Hallo Habr! Datensätze für Big Data und maschinelles Lernen nehmen exponentiell zu und müssen verarbeitet werden. Unser Beitrag zu einer weiteren innovativen Technologie im Bereich High Performance Computing (HPC), die auf dem Stand von Kingston auf der
Supercomputing 2019 vorgestellt wurde . Dies ist die Anwendung von Hi-End-Speichersystemen (SHD) in Servern mit Grafikprozessoren (GPU) und GPUDirect-Speicherbustechnologie. Dank des direkten Datenaustauschs zwischen Speicher und GPUs unter Umgehung der CPU wird das Laden von Daten in GPU-Beschleuniger um eine Größenordnung beschleunigt, sodass Big Data-Anwendungen mit der maximalen Leistung ausgeführt werden, die die GPU bietet. Die Entwickler von HPC-Systemen sind wiederum an Fortschritten bei der Speicherung mit der höchsten E / A-Geschwindigkeit interessiert - beispielsweise an Kingston-Releases.

GPU-Leistung vor dem Laden von Daten
Seit der Schaffung von CUDA, einer GPU-basierten Hardware- und Software-Parallel-Computing-Architektur für die Entwicklung von Allzweckanwendungen, im Jahr 2007 sind die Hardwarefunktionen der GPUs selbst enorm gewachsen. Heute werden GPUs zunehmend in HPC-Anwendungen wie Big Data, maschinelles Lernen und Deep Learning eingesetzt.
Beachten Sie, dass trotz der Ähnlichkeit der Begriffe die letzten beiden algorithmisch unterschiedliche Aufgaben sind. ML lehrt einen Computer basierend auf strukturierten Daten, und DL lehrt einen Computer basierend auf der Antwort von einem neuronalen Netzwerk. Ein Beispiel, das hilft, die Unterschiede zu verstehen, ist recht einfach. Angenommen, ein Computer sollte Fotos von Katzen und Hunden unterscheiden, die aus dem Speicher geladen wurden. Für ML sollten Sie eine Reihe von Bildern mit vielen Tags einreichen, von denen jedes ein bestimmtes Merkmal des Tieres definiert. Für DL ist es ausreichend, eine viel größere Anzahl von Bildern hochzuladen, aber mit nur einem Tag "das ist eine Katze" oder "das ist ein Hund". DL ist der Art und Weise, wie kleine Kinder unterrichtet werden, sehr ähnlich - es werden ihnen lediglich Bilder von Hunden und Katzen in Büchern und im Leben gezeigt (meist ohne den detaillierten Unterschied zu erklären), und das Gehirn des Kindes beginnt nach einer bestimmten kritischen Anzahl von Bildern selbst, den Tiertyp zu bestimmen ( Schätzungen zufolge sprechen wir von einhundert oder zwei Impressionen für die gesamte Zeit der frühen Kindheit. DL-Algorithmen sind noch nicht so perfekt: Um erfolgreich an der Definition von Bildern eines neuronalen Netzwerks arbeiten zu können, müssen Millionen von Bildern in der GPU eingereicht und verarbeitet werden.
Das Ergebnis des Vorworts: Auf der Basis der GPU können Sie HPC-Anwendungen im Bereich Big Data, ML und DL erstellen. Es gibt jedoch ein Problem: Die Datenmengen sind so groß, dass die Zeit, die zum Laden der Daten vom Speichersystem auf die GPU benötigt wird, die Gesamtleistung der Anwendung verringert. Mit anderen Worten, schnelle GPUs bleiben aufgrund der langsamen Eingabe / Ausgabe von Daten aus anderen Subsystemen unterlastet. Der Unterschied in der Eingangs- / Ausgangsgeschwindigkeit der GPU und dem Bus zur CPU / SHD kann eine Größenordnung betragen.
Wie funktioniert die GPUDirect-Speichertechnologie?
Der Eingabe- / Ausgabeprozess wird von der CPU gesteuert sowie das Laden von Daten aus dem Speicher in die GPUs für die nachfolgende Verarbeitung. Aus diesem Grund wurde eine Technologie angefordert, die einen direkten Zugriff zwischen der GPU und den NVMe-Laufwerken für eine schnelle Interaktion untereinander ermöglicht. Die erste derartige Technologie wurde von NVIDIA vorgeschlagen und als GPUDirect Storage bezeichnet. Tatsächlich handelt es sich hierbei um eine Variante der zuvor entwickelten GPUDirect RDMA-Technologie (Remote Direct Memory Address).
 Jensen Huang, NVIDIA-CEO, stellt GPUDirect Storage als Variante von GPUDirect RDMA bei SC-19 vor. Quelle: NVIDIA
Jensen Huang, NVIDIA-CEO, stellt GPUDirect Storage als Variante von GPUDirect RDMA bei SC-19 vor. Quelle: NVIDIADer Unterschied zwischen GPUDirect RDMA und GPUDirect Storage besteht in Geräten, zwischen denen eine Adressierung durchgeführt wird. Die GPUDirect RDMA-Technologie wurde neu zugewiesen, um Daten direkt zwischen der Netzwerkschnittstellenkarte (NIC) und dem GPU-Speicher zu übertragen. GPUDirect Storage bietet einen direkten Datenübertragungspfad zwischen lokalem oder Remote-Speicher wie NVMe oder NVMe über Fabric (NVMe-oF) und GPU-Speicher.
Beide Optionen, GPUDirect RDMA und GPUDirect Storage, vermeiden unnötige Datenbewegungen durch einen Puffer im CPU-Speicher und ermöglichen es dem Direct Memory Access (DMA) -Mechanismus, Daten von einer Netzwerkkarte oder einem Speicher direkt zum oder vom GPU-Speicher zu übertragen - und das alles ohne Belastung der Zentrale Prozessor Für GPUDirect Storage spielt der Speicherort keine Rolle: Es kann sich um eine NVME-Festplatte in einer GPU-Einheit, in einem Rack oder über ein Netzwerk als NVMe-oF handeln.
 GPUDirect Storage-Betriebsschema. Quelle: NVIDIA
GPUDirect Storage-Betriebsschema. Quelle: NVIDIAIm HPC-Anwendungsmarkt erforderlicher NVMe-High-End-Speicher
Mit dem Aufkommen von GPUDirect Storage wird das Interesse von Großkunden geweckt, Speichersysteme mit einer der GPU-Bandbreite entsprechenden Eingabe- / Ausgabegeschwindigkeit anzubieten. Kingston zeigte ein Demosystem, das aus Speichersystemen auf Basis von NVMe-Festplatten und einer Einheit mit einer GPU bei SC-19 besteht die Tausende von Satellitenbildern pro Sekunde analysiert. Wir haben bereits
in einem Bericht von der Ausstellung der Supercomputer über einen solchen Speicher auf der Basis von 10 Laufwerken DC1000M U.2 NVMe geschrieben.
 Speicher basierend auf 10 Laufwerken DC1000M U.2 NVMe ergänzt den Server angemessen mit Grafikbeschleunigern. Quelle: Kingston
Speicher basierend auf 10 Laufwerken DC1000M U.2 NVMe ergänzt den Server angemessen mit Grafikbeschleunigern. Quelle: KingstonEin solcher Speicher wird in Form einer Rack-Einheit von 1U oder mehr ausgeführt und kann in Abhängigkeit von der Anzahl der DC1000M U.2 NVMe-Festplatten mit einer Kapazität von 3,84 bis 7,68 TB skaliert werden. Der DC1000M ist das erste NVMe-SSD-Modell im U.2-Formfaktor in der Kingston-Laufwerkslinie für Rechenzentren. Die Haltbarkeitsbewertung (DWPD, Laufwerk schreibt pro Tag) ermöglicht es Ihnen, einmal täglich Daten mit voller Kapazität zu überschreiben, um eine garantierte Lebensdauer des Laufwerks zu gewährleisten.
Im fio v3.13-Test auf dem Ubuntu-Betriebssystem 18.04.3 LTS, Linux-Kernel 5.0.0-31-generic, zeigte das Messespeichermodell eine Sustained Read-Geschwindigkeit von 5,8 Millionen IOPS bei einer anhaltenden Bandbreite von 23,8 Gb / s.
Ariel Perez, SSD Business Manager von Kingston, beschrieb die neuen Speichersysteme folgendermaßen: „Wir sind bereit, die nächste Generation von Servern mit U.2 NVMe-SSDs auszustatten, um viele der Datenübertragungsengpässe zu beheben, die traditionell mit Speicher verbunden sind. Die Kombination von NVMe-SSDs und unserem Premium Server Premier DRAM macht Kingston zu einem der umfassendsten Anbieter von End-to-End-Datenprozessoren in der Branche. “
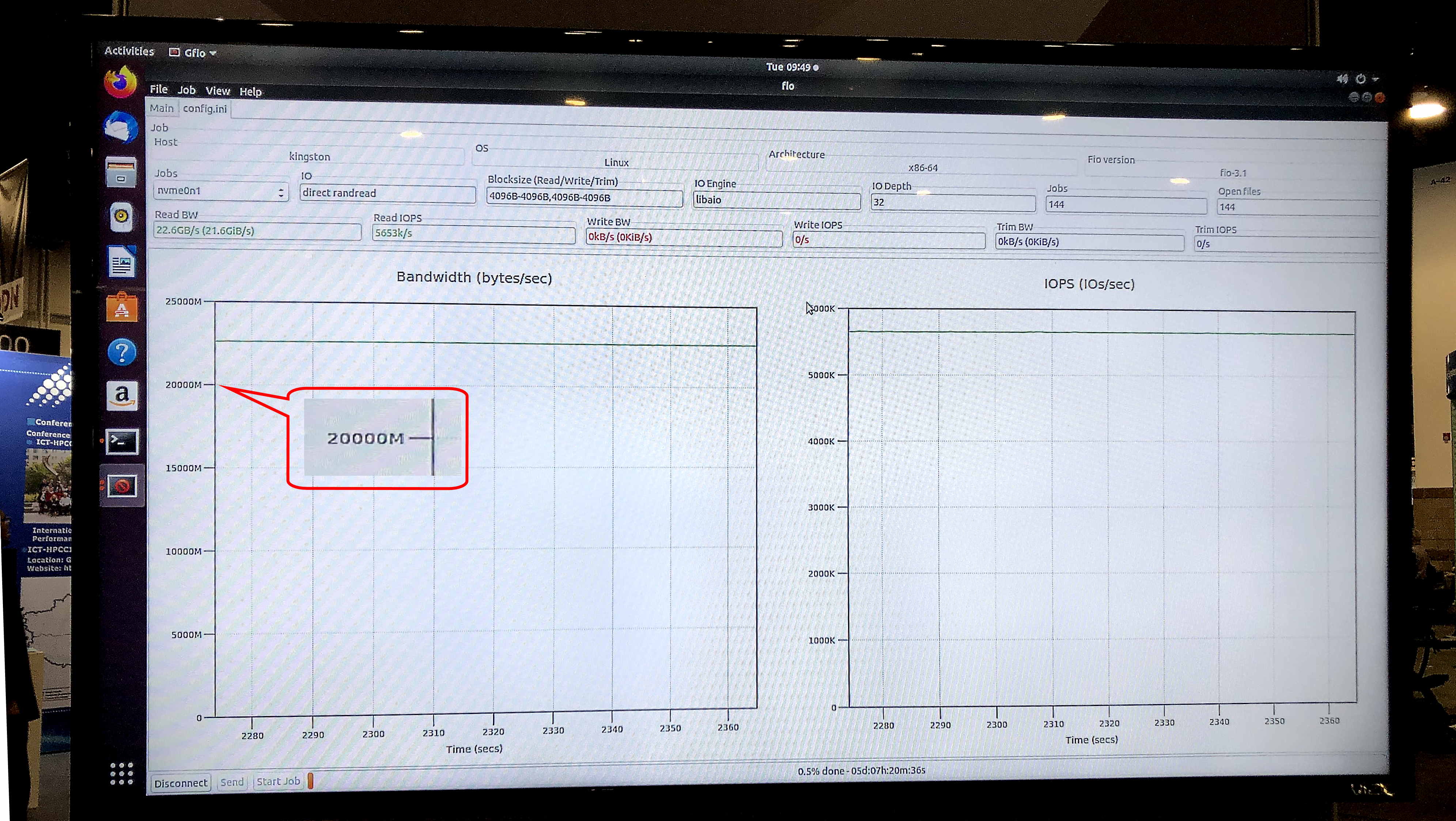 Der gfio v3.13-Test ergab eine Bandbreite von 23,8 Gbit / s für die Demo-Speicherung auf DC1000M U.2 NVMe-Laufwerken. Quelle: Kingston
Der gfio v3.13-Test ergab eine Bandbreite von 23,8 Gbit / s für die Demo-Speicherung auf DC1000M U.2 NVMe-Laufwerken. Quelle: KingstonWie sieht ein typisches System für HPC-Anwendungen aus, die GPUDirect-Speichertechnologie oder ähnliches verwenden? Hierbei handelt es sich um eine Architektur mit physischer Trennung von Funktionsblöcken innerhalb eines Racks: ein oder zwei Einheiten für RAM, einige weitere für GPU- und CPU-Rechenknoten und eine oder mehrere Einheiten für Speicher.
Mit der Ankündigung von GPUDirect Storage und dem möglichen Aufkommen ähnlicher Technologien bei anderen GPU-Anbietern erweitert Kingston seine Nachfrage nach Speichersystemen für den Einsatz im Hochleistungs-Computing. Der Marker ist die Lesegeschwindigkeit von Daten aus dem Speichersystem, vergleichbar mit der Bandbreite von 40- oder 100-Gbit-Netzwerkkarten am Eingang einer Rechnereinheit mit einer GPU. So werden ultraschnelle Speichersysteme, einschließlich externer NVMe durch Fabric, von exotic zum Mainstream für HPC-Anwendungen. Neben wissenschaftlichen und finanziellen Berechnungen werden sie auch in vielen anderen praktischen Bereichen Anwendung finden, beispielsweise in Sicherheitssystemen auf der Ebene der Großstadt Safe City oder in Überwachungszentren für den Verkehr, in denen die Erkennungs- und Erkennungsgeschwindigkeit auf der Ebene von Millionen von HD-Bildern pro Sekunde erforderlich ist “, die Marktnische an der Spitze SHD
Weitere Informationen zu Kingston-Produkten finden Sie auf
der offiziellen Website des Unternehmens.