Cube-on-Cube, Metacluster, Zellen, Ressourcenzuweisung
Abb. 1. Kubernetes-Ökosystem in der Alibaba-WolkeSeit 2015 ist der Alibaba Cloud Container Service für Kubernetes (ACK) einer der am schnellsten wachsenden Cloud-Services in der Alibaba Cloud. Es bedient zahlreiche Kunden und unterstützt auch die interne Infrastruktur von Alibaba und anderen Cloud-Diensten des Unternehmens.
Wie bei ähnlichen Containerdiensten von erstklassigen Cloud-Anbietern stehen Zuverlässigkeit und Verfügbarkeit im Vordergrund. Aus diesem Grund wurde eine skalierbare und global zugängliche Plattform für Zehntausende von Kubernetes-Clustern geschaffen.
In diesem Artikel werden wir unsere Erfahrungen mit der Verwaltung einer großen Anzahl von Kubernetes-Clustern in einer Cloud-Infrastruktur sowie mit der Architektur der zugrunde liegenden Plattform teilen.
Eintrag
Kubernetes ist zum De-facto-Standard für verschiedene Cloud-Workloads geworden. Wie in Abb. Ganz oben arbeiten immer mehr Alibaba Cloud-Anwendungen in Kubernetes-Clustern: Dies sind zustandsbehaftete / zustandslose Anwendungen sowie Anwendungsmanager. Die Verwaltung von Kubernetes war schon immer ein interessantes und ernstes Diskussionsthema für Ingenieure, die mit dem Aufbau und der Wartung der Infrastruktur befasst sind. Bei Cloud-Anbietern wie Alibaba Cloud steht die Skalierung im Vordergrund. Wie verwaltet man Kubernetes-Cluster in dieser Größenordnung? Wir haben bereits über Best Practices für die Verwaltung riesiger Kubernetes-Cluster mit 10.000 Knoten gesprochen. Dies ist natürlich ein interessantes Skalierungsproblem. Es gibt jedoch eine andere Skalenskala: die Anzahl
der Cluster selbst .
Wir haben dieses Thema mit vielen ACK-Benutzern diskutiert. Die meisten von ihnen ziehen es vor, Dutzende, wenn nicht Hunderte kleiner oder mittlerer Kubernetes-Cluster auszuführen. Dafür gibt es vernünftige Gründe: Begrenzung des potenziellen Schadens, Aufteilung von Clustern für verschiedene Teams, Erstellung virtueller Cluster zum Testen. Wenn ACK mit diesem Nutzungsmodell ein globales Publikum bedienen möchte, muss es eine große Anzahl von Clustern in mehr als 20 Regionen zuverlässig und effizient verwalten.
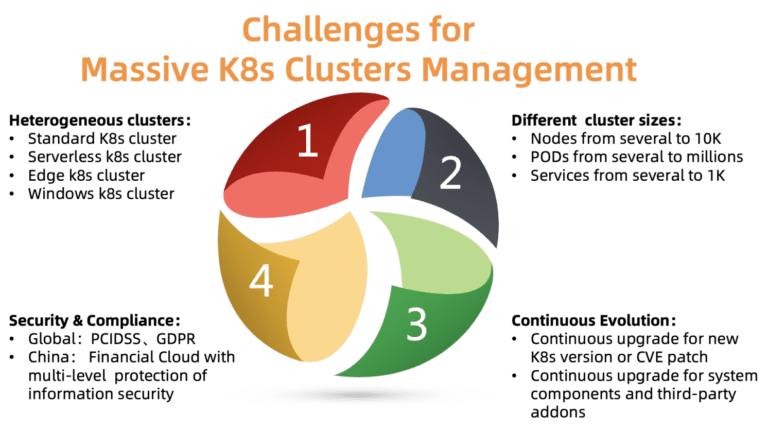 Abb. 2. Herausforderungen bei der Verwaltung einer großen Anzahl von Kubernetes-Clustern
Abb. 2. Herausforderungen bei der Verwaltung einer großen Anzahl von Kubernetes-ClusternWas sind die Hauptprobleme der Clusterverwaltung in dieser Größenordnung? Wie in der Abbildung gezeigt, gibt es vier Punkte, mit denen Sie sich befassen müssen:
ACK muss verschiedene Arten von Clustern unterstützen, darunter Standard, Serverless, Edge, Windows und einige andere. Unterschiedliche Cluster erfordern unterschiedliche Parameter, Komponenten und Hosting-Modelle. Einige Kunden benötigen Hilfe bei der Anpassung für ihre speziellen Fälle.
- Unterschiedliche Clustergrößen
Cluster variieren in der Größe: von einem Knotenpaar mit mehreren Hülsen bis zu Zehntausenden von Knoten mit Tausenden von Hülsen. Auch die Ressourcenanforderungen sind sehr unterschiedlich. Eine falsche Zuweisung von Ressourcen kann die Leistung beeinträchtigen oder sogar zum Ausfall führen.
- Verschiedene Ausführungen
Kubernetes wächst rasant. Alle paar Monate erscheinen neue Versionen. Kunden sind immer bereit, neue Funktionen auszuprobieren. Daher möchten sie die Testlast auf neue Versionen von Kubernetes und die Arbeitslast auf stabile Versionen legen. Um diese Anforderung zu erfüllen, muss ACK seinen Kunden kontinuierlich neue Versionen von Kubernetes liefern und dabei stabile Versionen beibehalten.
- Einhaltung der Sicherheitsbestimmungen
Cluster sind in verschiedenen Regionen verteilt. Sie müssen daher verschiedene Sicherheitsanforderungen und behördliche Vorschriften erfüllen. Beispielsweise muss ein Cluster in Europa der DSGVO entsprechen, und eine Finanzwolke in China muss ein zusätzliches Schutzniveau aufweisen. Diese Anforderungen sind obligatorisch und können nicht ignoriert werden, da dies enorme Risiken für Kunden von Cloud-Plattformen mit sich bringt.
Die ACK-Plattform wurde entwickelt, um die meisten der oben genannten Probleme zu lösen. Derzeit verwaltet es zuverlässig und stabil mehr als 10.000 Kubernetes-Cluster auf der ganzen Welt. Lassen Sie uns sehen, wie wir dies geschafft haben, auch aufgrund mehrerer Schlüsselprinzipien von Design / Architektur.
Design
Würfel auf Würfel und Waben
Im Gegensatz zu einer zentralisierten Hierarchie wird eine zellenbasierte Architektur normalerweise verwendet, um eine Plattform über ein einzelnes Rechenzentrum hinaus zu skalieren oder den Umfang der Notfallwiederherstellung zu erweitern.
Jede Region in der Alibaba Cloud besteht aus mehreren Zonen (AZ) und entspricht normalerweise einem bestimmten Rechenzentrum. In einer großen Region (wie Huangzhou) werden häufig Tausende von Kubernetes-Client-Clustern gefunden, auf denen ACK ausgeführt wird.
Das ACK verwaltet diese Kubernetes-Cluster mithilfe von Kubernetes selbst. Das heißt, wir verfügen über das Kubernetes-Metacluster für die Verwaltung von Kubernetes-Client-Clustern. Diese Architektur wird auch als "Cube-on-Cube" (kube-on-kube, KoK) bezeichnet. Die KoK-Architektur vereinfacht die Verwaltung von Client-Clustern, da die Bereitstellung eines Clusters einfach und deterministisch wird. Noch wichtiger ist, dass wir die Funktionen nativer Kubernetes wiederverwenden können. Zum Beispiel das Verwalten von API-Servern durch Deployment mit dem etcd-Operator zum Verwalten mehrerer etcd. Eine solche Rekursion bereitet immer besondere Freude.
In derselben Region werden je nach Anzahl der Clients mehrere Kubernetes-Metacluster bereitgestellt. Diese Metacluster nennen wir Zellen. Zum Schutz vor dem Ausfall einer gesamten Zone unterstützt ACK multiaktive Bereitstellungen in einer Region: Der Metacluster verteilt die Komponenten des Kubernetes-Client-Cluster-Assistenten auf mehrere Zonen und startet diese gleichzeitig, dh im multiaktiven Modus. Um die Zuverlässigkeit und Effektivität des Assistenten sicherzustellen, optimiert das ACK die Komponentenplatzierung und stellt sicher, dass API-Server und etcd nahe beieinander liegen.
Mit diesem Modell können Sie Kubernetes effektiv, flexibel und zuverlässig verwalten.
Metacluster-Ressourcenplanung
Wie bereits erwähnt, hängt die Anzahl der Metacluster in jeder Region von der Anzahl der Kunden ab. Aber an welchem Punkt fügen Sie einen neuen Metacluster hinzu? Dies ist ein typisches Ressourcenplanungsproblem. In der Regel ist es üblich, einen neuen zu erstellen, wenn vorhandene Metacluster alle Ressourcen aufgebraucht haben.
Nehmen Sie zum Beispiel Netzwerkressourcen. In der KoK-Architektur werden Kubernetes-Komponenten aus Client-Clustern als Pods im Metacluster bereitgestellt. Wir verwenden
Terway (Abb. 3), ein von Alibaba Cloud entwickeltes Hochleistungs-Plugin für das Containernetzwerkmanagement. Es bietet eine Vielzahl von Sicherheitsrichtlinien und ermöglicht es Ihnen, über die Alibaba Cloud Elastic Networking Interface (ENI) eine Verbindung zu Virtual Private Cloud (VPC) -Clients herzustellen. Um Netzwerkressourcen effizient auf Knoten, Pods und Services in einem Metacluster zu verteilen, müssen wir deren Verwendung in einem Metacluster von virtuellen privaten Clouds aus sorgfältig überwachen. Wenn die Netzwerkressourcen abgelaufen sind, wird eine neue Zelle erstellt.
Um die optimale Anzahl von Client-Clustern in jedem Metacluster zu ermitteln, berücksichtigen wir auch unsere Kosten, Dichteanforderungen, Ressourcenkontingente, Zuverlässigkeitsanforderungen und Statistiken. Die Entscheidung, einen neuen Metacluster zu erstellen, wird auf der Grundlage all dieser Informationen getroffen. Bitte beachten Sie, dass kleine Cluster in Zukunft stark expandieren können, sodass der Ressourcenverbrauch auch bei gleicher Anzahl von Clustern zunimmt. Normalerweise lassen wir genügend freien Speicherplatz für das Wachstum jedes Clusters.
 Abb. 3. Netzwerkarchitektur Terway
Abb. 3. Netzwerkarchitektur TerwayKomponenten des Skalierungsassistenten in Client-Clustern
Assistentenkomponenten haben unterschiedliche Ressourcenanforderungen. Sie hängen von der Anzahl der Knoten und Pods im Cluster und der Anzahl der nicht standardmäßigen Controller / Operatoren ab, die mit APIServer interagieren.
In der ACK unterscheidet sich jeder Kubernetes-Client-Cluster in Größe und Laufzeitanforderungen. Es gibt keine universelle Konfiguration für das Hosten von Assistentenkomponenten. Wenn wir versehentlich ein niedriges Ressourcenlimit für einen großen Client festlegen, wird sein Cluster die Last nicht bewältigen. Wenn Sie ein konservativ hohes Limit für alle Cluster festlegen, werden Ressourcen verschwendet.
Um einen subtilen Kompromiss zwischen Zuverlässigkeit und Kosten zu finden, verwendet ACK ein Typensystem. Wir definieren nämlich drei Arten von Clustern: kleine, mittlere und große. Jeder Typ hat ein separates Ressourcenzuweisungsprofil. Der Typ wird basierend auf dem Laden der Assistentenkomponenten, der Anzahl der Knoten und anderen Faktoren bestimmt. Die Art des Clusters kann sich im Laufe der Zeit ändern. ACK überwacht diese Faktoren ständig und kann den Typ entsprechend erhöhen / verringern. Nach dem Ändern des Clustertyps wird die Ressourcenverteilung automatisch mit minimalem Benutzereingriff aktualisiert.
Wir arbeiten daran, dieses System im Hinblick auf eine feinere Skalierung und genauere Typaktualisierungen zu verbessern, damit diese Änderungen reibungsloser und wirtschaftlicher ablaufen.
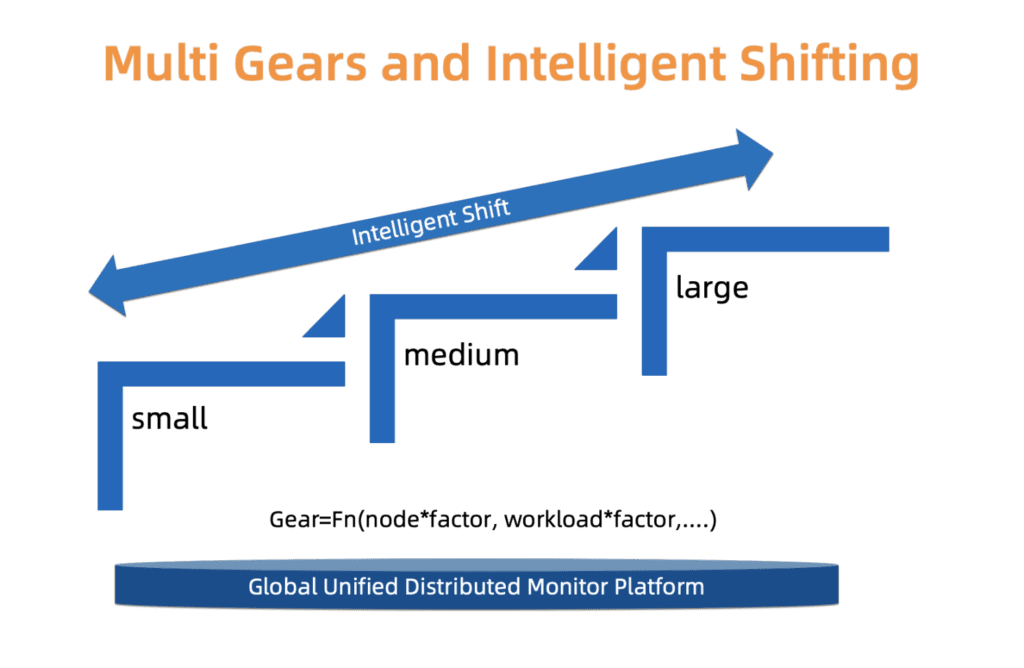 Abb. 4. Intelligente mehrstufige Typumschaltung
Abb. 4. Intelligente mehrstufige TypumschaltungDie Entwicklung von Kundenclustern auf einer Skala
In den vorherigen Abschnitten wurden einige Aspekte der Verwaltung einer großen Anzahl von Kubernetes-Clustern beschrieben. Es gibt jedoch ein anderes Problem, das angegangen werden muss: die Clusterentwicklung.
Kubernetes ist Linux in der Cloud-Welt. Es wird ständig aktualisiert und modularer. Wir müssen unsere Kunden ständig mit neuen Versionen versorgen, Schwachstellen beheben und vorhandene Cluster aktualisieren sowie eine große Anzahl zugehöriger Komponenten verwalten (CSI, CNI, Device Plugin, Scheduler Plugin und viele andere).
Nehmen Sie als Beispiel Kubernetes Komponentenmanagement. Zunächst haben wir ein zentrales Registrierungs- und Verwaltungssystem für alle diese Plug-In-Komponenten entwickelt.
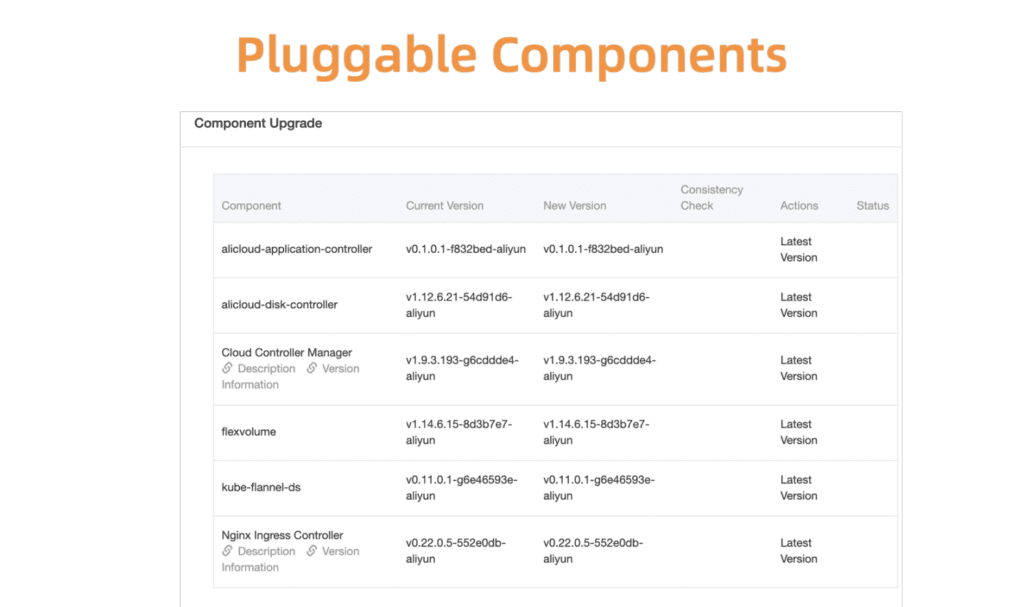 Abb. 5. Flexible und steckbare Komponenten
Abb. 5. Flexible und steckbare KomponentenBevor Sie fortfahren, müssen Sie sicherstellen, dass das Update erfolgreich ist. Dazu haben wir ein Komponenten-Health-Check-System entwickelt. Die Validierung wird vor und nach dem Upgrade durchgeführt.
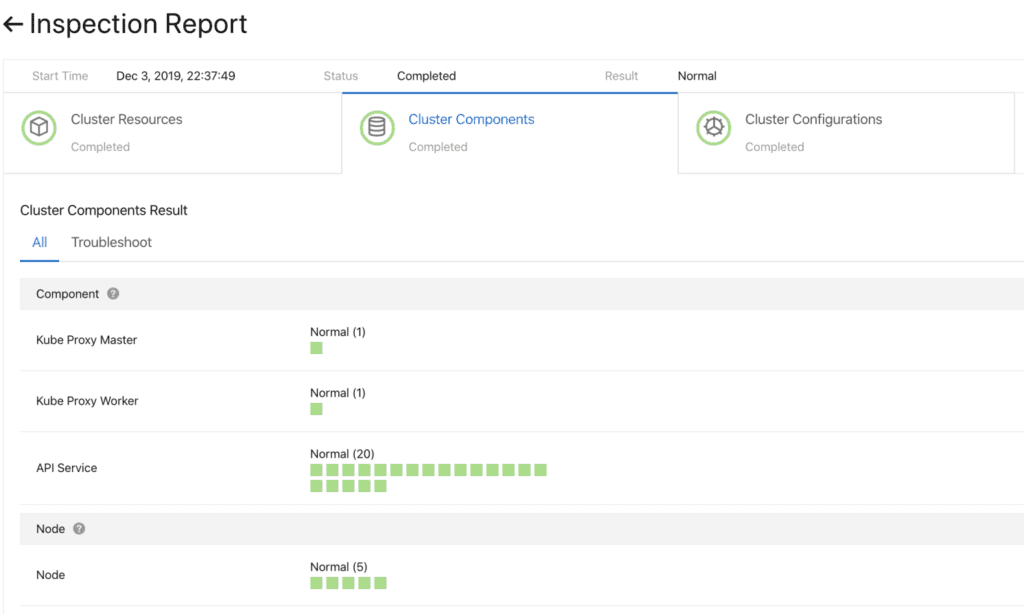 Abb. 6. Vorabprüfung der Clusterkomponenten
Abb. 6. Vorabprüfung der ClusterkomponentenUm diese Komponenten schnell und zuverlässig zu aktualisieren, unterstützt ein kontinuierliches Bereitstellungssystem die teilweise Heraufstufung (Graustufen), Pausen und andere Funktionen. Standard-Kubernetes-Controller sind für diese Verwendung nicht gut geeignet. Zur Verwaltung der Cluster-Komponenten haben wir daher eine Reihe spezialisierter Steuerungen entwickelt, darunter ein Plug-In und ein Zusatzsteuerungsmodul (Sidecar-Management).
Der BroadcastJob-Controller dient beispielsweise zum Aktualisieren von Komponenten auf jedem Arbeitscomputer oder zum Überprüfen von Knoten auf jedem Computer. Der Broadcast-Job führt auf jedem Knoten im Cluster einen Pod aus, wie z. B. ein DaemonSet. DaemonSet unterstützt jedoch immer den kontinuierlichen Betrieb des Pods, während BroadcastJob ihn minimiert. Der Broadcast-Controller startet auch Pods auf neu verbundenen Knoten und initialisiert Knoten mit den erforderlichen Komponenten. Im Juni 2019 haben wir den Quellcode für die OpenKruise Automation Engine geöffnet, die wir selbst im Unternehmen verwenden.
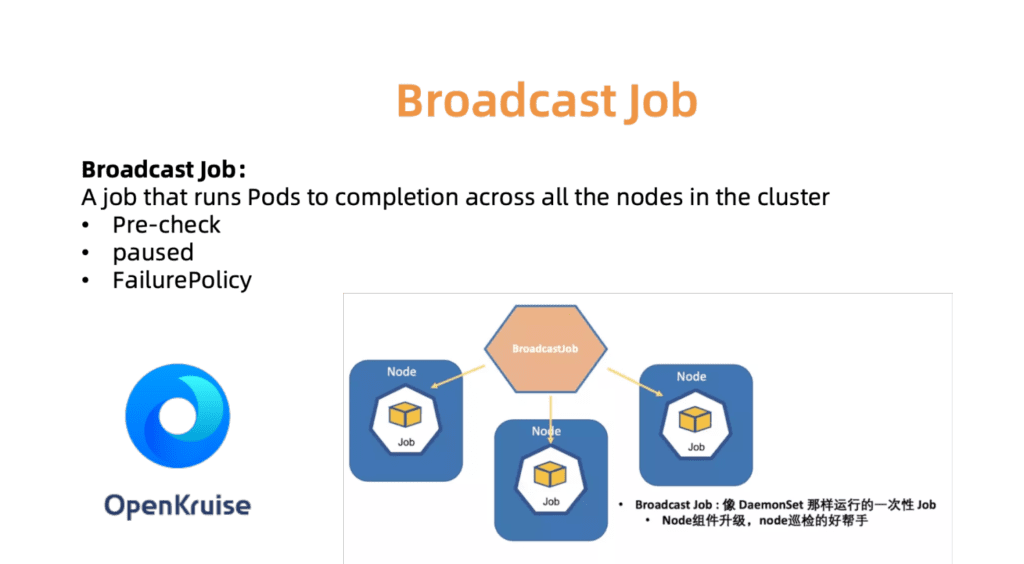 Abb. 7. OpenKurise organisiert Broadcast-Aufträge an allen Standorten.
Abb. 7. OpenKurise organisiert Broadcast-Aufträge an allen Standorten.Um Kunden bei der Auswahl der richtigen Cluster-Konfigurationen zu unterstützen, bieten wir auch eine Reihe vordefinierter Profile an, darunter Serverless-, Edge-, Windows- und Bare-Metal-Profile. Wenn sich die Landschaft erweitert und die Bedürfnisse unserer Kunden wachsen, werden wir weitere Profile hinzufügen, um den langwierigen Einrichtungsprozess zu vereinfachen.
 Abb. 8. Erweiterte und flexible Clusterprofile für verschiedene Szenarien
Abb. 8. Erweiterte und flexible Clusterprofile für verschiedene SzenarienBeobachtbarkeit des globalen Rechenzentrums
Wie unten in Abb. 9, Alibaba Cloud Container wird in zwanzig Regionen der Welt eingesetzt. Angesichts dieser Größenordnung besteht eine der Hauptaufgaben von ACK darin, den Status laufender Cluster auf einfache Weise zu überwachen: Wenn beim Client-Cluster ein Problem auftritt, können wir schnell auf die Situation reagieren. Mit anderen Worten, Sie müssen eine Lösung finden, mit der Sie effizient und sicher Echtzeitstatistiken von Kundenclustern in allen Regionen erfassen und die Ergebnisse visuell darstellen können.
 Abb. 9. Globale Bereitstellung des Alibaba Cloud Container Service in 20 Regionen
Abb. 9. Globale Bereitstellung des Alibaba Cloud Container Service in 20 RegionenWie bei vielen Kubernetes-Überwachungssystemen haben wir Prometheus als unser Hauptwerkzeug. Für jeden Metacluster erfassen Prometheus-Agenten die folgenden Metriken:
- Betriebssystemmetriken wie Hostressourcen (Prozessor, Speicher, Festplatte usw.) und Netzwerkbandbreite.
- Metriken für das Metacluster- und Clientcluster-Verwaltungssystem, z. B. kube-apiserver, kube-controller-manager und kube-scheduler.
- Metriken aus kubernetes-state-metrics und cadvisor.
- Etcd-Metriken wie Festplattenschreibzeit, Datenbankgröße, Durchsatz zwischen Knoten usw.
Globale Statistiken werden mithilfe eines typischen mehrschichtigen Aggregationsmodells erfasst. Überwachungsdaten von jedem Metacluster werden zuerst in jeder Region aggregiert und dann an einen zentralen Server gesendet, der das Gesamtbild zeigt. Alles funktioniert über den Föderationsmechanismus. Der Prometheus-Server in jedem Rechenzentrum sammelt die Messdaten dieses Rechenzentrums, und der zentrale Prometheus-Server ist für die Aggregation der Überwachungsdaten verantwortlich. Der AlertManager stellt eine Verbindung zum zentralen Prometheus her und sendet bei Bedarf Alarme über DingTalk, E-Mail, SMS usw. Visualisierung - mit Grafana.
In Abbildung 10 kann das Überwachungssystem in drei Ebenen unterteilt werden:
Die am weitesten von der Mitte entfernte Schicht. Der Prometheus Edge-Server wird auf jedem Metacluster ausgeführt und erfasst Metriken von Meta- und Client-Clustern innerhalb derselben Netzwerkdomäne.
Die Prometheus-Kaskadenschichtfunktion dient zum Sammeln von Überwachungsdaten aus mehreren Regionen. Diese Server arbeiten auf der Ebene größerer geografischer Einheiten wie China, Asien, Europa und Amerika. Wenn Cluster in einer Region wachsen, können sie aufgeteilt werden, und dann wird in jeder neuen großen Region ein Prometheus-Server auf Kaskadenebene angezeigt. Mit dieser Strategie können Sie nach Bedarf nahtlos skalieren.
Der zentrale Prometheus-Server stellt eine Verbindung zu allen kaskadierenden Servern her und führt die endgültige Datenaggregation durch. Aus Gründen der Zuverlässigkeit wurden zwei zentrale Prometheus-Instanzen, die mit denselben kaskadierenden Servern verbunden sind, in verschiedenen Zonen ausgelöst.
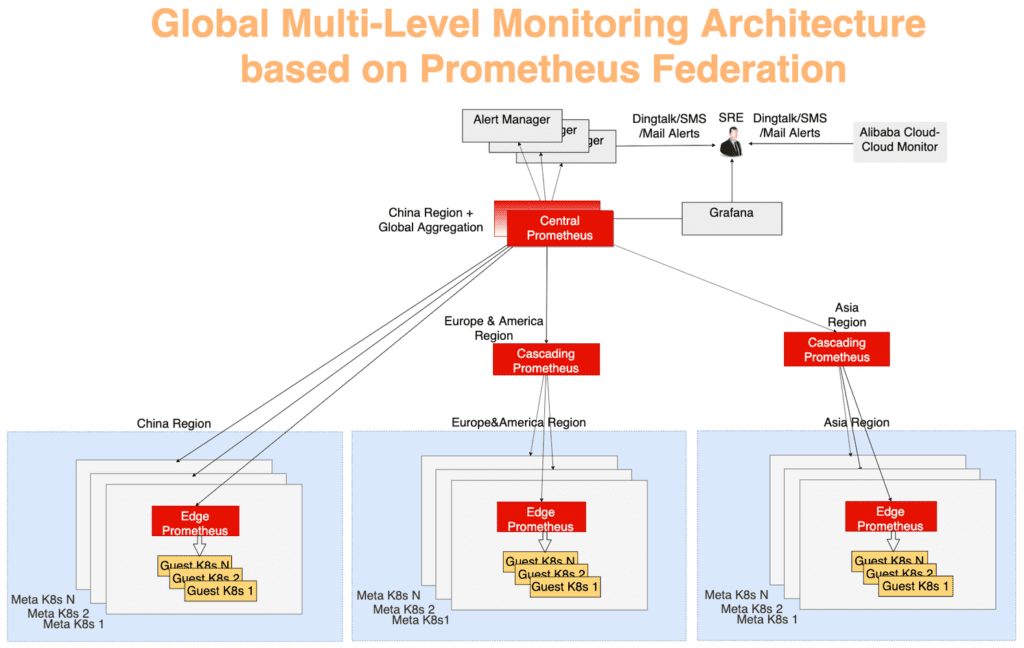 Abb. 10. Globale mehrschichtige Überwachungsarchitektur basierend auf dem Prometheus-Verbundmechanismus
Abb. 10. Globale mehrschichtige Überwachungsarchitektur basierend auf dem Prometheus-VerbundmechanismusZusammenfassung
Kubernetes-basierte Cloud-Lösungen verändern unsere Branche weiterhin. Alibaba Cloud Container Service bietet sicheres, zuverlässiges und leistungsstarkes Hosting - dies ist einer der besten Cloud-Hosting-Services von Kubernet. Das Alibaba Cloud-Team glaubt fest an die Prinzipien von Open Source und der Open Source-Community. Wir werden unser Wissen im Bereich Betrieb und Management von Cloud-Technologien auf jeden Fall weiter teilen.