Hintergrund
Einmal begann ein Gespräch mit einem Kollegen über die Verbesserung von Werkzeugen für die Arbeit mit Bit-Flags in C ++ - Enumerationen. Zu diesem Zeitpunkt hatten wir bereits die Funktion IsEnumFlagSet, die die getestete Variable als erstes Argument und die zweite zu überprüfende Gruppe von Flags verwendet. Warum ist es besser als das gute alte bitweise Und?
if (IsEnumFlagSet(state, flag)) { }
Meiner Meinung nach - Lesbarkeit. Ich arbeite im Allgemeinen selten mit Bit-Flags und Bit-Operationen. Wenn Sie also den Code eines anderen Benutzers anzeigen, ist es viel einfacher, die üblichen Funktionsnamen zu erkennen, als das kryptische & und |, das sofort das interne window.alert () mit der Überschrift „Attention! Es kann eine Art Magie passieren. “
Ein bisschen TraurigkeitLeider unterstützt C ++ immer noch keine Erweiterungsmethoden (obwohl es bereits einen
ähnlichen Vorschlag gab ) - ansonsten wäre zum Beispiel die Methode a la std :: bitset eine ideale Option:
if (state.Test(particularFlags)) {}
Insbesondere die Lesbarkeit verschlechtert sich beim Setzen oder Entfernen von Flags. Vergleichen Sie:
state |= flag;
Während der Diskussion wurde auch die Idee zum Ausdruck gebracht, die Funktion
SetEnumFlag(state, flag, isSet) : Abhängig vom dritten Argument würde
state entweder Flags
SetEnumFlag(state, flag, isSet) oder sie löschen.
Da davon ausgegangen wurde, dass dieses Argument zur
RaiseEnumFlag/ClearEnumFlag wird, können Sie im Vergleich zum
RaiseEnumFlag/ClearEnumFlag Paar nicht auf Overhead
RaiseEnumFlag/ClearEnumFlag . Aber aus Gründen des akademischen Interesses wollte ich es minimieren, indem ich
zum Teufel der Mikrooptimierungen in die
Mine hinabstieg.
Implementierung
1. Naive Umsetzung
Zuerst führen wir unsere Aufzählung ein (wir werden die Aufzählungsklasse nicht zum Vereinfachen verwenden):
#include <limits> #include <random> enum Flags : uint32_t { One = 1u << 1, Two = 1u << 2, Three = 1u << 3, OneOrThree = One | Three, Max = 1u << 31, All = std::numeric_limits<uint32_t>::max() };
Und die Implementierung selbst:
void SetFlagBranched(Flags& x, Flags y, bool cond) { if (cond) { x = Flags(x | y); } else { x = Flags(x & (~y)); } }
2. Mikrooptimierung
Die naive Implementierung hat eine offensichtliche Verzweigung, die ich sehr gerne auf das Rechnen übertragen möchte, was wir jetzt versuchen.
Zuerst müssen wir einen Ausdruck auswählen, mit dem wir basierend auf dem Parameter von einem Ergebnis zu einem anderen wechseln können. Zum Beispiel
(x | y) & ¬p
- Wenn
p = 0 die Flags:
(x | y) & ¬0 ≡ (x | y) & 1 ≡ x | y
- Wenn
p = y Flags entfernt:
(x | y) & ¬y ≡ (x & ¬y) | (y & ¬y) ≡ (x & ¬y) | 0 ≡ x & ¬y
Jetzt müssen wir die Änderung des Werts des Parameters in Abhängigkeit von der Variablen
cond irgendwie in die Arithmetik „packen“ (denken Sie daran - Verzweigung ist verboten).
Lassen Sie anfangs
p = y und, wenn
cond wahr ist, versuchen Sie,
p , wenn nicht, lassen Sie alles so, wie es ist.
Wir werden nicht in der Lage sein, direkt mit der Variablen
cond : Wenn bei der Konvertierung in den arithmetischen Typ true angegeben wird, erhalten wir nur eine Einheit in der niedrigen Reihenfolge, und im Idealfall müssen wir Einheiten in allen Bits erhalten (UPD:
Sie können immer noch ). Als Ergebnis fiel mir nichts besseres ein, als bitweise Verschiebungen vorzunehmen.
Wir definieren das Ausmaß der Verschiebung: Wir können nicht alle unsere Bits sofort verschieben, sodass der Parameter
p in einer Operation zurückgesetzt wird, da der Standard verlangt, dass das Ausmaß der Verschiebung kleiner als die Typgröße ist.
Nicht zu rechtDer Befehl zum Verschieben der Arithmetik nach links (SAL) in der ASM-Dokumentation lautet beispielsweise "Der Zählbereich ist auf 0 bis 31 begrenzt (oder 63, wenn der 64-Bit-Modus und REX.W verwendet werden)".
Daher berechnen wir die maximale Verschiebungsgröße, schreiben den vorläufigen Ausdruck
constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) * 8 - 1; (x | y) & ~ ( y >> shiftSize * cond);
Und verarbeiten Sie das niederwertige Bit des Ergebnisses des Ausdrucks
y >> shiftSize * cond :
(x | y) & ~ (( y >> shiftSize * cond) & ~cond);
Die Verzweigung wurde in
shiftSize * cond Abhängig von false oder true in cond ist der Verschiebungswert entweder 0 oder 31, und unser Parameter ist entweder gleich
y oder 0.
Was passiert wenn
shiftSize = 31 :
- Mit
cond = true verschieben wir die y Bits um 31 nach rechts, wodurch das höchstwertige Bit von y das niedrigstwertige wird und alle anderen zurückgesetzt werden. Im Gegensatz dazu ist das niedrigstwertige Bit 0 und alle anderen sind eins. Die bitweise Multiplikation dieser Werte ergibt eine saubere 0. - Wenn
cond = false keine Verschiebung auf, ~cond in allen Ziffern 1, und die bitweise Multiplikation dieser Werte ergibt y .
Ich möchte auf den Kompromiss dieses Ansatzes hinweisen, der nicht sofort offensichtlich ist: Ohne Verwendung von Verzweigungen berechnen wir
x | y x | y (d. h. einer der Zweige der naiven Version) und dann aufgrund der "zusätzlichen" arithmetischen Operationen in das gewünschte Ergebnis umwandeln. Und all dies ist sinnvoll, wenn der Mehraufwand für zusätzliche Arithmetik geringer ist als für Verzweigungen.
Die endgültige Entscheidung war also wie folgt:
void SetFlagsBranchless(Flags& x, Flags y, bool cond) { constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) * 8 - 1; x = Flags((x | y) & ~(( y >> shiftSize * cond) & ~cond)); }
(Die Verschiebungsgröße ist korrekter, um
std::numeric_limits::digits ,
siehe Kommentar )
3. Vergleich
Nachdem ich die Lösung ohne Verzweigung implementiert hatte, ging ich zu
quick-bench.com , um den Vorteil zu
überprüfen . Für die Entwicklung verwenden wir hauptsächlich clang, daher habe ich beschlossen, die Benchmarks (clang-9.0) auszuführen. Aber dann erwartete mich eine Überraschung ...
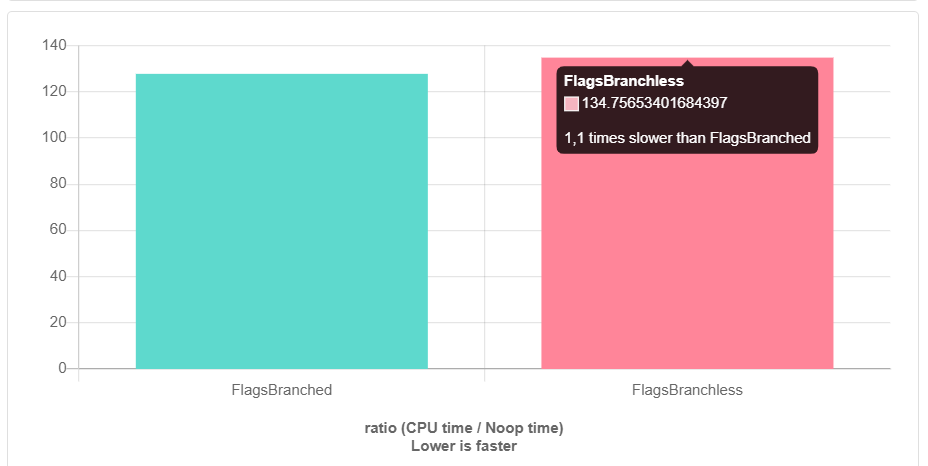
Und das ist mit -O3. Ohne Optimierungen ist es schlimmer. Wie ist es passiert? Wer ist schuld und was zu tun?
Wir befehlen, "die Panik beiseite zu legen!" Und gehen zu
godbolt.org (quick-bench bietet auch asm-Auflistung, aber godbolt sieht in dieser Hinsicht praktischer aus).
Als nächstes werden wir nur über den Optimierungsgrad -O3 sprechen. Welchen Code hat Clang für unsere naive Implementierung generiert?
SetFlagBranched(Flags&, Flags, bool): # @SetFlagBranched(Flags&, Flags, bool) mov eax, dword ptr [rdi] mov ecx, esi not ecx and ecx, eax or eax, esi test edx, edx cmove eax, ecx mov dword ptr [rdi], eax ret
Nicht schlecht, oder? Clang weiß auch, wie man einen Kompromiss eingeht, und versteht, dass es schneller sein wird, bedingte Sprungbefehle zu verwenden, um
beide Zweige zu berechnen und den bedingten Verschiebebefehl zu verwenden, der
keine Verzweigungsvorhersage in die Arbeit
einbezieht .
Verzweigungsloser Implementierungscode:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool) mov eax, dword ptr [rdi] or eax, esi test edx, edx mov ecx, 31 cmove ecx, edx shr esi, cl not esi or esi, edx and esi, eax mov dword ptr [rdi], esi ret
Fast „verzweigungslos“ - ich habe hier sozusagen die übliche Multiplikation angeordnet, und Sie, mein Freund, haben einen bedingten Zug ausgeführt. Vielleicht hat der Compiler recht, und test + cmove ist in diesem Fall schneller als imul, aber ich bin nicht so gut im Assembler (sachkundige Leute, sag es mir bitte in den Kommentaren).
Interessant ist auch, dass bei beiden Implementierungen nach Optimierungen der Compiler nicht genau das generiert hat, was wir angefordert haben, und dass wir dadurch etwas dazwischen bekommen haben: cmove wird in beiden Varianten verwendet, wir haben nur eine Menge zusätzlicher Arithmetik in der branchless-Implementierung, die den Benchmark überfordert.
Clang der achten und älteren Version verwendet im Allgemeinen echte bedingte Übergänge, „aufgrund derer“ die „verzweigungslose“ Version fast eineinhalb Mal langsamer wird:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool) mov eax, dword ptr [rdi] or eax, esi mov cl, 31 test edx, edx jne .LBB0_2 xor ecx, ecx .LBB0_2: shr esi, cl not esi or esi, edx and eax, esi mov dword ptr [rdi], eax ret
Welche Schlussfolgerung kann gezogen werden? Neben dem offensichtlichen Hinweis, dass Sie die Mikrooptimierung nicht unnötig durchführen sollten, es sei denn, Sie können Ihnen raten, immer das Ergebnis der Arbeit mit Maschinencode zu überprüfen. Es kann sich herausstellen, dass der Compiler die ursprüngliche Version bereits ausreichend optimiert hat und dass Ihre „genialen“ Optimierungen dies nicht verstehen und Sie darüber nachdenken werden Übergänge statt Multiplikationen.
An diesem Punkt wäre es möglich zu beenden, wenn nicht für ein "aber". Der gcc-Code für die naive Implementierung ist identisch mit dem Clang-Code, aber die verzweigungslose Version ist ..:
SetFlag(Flags&, Flags, bool): movzx edx, dl mov eax, esi or eax, DWORD PTR [rdi] mov ecx, edx sal ecx, 5 sub ecx, edx shr esi, cl not esi or esi, edx and esi, eax mov DWORD PTR [rdi], esi ret
Ich respektiere die Entwickler für eine so elegante Art und Weise, unseren Ausdruck zu optimieren, ohne entweder
imul oder
cmove . Was passiert hier: Die Bool-Variable cond wird bitweise um 5 Zeichen nach links verschoben (weil der Typ unserer Aufzählung uint32_t ist, ihre Größe 32 Bit, das heißt 100000
2 ) und dann vom Ergebnis subtrahiert. Somit erhalten wir im Fall von cond = true 11111
2 = 31
10 und andernfalls 0. Selbstverständlich ist eine solche Option schneller als die naive, auch unter Berücksichtigung der bedingten Bewegungsoptimierung?

Nun, das Ergebnis war sehr merkwürdig - je nach Compiler kann die Option ohne Verzweigungen schneller oder langsamer sein als die Implementierung mit Verzweigungen. Versuchen wir, unseren Ausdruck mit der gcc-Methode zu klingeln und zu transformieren (vereinfachen wir gleichzeitig den Teil
~((y >> shiftSize * cond) & ~cond) nach de Morgan - dies geschieht sowohl mit clang als auch mit gcc):
void SetFlagVerbose(Flags& x, Flags y, bool b) { constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) + 1; x = Flags( (x | y) & ( ~(y >> ((b << shiftSize) - b)) | b) ); }
Ein solcher Hinweis wirkt sich nur auf die Trunk-Version von clang aus, bei der tatsächlich Code ähnlich wie bei gcc generiert wird (obwohl es sich bei dem ursprünglichen "branchless" um denselben Test + cmove handelt).
Was ist mit MSVC? In beiden Versionen wird ohne Verzweigung "honest imul" verwendet (ich weiß nicht, wie viel schneller / langsamer als die Option "clang / gcc" ist - quick-bench unterstützt diesen Compiler nicht). In der naiven Version ist "conditional jump" aufgetreten. Traurig aber wahr.
Zusammenfassung
Die Hauptschlussfolgerung lässt sich vielleicht so fassen, dass die Absichten des Programmierers in Code auf hoher Ebene sich nicht immer in Maschinencode widerspiegeln. Dies macht Mikrooptimierungen ohne Benchmarks und Anzeigen von Auflistungen sinnlos. Darüber hinaus kann das Ergebnis von Mikrooptimierungen entweder besser oder schlechter als die übliche Version sein - es hängt alles vom Compiler ab, was ein ernstes Problem sein kann, wenn das Projekt plattformübergreifend ist.