Clickhouse ist ein von Yandex entwickeltes Open-Source-Open-Source-Datenbankmanagementsystem (OLAP) für analytische Abfragen. Es wird von Yandex, CloudFlare, VK.com, Badoo und anderen Diensten auf der ganzen Welt verwendet, um wirklich große Datenmengen zu speichern (fügen Sie Tausende von Zeilen pro Sekunde oder Petabyte von Daten ein, die auf der Festplatte gespeichert sind).
In einem regulären "String" -DBMS, beispielsweise MySQL, Postgres, MS SQL Server, werden die Daten in dieser Reihenfolge gespeichert:
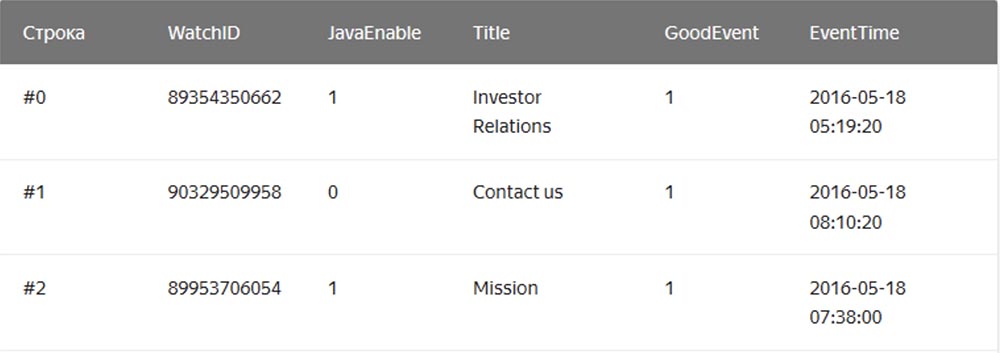
In diesem Fall werden Werte, die sich auf eine Zeile beziehen, physisch nebeneinander gespeichert. In einem Spalten-DBMS werden Werte aus verschiedenen Spalten separat gespeichert und die Daten einer Spalte werden zusammen gespeichert:
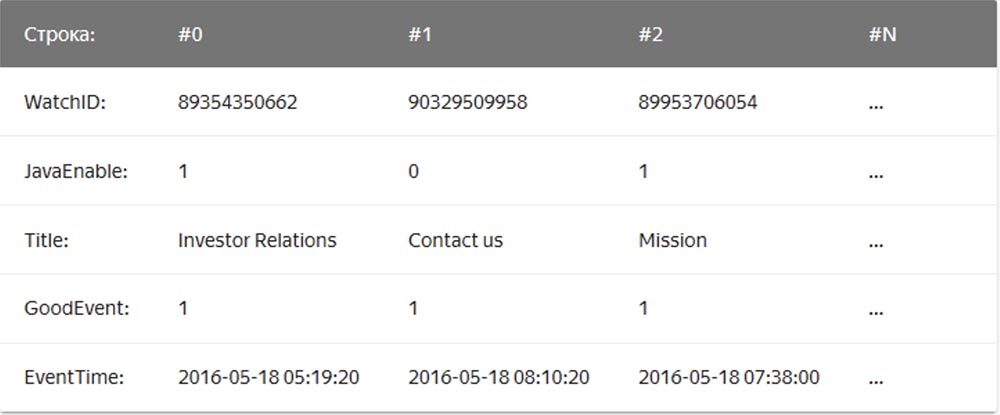
Beispiele für säulenförmige DBMS sind Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb +.
Das Mail-
Weiterleitungsunternehmen Qwintry begann 2018 mit der Verwendung von Clickhouse für die Berichterstellung und war von seiner Einfachheit, Skalierbarkeit, SQL-Unterstützung und Geschwindigkeit sehr beeindruckt. Die Geschwindigkeit dieses DBMS war von Zauberei begrenzt.
Einfachheit
Clickhouse wird auf Ubuntu mit einem einzigen Befehl installiert. Wenn Sie mit SQL vertraut sind, können Sie Clickhouse sofort für Ihre Anforderungen verwenden. Dies bedeutet jedoch nicht, dass Sie "show create table" in MySQL ausführen und SQL in Clickhouse kopieren und einfügen können.
Im Vergleich zu MySQL gibt es in diesem DBMS wichtige Unterschiede bei den Datentypen bei den Definitionen von Tabellenschemata. Für eine komfortable Arbeit benötigen Sie also noch einige Zeit, um die Definitionen des Tabellenschemas zu ändern und die Tabellenmodule zu untersuchen.
Clickhouse funktioniert ohne zusätzliche Software hervorragend. Wenn Sie jedoch die Replikation verwenden möchten, müssen Sie ZooKeeper installieren. Die Analyse der Abfrageleistung zeigt hervorragende Ergebnisse - Systemtabellen enthalten alle Informationen, und alle Daten können mit dem alten und langweiligen SQL abgerufen werden.
Leistung
- Benchmark- Vergleich von Clickhouse mit Vertica und MySQL auf einem Konfigurationsserver: zwei Intel® Xeon®-CPU-Sockel E5-2650 v2 bei 2,60 GHz; 128 GiB RAM; md RAID-5 auf 8 SATA-Festplatten mit 6 TB, ext4.
- Benchmark- Vergleich von Clickhouse mit dem Cloud-Datenspeicher von Amazon RedShift.
- Auszüge aus dem Cloudflare Clickhouse Performance Blog :

Die ClickHouse-Datenbank ist sehr einfach aufgebaut - alle Knoten im Cluster haben dieselbe Funktionalität und verwenden nur ZooKeeper für die Koordination. Wir haben einen kleinen Cluster aus mehreren Knoten erstellt und Tests durchgeführt. Dabei haben wir festgestellt, dass das System eine beeindruckende Leistung aufweist, was den in den Benchmarks für analytische DBMS angegebenen Vorteilen entspricht. Wir haben uns das Konzept von ClickHouse genauer angesehen. Das erste Hindernis für die Recherche war der Mangel an Tools und die geringe Größe der ClickHouse-Community. Daher haben wir uns mit dem Design dieses Datenbankverwaltungssystems befasst, um zu verstehen, wie es funktioniert.
ClickHouse unterstützt das direkte Empfangen von Daten von Kafka nicht (im Moment weiß es bereits wie), da es sich nur um eine Datenbank handelt. Deshalb haben wir unseren eigenen Adapterservice in Go geschrieben. Er las Cap'n Proto-codierte Nachrichten von Kafka, konvertierte sie in TSV und fügte sie stapelweise über die HTTP-Schnittstelle in ClickHouse ein. Später haben wir diesen Service umgeschrieben, um die Go-Bibliothek in Verbindung mit unserer eigenen ClickHouse-Oberfläche zu verwenden und die Leistung zu verbessern. Bei der Bewertung der Leistung beim Empfang von Paketen haben wir eine wichtige Erkenntnis gewonnen: Es stellte sich heraus, dass diese Leistung bei ClickHouse stark von der Größe des Pakets abhängt, dh von der Anzahl der gleichzeitig eingefügten Zeilen. Um zu verstehen, warum dies geschieht, haben wir untersucht, wie ClickHouse Daten speichert.
Das Hauptmodul bzw. die Familie der von ClickHouse zum Speichern von Daten verwendeten Tabellenmodule ist MergeTree. Diese Engine ähnelt konzeptionell dem von Google BigTable oder Apache Cassandra verwendeten LSM-Algorithmus, vermeidet jedoch das Erstellen einer Zwischenspeichertabelle und schreibt Daten direkt auf die Festplatte. Dies ergibt einen ausgezeichneten Schreibdurchsatz, da jedes eingefügte Paket nur nach dem Primärschlüssel sortiert wird, komprimiert und auf die Festplatte geschrieben wird, um ein Segment zu bilden.
Das Fehlen einer Speichertabelle oder eines Konzepts der „Aktualität“ von Daten bedeutet auch, dass sie nur hinzugefügt werden können, das System unterstützt das Ändern oder Löschen dieser Daten nicht. Heutzutage besteht die einzige Möglichkeit, Daten zu löschen, darin, sie nach Kalendermonaten zu löschen, da Segmente niemals die Monatsgrenze überschreiten. Das ClickHouse-Team arbeitet aktiv daran, diese Funktion anpassbar zu machen. Auf der anderen Seite werden Segmente nahtlos aufgezeichnet und zusammengeführt, sodass die Empfangsbandbreite linear mit der Anzahl der parallelen Einfügungen skaliert, bis E / A oder Kerne gesättigt sind.
Dies bedeutet jedoch auch, dass das System nicht für kleine Pakete geeignet ist, weshalb Kafka-Services und -Inserts zum Puffern verwendet werden. Darüber hinaus führt ClickHouse im Hintergrund das Zusammenführen von Segmenten fortwährend durch, sodass viele kleine Informationen mehrmals kombiniert und aufgezeichnet werden, wodurch die Aufzeichnungsintensität erhöht wird. In diesem Fall verursachen zu viele nicht zusammenhängende Teile eine aggressive Drosselung der Einsätze, solange der Zusammenschluss fortgesetzt wird. Wir haben festgestellt, dass der beste Kompromiss zwischen Echtzeitdatenempfang und Empfangsleistung darin besteht, eine begrenzte Anzahl von Einfügungen pro Sekunde in die Tabelle zu erhalten.
Der Schlüssel zur Leistung beim Lesen von Tabellen ist das Indizieren und Positionieren von Daten auf der Festplatte. Unabhängig davon, wie schnell die Verarbeitung ist, wenn die Engine Terabytes an Daten von der Festplatte scannen und nur einen Teil davon verwenden muss, dauert es einige Zeit. ClickHouse ist ein Spaltenspeicher, daher enthält jedes Segment eine Datei für jede Spalte (Spalte) mit sortierten Werten für jede Zeile. Somit können ganze Spalten, die nicht in der Abfrage enthalten sind, zuerst übersprungen werden, und dann können mehrere Zellen parallel zur vektorisierten Ausführung verarbeitet werden. Um einen vollständigen Scan zu vermeiden, verfügt jedes Segment über eine kleine Indexdatei.
Da alle Spalten nach "Primärschlüssel" sortiert sind, enthält die Indexdatei nur die Bezeichnungen (erfassten Zeilen) jeder N-ten Zeile, um sie auch für sehr große Tabellen im Speicher speichern zu können. Sie können beispielsweise die Standardeinstellungen "Alle 8192. Zeile markieren" und anschließend die "magere" Indizierung der Tabelle mit 1 Billion festlegen. Zeilen, die leicht in den Speicher passen, belegen nur 122.070 Zeichen.
Systementwicklung
Die Entwicklung und Verbesserung von Clickhouse lässt sich auf das
Github-Repo zurückführen und stellt sicher, dass der Prozess des "Erwachsenwerdens" in beeindruckendem Tempo abläuft.
Popularität
Clickhouse scheint exponentiell zu wachsen, insbesondere in der russischsprachigen Gemeinschaft. Die letztjährige Konferenz High Load 2018 (Moskau, 8. bis 9. November 2018) zeigte, dass Monster wie vk.com und Badoo Clickhouse verwenden, mit dem sie Daten (zum Beispiel Protokolle) von Zehntausenden von Servern gleichzeitig einfügen. In einem 40-minütigen Video
spricht Yuri Nasretdinov vom VKontakte-Team darüber, wie das gemacht wird . In Kürze werden wir das Transkript auf Habr veröffentlichen, um die Arbeit mit dem Material zu erleichtern.
Anwendungsgebiete
Nachdem ich einige Zeit recherchiert habe, gibt es Bereiche, in denen ClickHouse nützlich sein oder andere, traditionellere und populärere Lösungen, wie MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, vollständig ersetzen kann. TimescaleDB, Hadoop, MapReduce, Pinot und Druid. Im Folgenden werden Details zur Verwendung von ClickHouse zum Upgrade oder vollständigen Ersetzen der oben genannten DBMS aufgeführt.
Erweiterung von MySQL und PostgreSQL
Zuletzt haben wir MySQL für die
Newsletter- Plattform von
Mautic teilweise durch ClickHouse ersetzt. Das Problem war, dass MySQL aufgrund seines schlecht durchdachten Designs jede gesendete E-Mail und jeden Link in dieser E-Mail mit einem base64-Hash protokollierte und so eine riesige MySQL-Tabelle (email_stats) erstellte. Nachdem nur 10 Millionen Briefe an Service-Abonnenten gesendet worden waren, belegte diese Tabelle 150 GB Dateibereich, und MySQL wurde bei einfachen Abfragen "langweilig". Um das Dateibereichsproblem zu beheben, haben wir erfolgreich die InnoDB-Tabellenkomprimierung verwendet, die es um das Vierfache reduzierte. Es ist jedoch immer noch nicht sinnvoll, mehr als 20 bis 30 Millionen E-Mails in MySQL zu speichern, um die Story zu lesen, da jede einfache Anforderung, die aus irgendeinem Grund einen vollständigen Scan durchführen muss, zu einem Austausch und einer hohen Belastung der E / A führt über die wir regelmäßig Warnungen von Zabbix erhielten.

Clickhouse verwendet zwei Komprimierungsalgorithmen, die die Datenmenge um das
3-4-fache reduzieren. In diesem speziellen Fall waren die Daten jedoch besonders „komprimierbar“.

ELK Ersatz
Nach unseren eigenen Erfahrungen erfordert der ELK-Stack (ElasticSearch, Logstash und Kibana, in diesem speziellen Fall ElasticSearch) viel mehr Ressourcen, als zum Speichern von Protokollen erforderlich sind. ElasticSearch ist eine großartige Suchmaschine, wenn Sie eine gute Volltext-Protokollsuche benötigen (und ich glaube nicht, dass Sie sie wirklich benötigen), aber ich frage mich, warum sie de facto zur Standard-Protokolliermaschine geworden ist. Die Empfangsleistung in Kombination mit Logstash bereitete uns auch bei relativ geringen Belastungen Probleme und erforderte die Hinzufügung von mehr RAM und Speicherplatz. Als Datenbank ist Clickhouse aus folgenden Gründen besser als ElasticSearch:
- SQL-Dialekt-Unterstützung;
- Das beste Komprimierungsverhältnis der gespeicherten Daten;
- Unterstützung für reguläre reguläre Ausdruckssuchen anstelle von Volltextsuchen;
- Verbesserte Abfrageplanung und höhere Gesamtleistung.
Derzeit ist das größte Problem, das beim Vergleich von ClickHouse mit ELK auftritt, das Fehlen von Lösungen für Versandprotokolle sowie das Fehlen von Dokumentation und Schulungshilfen zu diesem Thema. Gleichzeitig kann jeder Benutzer ELK mithilfe des Digital Ocean Guide konfigurieren, was für die schnelle Implementierung solcher Technologien sehr wichtig ist. Es gibt hier eine Datenbank-Engine, aber noch keinen Filebeat für ClickHouse. Ja, es gibt ein
fließendes und ein System zum Arbeiten mit Protokolldateien. Es gibt ein
Klick- Tool zum Eingeben von Daten aus Protokolldateien in ClickHouse, aber all dies nimmt mehr Zeit in Anspruch. Allerdings führt ClickHouse aufgrund seiner Einfachheit immer noch dazu, dass selbst Anfänger es einfach installieren und es in nur 10 Minuten vollständig nutzen können.
Ich bevorzuge minimalistische Lösungen und versuche, FluentBit, ein Tool zum Versenden von Protokollen mit sehr wenig Speicher, zusammen mit ClickHouse, zu verwenden, während ich versuche, Kafka zu vermeiden. Kleinere Inkompatibilitäten, z. B.
Probleme mit dem Datumsformat , müssen jedoch behoben werden, bevor auf eine Proxy-Ebene verzichtet werden kann, die Daten von FluentBit nach ClickHouse konvertiert.
Alternativ zu Kibana können Sie
Grafana als ClickHouse-
Backend verwenden . Soweit ich weiß, kann dies zu Leistungsproblemen beim Rendern einer großen Menge von Datenpunkten führen, insbesondere bei älteren Versionen von Grafana. Bei Qwintry haben wir dies noch nicht ausprobiert, aber Beschwerden darüber erscheinen von Zeit zu Zeit auf dem ClickHouse-Support-Kanal in Telegram.
Ersetzen von Google Big Query und Amazon RedShift (Lösung für große Unternehmen)
Der ideale Anwendungsfall für BigQuery ist das Herunterladen von 1 TB JSON-Daten und das Ausführen von analytischen Abfragen. Big Query ist ein großartiges Produkt, dessen Skalierbarkeit schwer zu überschätzen ist. Dies ist eine wesentlich komplexere Software als ClickHouse, die auf einem internen Cluster ausgeführt wird. Aus Sicht des Clients hat sie jedoch viele Gemeinsamkeiten mit ClickHouse. BigQuery kann schnell im Preis steigen, sobald Sie für jedes SELECT bezahlen. Dies ist also eine echte SaaS-Lösung mit all ihren Vor- und Nachteilen.
ClickHouse ist die beste Wahl, wenn Sie viele rechenintensive Abfragen durchführen. Je mehr SELECT-Abfragen Sie täglich ausführen, desto sinnvoller ist es, Big Query durch ClickHouse zu ersetzen, da Sie durch eine solche Ersetzung Tausende von Dollar sparen, wenn es um viele Terabyte verarbeiteter Daten geht. Dies gilt nicht für gespeicherte Daten, deren Verarbeitung in Big Query recht kostengünstig ist.
In dem Artikel von Altinity-Mitbegründer Alexander Zaitsev,
„Switching to ClickHouse“ , werden die Vorteile einer solchen DBMS-Migration
erläutert .
TimescaleDB ersetzen
TimescaleDB ist eine PostgreSQL-Erweiterung, die die Arbeit mit Zeitreihen-Zeitreihen in einer regulären Datenbank optimiert (
https://docs.timescale.com/v1.0/introduction ,
https://habr.com/de/company/zabbix/blog/458530) / ).
Obwohl ClickHouse kein ernstzunehmender Konkurrent in der Zeitreihennische ist, sondern die Spaltenstruktur und Vektorausführung von Abfragen, ist es in den meisten Fällen bei der Verarbeitung von analytischen Abfragen viel schneller als TimescaleDB. Gleichzeitig ist die Leistung beim Empfang von ClickHouse-Paketdaten etwa dreimal so hoch. Darüber hinaus wird 20 Mal weniger Speicherplatz benötigt, was für die Verarbeitung großer Mengen historischer Daten wirklich wichtig ist:
https://www.altinity.com/blog/ClickHouse-for -Zeit-Serie .
Im Gegensatz zu ClickHouse können Sie in TimescaleDB nur mit ZFS oder ähnlichen Dateisystemen Speicherplatz sparen.
Bevorstehende ClickHouse-Aktualisierungen führen wahrscheinlich zu einer Delta-Komprimierung, die die Verarbeitung und Speicherung von Zeitreihendaten noch einfacher macht. In den folgenden Fällen ist TimescaleDB möglicherweise die bessere Wahl als ein nacktes ClickHouse:
- kleine Installationen mit sehr wenig RAM (<3 GB);
- eine große Anzahl kleiner INSERTs, die nicht in große Fragmente gepuffert werden sollen;
- bessere Konsistenz-, Homogenitäts- und ACID-Anforderungen;
- PostGIS-Unterstützung;
- Zusammenführen mit vorhandenen PostgreSQL-Tabellen, da Timescale DB im Wesentlichen PostgreSQL ist.
Wettbewerb mit Hadoop und MapReduce Systems
Hadoop und andere MapReduce-Produkte können viele komplexe Berechnungen durchführen, sind jedoch in der Regel mit großen Verzögerungen verbunden. ClickHouse behebt dieses Problem, indem es Terabytes an Daten verarbeitet und fast sofort Ergebnisse liefert. Somit ist ClickHouse viel effizienter für die Durchführung schneller, interaktiver Analysen, was für Datenverarbeitungsspezialisten interessant sein dürfte.
Konkurrenz mit Pinot und Druide
Die engsten Konkurrenten von ClickHouse sind Pinot und Druid, ein linear skalierbares Open-Source-Produkt. Ein hervorragender Vergleich dieser Systeme wurde in einem Artikel von
Roman Leventov vom 1. Februar 2018 veröffentlicht.
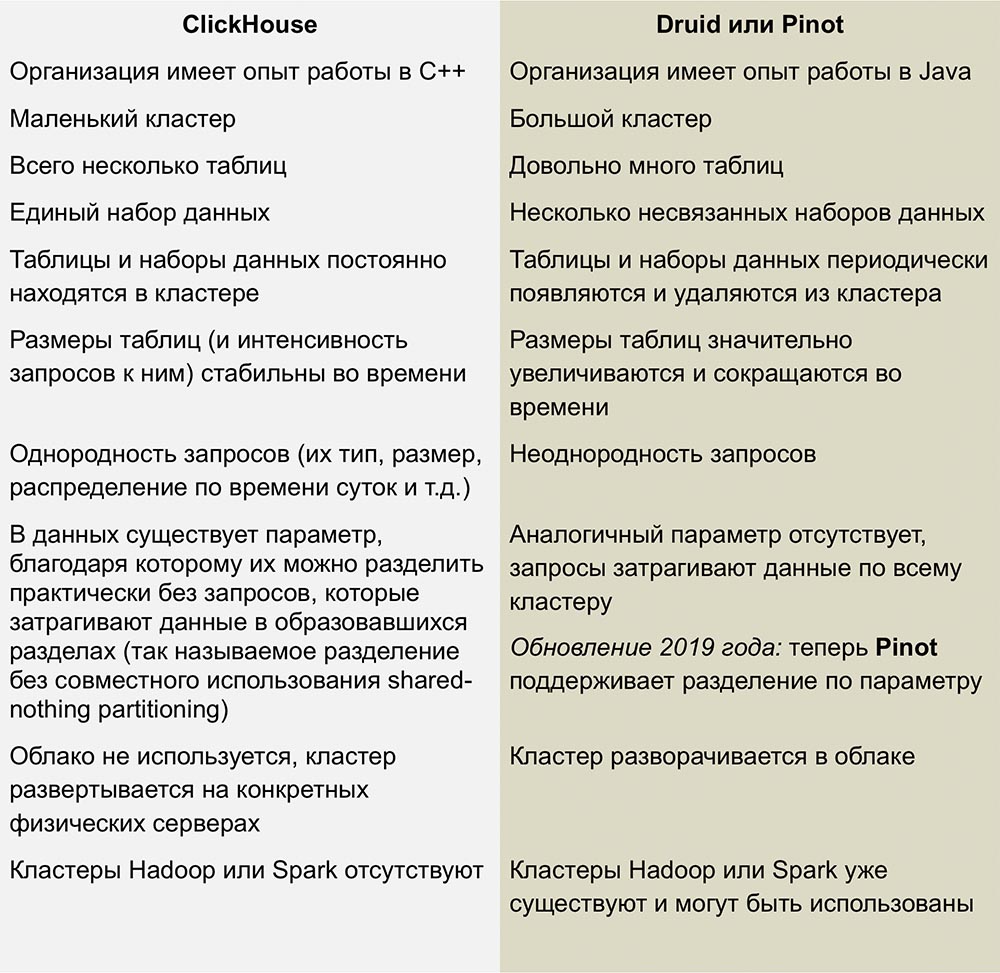
Dieser Artikel muss aktualisiert werden. ClickHouse unterstützt keine UPDATE- und DELETE-Vorgänge, was für die neuesten Versionen nicht vollständig zutrifft.
Wir haben nicht genug Erfahrung mit diesen DBMS, aber ich mag die Komplexität der Infrastruktur, die für die Ausführung von Druid und Pinot verwendet wird, nicht - dies ist eine ganze Reihe von "beweglichen Teilen", die von allen Seiten von Java umgeben sind.
Druid und Pinot sind Apache-Inkubatorprojekte, über deren Entwicklungsfortschritt Apache auf den Seiten seiner GitHub-Projekte ausführlich berichtet. Pinot erschien im Oktober 2018 im Inkubator und Druide wurde 8 Monate zuvor geboren - im Februar.
Der Mangel an Informationen über die Funktionsweise von AFS wirft einige und vielleicht alberne Fragen auf. Ich frage mich, ob die Autoren von Pinot bemerkt haben, dass die Apache Foundation Druiden gegenüber eher geneigt ist, und hat diese Haltung gegenüber dem Konkurrenten Neid ausgelöst? Wird sich die Entwicklung von Druiden verlangsamen und der Pinot beschleunigen, wenn Sponsoren, die die ersteren unterstützen, plötzlich Interesse an den letzteren entwickeln?
Nachteile von ClickHouse
Unreife: Offensichtlich ist dies noch keine langweilige Technologie, aber in anderen säulenartigen DBMS wird auf jeden Fall nichts Ähnliches beobachtet.
Kleine Beilagen funktionieren bei hoher Geschwindigkeit nicht gut: Beilagen müssen in große Teile geteilt werden, da die Leistung kleiner Beilagen proportional zur Anzahl der Spalten in jeder Zeile abnimmt. Auf diese Weise speichert ClickHouse Daten auf der Festplatte - jede Spalte bedeutet 1 Datei oder mehr. Um eine Zeile mit 100 Spalten einzufügen, müssen Sie mindestens 100 Dateien öffnen und schreiben. Aus diesem Grund ist ein Intermediär erforderlich, um Einfügungen zu puffern (es sei denn, der Client stellt selbst die Pufferung bereit). In der Regel handelt es sich hierbei um Kafka oder eine Art Warteschlangenverwaltungssystem. Sie können auch die Puffertabellen-Engine verwenden, um später große Datenmengen in MergeTree-Tabellen zu kopieren.
Tabellenverknüpfungen sind durch den Arbeitsspeicher des Servers begrenzt, aber zumindest sind sie vorhanden! Zum Beispiel haben Druid und Pinot überhaupt keine derartigen Verbindungen, da sie in verteilten Systemen, die das Verschieben großer Datenmengen zwischen Knoten nicht unterstützen, nur schwer direkt zu implementieren sind.
Schlussfolgerungen
In den kommenden Jahren planen wir, ClickHouse in Qwintry umfassend zu nutzen, da dieses DBMS ein hervorragendes Gleichgewicht zwischen Leistung, geringem Overhead, Skalierbarkeit und Einfachheit bietet. Ich bin mir ziemlich sicher, dass es sich schnell verbreiten wird, sobald die ClickHouse-Community mehr Möglichkeiten für die Verwendung in kleinen und mittleren Installationen findet.
Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Mögen Sie unsere Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden
Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen, ein
einzigartiges Analogon zu Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 Dollar oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2-mal billiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2 x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV ab 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
das Erstellen von Infrastruktur-Bldg. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?