 Es tut nur zum ersten Mal weh!
Es tut nur zum ersten Mal weh!Hallo allerseits! Liebe Freunde, in diesem Artikel möchte ich meine Erfahrungen mit TensorRT, RetinaNet, basierend auf dem Repository
github.com/aidonchuk/retinanet-examples , teilen (dies ist eine Abzweigung des offiziellen Turnkeys von
nvidia , mit dem wir so schnell wie möglich optimierte Modelle in der Produktion einsetzen können).
Wenn ich
durch die Community-
Kanäle von ods.ai scrolle, stoße ich auf Fragen zur Verwendung von TensorRT, und die meisten Fragen werden wiederholt. Daher habe ich beschlossen, eine
möglichst umfassende Anleitung für die Verwendung von Fast Inference auf der Basis von TensorRT, RetinaNet, Unet und Docker zu verfassen.
AufgabenbeschreibungIch schlage vor, die Aufgabe folgendermaßen zu definieren: Wir müssen den Datensatz markieren, das RetinaNet / Unet-Netzwerk auf Pytorch1.3 + trainieren, die empfangenen Gewichte in ONNX konvertieren, sie dann in die TensorRT-Engine konvertieren und das Ganze in Docker ausführen, vorzugsweise auf Ubuntu 18 und extrem vorzugsweise auf der ARM (Jetson) * -Architektur, wodurch die manuelle Bereitstellung der Umgebung minimiert wird. Als Ergebnis erhalten wir einen Container, der nicht nur für den Export und die Schulung von RetinaNet / Unet bereit ist, sondern auch für die vollständige Entwicklung und Schulung der Klassifizierung, Segmentierung mit allen erforderlichen Bindungen.
Stufe 1. Vorbereitung der UmgebungEs ist wichtig anzumerken, dass ich in letzter Zeit die Verwendung und Bereitstellung von mindestens einigen Bibliotheken auf dem Desktop-Computer sowie auf devbox vollständig aufgegeben habe. Das einzige, was Sie erstellen und installieren müssen, ist die virtuelle Python-Umgebung und Cuda 10.2 (Sie können sich auf einen einzigen NVIDIA-Treiber beschränken) von Deb.
Angenommen, Sie haben ein frisch installiertes Ubuntu 18. Installieren Sie cuda 10.2 (deb). Ich werde nicht im Detail auf den Installationsprozess eingehen, die offizielle Dokumentation reicht völlig aus.
Jetzt installieren wir Docker. Die Docker-Installationsanleitung ist leicht zu finden. Hier ist ein Beispiel:
www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-de . Die Version 19+ ist bereits verfügbar. Vergessen Sie nicht, die Verwendung von Docker ohne sudo zu ermöglichen, da dies bequemer ist. Nachdem sich herausgestellt hat, machen wir das so:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.imtqy.com/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.imtqy.com/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
Und Sie müssen nicht einmal in das offizielle Repository
github.com/NVIDIA/nvidia-docker schauen.
Jetzt git clone
github.com/aidonchuk/retinanet-examples .
Es bleibt nur ein bisschen, um Docker mit nvidia-image nutzen zu können, müssen wir uns in der NGC Cloud registrieren und einloggen. Wir gehen hier auf
ngc.nvidia.com , registrieren uns und
drücken , nachdem wir die NGC Cloud
betreten haben , SETUP in der oberen linken Ecke des Bildschirms oder folgen diesem Link
ngc.nvidia.com/setup/api-key . Klicken Sie auf "Schlüssel generieren". Ich empfehle, es zu speichern. Andernfalls müssen Sie es beim nächsten Besuch neu generieren und diesen Vorgang wiederholen, wenn Sie es auf einer neuen Schubkarre einsetzen.
Ausführen:
docker login nvcr.io Username: $oauthtoken Password: <Your Key> -
Benutzername einfach kopieren. Bedenken Sie, dass die Umgebung bereitgestellt ist!
Phase 2. Zusammenbau des Docker-ContainersIn der zweiten Phase unserer Arbeit werden wir Docker zusammenstellen und uns mit dessen Inneren vertraut machen.
Gehen wir zum Root-Ordner des Retina-Beispielprojekts und führen es aus
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Wir sammeln Docker, indem wir den aktuellen Benutzer hineinwerfen. Dies ist sehr nützlich, wenn Sie auf einem bereitgestellten VOLUME etwas mit den Rechten des aktuellen Benutzers schreiben, da es sonst zu Problemen und Problemen kommt.
Sehen wir uns die Docker-Datei an, während Docker ausgeführt wird:
FROM nvcr.io/nvidia/pytorch:19.10-py3 ARG USER=alex ARG UID=1000 ARG GID=1000 ARG PW=alex RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master COPY . retinanet/ RUN pip install --no-cache-dir -e retinanet/ RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl RUN pip install tensorboardx RUN pip install albumentations RUN pip install setproctitle RUN pip install paramiko RUN pip install flask RUN pip install mem_top RUN pip install arrow RUN pip install pycuda RUN pip install torchvision RUN pip install pretrainedmodels RUN pip install efficientnet-pytorch RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch RUN pip install pytorch_toolbelt RUN chown -R ${USER}:${USER} retinanet/ RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping RUN mkdir /var/run/sshd RUN echo 'root:pass' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile CMD ["/usr/sbin/sshd", "-D"]
Wie Sie dem Text entnehmen können, nehmen wir alle unsere Favoriten, kompilieren das Retinanet, verteilen grundlegende Tools für die bequeme Arbeit mit Ubuntu und konfigurieren den openssh-Server. Die erste Zeile ist nur die Vererbung des NVIDIA-Images, für das wir uns in NGC Cloud angemeldet haben und das Pytorch1.3, TensorRT6.xxx und eine Reihe von Bibliotheken enthält, mit denen wir den CPP-Quellcode für unseren Detektor kompilieren können.
Phase 3. Starten und Debuggen des Docker-ContainersFahren wir mit dem Hauptfall der Verwendung des Containers und der Entwicklungsumgebung fort, um nvidia docker zu starten und auszuführen. Ausführen:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest
Jetzt ist der Container unter ssh <curr_user_name> @localhost verfügbar. Öffnen Sie nach einem erfolgreichen Start das Projekt in PyCharm. Als nächstes öffnen
Settings->Project Interpreter->Add->Ssh Interpreter
Schritt 1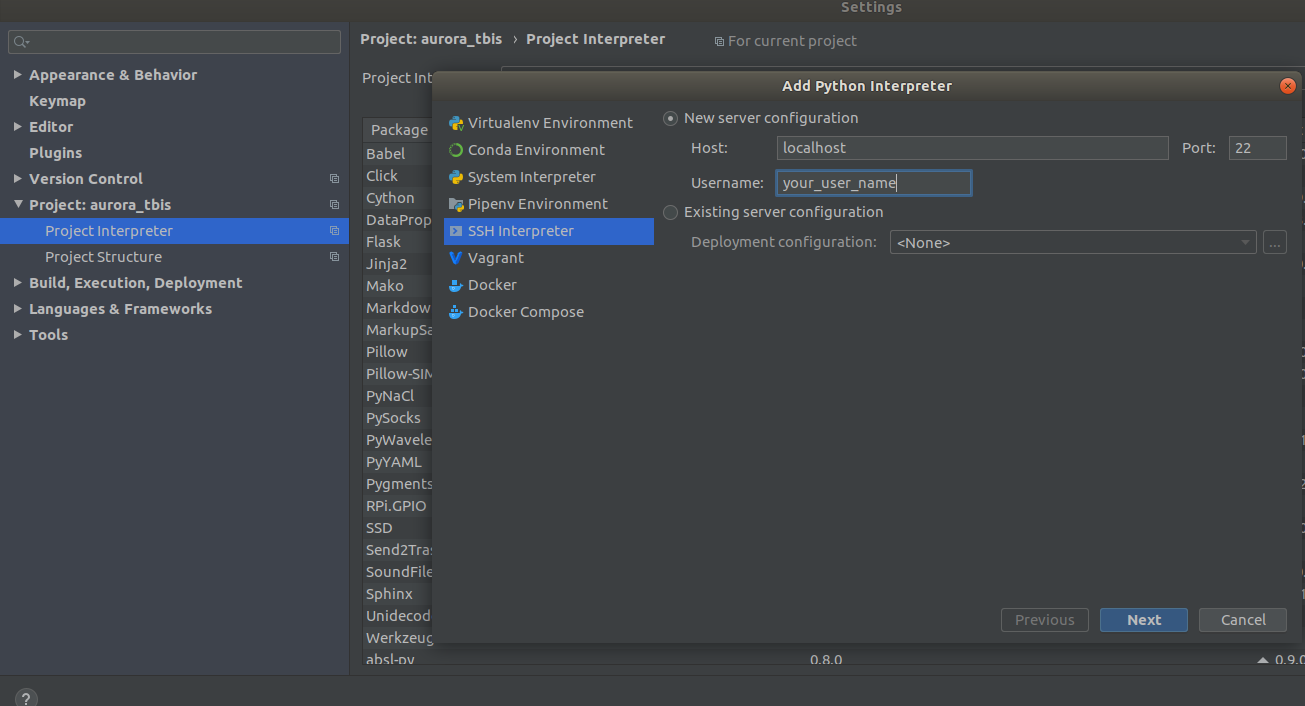 Schritt 2
Schritt 2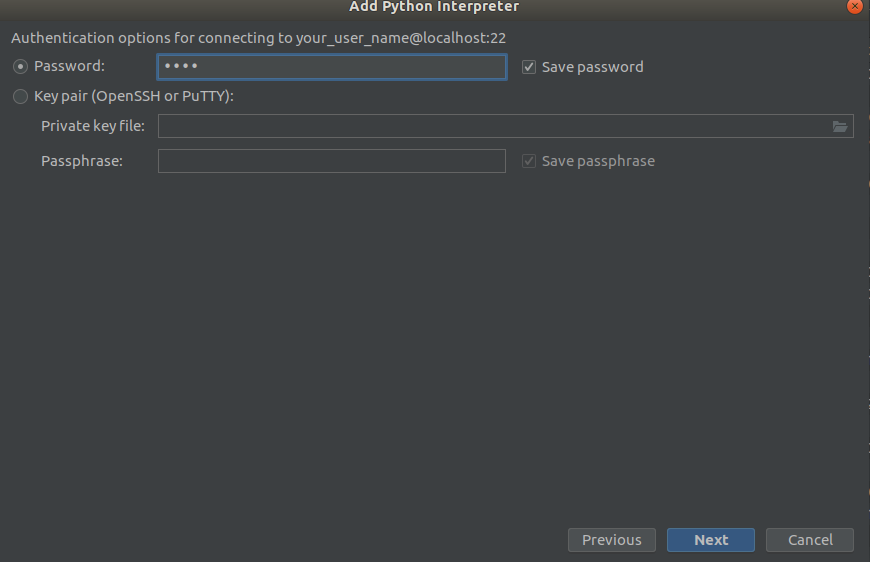 Schritt 3
Schritt 3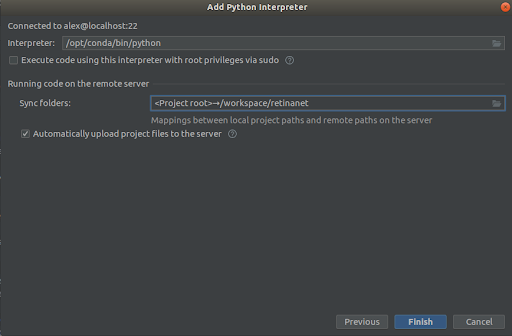
Wir wählen alles wie in den Screenshots,
Interpreter -> /opt/conda/bin/python
- Dies wird in Python3.6 und
Sync folder -> /workspace/retinanet
Wir drücken die Ziellinie, wir erwarten eine Indizierung und das ist alles, die Umgebung ist einsatzbereit!
WICHTIG !!! Extrahieren Sie unmittelbar nach der Indizierung die kompilierten Dateien für Retinanet aus docker. Wählen Sie im Kontextmenü des Projektstamms
Deployment->Download
Eine Datei und zwei Build-Ordner, retinanet.egg-info und _so, werden angezeigt
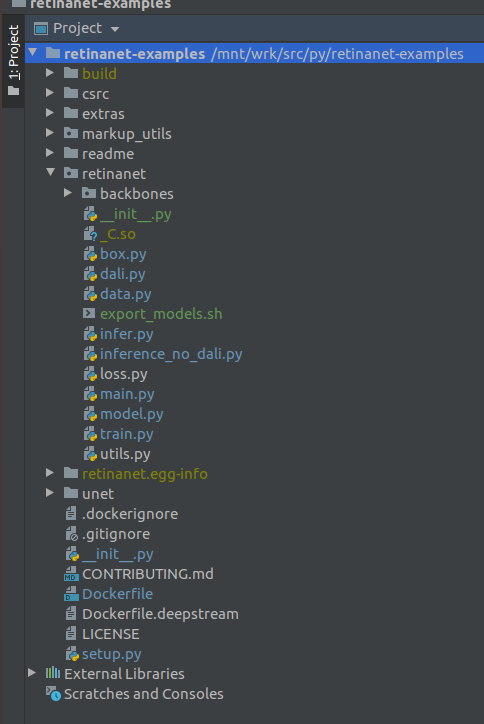
Wenn Ihr Projekt so aussieht, sieht die Umgebung alle erforderlichen Dateien und wir sind bereit, RetinaNet zu lernen.
Phase 4. Daten markieren und Detektor trainierenZum Markieren verwende ich hauptsächlich
supervise.ly - ein schönes und praktisches Tool, bei dem in der letzten Zeit ein paar Pfosten repariert wurden und das Verhalten viel besser wurde.
Angenommen, Sie haben ein Dataset markiert und heruntergeladen, aber es funktioniert nicht sofort, um es in unser RetinaNet zu übertragen, da es in einem eigenen Format vorliegt und wir es daher in COCO konvertieren müssen. Das Konvertierungstool befindet sich in:
markup_utils/supervisly_to_coco.py
Bitte beachten Sie, dass die Kategorie im Skript ein Beispiel ist und Sie Ihre eigene einfügen müssen (Sie müssen die Hintergrundkategorie nicht hinzufügen).
categories = [{'id': 1, 'name': '1'}, {'id': 2, 'name': '2'}, {'id': 3, 'name': '3'}, {'id': 4, 'name': '4'}]
Aus irgendeinem Grund haben die Autoren des Original-Repositorys entschieden, dass Sie nichts anderes als COCO / VOC für die Erkennung trainieren. Daher musste ich die Quelldatei leicht modifizieren
retinanet/dataset.py
Fügen Sie tutda Ihre bevorzugten Erweiterungen
albumentations.readthedocs.io/en/latest hinzu und schneiden Sie die fest verdrahteten Kategorien von COCO aus. Es ist auch möglich, große Erkennungsbereiche zu streuen, wenn Sie nach kleinen Objekten in großen Bildern suchen, einen kleinen Datensatz haben =) und nichts funktioniert, aber mehr dazu zu einem anderen Zeitpunkt.
Im Allgemeinen ist die Zugschleife auch schwach, anfangs wurden keine Checkpoints gespeichert, es wurde ein schrecklicher Scheduler verwendet usw. Jetzt müssen Sie nur noch das Backbone auswählen und ausführen
/opt/conda/bin/python retinanet/main.py
mit Parametern:
train retinanet_rn34fpn.pth --backbone ResNet34FPN --classes 12 --val-iters 10 --images /workspace/mounted_vol/dataset/train/images --annotations /workspace/mounted_vol/dataset/train_12_class.json --val-images /workspace/mounted_vol/dataset/test/images_small --val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json --jitter 256 512 --max-size 512 --batch 32
In der Konsole sehen Sie:
Initializing model... model: RetinaNet backbone: ResNet18FPN classes: 2, anchors: 9 Selected optimization level O0: Pure FP32 training. Defaults for this optimization level are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 1.0 Processing user overrides (additional kwargs that are not None)... After processing overrides, optimization options are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 128.0 Preparing dataset... loader: pytorch resize: [1024, 1280], max: 1280 device: 4 gpus batch: 4, precision: mixed Training model for 20000 iterations... [ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001 [ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001 [ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001 [ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001 [ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001 [ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001 [ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001 [ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001 [ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001 [ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001 [ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001 [ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001 [ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001 [ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Saving model: 148
Um den gesamten Parametersatz zu studieren, schauen Sie
retinanet/main.py
Im Allgemeinen sind sie Standard für die Erkennung und sie haben eine Beschreibung. Führen Sie das Training durch und warten Sie auf die Ergebnisse. Ein Beispiel für eine Folgerung finden Sie in:
retinanet/infer_example.py
oder führen Sie den Befehl aus:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth --images /workspace/mounted_vol/dataset/test/images --annotations /workspace/mounted_vol/dataset/val.json --output result.json --resize 256 --max-size 512 --batch 32
Focal Loss und mehrere Backbones sind bereits in das Repository integriert
retinanet/backbones/*.py
Die Autoren geben auf dem Typenschild einige Merkmale an:
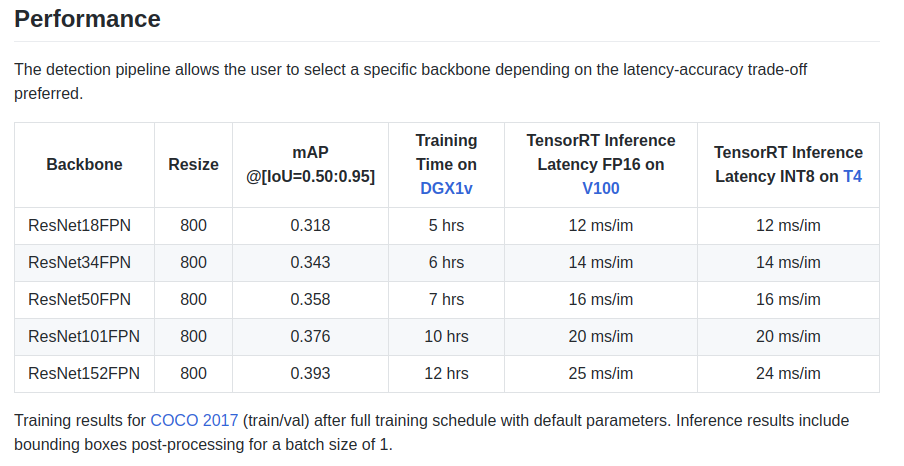
Es gibt auch ein Backbone ResNeXt50_32x4dFPN und ResNeXt101_32x8dFPN, die von Fackelvision stammen.
Ich hoffe, wir haben die Erkennung ein wenig herausgefunden, aber Sie sollten auf jeden Fall die offizielle Dokumentation lesen,
um die Export- und Protokollierungsmodi zu
verstehen .
Phase 5. Export und Inferenz von Unet-Modellen mit Resnet-EncoderWie Sie wahrscheinlich bemerkt haben, wurden die Bibliotheken für die Segmentierung im Dockerfile installiert, insbesondere die wunderbare Bibliothek
github.com/qubvel/segmentation_models.pytorch . Im Yunet-Paket finden Sie Beispiele für die Inferenz und den Export von Pytorch-Checkpoints in der TensorRT-Engine.
Das Hauptproblem beim Export von Unet-ähnlichen Modellen von ONNX nach TensoRT ist die Notwendigkeit, eine feste Upsample-Größe festzulegen oder ConvTranspose2D zu verwenden:
import torch.onnx.symbolic_opset9 as onnx_symbolic def upsample_nearest2d(g, input, output_size):
Mit dieser Konvertierung können Sie dies beim Export nach ONNX automatisch tun, aber bereits in Version 7 von TensorRT wurde dieses Problem behoben, und wir mussten sehr wenig warten.
FazitAls ich anfing, Docker zu verwenden, hatte ich Zweifel an seiner Leistung für meine Aufgaben. In einem meiner Geräte gibt es mittlerweile ziemlich viel Netzwerkverkehr, der von mehreren Kameras verursacht wird.
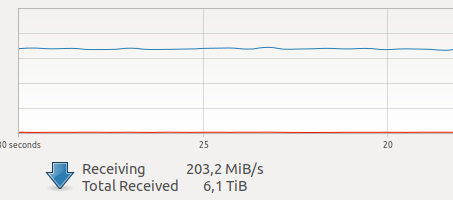
Verschiedene Tests im Internet ergaben einen relativ hohen Aufwand für die Netzwerkinteraktion und -aufzeichnung auf VOLUME sowie eine unbekannte und fürchterliche GIL. Da das Aufnehmen eines Frames, der Treiberbetrieb und das Übertragen eines Frames über ein Netzwerk atomare Vorgänge im
harten Echtzeitmodus sind , kommt es zu Verzögerungen Online sind sehr wichtig für mich.
Aber nichts ist passiert =)
PS Es bleibt noch Ihre Lieblingsschleife für die Segmentierung und Produktion hinzuzufügen!
Vielen DankDank der
ods.ai- Community ist es unmöglich, sich ohne sie zu entwickeln! Vielen Dank an
n01z3 , DL, der wollte, dass ich DL aufnehme, für seinen unschätzbaren Rat und seine außergewöhnliche Professionalität!
Verwenden Sie optimierte Modelle in der Produktion!
Aurorai, llc