
Einleitung
Ich programmiere sehr gerne, ich bin ein Amateur und das erste und letzte Mal, dass ich 1996 mit dem Programmieren Geld verdient habe. Aber manchmal schreibe ich etwas, um alltägliche Aufgaben zu automatisieren. Vor etwa einem Jahr wurde Golang entdeckt. Als Werkzeug zum Erstellen von Hilfsprogrammen erwies sich Golang als sehr praktisch. Also
Es bestand die Notwendigkeit, eine große Anzahl (mehr als tausend, und ich sehe das Lächeln eines Profis) von Archivdateien mit speziellen geophysikalischen Informationen zu verarbeiten. Das Dateiformat ist Text, einfach. Wenn Sie plötzlich interessiert sind, dann ist dies ein LAS-Format .
LAS-Datei enthält Header und Daten.
Die Daten sind praktisch CSV, nur Tabulatorbegrenzer oder Leerzeichen.
Und die Überschrift enthält eine Beschreibung der Daten und hier enthält sie normalerweise russischen Text. Dies kann der Name des Feldes, der Name der in einer Datei aufgezeichneten Studien usw. sein.
Diese Dateien wurden zu unterschiedlichen Zeiten und in unterschiedlichen Programmen erstellt. Dies führt dazu, dass in einer Datei ein Teil in CP1251 und ein Teil in CP866 codiert ist. Ich muss diese Dateien verarbeiten, was bedeutet, zu verstehen. Daher musste die Dateicodierung automatisch ermittelt werden.
Als Ergebnis erfand er ein Fahrrad auf Golang und dementsprechend entstand eine kleine Bibliothek mit der Fähigkeit, eine Codepage zu erkennen.
Über Kodierungen. Vor nicht allzu langer Zeit gab es auf habr einen guten Artikel über Kodierungen. Wie Textkodierungen funktionieren. Woher kommen die "Krokodile"? Die Prinzipien der Kodierung. Verallgemeinerung und detaillierte Analyse Wenn Sie verstehen wollen, was ein "Knochen" oder "Knochen" ist, dann ist es wert, gelesen zu werden.
Am Anfang habe ich meine Entscheidung getroffen. Dann habe ich versucht, eine fertige Arbeitslösung für Golang zu finden, aber es ist mir nicht gelungen. Es gab zwei Lösungen, aber beide funktionieren nicht.
- Die erste "out of the box" - golang.org/x/net/html/charset Funktion DetermineEncoding ()
- Zweite Bibliothek - Saintfish / Chardet auf Github
Beide sind sicherlich in einigen Codierungen falsch. Der Standard kann im Allgemeinen fast nichts aus Textdateien ermitteln. Es ist verständlich, dass dies für HTML-Seiten durchgeführt wurde.
Bei der Suche bin ich oft auf fertige Dienstprogramme aus der Linux-Welt gestoßen - enca . Die Version wurde für WIN32, Version 1.12, kompiliert. Ich werde es mir auch überlegen, da gibt es lustige Sachen. Ich entschuldige mich sofort für meine völlige Unkenntnis von Linux, was bedeutet, dass es wahrscheinlich mehr Lösungen gibt, die Sie auch versuchen können, auf Golang-Code zu schrauben, ich habe nicht mehr gesucht.
Vergleich der gefundenen Lösungen für die automatische Codierungserkennung
Erstellen eines Katalogs mit Softlandia \ cpd-Testdaten mit Dateien in verschiedenen Codierungen. Der Inhalt der Dateien ist sehr kurz und gleich. Eine Zeile "Russisch in der Codierung CodePageName". Ich fügte Dateien mit einer Mischung aus Codierungen und einigen komplexen Fällen hinzu und versuchte festzustellen.
Ich finde es lustig.
Beobachtung 1
enca hat die Kodierung der UTF-16LE-Datei ohne die Stückliste nicht ermittelt - das ist merkwürdig, okay. Ich habe versucht, mehr Text hinzuzufügen, habe aber das Ergebnis nicht erhalten.
Beobachtung 2. Probleme mit den Codierungen CP1251 und KOI8-R
Zeilen 15 und 16. Der Befehl enca hat Probleme.
Hier werde ich eine Erklärung abgeben, die Tatsache ist, dass die Kodierungen CP1251 (auch bekannt als Windows 1251) und KOI8-R sehr nahe beieinander liegen, wenn wir nur alphabetische Zeichen berücksichtigen.
Tabelle CP 1251
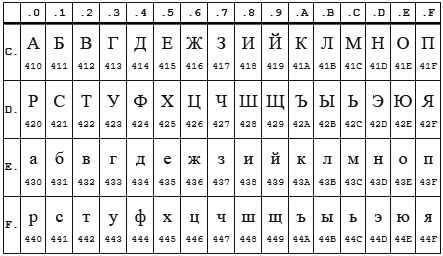
KOI8-r Tisch

In beiden Codierungen befindet sich das Alphabet zwischen 0xC0 und 0xFF , wobei eine Codierung Großbuchstaben und die andere Kleinbuchstaben enthält. Anscheinend arbeitet enca in Kleinbuchstaben. Wenn Sie also die in CP1251 codierte Zeichenfolge "STP" an das Programm " enca " senden, wird entschieden, dass es sich um die in KOI8-r "vehement" codierte Zeichenfolge handelt, die gemeldet wird. Rückwärts funktioniert auch.
Beobachtung 3
Der HTML / Zeichensatz- Standardbibliothek kann nur mit einer UTF-8- Definition vertraut werden, aber seien Sie vorsichtig! Es sollte genau charset.DetermineEncoding () verwendet werden , da die Methode utf8.Valid (b [] byte) für utf-16be-codierte Dateien true zurückgibt.
Eigenes Fahrrad

Die automatische Erkennung der Codierung ist nur durch ungenaue heuristische Methoden möglich. Wenn wir nicht wissen, in welcher Sprache und in welcher Codierung die Textdatei geschrieben ist, ist es möglich, die Codierung mit hoher Genauigkeit zu bestimmen, aber es wird schwierig ... und Sie werden viel Text benötigen.
Für mich war dieses Ziel nicht gesetzt. Es reicht mir, die Kodierungen unter der Annahme zu bestimmen, dass es Russisch gibt. Und zweitens müssen Sie durch eine kleine Anzahl von Zeichen bestimmen - 10 Zeichen sollten eine ziemlich sichere Definition haben, und vorzugsweise 5-6 Zeichen im Allgemeinen.
Algorithmus
Als ich die Übereinstimmung der Kodierungen KOI8-r und CP1251 anhand der Position des Alphabets entdeckte, war ich einige Tage traurig ... es wurde mir klar, dass ich ein wenig nachdenken musste. Es stellte sich so heraus.
Wichtige Entscheidungen:
- Wir werden mit einem Stück Byte arbeiten, um die Kompatibilität mit charset.DetermineEncoding () zu gewährleisten.
- UTF-8-Codierung und Stücklistenfälle werden separat geprüft
- Die Eingabedaten werden der Reihe nach an jede Codierung übergeben. Jedes berechnet zwei ganzzahlige Kriterien. Wessen Summe aus zwei Kriterien größer ist, hat er gewonnen.
Compliance-Kriterien
Erstes Kriterium
Das erste Kriterium ist die Anzahl der beliebtesten Buchstaben des russischen Alphabets.
Die häufigsten Buchstaben sind: o, e, a und n, t, s, p, b, l, k, m, d, p, y . Diese Buchstaben geben 82% Deckung. Für alle Kodierungen außer KOI8-r und CP1251 habe ich nur die ersten 9 Buchstaben verwendet: o, e, a und n, t, s, p, c. Dies reicht für eine zuverlässige Bestimmung aus.
Aber für KOI8-r und CP1251 musste ich die Datei ändern. Die Codes einiger dieser Buchstaben stimmen überein, z. B. hat der Buchstabe o in CP1251 den Code 0xEE, während dieser Code in KOI8-r den Buchstaben n hat . Die folgenden populären Buchstaben wurden für diese Kodierungen verwendet. Für CP1251 habe ich a, und n, c, p, b, l, k, i verwendet. Für KOI8-r - o, a, u, t, s, b, l, k, m.
Zweites Kriterium
In sehr kurzen Fällen (die Gesamtlänge des russischen Textes beträgt 5 bis 6 Zeichen) liegt das Vorkommen von populären Buchstaben bei 1 bis 3 Stück, und es gibt eine Überlappung der Kodierungen KOI8-r und CP1251. Ich musste ein zweites Kriterium einführen. Konsonant + Vokalzählung .
Es wird erwartet, dass solche Kombinationen am häufigsten in der russischen Sprache vorkommen, und dementsprechend hat diese Codierung bei der Codierung, bei der die Anzahl solcher Paare größer ist, ein größeres Kriterium.
Beide Kriterien werden berechnet, aufsummiert und der erhaltene Betrag ist das endgültige Kriterium.
Das Ergebnis ist in der obigen Tabelle dargestellt.
Funktionen, auf die ich gestoßen bin
Ein kleiner Vorgeschmack auf die Reize und Probleme, die mit Golang verbunden sind. Der Abschnitt ist möglicherweise nur für Anfänger interessant, die in Golang schreiben möchten.
Die Probleme
Ich bin persönlich um einige der Unterwasserkiesel der 50 Shades of Go herumgelaufen: Fallen, Fallstricke und häufige Anfängerfehler .
Übermäßig beunruhigt und versucht, ins Wasser zu blasen, von anderen über die schrecklichen Verbrennungen durch Milch zu hören, ging zu weit mit der Überprüfung der Eingabeparameter des io.Reader-Typs. Ich habe eine Variable wie io.Reader mit Reflektion überprüft.
Aber wie sich in meinem Fall herausstellte, reicht es aus, auf Null zu prüfen. Jetzt ist alles einfacher
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
Ein Aufruf von bufio.NewReader (r) .Peek (ReadBufSize) besteht leise den folgenden Test:
var data *os.File res, err := CodePageDetect(data)
In diesem Fall gibt Peek () einen Fehler zurück.
Einmal auf einen Rake getreten mit der Übertragung von Arrays nach Wert. Etwas dumm beim Versuch, die in der Karte gespeicherten Elemente zu ändern und sie in Reichweite zu durchlaufen ...
Freuden
Es ist schwierig, genau zu sagen, ob das ständige Händeschütteln des Interpreten und des Compilers oder die aktive Nutzung des Bereichs oder alles zusammen, aber es gibt praktisch keine Einbrüche, um den Index außerhalb der Grenzen zu halten.
Natürlich ist es sehr schön, mit dem Müllsammler zu leben. Ich schätze, ich muss immer noch den Rake der Automatisierung der Speicherzuweisung / -freigabe beherrschen, aber bisher lässt das schwachsinnige Lächeln mein Gesicht nicht los.
Starkes Tippen ist auch ein Stück Glück.
Variablen mit einem Funktionstyp sind dementsprechend eine einfache Implementierung verschiedener Verhaltensweisen für Objekte desselben Typs.
Seltsamerweise musste wenig im Debugger sitzen, ein erneutes Lesen des Codes ergibt normalerweise das Ergebnis.
Welpen freuen sich über viele sofort einsatzbereite Tools. Es ist ein wunderbares Gefühl, wenn der Compiler, die Sprache, die Bibliothek und IDE Visual Studio Code harmonisch für Sie zusammenarbeiten.
Danke falconandy für die konstruktiven und nützlichen Tipps.
Danke an ihn
- übersetzte Tests auf testify und sie wurden wirklich lesbarer
- Behobene Tests für Datendateipfade zur Kompatibilität mit Linux
- ging an einem Linter vorbei - dennoch fand er einen wirklichen Fehler (verdammte Kopie / Vergangenheit)
Ich füge weiterhin Tests hinzu, ein Fall, in dem UTF16 nicht definiert wurde, wurde aufgedeckt. Aktualisiert Jetzt werden UTF16 und LE und BE auch ohne russische Buchstaben erkannt