Oft enthalten Tabellen eine große Anzahl logischer Felder, es gibt keine Möglichkeit, alle zu indizieren, und die Effektivität einer solchen Indizierung ist gering. Für die Arbeit mit beliebigen logischen Ausdrücken in SQL ist jedoch ein mehrdimensionaler Indexierungsmechanismus geeignet, der unter cat erläutert wird.
In SQL werden logische Felder hauptsächlich in zwei Fällen verwendet. Erstens, wenn Sie wirklich ein binäres Attribut benötigen, z. B. 'buy / sell' in der Transaktionstabelle. Solche Attribute ändern sich selten im Laufe der Zeit.
Zweitens, um den Status der
Zustandsmaschine aufzuzeichnen, die den Datensatz beschreibt. Es versteht sich, dass ein logisches Objekt, das einem Tabelleneintrag entspricht, eine Reihe von Zuständen durchläuft, deren Anzahl und die Übergänge zwischen ihnen durch angewandte Logik bestimmt werden. Ein einfaches Beispiel ist die „Soft-Delete“ -Technik, bei der ein Datensatz nicht physisch zerstört, sondern nur als gelöscht markiert wird.
Wenn die Maschine komplex ist, kann es eine ganze Menge solcher Felder geben, in einer
unserer Tabellen gibt es 58 (+14 veraltete) solche Felder (einschließlich Flaggensätze) und dies ist nicht ungewöhnlich. Dies war ursprünglich nicht beabsichtigt, aber wenn sich das Produkt entwickelt und die externen Anforderungen ändern, entwickeln sich die entsprechenden Maschinen, Entwickler kommen und gehen, Analysten ändern sich ... Irgendwann ist es sicherer, eine neue Flagge zu bekommen, als alle Feinheiten zu verstehen. Darüber hinaus haben sich historische Daten angesammelt, und ihre Bedingungen müssen angemessen bleiben.
offtopicIn gewisser Hinsicht ähnelt dies dem Evolutionsprozess, in dem eine Vielzahl von Informationen / Mechanismen im Genom gespeichert sind, die auf den ersten Blick überhaupt nicht benötigt werden, aber nicht entfernt werden können. Andererseits lohnt es sich, diese Mechanismen zu respektieren, weil sie es den evolutionären Vorgängern ermöglichten, zu überleben (auch während des
großen Aussterbens ) und die evolutionäre Rasse zu gewinnen. Wer weiß schon, wohin uns die Evolution führen wird und was sich in Zukunft als nützlich erweisen wird?
Ein Flag zu setzen bedeutet nicht nur, ein Feld des entsprechenden Typs hinzuzufügen, sondern es auch bei der Operation des Automaten zu berücksichtigen, welche Zustände es beeinflusst und an welchen Übergängen es beteiligt ist. In der Praxis sieht es so aus:
- Ein Prozess oder eine Reihe von Prozessen, nennen wir sie "Schreiber", erstellen neue Datensätze im Anfangszustand (möglicherweise in einem der Anfangszustände).
- Bei einigen Prozessen, nennen wir sie "Leser", lesen sie von Zeit zu Zeit Objekte, die sich in den von ihnen benötigten Zuständen befinden
- Bei einer Reihe von Prozessen nennen wir sie "Handler", überwachen bestimmte Zustände und ändern diese Zustände auf der Grundlage der angewandten Logik. Das heißt Betreiben Sie eine Zustandsmaschine.
Um Datensätze auszuwählen, die sich in einem bestimmten Zustand befinden, ist es selten, dass das Filtern nach einem der Booleschen Felder ausreichend ist. Normalerweise ist dies ein ganzer Ausdruck, manchmal nicht trivial. Es scheint, dass Sie diese Felder indizieren müssen, und der SQL-Prozessor wird es herausfinden. Aber nicht so einfach.
Erstens kann es viele Boolesche Felder geben, deren Indizierung zu verschwenderisch wäre.
Zweitens könnte es sich seitdem als unbrauchbar herausstellen Die Selektivität für jedes der Felder ist gering, und die gemeinsame Wahrscheinlichkeit wird von den Statistiken des SQL-Prozessors nicht abgedeckt.
Angenommen, in Tabelle T1 gibt es zwei Boolesche Felder: F1 und F2 sowie die Abfrage
select F1, F2, count(1) from T1 group by F1, F2
gibt aus
Das heißt Obwohl nach F1 & F2 wahr und falsch gleich wahrscheinlich sind, fällt die Kombination (wahr, falsch) nur einmal aus tausend heraus. Wenn wir F1 und F2 separat indizieren
und erzwingen, dass sie in der Abfrage verwendet werden , müsste der SQL-Prozessor folglich die Hälfte beider Indizes lesen und die Ergebnisse kreuzen. Es kann billiger sein, die gesamte Tabelle zu lesen und den Ausdruck für jede Zeile zu berechnen.
Und selbst wenn Sie Statistiken über abgeschlossene Anforderungen erfassen, ist dies nicht von großem Nutzen. Statistiken speziell für die Felder, die für den Zustand der Maschine verantwortlich sind, schweben sehr stark. In der Tat kann jederzeit ein "Handler" kommen und die Hälfte der Leitungen von Zustand S1 nach S2 übertragen.
Um mit solchen Ausdrücken arbeiten zu können, bietet sich ein mehrdimensionaler Index an, dessen Algorithmus
zuvor vorgestellt wurde und sich als recht gut erwiesen hat.
Aber zuerst müssen Sie herausfinden, wie aus einem beliebigen logischen Ausdruck eine Abfrage für den Index wird.
Disjunktive Normalform
Eine einzelne Abfrage für einen mehrdimensionalen Index ist ein mehrdimensionales Rechteck, das den Abfragebereich begrenzt. Wenn das Feld an der Anforderung teilnimmt, wird eine Einschränkung dafür festgelegt. Wenn nicht, wird das Rechteck in dieser Koordinate nur durch die Breite dieser Koordinate begrenzt. Logische Koordinaten haben eine Kapazität von 1.
Eine Suchabfrage in einem solchen Index ist eine Kette von & (Konjunktion), zum Beispiel der Ausdruck: v1 & v2 & v3 & (! V4), äquivalent zu v1: [1,1], v2: [1,1], v3: [1, 1], v4: [0,0]. Und alle anderen Felder haben einen Bereich: [0,1].
Angesichts dessen wendet sich unser Blick sofort der
DNF zu - einer der kanonischen Formen logischer Ausdrücke. Es wird argumentiert, dass jeder Ausdruck als Disjunktion literarischer Konjunktionen dargestellt werden kann. Ein Literal bezieht sich hier auf ein logisches Feld oder dessen Negation.
Mit anderen Worten, durch einfache Manipulationen kann jeder logische Ausdruck als Disjunktion mehrerer Abfragen zu einem mehrdimensionalen logischen Index dargestellt werden.
Es gibt einen ABER. Eine solche Transformation kann in einigen Fällen zu einer exponentiellen Vergrößerung des Ausdrucks führen. Zum Beispiel Konvertierung von
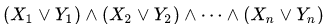
führt zu einem Ausdruck von 2 ** n Termen. In solchen Fällen sollte der Anwendungsentwickler über die physikalische Bedeutung seiner Tätigkeit nachdenken. Auf Seiten des SQL-Prozessors können Sie die Verwendung des logischen Index immer dann ablehnen, wenn die Anzahl der Konjunktionen die angemessenen Grenzwerte überschreitet.
Mehrdimensionaler Indexierungsalgorithmus
Für die mehrdimensionale Indizierung werden die Eigenschaften einer selbstähnlichen Nummerierungskurve verwendet, die auf hyperkubischen Simplexen mit Seite 2 basiert. Wie
sich herausstellte , sind zwei Versionen solcher Kurven von praktischer Bedeutung - die Z-Kurve und die Hilbert-Kurve.
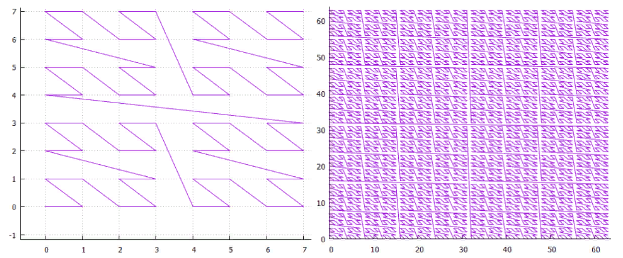 Abbildung 1 zweidimensionale Z-Kurve, 3 und 6 Iterationen
Abbildung 1 zweidimensionale Z-Kurve, 3 und 6 Iterationen Abbildung 2 zweidimensionale Hilbert-Kurve, Iterationen 3 und 6
Abbildung 2 zweidimensionale Hilbert-Kurve, Iterationen 3 und 6- Ein N-dimensionaler Simplex mit Seite 2 hat 2 ** n Eckpunkte und (2 ** n-1) Übergänge zwischen diesen.
- Eine elementare Iteration eines Simplex verwandelt jeden Scheitelpunkt eines Simplex in einen Simplex einer niedrigeren Ebene.
- Wenn wir die erforderliche Anzahl von Iterationen durchgeführt haben, können wir ein hyperkubisches Gitter beliebiger Größe konstruieren.
- Außerdem hat jeder Knoten dieses Gitters eine eigene eindeutige Nummer - den Pfad, der von Beginn an entlang der Nummerierungskurve verläuft. Darüber hinaus hat jeder Knoten dieses Gitters einen Wert in jeder der Koordinaten. Tatsächlich übersetzt die Nummerierungskurve den mehrdimensionalen Punkt in einen eindimensionalen Wert, der zum Indizieren mit einem regulären B-Baum geeignet ist .
- Alle Knoten, die sich in einem Simplex einer beliebigen Ebene befinden, befinden sich in demselben Intervall, und dieses Intervall schneidet sich nicht mit einem Simplex derselben Ebene.
- Daher kann jedes Suchrechteck (Kästchen) in eine kleine Anzahl von hyperkubischen Unterabfragen unterteilt werden, in denen der Index jeweils von einer Suche / Traverse gelesen werden kann.
- Dazu fügen wir die Magie der Low-Level-Arbeit mit dem B-Tree hinzu, um keine unnötigen Anfragen zu stellen, und ... der Algorithmus ist fertig.
So funktioniert es in der Praxis:
 Abbildung 3 Beispielsuche im zweidimensionalen Index (Z-Kurve)
Abbildung 3 Beispielsuche im zweidimensionalen Index (Z-Kurve)Abbildung 3 zeigt die Aufteilung des ursprünglichen Suchbereichs in Unterabfragen und die gefundenen Punkte. Es wurde ein zweidimensionaler Index verwendet, der auf einer zufälligen, gleichmäßig verteilten Menge von 100.000.000 Punkten im Umfang aufgebaut war [1.000.000, 1.000.000].
Logischer mehrdimensionaler Index
Da es sich um eine mehrdimensionale Indizierung handelt, ist es an der Zeit, darüber nachzudenken, wie viel mehrdimensional es sein kann. Gibt es objektive Einschränkungen?
Da der B-Baum eine Seitenorganisation hat und ein Baum sein soll, muss sichergestellt sein, dass mindestens zwei Elemente auf die Seite passen. Wenn Sie die Seite für 8 KB verwenden, kann das Speichern eines Elements nicht mehr als 4 KB umfassen. In 4K passen ohne Komprimierung etwa 1000 32-Bit-Werte. Dies ist eine Menge, über die Grenzen einer vernünftigen Anwendung hinaus können wir sagen, dass die physikalischen Grenzen praktisch nicht verfügbar sind.
Es gibt eine andere Seite, jede zusätzliche Dimension ist keineswegs frei, sie beansprucht Speicherplatz und verlangsamt die Arbeit. Aus Sicht der „physikalischen Bedeutung“ sollten Felder, die sich gleichzeitig ändern, in den gleichen Index aufgenommen werden, und die Suche nach ihnen geht auch zusammen. Es hat keinen Sinn, alles in einer Reihe zu indizieren.
Logische Felder sind unterschiedlich. Wie wir gesehen haben, können Dutzende von logischen Feldern an denselben Mechanismen beteiligt sein. Und die Speicher- / Lesekosten sind recht gering. Es ist eine Versuchung, alle logischen Felder in einem Index zu sammeln und zu sehen, was passiert.
Es stimmt, es gibt Nuancen:
- Bisher wurden im indizierten Wert die Ziffern verschiedener Koordinaten gemischt, in den niedrigstwertigen Ziffern des Schlüssels die niedrigstwertigen Bits der Koordinaten ... Daher war die Reihenfolge der Felder während der Indizierung unerheblich.
- Jetzt wird ein Bit zum Speichern des Wertes eines logischen Feldes ausgegeben. Das heißt Einige logische Felder werden an das Ende des Schlüssels und einige an den Anfang gehen. Dies bedeutet, dass das Filtern nach einem Teil der Felder sehr effektiv und nach einigen sehr ineffizient ist. Wenn wir in der niedrigsten Reihenfolge suchen, müssen wir den gesamten Index lesen, um eine Antwort zu erhalten. Dies ist jedoch (höchstwahrscheinlich) besser, als die gesamte Tabelle zu lesen, um dieselbe Frage zu beantworten.
- Es gibt ein Problem der Wahl - alle logischen Felder sind gleich, aber einige sind gleich wie andere. Aus allgemeinen Überlegungen ist es notwendig, die Verzerrungen der Statistik zu betrachten. Je stärker das Verhältnis von wahr zu falsch für ein bestimmtes Feld ist, desto älter ist die Entladung, in der sein Wert sein wird.
- Die Unterteilung nach der Art der Nummerierungskurve verschwindet, wenn früher zwischen der Z-Kurve und der Hilbert-Kurve gewählt werden musste, gibt es bei Einzelbitdaten keinen praktischen Unterschied.
- NULLs. Aufgrund der Tatsache, dass NULL kein unbekannter Wert ist, jedoch kein Wert vorhanden ist, sollten solche Datensätze nicht in den Index aufgenommen werden. In eindimensionalen Indizes ist dies der Fall. In unserem Fall kann sich jedoch herausstellen, dass einige der logischen Felder Werte enthalten und andere nicht. Aus diesem Grund können wir dies seitdem nicht mehr in den Index aufnehmen Der Suchalgorithmus kann nicht mit ternärer Logik arbeiten. Und deshalb sollten solche Datensätze nicht in die Tabelle eingefügt werden können (wenn es einen mehrdimensionalen Index gibt, übrigens nicht unbedingt einen logischen).
Es wird erwartet, dass ein logischer mehrdimensionaler Index in einigen Fällen nicht sehr effizient arbeitet. Streng genommen kann jeder Index ineffizient arbeiten, wenn zu viele Daten in den Suchbereich fallen. Bei einem logischen mehrdimensionalen Index wird dies jedoch durch die Abhängigkeit von der oben beschriebenen Halbbildreihenfolge verstärkt, wenn Sie für ein kleines Ergebnis den gesamten Index lesen müssen. Soweit dies in der Praxis ein Problem darstellt, kann nur das Experiment zeigen.
Numerisches Experiment
Einen Index erstellen:
- der Index wird 128-Bit sein, d.h. Auf 128 logischen Feldern aufgebaut
- und enthält 2 ** 30 Elemente
- Der Wert des Indexelements ist eine Zahl von 0 bis 2 ** 30
- der Schlüssel des Indexelements wird dieselbe Zahl sein, die 48 Bits nach links verschoben ist, d.h. Die logischen Felder 48 bis 78 werden in derselben Reihenfolge mit den Ziffern der Nummer gefüllt
- Als Ergebnis erhalten wir 30 signifikante logische Felder in der Mitte des Schlüssels, die verbleibenden Bits werden mit 0 gefüllt
- Jedes der Booleschen Felder hat die gleiche Statistik true / false
- Alle sind statistisch unabhängig.
Suche:
- Jedes Experiment entspricht der Auswahl mehrerer aufeinanderfolgender logischer Felder und der Zuweisung von Suchwerten für diese. Nicht weil der Algorithmus nur in Streifen suchen kann, sondern weil es möglich ist, die Ergebnisse des Experiments klarer darzustellen, haben wir nur zwei Dimensionen - die Breite des Streifens und seine Position
- Insgesamt 24 Versuchsreihen. In jeder Reihe werden wir nach Werten suchen, bei denen der Streifen der logischen Felder der entsprechenden Breite N (von 1 bis 24 Bit) den Wert true annimmt.
- In jeder Reihe wird es eine Unterreihe von Experimenten geben, in denen sich ein Streifen von logischen Feldern einer ausgewählten Breite mit unterschiedlichen Verschiebungen S vom Anfang des Streifens in 30 signifikante logische Felder befindet. Insgesamt (30-N) Experimente in den Unterserien.
- In jedem Experiment wird nach allen Elementen des Index gesucht, die die Bedingung erfüllen, d.h. Felder mit Zahlen im Intervall [48 + S, 48 + S + N -1] werden im Intervall [1,1] gesucht, der Rest im Intervall [0,1]
- Die Suche erfolgt von einem Kaltstart aus
- Das Ergebnis ist die Anzahl der gelesenen Plattenseiten, einschließlich Caching (4096 Seiten-Cache).
- Die Kontrolle der korrekten Operation erfolgt auf zwei Arten: Die Anzahl der gefundenen Elemente muss 2 ** (30-N) betragen, und in den gefundenen Werten können Sie die entsprechenden Ziffern überprüfen
Also
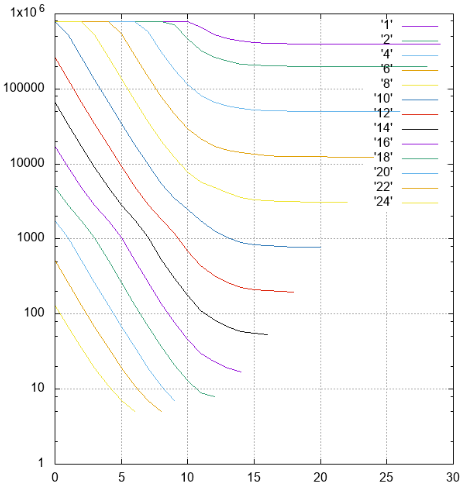 Abbildung 4 Ergebnisse, die Anzahl der gelesenen Seiten in verschiedenen Serien
Abbildung 4 Ergebnisse, die Anzahl der gelesenen Seiten in verschiedenen SerienMit Y - die Anzahl der gelesenen Seiten wird verschoben.
Auf X - Verschiebung von Streifen von der jüngsten (48) Kategorie zum Senior. Streifen unterschiedlicher Breite sind farblich signiert und gekennzeichnet.
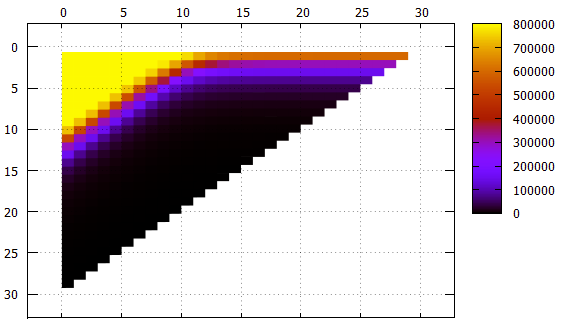 Abbildung 5 Die gleichen Daten wie in Abbildung 4, eine andere Ansicht
Abbildung 5 Die gleichen Daten wie in Abbildung 4, eine andere AnsichtX - Bandverschiebung
Y - Bandbreite
Was ist zu beachten:
- Obwohl dies in den Bildern nicht direkt sichtbar ist, funktioniert der Index ordnungsgemäß. Er ist sowohl in der Anzahl der gefundenen Elemente als auch im Inhalt der Elemente selbst sichtbar
- Alle Streifen mit einer Breite von nicht mehr als 10 mit einer Verschiebung von 0 erfordern ein kontinuierliches Lesen des Index
- Streifen mit einer Breite von 1 bis 18 mit einer Zunahme der Verschiebung erreichen die Asymptote 2 ** (- N) der Größe des gesamten Index, was logisch ist
- Für breitere Bereiche der Asymptote - die Höhe des Baumes - kann es nicht weniger Messwerte geben
- Etwas mehr als 1000 Elemente sind auf der Blattseite des Index platziert. Dies ist in einem Streifen mit der Breite 10 zu sehen. Wenn beim Verschieben von 0 nicht mehr der gesamte Index gelesen werden muss, können einige Seiten übersprungen werden
- Low-Level-Filterung funktioniert überraschend gut. Stellen Sie sich einen Streifen mit einer Breite von 10 vor. Eine ideale Suchoption ist eine Verschiebung von 20 (insgesamt 30 signifikante Felder). Wenn das Präfix keine undefinierten Felder enthält, können die Daten mit einem einzelnen Strahl gefunden werden. In dieser Situation wird ungefähr 1/1000 des Index während der Suche gelesen - 779 Seiten.
Der Zwischenfall ist eine Verschiebung von 10, wir haben ein Präfix und ein Suffix von 10 unbekannten Feldern. Die Seitenzahl beträgt 2484, nur dreimal so viel wie im Idealfall.
Und selbst im schlimmsten Fall können Sie mit einer Verschiebung von 0 (einem Präfix von 20 unbekannten Feldern) einige Seiten überspringen.
Insgesamt kann der mehrdimensionale Indexierungsalgorithmus auch in einem solchen absurden Fall als effizient angesehen werden.
Die aus Sicht des logischen Index erfolgloseste Option wird jedoch in Betracht gezogen - gleichwahrscheinliche Zustände in allen unabhängigen logischen Feldern.Experimentieren Sie mit realen Daten
Handelstabelle, insgesamt 278.479.918 Zeilen, Daten aus einer der Testschleifen.
Die Ergebnisse einiger Abfragen in der folgenden Tabelle:
Das Lesen / Verarbeiten einer einzelnen Seite dauert durchschnittlich 0,8 ms.
Es ist nicht erforderlich, die Bedeutung bestimmter Abfragen zu beschreiben. Sie dienen lediglich der Veranschaulichung der Bedienbarkeit. Was übrigens bestätigt wird.
Aber bevor diese Technik von praktischem Nutzen sein kann, bleibt noch viel zu tun. Also, weiter so.