2017 mit seinem AI-Chip auf den Anruf. 2018 kündigte Amazon die Veröffentlichung seines eigenen AI-Chips an, der als Teil der Cloud-Dienste des Unternehmens verwendet werden kann. Sogar Microsoft soll an seinem AI-Chip arbeiten.
Smartphone-Hersteller arbeiten auch an Chips, mit denen mobile Geräte mehr lokal mit NS rechnen können, ohne Daten auf Server hochladen zu müssen. Solches Computing auf Geräten reduziert die Latenz und verbessert die Privatsphäre.
Sogar Tesla ist mit speziellen Chips in dieses Spiel eingestiegen. In diesem Jahr zeigte Tesla einen neuen leistungsstarken Computer, der für die Berechnung von NS optimiert wurde. Tesla nannte es Full Self-Driving Computer und präsentierte es als Schlüsselmoment in der Strategie des Unternehmens, die Tesla-Flotte in Roboterfahrzeuge zu verwandeln.
Die Verfügbarkeit von für KI optimierten Computerkapazitäten hat eine Anforderung nach den Daten erzeugt, die zum Trainieren von immer komplexer werdenden NS erforderlich sind. Diese Dynamik zeigt sich am deutlichsten im Robomobilsektor, in dem Unternehmen Daten über Millionen Kilometer realer Straßen sammeln. Tesla kann diese Daten automatisch von den Autos der Benutzer sammeln, und seine Konkurrenten Waymo und Cruise bezahlten Fahrer, die ihre Autos auf öffentlichen Straßen fuhren.

Die Datenanforderung bietet großen Online-Unternehmen einen Vorteil, die bereits auf große Mengen von Benutzerdaten zugreifen können.
Deep Learning hat aufgrund seiner extremen Flexibilität so viele verschiedene Bereiche erobert. Jahrzehntelange Versuche und Irrtümer haben es den Forschern ermöglicht, die Grundbausteine für die häufigsten Aufgaben im MO-Bereich zu entwickeln - beispielsweise Faltungsnetzwerke für eine effiziente Bilderkennung. Wenn Sie jedoch ein für das Schema geeignetes Netzwerk auf hoher Ebene und genügend Daten haben, ist der Schulungsprozess einfach. Deep NSs sind in der Lage, eine außergewöhnlich breite Palette komplexer Muster zu erkennen, ohne die besonderen Anweisungen menschlicher Entwickler zu beachten.
Natürlich gibt es Einschränkungen. Zum Beispiel gönnten sich einige Leute die Idee, Robomobile nur mit Hilfe von GO zu trainieren - das heißt, sie fütterten Bilder, die von einer Kamera oder einem neuronalen Netzwerk empfangen wurden, und erhielten Anweisungen von ihr, das Lenkrad und das Pedal zu drehen. Ich bin diesem Ansatz skeptisch gegenüber.
Die Nationalversammlung hat die Fähigkeit, komplexe logische Überlegungen anzustellen, die erforderlich sind, um bestimmte Bedingungen auf der Straße zu verstehen, noch nicht unter Beweis gestellt. Darüber hinaus sind NS „Black Boxes“, deren Workflow praktisch unsichtbar ist. Es wäre schwierig, die Sicherheit eines solchen Systems zu bewerten und zu bestätigen.Mit GO konnten jedoch in einem unerwartet großen Anwendungsbereich sehr große Sprünge erzielt werden. In den kommenden Jahren ist mit weiteren Fortschritten in diesem Bereich zu rechnen.