Hallo allerseits. Unten finden Sie eine Abschrift des Berichts mit Big Monitoring Meetup 4 .
Prometheus ist ein Überwachungssystem für verschiedene Systeme und Dienste, mit dem Systemadministratoren Informationen über die aktuellen Parameter von Systemen sammeln und Warnungen konfigurieren können, um Benachrichtigungen über Abweichungen im Betrieb von Systemen zu erhalten.
In dem Bericht werden Thanos und VictoriaMetrics , Projekte zur Langzeitspeicherung von Prometheus-Metriken, verglichen.


Zuerst werde ich über Prometheus sprechen. Dies ist ein Überwachungssystem, das Metriken von bestimmten Zielen sammelt und diese im lokalen Speicher speichert. Prometheus kann Metriken in ein Remote-Repository schreiben, Warnungen generieren und Regeln aufzeichnen.

Prometheus Einschränkungen:
- Es gibt keine globale Abfrageansicht. Dies ist, wenn Sie mehrere unabhängige Instanzen von Prometheus haben. Sie sammeln Metriken. Und Sie möchten zusätzlich zu all diesen Metriken, die von verschiedenen Prometheus-Instanzen gesammelt wurden, eine Anfrage stellen. Prometheus erlaubt das nicht.
- Bei prometheus ist die Leistung auf nur einen Server beschränkt. Prometheus kann nicht automatisch auf mehrere Server skalieren. Sie können Ihre Ziele nur manuell auf mehrere Prometheus aufteilen.
- Das Volumen der Metriken in Prometheus ist aus demselben Grund auf nur einen Server beschränkt, da es nicht automatisch auf mehrere Server skaliert werden kann.
- In Prometheus ist es nicht so einfach, die Datensicherheit zu organisieren.

Diese Probleme / Herausforderungen lösen?
Die Lösungen sind:
Alle diese Remote-Speicherlösungen wurden von Prometheus gesammelt. Sie lösen das Remotespeicherproblem der vorherigen Folie auf unterschiedliche Weise. In dieser Präsentation werde ich nur auf die ersten beiden Lösungen eingehen : Thanos und VictoriaMetrics .
Zum ersten Mal erschienen Informationen über Thanos unter diesem Link . Es beschreibt die Architektur von Thanos und wie es funktioniert.

Dann nimmt Prometheus die von Prometheus gespeicherten Daten auf die lokale Festplatte und kopiert sie in S3, in GCS oder in einen anderen Objektspeicher.

Auf diese Weise bietet Thanos eine globale Abfrageansicht. Sie können im Objektspeicher gespeicherte Daten von mehreren Instanzen von Prometheus anfordern.

Thanos unterstützt PromQL und die Prometheus-Abfrage-API .

Thanos verwendet Prometheus-Code zum Speichern von Daten.

Thanos wird von denselben Entwicklern wie Prometheus entwickelt.
Über VictoriaMetrics . Hier ist der Link, über den wir zuerst über VictoriaMetrics gesprochen haben .

VictoriaMetrics empfängt Daten von mehreren Prometheus über das von Prometheus unterstützte Remote Write API- Protokoll.
VictoriaMetrics bietet eine globale Abfrageansicht, da mehrere Instanzen von Prometheus Daten in eine VictoriaMetrics schreiben können. Dementsprechend können Sie alle diese Daten anfordern.

VictoriaMetrics unterstützt auch Thanos, PromQL und die Prometheus-Abfrage-API.

Im Gegensatz zu Thanos wird der VictoriaMetrics-Quellcode von Grund auf neu geschrieben und hinsichtlich Geschwindigkeit und Ressourcen optimiert.

VictoriaMetrics skaliert im Gegensatz zu Thanos sowohl vertikal als auch horizontal. Es gibt eine Single-Node-Version , die vertikal skaliert. Sie können mit einem Prozessor und 1 GB Arbeitsspeicher beginnen und schrittweise auf Hunderte von Prozessoren und 1 TB Arbeitsspeicher anwachsen. VictoriaMetrics kann all diese Ressourcen nutzen. Die Leistung wird im Vergleich zu einem Single-Core-System um das 100-fache gesteigert.

Die Geschichte von Thanos begann im November 2017, als das erste öffentliche Commit erschien. Zuvor wurde Thanos intern von improbable.io entwickelt .

Im Juni 2019 gab es eine wegweisende Version 0.5.0, in der das Klatschprotokoll entfernt wurde . Er wurde von Thanos entfernt, weil er nicht sein Bestes gab. Oft funktionierte der Thanos-Cluster nicht richtig, die Knoten, die aufgrund des Gossip-Protokolls falsch damit verbunden waren. Deshalb beschlossen sie, es von dort zu entfernen. Ich denke das ist die richtige Entscheidung.

Ebenfalls im Juni 2019 sandten sie den Antrag Nr. 256 an die Cloud Native Computing Foundation .

Und nach ein paar Monaten trat Thanos der Cloud Native Computing Foundation bei , zu der Prometheus, Kubernetes und andere beliebte Projekte gehören.

Im Januar 2018 begann die Entwicklung von VictoriaMetrics.

Im September 2018 habe ich VictoriaMetrics zum ersten Mal öffentlich erwähnt.

Im Dezember 2018 wurde die Single-Node-Version veröffentlicht.

Im Mai 2019 wurden die Quellen sowohl der Single-Node- als auch der Cluster-Version veröffentlicht .

Im Juni 2019 haben wir uns wie Thanos unter der Nummer 255 bei der CNCF-Stiftung beworben. Wir haben uns einen Tag vor Thanos beworben.

Leider sind wir dort noch nicht aufgenommen worden. Brauche Hilfe von der Community.

Betrachten Sie die wichtigsten Folien zur Architektur von Thanos und VictoriaMetrics.

Beginnen wir mit Thanos. Gelbe Komponenten sind Prometheus-Komponenten. Alles andere sind die Thanos-Komponenten. Beginnen wir mit der wichtigsten Komponente. Thanos Sidecar ist eine Komponente, die neben jedem Prometheus installiert wird. Er ist verpflichtet, Prometheus-Daten aus dem lokalen Speicher in S3 oder einen anderen Objektspeicher zu laden.
Es gibt auch eine Komponente wie Thanos Store Gateway, die diese Daten bei eingehenden Anforderungen von Thanos Query aus dem Objektspeicher lesen kann. Thanos Query implementiert PromQL und die Prometheus-API. Das heißt, von außen sieht es aus wie ein Prometheus. Es akzeptiert PromQL-Abfragen, sendet sie an Thanos Store Gateway, Thanos Store Gateway ruft die erforderlichen Daten aus Object Storage ab und sendet sie zurück.
Aufgrund der Besonderheit der Thanos Sidecar-Implementierung, die die letzten zwei Stunden nicht in Object Storage S3 hochladen kann, haben wir die Daten im Objektspeicher ohne die letzten zwei Stunden gespeichert, da Prometheus für diese zwei Stunden noch keine Dateien im lokalen Speicher erstellt hat.
Wie haben sie beschlossen, das zu umgehen? Thanos Query sendet zusätzlich zu den Anforderungen vom Thanos Store Gateway parallele Anforderungen an alle Thanos-Seitenwagen, die sich neben Prometheus befinden.
Und Thanos Sidecar wiederum vertritt Anfragen in Prometheus und erhält Daten für die letzten zwei Stunden.
Zusätzlich zu diesen Komponenten gibt es eine optionale Komponente, ohne die sich Thanos nicht wohlfühlt. Dies ist Thanos Compact, bei dem kleine Dateien im Objektspeicher zu größeren Dateien zusammengeführt werden, die von Thanos Sidecar hier hochgeladen wurden. Thanos Sidecar lädt dort in zwei Stunden Datendateien hoch. Wenn Sie diese Dateien nicht zu größeren Dateien zusammenführen, kann ihre Anzahl erheblich zunehmen. Je mehr solcher Dateien, desto mehr Speicher wird für Thanos Store Gateway benötigt, desto mehr Ressourcen werden zum Übertragen von Daten über das Netzwerk und von Metadaten benötigt. Thanos Store Gateway wird ineffizient. Daher müssen Sie auf jeden Fall Thanos Compact ausführen, bei dem kleine Dateien in größere zusammengeführt werden, damit weniger solche Dateien vorhanden sind, und um den Overhead auf dem Thanos Store Gateway zu verringern.
Es gibt auch eine solche Komponente wie Thanos Ruler. Es folgt den Prometheus-Warnregeln und kann die Prometheus-Aufzeichnungsregeln berechnen, um Daten in den Objektspeicher zurückzuschreiben. Diese Komponente wird aber nicht empfohlen, weil Er ist geneigt, unvollständige Daten zurückzugeben .
Dies ist ein einfaches Schema für Thanos.
Vergleichen Sie nun mit dem VictoriaMetrics-Schema.
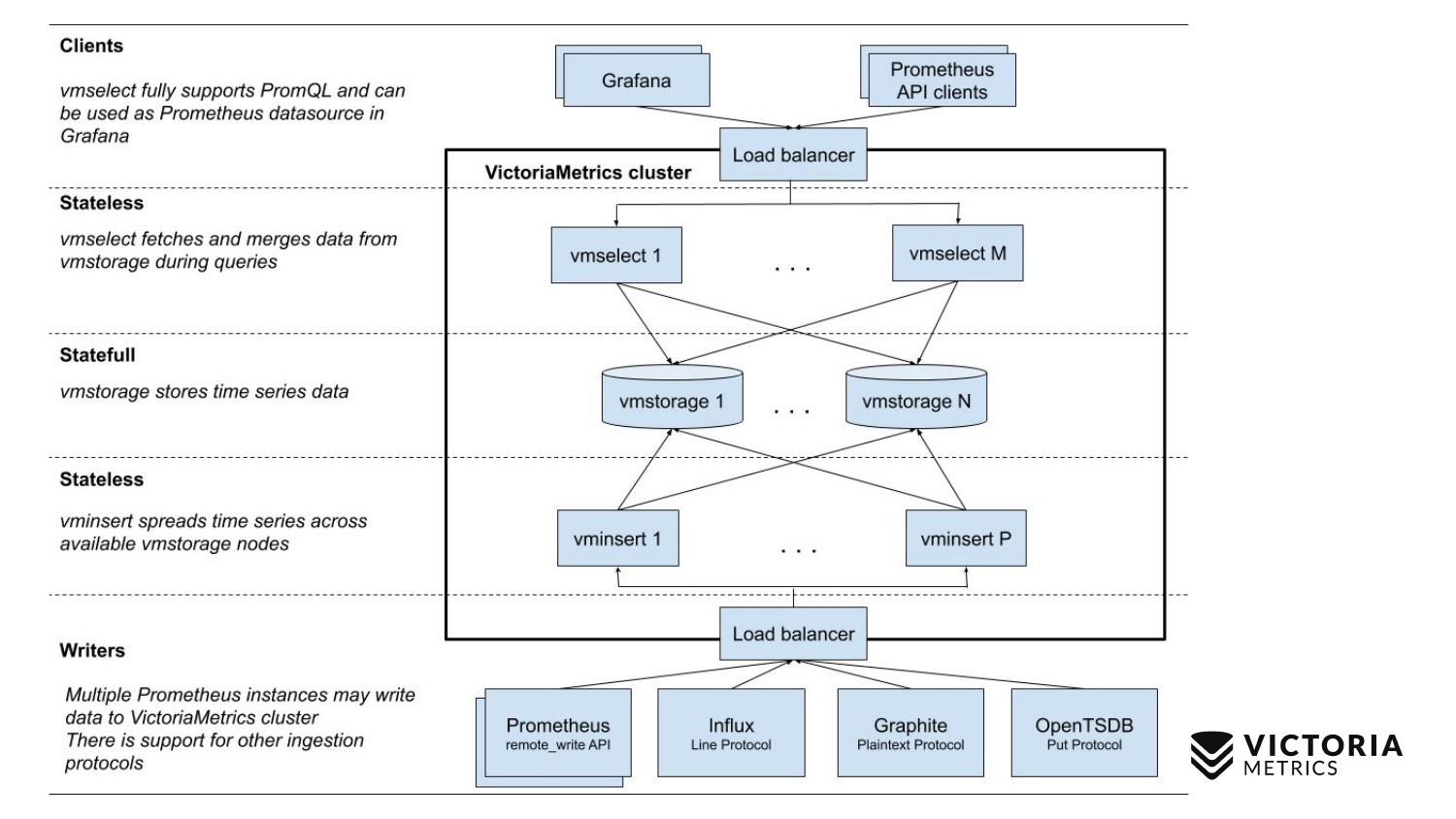
VictoriaMetrics hat zwei Versionen: Einzelknoten- und Cluster-Version. Einzelner Knoten wird auf einem einzelnen Computer ausgeführt. Single-Node hat diese Komponenten nicht, nur eine Binärdatei. Diese Binärdatei auf der Folie sieht aus wie dieses Quadrat. Alles, was sich innerhalb des Quadrats befindet, ist der Inhalt der Binärdatei für die Single-Node-Version. Du musst nichts über ihn wissen. Starten Sie einfach die Binärdatei - und alles funktioniert für uns.
Die Cluster-Version ist komplizierter. Darin befinden sich drei verschiedene Komponenten: vmselect, vminsert und vmstorage. Aus ihrem Namen sollte klar sein, was jeder von ihnen tut. Die Insert-Komponente akzeptiert Daten in verschiedenen Formaten: von der Prometheus-Fernschreib-API, dem Influx-Leitungsprotokoll, dem Graphite-Protokoll und dem OpenTSDB-Protokoll. Die Insert-Komponente akzeptiert sie, analysiert sie und verteilt sie auf vorhandene Speicherkomponenten, in denen die Daten bereits gespeichert sind. Die Select-Komponente akzeptiert wiederum PromQL-Abfragen. Es implementiert PromQL sowie die Prometheus-Abfrage-API und kann als Ersatz für Prometheus in Grafana oder anderen Prometheus-API-Clients verwendet werden. Select akzeptiert eine Promql-Anforderung, analysiert sie, liest die erforderlichen Daten zum Ausführen dieser Anforderung vom Speicherknoten, verarbeitet diese Daten und gibt eine Antwort zurück.

Vergleichen Sie die Schwierigkeiten bei der Installation von Thanos und VictoriaMetrics.

Beginnen wir mit Thanos. Bevor Sie mit Thanos arbeiten, müssen Sie in Object Storage einen Bucket erstellen, z. B. S3 oder GCS, damit Thanos Sidecar dort Daten schreiben kann.

Dann müssen Sie für jeden Prometheus Thanos Sidecar installieren. Vorher müssen Sie daran denken, die Datenkomprimierung in Prometheus zu deaktivieren. Durch die Datenkomprimierung werden die Daten im lokalen Speicher von Prometheus regelmäßig komprimiert, um den Ressourcenverbrauch zu senken.
Wenn Sie Thanos Sidecar auf Ihrem Prometheus installieren, müssen Sie diese Datenkomprimierung deaktivieren, da Thanos Sidecar bei aktivierter Datenkomprimierung nicht normal funktioniert. Dies bedeutet, dass Ihr Prometheus beginnt, Daten in Blöcken von zwei Stunden zu speichern und diese Blöcke nicht mehr zu größeren Blöcken zusammenführt. Dementsprechend funktionieren Anforderungen, die länger als die letzten zwei Stunden sind, nicht so effizient wie bei aktivierter Datenkomprimierung.

Daher empfiehlt Thanos, die Datenaufbewahrungszeit im lokalen Speicher auf 6-8 Stunden zu reduzieren, um den Overhead einer großen Anzahl kleiner Blöcke zu verringern.
Nach der Installation von Thanos Sidecar müssen Sie zwei Komponenten für jeden Object Storage Bucket installieren. Dies sind Thanos Compactor und Thanos Store Gateway.

Danach müssen Sie Thanos Query installieren und so konfigurieren, dass es weiß, wie eine Verbindung zu allen Thanos Store Gateways hergestellt wird und wie eine Verbindung zu allen Thanos Sidecar hergestellt wird.
Möglicherweise liegt ein kleines Problem vor.

Sie müssen eine zuverlässige und sichere Verbindung von Thanos Query zu diesen Komponenten konfigurieren. Befindet sich Ihr Prometheus in verschiedenen Rechenzentren oder in verschiedenen VPCs, sind externe Verbindungen zu diesen verboten. Aber damit Thanos Query funktioniert, müssen Sie die Verbindung dort irgendwie konfigurieren und einen Weg finden.
Wenn Sie viele solcher Rechenzentren haben, sinkt dementsprechend die Zuverlässigkeit des gesamten Systems. Da Thanos Query ständig mit allen Thanos Sidecar verbunden bleiben muss, befinden sich diese in verschiedenen Rechenzentren. Bei jeder eingehenden Anfrage wird er Anfragen an alle Thanos Sidecar weiterleiten. Wenn die Verbindung unterbrochen wird, erhalten Sie entweder einen unvollständigen Datensatz oder die Antwort "Der Cluster funktioniert nicht".

In VictoriaMetrics ist es etwas einfacher. Bei der Single-Node-Version reicht es aus, nur eine Binärdatei auszuführen, und alles funktioniert.

In einer Cluster-Version reicht es aus, alle drei oben genannten Komponententypen in einer beliebigen Anzahl auszuführen oder den Start von Komponenten in Kubernetes mithilfe des Steuerdiagramms zu automatisieren. Wir planen immer noch, einen Kubernetes-Betreiber zu machen. Die Helmkarte deckt einige Fälle nicht ab und ermöglicht es Ihnen, Ihr Bein zu schießen. So können Sie beispielsweise die Anzahl der Speicherknoten reduzieren, was zu Datenverlusten führt.

Nachdem Sie eine Binär- oder Cluster-Version gestartet haben, müssen Sie der Prometheus-Konfiguration lediglich die Einstellung für die Remote-Schreib-URL hinzufügen, damit Daten parallel zum lokalen Speicher und zum Remote-Speicher geschrieben werden. Wie Sie bemerkt haben, sollte diese Konfiguration im Vergleich zur Thanos-Konfiguration wesentlich zuverlässiger funktionieren. Wir müssen VictoriaMetrics nicht mit allen Prometheus in Verbindung halten, da die Prometheus selbst eine Verbindung zu VictoriaMetrics herstellen und die Daten übertragen.

Betrachten Sie die Escorts Thanos und VictoriaMetrics.

Thanos muss Sidecar im Auge behalten, damit es nicht aufhört, Daten in Object Storage zu laden. Sie können das Laden dieser Daten aufgrund von Ladefehlern stoppen, z. B. wenn Ihre Netzwerkverbindung mit dem Objektspeicher vorübergehend getrennt wird oder der Objektspeicher vorübergehend nicht verfügbar ist. In diesem Moment wird Thanos Sidecar dies bemerken, einen Fehler melden, herunterfallen und dann aufhören zu arbeiten. Wenn Sie es nicht überwachen, werden Ihre Daten nicht mehr in den Objektspeicher übertragen. Wenn die Aufbewahrungszeit abgelaufen ist (6-8 Stunden empfohlen), gehen Daten verloren, die nicht in den Objektspeicher gefallen sind.

Alsos Verdichter können aufhören zu arbeiten, weil sie mit Sidecar fahren . Komprimierer nehmen Daten aus dem Objektspeicher und führen sie zu größeren Datenblöcken zusammen. Da die Kompaktoren nicht mit dem Beiwagen synchronisiert sind, kann dies passieren: Beiwagen hat den Block noch nicht fertig geschrieben, Kompaktor entscheidet, dass dieser Block vollständig aufgezeichnet ist. Compactor beginnt es zu lesen. Der Block wird nicht vollständig gelesen und funktioniert nicht mehr. Details finden Sie hier .

Store Gateway kann aufgrund des Wettlaufs zwischen Compactor und Sidecar inkonsistente Daten liefern. Dies ist dasselbe, da das Store Gateway in keiner Weise mit dem von Compactor und Sidecar synchronisiert ist. Dementsprechend kann eine Wettlaufsituation eintreten, wenn das Store Gateway einen Teil der Daten oder überschüssige Daten nicht sieht.

Die Abfragekomponente in Thanos führt standardmäßig zu Teilergebnissen, wenn derzeit einige Sidecar- oder Store Gateway-Komponenten nicht verfügbar sind. Sie erhalten einen Teil der Daten und wissen nicht einmal, dass nicht alle Daten empfangen wurden. Dass es standardmäßig so funktioniert. In einer ähnlichen Situation gibt VictoriaMetrics die markierten Daten als Teil zurück.

Im Gegensatz zu Thanos verliert VictoriaMetrics selten Daten. Auch wenn die Verbindung von Prometheus zu VictoriaMetrics unterbrochen wird, ist dies kein Problem, da Prometheus weiterhin eingehende neue Daten im Write Ahead Log aufzeichnet, das 2 Stunden groß ist. Wenn Sie innerhalb von zwei Stunden erneut eine Verbindung zu VictoriaMetrics herstellen, gehen die Daten nicht verloren. Prometheus kann Daten hinzufügen, nachdem die Verbindung zu VictoriaMetrics wiederhergestellt wurde .

Im Gegensatz zu Thanos, bei dem Daten erst nach zwei Stunden in den Objektspeicher geschrieben werden, repliziert Prometheus Daten automatisch über das Remote-Schreibprotokoll in den Remote-Speicher, z. B. VictoriaMetrics. Sie haben keine Angst, den lokalen Speicher in Prometheus zu verlieren. Wenn er plötzlich den lokalen Speicher verloren hat, gehen im schlimmsten Fall die letzten Sekunden der Daten verloren, die keine Zeit zum Schreiben auf den Remotespeicher hatten.

Im Gegensatz zu Thanos verwaltet Kubernetes den Cluster automatisch. Im Gegensatz zu VictoriaMetrics-Cluster-Komponenten sind alle Thanos-Komponenten schwer in einen einzelnen Kubernetes-Cluster zu integrieren.

VictoriaMetrics hat ein sehr einfaches Upgrade auf die neue Version. Stoppen Sie einfach VictoriaMetrics, aktualisieren Sie die Binärdateien und führen Sie sie aus. Wenn Sie ein SIGINT-Signal beenden, werden alle VictoriaMetrics-Binärdateien ordnungsgemäß heruntergefahren. Sie speichern die erforderlichen Daten korrekt, schließen eingehende Verbindungen korrekt, um nichts zu verlieren. Daher verlieren Sie beim Upgrade nichts.

VictoriaMetrics bietet eine sehr einfache Möglichkeit, einen Cluster zu erweitern. Fügen Sie einfach die erforderlichen Komponenten hinzu und arbeiten Sie weiter.

Über die Fallstricke in Thanos und Victoria Metrics.

Thanos hat die folgenden Tücken. Prometheus sollte Daten für die letzten zwei Stunden speichern. Wenn sie verloren gehen, verlieren Sie sie vollständig, da sie noch nicht im Objektspeicher registriert wurden, wie z. B. S3.

Die Store Gateway-Komponente und die Compactor-Komponente benötigen möglicherweise viel Speicher, um mit großem Objektspeicher zu arbeiten, wenn dort viele kleine Dateien gespeichert sind. Je größer die Anzahl und das Volumen der Dateien ist, desto mehr Speicher für Store Gateway und Compactor ist erforderlich, um Metainformationen zu speichern. Thanos hat eine Menge Probleme mit Store Gateway und Compactor, die mit durchschnittlich aufgezeichneten Daten abfallen .

Thanos wird angepriesen, dass es sich unbegrenzt nach der Höhe Ihres Prometheus skalieren lässt. Das stimmt eigentlich nicht. Da alle Anforderungen die Abfragekomponente durchlaufen, die gleichzeitig alle Store Gateway-Komponenten und alle Sidecar-Komponenten abfragen muss, ziehen Sie Daten von dort und verarbeiten Sie sie dann vor. Offensichtlich wird die Abfragegeschwindigkeit durch das langsamste schwache Glied, das langsamste Store Gateway oder das langsamste Sidecar begrenzt.
Diese Komponenten können ungleichmäßig belastet sein. Zum Beispiel haben Sie einen Prometheus, der Millionen von Metriken pro Sekunde sammelt. Und da ist Prometheus, der Tausende von Metriken pro Sekunde sammelt. Prometheus, das Millionen von Metriken pro Sekunde sammelt, lädt den Server, auf dem es ausgeführt wird, viel mehr. Dementsprechend ist Sidecar dort langsamer. Im Allgemeinen arbeitet dort alles langsam. Und die Abfragekomponente ruft Daten von dort sehr langsam ab. Dementsprechend wird die Leistung Ihres gesamten Clusters durch diesen langsamen Beiwagen eingeschränkt.

Standardmäßig gibt Thanos Teildaten zurück, wenn einige Sidecars und Store Gateway nicht verfügbar sind. Wenn beispielsweise Sidecar in verschiedenen Rechenzentren auf der ganzen Welt verteilt ist, steigt die Wahrscheinlichkeit einer Trennung und Nichtverfügbarkeit von Komponenten erheblich. Dementsprechend erhalten Sie in den meisten Fällen Teildaten, ohne es überhaupt zu wissen.

VictoriaMetrics hat auch Fallstricke. Der erste Nachteil ist eine Option, die den für den VictoriaMetrics-Cache verwendeten RAM-Speicher begrenzt. Standardmäßig entspricht dies 60% des Arbeitsspeichers auf dem Computer, auf dem VictoriaMetrics ausgeführt wird, oder 60% des VictoriaMetrics-Pod-Arbeitsspeichers in Kubernetes.
Wenn Sie diesen Wert falsch ändern, kann dies die Leistung von VictoriaMetrics beeinträchtigen. Wenn Sie beispielsweise den Wert zu niedrig festlegen, passen die Daten möglicherweise nicht mehr in den VictoriaMetrics-Cache. Aus diesem Grund muss sie zusätzliche Arbeit leisten und den Prozessor mit der Festplatte laden. Wenn Sie diese Option zu groß wählen, erhöht sich zum einen die Wahrscheinlichkeit, dass VictoriaMetrics mit einem Speicherfehler abstürzt, und zum anderen verbleibt sehr wenig Arbeitsspeicher im Betriebssystem Speicher für den Dateicache. Und VictoriaMetrics benötigt einen Dateicache für die Leistung. Wenn dies nicht ausreicht, kann sich die Belastung der Festplatte erheblich erhöhen. Daher ein Tipp: Ändern Sie den Parameter nicht, es sei denn, dies ist unbedingt erforderlich.
Die zweite Möglichkeit. Dies ist der Aufbewahrungszeitraum - der Zeitraum, der standardmäßig auf 1 Monat festgelegt ist. Dies ist die Zeit, in der VictoriaMetrics Daten speichert. Nach dieser Zeit löscht VictoriaMetrics die Daten.
Viele führen VictoriaMetrics ohne diesen Parameter aus und zeichnen Daten für einen Monat auf. Und dann fragen sie: Warum sind die Daten für den Vormonat verschwunden? Da die Aufbewahrungsdauer standardmäßig 1 Monat beträgt. Daher müssen Sie den richtigen Aufbewahrungszeitraum kennen und festlegen.

Lassen Sie uns durch einzigartige Möglichkeiten gehen.

Thanos verfügt über eine Funktion wie das Downsampling: Intervalle von 5 Minuten und Stunden, die häufig nicht richtig funktionieren . Wenn Sie es googeln und sich das Problem auf Github ansehen, gibt es eine Menge Probleme im Zusammenhang mit diesem Downsampling, die manchmal nicht richtig funktionieren oder nicht so funktionieren, wie die Benutzer es erwarten.

Thanos verfügt über eine Datendeduplizierung für Prometheus HA-Paare. Wenn zwei Prometheus'a dieselben Metriken vom selben Ziel sammeln und Thanos sie in den Objektspeicher legt. Thanos , VictoriaMetrics.

Thanos alert , Thanos. production .

Thanos , Thanos Prometheus — . Thanos Prometheus . Thanos Prometheus .

VictoriaMetrics — MetricsQL. VictoriaMetrics PromQL, big monitoring metup.

VictoriaMetrics . VictoriaMetrics Prometheus, Influx, OpenTSDB Graphite.

VictoriaMetrics Thanos Prometheus.
, 2-5 Prometheus Thanos.

VictoriaMetrics — .

.

Thanos , object storage, .
object storage, ($10 ). object storage, , AWS — . , $10 $230 1. , Thanos .

Thanos Compact, Store Gateway, Query , , .

VictoriaMetrics . GCE HDD , $40 1. VictoriaMetrics HDD , SSD, . VictoriaMetrics HDD.

VictoriaMetrics benötigt Server für Komponenten: entweder Single-Nod- oder Cluster-Komponenten, die im Gegensatz zu Thanos-Komponenten viel weniger CPU und RAM benötigen - entsprechend günstiger.

Beispiele für die Implementierung.

Das Implementierungsbeispiel von Thanos ist Gitlab. Gitlab wird vollständig von Thanos unterstützt. Aber es ist nicht so glatt. Wenn Sie sich ihre Probleme ansehen, können Sie feststellen, dass sie ständig Probleme mit Thanos haben : Es ist nicht genügend Speicher für Store Gateway- oder Query-Komponenten vorhanden. Sie müssen ständig die Speicherkapazität erhöhen.
Aus diesem Grund steigen die Kosten zur Lösung dieser Probleme.
Die zweite Implementierung, die erfolgreicher sein könnte, ist das Unternehmen Improbable, das mit der Entwicklung von Thanos begonnen hat. Sie veröffentlichten die Quelle von Thanos. Unwahrscheinlich ist ein Unternehmen, das Game-Engines entwickelt.

Öffentliche Beispiele für die Implementierung von VictoriaMetrics sind:
- wix.com site builder
- Adidas stellt VictoriaMetrics vor und hat sogar auf der letzten PromCon 2019 eine Präsentation gehalten
- TrafficStars - Werbenetzwerk
- Seznam.cz ist eine beliebte tschechische Suchmaschine.
Und dann ging es zum Firmennamen, den ich jetzt nicht nennen kann. Sie stimmten nicht zu.
- Ein großer Spieleentwickler. Größer als sie Unwahrscheinlich.
- Ein bedeutender Grafik-Software-Entwickler.
- Große russische Bank.
- Europäischer Hersteller von Windkraftanlagen, der VictoriaMetrics erfolgreich getestet hat. Dieser Hersteller implementiert VictoriaMetrics, um Daten von Windkraftanlagen mit einer Geschwindigkeit von 50 Abtastwerten pro Sekunde und Sensor zu überwachen. Jede Windkraftanlage verfügt über mehrere hundert Sensoren. Sie haben mehrere hundert Windkraftanlagen.
- Russische Fluggesellschaften, die VictoriaMetrics einführen wollen, können dies aber immer noch nicht. Wir sind mit ihnen im Vertragsstadium.
 Schlussfolgerungen
Schlussfolgerungen
VictoriaMetrics und Thanos lösen ähnliche Probleme auf unterschiedliche Weise:
- Globale Abfrageansicht
- horizontale Skalierung
- willkürliche Aufbewahrung

Vielen Dank.
Auf unserem Telegrammkanal warten wir auf Sie.
