Die Komplexität der Interpretation seismischer Daten beruht auf der Tatsache, dass für jede Aufgabe ein individueller Ansatz gesucht werden muss, da jeder Satz solcher Daten einzigartig ist. Die manuelle Verarbeitung erfordert erhebliche Arbeitskosten, und das Ergebnis enthält häufig Fehler, die sich auf den menschlichen Faktor beziehen. Die Verwendung neuronaler Netze zur Interpretation kann die manuelle Arbeit erheblich reduzieren, die Eindeutigkeit der Daten schränkt jedoch die Automatisierung dieser Arbeit ein.
Dieser Artikel beschreibt ein Experiment zur Analyse der Anwendbarkeit neuronaler Netze zur Automatisierung der Zuordnung geologischer Schichten in 2D-Bildern am Beispiel vollständig beschrifteter Daten aus der Nordsee.
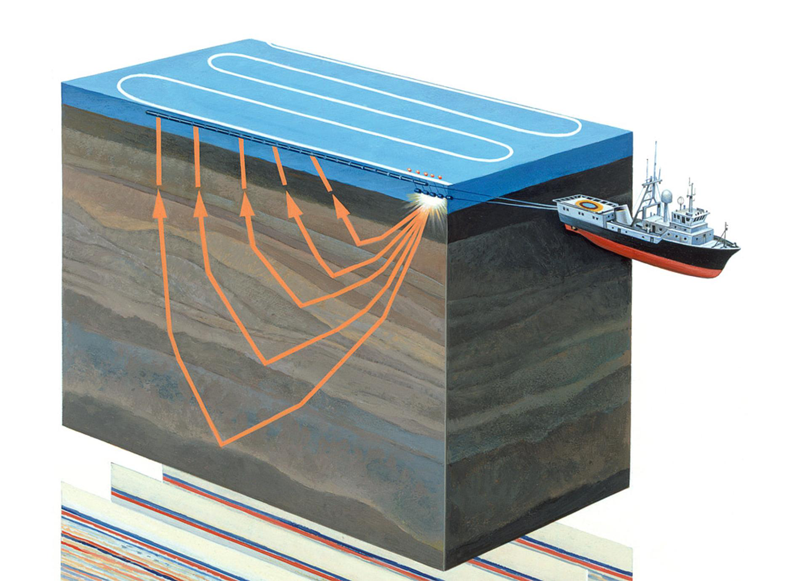
Abbildung 1. Aquatorial Seismic Surveys (
Quelle )
Ein bisschen über den Themenbereich
Die seismische Erkundung ist eine geophysikalische Methode zur Untersuchung von geologischen Objekten mit Hilfe von elastischen Schwingungen - seismischen Wellen. Diese Methode basiert auf der Tatsache, dass die Ausbreitungsgeschwindigkeit von seismischen Wellen von den Eigenschaften der geologischen Umgebung abhängt, in der sie sich ausbreiten (Gesteinszusammensetzung, Porosität, Bruch, Feuchtigkeitssättigung usw.). Durch geologische Schichten mit unterschiedlichen Eigenschaften werden seismische Wellen reflektiert verschiedene Objekte und zurück zum Empfänger (siehe Abbildung 1). Ihre Art wird aufgezeichnet und nach der Verarbeitung können Sie ein zweidimensionales Bild - einen seismischen Abschnitt oder ein dreidimensionales Datenarray - einen seismischen Würfel erstellen.
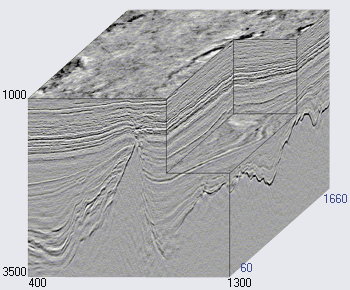
Abbildung 2. Ein Beispiel für einen seismischen Würfel (
Quelle )
Die horizontale Achse des seismischen Würfels befindet sich entlang der Erdoberfläche und die vertikale Achse repräsentiert die Tiefe oder Zeit (siehe Abbildung 2). In einigen Fällen ist der Würfel in vertikale Abschnitte entlang der Achse der Geophone (sogenannte Inlines, Inlines) oder quer (Crosslines, Crosslines, Xlines) unterteilt. Jede Würfelvertikale (und Scheibe) ist eine separate seismische Spur.
Inlines und Crosslines bestehen also aus denselben seismischen Spuren, nur in einer anderen Reihenfolge. Die angrenzenden seismischen Pfade sind einander sehr ähnlich. Eine dramatischere Änderung tritt an den Fehlerpunkten auf, es wird jedoch immer noch Ähnlichkeiten geben. Dies bedeutet, dass benachbarte Schichten einander sehr ähnlich sind.
All dieses Wissen wird uns bei der Planung von Experimenten nützlich sein.
Die Interpretationsaufgabe und die Rolle neuronaler Netze in ihrer Lösung
Die erhaltenen Daten werden manuell von Dolmetschern verarbeitet, die direkt auf dem Würfel oder an jeder Scheibe die einzelnen geologischen Gesteinsschichten und deren Grenzen (Horizonte, Horizonte), Salzablagerungen, Verwerfungen und andere Merkmale der geologischen Struktur des untersuchten Gebiets identifizieren. Der Dolmetscher, der mit einem Würfel oder einer Scheibe arbeitet, beginnt seine Arbeit mit der sorgfältigen manuellen Auswahl geologischer Schichten und Horizonte. Jeder Horizont muss manuell ausgewählt werden (aus der englischen Sammlung "picking"), indem Sie mit dem Mauszeiger darauf zeigen und mit der Maus klicken.
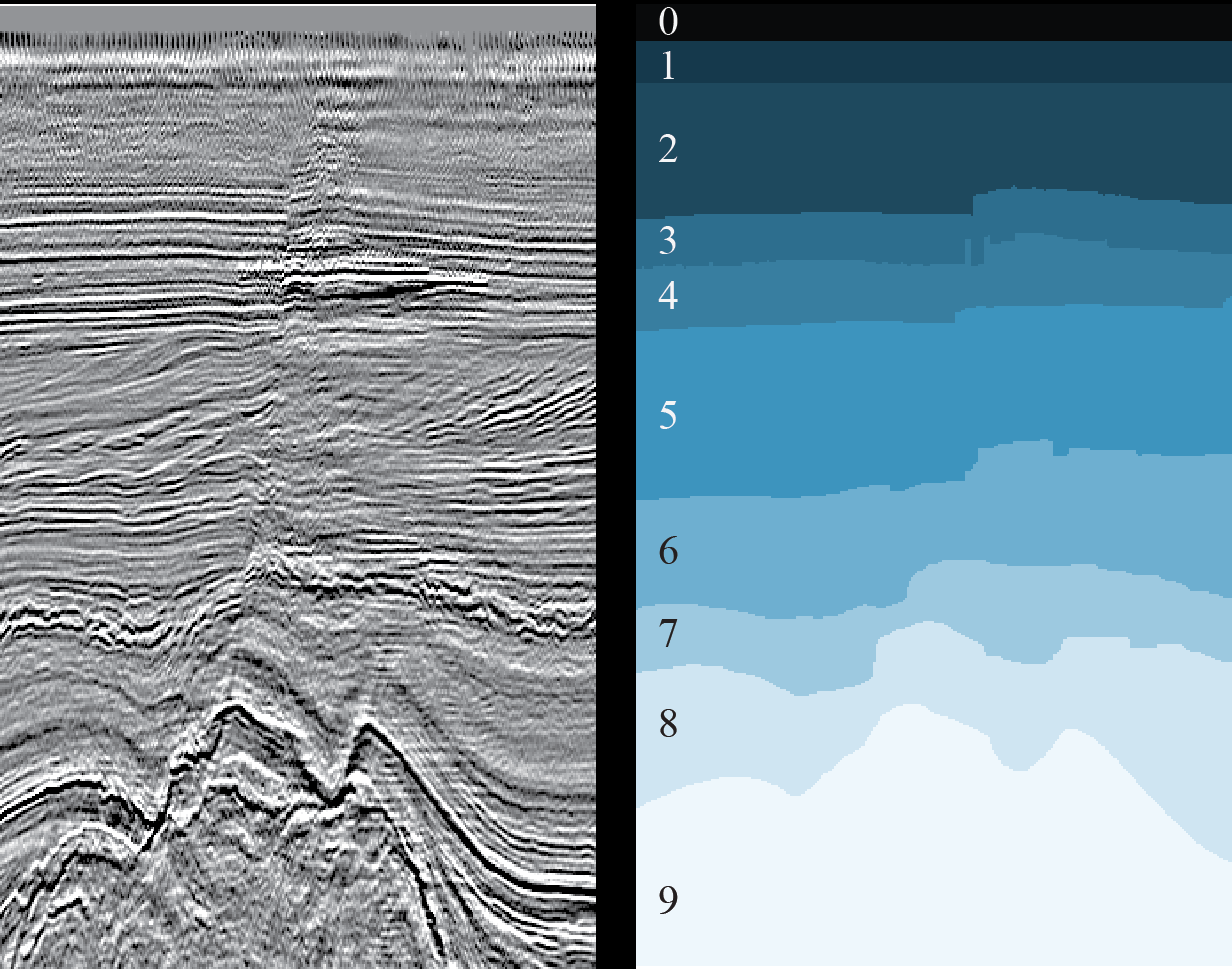
Abbildung 3. Ein Beispiel für einen 2D-Schnitt (links) und das Ergebnis der Markierung der entsprechenden geologischen Schichten (rechts) (
Quelle )
Das Hauptproblem hängt mit der zunehmenden Menge an seismischen Daten zusammen, die jedes Jahr unter immer komplexeren geologischen Bedingungen (z. B. Unterwasserabschnitten mit großen Meerestiefen) erfasst werden, und mit der Mehrdeutigkeit der Interpretation dieser Daten. Darüber hinaus macht der Dolmetscher bei engen Fristen und / oder großen Mengen unvermeidlich Fehler, z. B. verfehlt er verschiedene Merkmale des geologischen Abschnitts.
Dieses Problem kann teilweise mit Hilfe neuronaler Netze gelöst werden, wodurch die manuelle Arbeit erheblich reduziert wird, wodurch der Interpretationsprozess beschleunigt und die Anzahl der Fehler verringert wird. Für den Betrieb des neuronalen Netzes ist eine bestimmte Anzahl von vorgefertigten, beschrifteten Abschnitten (Abschnitten des Würfels) erforderlich, und als Ergebnis wird eine vollständige Markierung aller Abschnitte (oder des gesamten Würfels) erhalten, was idealerweise nur eine geringfügige Verfeinerung durch eine Person erfordert, um bestimmte Abschnitte des Horizonts anzupassen oder kleine Bereiche, die neu zu markieren Das Netzwerk konnte nicht richtig erkennen.
Es gibt viele Lösungen für die Interpretationsprobleme mit neuronalen Netzen, hier nur einige Beispiele:
eins ,
zwei ,
drei . Die Schwierigkeit liegt in der Tatsache, dass jeder Datensatz einzigartig ist - aufgrund der Besonderheiten der geologischen Gesteine der untersuchten Region, aufgrund verschiedener technischer Mittel und Methoden der seismischen Erkundung, aufgrund der verschiedenen Methoden, mit denen Rohdaten in vorgefertigte umgewandelt werden. Auch wegen äußerer Geräusche (zum Beispiel ein Hundebellen und andere laute Geräusche), die nicht immer vollständig beseitigt werden können. Daher muss jede Aufgabe einzeln gelöst werden.
Trotzdem lassen sich mit zahlreichen Arbeiten unterschiedliche allgemeine Lösungsansätze für verschiedene Interpretationsprobleme finden.
Wir bei
MaritimeAI (ein Projekt, das aus der
ODS-Community für maschinelles Lernen für soziale Güter
entwickelt wurde ,
ein Artikel über uns ) studieren für jede Zone unseres Interessengebiets (Meeresforschung) bereits veröffentlichte Arbeiten und führen unsere eigenen Experimente durch, um die Grenzen und Merkmale der Anwendung bestimmter zu klären Lösungen, und manchmal finden Sie Ihre eigenen Ansätze.
Die Ergebnisse eines Experiments beschreiben wir in diesem Artikel.
Unternehmensforschungsziele
Für einen Data Science-Spezialisten ist es ausreichend, einen Blick auf Abbildung 3 zu werfen, um aufatmen zu können - eine häufige Aufgabe der semantischen Bildsegmentierung, für die viele neuronale Netzwerkarchitekturen und Lehrmethoden erfunden wurden. Sie müssen nur die richtigen auswählen und das Netzwerk trainieren.
Aber nicht so einfach.
Um mit Hilfe eines neuronalen Netzwerks ein gutes Ergebnis zu erzielen, benötigen Sie so viele bereits markierte Daten, wie es lernen wird. Unsere Aufgabe ist es aber gerade, den manuellen Aufwand zu reduzieren. Und aufgrund der starken Unterschiede in der geologischen Struktur ist es selten möglich, markierte Daten aus anderen Regionen zu verwenden.
Wir übersetzen das oben Genannte in die Geschäftssprache.
Damit die Verwendung neuronaler Netze wirtschaftlich gerechtfertigt ist, muss der Umfang der primären manuellen Interpretation und der Verfeinerung der erzielten Ergebnisse minimiert werden. Das Reduzieren der Daten für das Training des Netzwerks wirkt sich jedoch negativ auf die Qualität des Ergebnisses aus. Kann ein neuronales Netzwerk also die Arbeit der Dolmetscher beschleunigen und erleichtern und die Qualität der beschrifteten Bilder verbessern? Oder komplizieren Sie einfach den üblichen Prozess?
Das Ziel dieser Studie ist es, das minimale ausreichende Volumen von markierten seismischen Würfeldaten für ein neuronales Netzwerk zu bestimmen und die erzielten Ergebnisse auszuwerten. Wir haben versucht, Antworten auf die folgenden Fragen zu finden, die den "Eigentümern" der Ergebnisse der seismischen Untersuchung bei der Entscheidung für eine manuelle oder teilweise automatisierte Interpretation helfen sollen:
- Wie viele Daten benötigen Experten, um ein neuronales Netzwerk zu trainieren? Und welche Daten sollten dafür ausgewählt werden?
- Was passiert bei einem solchen Ausgang? Wird eine manuelle Verfeinerung der Vorhersagen für neuronale Netze erforderlich sein? Wenn ja, wie komplex und umfangreich?
Allgemeine Beschreibung des Versuchs und der verwendeten Daten
Für das Experiment haben wir eines der Interpretationsprobleme ausgewählt, nämlich die Aufgabe, geologische Schichten auf 2D-Schnitten eines seismischen Würfels zu isolieren (siehe Abbildung 3). Wir haben bereits versucht, dieses Problem zu lösen (siehe
hier ) und laut den Autoren ein gutes Ergebnis für 1% der zufällig ausgewählten Scheiben erzielt. Bei der Größe des Würfels handelt es sich um 16 Bilder. Der Artikel enthält jedoch keine Metriken zum Vergleich und es gibt keine Beschreibung der Trainingsmethodik (Verlustfunktion, Optimierer, Schema zum Ändern der Lerngeschwindigkeit usw.), wodurch das Experiment nicht reproduzierbar wird.
Darüber hinaus reichen die dort präsentierten Ergebnisse unserer Meinung nach nicht aus, um eine vollständige Antwort auf die gestellten Fragen zu erhalten. Ist dieser Wert bei 1% optimal? Oder vielleicht für eine andere Probe von Scheiben wird es anders sein? Kann ich weniger Daten auswählen? Lohnt es sich, mehr zu nehmen? Wie wird sich das Ergebnis ändern? Usw.
Für das Experiment haben wir denselben Satz vollständig gekennzeichneter Daten aus dem niederländischen Sektor der Nordsee verwendet. Die seismischen Quelldaten sind auf der Website von Open Seismic Repository:
Project Netherlands Offshore F3 Block verfügbar. Eine kurze Beschreibung findet sich bei
Silva et al. "Niederländischer Datensatz: Ein neuer öffentlicher Datensatz für maschinelles Lernen in der seismischen Interpretation .
"Da es sich in unserem Fall um 2D-Schnitte handelt, haben wir nicht den ursprünglichen 3D-Würfel verwendet, sondern das bereits erstellte „Slicing“, das hier verfügbar ist:
Netherlands F3 Interpretation Dataset .
Während des Experiments haben wir folgende Aufgaben gelöst:
- Wir haben uns die Quelldaten angesehen und die Scheiben ausgewählt, deren Qualität der manuellen Markierung am nächsten kommt.
- Wir haben die Architektur des neuronalen Netzwerks, die Methodik und die Parameter des Trainings sowie das Prinzip der Auswahl von Schichten für das Training und die Validierung aufgezeichnet.
- Zum Vergleich der Ergebnisse haben wir 20 identische neuronale Netze auf verschiedenen Datenmengen desselben Scheibentyps trainiert.
- Wir haben weitere 20 neuronale Netze auf eine unterschiedliche Datenmenge verschiedener Arten von Schichten trainiert, um die Ergebnisse zu vergleichen.
- Geschätzter Umfang der erforderlichen manuellen Verfeinerung der Prognoseergebnisse.
Die Ergebnisse des Experiments in Form von geschätzten Metriken, die von den Netzwerken der Schnittmasken vorhergesagt werden, sind nachstehend aufgeführt.
Aufgabe 1. Datenauswahl
Als Ausgangsdaten verwendeten wir fertige Inlines und Crosslines des seismischen Würfels aus dem niederländischen Sektor der Nordsee. Eine detaillierte Analyse ergab, dass nicht alles reibungslos funktioniert - es gibt viele Bilder und Masken mit Artefakten und sogar stark verzerrten Bildern (siehe Abbildungen 4 und 5).

Abbildung 4. Beispielmaske mit Artefakten
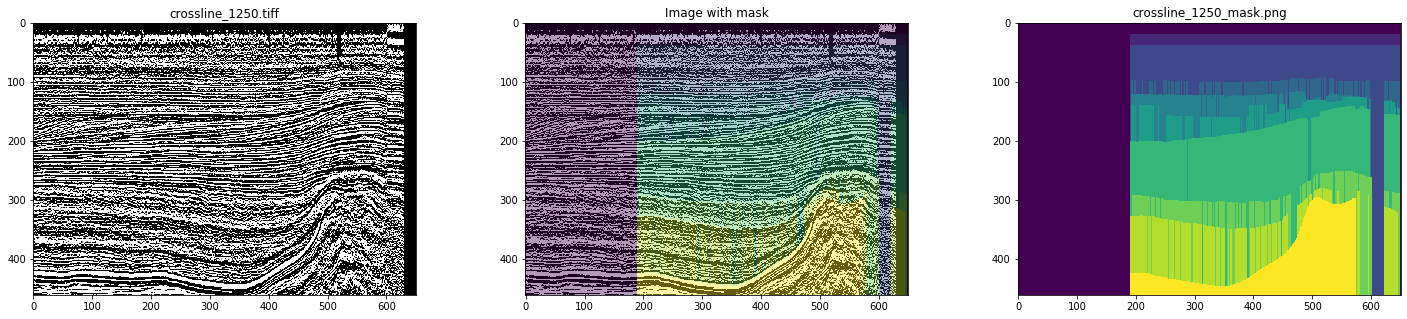
Abbildung 5. Ein Beispiel für eine verzerrte Maske
Bei manueller Kennzeichnung wird nichts dergleichen beachtet. Um die Arbeit des Dolmetschers zu simulieren und das Netzwerk zu trainieren, wählten wir daher nur saubere Masken, nachdem wir uns alle Schichten angesehen hatten. Als Ergebnis wurden 700 Kreuzlinien und 400 Inlines ausgewählt.
Aufgabe 2. Die Parameter des Experiments festlegen
Dieser Abschnitt ist in erster Linie für Spezialisten der Datenwissenschaft von Interesse, daher wird eine geeignete Terminologie verwendet.
Da Inlines und Crosslines aus denselben seismischen Spuren bestehen, können zwei sich gegenseitig ausschließende Hypothesen aufgestellt werden:
- Das Training kann nur für einen Scheibentyp (z. B. Inlines) durchgeführt werden, wobei Bilder eines anderen Typs als verzögerte Auswahl verwendet werden. Dies wird eine angemessenere Bewertung des Ergebnisses geben, weil Die verbleibenden Scheiben desselben Typs, die für das Training verwendet wurden, sind denen für das Training weiterhin ähnlich.
- Für das Training ist es besser, eine Mischung aus Scheiben verschiedener Arten zu verwenden, da dies eine fertige Ergänzung ist.
Probieren Sie es aus.
Darüber hinaus führten die Ähnlichkeit benachbarter Schichten desselben Typs und der Wunsch, ein reproduzierbares Ergebnis zu erzielen, zu einer Strategie zur Auswahl von Schichten für das Training und die Validierung, und zwar nicht nach einem willkürlichen Prinzip, sondern gleichmäßig über den gesamten Würfel, d.h. Damit die Slices so weit wie möglich voneinander entfernt sind und somit die größtmögliche Datenvielfalt abdecken.
Zur Validierung wurden 2 Schnitte verwendet, die ebenfalls gleichmäßig auf benachbarte Bilder der Trainingsprobe verteilt waren. Für den Fall einer Trainingsstichprobe von 3 Inlines bestand die Validierungsstichprobe beispielsweise aus 4 Inlines für 3 Inlines und 3 Crosslines für 8 Slices.
Aus diesem Grund haben wir zwei Schulungsreihen durchgeführt:
- Schulung an Inline-Mustern von 3 bis 20 Slices, die gleichmäßig über den Cube verteilt sind, mit Überprüfung des Ergebnisses der Netzwerkvorhersagen für die verbleibenden Inlines und für alle Crosslines. Zusätzlich wurden Schulungen in 80 und 160 Abschnitten durchgeführt.
- Training in kombinierten Stichproben aus Inlines und Crosslines von 3-10 Abschnitten jedes Typs, die gleichmäßig über einen Würfel verteilt sind, mit Überprüfung des Ergebnisses der Netzwerkvorhersagen in den verbleibenden Bildern. Zusätzlich wurden Schulungen zu 40 + 40 und 80 + 80 Abschnitten durchgeführt.
Bei diesem Ansatz muss berücksichtigt werden, dass die Größen der Trainings- und Validierungsstichproben erheblich variieren, was den Vergleich erschwert, aber das Volumen der verbleibenden Bilder wird nicht so stark reduziert, dass Änderungen des Ergebnisses angemessen bewertet werden können.
Um die Umschulung für die Trainingsstichprobe zu reduzieren, wurde eine Augmentation mit einer willkürlichen Fruchtgröße von 448 × 64 und einem Spiegelbild entlang der vertikalen Achse mit einer Wahrscheinlichkeit von 0,5 verwendet.
Da es uns nur um die Abhängigkeit der Qualität des Ergebnisses von der Anzahl der Schnitte im Trainingsmuster geht, kann die Vorverarbeitung der Bilder vernachlässigt werden. Wir haben eine einzelne Schicht von PNG-Bildern ohne Änderungen verwendet.
Aus dem gleichen Grund muss im Rahmen dieses Experiments nicht nach der besten Netzwerkarchitektur gesucht werden - Hauptsache, sie muss bei jedem Schritt gleich sein. Wir haben eine einfache, aber gut etablierte UNet für diese Aufgaben ausgewählt:

Abbildung 6. Netzwerkarchitektur
Die Verlustfunktion bestand aus einer Kombination des Jacquard-Koeffizienten und der binären Kreuzentropie:
def jaccard_loss(y_true, y_pred): smoothing = 1. intersection = tf.reduce_sum(y_true * y_pred, axis = (1, 2)) union = tf.reduce_sum(y_true + y_pred, axis = (1, 2)) jaccard = (intersection + smoothing) / (union - intersection + smoothing) return 1. - tf.reduce_mean(jaccard) def loss(y_true, y_pred): return 0.75 * jaccard_loss(y_true, y_pred) + 0.25 * keras.losses.binary_crossentropy(y_true, y_pred)
Andere Lernoptionen:
keras.optimizers.SGD(lr = 0.01, momentum = 0.9, nesterov = True) keras.callbacks.EarlyStopping(monitor = 'val_loss', patience = 10), keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', patience = 5)
Um den Einfluss der Zufälligkeit der Wahl der Anfangsgewichte auf die Ergebnisse zu verringern, wurde das Netzwerk für eine Ära an 3 Inlines trainiert. Alle anderen Trainingseinheiten begannen mit diesen erhaltenen Gewichten.
Jedes Netzwerk wurde auf der GeForce GTX 1060 6Gb für 30-60 Epochen trainiert. Das Training jeder Epoche dauerte je nach Stichprobengröße 10 bis 30 Sekunden.
Aufgabe 3. Training auf einem Scheibentyp (Inlines)
Die erste Serie bestand aus 18 unabhängigen Netzwerktrainings mit 3 bis 20 Inlines. Und obwohl wir nur daran interessiert sind, den Jacquard-Koeffizienten für Scheiben zu schätzen, die nicht für Training und Validierung verwendet werden, ist es interessant, alle Diagramme zu betrachten.
Es sei daran erinnert, dass die Interpretationsergebnisse für jede Schicht 10 Klassen (geologische Schichten) sind, die in den Figuren weiterhin mit Zahlen von 0 bis 9 gekennzeichnet sind.

Abbildung 7. Jacquard-Koeffizient für das Trainingsset

Abbildung 8. Jacquard-Koeffizient für die Validierungsprobe
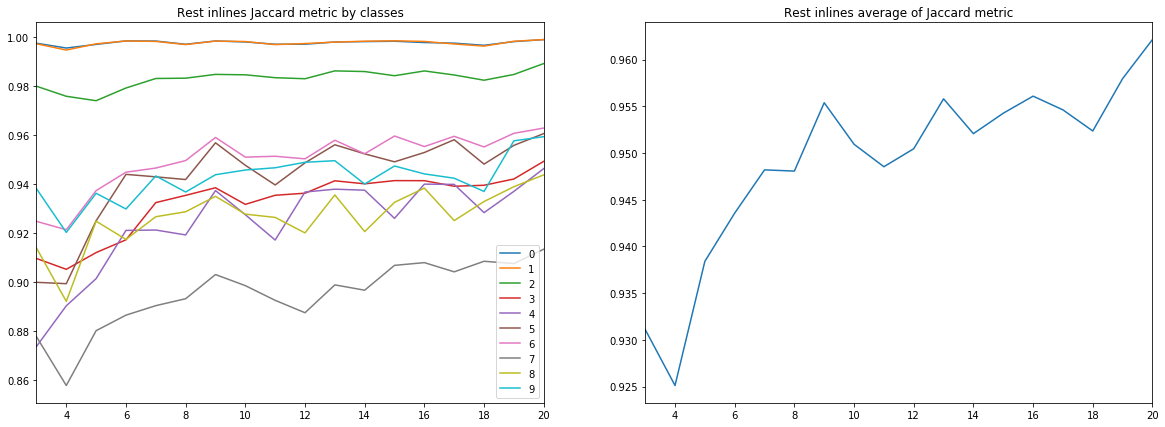
Abbildung 9. Jacquard-Koeffizient für die verbleibenden Inlines
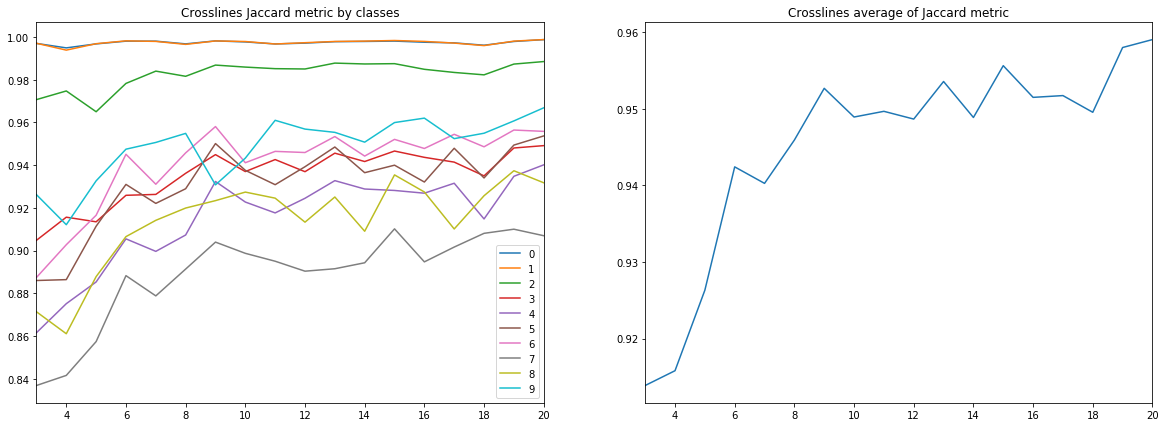
Abbildung 10. Jacquard-Koeffizient für Querlinien
Aus den obigen Diagrammen können eine Reihe von Schlussfolgerungen gezogen werden.
Erstens erreicht die Prognosequalität, gemessen am Jacquard-Koeffizienten, bereits bei 9 Inlines einen sehr hohen Wert, wonach sie weiter wächst, jedoch nicht so intensiv. Das heißt Die Hypothese, dass nur wenige markierte Bilder für das Training eines neuronalen Netzwerks ausreichen, wird bestätigt.
Zweitens wurde trotz der Tatsache, dass nur Inlines für die Schulung und Validierung verwendet wurden, ein sehr hohes Ergebnis für Kreuzlinien erzielt - die Hypothese, dass nur ein Scheibentyp ausreicht, wird ebenfalls bestätigt. Für die endgültige Schlussfolgerung müssen Sie jedoch die Ergebnisse mit dem Training an einer Mischung aus Inlines und Crosslines vergleichen.
Drittens Metriken für verschiedene Schichten, d.h. Die Qualität ihrer Anerkennung ist sehr unterschiedlich. Dies führt zu der Idee, eine andere Lernstrategie zu wählen, z. B. Gewichte oder zusätzliche Netzwerke für schwache Klassen oder ein vollwertiges „one vs all“ -Schema.
Abschließend ist anzumerken, dass der Jacquard-Koeffizient keine vollständige Beschreibung der Qualität des Ergebnisses liefern kann. Um in diesem Fall die Netzwerkvorhersagen zu bewerten, ist es besser, die Masken selbst zu betrachten, um ihre Eignung für die Überarbeitung durch den Interpreter zu bewerten.
Die folgenden Abbildungen zeigen das Markup eines auf 10 Inlines trainierten Netzwerks. Die zweite Spalte mit der Bezeichnung „GT-Maske“ (Ground Truth Mask) stellt die Zielinterpretation dar, die dritte die Vorhersage des neuronalen Netzes.


Abbildung 11. Beispiele für Netzwerkvorhersagen für Inlines
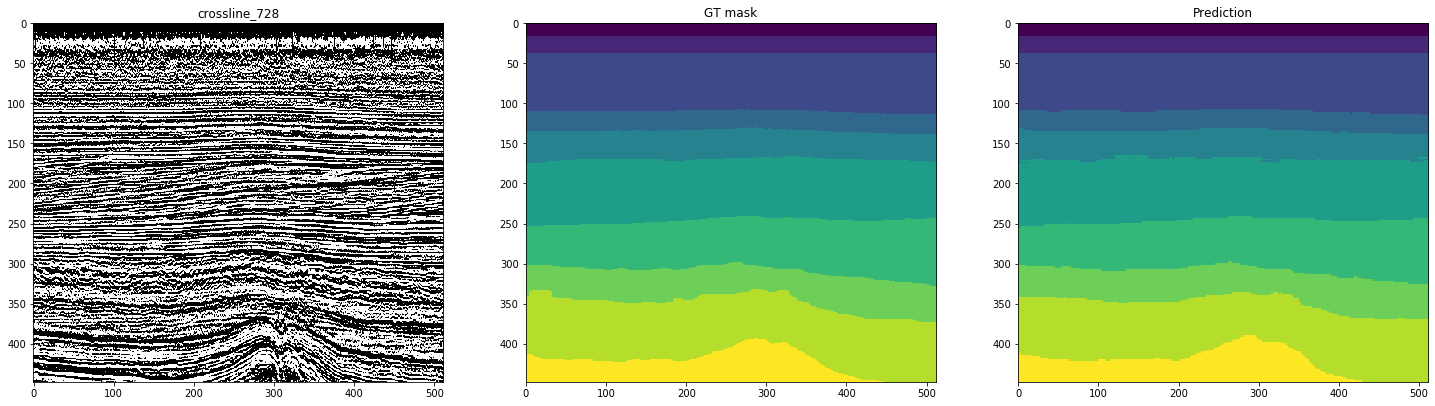

Abbildung 12. Beispiele für Netzwerkvorhersagen für Querlinien
Den Zahlen ist zu entnehmen, dass das Netzwerk zusammen mit relativ sauberen Masken selbst an den Inlines selbst nur schwer komplexe Fälle erkennen kann. Daher muss ein Teil der Ergebnisse trotz der ausreichend hohen Metrik für 10 Slices erheblich verfeinert werden.
Die von uns berücksichtigten Stichprobengrößen schwanken um 1% des gesamten Datenvolumens - und dies ermöglicht es bereits, einen Teil der verbleibenden Schnitte recht gut zu markieren. Sollte ich die Anzahl der ursprünglich markierten Abschnitte erhöhen? Wird dies zu einer vergleichbaren Qualitätssteigerung führen?
Betrachten Sie die Dynamik von Änderungen in den Prognoseergebnissen durch Netzwerke, die auf 5, 10, 15, 20, 80 (5% des Gesamtvolumens des Cubes) und 160 (10%) Inlines trainiert wurden, indem Sie dieselben Abschnitte als Beispiel verwenden.
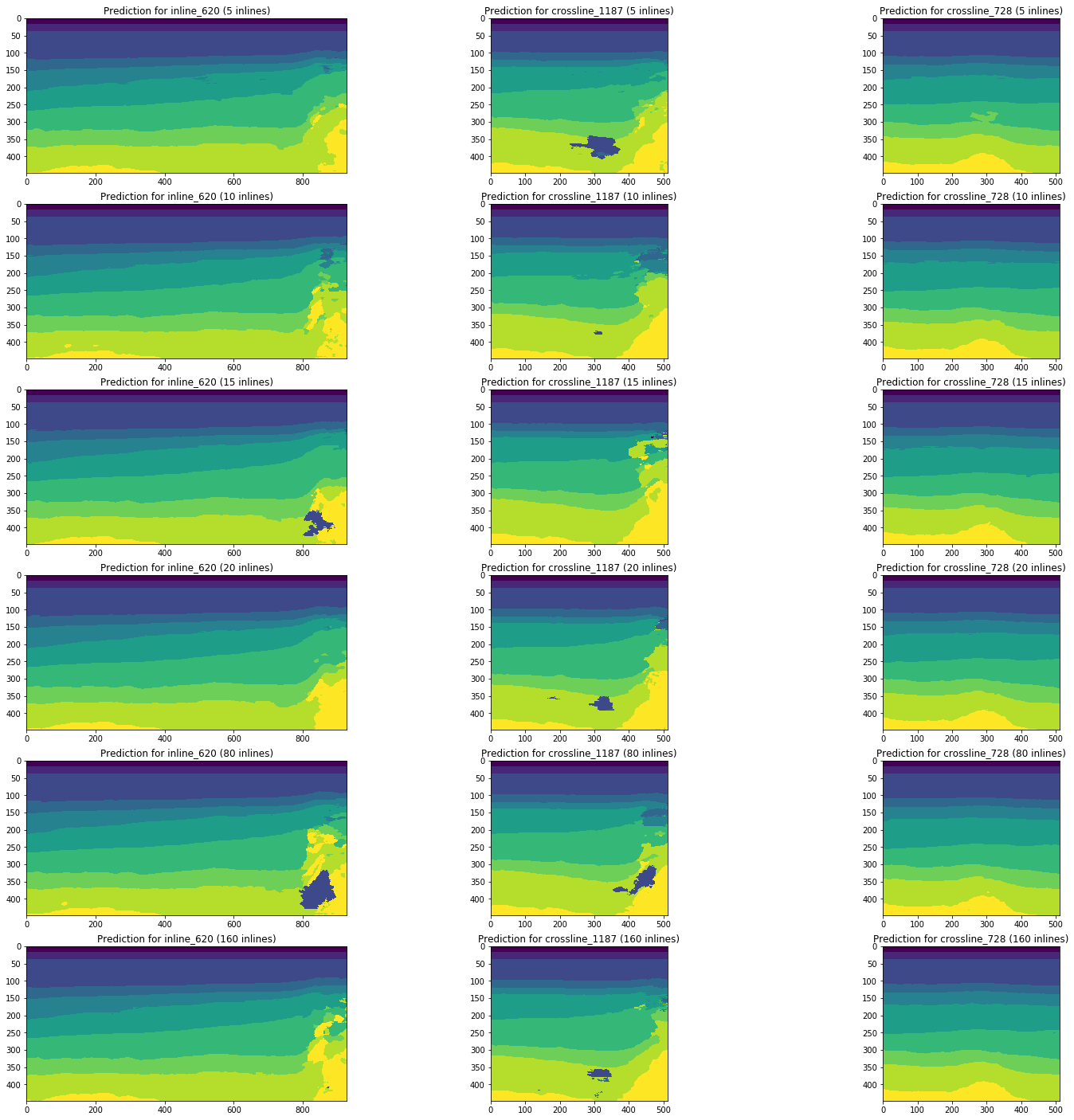
Abbildung 13. Beispiele für Vorhersagen von Netzwerken, die auf verschiedenen Volumina der Trainingsstichprobe trainiert wurden
Abbildung 13 zeigt, dass eine Erhöhung des Volumens der Trainingsstichprobe um das Fünffache oder gar das Zehnfache keine signifikante Verbesserung bewirkt. Scheiben, die in 10 Trainingsbildern bereits gut erkannt werden, werden nicht schlechter.
Somit kann auch ein einfaches Netzwerk ohne Anpassung und Vorverarbeitung von Bildern einen Teil der Schnitte mit einer ausreichend hohen Qualität mit einer geringen Anzahl von manuell markierten Bildern interpretieren. Wir werden die Frage des Anteils solcher Interpretationen und die Komplexität der Fertigstellung von schlecht erkannten Schnitten betrachten.
Die sorgfältige Auswahl der Architektur, der Netzwerkparameter und des Trainings sowie die Bildvorverarbeitung können diese Ergebnisse bei gleichem Datenvolumen verbessern. Dies geht aber bereits über den Rahmen des aktuellen Experiments hinaus.
Aufgabe 4. Training auf verschiedenen Arten von Schnitten (Inlines und Crosslines)
Vergleichen wir nun die Ergebnisse dieser Reihe mit den Prognosen, die durch Training an einer Mischung aus Inlines und Crosslines erhalten wurden.
Die nachstehenden Diagramme zeigen Schätzungen des Jacquard-Koeffizienten für verschiedene Proben, einschließlich im Vergleich zu den Ergebnissen der vorhergehenden Reihen. Zum Vergleich (siehe die rechten Diagramme in den Figuren) wurden nur Proben desselben Volumens entnommen, d.h. 10 Inlines vs 5 Inlines + 5 Crosslines usw.

Abbildung 14. Jacquard-Koeffizient für das Trainingsset

Abbildung 15. Jacquard-Koeffizient für die Validierungsprobe

Abbildung 16. Jacquard-Koeffizient für die verbleibenden Inlines

Abbildung 17. Jacquard-Koeffizient für die verbleibenden Querlinien
Die Diagramme veranschaulichen deutlich, dass das Hinzufügen von Slices eines anderen Typs die Ergebnisse nicht verbessert. Auch im Kontext von Klassen (siehe Abbildung 18) wird bei keiner der betrachteten Stichprobengrößen der Einfluss von Kreuzlinien beobachtet.

Abbildung 18. Jacquard-Koeffizient für verschiedene Klassen (entlang der X-Achse) und verschiedene Größen und Zusammensetzungen der Trainingsstichprobe
Um das Bild zu vervollständigen, vergleichen wir die Ergebnisse der Netzwerkprognose in denselben Schichten:
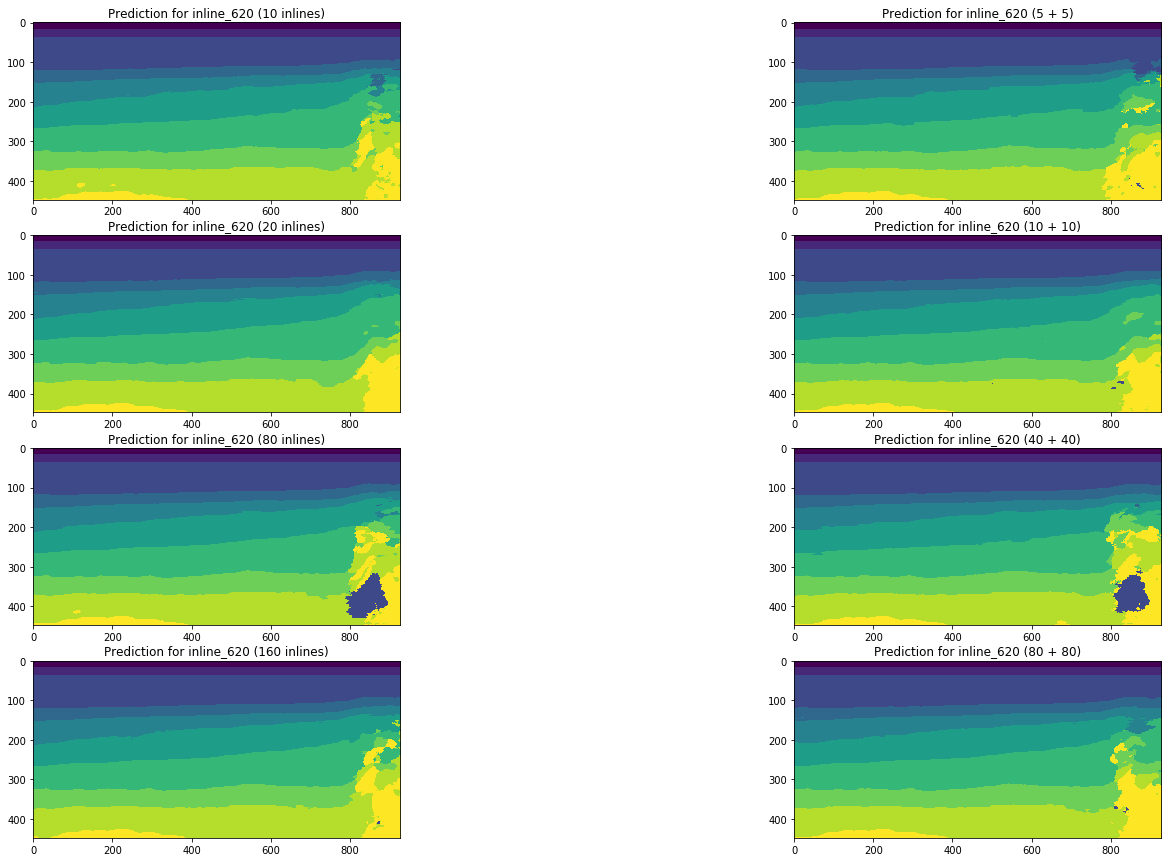
Abbildung 19. Vergleich der Netzwerkvorhersagen für Inline
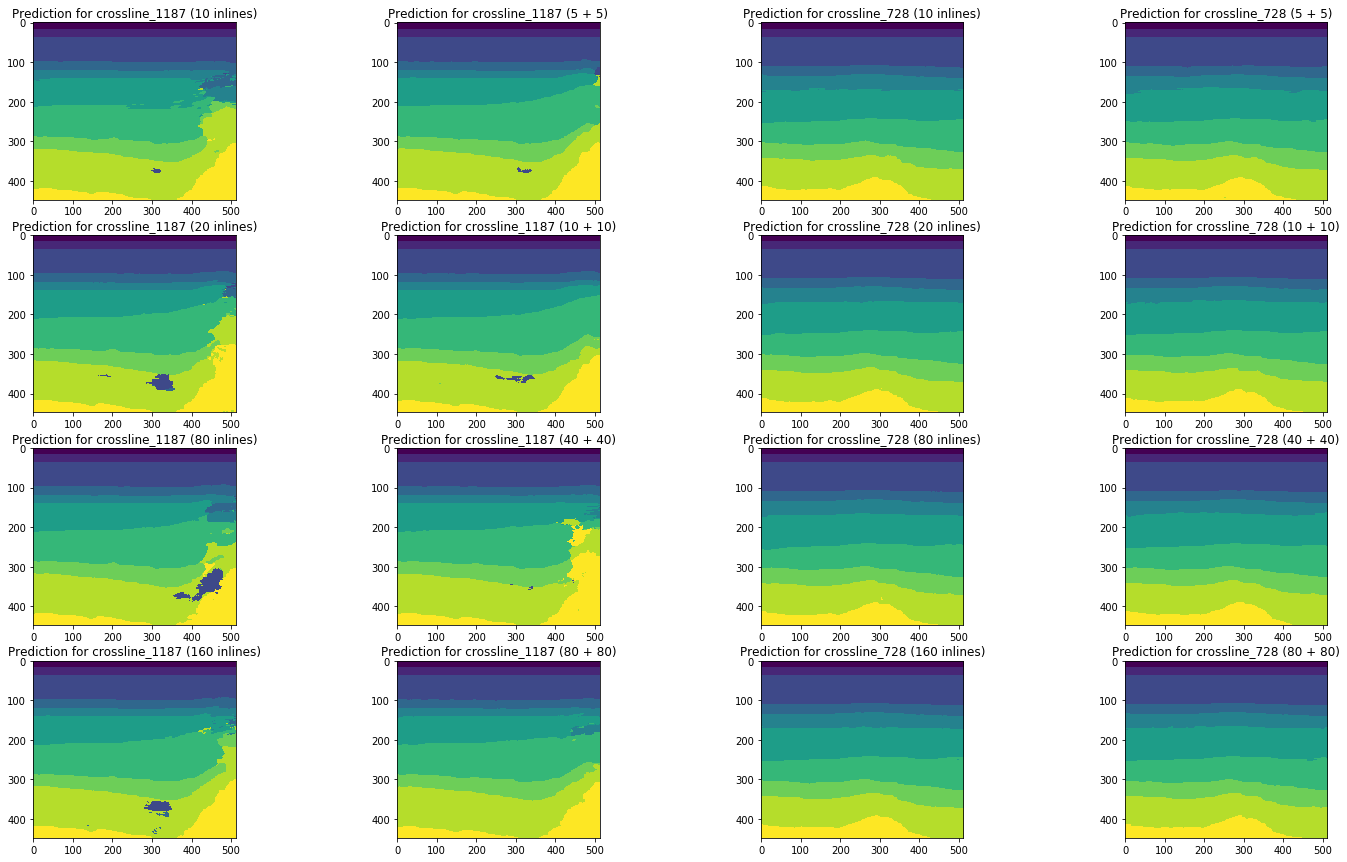
Abbildung 20. Vergleich der Netzwerkvorhersagen für Querlinien
Ein visueller Vergleich bestätigt die Annahme, dass das Hinzufügen verschiedener Arten von Schichten zum Training die Situation nicht grundlegend ändert. Einige Verbesserungen sind nur für die linke Querlinie zu beobachten, aber sind sie global? Wir werden versuchen, diese Frage weiter zu beantworten.
Aufgabe 5. Bewertung des Umfangs der manuellen Verfeinerung
Für eine endgültige Schlussfolgerung zu den Ergebnissen ist es erforderlich, den Grad der manuellen Verfeinerung der erhaltenen Netzwerkvorhersagen abzuschätzen. Zu diesem Zweck haben wir die Anzahl der verbundenen Komponenten (d. H. Durchgezogene Punkte derselben Farbe) für jede erhaltene Vorhersage bestimmt. Wenn dieser Wert 10 ist, sind die Ebenen korrekt ausgewählt und es handelt sich um eine maximale geringfügige Horizontkorrektur. Wenn es nicht mehr viele gibt, müssen Sie nur die kleinen Bereiche des Bildes "säubern". Wenn es wesentlich mehr davon gibt, ist alles schlecht und muss möglicherweise sogar komplett neu gestaltet werden.
Zum Testen haben wir 110 Inlines und 360 Crosslines ausgewählt, die für das Training in keinem der untersuchten Netzwerke verwendet wurden.
Tabelle 1. Über beide Arten von Slices gemittelte Statistiken
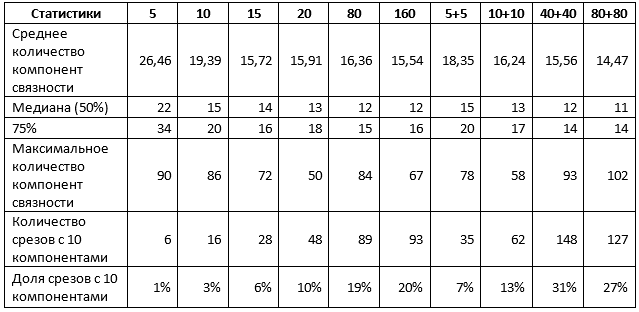
Tabelle 1 bestätigt einige der vorherigen Ergebnisse. Insbesondere wenn 1% Scheiben für das Training verwendet werden, gibt es keinen Unterschied. Verwenden Sie einen Scheibentyp oder beides. Das Ergebnis kann wie folgt charakterisiert werden:
- etwa 10% der Vorhersagen sind nahezu ideal, d.h. erfordern nicht mehr als Anpassungen an einzelnen Abschnitten des Horizonts;
- 50% der Vorhersagen enthalten nicht mehr als 15 Spots, d. H. nicht mehr als 5 extra;
- 75% der Vorhersagen enthalten nicht mehr als 20 Punkte, d. H. nicht mehr als 10 extra;
- Die verbleibenden 25% der Prognosen erfordern eine gründlichere Verfeinerung, einschließlich möglicherweise einer vollständigen Neugestaltung einzelner Schichten.
Eine Erhöhung des Stichprobenumfangs um bis zu 5% ändert die Situation. Insbesondere Netzwerke, die auf einer Mischung von Abschnitten trainiert wurden, weisen signifikant höhere Indikatoren auf, obwohl der Maximalwert der Komponenten ebenfalls zunimmt, was auf das Auftreten separater Interpretationen von sehr schlechter Qualität hinweist. Wenn Sie jedoch die Probe um das Fünffache erhöhen und eine Mischung aus Scheiben verwenden, gehen Sie wie folgt vor:
- ungefähr 30% der Vorhersagen sind nahezu ideal, d.h. erfordern nicht mehr als Anpassungen an einzelnen Abschnitten des Horizonts;
- 50% der Vorhersagen enthalten nicht mehr als 12 Punkte, d. H. nicht mehr als 2 extra;
- 75% der Vorhersagen enthalten nicht mehr als 14 Punkte, d. H. nicht mehr als 4 extra;
- Die verbleibenden 25% der Prognosen erfordern eine gründlichere Verfeinerung, einschließlich möglicherweise einer vollständigen Neugestaltung einzelner Schichten.
Eine weitere Erhöhung der Stichprobengröße führt nicht zu verbesserten Ergebnissen.
Im Allgemeinen können wir für den von uns untersuchten Datenwürfel Rückschlüsse darauf ziehen, dass 1-5% des gesamten Datenvolumens ausreichen, um ein gutes Ergebnis von einem neuronalen Netzwerk zu erhalten.
Aus diesen Daten lassen sich in Verbindung mit den oben genannten Metriken und Abbildungen bereits Schlussfolgerungen über die Angemessenheit der Verwendung neuronaler Netze zur Unterstützung von Dolmetschern und über die Ergebnisse ziehen, mit denen Spezialisten umgehen werden.
Schlussfolgerungen
Nun können wir die am Anfang des Artikels gestellten Fragen anhand der Ergebnisse beantworten, die am Beispiel eines seismischen Würfels der Nordsee erhalten wurden:
Wie viele Daten benötigen Experten, um ein neuronales Netzwerk zu trainieren? Und welche Daten soll ich wählen?Um eine gute Prognose des Netzwerks zu erhalten, ist es wirklich ausreichend, 1-5% der Gesamtzahl der Slices vorab zu markieren. Eine weitere Steigerung des Volumens führt nicht zu einer Verbesserung des Ergebnisses, vergleichbar mit der Zunahme der Anzahl der zuvor markierten Daten. Um ein besseres Markup für ein so kleines Volumen mithilfe eines neuronalen Netzwerks zu erzielen, müssen andere Ansätze verwendet werden, z. B. die Feinabstimmung der Architektur und der Lernstrategien, die Bildvorverarbeitung usw.
Für die vorläufige Markierung empfiehlt es sich, Scheiben beider Arten zu wählen - Inlines und Crosslines.
Was passiert bei einem solchen Ausgang? Wird eine manuelle Verfeinerung der Vorhersagen für neuronale Netze erforderlich sein? Wenn ja, wie komplex und umfangreich?
Infolgedessen erfordert ein erheblicher Teil der durch ein solches neuronales Netz gekennzeichneten Bilder nicht die bedeutendste Verfeinerung, die darin besteht, einzelne schlecht erkannte Zonen zu korrigieren. Darunter sind solche Interpretationen, die keine Korrekturen erfordern. Und nur für einzelne Bilder benötigen Sie möglicherweise ein neues manuelles Layout.
Wenn der Lernalgorithmus und die Netzwerkparameter optimiert werden, können natürlich die Vorhersagefähigkeiten verbessert werden. In unserem Experiment war die Lösung solcher Probleme nicht enthalten.
Darüber hinaus sollten die Ergebnisse einer Studie zu einem seismischen Würfel nicht leichtfertig verallgemeinert werden - gerade wegen der Einzigartigkeit jedes Datensatzes. Diese Ergebnisse bestätigen jedoch ein Experiment, das von anderen Autoren durchgeführt wurde, und bilden die Grundlage für den Vergleich mit unseren nachfolgenden Studien, über die wir ebenfalls in Kürze schreiben werden.
Danksagung
Zum Schluss möchte ich meinen Kollegen von
MaritimeAI (insbesondere Andrey Kokhan) und
ODS für wertvolle Kommentare und Hilfe danken!
Liste der verwendeten Quellen:
- Bas Peters, Eldad Haber, Justin Granek. Neuronale Netze für Geophysiker und ihre Anwendung auf die Interpretation seismischer Daten
- Hao Wu, Bo Zhang. Ein tiefes neuronales Faltungscodierer-Decodierer-Netzwerk zur Unterstützung der seismischen Horizontverfolgung
- Thilo Wrona, Indranil Pan, Robert L. Gawthorpe und Haakon Fossen. Seismische Fazies-Analyse mit maschinellem Lernen
- Reinaldo Mozart Silva, Rodrigo S. Ferreira, Daniel Civitarese, Daniela Szwarcman, Emilio Vital Brazil. Niederländischer Datensatz: Ein neuer öffentlicher Datensatz für maschinelles Lernen in der seismischen Interpretation