Hinweis perev. : Dieser Medium-Hit-Artikel gibt einen Überblick über wichtige Änderungen (2010-2019) in der Welt der Programmiersprachen und des zugehörigen Technologie-Ökosystems (Docker und Kubernetes werden besonders berücksichtigt). Die ursprüngliche Autorin ist Cindy Sridharan, die sich auf Tools für Entwickler und verteilte Systeme spezialisiert hat - insbesondere das Buch „Distributed Systems Observability“ (Beobachtbarkeit verteilter Systeme) - und im Internet bei IT-Experten, die sich besonders für das Thema Cloud Native interessieren, sehr beliebt ist.
Das Jahr 2019 ist zu Ende und ich möchte meine Gedanken über einige der wichtigsten technologischen Errungenschaften und Innovationen des letzten Jahrzehnts teilen. Darüber hinaus werde ich versuchen, einen Blick in die Zukunft zu werfen und die Hauptprobleme und -chancen des kommenden Jahrzehnts zu skizzieren.
Ich möchte sofort reservieren, dass ich in diesem Artikel keine Änderungen in Bereichen wie
Datenwissenschaft , künstliche Intelligenz, Frontend-Engineering usw. behandele, da ich persönlich nicht genug Erfahrung darin habe.
Tippen schlägt zurück
Einer der positivsten Trends der 2010er Jahre war die Wiederbelebung von Sprachen mit statischer Typisierung. Solche Sprachen sind jedoch nirgendwo verschwunden (C ++ und Java sind heute gefragt; sie dominierten vor zehn Jahren). Sprachen mit dynamischer Typisierung (dynamisch) erfreuten sich jedoch nach dem Aufkommen der Ruby-on-Rails-Bewegung im Jahr 2005 einer deutlichen Zunahme. Dieses Wachstum erreichte 2009 mit der Eröffnung des Quellcodes von Node.j seinen Höhepunkt und machte Javascript auf dem Server zur Realität.
Im Laufe der Zeit haben dynamische Sprachen in der Entwicklung von Serversoftware an Attraktivität verloren. Die Go-Sprache, die während der Container-Revolution populär wurde, schien besser dafür geeignet zu sein, leistungsfähige, ressourceneffiziente Server mit paralleler Verarbeitung von Informationen zu erstellen (dem der Schöpfer von Node.js
zustimmt ).
Rust, das 2010 eingeführt wurde, schloss Fortschritte in der
Typentheorie ein, um eine sichere und typisierte Sprache zu werden. In der ersten Hälfte des Jahrzehnts war die Einstellung gegenüber Rust in der Branche ziemlich cool, aber in der zweiten Hälfte stieg seine Popularität erheblich. Zu den bemerkenswerten Beispielen für die Verwendung von Rust zählen die Verwendung für
Magic Pocket in Dropbox ,
AWS Firecracker (wir haben in diesem Artikel darüber gesprochen) , Fastlys früher WebAssembly-Compiler von Fastly (jetzt Teil der Bytecode Alliance) usw. In einer Situation, in der Microsoft erwägt, einige Teile von Windows in Rust umzuschreiben, kann man mit Sicherheit sagen, dass diese Sprache in den 2020er Jahren eine glänzende Zukunft hat.
Sogar dynamische Sprachen haben neue Funktionen wie
optionale Typen erhalten . Sie wurden zuerst in TypeScript implementiert, einer Sprache, mit der Sie getippten Code erstellen und in JavaScript kompilieren können. PHP, Ruby und Python haben eigene optionale Schreibsysteme (
mypy ,
Hack ) erworben, die erfolgreich in der
Produktion eingesetzt werden .
SQL kehrt zu NoSQL zurück
NoSQL ist eine andere Technologie, die zu Beginn des Jahrzehnts viel beliebter war als am Ende. Ich denke, dafür gibt es zwei Gründe.
Erstens erwies sich das NoSQL-Modell mit dem Mangel an Schema, Transaktionen und schwächeren Konsistenzgarantien als schwieriger zu implementieren als das SQL-Modell. In einem
Blog-Beitrag mit dem Titel "
Warum sollten Sie nach Möglichkeit eine starke Konsistenz wählen?" Schreibt Google:
Bei Google haben wir unter anderem gelernt, dass der Anwendungscode einfacher und die Entwicklungszeit kürzer ist, wenn sich Ingenieure auf vorhandenen Speicher verlassen können, um komplexe Transaktionen zu verarbeiten und die Datenreihenfolge aufrechtzuerhalten. In der Originaldokumentation von Spanner heißt es: „Wir sind der Meinung, dass es besser ist, wenn Programmierer sich mit Anwendungsleistungsproblemen aufgrund von Transaktionsmissbrauch befassen, da Engpässe auftreten, anstatt ständig keine Transaktionen im Auge zu behalten.“
Der zweite Grund hängt mit dem Wachstum von "skalierbaren" verteilten SQL-Datenbanken (wie
Cloud Spanner und
AWS Aurora ) im öffentlichen Cloud-Bereich sowie Open Source-Alternativen wie CockroachDB
(wir haben auch darüber geschrieben - ca. übersetzt) zusammen , die viele lösen von technischen Problemen, aufgrund derer traditionelle SQL-Basen "nicht skaliert" haben. Sogar MongoDB, einst der Inbegriff der NoSQL-Bewegung,
bietet jetzt verteilte Transaktionen an.
In Situationen, in denen atomare Lese- und Schreibvorgänge für mehrere Dokumente (in einer oder mehreren Sammlungen) erforderlich sind, unterstützt MongoDB Transaktionen mit mehreren Dokumenten. Bei verteilten Transaktionen können Transaktionen für viele Vorgänge, Sammlungen, Datenbanken, Dokumente und Shards verwendet werden.
Streaming insgesamt
Apache Kafka ist ohne Zweifel eine der wichtigsten Erfindungen des letzten Jahrzehnts geworden. Der Quellcode wurde im Januar 2011 eröffnet und im Laufe der Jahre hat Kafka die Funktionsweise des Datengeschäfts revolutioniert. Kafka wurde in allen Unternehmen eingesetzt, in denen ich arbeiten durfte, von Start-ups bis hin zu großen Unternehmen. Die ihnen zur Verfügung gestellten Garantien und Anwendungsfälle (Pub-Sub, Streams, ereignisorientierte Architekturen) werden für verschiedene Aufgaben verwendet: von der Organisation der Datenspeicherung bis zur Überwachung und Streaming-Analyse, die in vielen Bereichen wie Finanzen, Gesundheitswesen, öffentlicher Sektor, Einzelhandel und etc.
Kontinuierliche Integration (und in geringerem Maße kontinuierliche Bereitstellung)
Kontinuierliche Integration (Continuous Integration) ist in den letzten 10 Jahren nicht aufgetreten, hat sich jedoch in den letzten zehn Jahren
so weit verbreitet, dass es Teil des Standardworkflows geworden ist (Tests für alle Pull-Anforderungen ausführen). Ein GitHub als Plattform zum Entwickeln und Speichern von Code zu werden und, was noch wichtiger ist, einen auf
GitHub Flow basierenden Workflow zu entwickeln
, bedeutet, dass die Durchführung von Tests vor dem Akzeptieren einer Pull-Anfrage in den Master der
einzige Workflow in der Entwicklung ist, der Ingenieuren vertraut ist, die ihre Karriere begonnen haben letzten zehn Jahre.
Continuous Deployment (Continuous Deployment; Bereitstellen jedes Commits wie es ist und wenn es in den Master eintritt) ist nicht so weit verbreitet wie die kontinuierliche Integration. Mit vielen verschiedenen Cloud-basierten APIs für die Bereitstellung, der wachsenden Beliebtheit von Plattformen wie Kubernetes (Bereitstellung einer standardisierten API für Bereitstellungen) und der Einführung von Multi-Plattform-Multi-Cloud-Tools wie Spinnaker (die auf diesen standardisierten APIs aufbauen) sind die Bereitstellungsprozesse jedoch automatisierter, rationalisierter und rationalisierter geworden. im Allgemeinen sicherer.
Behälter
Die Container können vielleicht als die meist diskutierte, beworbene und missverstandene Technologie der 2010er bezeichnet werden. Auf der anderen Seite ist dies eine der wichtigsten Neuerungen des vergangenen Jahrzehnts. Ein Teil des Grundes für all diese Kakophonie liegt in den gemischten Signalen, die wir fast überall erhalten haben. Nachdem sich der Hype etwas beruhigt hat, haben einige Momente deutlichere Schattierungen angenommen.
Container sind nicht populär geworden, weil sie die beste Möglichkeit sind, eine Anwendung auszuführen, die den Anforderungen der globalen Entwicklergemeinschaft entspricht. Behälter wurden populär, weil sie erfolgreich in eine Marketinganfrage nach einem Werkzeug passten, das ein völlig anderes Problem löst. Docker erwies sich als
fantastisches Entwicklungswerkzeug, um das Problem der Presskompatibilität zu lösen („funktioniert auf meiner Maschine“).
Genauer gesagt, das
Docker-Image stellte eine Revolution dar, da es das Problem der Parität zwischen Umgebungen löste und eine echte Portabilität nicht nur der Anwendungsdatei, sondern auch aller ihrer Software- und Betriebsabhängigkeiten sicherstellte. Die Tatsache, dass dieses Tool die Popularität von "Containern", die in der Tat ein Detail der Implementierung auf sehr niedriger Ebene darstellen, in gewisser Weise beflügelt hat, bleibt vielleicht das Hauptgeheimnis des letzten Jahrzehnts.
Serverlos
Ich wette, dass das Auftreten von "serverlosem" Computing noch wichtiger ist als Container, da Sie damit wirklich den Traum vom
On-Demand- Computing verwirklichen können. In den letzten fünf Jahren habe ich beobachtet, wie der Anwendungsbereich des serverlosen Ansatzes schrittweise erweitert wurde (Unterstützung für neue Sprachen und Laufzeiten wurde hinzugefügt). Die Einführung von Produkten wie Azure Durable Functions scheint ein sicherer Schritt zur Implementierung von Stateful Functions zu sein (und gleichzeitig
einige Probleme im Zusammenhang mit FaaS-Einschränkungen zu lösen). Ich werde mit Interesse beobachten, wie sich dieses neue Paradigma in den kommenden Jahren entwickeln wird.
Automatisierung
Vielleicht hat die Community der Betriebsingenieure am meisten von diesem Trend profitiert, da er die Implementierung von Konzepten wie „Infrastruktur als Code“ (IaC) ermöglichte. Darüber hinaus fiel die Leidenschaft für die Automatisierung mit dem Wachstum der „SRE-Kultur“ zusammen, deren Ziel eine programmorientiertere Herangehensweise an den Betrieb ist.
Universelle API
Ein weiteres merkwürdiges Merkmal des letzten Jahrzehnts war die API-Fokussierung verschiedener Entwicklungsaufgaben. Mit guten, flexiblen APIs können Entwickler innovative Workflows und Tools erstellen, die wiederum zur Wartung und zur Verbesserung der Benutzerfreundlichkeit beitragen.
Darüber hinaus ist API-Fiktion der erste Schritt zur SaaS-Fiktion einiger Funktionen oder Tools. Dieser Trend fiel auch mit der wachsenden Popularität von Microservices zusammen: SaaS war nur ein weiterer Dienst, mit dem Sie mithilfe der API arbeiten können. Derzeit gibt es viele SaaS- und FOSS-Tools in Bereichen wie Überwachung, Zahlungen, Lastenausgleich, kontinuierliche Integration, Warnungen,
Feature-Flagging , CDN, Verkehrstechnik (z. B. DNS) usw. die in den letzten zehn Jahren blühte.
Beobachtbarkeit
Es ist erwähnenswert, dass wir heute
weitaus fortschrittlichere Tools zur Überwachung und Diagnose des Anwendungsverhaltens als je zuvor zur Verfügung haben. Das Prometheus-Überwachungssystem, das 2015 den Status Open Source erhalten hat, kann als das vielleicht
beste Überwachungssystem derer bezeichnet werden, mit denen ich gearbeitet habe. Es ist nicht perfekt, aber eine erhebliche Anzahl von Dingen wird vollständig korrekt implementiert (z. B. Unterstützung für
Bemaßungen bei Metriken).
Distributed Tracing war eine weitere Technologie, die in den 2010er Jahren dank Initiativen wie OpenTracing (und dessen Nachfolger OpenTelemetry) Einzug gehalten hat. Obwohl die Verwendung der Rückverfolgung immer noch recht schwierig ist, lassen einige der neuesten Entwicklungen die Hoffnung aufkommen, dass wir in den 2020er Jahren das wahre Potenzial der Rückverfolgung aufdecken werden.
(Anmerkung perev.: Lesen Sie auch in unserem Blog die Übersetzung des Artikels " Distributed Tracing: Wir haben alles falsch gemacht " vom selben Autor.)In die Zukunft blicken
Leider gibt es viele Schwachstellen, die darauf warten, im kommenden Jahrzehnt behoben zu werden. Hier sind meine Gedanken zu ihnen und einige mögliche Ideen, wie ich sie loswerden kann.
Moore Law Problemlösung
Das Ende von Dennards Skalierungsgesetz und die Verzögerung von Moores Gesetz erfordern neue Innovationen. John Hennessy erklärt in
seinem Vortrag, warum
domänenspezifische Architekturen wie TPUs eine der Lösungen für das Problem sein können, hinter Moores Gesetz zurückzubleiben. Toolkits wie die
MLIRs von Google
scheinen bereits ein guter Schritt in diese Richtung zu sein:
Compiler sollten neue Anwendungen unterstützen, einfach auf neue Hardware portieren, viele Abstraktionsebenen verbinden, von dynamischen, kontrollierten Sprachen bis hin zu Vektorbeschleunigern und programmgesteuerten Speichergeräten, und gleichzeitig Switches auf hoher Ebene für die automatische Optimierung und Just-in-Funktionalität bereitstellen Diagnostizieren und Verteilen von Debugging-Informationen über die Funktionsweise und Leistung von Systemen im gesamten Stapel, und in den meisten Fällen bieten zvoditelnost ausreichend nahe an den handgeschriebenen Assembler. Wir beabsichtigen, unsere Vision, Fortschritte und Pläne hinsichtlich des Aufbaus und der öffentlichen Verfügbarkeit einer solchen Kompilierungsinfrastruktur zu teilen.
CI / CD
Obwohl die wachsende Beliebtheit von CI zu einem der Haupttrends der 2010er Jahre geworden ist, ist Jenkins immer noch der Goldstandard von CI.
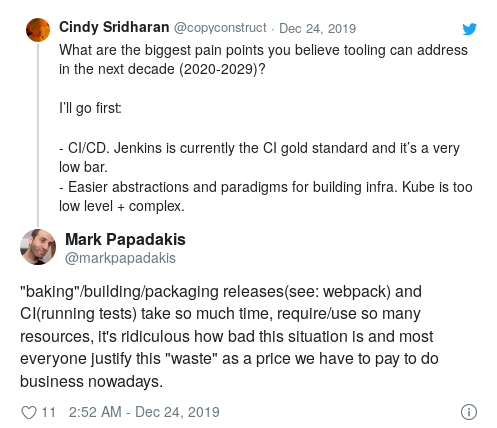
Dieser Raum braucht dringend Innovationen in folgenden Bereichen:
- Benutzerschnittstelle (DSL zur Kodierung der Testspezifikationen);
- Implementierungsdetails, die es wirklich skalierbar und schnell machen;
- Integration in verschiedene Umgebungen (Staging, Produktentwicklung usw.) für die Implementierung fortgeschrittenerer Testformen;
- kontinuierliche Validierung und Bereitstellung.
Entwicklertools
Als Branche haben wir begonnen, immer komplexere und beeindruckendere Software zu entwickeln. Wenn es jedoch um unsere eigenen Tools geht, können wir sagen, dass die Situation viel besser sein könnte.
Joint und Remote (via ssh) Editing haben an Popularität gewonnen, sind aber noch nicht die neue Standardentwicklungsmethode geworden. Wenn Sie wie ich die Vorstellung ablehnen,
dass eine permanente Internetverbindung erforderlich ist, um programmieren zu können, ist es unwahrscheinlich, dass Sie mit ssh auf einem Remotecomputer arbeiten.
Lokale Entwicklungsumgebungen, insbesondere für Ingenieure, die an großen serviceorientierten Architekturen arbeiten, bleiben weiterhin ein Problem. Einige Projekte versuchen es zu lösen, und ich würde gerne wissen, wie das ergonomischste UX für diesen Anwendungsfall aussehen wird.
Es wäre auch interessant, das Konzept der „tragbaren Umgebungen“ auf andere Bereiche der Entwicklung
auszudehnen , z. B. auf Reproduktionsfehler (oder
Flockentests ), die unter bestimmten Bedingungen oder mit bestimmten Einstellungen auftreten.
Ich würde auch gerne mehr Innovationen in Bereichen wie der semantischen und kontextsensitiven Codesuche sehen, Tools, mit denen Sie Produktionsvorfälle mit bestimmten Teilen der Codebasis in Beziehung setzen können usw.
Berechnungen (zukünftiges PaaS)
Inmitten des allgemeinen Hype um Container und Serverless in den 2010er Jahren hat sich das Lösungsspektrum in der Public Cloud in den letzten Jahren erheblich erweitert.

In dieser Hinsicht ergeben sich mehrere interessante Fragen. Erstens wächst die Liste der verfügbaren Optionen in der öffentlichen Cloud ständig. Cloud-Dienstanbieter verfügen über Personal und Ressourcen, um mit den neuesten Entwicklungen in der Open Source-Welt Schritt zu halten und Produkte wie serverlose Pods (ich vermute nur, indem sie ihre eigenen FaaS-Laufzeiten mit OCI kompatibel machen) oder andere herauszubringen Ähnliches schickes Zeug.
Wer diese Cloud-Lösungen nutzt, kann nur beneidet werden. Theoretisch bieten die Cloud-Angebote von Kubernetes (GKE, EKS, EKS bei Fargate usw.) Cloud-unabhängige Provider-APIs zum Ausführen von Workloads. Wenn Sie ähnliche Produkte verwenden (ECS, Fargate, Google Cloud Run usw.), werden Sie wahrscheinlich die interessantesten Funktionen des Dienstanbieters optimal nutzen. Darüber hinaus dürfte die Migration mit dem Aufkommen neuer Produkte oder Computerparadigmen einfach und problemlos sein.
In Anbetracht der Geschwindigkeit, mit der sich die Palette solcher Lösungen entwickelt (ich bin sehr überrascht, wenn in naher Zukunft einige neue Optionen nicht auftauchen), kleine "Plattform" -Teams (Teams, die sich auf die Infrastruktur beziehen und für die Erstellung lokaler Plattformen zum Starten von Workloads verantwortlich sind In Unternehmen wird es unglaublich schwierig sein, hinsichtlich Funktionalität, Benutzerfreundlichkeit und Zuverlässigkeit zu konkurrieren. Die 2010er Jahre waren von Kubernetes als Tool zur Erstellung von PaaS (Platform-as-a-Service) gekennzeichnet. Daher erscheint es völlig sinnlos, eine interne Plattform auf Basis von Kubernetes zu erstellen, die die gleiche Auswahl, Einfachheit und Freiheit bietet, die in einem öffentlichen Cloud-Bereich verfügbar ist. Das Konzept des container-basierten PaaS als Kubernetes-Strategie kommt dem absichtlichen Verzicht auf die innovativsten Cloud-Funktionen gleich.
Wenn Sie sich die
heute verfügbaren Rechenkapazitäten ansehen, wird deutlich, dass das Erstellen eines eigenen PaaS ausschließlich auf der Basis von Kubernetes gleichbedeutend ist, wenn Sie sich in eine Ecke drängen (nicht zu weitsichtig, oder?). Auch wenn sich heute jemand für die Erstellung von containerisiertem PaaS auf Kubernet-Basis entscheidet, wird es in ein paar Jahren im Vergleich zu Cloud-Funktionen veraltet sein. Obwohl Kubernetes als Open-Source-Projekt begann, ist sein Vorläufer und ideologischer Inspirator das entsprechende interne Google-Tool. Es wurde jedoch ursprünglich in den frühen / mittleren 2000er Jahren entwickelt, als die Computerlandschaft völlig anders war.
Darüber hinaus sollten Unternehmen im weitesten Sinne keine Experten für die Arbeit mit dem Kubernetes-Cluster werden und auch keine eigenen Rechenzentren einrichten und warten. Die Bereitstellung einer zuverlässigen Datenverarbeitungsgrundlage ist das primäre Ziel von
Cloud-Dienstanbietern .
Schließlich habe ich das Gefühl, dass wir uns als Branche in Bezug
auf Interaktionserfahrung (
UX ) etwas zurückgebildet haben. Heroku wurde 2007 gestartet und ist nach wie vor eine der am
einfachsten zu bedienenden Plattformen. Ohne Zweifel hat Kubernetes viel mehr Leistung, Erweiterbarkeit und Programmierbarkeit, aber ich vermisse, wie einfach es ist, mit Heroku zu beginnen und es zu implementieren. Um diese Plattform zu nutzen, muss man Git kennen.
All dies führt mich zu folgendem Schluss: Für die Arbeit brauchen wir bessere Abstraktionen auf höherer Ebene (dies gilt insbesondere für
Abstraktionen auf höchster Ebene ).
Die richtige API auf höchstem Niveau
Docker ist ein gutes Beispiel für die Notwendigkeit einer besseren Aufgabentrennung und der
korrekten Implementierung der API auf höchster Ebene .
Das Problem von Docker ist, dass (zumindest) die Ziele des Projekts zu global festgelegt wurden: Alles, um das Kompatibilitätsproblem („funktioniert auf meiner Maschine“) mithilfe der Containertechnologie zu lösen. Docker war sowohl ein Image-Format als auch eine Laufzeitumgebung mit einem eigenen virtuellen Netzwerk, einem CLI-Tool, einem Root-Daemon und vielem mehr. In jedem Fall war das Messaging verwirrender, ganz zu schweigen von den „schlanken VMs“, Kontrollgruppen, Namespaces, zahlreichen Sicherheitsproblemen und Funktionen, die mit dem Marketing-Aufruf „Erstellen, Bereitstellen, Ausführen von Anwendungen an jedem Ort“ gemischt wurden.

Wie bei allen guten Abstraktionen braucht es Zeit (sowie Erfahrung und Schmerz), um die verschiedenen Probleme in logische Schichten aufzuteilen, die miteinander kombiniert werden können. Leider trat Kubernetes in den Kampf ein, bevor Docker es schaffte, eine solche Reife zu erreichen. Er monopolisierte den Hype-Zyklus so sehr, dass nun jeder versuchte, mit den Veränderungen im Kubernetes-Ökosystem Schritt zu halten, und das Container-Ökosystem einen sekundären Status erlangte.
Kubernetes hat in vielerlei Hinsicht dieselben Probleme wie Docker. Trotz aller Rede von cooler und komponierbarer Abstraktion ist die
Aufgabentrennung in Ebenen nicht allzu stark gekapselt. Grundsätzlich handelt es sich um ein Container-Orchester, das Container in einem Cluster verschiedener Maschinen startet. Dies ist eine relativ einfache Aufgabe, die nur für Ingenieure gilt, die den Cluster betreiben. Kubernetes ist andererseits auch eine
Abstraktion auf höchstem Niveau , ein CLI-Tool, mit dem Benutzer über YAML interagieren.
Docker war (und ist) trotz aller Mängel ein
cooles Entwicklungswerkzeug. Um mit allen „Hasen“ gleich mithalten zu können, ist es den Entwicklern gelungen, die
Abstraktion auf höchstem Niveau korrekt umzusetzen.
Mit Abstraktion auf höchstem Niveau meine ich eine Teilmenge der Funktionalität, an der die Zielgruppe wirklich interessiert war (in diesem Fall die Entwickler, die die meiste Zeit in ihren lokalen Entwicklungsumgebungen verbracht haben) und die perfekt „out of the box“ funktioniert hat .
Dockerfile und das
docker CLI-Dienstprogramm sollten ein Beispiel für die Erstellung einer guten Benutzeroberfläche auf oberster Ebene sein. Ein gewöhnlicher Entwickler kann mit Docker arbeiten, ohne die Feinheiten der
Implementierung zu kennen, die zur Betriebserfahrung beitragen , wie z. B. Namespaces, Kontrollgruppen, Speicher- und CPU-Einschränkungen usw. Letztendlich ist das Schreiben einer Docker-Datei nicht viel anders als das Schreiben eines Shell-Skripts.
Kubernetes richtet sich an verschiedene Zielgruppen:
- Cluster-Administratoren
- Software-Ingenieure, die mit Infrastrukturproblemen befasst sind, die Fähigkeiten von Kubernetes erweitern und darauf basierende Plattformen erstellen;
- Endbenutzer, die über
kubectl mit Kubernetes kubectl .
Kubernetes 'One API fits all'-Ansatz ist ein unzureichend gekapselter' Berg der Komplexität ', ohne dass angegeben wird, wie er skaliert werden muss. All dies führt zu einem unangemessen langen Lernweg. Adam Jacob: „Docker hat den Nutzern eine noch nie da gewesene transformative Erfahrung gebracht. Fragen Sie jeden, der K8 verwendet, ob er möchte, dass es wie sein erster
docker run funktioniert. Die Antwort lautet "Ja":

Ich würde sagen, dass der Großteil der heutigen Infrastrukturtechnologie zu niedrig ist (und daher als "zu komplex" eingestuft wird). Kubernetes ist auf relativ niedrigem Niveau implementiert. Die verteilte Verfolgung in ihrer
aktuellen Form (viele Bereiche wurden zu einer Verfolgungsansicht zusammengenäht) ist ebenfalls auf einer zu niedrigen Ebene implementiert. Am erfolgreichsten sind Tools für Entwickler, die in der Regel "Abstraktionen auf höchstem Niveau" implementieren. Diese Schlussfolgerung trifft in überraschend vielen Fällen zu (wenn die Technologie zu komplex oder zu schwierig zu verwenden ist, muss die "API / UI auf höchster Ebene" für diese Technologie erst noch geöffnet werden).
Im Moment ist es dem Cloud-Ökosystem peinlich, sich auf niedrige Ebenen zu konzentrieren. Als Branche müssen wir innovieren, experimentieren und lehren, wie die richtige Ebene der „maximalen, höchsten Abstraktion“ aussieht.
Einzelhandel
In den 2010er Jahren hat sich das digitale Einzelhandelserlebnis kaum verändert. Einerseits dürfte die Leichtigkeit des Online-Shoppings klassische Einzelhandelsgeschäfte getroffen haben, andererseits hat sich das Online-Shopping in einem Jahrzehnt kaum grundlegend verändert.
Obwohl ich keine konkreten Gedanken zur Entwicklung dieser Branche im nächsten Jahrzehnt habe, werde ich sehr enttäuscht sein, wenn wir im Jahr 2030 auf die gleiche Weise einkaufen wie im Jahr 2020.
Journalismus
Der Zustand des Weltjournalismus enttäuscht mich zunehmend. Es wird immer schwieriger, unparteiische Nachrichtenquellen zu finden, die objektiv und sorgfältig übertragen werden. Sehr oft wird die Grenze zwischen den Nachrichten selbst und der Meinung darüber aufgehoben. Informationen sind in der Regel voreingenommen. Dies gilt insbesondere für einige Länder, in denen es historisch gesehen keine Trennung zwischen Nachrichten und Meinungen darüber gab. In einem kürzlich nach den letzten Parlamentswahlen in Großbritannien veröffentlichten Artikel
schreibt Alan Rusbridger, ehemaliger Herausgeber von The Guardian:
Die Hauptidee ist, dass ich jahrelang in amerikanischen Zeitungen nachgesehen habe und Mitleid mit den Kollegen dort hatte, die ausschließlich für die Nachrichten verantwortlich waren und Kommentare zu ganz anderen Leuten abgaben. Mit der Zeit wurde aus Mitleid jedoch Neid. Jetzt denke ich, dass alle britischen nationalen Zeitungen die Verantwortung für Nachrichten von der Verantwortung für Kommentare trennen sollten. Leider ist der durchschnittliche Leser - insbesondere der Online-Leser - zu hart, um den Unterschied zu erkennen.
Angesichts des eher zweifelhaften Rufs von Silicon Valley in Bezug auf Ethik würde ich auf keinen Fall darauf vertrauen, dass Technologie den Journalismus „revolutioniert“. Gleichzeitig würde ich mich (und viele meiner Freunde) freuen, wenn eine unparteiische, desinteressierte und vertrauenswürdige Nachrichtenquelle auftauchen würde. Obwohl ich mir nicht vorstellen kann, wie eine solche Plattform aussehen könnte, bin ich mir sicher, dass in einer Zeit, in der die Wahrheitsfindung immer schwieriger wird, das Bedürfnis nach ehrlichem Journalismus größer ist als je zuvor.
Soziale Netzwerke
Soziale Netzwerke und kollektive Nachrichtenplattformen sind die Hauptinformationsquelle für viele Menschen in verschiedenen Teilen der Welt, und die mangelnde Genauigkeit und die mangelnde Bereitschaft einiger Plattformen, zumindest eine grundlegende Überprüfung grundlegender Tatsachen durchzuführen, führen zu so schlimmen Konsequenzen wie Völkermord, Einmischung in Wahlen usw.
Soziale Netzwerke sind auch das mächtigste Medientool, das es je gab. Sie haben die politische Praxis radikal verändert. Sie haben die Anzeigen geändert. Sie haben die Popkultur verändert (zum Beispiel sind es soziale Netzwerke, die den Hauptbeitrag zur Entwicklung der sogenannten Stornokultur leisten
[ soziale Netzwerke des
Ostrakismus - ca. transl.] ). Kritiker argumentieren, dass soziale Medien sich als fruchtbarer Boden für schnelle und „launische“ Veränderungen der moralischen Werte herausstellten, aber sie gaben auch Vertretern von Randgruppen die Möglichkeit, sich zu vereinen (sie hatten noch nie zuvor eine solche Gelegenheit gehabt). Im Wesentlichen haben soziale Netzwerke die Art und Weise, wie Menschen kommunizieren und sich ausdrücken, im 21. Jahrhundert verändert.
Ich bin jedoch auch davon überzeugt, dass soziale Netzwerke zur Manifestation der schlimmsten menschlichen Impulse beitragen. Aufmerksamkeit und Nachdenklichkeit werden aus Gründen der Popularität oft vernachlässigt, und es wird fast unmöglich, eine begründete Meinungsverschiedenheit mit bestimmten Meinungen und Standpunkten zum Ausdruck zu bringen. Die Polarisierung gerät oft außer Kontrolle, und die Öffentlichkeit hört einfach keine getrennten Meinungen, während Absolutisten Fragen der Online-Etikette und Akzeptanz kontrollieren.
Ich frage mich, ob es möglich ist, eine „bessere“ Plattform zu schaffen, die dazu beiträgt, die Qualität der Diskussionen zu verbessern. Schließlich ist es genau das, was das „Engagement“ antreibt, das diesen Plattformen häufig den Hauptgewinn bringt. Kara Swisher
schreibt in der New York Times:
Digitales Engagement kann entwickelt werden, ohne Hass und Intoleranz zu provozieren. Der Grund, warum die meisten sozialen Netzwerke so giftig erscheinen, ist, dass sie für Geschwindigkeit, Viralität und Aufmerksamkeit geschaffen wurden, nicht für Inhalt und Genauigkeit.
Es wäre wirklich bedauerlich, wenn das einzige Vermächtnis sozialer Netzwerke in ein paar Jahrzehnten die Erosion von Nuancen und die Angemessenheit des öffentlichen Diskurses wäre.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: