In diesem Artikel präsentiere ich Ihnen meine Gedanken zur Geschichte und den Perspektiven der Entwicklung des Internets, der zentralen und dezentralen Netze und damit der möglichen Architektur des dezentralen Netzes der nächsten Generation.
Mit dem Internet stimmt etwas nicht
Ich habe das Internet zum ersten Mal im Jahr 2000 kennengelernt. Dies ist natürlich noch lange nicht alles - das Netzwerk existierte bereits zuvor, aber diese Zeit kann als die erste Blütezeit des Internets bezeichnet werden. Das World Wide Web ist eine brillante Erfindung von Tim Berners-Lee, web1.0 in seiner klassischen kanonischen Form. Viele Websites und Seiten, die über Hyperlinks miteinander verbunden sind. Auf den ersten Blick - eine einfache, wie alle geniale Architektur:
dezentral und frei . Ich möchte - Ich reise durch die Websites anderer Leute und folge Hyperlinks. Ich möchte - ich erstelle meine eigene Website, auf der ich das veröffentliche, was mich interessiert - zum Beispiel meine Artikel, Fotos, Programme, Hyperlinks zu Websites, die mich interessieren. Und andere posten Links zu mir.
Es scheint - ein idyllisches Bild? Aber Sie wissen bereits, wie alles endete.
Es gab zu viele Seiten, und die Suche nach Informationen wurde zu einer sehr nicht unbedeutenden Sache. Die von den Autoren registrierten Hyperlinks konnten diese riesige Informationsmenge einfach nicht strukturieren. Zuerst wurden die Verzeichnisse manuell gefüllt, und dann begannen riesige Suchmaschinen, ausgeklügelte heuristische Ranking-Algorithmen zu verwenden. Sites wurden erstellt und aufgegeben, Informationen wurden dupliziert und verzerrt. Das Internet wurde schnell kommerzialisiert und entfernte sich immer mehr vom idealen akademischen Netzwerk. Auszeichnungssprache wurde schnell zu einer Formatierungssprache. Es gab Werbung, abscheuliche nervige Banner und die Technologie der Werbung und Täuschung von Suchmaschinen - SEO. Das Netzwerk wurde schnell mit Informationsmüll verstopft. Hyperlinks haben aufgehört, ein logisches Kommunikationsmittel zu sein, und wurden zu einem Werbemittel. Websites wurden verkleinert, geschlossen, von offenen "Seiten" in hermetische "Anwendungen" verwandelt und nur zur Erzielung von Einnahmen verwendet.
Schon damals hatte ich den Gedanken, dass "hier etwas nicht stimmt". Eine Reihe von verschiedenen Websites, angefangen von primitiven Homepages mit einem vyrviglazny Erscheinungsbild bis hin zu "Megaportalen", die mit flackernden Bannern überladen sind. Auch wenn Websites zum selben Thema gehören, haben sie keinerlei Beziehung, jedes hat ein eigenes Design, eine eigene Struktur, nervige Banner, eine schlecht funktionierende Suche und Probleme beim Herunterladen (ja, ich wollte Informationen offline haben). Schon damals verwandelte sich das Internet in eine Art Fernseher, in dem alle Arten von Lametta mit Nägeln an nützlichen Inhalten befestigt waren.
Die Dezentralisierung ist zum Albtraum geworden.
Was willst du
Paradoxerweise brauchte ich als Benutzer keine Dezentralisierung! Wenn ich mich an meine klaren Gedanken dieser Zeit erinnere, komme ich zu dem Schluss, dass ich ... eine
einzige Datenbank brauchte! Eine solche Abfrage würde alle Ergebnisse liefern, ist aber für den Ranking-Algorithmus nicht am besten geeignet. Eines, bei dem alle diese Ergebnisse einheitlich und nach meinem eigenen Entwurf gestaltet wurden, anstatt nach selbst gemachten vyrviglaznymi-Entwürfen von zahlreichen Vasya Pupkin. Eine, die offline gehalten werden kann und keine Angst hat, dass die Site morgen verschwindet und die Informationen für immer verschwinden. Eine, in die ich meine Informationen eingeben kann - zum Beispiel Kommentare und Tags. Eine, in der ich mit meinen persönlichen Algorithmen suchen, sortieren und filtern konnte.
Web 2.0 und soziale Netzwerke
Inzwischen hat das Web 2.0-Konzept Einzug gehalten. Formuliert von Tim O'Reilly im Jahr 2005 als „Methode zum Entwerfen von Systemen, die unter Berücksichtigung von Netzwerkinteraktionen umso besser werden, je mehr Benutzer sie verwenden“ - und impliziert die aktive Einbeziehung von Benutzern in die kollektive Erstellung und Bearbeitung von Webinhalten. Ohne Übertreibung wurden soziale Netzwerke zum Höhepunkt und Triumph dieses Konzepts. Riesige Plattformen, die Milliarden von Benutzern zusammenbringen und Hunderte von Petabyte an Daten speichern.
Was haben wir in sozialen Netzwerken bekommen?
- Schnittstellenvereinheitlichung; es stellte sich heraus, dass nicht alle Möglichkeiten zur Schaffung eines vielfältigen vyviglazny Design Benutzer brauchen; alle seiten aller benutzer haben das gleiche design und es passt allen und ist sogar praktisch; nur der inhalt ist anders.
- funktionale Vereinheitlichung; Die ganze Vielfalt der Skripte war auch unnötig. Lenta, Freunde, Alben ... Während der Existenz sozialer Netzwerke hat sich ihre Funktionalität mehr oder weniger stabilisiert und es ist unwahrscheinlich, dass sie sich ändert. Schließlich wird die Funktionalität durch die Art der Aktivitäten der Menschen bestimmt, und die Menschen ändern sich praktisch nicht.
- einzelne Datenbank; Die Arbeit mit einer solchen Datenbank erwies sich als viel bequemer als mit vielen unterschiedlichen Sites. Die Suche ist viel einfacher geworden. Anstatt eine Vielzahl von lose gekoppelten Seiten fortlaufend zu scannen und all dies zwischenzuspeichern und nach komplexen heuristischen Algorithmen zu ordnen - eine relativ einfache, einheitliche Abfrage an eine einzelne Datenbank mit einer bekannten Struktur.
- Feedback-Schnittstelle - Likes und Reposts; Im regulären Web konnte Google nach dem Klicken auf den Link in den Suchergebnissen kein Feedback von Nutzern erhalten. In sozialen Netzwerken war diese Verbindung einfach und natürlich.
Was haben wir verloren?
Wir haben die Dezentralisierung verloren, was Freiheit bedeutet . Es wird angenommen, dass unsere Daten jetzt nicht zu uns gehören. Konnten wir eine Homepage noch nicht auf unserem eigenen Computer hosten, geben wir jetzt alle unsere Daten an Internetgiganten weiter.
Mit der Entwicklung des Internets interessierten sich auch Regierungen und Unternehmen für das Internet, und es gab Probleme mit politischer Zensur und urheberrechtlichen Beschränkungen. Unsere Seiten in sozialen Netzwerken können gesperrt und gelöscht werden, wenn der Inhalt nicht den Regeln des sozialen Netzwerks entspricht; für eine nachlässige Nachbearbeitung - zur administrativen und sogar strafrechtlichen Verantwortlichkeit bringen.
Und hier denken wir wieder: Kann man uns die Dezentralisierung zurückgeben? Aber in einer anderen Form, ohne die Mängel des ersten Versuchs?
Peer-to-Peer-Netzwerke
Die ersten p2p-Netzwerke tauchten lange vor Web 2.0 auf und entwickelten sich parallel zur Entwicklung des Webs. Die klassische Hauptanwendung von p2p ist das Filesharing. Die ersten Netzwerke waren für die gemeinsame Nutzung von Musik konzipiert. Die ersten Netzwerke (wie Napster) waren im Wesentlichen zentralisiert und wurden daher von den Inhabern von Urheberrechten schnell abgedeckt. Die Anhänger gingen den Weg der Dezentralisierung. Im Jahr 2000 erschienen die Protokolle ED2K (der erste eDokney-Client) und Gnutella, im Jahr 2001 das FastTrack-Protokoll (KaZaA-Client). Allmählich nahm der Dezentralisierungsgrad zu, und die Technologien verbesserten sich. Systeme mit einer „Download-Warteschlange“ wurden durch Torrents ersetzt, und das Konzept verteilter DHT-Hash-Tabellen wurde eingeführt. Durch die Verschärfung der Nüsse durch die Staaten wurde die Anonymität der Teilnehmer stärker gefordert. Seit 2000 wird das Freenet-Netzwerk entwickelt, seit 2003 I2P, und 2006 wurde das RetroShare-Projekt gestartet. Sie können die zahlreichen P2P-Netzwerke erwähnen, die früher existierten und bereits verschwunden sind - und jetzt betriebsbereit sind: WASTE, MUTE, TurtleF2F, RShare, PerfectDark, ARES, Gnutella2, GNUNet, IPFS, ZeroNet, Tribbler und viele andere. Es gibt viele davon. Sie sind unterschiedlich. Sehr unterschiedlich - sowohl in Bezug auf den Zweck als auch auf das Design ... Wahrscheinlich kennen viele von Ihnen nicht einmal alle diese Namen. Und das ist noch lange nicht alles.
P2P-Netze haben jedoch eine Reihe von Nachteilen. Zusätzlich zu den technischen Mängeln, die zum Beispiel bei jeder spezifischen Implementierung des Protokolls und des Clients auftreten, besteht ein ziemlich allgemeiner Nachteil in der Komplexität der Suche (d. H. Alles, was Web 1.0 angetroffen hat, jedoch in einer noch komplizierteren Version). Google ist nicht hier mit seiner allgegenwärtigen und sofortigen Suche. Und wenn Sie für Filesharing-Netzwerke immer noch die Suche nach Dateinamen oder Metainformationen verwenden können, ist es sehr schwierig, wenn überhaupt möglich, etwas zu finden, z. B. in Zwiebel- oder i2p-Overlay-Netzwerken.
Wenn wir Analogien zum klassischen Internet ziehen, stecken die meisten dezentralen Netzwerke im Allgemeinen irgendwo auf FTP-Ebene fest. Stellen Sie sich das Internet vor, in dem es nichts als FTP gibt: weder moderne Sites noch Web2.0 oder Youtube ... Das ist ungefähr in diesem Zustand, und es gibt dezentrale Netzwerke. Und trotz individueller Versuche, etwas zu ändern, gibt es nur wenige Änderungen.
Inhalt
Wenden wir uns einem weiteren wichtigen Teil dieses Puzzles zu - dem Inhalt. Inhalt ist das Hauptproblem jeder Internet-Ressource und insbesondere dezentralisiert. Woher bekommen Sie es? Natürlich können Sie sich auf eine Menge Enthusiasten verlassen (wie es bei bestehenden p2p-Netzwerken der Fall ist), aber dann wird die Entwicklung des Netzwerks ziemlich lang und es wird wenig Inhalt geben.
Das Arbeiten mit dem normalen Internet ist das Suchen und Studieren von Inhalten. Manchmal ist es eine Bewahrung (wenn der Inhalt interessant und nützlich ist, dann halten viele, insbesondere diejenigen, die während der Einwahl ins Netzwerk gekommen sind - einschließlich mir -, ihn mit Bedacht offline, um nicht verloren zu gehen. Das Internet ist für uns eine unkontrollierbare Sache. Heute gibt es keine Website für morgen , heute gibt es ein Video auf YouTube - morgen wurde es gelöscht usw.
Und für Torrents (die wir eher als Übermittlungsmedium als als p2p-Netzwerk wahrnehmen) ist die Aufbewahrung im Allgemeinen impliziert. Übrigens ist dies eines der Probleme von Torrents: Es ist schwierig, die heruntergeladene Datei einmal an einen Ort zu verschieben, an dem sie bequemer zu verwenden ist (in der Regel müssen Sie die Distribution manuell neu generieren), und es ist absolut unmöglich, sie umzubenennen (Sie können einen Hardlink erstellen, aber nur sehr wenige wissen davon).
Im Allgemeinen speichern viele Inhalte auf die eine oder andere Weise. Was ist sein zukünftiges Schicksal? Normalerweise werden die gespeicherten Dateien irgendwo auf der Festplatte, in einem Ordner wie Downloads, auf einem gemeinsamen Heap gespeichert und liegen dort zusammen mit vielen tausend anderen Dateien. Das ist schlecht - und schlecht für den Benutzer. Wenn das Internet über Suchmaschinen verfügt, verfügt der lokale Computer des Benutzers über nichts dergleichen. Es ist gut, wenn der Benutzer ordentlich ist und die "eingehenden" heruntergeladenen Dateien sortiert. Aber nicht alle von ihnen ...
Tatsächlich gibt es inzwischen viele, die nichts sparen, sondern sich ausschließlich auf das Internet verlassen. In P2P-Netzwerken wird jedoch davon ausgegangen, dass der Inhalt lokal auf dem Gerät des Benutzers gespeichert und an andere Teilnehmer verteilt wird. Ist es möglich, eine Lösung zu finden, die es ermöglicht, beide Benutzerkategorien in ein dezentrales Netzwerk einzubeziehen, ohne ihre Gewohnheiten zu ändern, und darüber hinaus ihr Leben zu erleichtern?
Die Idee ist ganz einfach: Was ist, wenn wir dem Benutzer ein Mittel zur bequemen und transparenten Speicherung von Inhalten aus dem regulären Internet und zur intelligenten Speicherung mit semantischen Metainformationen zur Verfügung stellen, und zwar nicht in einem allgemeinen Haufen, sondern in einer spezifischen Struktur mit der Möglichkeit einer weiteren Strukturierung und gleichzeitiger Verteilung der gespeicherten Inhalte an Dezentralisierer das Netzwerk?
Beginnen wir mit dem Speichern
Wir werden die zweckmäßige Nutzung des Internets zur Anzeige von Wettervorhersagen oder Flugzeugplänen nicht berücksichtigen. Wir interessieren uns mehr für in sich geschlossene und mehr oder weniger unveränderliche Objekte - Artikel (beginnend mit Tweets / Posts aus sozialen Netzwerken und endend mit großen Artikeln, wie hier auf Habré), Bücher, Bilder, Programme, Audio- und Videoaufnahmen. Woher kommen die Informationen? Normalerweise ist es
- soziale Netzwerke (verschiedene Nachrichten, kleine Notizen - "Tweets", Bilder, Audio und Video)
- Artikel über thematische Ressourcen (wie Habr); es gibt nicht viele gute ressourcen, normalerweise basieren diese ressourcen auch auf dem prinzip der sozialen netzwerke
- Nachrichtenseiten
In der Regel gibt es dort Standardfunktionen: wie, reposten, in sozialen Netzwerken teilen, etc.
Stellen Sie sich ein
Browser-Plug-In vor , das auf besondere Weise alles speichert, was wir mochten, erneut veröffentlichten, in den „Favoriten“ speicherten (oder auf eine spezielle Plug-In-Schaltfläche klickten, die im Browser-Menü angezeigt wird, falls die Site keine ähnliche Funktion hat) / repost / bookmark). Die Hauptidee ist, dass Sie genau das tun, was Sie bereits millionenfach getan haben, und das System den Artikel, das Bild oder das Video in einem speziellen Offline-Speicher speichert und dieser Artikel oder dieses Bild verfügbar wird - und für die Offline-Anzeige über die dezentrale Client-Oberfläche und im dezentralsten Netzwerk! Ich finde das sehr praktisch. Keine unnötigen Maßnahmen, und wir lösen sofort viele Probleme:
- Speichern von wertvollen Inhalten, die verloren gehen oder gelöscht werden können
- dezentrales Netzwerk schnelles Befüllen
- Zusammenfassung von Inhalten aus verschiedenen Quellen (Sie können in Dutzenden von Internetressourcen registriert sein, und alle Likes / Reposts fließen in eine einzige lokale Datenbank)
- Strukturieren Sie Ihre Inhalte nach Ihren Regeln
Natürlich muss das Browser-Plug-In für die Struktur jeder Site konfiguriert werden (dies ist durchaus realistisch - es gibt bereits Plug-Ins zum Speichern von Inhalten von Youtube, Twitter, VK usw.). Es gibt nicht so viele Sites, für die es sinnvoll ist, persönliche Plugins zu erstellen. In der Regel handelt es sich dabei um weit verbreitete soziale Netzwerke (es gibt kaum mehr als ein Dutzend) und eine bestimmte Anzahl hochwertiger thematischer Websites wie Habr (es gibt auch wenige davon). Mit Open Source Code und Spezifikationen sollte die Entwicklung eines neuen Plugins basierend auf einem Template Blank nicht viel Zeit in Anspruch nehmen. Für andere Websites können Sie die universelle Schaltfläche zum Speichern verwenden, mit der die gesamte Seite in HTML gespeichert wird - möglicherweise nach dem Löschen der Seite aus der Werbung.
Nun zur Strukturierung
Mit "intelligentem" Speichern meine ich zumindest das Speichern mit Metainformationen: Inhaltsquelle (URL), zuvor festgelegte Likes, Tags, Kommentare, deren Bezeichner usw. Während des normalen Speichervorgangs gehen diese Informationen verloren. Eine Quelle kann nicht nur eine direkte URL, sondern auch eine semantische Komponente sein, z. B. eine Gruppe in sozialen Netzwerken oder ein Benutzer, der eine erneute Veröffentlichung vorgenommen hat. Das Plugin kann intelligent genug sein, um diese Informationen für die automatische Strukturierung und Kennzeichnung zu verwenden. Es sollte auch klar sein, dass der Benutzer selbst immer einige Metainformationen zu den gespeicherten Inhalten hinzufügen kann, für die Sie maskierbar praktische Interface-Tools bereitstellen sollten (ich habe viele Ideen, wie dies zu tun ist).
Damit ist das Problem der Strukturierung und Organisation lokaler Benutzerdateien gelöst. Dies ist ein fertiger Vorteil, der auch ohne P2P genutzt werden kann. Es ist nur eine Art Offline-Datenbank, die weiß, was, wo und in welchem Kontext wir gespeichert haben, und die es Ihnen ermöglicht, kleine Studien durchzuführen. Suchen Sie zum Beispiel Benutzer eines externen sozialen Netzwerks, die am liebsten unter denselben Posts wie Sie sind. Wie viele soziale Netzwerke erlauben dies explizit?
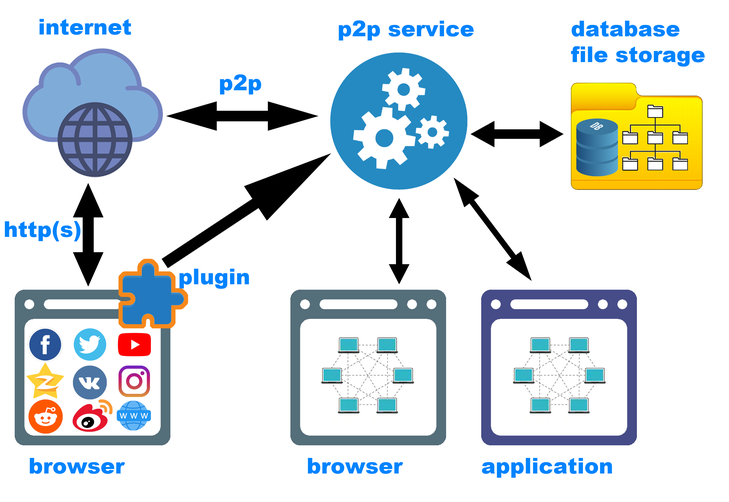
Es sollte hier bereits erwähnt werden, dass ein Browser-Plugin sicherlich nicht ausreicht. Die zweitwichtigste Komponente des Systems ist ein dezentraler Netzwerkdienst, der im Hintergrund ausgeführt wird und sowohl das P2P-Netzwerk selbst (Anforderungen vom Netzwerk und Anforderungen vom Client) als auch das Speichern neuer Inhalte mithilfe des Plug-Ins bedient. Der Dienst, der mit dem Plugin zusammenarbeitet, platziert den Inhalt an der richtigen Stelle, berechnet die Hashes (und stellt möglicherweise fest, dass dieser Inhalt bereits gespeichert wurde) und fügt der lokalen Datenbank die erforderlichen Metainformationen hinzu.
Was interessant ist - das System wäre schon in dieser Form nützlich, ohne p2p. Viele Leute benutzen Web-Clipper, die interessante Inhalte aus dem Web hinzufügen, zum Beispiel zu Evernote. Die vorgeschlagene Architektur ist eine erweiterte Version eines solchen Clippers.
Zum Schluss p2p austauschen
Das Beste daran ist, dass Informationen und Metainformationen (sowohl aus dem Internet als auch von Ihnen selbst erfasst) ausgetauscht werden können. Das Konzept eines sozialen Netzwerks ist gut auf die P2P-Architektur abgestimmt. Wir können sagen, dass das soziale Netzwerk und p2p füreinander gemacht zu sein scheinen. Jedes dezentrale Netzwerk sollte idealerweise als soziales Netzwerk aufgebaut werden, nur dann funktioniert es effizient. "Freunde", "Gruppen" - dies sind die Feste, zu denen stabile Verbindungen bestehen sollten, und diese stammen aus einer natürlichen Quelle - den gemeinsamen Interessen der Benutzer.
Die Prinzipien zum Speichern und Verteilen von Inhalten in einem dezentralen Netzwerk sind völlig identisch mit den Prinzipien zum Speichern (Erfassen) von Inhalten aus dem regulären Internet. Wenn Sie Inhalte aus dem Netzwerk verwenden (was bedeutet, dass Sie sie gespeichert haben), kann jeder Ihre Ressourcen (Datenträger und Kanal) verwenden, die für den spezifischen Empfang dieser Inhalte erforderlich sind.
Likes sind das einfachste Tool zum Speichern und Teilen. Wenn es mir gefällt - egal ob im externen Internet oder in einem dezentralen Netzwerk -, dann gefällt mir der Inhalt und wenn ja, dann bin ich bereit, ihn lokal aufzubewahren und an andere Mitglieder des dezentralen Netzwerks zu verteilen.
- Inhalt ist nicht "verloren"; es wird jetzt lokal bei mir gespeichert, ich kann später jederzeit darauf zurückgreifen, ohne dass sich jemand Sorgen machen muss, der es löscht oder blockiert
- Ich kann es (sofort oder später) kategorisieren, mit Tags versehen, kommentieren, mit anderen Inhalten verknüpfen, im Allgemeinen etwas Sinnvolles damit anfangen - nennen wir es „Bildung von Metainformationen“.
- Ich kann diese Metainformationen mit anderen Netzwerkmitgliedern teilen.
- Ich kann meine Metainformationen mit den Metainformationen anderer Teilnehmer synchronisieren
Wahrscheinlich ist die Ablehnung von Abneigungen auch logisch: Wenn mir der Inhalt nicht gefällt, ist es ganz logisch, dass ich nicht meinen Speicherplatz und meinen Internetkanal für die Verteilung dieses Inhalts verschwenden möchte. Daher passen Abneigungen sehr organisch nicht in die Dezentralisierung (obwohl dies manchmal immer noch
nützlich ist ).
Manchmal müssen Sie auch speichern, was Sie nicht mögen. Es gibt so ein Wort "notwendig" :)
„
Lesezeichen “ (oder „Favoriten“) - Ich drücke meine Einstellung zum Inhalt nicht aus, speichere ihn jedoch in meiner lokalen Lesezeichen-Datenbank. «» (favorites) ( ), «» (bookmarks) — . «» — «» (.. «» ), «» - . ?
"
". , , , . () .
"
" — , , - , — , . , «», , — , / , .
, . — . — . , , , .
, , . , , , . , -, , ; , , .
, . , . , , , .. , . — , (, «» — , … , ).
, — ( i2p Retroshare), TOR VPN.
( ). , — , . — p2p , («backend»). , . — frontend. - ( ), GUI- (Windows, Linux, MacOS, Andriod, iOS ..). frontend'. backend'.
, . (.. , , , , — , , , ..), ( , Libgen), ( Freenet), ( ), ( — , , , , ..) .
1. — . (, ...) (, ...) —
2. , — /; p2p,
3.
4. /