Am 14. März 2017 sprach Arthur Khachuyan, CEO von Social Data Hub, im BBDO-Hörsaal. Arthur sprach über intelligente Überwachung, das Erstellen von Verhaltensmodellen, das Erkennen von Foto- und Videoinhalten sowie andere Tools und Studien des Social Data Hub, mit denen Sie Ihre Zielgruppe mithilfe von sozialen Netzwerken und Big Data-Technologien ansprechen können.
 Arthur Khachuyan (im Folgenden - AH):
Arthur Khachuyan (im Folgenden - AH): - Hallo! Hallo allerseits! Mein Name ist Arthur Khachuyan, ich leite das Social Data Hub-Unternehmen, und wir beschäftigen uns mit verschiedenen interessanten intellektuellen Analysen von offenen Datenquellen, Informationsfeldern und machen alle möglichen interessanten Studien und so weiter.
Und heute fragten Kollegen der BBDO-Gruppe nach modernen Technologien für die Analyse von Big Data, Big Data und nicht so vielen Daten für die Werbung: Wie sie verwendet werden, zeigen einige interessante Beispiele. Ich hoffe, Sie werden unterwegs Fragen stellen, da ich anfangen kann, mich zu ärgern und die Essenz nicht preiszugeben und so weiter. Seien Sie also nicht schüchtern.
Tatsächlich sind die Hauptbereiche, in denen jemals eine Art "fast big-digit" -Lösung angewendet wurde, alle klar: Zielgruppenansprache, Analyse, irgendeine Art von Analyse und Marktforschung. Es ist aber immer interessant, welche zusätzlichen Daten gefunden werden können, welche zusätzlichen Bedeutungen nach der Anwendung der Analyse gefunden werden können.
Warum brauchen wir Technologie für Werbung?
Wo fangen wir an? Am verständlichsten ist die Werbung in sozialen Netzwerken. Heute habe ich es am Morgen gedreht: Aus irgendeinem Grund glaubt Vkontakte, dass ich diese bestimmte Werbung sehen sollte ... Zum Guten oder Schlechten ist dies die zweite Frage. Wir sehen, dass ich mit Sicherheit in die Kategorie der Entwurfsempfänger falle:

Das allererste und interessanteste, was man als technologische Lösung betrachten kann ... Bevor wir anfangen, wollte ich zunächst die Begriffe definieren: Was sind offene Daten und was sind Big Data? Weil alle Menschen ein eigenes Verständnis für dieses Thema haben und ich meine Bedingungen niemandem aufzwingen möchte, aber ... Nur damit es keine Unstimmigkeiten gibt.
Persönlich denke ich, dass offene Daten alle Daten sind, die ich ohne Login oder Passwort erreichen kann. Dies ist ein offenes Profil in sozialen Netzwerken, dies sind Suchergebnisse, dies sind offene Register usw. Nach meinem eigenen Verständnis sind Big Data: Wenn es sich um eine Datenplatte handelt, sind es Milliarden Zeilen, wenn es sich um eine Art Dateispeicher handelt, handelt es sich um Daten irgendwo Petabyte an Daten. Der Rest in meiner Terminologie ist nicht Big Data, sondern etwas in der Nähe.
Hochpräzise Profile und Bewertungsprofile
Gehen wir in Ordnung. Das erste und interessanteste, was Sie aus einer Analyse offener Datenquellen ableiten können, ist das hochpräzise Profilieren und Bewerten von Profilen. Was ist das? Dies ist eine Geschichte, in der Sie nicht nur vorhersagen können, wer Sie sind, sondern auch Ihre Interessen in Ihrem sozialen Netzwerkkonto.
Wenn Sie nun verschiedene Quellen kombinieren, können Sie die durchschnittliche Höhe Ihres Gehalts, die Höhe Ihrer Wohnung und den Standort Ihrer Wohnung nachvollziehen. Und all diese Daten können buchstäblich mit improvisierten Mitteln verwendet werden. Wenn Sie beispielsweise Ihr Konto in einem sozialen Netzwerk einrichten, sehen Sie beispielsweise, wo Sie wohnen und arbeiten. Verstehen Sie, in welchem Geschäftsbereich sich das Unternehmen befindet, in dem Sie arbeiten. Entladen Sie ähnliche Stellenangebote von HH und SuperJob, wenn Sie Analyst, Manager usw. sind. Sehen Sie, wo Sie wohnen (Basis, sagen Sie CIAN), verstehen Sie, wie viel es kostet, ein Haus an diesem Ort zu mieten, wie viel es kostet, ein Haus an diesem Ort zu kaufen, um vorherzusagen, wie viel Sie verdienen. Weiter in Ihren sozialen Netzwerken können Sie nachvollziehen, wie viel Sie reisen, wo Sie sind, wie loyal Sie dem Arbeitgeber gegenüber sind.
Dementsprechend können wir aus einer solch großen Anzahl von Metriken alles machen. Wir können Ihnen ein Produkt vorstellen, das Sie interessiert. Stellen Sie sich einen Online-Shop vor? Sie gehen dorthin - dieser Online-Shop fängt Ihr Konto im sozialen Netzwerk auf und sagt Ihnen: "Mascha, Sie haben gerade Schluss gemacht mit einem Mann, hier haben Sie bestimmte, bestimmte Produkte." Dies ist nicht die nahe Zukunft ...
Wie bestimme ich die Geolokalisierung einer Person?
Antworten auf Fragen des Publikums:- Normalerweise werden 80% aller Check-Ins als exakter Wohnort angesehen. Aber für Leute, die nirgendwo einchecken, gibt es verschiedene Möglichkeiten: entweder einen Check-in oder eine Geoposition oder eine Analyse von Beiträgen und Veröffentlichungen für den gesamten Zeitraum, in dem etwas von einer Person geschrieben wurde ... Und irgendwo sollte etwas auftauchen wie "Ich möchte einen Kinderwagen in der Nähe des Akademikers kaufen" oder "Ich habe hier kürzlich hässliche Graffiti an der Wand gesehen." Das heißt, fast 80% der Menschen können ihren Standort, ihren Arbeitsplatz und ihren Wohnort anhand von Daten oder Metadaten bestimmen, die in sozialen Netzwerken gesammelt werden können.
Dies ist wiederum eine Analyse der Beiträge. Im einfachsten Sinne handelt es sich um eine Analyse von Eincheckvorgängen und Geolokalisierungen in sozialen Netzwerken, bei denen JPEG-Metadaten nicht gelöscht werden (Sie können etwas darauf analysieren). Bei den übrigen Personen handelt es sich in der Regel um Textsendungen: Entweder "leuchtet" eine Person ihren Standort, wenn sie über etwas schreibt, oder sie "leuchtet" ihr Telefon, auf dem Sie einige seiner Anzeigen auf Avito oder auf seinem Konto finden "Auto.ru". Nach diesen Daten können Sie kombinieren (zum Beispiel "Ich verkaufe ein Auto in der Nähe von Mayakovskaya") und dies grob annehmen. - Normalerweise posten Leute dies in sozialen Netzwerken. Wir arbeiten nur mit Open Source und hier geht es ausschließlich um Open Source. Normalerweise werden Anzeigen veröffentlicht, das heißt, 60 Prozent der Fälle, in denen die Leute ihre aktuelle Handynummer „leuchten“ - dies sind Anzeigen für den Verkauf von etwas. Entweder schreibt jemand in einigen Gruppen („Ich verkaufe das oder das dort), oder er geht irgendwohin.
Ja Normalerweise kommentieren sie: „Antworte mir oder wirf eine SMS, ruf mich unter der Nummer an. Dies passiert sehr oft bei Leuten, die etwas verkaufen, in sozialen Netzwerken einkaufen, mit jemandem kommunizieren ... Entsprechend können Sie über diese Nummer sein Profil an ihn im Cyan Institute binden, wenn er einmal etwas veröffentlicht hat, oder wieder auf Avito. Dies sind einfach die beliebtesten und beliebtesten Quellen - das sind Avito, CIAN und so weiter. - Dies bezieht sich auf einen Online-Shop. Als Nächstes folgen die Gesichtserkennung und die Profilerkennungstechnologie (wir werden darüber sprechen). Theoretisch kann dies auch auf einen Offline-Speicher angewendet werden. Und im Allgemeinen ist mein großer Traum, dass wenn Straßenbanner auftauchen, wenn Sie an der Kamera vorbeigehen, sie Ihr Gesicht „streifen“. Dieser Fall wird jedoch gesetzlich verboten, da er eine Verletzung der Privatsphäre darstellt. Ich hoffe, dass es früher oder später sein wird.
- Ich habe aus eigener Erfahrung. Sehr oft, wenn eine Person Ihnen etwas schreibt, operieren Sie mit einigen Fakten aus seinem Leben, die Sie nicht kennen sollten ... In den meisten Fällen haben die Menschen Angst. Aber! Basierend auf jüngsten Statistiken ist die Anzahl der geschlossenen Konten in sozialen Netzwerken um 14% gesunken. Die Anzahl der Fälschungen steigt, die Anzahl der offenen Konten steigt - die Menschen bewegen sich zunehmend in Richtung Offenheit. Ich denke, dass sie nach 3-4 Jahren aufhören werden, so scharf auf die Tatsache zu reagieren, dass jemand Informationen über sie kennt, die er möglicherweise nicht wissen sollte. Tatsächlich ist es jedoch sehr einfach, die Wand zu betrachten.
Was kann aus offenen Quellen entnommen werden?
Eine ungefähre Liste von Dingen, die mit relativ hoher Zuverlässigkeit von Open Source verstanden werden können - das ist es. Tatsächlich gibt es noch mehr verschiedene Metriken. es hängt vom Kunden solcher Forschung ab. Es gibt eine Personalagentur, die daran interessiert ist, ob Sie in sozialen Netzwerken oder irgendwo im öffentlichen Raum schwören. Jemand interessiert sich dafür, ob Sie unter den Veröffentlichungen von Navalny oder umgekehrt unter den Veröffentlichungen von United Russia oder unter irgendwelchen pornografischen Inhalten Gefallen finden - solche Dinge passieren ziemlich oft.
Die wichtigsten sind die Familienwerte, die ungefähren Kosten für eine Wohnung, eine Wohnung, eine Autosuche usw. Aus diesem Grund können Menschen in soziale Gruppen eingeteilt werden. Dies sind die Nutzer des Moskauer „Zunders“, wer sie sind (gemäß ihren Bildern, die auf ihren Facebook-Konten zu finden sind); Aufgrund ihrer Interessen werden sie in verschiedene soziale Gruppen eingeteilt:

Wenn wir uns der Werbung nähern, haben wir die Standardausrichtung der Werbung schrittweise verlassen, wenn Sie in der bedingten Vkontakte auswählen, dass Sie an Männern im Alter von 18 Jahren interessiert sind, die bestimmte Gruppen abonniert haben. Ich habe so ein Bild weiter, jetzt zeige ich dir:

Das Fazit ist, dass die meisten der aktuellen Dienste, die im Prinzip Menschen analysieren, die soziale Netzwerke analysieren, an der Analyse von Interessen interessiert sind. Das erste, was den Menschen einfällt, ist die Analyse der Top-Gruppen ihrer Abonnenten. Vielleicht funktioniert das mit jemandem, aber ich persönlich denke, dass dies grundlegend falsch ist. Warum?
Ihre Vorlieben sammeln und analysieren
Nehmen Sie jetzt Ihre Telefone, schauen Sie sich Ihre Top-Gruppen an - es wird sicherlich mehr als 50% der Gruppen geben, die Sie bereits vergessen haben. Dies ist eine Art von Inhalt, der für Sie eigentlich irrelevant ist. Sie verbrauchen es überhaupt nicht, aber das System wird Sie trotzdem danach strecken: dass Sie Rezepte abonniert haben, einige populäre Gruppen. Das heißt, Sie verletzen das System, das Ihr Profil analysiert, und Ihre Interessen werden nicht gerechtfertigt.
Weitermachen ... Was ist da? Wir gehen davon aus, dass es dem Rest der Leute gut geht. Nach unserer Meinung ist Likes die beste Methode, um die Interessen der Benutzer einzuschätzen. Zum Beispiel gibt es in Vkontakte kein Like-Feed und die Leute glauben, dass niemand weiß, was sie mögen. Ja, ein Teil der Likes wurde auf Instagram vorgestellt, wir sehen etwas auf Facebook, aber die meisten Inhalte in bestimmten Gruppen strahlen dies nicht in einem gemeinsamen Stream aus, und die Leute leben und glauben, dass niemand weiß, was sie mögen.
Und indem wir bestimmte Inhalte von Inhalten sammeln, die uns interessieren, diese Posts sammeln, diese Likes sammeln und dann diese Person aus dieser Datenbank überprüfen, können wir mit hoher Genauigkeit feststellen, wer er ist, was sein Schicksal ist, woran er interessiert ist. Identifizieren Sie sich genau in einer bestimmten sozialen Gruppe und interagieren Sie mit ihr.
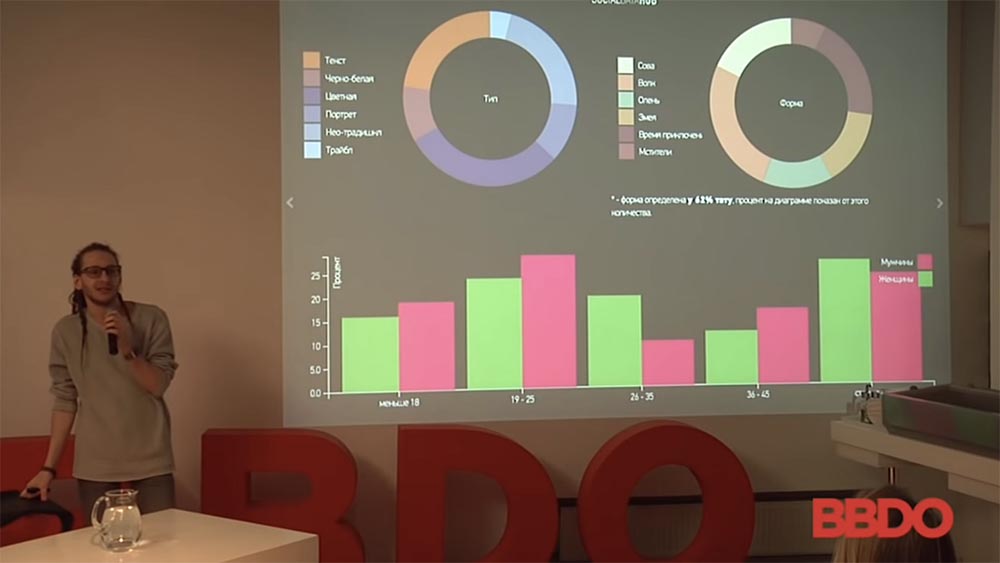
Der Kauf eines Autos verändert das Verhalten
Ich habe so ein Beispiel. Ich werde sofort eine Reservierung vornehmen, für die ich Beispiele für Near Advertising und Near Marketing habe, da, wie Sie wissen, die meisten Fälle durch die NDA geschützt sind und so weiter. Trotzdem wird es viele interessante Dinge geben. Also, die Geschichte mit diesen Leuten: Das sind Männer, die zwischen 2010 und 2015 ein Auto gekauft haben. Wie sich ihr soziales Verhalten im Netzwerk geändert hat, ist farblich gekennzeichnet. Der Prozentsatz der Mädchen in den Abonnenten hat sich geändert, der "patsansky" Öffentlichkeit abonniert, einen ständigen Sexualpartner gefunden ...

Diese ganze Sache ist nach Automarken und nach der Anzahl der Personen aufgeschlüsselt. Von hier aus können Sie viele interessante Rückschlüsse auf das Verhalten der Menschen ziehen, wie das alles funktioniert. Ich kann sagen, dass der "Porsche Cayenne" und der "Priora" in Bezug auf die Anzahl der anziehenden Zuschauer fast gleich sind. Die Qualität dieses Publikums, ihr Verhalten ist unterschiedlich, aber die Menge ist ungefähr gleich. Die Schlussfolgerung von hier aus kann, je nachdem, näher an Ihrem Markt gemacht werden. Sie verkaufen Audi, Sie machen den Slogan "Kaufen Sie Audi, fahren Sie von Ihren Eltern weg!" Und so weiter.
Dies ist ein lächerliches Beispiel für die Tatsache, dass das Verhalten von Menschen basierend auf einer Likes-Analyse, basierend auf der Gruppe, zu der sie gehen, und dem Inhalt, den sie analysieren, es fast zu 100% wahrscheinlich macht, wer Sie sind. Denn wenn Sie keinen Zugang zum Netzwerkverkehr haben, keine privaten Nachrichten lesen, sagt Ihnen Likes immer, wer diese Person ist - eine schwangere Frau, Mutter, Militär, Polizistin. Und für Sie, wie für eine Person, die Werbung schalten kann, ist dies ein großer Treffer für das Ziel.
Antworten auf Publikumsfragen:- Jede Spalte gibt die Anzahl der Personen in einem bestimmten Auto an. wie sich das Muster ihres Verhaltens geändert hat. Schauen Sie: Menschen, die Porsche Cayenne gekauft haben - etwa 550 Menschen (gelb), der Anteil der Mädchen in Abonnenten hat zugenommen.
- Die Stichprobe umfasst Nutzer der sozialen Netzwerke VKontakte, Facebook und Instagram von 2010 bis 2015. Einzige Klarstellung: Es handelt sich um ausgewählte Maschinen, die mit bestimmten Werkzeugen mit mehr als 80% iger Genauigkeit auf Fotos ermittelt werden können.
- Für eine gewisse Zeit hat sein Auto (also nicht sein, wir überlassen es den sozialen Netzwerken) ... Für eine gewisse Zeit hat eine Person ständig Bilder mit einem Auto gemacht, war mit ihm zusammen, die Veröffentlichungen waren unterschiedlich, die Fotos waren aus verschiedenen Blickwinkeln und so weiter . Es wird weiter ein Bild geben, welche Menschen mit welchen Maschinen fotografiert werden und ... Ja, das ist die zweite Frage - Vertrauen in die Daten sozialer Netzwerke.
- Da wir es erhoben haben - leider sind die Daten in den sozialen Netzwerken nicht immer korrekt. Menschen sind nicht immer geneigt, ihre Informationen zu veröffentlichen. Persönlich habe ich eine solche Studie durchgeführt: Ich habe die Anzahl der Absolventen der Moskauer Universitäten mit der Anzahl der in sozialen Netzwerken registrierten Personen verglichen. Durchschnittlich 60% mehr Menschen sind in sozialen Netzwerken registriert - MSU-Absolventen für ein bestimmtes Jahr in bestimmten Fachgebieten, als sie im Prinzip tatsächlich existieren. Also ja - hier gibt es natürlich einen Prozentsatz an Fehlern und niemand verbirgt sie. Hierbei werden einfach diejenigen Autos zugrunde gelegt, die mit einer Wahrscheinlichkeit von mehr als 80% ermittelt werden können.
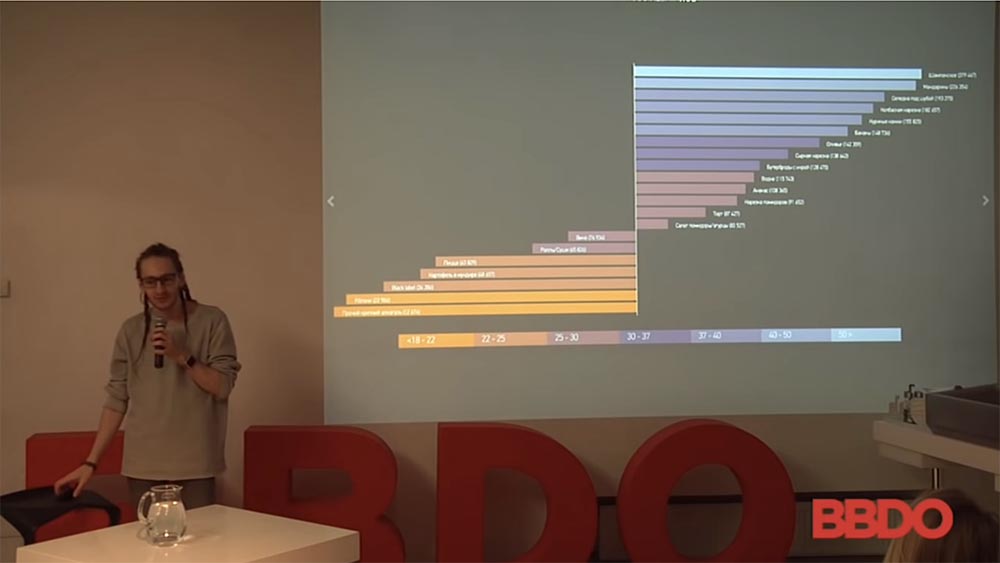
Quellenverzeichnis für das Modelltraining
Hier ist ein Beispiel einer Liste von Quellen, die verwendet werden können, um mit großer Sicherheit das soziale Profil einer Person zu bestimmen, wer sie ist.

Aus sozialen Netzwerken nehmen wir ein Profil, aus CIAN - die Kosten für eine Wohnung betragen ungefähr "Head Hunter", "Super Job" - dies ist das Durchschnittsgehalt für diese Person. Ich hoffe, dass es hier keine Head Hunter-Vertreter gibt, da sie der Meinung sind, dass es nicht sehr gut ist, diese Daten von ihnen zu übernehmen. Dies ist jedoch der Durchschnittslohn für bestimmte Regionen für bestimmte Arten von beruflichen Tätigkeiten.
Avito, Avto.ru: Sehr oft haben Menschen, wenn sie ihr Telefon anzünden, (in vielen Fällen) zumindest etwas auf Avito, Avto.ru oder sogar Mehrere Websites, auf denen Sie nachvollziehen können, wer sie sind. Wenn Sie einen Kinderwagen oder ein Auto über dieses Telefon verkauft haben ... Rosstat und die USRLE sind immer noch weitere Register, mit denen Sie die Arbeitgeberfirma nach einer Formel, nach einem Modell, das jeder fragen kann, einstufen können (Sie können das Geld dieser Person grob bestimmen) usw.).
"Zunder" hilft, Daten über die Situation von Menschen zu sammeln
Außerdem gibt es so eine interessante Sache (als Option, sehr lustig in der Studie) - dies ist wiederum das Sammeln von Daten aus dem Moskauer Zunder unter Verwendung von Bots für diesen Zunder. Die Entfernung zu Personen wurde bestimmt, und dann wurde ihre ungefähre Position bestimmt.

Das Ziel dieser Studie war es, die Anzahl der Zunder-Konten auf dem Territorium staatlicher Institutionen zu bestimmen - in der Duma, der Staatsanwaltschaft und so weiter. Aber Sie als Werbetreibender können sich alles vorstellen: Es kann zum Beispiel Starbucks oder jemand anderes sein ... Das heißt, die Anzahl der Personen mit demselben Zunder, die bei Ihnen Kaffee trinken, etwas bestellen, sind in speichert. In Bezug auf diese Geolokalisierung: Dies kann mit jedem Dienst durchgeführt werden.
Die Antwort auf eine Frage des Publikums:- Zunder? Sie wissen nicht? "Zunder" ist eine solche Datierungsanwendung, bei der Sie Fotos (von links nach rechts) anzeigen und diese Anwendung zeigt Ihnen die Entfernung zu einer Person. Wenn Sie die Entfernung zu dieser Person von drei verschiedenen Punkten aus ermitteln, können Sie den Standort ungefähr (+ 5-7 Meter) bestimmen. In diesem Fall ist es nicht so schwierig, das Territorium der Staatsanwaltschaft oder der Staatsduma zu bestimmen. Aber es könnte auch Ihr Geschäft sein, es könnte alles sein.
Zum Beispiel hatten wir einen solchen Fall (keine Forschung) für eine lange Zeit, als wir Daten von einem der Mobilfunkbetreiber über die Flussdichte, Daten über die Bewegungsdichte von Mobilfunkpunkten erhielten und all diese Informationen den Koordinaten der Werbetafeln auf den Autobahnen überlagert wurden . Und die Aufgabe des Mobilfunkbetreibers ist es, zu bestimmen, wie ungefähr eine Anzahl von Personen durchfahren und möglicherweise diese Plakatwerbung sehen kann.
Wenn es Spezialisten für Plakatwerbung gibt, kann man sagen: Es ist unmöglich, supersicher zu verstehen - jemand reist, jemand hat nicht geschaut, jemand hat geschaut ... Trotzdem ist dies ein Beispiel dafür, wie 20 Milliarden solcher Polygone in Moskau sind Womit sich diese Personen auf bestimmten Strecken stündlich verdichten ... Sie können jederzeit sehen, an was diese Personen vorbeigefahren sind, und den Passagierfluss ungefähr schätzen.
Die Antwort auf eine Frage des Publikums:- Niemand gibt solche Daten. Wir haben eine solche Studie für einen der Betreiber durchgeführt, dies ist eine ausschließlich interne Geschichte, daher wird sie leider nicht in Form von Bildern präsentiert. Aber oft haben große Werbeagenturen keine Probleme, mit dem Betreiber in Kontakt zu treten. Zumindest in Moskau gibt es viele Präzedenzfälle, in denen sich Versicherungsunternehmen beispielsweise an Unternehmen wie GetTaxi wenden, die anonymisierte Daten darüber bereitstellen, wie alt der Fahrer ist, wie er fährt (gut - schlecht, rücksichtslos - nein) Richtlinien und so weiter zu prognostizieren. Jeder kämpft damit, aber auf einer internen Ebene, um anonyme Daten zu geben - ich denke, dass niemand ein solches Problem hat.
Erkennen von Bildern und Bildern
Lass uns weitermachen. Mein Favorit ist die Bilderkennung. Es wird ein kleines Stück über das Finden von Menschen anhand von Gesichtern geben, aber wir nehmen meistens nicht an diesem Teil teil. Wir nehmen die Mustererkennung und Definitionen, die in diesem Bild die Marke des Autos, seine Farbe und so weiter ist.

:

. , , , . , ( ).
. , , , – - BMW X6, , , , . , .

: , ; – . : , - - ( ).

( ): . , , -, : . , - ( «») , , - . .
. , , . , .
:- – . . , , … , . Tschüss. , , - … . , . , . , - .
, , , ( ), – , .
, . , . – :
. , , . , , , : , . , , , . , - - .
. , , . , . , . .
:

, - , , . , , -, , , , , .
: , , , , ( ) , ; , , , . , . , , , .


: . , , , – , , .

– . , , , . , . , , . . , , - , - .
. - , . – , – , .

, , , , , … , , , … , :

. . , / – , Transparency International, « », . – , , « ».
, ( ), . , , . , , - . ( , ), - , , , - - – .
. : BBDO Group, . , , , …

, . , - , – , .
– , . – ; , , - . – (, ); , , , , . – , .
,
– , : , - , -, . , , , , , (, ).
– , , -, , - , , - «. » , . , , , .
, , – , . , , , ( , ). , – . , «».
– , , ; - . , «» , . , – . :

– ( ). , . – , – , . . , , , , . , . -, «» , - .
.
( , ) . , . , , . :

: « » , . , , . , «», , : , , « – », , , , . , , , - , . !
, . ! , , -. , ; ( ) , . ! …
, , , . . , . , , - , - , .
, , . .

. . … , , , , – «, 37% , – , – « ! !» : , .
, … , , , - , - - . - . - .
( , 10 ), , , , , . « », « » .
«», -
: , «» .

: , , , 2%, – « ». , – , - . , – , . , , , - .
. , ?

- , , , , . , -, , – . . , , … – ! , . , , .
:Big Data
Tatsächlich habe ich viele verschiedene interessante politische Beispiele zu Trump und zu allen anderen, aber ich habe beschlossen, sie nicht hierher zu bringen. Aber es gibt ein politisches Beispiel.
Dies ist eine Wahl in die Staatsduma. Wann warst du Letztes Jahr? Vor fast anderthalb Jahren.

Hier sind Leute, die es geschafft haben, ihren genauen Standort bis zu einem bestimmten geografischen Punkt zu bestimmen, um zu verstehen, in welcher selektiven PEC sie sich befinden. Und dann wurden nur diejenigen, die ihre definitive Meinung äußerten, von diesen Leuten genommen, für die sie zur Abstimmung gehen würden.
Aus Sicht der politischen Technologien ist dies nicht sehr richtig, da das Ganze auf die Bevölkerungsdichte usw. normalisiert werden muss. Trotzdem, der Blues wird hier wählen, Sie wissen, für wen, die roten sind für die Oppositionsgenossen, die übrigens nicht so viele waren.
Ich persönlich denke, dass Big Data die politischen Technologien nicht sehr bald erreichen wird, aber als Option ist der Kandidat auch eine Marke. In gewissem Umfang handelt es sich dabei auch um eine Analyse von Fakten und Meinungen zu Ihrer Marke, und dies ist eine interessante Sache, da Sie in Echtzeit verstehen können, wer was tut. Ich kenne jetzt mehrere Fälle von der BBC, in denen sie soziale Netzwerke in Echtzeit in einer Art Sendung überwacht haben: Die Antwort ist so und so, die Leute schreiben darüber, stellen so und so eine Frage - und es ist cool! Ich denke, es wird sehr bald angewendet, weil es für alle interessant ist.
Modellierung von Markenpositionen

Als nächstes habe ich die Positionen von Marken modelliert. Eine kleine, kurze Sache darüber, wie Sie mit verschiedenen Metriken (nicht wie Abonnenten in sozialen Netzwerken, aber mit komplexen Metriken, Interesse an Inhalten, Zeitaufwand für das Abrufen von Metriken) Marken bewerten können.

Ich habe ein Beispiel für einen „Bauernhof“ für einen bestimmten. Hier sind kleine runde Kreise intern, hell - dies ist die Menge an Textinhalten, die die Marke erstellt, große runde Kreise - dies ist die Menge an Foto- und Videoinhalten, die die Marke erstellt.
Die Nähe zum Zentrum zeigt, wie interessant diese Inhalte für das Publikum sind. Es gibt ein großes Modell, es gibt viele verschiedene Parameter: Likes, Reposts, Antwortzeiten, die dort im Durchschnitt geteilt wurden ... Hier sehen Sie: Es gibt ein wundervolles „Kagocel“, das viel Geld für die Erstellung eigener Inhalte verdient, und aufgrund dessen sind sie ziemlich nahe beieinander in die Mitte. Und es gibt Genossen, die auch ihre Inhalte erstellen, aber es ist für das Publikum nicht interessant. Dies ist kein sehr angemessenes Beispiel, da all diese Konten fast tot sind.
Yegor Creed liebt mehr als Basta

Leider ist der Rest ... von was zu zeigen ... Hier gibt es noch russische Rapper, als Option, von echten Firmen.
Was ist das Plus? Die Tatsache, dass ein Unternehmen fast alles in ein solches Modell einbauen kann, beginnend mit dem Durchschnittsgehalt der Abonnenten Ihrer Marke. jedes Modell, das sie mögen. Da jede Werbeagentur ihre eigenen Kennzahlen unterschiedlich betrachtet, betrachten Marken ihre eigenen Kennzahlen unterschiedlich.
Es gibt hier auch eine - Basta, die eine große Menge an Inhalten generiert, sich aber an der Peripherie befindet, weil diese Inhalte für das Publikum anscheinend nicht sehr interessant sind. Auch hier vermute ich nicht zu urteilen. Trotzdem gibt es Yegor Creed, der laut sozialen Netzwerken fast der beste Performer unserer Zeit ist und gleichzeitig nur seine persönlichen Fotos veröffentlicht. Trotzdem hat er eine große Anzahl von Abonnenten: Es gibt ungefähr eine Million von ihnen. Ich erinnere mich nicht an den genauen Betrag. Ich erinnere mich, dass der Prozentsatz der Beteiligung dieser Leute viel höher als 85% ist, dh für eine Million Abonnenten erhält er 850.000 Antworten von diesen echten Leuten - das ist echter Wahnsinn. Ist das so.
 Antworten auf Publikumsfragen:
Antworten auf Publikumsfragen:Wie lange hat es gedauert, ein Rapper-Analysemodell zu erstellen?
- Jedes hat seine eigene Zielgruppe, seine Interessen, diese Personen werden gezählt ... All dies ist auf eine Entfernung zum Zentrum ungefähr normalisiert, ihre radiale Position ist nicht wichtig (es ist hier nur aus Schönheitsgründen verschmiert, damit sie nicht ineinander laufen). Wichtig ist nur die ungefähre Nähe zum Zentrum. Dies ist das Modell, das wir verwenden. Zum Beispiel mag ich den Kreis mehr, jemand tut es im Sinn eines Halbkreises.
- Dieses Modell wurde schnell erstellt, in zwei Stunden, in drei (ja, eine Person). Hier wurden ausschließlich Metriken eingefügt: Was wir multiplizieren, addieren, dann irgendwie normalisieren. Kommt auf das Modell an. Es gibt Leute, die am Durchschnittsgehalt (das ist kein Scherz) ihrer Abonnenten interessiert sind. Und dafür müssen Sie ihre Kontakte finden, "Avito", all dies zu berechnen, multiplizieren. Es passiert, es dauert lange, aber genau genommen (verweist auf die vorherige Folie) - hier sind sehr einfache Parameter: Abonnenten, Umbuchungen und so weiter. Es dauerte ungefähr zwei bis drei Stunden. Dementsprechend wird dieses Ding dann in Echtzeit aktualisiert, es kann verwendet werden.
Nun der lustige Teil. Ich habe alles mit Beispielen, weil es nicht interessant ist, lange alleine zu reden. Und ich hoffe, dass Sie jetzt Fragen stellen und wir von Thema zu Thema voranschreiten, denn ich habe Beispiele dafür, wie Technologien eingesetzt werden können und so weiter ...
Antworten auf Publikumsfragen:- Ich hatte einen sozusagen einzigen persönlichen Fall mit einem, okolokazino, als die Kamera dort platziert wurde, wurden Gesichter erkannt und so weiter. Der Prozentsatz an anerkannten Personen ist definitiv ziemlich hoch - was wir haben, was unsere Konkurrenten haben. Aber eigentlich ist es interessant genug. Ich sehe das als eine interessante Sache: Sie können verstehen, wer diese Leute sind und recht gut vorhersagen, warum sie hierher gekommen sind, was sich in ihrem Leben verändert hat, dass sie beschlossen haben, ins Casino zu kommen. Aber über bestimmte Geschäftsarten ... Wenn Sie so etwas in eine Apotheke stecken, macht es keinen Sinn - Sie können nicht vorhersagen, warum eine Person in eine Apotheke kam.
Die globale Aufgabe bestand darin, ein Modell zu erstellen, um zu verstehen, wann eine Person möglicherweise Ihre Marke interessieren möchte, um ihr eine Werbung zu geben, nicht nachdem sie etwas gekauft hat (wie es derzeit geschieht), sondern um ihr eine Werbung „in der Prognose“ zu geben. von wann alles passiert. Mit so einem "Okolokazino" war es interessant; Dort stellte sich ein ziemlich interessanter Prozentsatz dieser Leute heraus - warum: jemand bekam plötzlich eine Gehaltserhöhung, jemand anderes etwas - so interessante Einsichten. Aber mit einigen Geschäften, mit Einzelhandelsgeschäften, mit einigen Pillengeschäften, scheint es mir, dass es nicht sehr richtig sein wird.
Wird Big Data offline verwendet?
- Es war offline. Sie müssen nur ungefähr genau verstehen - dieses Modell wird konvergieren, nicht konvergieren. Wiederum mit Sodawasser ... Ich interessiere mich eigentlich für alles, aber ich persönlich verstehe nicht, wie sehr das Profil dieser Menschen von ihrem Verhalten abhängt, wann sie Wasser in Flaschen kaufen möchten. Obwohl dies wahr sein mag, weiß ich es nicht.
Wie viele offene Konten in sozialen Netzwerken?
- Wir haben speziell 11 soziale Netzwerke - das sind Vkontakte, Facebook, Twitter, Odnoklassniki, Instagram und einige Kleinigkeiten dort (ich kann die Liste sehen, wie Mail.ru und so weiter). "Vkontakte" wir haben definitiv eine Kopie von all diesen Kameraden. Wir haben Vkontakte - das sind 430 Millionen von allem, was jemals existiert hat (von denen ungefähr 200 Millionen ständig aktiv sind); es gibt gruppen, es gibt verbindungen zwischen diesen menschen und es gibt inhalte, die uns interessieren (text) und einen teil der medien, aber sehr klein ... grob gesagt schauen wir uns dieses bild an: wenn es gesichter gibt, speichern wir sie, wenn das memes von uns verwendet wird Wir sparen nicht, denn selbst bei uns würde nichts ausreichen, um den Medieninhalt zu bewahren.
Es gibt ein russischsprachiges Facebook. Irgendwo sind jetzt 60-80% Odnoklassniki, in ein paar Monaten werden wir sie wahrscheinlich alle bis zum Ende bekommen. Russisches "Instagram". Für all diese sozialen Netzwerke gibt es Gruppen, Menschen, Verbindungen zwischen ihnen und dem Text. - Über 400 Millionen Menschen. Es gibt eine Feinheit: Es gibt Menschen, die keine Stadt haben (sie sind möglicherweise russisch / nicht russisch). Davon im Durchschnitt in sozialen Netzwerken, hier - auf Vkontakte - 14% der geschlossenen Konten. Ich kenne die genaue Anzahl auf Facebook nicht.
- Auf Instagram speichern wir auch keine Medien - nur wenn es dort Gesichter gibt. Wir speichern solche (anderen) Medieninhalte nicht. Normalerweise interessant: nur Text, Kommunikation zwischen Menschen; das ist alles Die häufigste Instagram-Recherche ist die übliche Recherche des Publikums: Wer diese Personen sind, ist hier wie das Wichtigste die Verbindung dieser Personen mit anderen sozialen Netzwerken. Finden Sie das Profil dieser Person in Vkontakte und Facebook, um ihr Alter zu berechnen und so weiter.
- Bisher müssen nicht alle anderen mitgenommen werden - einfach, weil es keine Kunden gibt. In Bezug auf die Sprache: Wir haben Russisch, Englisch, Spanisch, aber es wird bisher ausschließlich für Marken aus Russland verwendet; na ja, oder Firmen, die sie aus Russland führen.
- Jeden Tag befragen wir Menschen in vielen, vielen, vielen Abläufen: Wir sammeln Daten durch das Sammeln des Webs und aktualisieren diese Indikatoren mithilfe von API. In 2-3 Tagen können Sie die gesamte Vkontakte durchgehen, nachdem Sie sie gescannt haben. Irgendwann in einer Woche können Sie durch die gesamte Facebook gehen und feststellen, wer dort aktualisiert hat, was nicht. Und dann sollten diese Leute getrennt wieder zusammengesetzt werden: Was genau hat sich geändert, um diese ganze Geschichte aufzuschreiben. In meiner Erinnerung ist es sehr selten, dass eine echte Geschäftsaufgabe das alte Profil einer Person in sozialen Netzwerken verwendet. Dies war die Zeit, in der sich ein Politiker näherte und seine Aufgabe darin bestand, zu verstehen, welche Art von Personen vor 6-8 Monaten in das Hauptquartier kamen (löschten sie nicht ihr Profil, aber tatsächlich kamen für einen anderen Kandidaten die Stimmzettel zu verderben).
Und ein paar Mal - persönliche Geschichten, wenn Fotos von jemandem öffentlich veröffentlicht wurden. Es war notwendig, Verbindungen usw. zu finden. Leider ist es sehr erbärmlich, aber wir können nicht vor Gericht aussagen, weil unsere Basis rechtlich illiquide ist. - MongoDB Repository ist mein Favorit.
Soziale Netzwerke haben mit der Datenerfassung zu kämpfen
- Normalerweise entladen wir Werbetreibenden nur die Liste dieser Konten, und dann verwenden sie die Standardliste ... Das heißt, in sozialen Netzwerken können Sie in Vkontakte eine Liste dieser Personen angeben.
Für Facebook werden jedoch die gekauften Cookies verwendet. Wir selbst arbeiten nicht mit Cookies, aber es gab mehrere Geschichten, in denen der Werbetreibende selbst einige Personen übermittelte, mit denen wir interagierten. Sie haben diese Netzwerke, mit Teaser- und Nicht-Teaser-Werbung, diese Cookies. Sie können binden - keine Frage! Aber ich mag diese Dinge nicht wirklich, weil ich denke, dass dies nicht sehr zuverlässig ist. Es ist meiner Meinung nach rein, es ist wie TNS, das Fernsehen "streamt" - es ist nicht klar, ob Sie dieses Fernsehen sehen, nicht zuschauen, das Geschirr spülen, während Ihr Fernseher funktioniert ... Und das Gleiche hier: Ich google sehr oft Internet, aber das bedeutet nicht, dass ich es kaufen möchte. - Wenn Sie ein Standardnetzwerk für kontextbezogene Werbung verwenden: Ich hatte mehrere Geschichten, als wir diese Personen zu ihnen entluden und versuchten, sie über ihre Benutzeroberflächen mit „Cookies“ auf ihren Websites zu binden. Aber ich mag solche Dinge nicht wirklich.
Internet User Payroll Formula
- Die allgemeine Formel für das Durchschnittsgehalt: Dies ist die Region, in der die Person lebt. Dies ist die Kategorie des Geschäfts, in der sie arbeitet (dh das Unternehmen, das sein Arbeitgeber ist). Dann wird ihre Position in diesem Unternehmen eingenommen. Das Durchschnittsgehalt in dieser Position wird als ... Durchschnittsgehalt angegeben entnommen aus Head Hunter und Super Job (und es gibt mehrere weitere Quellen) für eine bestimmte Stelle in einer bestimmten Region und für einen bestimmten Geschäftskontext.
Bei Avito und Auto.ru werden normalerweise zusätzliche Parameter verwendet, wenn eine Person das Telefon aufleuchtet. Mit Avito können Sie sehen, was eine Person verkauft - teuer, günstig, gebraucht, nicht gebraucht. Mit "Auto.ru" können Sie sehen, ob er ein Auto hat - er besitzt, besitzt nicht. Dies sind weniger als 20% der Personen, die ihr Telefon versehentlich irgendwo abgelegt haben, und ihr Konto kann mit diesen Daten verknüpft werden.
Wie groß ist das Datenerfassungsunternehmen?
- Das Volumen der gespeicherten Fotos in Petabyte beträgt 6,4. Ich kann die Wachstumsrate derzeit nicht mit Sicherheit sagen, da wir im Jahr 2016 mit der Aufnahme von Periskopen und ein wenig mit der Videoaufnahme begonnen haben.
Ich kann nicht genau sagen, wann es Null war. Wir gingen von Firma zu Firma - das sind alles lange Geschichten. Aber ich kann sagen, dass VK, Facebook, Instagram und Twitter - all dieses Geschäft (Menschen, Gruppen und Links zwischen ihnen) mit Text und Inhalten - nicht so viele Daten sind, es ist kaum ein Petabyte abgeholt. Ich denke, das ist ein Gigabyte von 700, wahrscheinlich 800.
Helfen Sie Kunden, die aktuelle Nische zu identifizieren, wo sie "graben" sollen?
- Wenn ein Kunde eintrifft, teilen wir ihm dies mit, tun dies jedoch nicht wie Google Trends.
- Wir hatten mehrere soziologische Geschichten mit einer Wahlvorwahlgeschichte - wir haben das alles analysiert. Mit Marken und der Bewertung von Meinungen über Marken stimmt fast immer alles überein. Hier sind die Geschichten zu den Wahlen - nein (mit einer Einschätzung, welcher Kandidat gewinnen sollte). Nun, wer hier falsch liegt - wir oder diejenigen, die an VTsIOM glauben - ich weiß es nicht.
- Normalerweise beziehen wir diese Kontrollergebnisse von der Marke selbst, sie beziehen sie von den Kameraden, die Nachforschungen anstellen - Telefonieren, Marketing und so weiter. Außerdem kann das Ganze mit grundlegenden Dingen überprüft werden: Jemand hat dort auf den Newsletter geantwortet, jemand befragt ... Wenn es sich um eine große Marke handelt (zum Beispiel Coca-Cola), muss sie eine Million oder zwei interne Kundenbewertungen haben - Dies sind nicht nur Kommentare in sozialen Netzwerken und Meinungen; Einige interne Systeme, Überprüfungen usw.
Das Gesetz "weiß" nicht, was personenbezogene Daten sind!
- Wir analysieren ausschließlich offene Datenquellen und klettern niemals in schmutzige Tschernukha. Unser Modell basiert auf der Tatsache, dass wir alle offenen Daten in einigen öffentlichen Rechenzentren speichern, woanders vermieten und zu Hause, auf dem Territorium von Büros oder auf unseren Servern analysieren, und dies geht nirgendwo über das Territorium hinaus.
Unsere Open-Data-Gesetzgebung ist jedoch sehr vage.
Wir haben kein klares Verständnis dafür, was offene Daten sind, was persönliche Daten sind - es gibt das 152. Bundesgesetz, aber trotzdem ... Sie denken, wie? Wenn ich jetzt Ihren Namen und Ihr Telefon in einer Datenbank habe, habe ich Ihr Telefon und Ihre E-Mail in einer anderen Datenbank und in der dritten sagen wir, Ihre E-Mail und Ihr Auto. all dies ist wie nicht personenbezogene Daten. Wenn Sie alles zusammenfassen, scheint es, als würden es gesetzlich personenbezogene Daten sein.
Wir umgehen das auf zwei Arten. Zuerst stellen wir dem Kunden den Server mit Software zur Verfügung, und dann gehen diese Daten nicht über sein Hoheitsgebiet hinaus. Dann ist der Kunde für die Verbreitung dieser personenbezogenen Daten, nicht personenbezogener Daten usw. verantwortlich. Oder die zweite Option: Wenn es sich um eine Art Geschichte handelt, in der Sie das soziale Netzwerk oder etwas anderes verklagen müssen ...
Wir hatten eine solche Studie, als wir für LifeNews-Berichte dieser Kameraden sammelten (das waren die Vorwahlen von "United Russia") und sahen, welche Art von Porno sie mögen. Das Lustige war, aber trotzdem. Wir verkaufen dies als unsere eigene, persönliche Meinung, ohne in den von uns analysierten Dokumenten - das Register, das Gehalt, die sozialen Netzwerke - rechtlich zu offenbaren. Wir verkaufen Gutachten und erklären der Person bereits am Rande, was wir analysiert haben und wie.
Es gab mehrere Geschichten, aber sie waren mit einigen öffentlichen kommerziellen Projekten verbunden. Zum Beispiel haben wir ein kostenloses gemeinnütziges Projekt für diejenigen, die Longboards fahren (solche Boards sind lang): Die Aufgabe bestand darin, die Veröffentlichungen der Leute zu sammeln - wenn jemand postet: "Ich bin zum Reiten in Gorkys Park gegangen." Und dann sollte er sich auf die Karte setzen und die Leute um ihn herum können sehen, dass jemand neben ihm ist. VK hat sehr lange mit uns über dieses Thema gestritten, weil es ihnen nicht gefiel, dass wir diese Informationen ohne die Erlaubnis von Personen veröffentlichen. Aber dann ging die Sache nicht vor Gericht, weil wir in mehreren großen Gemeinden die Regeln hinzugefügt haben, dass die Daten von Drittagenturen, Agenturen, Analysen usw. verwendet werden können. Natürlich war es nicht besonders ethisch, aber dennoch. - Wir fingen plötzlich an und fingen an, unsere Expertenmeinung an alle zu verkaufen.
Arbeiten Sie mit Bildungseinrichtungen zusammen?
- Wir kooperieren mit pädagogischen, ja. Wir haben eine ganze Reihe: Wir haben ein Masterstudium an der Higher School, wir kooperieren mit anderen Universitäten. Universitäten, die wir wirklich lieben!
- Es gibt meine Kontakte - Sie können schreiben. Und ein Verweis auf die Präsentation, wenn jemand interessiert wäre - es gibt all diese Beispiele, die Sie bewegen können.
- Wenn ein Telefon bekannt ist, ist Mail fast eine absolute Option, niemand wird es entfernen. Wenn es kein Telefon gibt, ist dies normalerweise ein Bild, es gibt kein Bild - dies ist das Jahr, der Wohnort, die Arbeit. Das heißt, nach Jahr, Wohn- und Arbeitsort können fast alle immer ganz subtil identifiziert werden. Aber auch dies ist eine Frage zur Aufgabe.
Wir haben zum Beispiel einen Kunden, der Internet-TV verkauft. Jemand hat von ihnen ein Abonnement für diese Games of Thrones gekauft, und die Aufgabe besteht darin, diese Personen aus ihrem CRM in sozialen Netzwerken zu finden und dann potenzielle Personen aus ihrem Einflussbereich zu finden. Ich sage nur, dass sie beispielsweise einen Namen, einen Nachnamen und eine E-Mail-Adresse haben ... Und dann ist es sehr schwierig, etwas zu tun. In den meisten Fällen können Sie Personen per E-Mail finden. - In Bezug auf Freunde „stimmen“ wir normalerweise Leute mit sozialen Netzwerken überein, aber das ist nicht immer richtig. Nicht, dass es nicht immer richtig ist - es funktioniert nicht immer. Erstens erfordert dies viel Arbeit, da diese Operation (für übereinstimmende Personen) zuerst für jeden der Freunde durchgeführt werden muss - um zu verstehen, ob sie von sozialen Netzwerken gewechselt sind oder nicht. Und dann - denn niemand ist eine unbekannte Tatsache, dass "Vkontakte" wir nur Freunde haben, auf "Facebook" haben wir andere Freunde. Nicht für alle, aber für mich zum Beispiel; .
?
- . , , . NDA. , , , , – , , . , – , – .
?
- , , , – , , – . , , , – Social Data Hub, . . , , , , . , …
- ( ?) , , .
( ): , , . - «» – 14%, «» ( ). , – .
, !
- , – . , «». , , … , ! - – , . – , . , , …
- : «, - ! !» , . - , – , , … , , 5 , - . , HR-, , : « – »!
. ?
- -10 . : … – , HR- , . , , - …
- ( ) 25 , .
- , , , 50 %. , - . , 40 , 50-60 % . . , - , , - , , … , – , . .
Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Mögen Sie unsere Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden
Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen, ein
einzigartiges Analogon zu Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 Dollar oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2-mal billiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2 x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV ab 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
das Erstellen von Infrastruktur-Bldg. Klasse C mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?