Versionskontrollsysteme sind für Entwickler seit langem ein tägliches Werkzeug. In großen Monorepositories sind die Anforderungen sehr spezifisch. Aus diesem Grund passen Unternehmen entweder vorhandene Lösungen an, wie es Facebook mit Mercurial und Microsoft mit Git tut, oder entwickeln ihre eigenen Systeme: Piper und CitC bei Google und Arc VCS bei Yandex.
In dem Bericht erklärt der Entwickler Vladimir Kikhtenko
kikht , warum Yandex ein eigenes Versionskontrollsystem benötigte und wie es funktioniert. Betrachten Sie es von der Seite eines gewöhnlichen Entwicklers: wie Sie auf den Quellcode zugreifen, einen Zweig für die Entwicklung beiseite legen und die Änderungen in eine gemeinsame Codebasis integrieren. Wir schauen unter die Haube - wir lernen die interne Darstellung der Daten und deren Anzeige in einem virtuellen Dateisystem mit einer Arbeitskopie. Wir werden die Schwierigkeiten bei der Implementierung von VCS-Funktionen in einem virtuellen Dateisystem und beim langsamen Laden von Daten diskutieren. Lassen Sie uns darüber sprechen, wie die Zuverlässigkeit der Serverinfrastruktur des Repositorys sichergestellt werden kann.
Am Ende sehen Sie eine inoffizielle Aufzeichnung des Berichts.
- Guten Tag allerseits, mein Name ist Vladimir. Sie alle haben Reden darüber gehört, keine Fahrräder zu schreiben. Mein Bericht wird auf der anderen Seite der Barrikade sein.
In der Tat hat Yandex ein Monorepository, in dem sich viel Code befindet. Und wir sind zu dem Schluss gekommen, dass wir ein eigenes Versionskontrollsystem entwickeln.

Wie sind wir zu so einem Leben gekommen? Historisch gesehen lebte dieses Monorepository bei uns im SVN. Es übt die stammbasierte Entwicklung aus. Es gibt keine Niederlassungen mit sehr wenigen Ausnahmen. Der gesamte Code muss zuerst in den Kofferraum gelangen und dann voll werden.
Mit dem Wachstum des Repositorys war die einzige Möglichkeit, damit zu arbeiten, das selektive Auschecken, da es in SVN unterstützt wird. Es ist nicht ganz unmöglich, das gesamte Repository auf sich selbst hochzuladen, aber es ist sehr schwierig, damit zu arbeiten.

Wie groß ist unser Problem? Hier einige Zahlen: 6 Millionen Commits, fast 2 Millionen Einzeldateien. Die Gesamtgröße mit dem gesamten Verlauf des Repository beträgt 2 TB. Um zu verdeutlichen, was diese Zahlen im Vergleich zu anderen typischen Repositorys bedeuten, sehen Sie hier ein Diagramm. GitHub-Median ist die Median-Repository-Größe von GitHub, 1 MB. Das 90. Perzentil bei GitHub wurde von meinen Kollegen als "Aufbewahrungsort des Sohnes meiner Mutter" bezeichnet. Und alles andere sind die berühmten großen Aufbewahrungsorte.
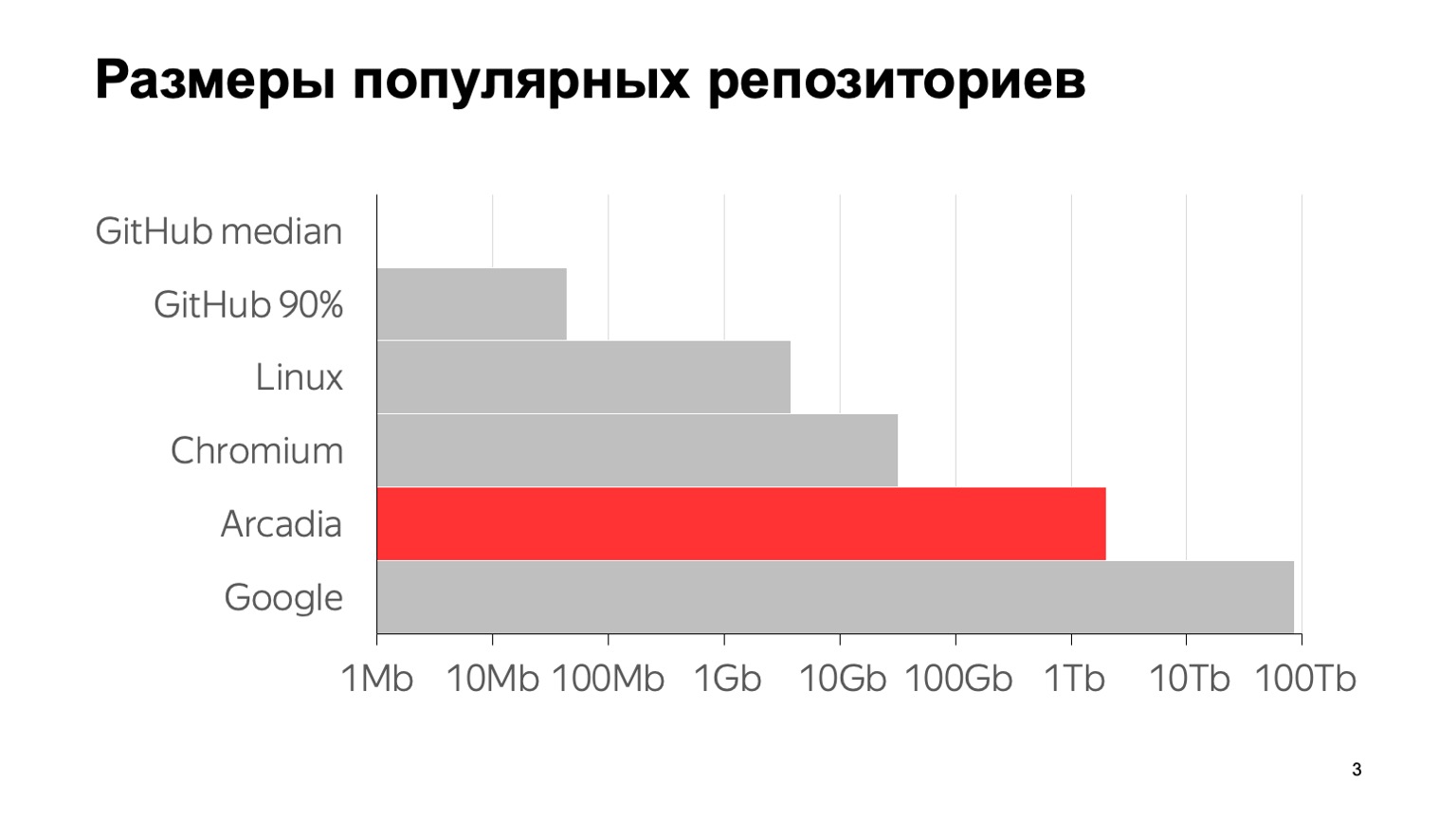
Soweit ich weiß, befindet sich das größte Repository der Welt bei Google. Eine Schätzung der Größe geht aus einem Artikel aus dem Jahr 2015 hervor - wahrscheinlich sind sie seitdem gewachsen. Wie Sie sehen, ist die Skala logarithmisch. Es ist zu sehen, dass wir auch ziemlich groß sind.
Wie funktionieren verschiedene Versionskontrollsysteme, wenn versucht wird, das gesamte Repository herunterzuladen? Natürlich haben wir nicht sofort mit der Entwicklung unseres Versionskontrollsystems begonnen. Wir haben versucht, unser Repository auf verschiedene Systeme umzustellen. Der schwerste Versuch wurde mit Mercurial gemacht. Und die Ergebnisse der Zeit von typischen Operationen passen noch nicht zu uns.
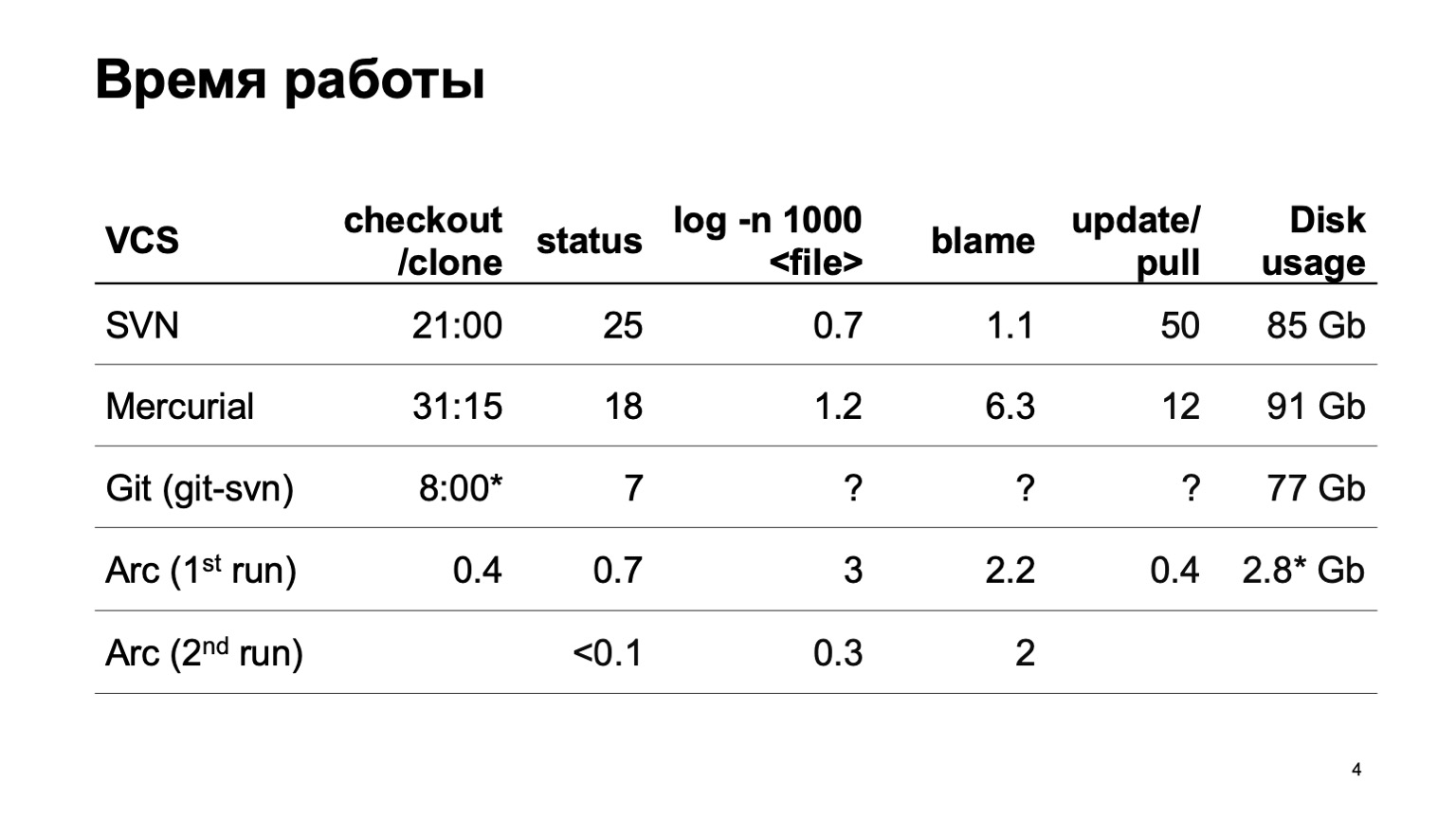
Während der Erstellung des Berichts konnte git-svn leider nicht unser gesamtes Repository konvertieren. Einige Teile einer kleinen Anzahl von Commits wurden konvertiert, sodass ich nicht abschätzen kann, wie viele Operationen im Zusammenhang mit der Historie funktionieren. In einem Segment sind sie schnell und wie es für 6 Millionen Commits sein wird, ist nicht sehr klar.
Am Ende stehen die Nummern für unser Versionskontrollsystem. Sie können sich sofort eine Arbeitskopie besorgen. Beim ersten Start werden die Protokolloperationen etwas verlangsamt, beim zweiten Start funktioniert alles schnell.
Und die letzte Ziffer. Da unser Versionskontrollsystem alle Daten träge lädt, befinden sich nur die Quellcodes auf der Festplatte, die wir wirklich ausgearbeitet haben und die wir wirklich verwendet haben. Dies ist bedeutend weniger als das Herunterladen des Ganzen.

Wie haben wir das erreicht? Das Hauptmerkmal: Die von uns erstellte Arbeitskopie ist keine echte Datei auf der Festplatte. Dies ist ein virtuelles Dateisystem. Unter Linux und Mac erfolgt dies mit fuse, unter Windows mit ProjFS. Wir laden alle Daten träge, damit so viel Speicherplatz verbraucht wird, wie wir wirklich brauchen. Wir versuchen nicht, alles im Voraus zu laden. Und wir führen alle Arten von schweren Operationen auf dem Server aus. Insbesondere - der Betrieb des Protokolls und einige mehr.

Die Oberfläche unseres Versionskontrollsystems wiederholt im Großen und Ganzen Git, sodass ich nicht zeigen kann, wie ein typischer Workflow aussieht. Stell dir Git vor. Alles ist gleich: Checkout, um die gewünschte Revision zu erhalten, Branch, um Branches zu erstellen, Commit für Commits, Stash wird auf die gleiche Weise unterstützt. Was gibt dieser Ansatz? Wir senken die Eintrittsschwelle deutlich. Die meisten Entwickler innerhalb und außerhalb von Yandex können mit Git arbeiten. Sie müssen nichts Neues lernen.
Auf der anderen Seite haben wir kein Ziel, Git zu ersetzen. Ich werde später genauer darauf eingehen. Die ganze Vielfalt der Git-Teams zu unterstützen, scheint verrückt, wir brauchen sie kaum alle.

Ich erzähle Ihnen ein wenig über das Innere, darüber, wie alles funktioniert. Beginnen wir mit dem Datenmodell. Unser Datenmodell ist dem geografischen mit einigen Unterschieden sehr ähnlich. Ebenso sind alle Objekte, die wir in uns erstellen, unveränderlich, werden durch einen Hash ihres Inhalts angesprochen und in flachen Puffern gespeichert.

Wie sieht die Struktur aus? Es gibt Festschreibungsobjekte. Jede Festschreibung hat einen eigenen oder mehrere Vorfahren. Und auf diese Weise bauen sie einige DAG-Geschichten (Directed Acyclic Graph) auf.
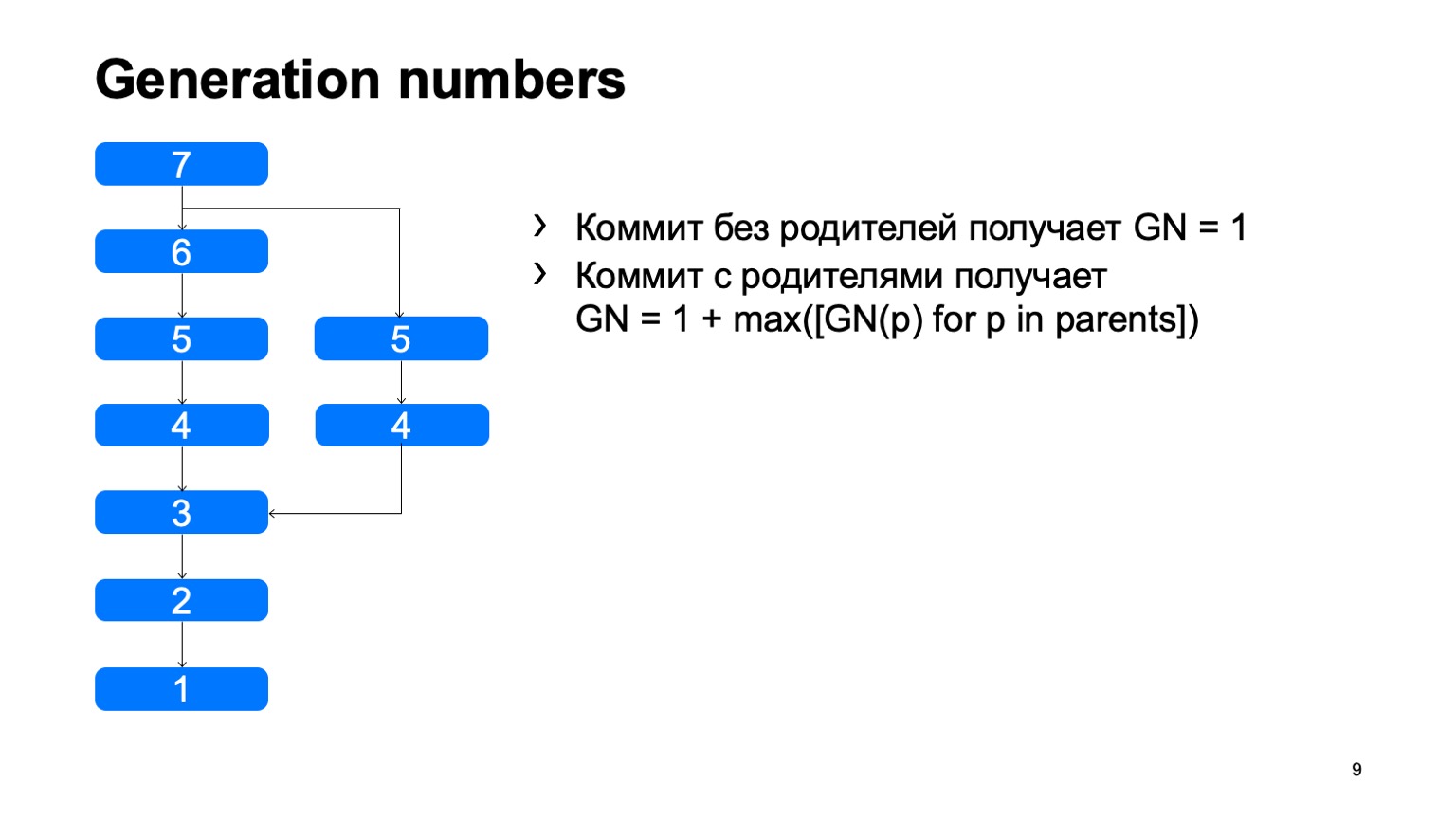
Was wir haben und was nicht sofort in Git auftauchte, sind die Generationsnummern. Mit einem einfachen Algorithmus betrachten wir einen bestimmten Abstand von der Wurzel des Baumes. Warum brauchen wir das? Dies ist alles in die Struktur von Objekten eingenäht, einmal fixiert und ändert sich nie wieder.
Eine ziemlich wichtige Operation für ein Versionskontrollsystem ist das Finden des kleinsten gemeinsamen Vorfahren für die beiden Festschreibungen. In der Basisversion kann es einfach implementiert werden, indem man von zwei Punkten ausgehend in der Breite herumgeht und alle dort erreichten Commits mit dem einen oder anderen Zeichen markiert. Sobald ein Commit gefunden wird, das beide Zeichen enthält, gibt es den am wenigsten verbreiteten Vorfahren.
Wie wird dies in einer naiven Implementierung funktionieren? Etwas in der Art: Gehen Sie herum und finden Sie unser gewünschtes Commit.
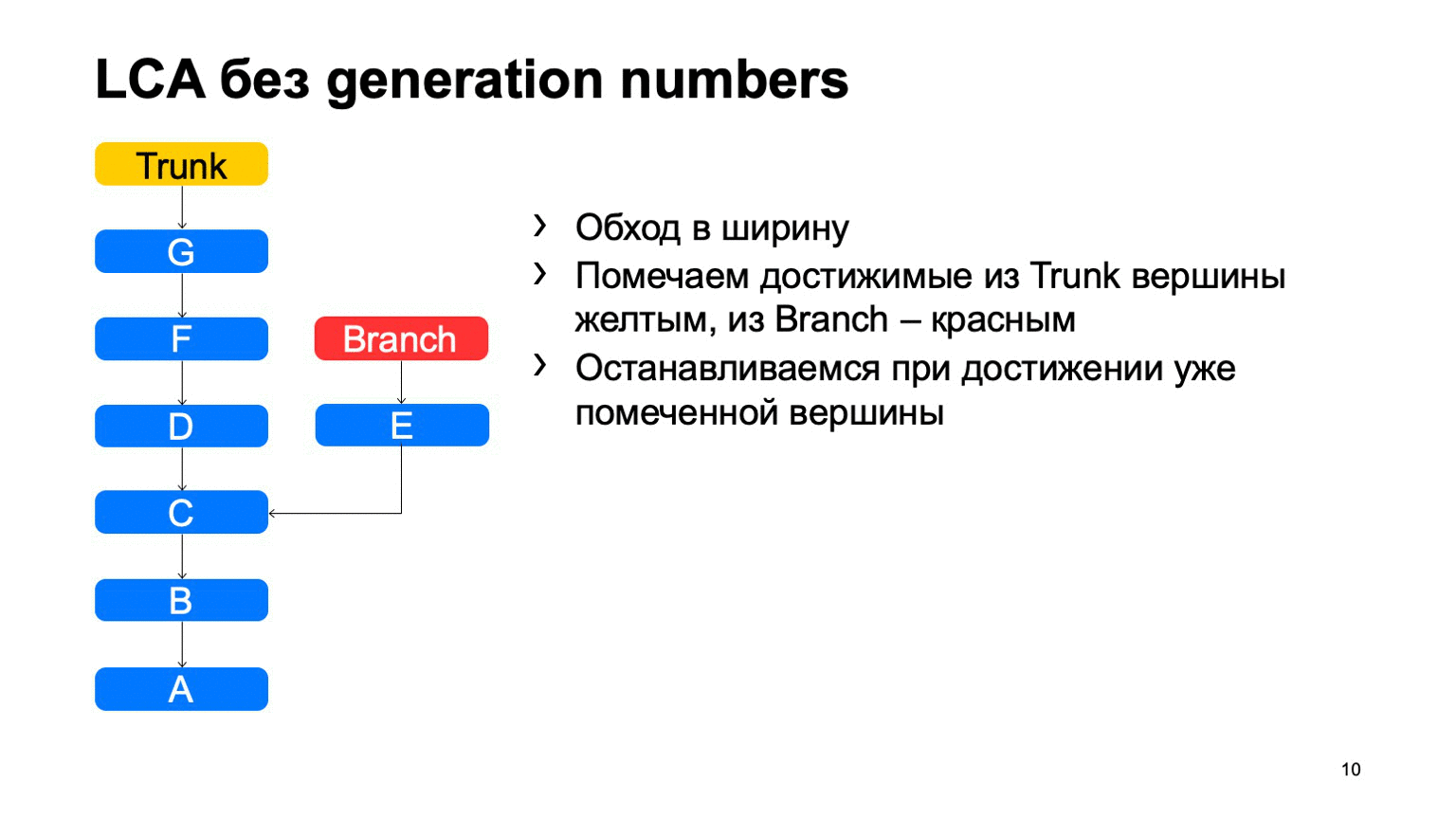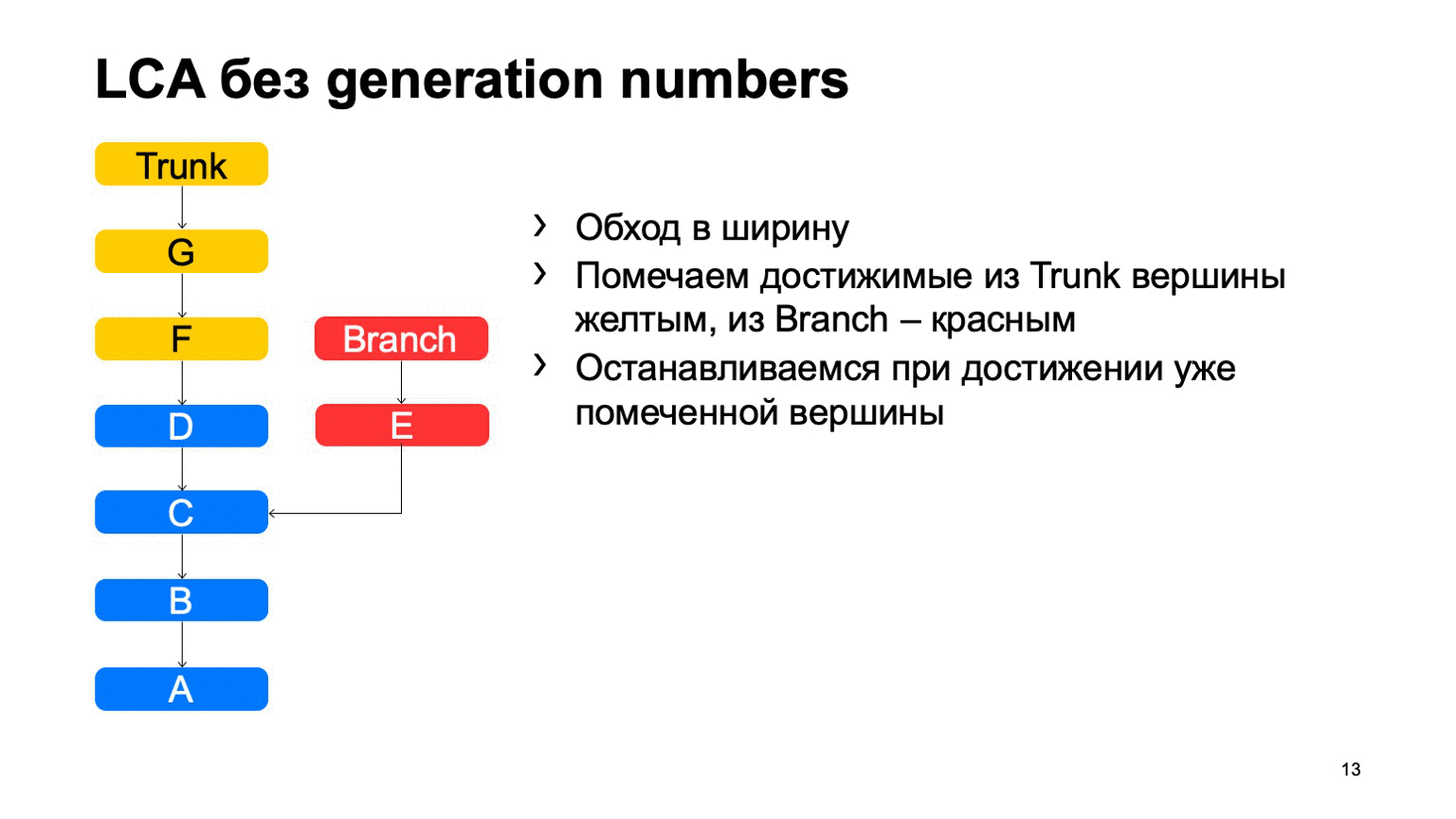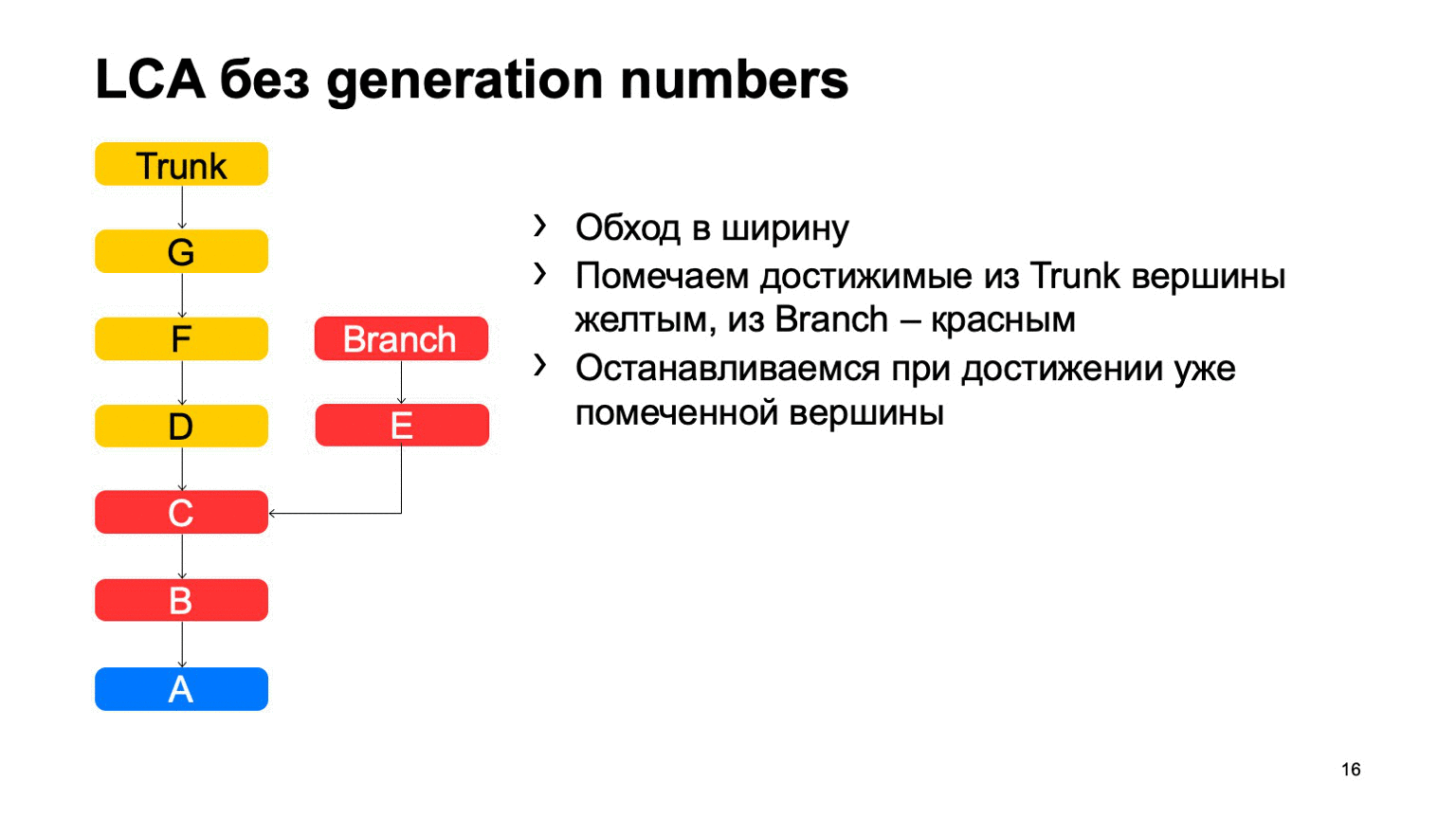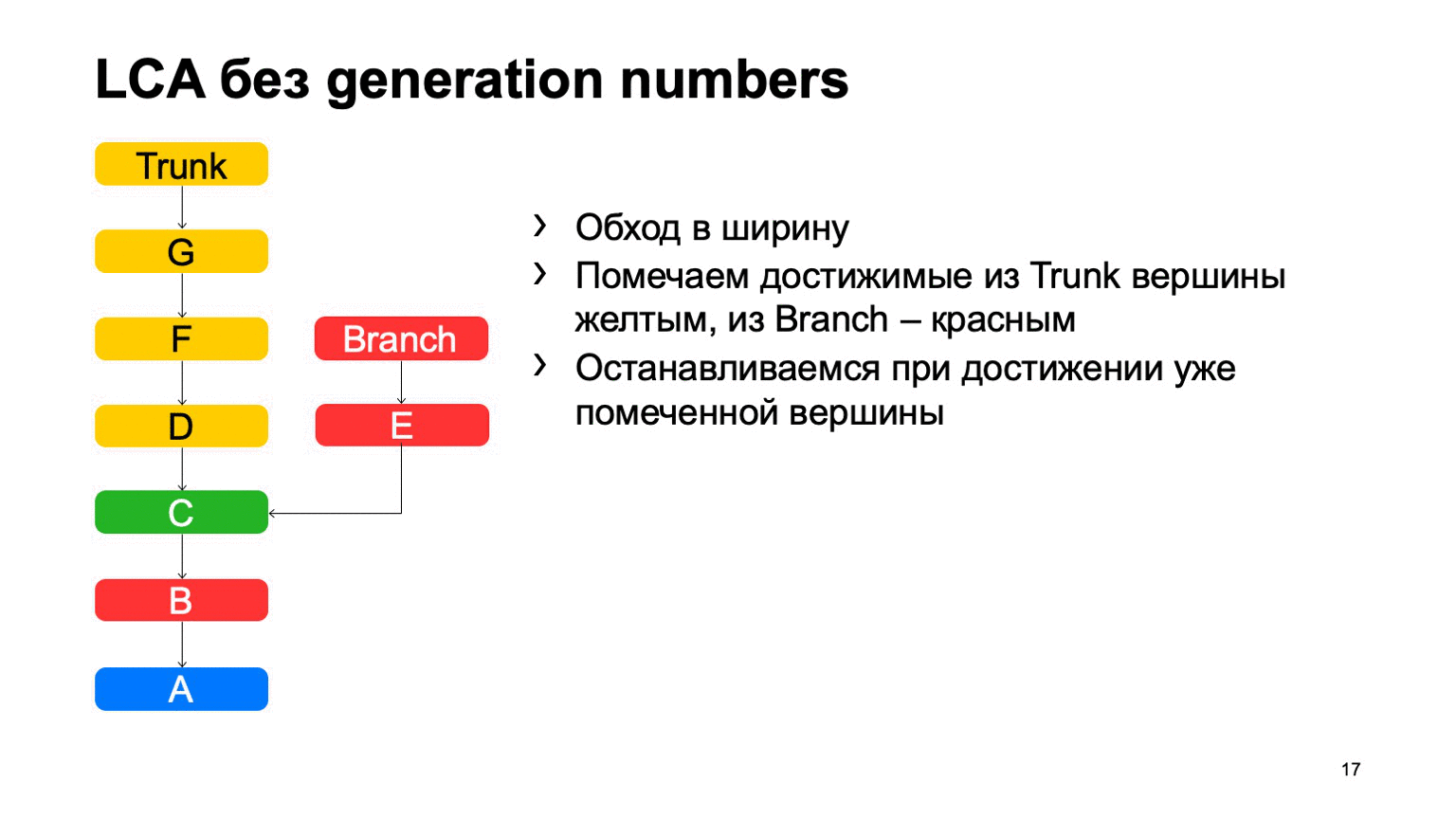
Das Problem ist mit B, was überflüssig ist. Es scheint, dass wir nicht darauf eingehen konnten, aber wir haben es uns angesehen. Und je mehr wir den Unterschied zwischen einem Zweig und einem Stamm anhand eines Beispiels feststellen, desto mehr solcher zusätzlichen Commits werden wir finden. Bei einem Monorepository kann dieser Abstand sehr groß sein, wenn die Anzahl der Festschreibungen für einen Trunk hoch genug ist. Und es wird Zehntausende solcher zusätzlichen Verpflichtungen geben.


Wenn es Generationsnummern gibt, können wir die Prioritätswarteschlange beim Crawlen verwenden, und das Crawlen sieht ungefähr so aus: einmal - und findet sofort, was Sie brauchen.

Dies ist ein Beispiel für den Unterschied zwischen unserem Modell. In Git wurde dieses Ding zuvor unterstützt. Sie verwendeten Zeitstempel für die Generierungsnummern. Dies funktioniert jedoch nur, wenn die Zeiten für das Erstellen von Commits mit dem Commit-Diagramm übereinstimmen.
Leider ist dies in unserer Repository-Historie nicht der Fall. Es gibt Commits, die aus der Migration eines anderen Repositorys resultieren, und die Zeit beginnt, in ihnen rückwärts zu vergehen. In Git wurde dieses Ding irgendwann unterstützt, aber es ist dort nicht immer anwendbar, weil Sie in Git das Festschreibungsobjekt lokal durch ein anderes ersetzen können. Die Immunität des Modells leidet darunter, daher sind diejenigen Generationsnummern, die nicht aufzeichnen, manchmal nicht auf das anwendbar, was in ihnen geschrieben steht, dies ist nicht wahr. Wir haben kein solches Problem.
Ein weiteres Plus dieser Optimierung ist, dass sie vollständig lokal ist. Um diese Zahlen zu verwenden, muss nicht das gesamte Festschreibungsdiagramm vorhanden sein. Und normalerweise haben wir es überhaupt nicht, bei uns wird es faul geladen. Je weniger wir faul laden, desto besser leben wir.
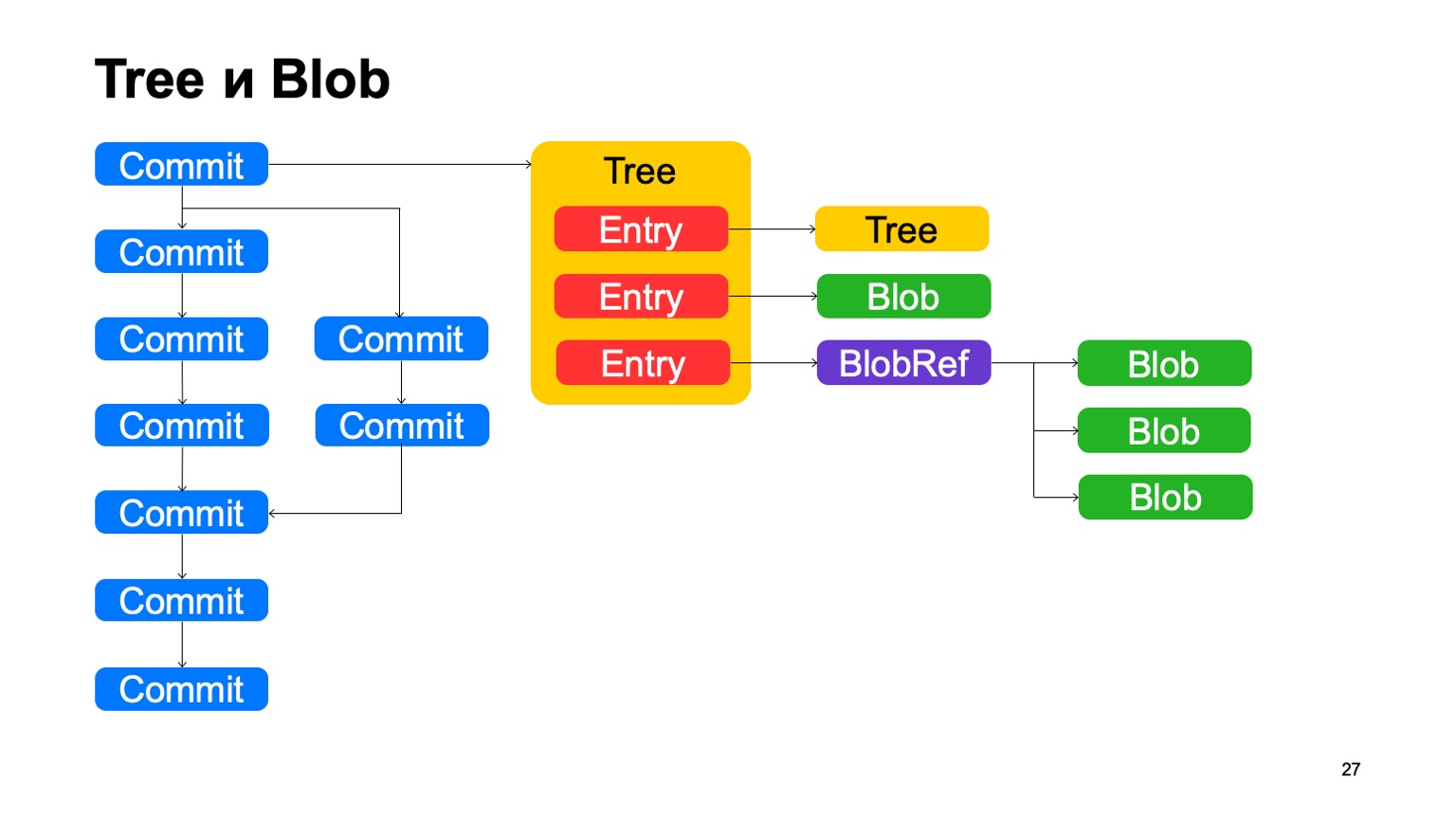
Abgesehen von Commits ist das Modell Git sehr ähnlich. Jedes Commit verweist auf ein bestimmtes Baumobjekt, der Baum besteht aus Datensätzen, jeder Datensatz ist entweder ein anderer Baum, und so wird die Verzeichnishierarchie in uns angezeigt, oder dies ist ein Blob, eine Datei. Außerdem haben wir so etwas wie BlobRef. Wenn die Datei sehr groß ist, teilen wir sie in Stücke und präsentieren sie in einem speziellen Objekt. Das ist alles, wie in Git.

Was wir in Git nicht mögen Wir nennen dieses Ding copy-info. Wenn die Datei in einer Art Commit kopiert wurde, speichert Git diese Informationen in keiner Weise und versucht, sie mit Heuristiken wiederherzustellen, wenn Unterschiede und Status angezeigt werden. Wir speichern diese Informationen in der Grafik. Datensätze verfügen möglicherweise über einen Link mit Kopierinformationen zu einem anderen Commit, zu dem Pfad im Repository in diesem Commit, über den bekannt ist, dass diese Datei in diesem Commit kopiert wurde.
Es gibt auch eine Deduplizierung, da dieser Blob nebenbei einmal gespeichert wird. Die Deduplizierung ist jedoch gleich, da sich der Inhalt der Datei nicht geändert hat und die Deduplizierung durch Hash erfolgt wäre.
Wie sind die Backends angeordnet? Wenn Git über ein verteiltes Versionskontrollsystem verfügt, werden keine Backends benötigt. Wir spüren das besonders deutlich, wenn GitHub nicht verfügbar ist. Wir verstehen klar, dass Git keine Backends benötigt. Unser System ist Client-Server, es speichert alle Daten auf dem Server, und die Serververfügbarkeit ist erforderlich, um die Objekte herunterzuladen, die noch nicht auf dem Client vorhanden sind.

Alle Daten, die wir in der Yandex-Datenbank speichern. Dies ist eine sehr coole Datenbank, die der Transaktion das notwendige Maß an Zuverlässigkeit bietet. Es hat alles, was wir brauchen, und dieses Ding hat uns vor vielen Problemen bewahrt.
Dank dessen sind die Backends selbst völlig zustandslos, der gesamte Status befindet sich in der Datenbank, und die Backends können sehr einfach beliebig skaliert werden.
Und für die Interaktion mit Kunden, die von interserver verwendet werden, gab es heute einen detaillierten Bericht darüber.
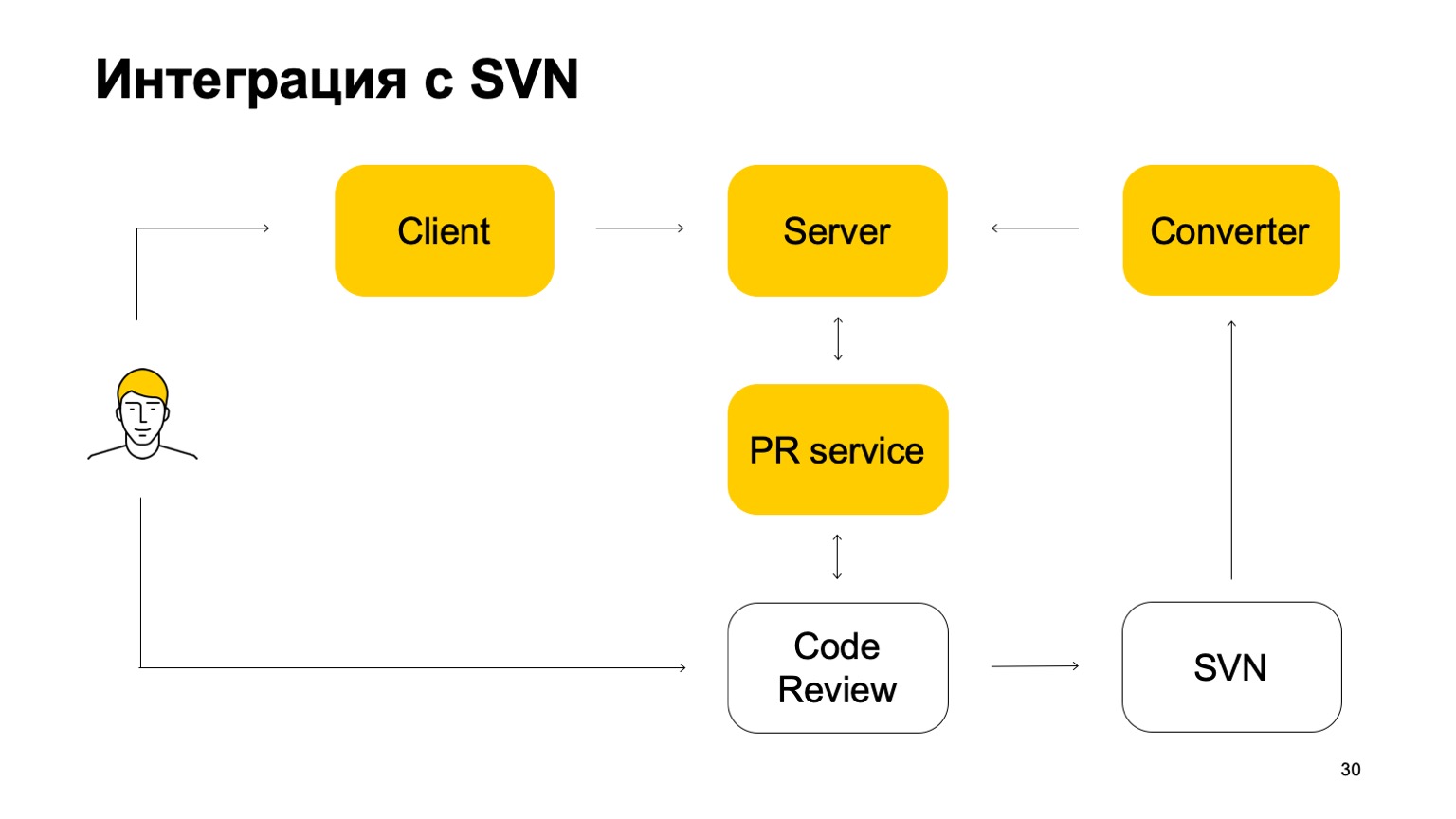
Wie ist unser System in SVN integriert? Das SVN-Repository lebt weiter. Darüber hinaus ist unser Versionskontrollsystem noch nicht autark. Wie arbeitet sie in diesem Teil? Zunächst gibt es eine Converter-Komponente, die den Status des SVN-Repositorys überwacht und SVN-Commits in Arc-Commits umwandelt - unser Versionskontrollsystem.
Als Nächstes gibt es einen Client, der eine Arbeitskopie bereitstellt und Daten vom Server abruft. Wenn ein Entwickler etwas festschreibt, wird es zuerst an den Arc-Server gesendet. Damit diese Änderungen jedoch in den Trunk, unseren Hauptzweig, gelangen, müssen sie das Pool-Anforderungs- und das Code-Überprüfungssystem durchlaufen. Hier kommt ein weiterer Dienst, der die Verzweigungen von Arc überwacht und bei Aktualisierung eine Poolanforderung an unsere Systemcodeüberprüfung sendet. Als nächstes wird das Codeüberprüfungssystem, wenn entschieden wird, dass dieser Patch zusammengeführt werden muss, an SVN übergeben. Nicht ganz einfach: Es fügt dort eine bestimmte Menge von Metadaten hinzu, dass es sich bei diesem Commit tatsächlich um eine Zusammenführung eines solchen und eines solchen Zweigs von Arc handelt. Und dann sieht dieses Commit den Konverter bereits, findet diese Metadaten darin und erstellt ein Commit auf dem Arc-Server. Dies ist der Zyklus von Commits. Daher können wir zwar nicht ohne SVN leben, weil wir Trunk in SVN haben.
Der Hauptzweig wird ständig mit unserem Server synchronisiert, es ist jedoch nicht zulässig, eine direkte Bindung zu ihm herzustellen.

Über die Zuverlässigkeit von Backends. Natürlich planen wir, dass alle Yandex-Entwickler dieses Ding verwenden, deshalb ist es für uns wichtig, dass es nicht kaputt geht. Dies ist ein solcher Intra-Index-Standard: Unsere Services müssen den Ausfall eines Rechenzentrums überstehen. Versionskontrollsystem ist keine Ausnahme. Hier spart uns die Tatsache sehr, dass YDB dies unterstützt. Und unsere Backends sind zustandslos, da verschiedene Teile leicht unterschiedlich implementiert sind. Server, die auf Arc-Objekten ausgeführt werden, werden auf Zweigen ausgeführt. Sie sind zustandslos und werden repliziert. Konverter, die ständig von SVN konvertieren, werden nach dem Aktiv-Aktiv-Schema repliziert. Es arbeiten mehrere Konverter gleichzeitig, sie konvertieren zur gleichen Zeit, und sobald sie versuchen, den Arc-Zweig zu aktualisieren, lösen sie Konflikte. Einer war erfolgreich, der andere scheiterte. Er versucht etwas weiter zu konvertieren.
Der Poolanforderungsdienst wird von Master-Slave repliziert. Es gibt eine Hauptfunktion. Wenn dies fehlschlägt, wird über YDB ein neuer ausgewählt. Es gibt so wunderbare Dinge wie Semaphore, die ernsthafte Garantien für Zugänglichkeit und Zuverlässigkeit bieten. Zugriffe auf Semaphore werden vollständig serialisiert. Wir verwenden Semaphore sowohl für den Pool Request Discovery Service als auch für die Auswahl von Leadern.
Ein wenig darüber, wie der Kunde arbeitet. Dies ist der schwierigste Teil unseres Versionskontrollsystems, da es ein virtuelles Dateisystem gibt. Tatsächlich sind wir gezwungen, alle Operationen an Dateien selbst durchzuführen. Ich gehe einige grundlegende Operationen durch und beschreibe grob an den Fingern, was in ihnen passiert, wenn wir sie ausführen.

Zum Beispiel haben wir eine Datei zur Aufnahme geöffnet. Wenn wir die Datei zum Schreiben öffnen, finden wir den entsprechenden Blob unseres Objektmodells. Laden Sie bei Bedarf etwas vom Server hoch. Wenn wir eine Datei physisch in einem speziellen Speicher erstellen, werden alle weiteren Anforderungen, die an diese Datei gesendet werden, dort weitergeleitet. Bis die lokalisierten Änderungen festgeschrieben sind (in Git wird dies als nicht bereit gestellt bezeichnet), gelangen sie in den temporären Speicher. Wir nennen solche Dateien materialisiert.

Wenn wir die Datei zum Lesen öffnen, können wir nichts materialisieren, sondern einfach Daten direkt aus unserem Blob geben.

In diesem Moment fügen wir die Datei dem Index hinzu. An diesem Punkt müssen Sie sehen, ob wir etwas materialisiert haben. Gibt es eine Datei, die geändert wurde. Wenn dies der Fall ist, erstellen Sie einen Blob und speichern Sie ihn im Index.

Die nächste Operation ist der Lichtbogenstatus. Es ist interessant, weil es in herkömmlichen Versionskontrollsystemen bei solchen Größen langsam ist, weil es den gesamten Dateibaum durchlaufen muss. Wir müssen nicht den gesamten Dateibaum durchsuchen, da alle Anfragen zum Ändern von Dateien über unseren Sicherungstreiber erfolgen und wir sofort wissen, welche Dateien es wert sind, auf Änderungen überprüft zu werden. Wir überprüfen, was wir in den Index geschrieben haben, und drucken die Antwort aus.

Zeit festschreiben. Alles scheint klar zu sein. Es gibt einen Index, für diese Objekte haben wir bereits Blobs erstellt, Baumobjekte, die diesem Status entsprechen, erstellen ein neues Festschreibungsobjekt und schreiben es in den Objektspeicher.

Als nächstes wechseln wir die Arbeitskopie zum neuen Commit. Dies ist eine knifflige Operation, die mit dem Befehl checkout ausgeführt werden kann. Und hier könnte man meinen, dass all unsere lokalen Änderungen bereits eingetreten zu sein scheinen. Wir können davon ausgehen, dass wir dann Dateien zurückgeben sollten, die nicht durch neue Commits zustande gekommen sind. Und alle. Alle nachfolgenden Operationen werden einfach an einen anderen Baum und Blobs gesendet.

Warum könnte das nicht funktionieren? Die erste Version war darüber. Das Problem liegt in allerlei kniffligen Vorgängen wie Arc Reset - Soft. Sie schalten uns einen Baumschalter, materialisieren aber keine Dateien. Sie existieren weiterhin an einem heiligen Ort. Wir haben auch nicht verfolgte und ignorierte Dateien, die ebenfalls auf besondere Weise verarbeitet werden müssen. An dieser Stelle haben wir eine Menge Rakes gesammelt und sind schließlich zu dem Schluss gekommen, dass wir beim Auschecken noch einen Baum (jetzt eine Arbeitskopie) nehmen müssen, den Baum des Commits, zu dem wir wechseln, nehmen den Index und ordentlich abschneiden müssen Warte einen Moment.
In Bezug auf die Komplexität der Algorithmen haben wir hier nichts verloren: Alle diese Bäume lokaler Änderungen sind proportional zu den Änderungen, die wir vorgenommen haben. Daher sollten wir mit diesen Vorgängen nicht das gesamte Repository durchgehen, sie funktionieren immer noch ziemlich schnell.
Gleichzeitig machen wir etwas Magie, damit die Zeitstempel, die wir Dateien geben, mehr oder weniger korrekt sind. Wenn wir nur Dateien im Dateisystem speichern, wird dies überwacht und die Zeit läuft immer weiter. Hier müssen wir uns irgendwie merken, welche Datei der Benutzer zu welchem Zeitpunkt gesehen hat. Und wenn er zu einem früheren Commit gewechselt ist, geben Sie ihm keine frühere Zeit. Da Assembly-Systeme, für die nicht alle IDEs bereit sind, eine Menge Dinge wegnehmen.

In unserem Versionskontrollsystem ist die Unterstützung für die stammbasierte Entwicklung auf den Punkt gebracht. Erstens, was ich bereits gesagt habe: Alle Änderungen durchlaufen die Poolanforderungen und den Trunk. Es gibt noch ein paar Punkte. Wir haben keine Unterstützung für Gruppenzweige. In Arc erstellte Verzweigungen sind an einen bestimmten Benutzer gebunden, und nur dieser kann sie festschreiben. Dies ermöglicht es uns, langlebige Zweige zu vermeiden. In SVN war dies nicht besonders, da es dort unpraktisch ist, Zweige zu machen. Und es ist bequem, sie in Arc zu erstellen. Wenn dies nicht kontrolliert wird, haben wir Angst, dass einige Teile unseres Mono-Repositorys in ihre Filialen abwandern und dort ihre Entwicklung durchführen. Dies widerspricht dem Modell, das wir machen wollen.

Zweitens haben wir keinen Befehl zum Zusammenführen. Alle Zusammenschlüsse von Zweigniederlassungen erfolgen unter unserer strengen Kontrolle. Wir entwickeln jetzt Filialen für Releases, in denen es auch möglich sein wird, zu fusionieren. Dies wird höchstwahrscheinlich auch nicht von einem Benutzerteam, sondern von einer Servermaschine durchgeführt.

Was haben wir vor? 20% der Monorepository-Entwickler verwenden bereits unser Versionskontrollsystem. Wir sind bereits aus einem infantilen Zustand hervorgegangen, dies ist ein ernsthaft genutztes System, es ist einfach unmöglich, es einfach so hinauszuwerfen. Das ultimative Ziel ist es, das Hauptversionskontrollsystem in Yandex zu werden. Wir müssen die verbleibenden 80% der Entwickler irgendwie davon überzeugen, dass wir ziemlich stabil, zuverlässig und brauchbar sind. Es ist klar, dass Sie dafür alle Fehler beheben und die Funktionen in Git beenden müssen.
In gewisser Hinsicht planen wir natürlich, autark zu werden, den Konverter aufzugeben oder in die entgegengesetzte Richtung zu implementieren, sodass zunächst alle Änderungen an Arc und dann an SVN für die beständigsten Programmierer vorgenommen werden.
Jetzt haben wir eine große Herausforderung - die Integration des Versionskontrollsystems in unsere Auto-Assemblierung, in unser CI und in andere Pipelines. Die Herausforderung besteht darin, dass die Leute einen schwachen Geist haben, langsam Code tippen und langsam Commit ausführen. Und sie laden sich den Code zu langsam herunter. Und Robotern wird dieser Nachteil vorenthalten.
— , CI Arc, - . , . . , ++- , , . .
. « Git». : Git. , , .
. Git . , . - . , checkout reset, . , , . : Git. « , ». Git .
. Git, git begin-wave-stash?
:
— .
— , Git ? — , , , . , . Git . , . Vielen Dank.