In diesem Artikel möchte ich meine Erfahrungen mit der Verwendung dieser Open-Source-Bibliothek am Beispiel der Implementierung einer Aufgabe mit dem Parsen von
PDF / DOC / DOCX- Dateien mit Lebensläufen von Spezialisten teilen.
Hier beschreibe ich auch die Schritte zur Implementierung des Tools zur Vorbereitung des Datensatzes. Anschließend kann das
BERT- Modell im Rahmen der Erkennung von Entitäten anhand von Texten auf den empfangenen Datensatz trainiert werden (
Named Entity Recognition - im Folgenden:
NER ).
Also, wo soll ich anfangen? Natürlich müssen Sie zuerst die Umgebung installieren und konfigurieren, um unser Tool auszuführen. Ich werde auf
Windows 10 installieren.
Auf Habré gibt es bereits einige Artikel der Entwickler dieser Bibliothek, in denen es nur eine ausführliche Installationsanleitung gibt. Und in diesem Artikel möchte ich alles zusammenstellen, vom Start bis zum Modelltraining. Ich werde auch Lösungen für einige der Probleme nennen, auf die ich bei der Arbeit mit dieser Bibliothek gestoßen bin.
WICHTIG: Bei der Installation ist es wichtig, die Versionen aller Produkte und Komponenten einzuhalten, da häufig Probleme mit inkompatiblen Versionen auftreten. Dies gilt insbesondere für die TensorFlow- Bibliothek. Es kommt sogar vor, dass Sie für einige Aufgaben, bis zum erforderlichen Festschreiben auf GitHub, diese verwenden müssen. Im Falle von DeepPavlov ist die Einhaltung nur der unterstützten Version ausreichend.
Ich werde die Produktversionen der Arbeitskonfiguration und die Spezifikationen meines Laptops angeben, auf denen ich mit dem Training des neuronalen Netzwerks begonnen habe. Ich werde einige Links bereitstellen, die auch die Installation und Konfiguration der Open-Source-
DeepPavlov- Bibliothek beschreiben.
Nützliche Links von DeepPavlov-Entwicklern
Komponentenversionen für die Installation
- Python 3.6.6 - 3.7
- Visual Studio Community 2017 (optional)
- Visual C ++ Build Tools 14.0.25420.1
- nVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0-windows10-x64-v7.6.5.32
Festlegen der Umgebung für die GPU-Unterstützung
- Installieren Sie Python oder Visual Studio Community 2017, die in Python enthalten sind . In meiner Installation habe ich die zweite Methode verwendet, Visual Studio Community mit Python- Unterstützung zu installieren.
Natürlich müssen Sie den Pfad zum Ordner manuell hinzufügenC:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64
Für die Systemvariable PATH , in der Python von Visual Studio installiert wird, ist es für mich jedoch kein Problem, zu wissen, dass ich eine Version für Python installiert habe.
Aber das ist mein Fall, du kannst alles separat installieren. - Der nächste Schritt ist die Installation der Visual C ++ Build Tools .
- Installieren Sie dann nVIDIA CUDA .
WICHTIG: Wenn die nVIDIA CUDA- Bibliothek zuvor installiert wurde, müssen Sie alle zuvor installierten Komponenten von nVIDIA bis zum Grafiktreiber entfernen. Führen Sie erst dann bei einer Neuinstallation des Grafiktreibers die Installation von nVIDIA CUDA durch .
- Installieren Sie nun cuDNN für nVIDIA CUDA .
Dazu müssen Sie sich für die Mitgliedschaft im NVIDIA Developer Program registrieren (kostenlos).

- Laden Sie die cuDNN- Version für CUDA 10.0 herunter

- Entpacke das Archiv in einen Ordner
C:\Users\<_>\Downloads\cuDNN
- Kopieren Sie den gesamten Inhalt des Ordners .. \ cuDNN in den Ordner, in dem CUDA installiert ist
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
- Starten Sie den Computer neu. Optional, aber ich empfehle.
Installieren Sie DeepPavlov
- Erstellen und aktivieren Sie die virtuelle Python- Umgebung.
WICHTIG: Das habe ich über Visual Studio gemacht.
- Zu diesem Zweck habe ich ein neues Projekt für From Existing Python-Code erstellt .

- Wir drücken weiter bis zum letzten Fenster, aber auf Fertig stellen klicken wir noch nicht. Sie müssen das Kontrollkästchen " Virtuelle Umgebungen erkennen " deaktivieren.

- Klicken Sie auf Fertig stellen .
- Jetzt müssen Sie eine virtuelle Umgebung erstellen.

- Wir lassen alles standardmäßig.

- Öffnen Sie den Projektordner in der Befehlszeile. Und führen Sie den Befehl aus:
.\env\Scripts\activate.bat

- Jetzt ist alles bereit, um DeepPavlov zu installieren. Wir führen den Befehl aus:
pip install deeppavlov
- Als nächstes müssen Sie TensorFlow 1.14.0 mit GPU- Unterstützung installieren. Führen Sie dazu den folgenden Befehl aus:
pip install tensorflow-gpu==1.14.0
- Fast alles ist fertig. Sie müssen nur sicherstellen, dass TensorFlow die Grafikkarte für Berechnungen verwendet. Dazu schreiben wir ein einfaches Skript devices.py mit folgendem Inhalt:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
oder tensorflow_test.py :
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)
- Nach dem Ausführen von devices.py sollte etwa Folgendes angezeigt werden :
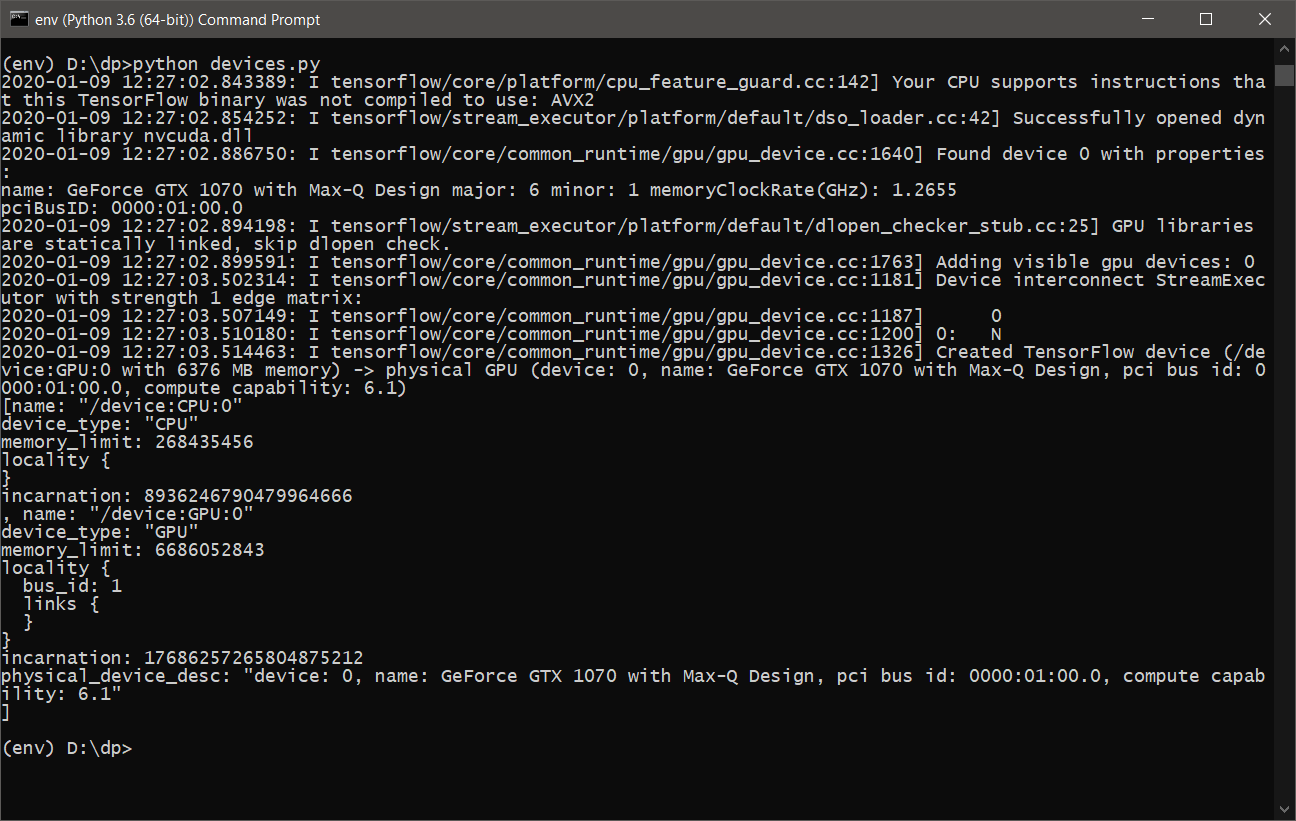
- Jetzt können Sie DeepPavlov mit GPU- Unterstützung erlernen und verwenden.
DeepPavlov auf REST API
Um den Dienst für die REST-API zu starten und zu installieren, müssen Sie die folgenden Befehle ausführen:
- Installation in einer aktiven virtuellen Umgebung
python -m deeppavlov install ner_ontonotes_bert_mult
- Laden Sie das ner_ontonotes_bert_mult- Modell von DeepPavlov- Servern herunter
python -m deeppavlov download ner_ontonotes_bert_mult
- Führen Sie die REST-API aus
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
Dieses Modell ist unter
http: // localhost: 5005 verfügbar. Sie können Ihren Port angeben.
Alle Modelle werden standardmäßig heruntergeladen.
C:\Users\<_>\.deeppavlov
DeepPavlov für das Training einrichten
Bevor Sie mit dem Lernprozess beginnen, müssen Sie
DeepPavlov so konfigurieren, dass der Lernprozess nicht mit dem Fehler „abstürzt“, dass der Speicher auf unserer Grafikkarte voll ist. Dafür haben wir Konfigurationsdateien für jedes Modell.
Wie im Beispiel der Entwickler verwende ich auch das Modell
ner_ontonotes_bert_mult . Alle Standardkonfigurationen für
DeepPavlov befinden sich entlang des Pfads:
<_>\env\Lib\site-packages\deeppavlov\configs\ner
In meinem Fall wird die Datei wie das Modell
ner_ontonotes_bert_mult.json benannt .
Für meine Laptop-Konfiguration musste ich den
batch_size- Wert im
Zugblock auf 4 ändern.

Ansonsten „erstickte“ meine Grafikkarte nach ein paar Minuten und der Lernprozess fiel mit einem Fehler aus.
Nobook-Konfiguration
- Modell: MSI GS-65
- Prozessor: Core i7 8750H 2200 MHz
- Die Menge des installierten Speichers: 32 GB DDR-4
- Festplatte: 512 GB SSD
- Grafikkarte: GeForce GTX 1070 8192 Mb
Tool zur Datensatzvorbereitung
Um das Modell zu trainieren, müssen Sie einen Datensatz vorbereiten. Der Datensatz besteht aus drei Dateien
train.txt ,
valid.txt und
test.txt . Mit einer Aufschlüsselung der Daten in den folgenden Prozentsatz Zug - 80%, gültig und Test für 10%.
Der Datensatz für das BERT-Modell lautet wie folgt:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG IO ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
Das Format des Datensatzes lautet wie folgt:
<_><><_>
WICHTIG: Nach dem Satzende muss ein Zeilenumbruch erfolgen. Wenn das Angebot mehr als 75 Token enthält, muss auch ein Zeilenumbruch eingefügt werden. Andernfalls schlägt der Prozess beim Erlernen des Modells fehl.
Um den Datensatz vorzubereiten, habe ich eine Webschnittstelle geschrieben, über die es möglich ist,
DOC / PDF / DOCX- Dateien auf einen Server hochzuladen, sie in Klartext zu analysieren und diesen Text dann über ein aktives Modell mit REST-API-Zugriff auszuführen, während das Ergebnis in einer Zwischendatenbank gespeichert wird. Dafür benutze ich
MongoDB .
Nachdem die obigen Aktionen abgeschlossen sind, können Sie mit der Erstellung des Datensatzes für unsere Bedürfnisse fortfahren.
Zu diesem Zweck habe ich in meiner schriftlichen Weboberfläche ein separates Bedienfeld erstellt, in dem es möglich ist, nach Dataset-Token zu suchen und dann den Tokentyp und den Tokentext selbst zu ändern.
Das Tool weiß auch, wie der vom Benutzer auf Anfrage angegebene Tokentyp anhand einer Wortliste automatisch aktualisiert wird.
Im Allgemeinen hilft das Tool, einen Teil der Arbeit zu automatisieren, aber Sie müssen noch viel manuelle Arbeit leisten.
Eine Schnittstelle zur Überprüfung des Ergebnisses und zur Aufteilung des Datensatzes in drei Dateien ist ebenfalls implementiert.
DeepPavlov Training
Also kamen wir zum interessantesten Teil. Für den Lernprozess müssen Sie zuerst das
ner_ontonotes_bert_mult- Modell herunterladen. Wenn Sie dies noch nicht getan haben, müssen Sie die ersten beiden Schritte vom
DeepPavlov- Abschnitt
zur obigen
REST-API ausführen .
Bevor Sie mit dem Lernprozess beginnen, müssen Sie zwei Schritte ausführen:
- Löschen Sie den Ordner mit dem trainierten Modell vollständig:
C:\Users\<_>\.deeppavlov\models\ner_ontonotes_bert_mult
Da dieses Modell auf einen anderen Datensatz trainiert wurde. - Kopieren Sie die vorbereiteten Dataset-Dateien train.txt, valid.txt, test.txt in den Ordner
C:\Users\<_>\.deeppavlov\downloads\ontonotes
Jetzt können Sie den Lernprozess starten.
Um mit dem Training zu beginnen, können Sie ein einfaches
train.py- Skript in der folgenden Form schreiben:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
oder benutze die Kommandozeile:
python -m deeppavlov train <_>\env\Lib\site-packages\deeppavlov\configs\ner\ner_ontonotes_bert_mult.json
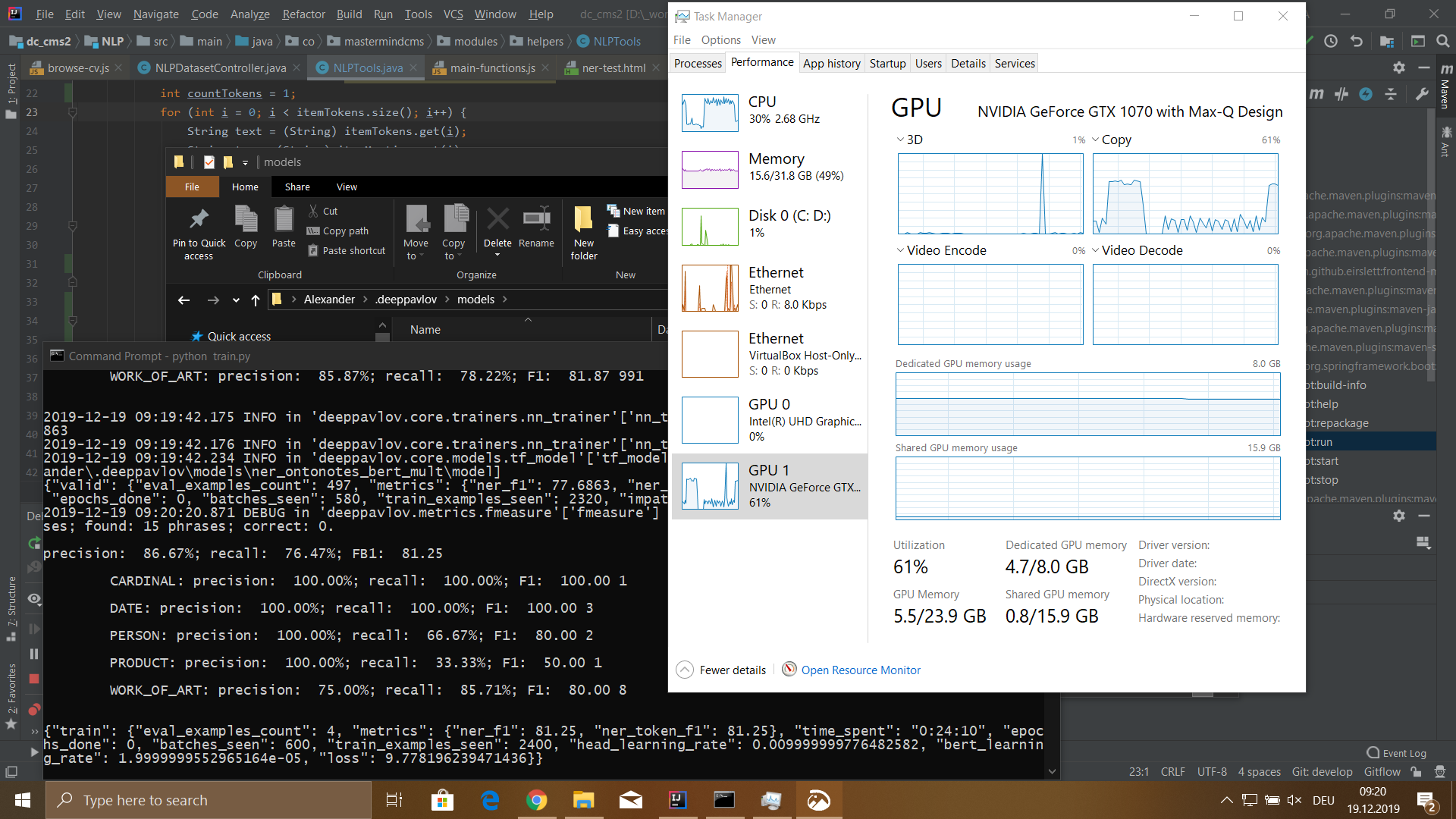
Ergebnisse
Ich habe ein Modell auf einen Datensatz mit einer Größe von 115.540 Token trainiert. Dieser Datensatz wurde aus 100 Lebenslaufdateien von Mitarbeitern generiert. Der Lernprozess dauerte 5 Stunden 18 Minuten.
Das Modell hatte folgende Bedeutungen:
- Präzision: 76,32%;
- Rückruf: 72,32%;
- FB1: 74,27;
- Verlust: 5,4907482981681826;
Nach der Bearbeitung mehrerer Probleme bei der automatischen Generierung des Datensatzes habe ich unten einen
Verlust erhalten . Aber im Allgemeinen war ich mit dem Ergebnis zufrieden. Natürlich habe ich noch viele Fragen zur Verwendung dieser Bibliothek, und was ich hier beschrieben habe, ist nur ein Tropfen auf den heißen Stein.
Die Bibliothek hat mir wegen ihrer Einfachheit und Benutzerfreundlichkeit sehr gut gefallen. Zumindest für die
NER- Aufgabe. Ich werde sehr froh sein, andere Funktionen dieser Bibliothek zu diskutieren, und ich hoffe, dass jemand das Material aus diesem Artikel nützlich finden wird.