Der Artikel besteht aus zwei Teilen:
- Eine kurze Beschreibung einiger Netzwerkarchitekturen zum Erkennen von Objekten in einem Bild und eine Bildsegmentierung mit den für mich verständlichsten Links zu Ressourcen. Ich habe versucht, Video-Erklärungen zu wählen und am besten auf Russisch.
- Der zweite Teil ist ein Versuch, die Entwicklungsrichtung neuronaler Netzwerkarchitekturen zu verstehen. Und darauf basierende Technologien.

Abbildung 1 - Das Verständnis der Architektur neuronaler Netze ist nicht einfach
Alles begann damit, dass er zwei Demoanwendungen zum Klassifizieren und Erkennen von Objekten auf einem Android-Handy erstellt hat:
- Backend-Demo , wenn Daten auf dem Server verarbeitet und auf das Telefon übertragen werden. Bildklassifizierung von drei Arten von Bären: Braun, Schwarz und Teddy.
- Front-End-Demo, wenn Daten auf dem Telefon selbst verarbeitet werden. Objekterkennung von drei Arten: Haselnüsse, Feigen und Datteln.
Es gibt einen Unterschied zwischen der Klassifizierung von Bildern, der Erkennung von Objekten in einem Bild und der Segmentierung von Bildern . Es bestand daher die Notwendigkeit herauszufinden, welche neuronalen Netzwerkarchitekturen Objekte in Bildern erkennen und welche segmentiert werden können. Ich habe die folgenden Beispiele für Architekturen mit den für mich verständlichsten Links zu Ressourcen gefunden:
- Eine Reihe von Architekturen, die auf R-CNN basieren (Regionen mit C onvolution N etural N works): R-CNN, Schnelles R-CNN, Schnelleres R-CNN , Maske R-CNN . Um ein Objekt in einem Bild mithilfe des RPN-Mechanismus (Region Proposal Network) zu erkennen, werden Begrenzungsrahmen zugewiesen. Ursprünglich wurde der langsamere Selective Search-Mechanismus anstelle des RPN verwendet. Dann werden die ausgewählten begrenzten Regionen dem Eingang eines normalen neuronalen Netzwerks zur Klassifizierung zugeführt. In der Architektur von R-CNN gibt es explizite Aufzählungszyklen für begrenzte Regionen, insgesamt bis zu 2000 Läufe über das interne AlexNet-Netzwerk. Aufgrund expliziter "for" -Schleifen wird die Bildverarbeitungsgeschwindigkeit verlangsamt. Die Anzahl expliziter Zyklen, die durch das interne neuronale Netzwerk laufen, nimmt mit jeder neuen Version der Architektur ab, und Dutzende weiterer Änderungen werden durchgeführt, um die Geschwindigkeit zu erhöhen und die Aufgabe der Erkennung von Objekten durch Segmentierung von Objekten in der Maske R-CNN zu ersetzen.
- YOLO ist das erste neuronale Netzwerk, das Objekte in Echtzeit auf mobilen Geräten erkennt. Besonderheit: Objekte in einem Durchgang unterscheiden (nur einmal schauen). Das heißt, in der YOLO-Architektur gibt es keine expliziten "for" -Schleifen, weshalb das Netzwerk schnell ist. Dies ist zum Beispiel eine Analogie: In NumPy gibt es keine expliziten "for" -Schleifen beim Arbeiten mit Matrizen, die in NumPy auf niedrigeren Architekturebenen durch die Programmiersprache C implementiert sind. YOLO verwendet ein Raster vordefinierter Fenster. Um zu verhindern, dass dasselbe Objekt mehrmals erkannt wird, wird der Fensterüberlappungskoeffizient (IoU, Intersection over Union) verwendet. Diese Architektur arbeitet in einem weiten Bereich und weist eine hohe Robustheit auf : Das Modell kann in Fotografien trainiert werden, funktioniert aber gleichzeitig gut in gemalten Gemälden.
- SSD (Single Hot MultiBox Designer) - die erfolgreichsten „Hacks“ der YOLO-Architektur (z. B. nicht maximale Unterdrückung) werden verwendet und neue hinzugefügt, um das neuronale Netzwerk schneller und genauer zu machen. Besonderheit: Unterscheiden von Objekten in einem Durchgang mithilfe eines bestimmten Fenstergitters (Standardfeld) auf der Bildpyramide. Die Pyramide von Bildern wird während aufeinanderfolgender Faltungs- und Bündelungsoperationen in Faltungstensoren codiert (bei der Max-Pooling-Operation nimmt die räumliche Dimension ab). Auf diese Weise werden sowohl große als auch kleine Objekte in einem einzigen Netzwerklauf ermittelt.
- MobileSSD ( Mobile NetV2 + SSD ) ist eine Kombination aus zwei neuronalen Netzwerkarchitekturen. Das erste MobileNetV2- Netzwerk ist schnell und erhöht die Erkennungsgenauigkeit. MobileNetV2 wird anstelle von VGG-16 verwendet, das ursprünglich im Originalartikel verwendet wurde. Das zweite SSD-Netzwerk bestimmt die Position von Objekten im Bild.
- SqueezeNet ist ein sehr kleines, aber genaues neuronales Netzwerk. An sich löst es nicht das Problem der Erkennung von Objekten. Es kann jedoch mit einer Kombination verschiedener Architekturen verwendet werden. Und auf mobilen Geräten verwendet werden. Eine Besonderheit besteht darin, dass die Daten zunächst zu vier 1 × 1-Faltungsfiltern komprimiert und dann zu vier 1 × 1-Faltungsfiltern und vier 3 × 3-Faltungsfiltern erweitert werden. Eine solche Iteration der Datenkomprimierungserweiterung wird als "Feuermodul" bezeichnet.
- DeepLab (Semantische Bildsegmentierung mit Deep Convolutional Nets) - Segmentierung von Objekten im Bild. Ein charakteristisches Merkmal der Architektur ist eine verdünnte Faltung, die die räumliche Auflösung beibehält. Anschließend erfolgt die Nachbearbeitung der Ergebnisse mithilfe eines grafischen Wahrscheinlichkeitsmodells (Bedingtes Zufallsfeld), mit dem Sie geringes Rauschen in der Segmentierung entfernen und die Qualität des segmentierten Bildes verbessern können. Hinter dem gewaltigen Namen "Graphical Probabilistic Model" verbirgt sich der übliche Gauß-Filter, der durch fünf Punkte angenähert wird.
- Ich habe versucht, das RefineDet- Gerät (Single-Shot Refine ment Neural Network zur Objekterkennung) zu verstehen, aber ich habe sehr wenig verstanden.
- Ich habe mir auch angesehen, wie die Aufmerksamkeitstechnologie funktioniert: Video1 , Video2 , Video3 . Ein charakteristisches Merkmal der "Aufmerksamkeit" -Architektur ist die automatische Zuweisung von Bereichen mit erhöhter Aufmerksamkeit zum Bild (ROI, Interessensregionen) unter Verwendung eines neuronalen Netzwerks, das als Aufmerksamkeitseinheit bezeichnet wird. Bereiche mit erhöhter Aufmerksamkeit ähneln eingeschränkten Bereichen (Begrenzungsrahmen), sind jedoch im Gegensatz zu diesen nicht auf dem Bild fixiert und weisen möglicherweise unscharfe Ränder auf. Anschließend werden aus den Bereichen mit erhöhter Aufmerksamkeit Merkmale (Features) unterschieden, die wiederkehrenden neuronalen Netzwerken mit LSDM-, GRU- oder Vanilla RNN- Architekturen "zugeführt" werden. Rekursive neuronale Netze können die Beziehung von Zeichen in einer Sequenz analysieren. Rekursive neuronale Netze wurden ursprünglich verwendet, um Text in andere Sprachen zu übersetzen, und jetzt, um Bilder in Text und Text in Bilder zu übersetzen.
Als ich diese Architekturen studierte, stellte ich fest, dass ich nichts verstand . Und der Punkt ist nicht, dass mein neuronales Netzwerk Probleme mit dem Aufmerksamkeitsmechanismus hat. Das Erstellen all dieser Architekturen sieht aus wie ein riesiger Hackathon, bei dem Autoren an Hacks teilnehmen. Hack ist eine schnelle Lösung für eine schwierige Softwareaufgabe. Das heißt, es gibt keine sichtbare und verständliche logische Verbindung zwischen all diesen Architekturen. Alles, was sie verbindet, ist eine Reihe der erfolgreichsten Hacks, die sie voneinander ausleihen, sowie eine gemeinsame Faltungsoperation mit Rückkopplung (umgekehrte Ausbreitung von Fehlern, Backpropagation). Kein systemisches Denken ! Es ist nicht klar, was geändert und wie vorhandene Erfolge optimiert werden sollen.
Aufgrund des Fehlens einer logischen Verbindung zwischen Hacks ist es äußerst schwierig, sich an sie zu erinnern und sie in die Praxis umzusetzen. Das ist fragmentiertes Wissen. Im besten Fall werden einige interessante und unerwartete Momente in Erinnerung gerufen, aber das meiste, was verstanden und unverständlich ist, verschwindet innerhalb weniger Tage aus dem Gedächtnis. Es wird gut sein, wenn ich mich in einer Woche zumindest an den Namen der Architektur erinnere. Aber es dauerte mehrere Stunden und sogar Tage, um Artikel zu lesen und Review-Videos anzuschauen!
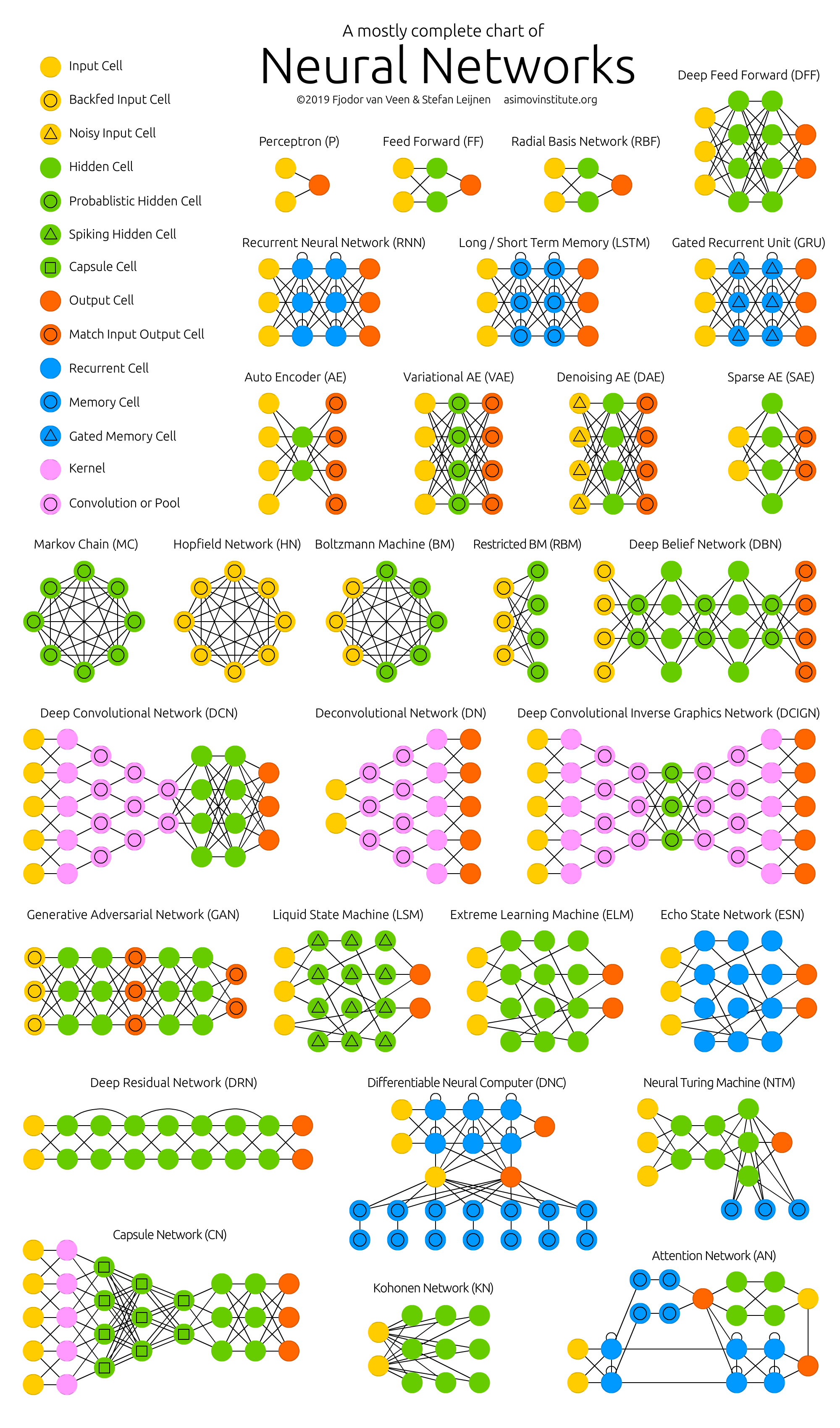
Abbildung 2 - Zoo neuronaler Netze
Die meisten Autoren von wissenschaftlichen Artikeln tun meiner Meinung nach alles, damit auch dieses fragmentierte Wissen vom Leser nicht verstanden wird. Aber die Partizipien in Zehn-Zeilen-Sätzen mit Formeln, die "von der Decke" genommen wurden, sind ein Thema für einen separaten Artikel (Problem veröffentlichen oder zugrunde gehen ).
Aus diesem Grund wurde es notwendig, Informationen in neuronalen Netzen zu systematisieren und damit die Qualität des Verstehens und des Erinnerns zu verbessern. Daher war das Hauptthema der Analyse einzelner Technologien und Architekturen künstlicher neuronaler Netze die folgende Aufgabe: herauszufinden, wo sich all dies bewegt , und nicht das Gerät eines bestimmten neuronalen Netzes separat.
Wohin geht das alles? Die wichtigsten Ergebnisse:
- Die Zahl der Startups im Bereich des maschinellen Lernens ist in den letzten zwei Jahren stark zurückgegangen. Möglicher Grund: "Neuronale Netze sind nicht mehr neu."
- Jeder kann ein funktionierendes neuronales Netzwerk erstellen, um ein einfaches Problem zu lösen. Nehmen Sie dazu das fertige Modell aus dem „Modellzoo“ und trainieren Sie die letzte Schicht des neuronalen Netzwerks ( Transfer Learning ) mit den fertigen Daten aus der Google Dataset Search oder aus 25.000 Kaggle-Datensätzen in der kostenlosen Jupyter Notebook-Cloud .
- Große Hersteller neuronaler Netze begannen, "Modellzoos" (model zoo) zu schaffen. Mit ihnen können Sie schnell eine kommerzielle Anwendung erstellen: TF Hub für TensorFlow, MMDetection für PyTorch, Detectron für Caffe2, chainer-modelzoo für Chainer und andere .
- Neuronale Echtzeitnetze auf Mobilgeräten. 10 bis 50 Bilder pro Sekunde.
- Die Verwendung von neuronalen Netzen in Telefonen (TF Lite), in Browsern (TF.js) und in Haushaltsgegenständen (IoT, Internet und T hings). Besonders in Telefonen, die bereits neuronale Netze auf Hardware-Ebene unterstützen (Neuroaccelerators).
- „Jedes Gerät, jede Kleidung und möglicherweise auch jedes Essen wird eine IP-v6-Adresse haben und miteinander kommunizieren“ - Sebastian Trun .
- Die Zunahme der Veröffentlichungen zum maschinellen Lernen hat begonnen, das Gesetz von Moore (das sich alle zwei Jahre verdoppelt) seit 2015 zu übertreffen . Offensichtlich werden neuronale Netze zur Artikelanalyse benötigt.
- Folgende Technologien werden immer beliebter:
- PyTorch - Popularität wächst schnell und scheint TensorFlow zu überholen.
- Automatische Auswahl von AutoML- Hyperparametern - die Popularität wächst stetig.
- Allmähliche Abnahme der Genauigkeit und Erhöhung der Rechengeschwindigkeit: Fuzzy-Logik , Boosting- Algorithmen, ungenaue (ungefähre) Berechnungen, Quantisierung (wenn die Gewichte eines neuronalen Netzwerks in ganze Zahlen und quantisiert werden), Neuro-Beschleuniger.
- Übersetzung von Bild in Text und Text in Bild .
- Erstellen Sie dreidimensionale Objekte auf Video , jetzt in Echtzeit.
- Die Hauptsache in DL sind viele Daten, aber das Sammeln und Markieren ist nicht einfach. Daher entwickelt sich eine automatisierte Annotation für neuronale Netze unter Verwendung neuronaler Netze.
- Mit neuronalen Netzen wurde die Informatik plötzlich zu einer experimentellen Wissenschaft und es kam zu einer Reproduzierbarkeitskrise .
- IT-Geld und die Popularität neuronaler Netze entstanden gleichzeitig, als das Rechnen zum Marktwert wurde. Die Wirtschaft von Gold und Devisen wird zum Goldwährungsrechner . Siehe meinen Artikel über Wirtschaftsphysik und den Grund für die Entstehung von IT-Geld.
Allmählich erscheint eine neue ML / DL-Programmiermethode (Machine Learning & Deep Learning), die auf der Darstellung des Programms als Sammlung trainierter neuronaler Netzwerkmodelle basiert.
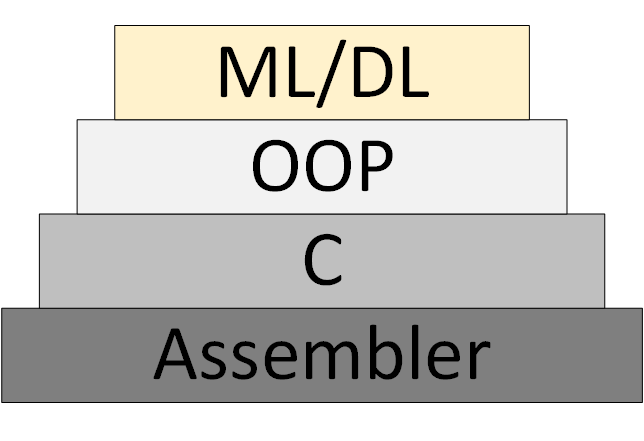
Abbildung 3 - ML / DL als neue Programmiermethode
Die „Theorie der neuronalen Netze“ , in deren Rahmen man systematisch denken und arbeiten kann, ist jedoch nicht aufgetaucht. Was heute als "Theorie" bezeichnet wird, sind experimentelle heuristische Algorithmen.
Links zu meinen und nicht nur Ressourcen:
- Data Science Newsletter. Meistens Bildverarbeitung. Wer empfangen möchte, soll ihm eine E-Mail senden (foobar167 <gaff-gaf> gmail <dot> com). Ich sende Links zu Artikeln und Videos, wenn sich Material ansammelt.
- Eine allgemeine Liste der Kurse und Artikel , an denen ich teilgenommen habe und teilnehmen möchte.
- Kurse und Videos für Anfänger , ab denen es sich lohnt, neuronale Netze zu studieren. Dazu die Broschüre "Einführung in maschinelles Lernen und künstliche neuronale Netze".
- Nützliche Tools, bei denen jeder etwas Interessantes für sich findet.
- Die Videokanäle zur Analyse von wissenschaftlichen Artikeln über Data Science haben sich als äußerst nützlich erwiesen. Suchen, abonnieren und Links an Ihre Kollegen und mich senden. Beispiele:
Vielen Dank für Ihre Aufmerksamkeit!