Heutzutage gibt es vorgefertigte (proprietäre) Lösungen zur Überwachung von IP (TS) -Streams, beispielsweise VB und iQ , die über einen ziemlich umfangreichen Funktionsumfang verfügen und in der Regel für große Betreiber verfügbar sind, die sich mit Fernsehdiensten befassen. Dieser Artikel beschreibt eine Lösung, die auf dem Open-Source-Projekt TSDuck basiert und für die minimale Steuerung von IP-Streams (TS-Streams) durch den Zähler CC (Continuity Counter) und die Bitrate ausgelegt ist. Eine mögliche Anwendung besteht darin, den Verlust von Paketen oder des gesamten Datenstroms über einen gemieteten L2-Kanal zu steuern (der normalerweise nicht überwacht werden kann, z. B. durch Lesen der Verlustzähler in Warteschlangen).
Sehr kurz über TSDuck
TSDuck ist eine Open-Source-Software (2-Klausel-BSD-Lizenz) (eine Reihe von Konsolendienstprogrammen und eine Bibliothek zur Entwicklung ihrer Dienstprogramme oder Plug-Ins) zur Manipulation von TS-Streams. Als Eingang kann es mit IP (Multicast / Unicast), http, hls, DVB-Tuner, DVB-ASI-Demodulator von Dektec arbeiten, es gibt einen internen TS-Stream-Generator und das Lesen von Dateien. Die Ausgabe kann eine Datei, IP (Multicast / Unicast), hls, dektec dvb-asi und HiDes-Modulatoren, Player (mplayer, vlc, xine) und Drop sein. Zwischen Ein- und Ausgabe können Sie verschiedene Verkehrsprozessoren einschalten, z. B. PID-Remapping, Scrambling / Descrambling, Analyse von CC-Zählern, Bitratenberechnung und andere für TS-Streams typische Vorgänge.
In diesem Artikel werden IP-Streams (Multicast) als Eingabe verwendet, Bitrate_Monitor-Prozessoren werden verwendet (aus dem Namen ist klar, was es ist) und Kontinuität (Analyse von CC-Zählern). Sie können IP-Multicast problemlos durch einen anderen von TSDuck unterstützten Eingabetyp ersetzen.
Es gibt offizielle Builds / Pakete von TSDuck für die meisten aktuellen Betriebssysteme. Für Debian ist dies nicht der Fall, aber es war möglich, ohne Probleme unter Debian 8 und Debian 10 zusammenzustellen.
Als nächstes wird die TSDuck-Version 3.19-1520 verwendet, als Betriebssystem wird Linux verwendet (Debian 10 wurde zur Vorbereitung der Lösung verwendet, CentOS 7 wurde für den realen Gebrauch verwendet).
TSDuck und OS vorbereiten
Bevor Sie den tatsächlichen Datenfluss überwachen, müssen Sie sicherstellen, dass TSDuck ordnungsgemäß funktioniert und dass auf Netzwerkkarten- oder Betriebssystemebene (Socket-Ebene) keine Tropfen vorhanden sind. Dies ist erforderlich, um später nicht zu erraten, wo die Abbrüche aufgetreten sind - im Netzwerk oder "im Server". Sie können die Drops auf Netzwerkkartenebene mit dem Befehl ethtool -S ethX überprüfen. Die Optimierung erfolgt mit demselben ethtool (normalerweise müssen Sie den RX-Puffer (-G) erhöhen und manchmal einige Offloads (-K) deaktivieren). Als allgemeine Empfehlung wird empfohlen, einen separaten Port für den Empfang des analysierten Datenverkehrs zu verwenden. Dies minimiert, wenn möglich, die mit der Tatsache verbundenen Fehlalarme, die aufgrund des Vorhandenseins von anderem Datenverkehr auf dem Analysatorport kohärent auftraten. Wenn dies nicht möglich ist (ein Mini-Computer / NUC mit einem einzelnen Port wird verwendet), ist es äußerst wünschenswert, den analysierten Verkehr gegenüber dem Rest auf dem Gerät, an das der Analysator angeschlossen ist, zu priorisieren. In Bezug auf virtuelle Umgebungen müssen Sie vorsichtig sein und in der Lage sein, Paketablagen zu finden, die am physischen Port beginnen und mit der Anwendung in der virtuellen Maschine enden.
Erzeugung und Empfang eines Streams im Host
Als ersten Schritt bei der Vorbereitung von TSDuck werden wir mithilfe von Netzen Datenverkehr auf demselben Host generieren und empfangen.
Kochumgebung:
ip netns add P
Die Umgebung ist bereit. Wir starten den Traffic Analyzer:
ip netns exec P tsp --realtime -t \ -I ip 239.0.0.1:1234 \ -P continuity \ -P bitrate_monitor -p 1 -t 1 \ -O drop
Dabei bedeutet "-p 1 -t 1", dass Sie die Bitrate jede Sekunde berechnen und Informationen zur Bitrate jede Sekunde anzeigen müssen
Wir starten den Traffic Generator mit einer Geschwindigkeit von 10 Mbit / s:
tsp -I craft \ -P regulate -b 10000000 \ -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
wobei "-p 7 -e" bedeutet, dass Sie 7 TS-Pakete in 1 IP-Paket packen und es schwer machen müssen (-e), d. h. Warten Sie immer auf 7 TS-Pakete vom letzten Prozessor, bevor Sie ein IP-Paket senden.
Der Analysator beginnt mit der Anzeige der erwarteten Meldungen:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s * 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s * 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/s
Fügen Sie nun einige Tropfen hinzu:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROP
und Nachrichten wie diese erscheinen:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets * 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets
was erwartet wird. Deaktivieren Sie den Paketverlust (ip netns exec P iptables -F) und versuchen Sie, die Bitrate des Generators auf 100 Mbit / s zu erhöhen. Der Analysator meldet eine Reihe von CC-Fehlern und etwa 75 Mbit / s anstelle von 100. Wir versuchen herauszufinden, wer die Schuld trägt - der Generator hat keine Zeit oder das Problem ist nicht darin enthalten. Dafür generieren wir eine feste Anzahl von Paketen (700.000 TS-Pakete = 100.000 IP-Pakete):
# ifconfig veth0 | grep TX TX packets 151825460 bytes 205725459268 (191.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234 * count: PID 0 (0x0000): 700,000 packets # ifconfig veth0 | grep TX TX packets 151925460 bytes 205861259268 (191.7 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Wie Sie sehen, wurden genau 100.000 IP-Pakete generiert (151925460-151825460). Damit wir verstehen, was mit dem Analysator passiert, überprüfen wir dies mit dem RX-Zähler auf veth1, er ist genau gleich dem TX-Zähler auf veth0, und schauen uns dann an, was auf Sockelebene passiert:
# ip netns exec P cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355
Hier sehen Sie die Anzahl der Drop = 24355. In TS-Paketen sind es 170485 oder 24,36% von 700000, so dass genau 25% der verlorenen Bitrate Drop in der UDP-Buchse sind. In einem UDP-Socket treten normalerweise aufgrund eines fehlenden Puffers Abbrüche auf. Sehen Sie sich die Größe des Standard-Socket-Puffers und die maximale Größe des Socket-Puffers an:
# sysctl net.core.rmem_default net.core.rmem_default = 212992 # sysctl net.core.rmem_max net.core.rmem_max = 212992
Wenn Anwendungen die Größe des Puffers nicht explizit anfordern, werden Sockets mit einem Puffer von 208 KB erstellt. Wenn sie jedoch mehr anfordern, erhalten sie immer noch nicht, was angefordert wird. Da Sie in tsp die Puffergröße (--buffer-size) für die IP-Eingabe festlegen können, berühren wir standardmäßig nicht die Socket-Größe. Wir legen lediglich die maximale Größe des Socket-Puffers fest und geben die Puffergröße explizit über tsp-Argumente an:
sysctl net.core.rmem_max=8388608 ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O drop
Bei dieser Einstellung des Socket-Puffers beträgt die nun gemeldete Bitrate ca. 100 Mbit / s, es treten keine CC-Fehler auf.
Durch die CPU-Auslastung durch die TLP-Anwendung selbst. Bezogen auf einen Kern der i5-4260U-CPU bei 1,40 GHz erfordert die Analyse eines 10-Mbit / s-Datenstroms 3-4% CPU, 100 Mbit / s - 25%, 200 Mbit / s - 46%. Bei der Einstellung von% Packet Loss nimmt die CPU-Last praktisch nicht zu (kann aber abnehmen).
Auf einer produktiveren Hardware konnten problemlos Flüsse von mehr als 1 Gbit / s generiert und analysiert werden.
Testen auf echten Netzwerkkarten
Nach dem Testen eines Veth-Paares müssen Sie zwei Hosts oder zwei Ports eines Hosts verwenden, die Ports miteinander verbinden, den Generator auf einem Host und den Analysator auf dem zweiten Host ausführen. Es gab keine Überraschungen, aber in Wirklichkeit hängt alles von Eisen ab, je schwächer, desto interessanter wird es.
Verwendung der empfangenen Daten durch das Überwachungssystem (Zabbix)
Tsp hat keine maschinenlesbare API wie SNMP oder ähnliches. CC-Nachrichten müssen mindestens 1 Sekunde lang aggregiert werden (bei einem hohen Prozentsatz an Paketverlusten kann es je nach Bitrate zu Hunderten / Tausenden / Zehntausenden pro Sekunde kommen).
Um Informationen zu speichern und Diagramme der CC-Fehler und der Bitrate zu zeichnen und eine Art Unfall zu verursachen, können die folgenden Optionen weiter ausgeführt werden:
- Analysiere und aggregiere (gemäß CC) die Ausgabe von tsp, d.h. konvertieren Sie es in die gewünschte Form.
- Fügen Sie die tsp- und / oder Prozessor-Plug-ins bitrate_monitor und continuity selbst hinzu, damit das Ergebnis in einer maschinenlesbaren Form angezeigt wird, die für ein Überwachungssystem geeignet ist.
- Schreiben Sie Ihre Anwendung oben auf die tsduck-Bibliothek.
Unter dem Gesichtspunkt der Arbeitskosten ist Option 1 offensichtlich die einfachste, insbesondere wenn man bedenkt, dass tsduck selbst in einer (nach modernen Standards) einfachen Sprache (C ++) geschrieben ist.
Ein einfacher Prototyp des Parser + Aggregators für Bash zeigte, dass bei einem Stream mit 10 Mbit / s und einem Paketverlust von 50% (der schlimmste Fall) der Bash-Prozess das 3-4-fache der CPU-Belastung des eigentlichen TLP-Prozesses aufwies. Dieses Szenario ist nicht akzeptabel. Eigentlich ein Stück dieses Prototyps unten
Abgesehen von der Tatsache, dass es inakzeptabel langsam arbeitet, gibt es keine normalen Threads in Bash, Bash-Jobs sind unabhängige Prozesse, und ich musste den Wert von missingPackets einmal pro Sekunde für den Nebeneffekt aufzeichnen (wenn ich Bitraten-Nachrichten erhalte, die jede Sekunde kommen). Infolgedessen wurde bash alleine gelassen und es wurde beschlossen, einen Wrapper (Parser + Aggregator) in Golang zu schreiben. Der CPU-Verbrauch von ähnlichem Golang-Code ist 4-5 mal geringer als der von TLP. Es stellte sich heraus, dass die Beschleunigung des Wrappers durch Ersetzen von bash durch golang etwa 16-mal betrug und das Ergebnis insgesamt akzeptabel war (im schlimmsten Fall 25% Overhead auf der CPU). Die Quelldatei auf Golang ist hier .
Wrapper-Start
Um den Wrapper auszuführen, wurde ( hier ) die einfachste Dienstvorlage für systemd erstellt. Es wird davon ausgegangen, dass der Wrapper selbst in eine Binärdatei kompiliert ist (go build tsduck-stat.go), die sich in / opt / tsduck-stat / befindet. Es wird angenommen, dass Golang mit Unterstützung für die monotone Uhr (> = 1,9) verwendet wird.
Um eine Instanz des Dienstes zu erstellen, müssen Sie den Befehl systemctl enable tsduck-stat@239.0.0.1: 1234 ausführen und anschließend systemctl start tsduck-stat@239.0.0.1: 1234 verwenden.
Entdeckung von Zabbix
Damit zabbix die Suche nach laufenden Diensten durchführen kann, wird ein Gruppenlistengenerator (discovery.sh) in dem für die Zabbix-Suche erforderlichen Format erstellt. Es wird davon ausgegangen, dass er sich dort befindet - in / opt / tsduck-stat. Um die Ermittlung über zabbix-agent zu starten, müssen Sie die .conf-Datei zum Verzeichnis mit den zabbix-agent-Konfigurationen hinzufügen, um den Benutzerparameter hinzuzufügen.
Zabbix-Vorlage
Die erstellte Vorlage (tsduck_stat_template.xml) enthält die AutoErmittlungsregel, Prototypen von Datenelementen, Diagrammen und Triggern.
Eine kurze Checkliste (na ja, wenn sich jemand entscheidet, sie zu benutzen)
- Stellen Sie sicher, dass tsp unter "idealen" Bedingungen keine Pakete fallen lässt (der Generator und der Analysator sind direkt verbunden). Falls es zu Tropfen kommt, lesen Sie Abschnitt 2 oder den Text des Artikels zu diesem Thema.
- Stellen Sie den maximalen Socket-Puffer ein (net.core.rmem_max = 8388608).
- Kompilieren Sie tsduck-stat.go (erstellen Sie tsduck-stat.go).
- Legen Sie die Dienstvorlage in / lib / systemd / system ab.
- Starten Sie die Dienste mit systemctl und überprüfen Sie, ob die Leistungsindikatoren angezeigt werden (grep "" / dev / shm / tsduck-stat / *). Anzahl der Dienste nach Anzahl der Multicast-Streams. Hier müssen Sie möglicherweise eine Route zur Multicast-Gruppe erstellen, möglicherweise rp_filter deaktivieren oder eine Route zur Quell-IP erstellen.
- Führen Sie discovery.sh aus, und stellen Sie sicher, dass es JSON generiert.
- Hängen Sie die Konfiguration des zabbix-Agenten an und starten Sie den zabbix-Agenten neu.
- Laden Sie die Vorlage auf zabbix herunter, wenden Sie sie auf den Host an, auf dem zabbix-agent überwacht und installiert wird. Warten Sie ca. 5 Minuten, bis neue Datenelemente, Grafiken und Trigger angezeigt werden.
Ergebnis
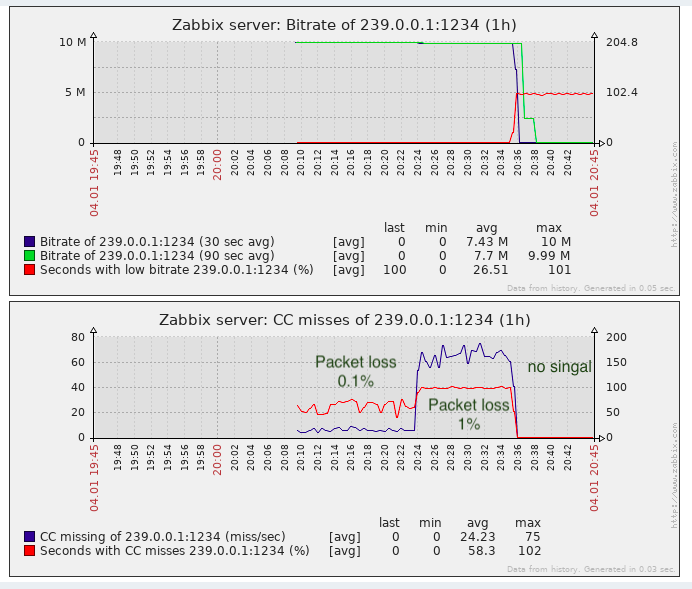
Für die Aufgabe, Paketverluste zu erkennen, reicht es fast aus, zumindest ist es besser als die fehlende Überwachung.
Tatsächlich können CC- „Verluste“ auftreten, wenn Videoclips geklebt werden (soweit ich weiß, werden Einfügungen in lokalen Telezentren in der Russischen Föderation vorgenommen, dh ohne den CC-Zähler zu zählen). Dies muss beachtet werden. In proprietären Lösungen wird dieses Problem teilweise umgangen, indem SCTE-35-Tag-Labels erkannt werden (sofern sie vom Stream-Generator hinzugefügt werden).
UPD: Unterstützung für SCTE-35-Tags zur Wrapper- und Zabbix-Vorlage hinzugefügt
Unter dem Gesichtspunkt der Überwachung der Transportqualität gibt es nicht genügend Überwachungsjitter (Monitoring Jitter, IAT), weil TV-Geräte (egal ob Modulatoren oder Endgeräte) stellen Anforderungen an diesen Parameter und es ist nicht immer möglich, den Jitbuffer auf unendlich zu erhöhen. Und Jitter kann schwanken, wenn Geräte mit großen Puffern während der Übertragung verwendet werden und die QoS nicht oder nur unzureichend für die Übertragung eines solchen Echtzeitverkehrs konfiguriert ist.