- Eintrag
- Bibliotheksverbindung
- Wo Klasse
- Klasse beitreten
- Klassenabfrage
╔═══╗╔═══╗╔═══╗╔═══╗╔╗─╔╗────╔═══╗╔══╗╔═══╗ ║╔══╝║╔═╗║║╔══╝║╔══╝║╚═╝║────║╔═╗║╚╗╔╝║╔══╝ ║║╔═╗║╚═╝║║╚══╗║╚══╗║╔╗─║────║╚═╝║─║║─║║╔═╗ ║║╚╗║║╔╗╔╝║╔══╝║╔══╝║║╚╗║────║╔══╝─║║─║║╚╗║ ║╚═╝║║║║║─║╚══╗║╚══╗║║─║║────║║───╔╝╚╗║╚═╝║ ╚═══╝╚╝╚╝─╚═══╝╚═══╝╚╝─╚╝────╚╝───╚══╝╚═══╝ 5HHHG HH HHHHHHH 9HHHA HHHHHHHH5 HHHHHHHHHHHHHHHHHH 9HHHHH5 5HHHHHHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHHHHHHH ;HHHHHHHHHHHHHHHHHHHHHHHHHHA H2 HHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHH9 HHHHHHHHHHHHHHHHHHHHHHH AHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHH9 iHS HHHHHHHHHHHHHHHHHHHHHHhh HHHHHHHHHHHHHHHHHH AA HHHHHHHHHHHHHH3 &H Hi HS Hr & H& H& Hi
Eintrag
Ich möchte Ihnen etwas über die Entwicklung meiner kleinen Bibliothek in PHP erzählen. Welche Aufgaben löst sie? Warum habe ich beschlossen, es zu schreiben und warum könnte es für Sie nützlich sein? Nun versuchen Sie, diese Fragen zu beantworten.
GreenPig (im Folgenden GP ) ist ein kleiner Datenbankassistent, der die Funktionalität jedes von Ihnen verwendeten PHP-Frameworks ergänzen kann.
Wie jedes GP- Tool wird es zur Lösung bestimmter Probleme geschärft. Es ist nützlich für Sie, wenn Sie Datenbankabfragen lieber in reinem SQL schreiben und Active Record und andere ähnliche Technologien nicht verwenden möchten. Zum Beispiel haben wir eine Oracle-Datenbank in Arbeit und oft belegen Abfragen mehrere Bildschirme mit Dutzenden von Joins, Plsql-Funktionen, Union all, usw. werden immer noch verwendet. usw., es bleibt also nichts anderes übrig, als Abfragen in reinem SQL zu schreiben.
Bei diesem Ansatz stellt sich jedoch die Frage, wie der Teil der SQL-Abfrage generiert werden soll, wenn Benutzer nach Informationen suchen. GP zielt in erster Linie auf die bequeme Kompilierung mittels PHP ab, wenn eine Anfrage von beliebiger Komplexität vorliegt.
Aber was hat mich dazu veranlasst, diese Bibliothek zu schreiben (außer natürlich, um interessante Erfahrungen zu sammeln)? Das sind drei Dinge:
Erstens die Notwendigkeit, keine standardmäßige flache Antwort aus der Datenbank zu erhalten, sondern ein geschachteltes, baumartiges Array.
Hier ist ein Beispiel für ein Standarddatenbankbeispiel: [ [0] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [1] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [2] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [3] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [4] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [5] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [6] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [7] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [8] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [9] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [10] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [11] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [12] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [13] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [14] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [15] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [16] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [17] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ] ]
Um ein baumartiges Array zu erhalten, müssen wir entweder das Ergebnis selbst auf das gewünschte Formular bringen oder N Datenbankabfragen für jedes Produkt durchführen. Und wenn wir Paginierung brauchen und auch mit Sortieren? GP ist in der Lage, diese Probleme zu lösen. Hier ist ein Beispiel für ein Beispiel mit GP :
[ [1] => [ ['prod_type'] => 'car' ['properties'] => [ [1] => [ ['name'] => ' ()' ['value'] => 790 ] [2] => [ ['name'] => ' ' ['value'] => 24 ] [3] => [ ['name'] => ' ' ['value'] => 75 ] ] ] [4] => [ ['prod_type'] => 'phone' ['properties'] => [ [10] => [ ['name'] => ' ' ['value'] => 5 ] [8] => [ ['name'] => ' ()' ['value'] => 0.12 ] [9] => [ ['name'] => ' ' ['value'] => 1 ] ] ] ]
Und natürlich gleichzeitig bequemes Paginieren und Sortieren: ->pagination(1, 10)->sort('id') .
Der zweite Grund ist nicht so häufig, tritt aber dennoch auf (und in meinem Fall ist dies der Hauptgrund). Wenn einige Entitäten in der Datenbank gespeichert sind und die Eigenschaften dieser Entitäten dynamisch sind und von Benutzern festgelegt wurden, müssen Sie beim Suchen nach Entitäten anhand ihrer Eigenschaften dieselbe Tabelle mit den Eigenschaftswerten hinzufügen (verknüpfen) (so oft sie verwendet werden) Eigenschaften bei der Suche). Der GP hilft Ihnen also, alle Tabellen zu verbinden und die where-Abfrage mit fast einer Funktion zu generieren. Gegen Ende des Artikels werde ich diesen Fall im Detail analysieren.
Und schließlich sollte all dies sowohl für die Oracle-Datenbank als auch für mySql funktionieren. Es gibt auch eine Reihe von Funktionen, die in der Dokumentation beschrieben werden.
Es ist möglich, dass ich ein anderes Fahrrad erfunden habe, aber ich habe gewissenhaft gesucht und keine für mich geeignete Lösung gefunden. Wenn Sie eine Bibliothek kennen, die diese Probleme löst, schreiben Sie bitte in die Kommentare.
Bevor ich direkt zu einer Untersuchung der Bibliothek selbst und zu Beispielen übergehe, sage ich, dass es nur das Wesentliche ohne detaillierte Erklärungen geben wird. Wenn Sie sich für die Funktionsweise des Hausarztes interessieren, können Sie sich die Dokumentation ansehen. Ich habe versucht, alles im Detail zu erklären.
Bibliotheksverbindung
Die Bibliothek kann über Composer installiert werden: composer require falbin/green-pig-dao
Dann müssen Sie eine Factory schreiben, über die Sie diese Bibliothek verwenden.
Wo Klasse
Mit dieser Klasse können Sie den Where-Teil der SQL-Abfrage beliebiger Komplexität zusammenstellen.
Atomarer Teil der Anfrage
Betrachten Sie den kleinsten atomaren Teil einer Abfrage. Es wird durch ein Array beschrieben: [, , ]
Beispiel: ['name', 'like', '%%']
- Das erste Element des Arrays ist nur eine Zeichenfolge, die ohne Änderungen in die SQL-Abfrage eingefügt wird. Daher können Sie SQL-Funktionen darin schreiben. Beispiel:
['LOWER(name)', 'like', '%%'] - Das zweite Element ist ebenfalls eine Zeichenfolge, die ohne Änderungen zwischen zwei Operanden in sql eingefügt wird. Es kann die folgenden Werte annehmen: =,>, <,> =, <=, <>, wie, nicht wie, zwischen, nicht zwischen, in, nicht in .
- Das dritte Element des Arrays kann entweder ein numerischer oder ein String-Typ sein. Wobei die Klasse den generierten Alias automatisch in die SQL-Abfrage einfügt.
- Array-Element mit SQL-Schlüssel. Manchmal ist es notwendig, dass der Wert ohne Änderungen in den SQL-Code eingefügt wird. Zum Beispiel, um Funktionen anzuwenden. Dies kann durch Angabe von 'sql' als Schlüssel (für das 3. Element) erreicht werden. Beispiel:
['LOWER(name)', 'like', 'sql' => "LOWER('$name')"] - Ein Array-Element mit dem Bindungsschlüssel ist ein Array zum Speichern von Bindungen. Das obige Beispiel ist aus Sicherheitsgründen falsch. Sie können keine Variablen in sql einfügen - es ist zu viel Injektion. In diesem Fall müssen Sie Aliase wie
['LOWER(name)', 'like', 'sql' => "LOWER(:name)", 'bind'=> ['name' => $name] ] selbst angeben: ['LOWER(name)', 'like', 'sql' => "LOWER(:name)", 'bind'=> ['name' => $name] ] - Der in-Operator kann folgendermaßen geschrieben werden:
['curse', 'not in', [1, 3, 5]] . Die Where-Klasse konvertiert einen solchen Eintrag in den folgenden SQL-Code: curse not in (:al_where_jCgWfr95kh, :al_where_mCqefr95kh, :al_where_jCfgfr9Gkh) - Die between-Anweisung kann folgendermaßen geschrieben werden:
['curse', ' between', 1, 5] . Die Where-Klasse konvertiert einen solchen Eintrag in den folgenden SQL-Code: curse between :al_where_Pi4CRr4xNn and :al_where_WiPPS4NKiG
Seien Sie jedoch vorsichtig, wenn das dritte und vierte Element des Arrays Zeichenfolgen sind, wird eine spezielle Logik angewendet. In diesem Fall wird angenommen, dass die Auswahl aus einem Datumsbereich stammt und daher die SQL-Funktion zum Umwandeln einer Zeichenfolge in ein Datum verwendet wird. Die Funktion zum Konvertieren in ein Datum (mySql und Oracle haben unterschiedliche) und die Parameter werden aus einer Reihe von Einstellungen übernommen (mehr in der Dokumentation). Das Array ['build_date', 'between', '01.01.2016', '01.01.2019'] wird build_date between TO_DATE(:al_where_fkD7nZg5lU, 'dd.mm.yyyy hh24:mi::ss') and TO_DATE(:al_where_LdyVRznPF8, 'dd.mm.yyyy hh24:mi::ss') in sql: build_date between TO_DATE(:al_where_fkD7nZg5lU, 'dd.mm.yyyy hh24:mi::ss') and TO_DATE(:al_where_LdyVRznPF8, 'dd.mm.yyyy hh24:mi::ss')
Komplizierte Abfragen
Erstellen wir eine Instanz der Klasse über die Factory: $wh = GP::where();
Um die logische Verbindung zwischen den "atomaren Teilen" der Anforderung linkAnd() , müssen Sie die Funktionen linkAnd() oder linkOr() verwenden. Ein Beispiel:
Bei Verwendung der Funktionen linkAnd / linkOr werden alle Daten in einer Instanz der Klasse Where - $ wh gespeichert. Außerdem werden alle in der Funktion angegebenen „atomaren Teile“ in Klammern gesetzt .
SQL jeder Komplexität kann durch drei Funktionen beschrieben werden: linkAnd(), linkOr(), getRaw() . Betrachten Sie ein Beispiel:
Die Where-Klasse verfügt über eine private Variable, die den Rohausdruck speichert. Die linkAnd() und linkOr() überschreiben diese Variable. Daher werden beim linkOr() eines logischen Ausdrucks die Methoden zusammengeschachtelt, und die Variable mit dem Rohausdruck enthält Daten, die von der zuletzt ausgeführten Methode stammen.
JOIN-Klasse
Join ist eine Klasse, die ein Join-Fragment von SQL-Code generiert. Erstellen wir eine Instanz der Klasse über die Factory: $jn = GP::leftJoin('coursework', 'student_id', 's.id') , wobei:
- Kursarbeit ist der Tisch, an dem wir teilnehmen werden.
- student_id - eine Spalte mit einem Fremdschlüssel aus der Kursarbeitstabelle .
- s.id - die Spalte der Tabelle, mit der der Join zusammen mit dem Alias der Tabelle geschrieben werden soll (in diesem Fall ist der Alias der Tabelle s).
Generiertes sql: left JOIN coursework coursework_joM9YuTTfW ON coursework_joM9YuTTfW.student_id = s.id
Beim Erstellen einer Instanz der Klasse haben wir bereits die Bedingung für das Verknüpfen von Tabellen beschrieben. Es kann jedoch erforderlich sein, die Bedingung zu klären und zu erweitern. Die Funktionen linkAnd / linkOr helfen Ihnen dabei: $jn->linkAnd(['semester_number', '>', 2])
Generiertes sql: inner JOIN coursework coursework_Nd1n5T7c0r ON coursework_Nd1n5T7c0r.student_id = s.id and (semester_number > :al_where_M1kEcHzZyy) coursework coursework_Nd1n5T7c0r inner JOIN coursework coursework_Nd1n5T7c0r ON coursework_Nd1n5T7c0r.student_id = s.id and (semester_number > :al_where_M1kEcHzZyy)
Wenn mehrere Tabellen verknüpft werden müssen, können Sie diese in einer Klasse kombinieren: CollectionJoin .
Klassenabfrage
Dies ist die Hauptklasse für die Arbeit mit der Datenbank, über die eine Auswahl, Aufzeichnung, Aktualisierung und Löschung von Daten erfolgt. Sie können auch bestimmte Daten verarbeiten, die aus der Datenbank stammen.
Betrachten Sie ein typisches Beispiel.
Erstellen wir eine Instanz der Klasse über die Factory: $qr = GP::query();
Jetzt werden wir die SQL-Vorlage festlegen, die für das gegebene Szenario erforderlichen Werte in die SQL-Vorlage einsetzen und sagen, dass wir einen Datensatz und insbesondere die Daten aus der Spalte average_mark erhalten möchten .
$rez = $qr->sql("select /*select*/ from student s inner join mark m on s.id = m.student_id inner join lesson l on l.id = m.lesson_id /*where*/ /*group*/") ->sqlPart('/*select*/', 's.name, avg(m.mark) average_mark', []) ->whereAnd('/*where*/', ['s.id', '=', 1]) ->sqlPart('/*group*/', 'group by s.name', []) ->one('average_mark');
Ergebnis: 3,16666666666666666666666666666666666667
Auswahl aus einer Datenbank mit verschachtelten Parametern
Am allermeisten hatte ich nicht die Möglichkeit, eine Auswahl aus der Datenbank in einer Baumansicht mit angehängten Eigenschaften zu erhalten. Daher hat die GP-Bibliothek eine solche Gelegenheit, und die Tiefe der Verschachtelung ist nicht begrenzt.
Am einfachsten lässt sich das Funktionsprinzip anhand eines Beispiels betrachten. Zur Berücksichtigung nehmen wir das folgende Datenbankschema:

Tabelleninhalt:
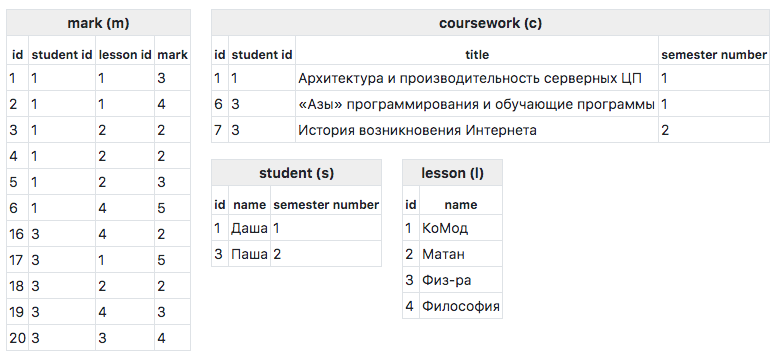
Wenn Sie eine Datenbank abfragen, möchten Sie häufig eine baumartige und keine flache Antwort erhalten. Zum Beispiel durch Ausführen dieser Abfrage:
SELECT s.id, s.name, c.id title_id, c.title FROM student s INNER JOIN coursework c ON c. student_id = s.id WHERE s.id = 3
Wir erhalten ein pauschales Ergebnis:
[ 0 => [ 'id' => 3, 'name' => '', 'title_id' => 6, 'title' => '«» ', ], 1=> [ 'id' => 3, 'name' => '', 'title_id' => 7, 'title' => ' ' ] ]
Mit GP erhalten Sie folgendes Ergebnis:
[ 3 => [ 'name' => '', 'courseworks' => [ 6 => ['title' => '«» '], 7 => ['title' => ' '] ] ] ]
Um dieses Ergebnis zu erzielen, müssen Sie der Funktion all ein Array mit Optionen übergeben (die Funktion gibt alle Abfragezeilen zurück):
all([ 'id'=> 'pk', 'name' => 'name', 'courseworks' => [ 'title_id' => 'pk', 'title' => 'title' ] ])
Das Array $option im Funktionsaggregator ( $option , $ rawData) und allen ( $options ) wird nach folgenden Regeln erstellt:
- Array-Schlüssel - Spaltennamen. Array-Elemente - neue Namen für Spalten, Sie können den alten Namen eingeben.
- Es gibt ein reserviertes Wort für Array-Werte -
pk . Die Daten werden nach dieser Spalte gruppiert (der Array-Schlüssel ist der Name der Spalte). - Auf jedem Level sollte es nur einen
pk . - Im aggregierten (resultierenden) Array werden die Werte aus der von
pk deklarierten Spalte als Schlüssel verwendet. - Wenn ein Teil der Spalten eine Ebene tiefer platziert werden muss, wird ein neuer, erfundener Name als Array-Schlüssel verwendet, und ein Array, das gemäß den oben beschriebenen Regeln erstellt wurde, wird als Wert verwendet.
Betrachten Sie ein komplexeres Beispiel. Nehmen wir an, wir müssen alle Schüler mit dem Namen ihrer Lehrveranstaltung und mit allen Noten in allen Fächern befragen. Wir möchten es nicht in flacher Form, sondern in baumartiger Form ohne Duplikate erhalten. Unten ist die gewünschte Abfrage an die Datenbank und das Ergebnis.
SELECT s.id student_id, s.name student_name, s.semester_number, c.id coursework_id, c.semester_number coursework_semester, c.title coursework_title, l.id lesson_id, l.name lesson, m.id mark_id, m.mark FROM student s LEFT JOIN coursework c ON c.student_id = s.id LEFT JOIN mark m ON m.student_id = s.id LEFT JOIN lesson l ON l.id = m.lesson_id ORDER BY s.id, c.id, l.id, m.id
Das Ergebnis passt nicht zu uns:
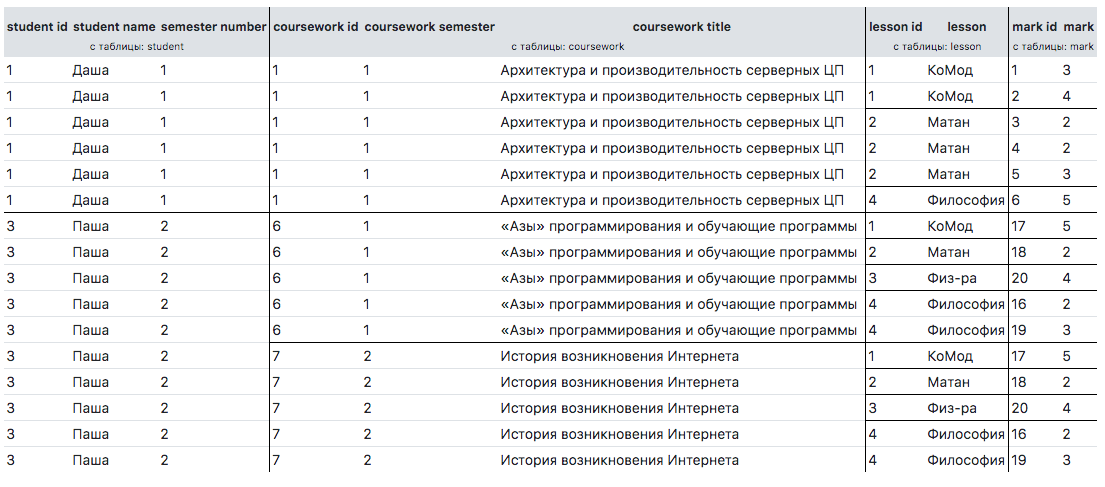
Um die Aufgabe zu erfüllen, müssen Sie das folgende $option Array schreiben:
$option = [ 'student_id' => 'pk', 'student_name' => 'name', 'courseworks' => [ 'coursework_semester' => 'pk', 'coursework_title' => 'title' ], 'lessons' => [ 'lesson_id' => 'pk', 'lesson' => 'lesson', 'marks' => [ 'mark_id' => 'pk', 'mark' => 'mark' ] ] ];
Datenbankabfrage:
Die aggregator kann jedes Array mit einer Struktur verarbeiten, die dem Ergebnis einer Datenbankabfrage ähnlich ist, und zwar gemäß den in $option beschriebenen Regeln.
Die Variable $result enthält folgende Daten:
[ 1 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => ' '], ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 1 => ['mark' => 3], 2 => ['mark' => 4] ] ], 2 => [ 'lesson' => '', 'marks' => [ 3 => ['mark' => 2], 4 => ['mark' => 2], 5 => ['mark' => 3] ] ], 4 => [ 'lesson' => '', 'marks' => [ 6 => ['mark' => 5] ] ] ] ], 3 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => '«» '], 2 => ['title' => ' '] ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 17 => ['mark' => 5] ] ], 2 => [ 'lesson' => '', 'marks' => [ 18 => ['mark' => 2] ] ], 3 => [ 'lesson' => '-', 'marks' => [ 20 => ['mark' => 4] ] ], 4 => [ 'lesson' => '', 'marks' => [ 16 => ['mark' => 2], 19 => ['mark' => 3] ] ], ] ] ]
Übrigens werden bei Paginierung mit aggregierter Abfrage nur die obersten, grundlegendsten Daten berücksichtigt. Im obigen Beispiel gibt es nur 2 Zeilen für die Paginierung.
Mehrfache Vereinigung mit sich selbst im Namen der Suche
Wie ich bereits geschrieben habe, besteht die Hauptaufgabe meiner Bibliothek darin, die Generierung der Where-Parts für ausgewählte Abfragen zu vereinfachen. In welchem Fall müssen wir möglicherweise wiederholt dieselbe Tabelle für die Where-Abfrage verbinden? Eine der Optionen ist, wenn wir ein bestimmtes Produkt haben, dessen Eigenschaften nicht im Voraus bekannt sind und das von den Benutzern hinzugefügt wird, und wir die Möglichkeit haben müssen, anhand dieser dynamischen Eigenschaften nach Produkten zu suchen. Am einfachsten lässt sich das anhand eines vereinfachten Beispiels erklären.
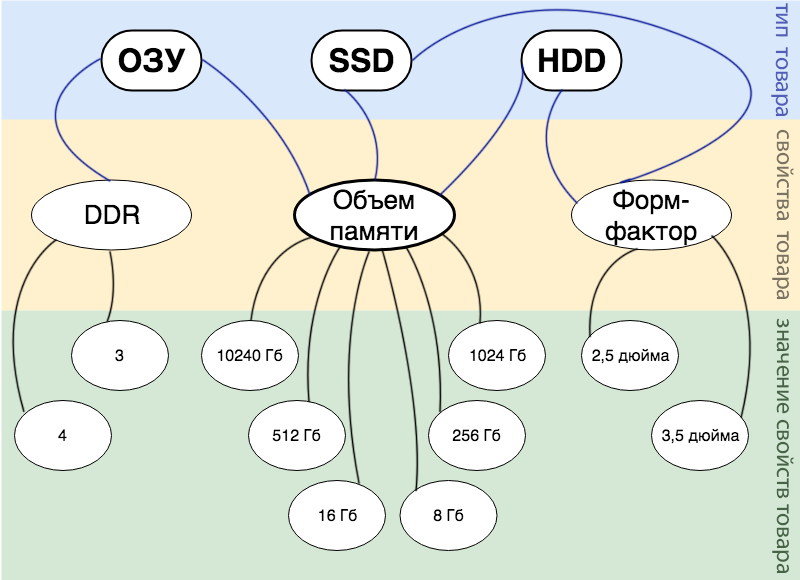
Angenommen, wir haben einen Online-Shop, der Computerkomponenten verkauft, und wir haben kein genaues Sortiment, und wir werden regelmäßig die eine oder andere Komponente kaufen. Wir möchten jedoch alle unsere Produkte als eine Einheit beschreiben und nach allen Produkten suchen. Also, welche Entitäten können aus Sicht der Geschäftslogik unterschieden werden:
- Produkt. Die wichtigste Einheit, um die sich alles dreht.
- Art des Produktes. Dies kann als Stammeigenschaft für alle anderen Produkteigenschaften dargestellt werden. In unserem kleinen Laden gibt es zum Beispiel nur: RAM, SSD und HDD.
- Produkteigenschaften. In unserer Implementierung kann jede Eigenschaft auf jede Art von Produkt angewendet werden, die Wahl bleibt dem Manager überlassen. In unserem Geschäft haben Manager nur drei Eigenschaften erstellt: Speichergröße, Formfaktor und DDR.
- Der Wert der Ware. Der Wert, den der Käufer bei der Suche antreibt.
Die gesamte oben beschriebene Geschäftslogik spiegelt sich detailliert in der folgenden Abbildung wider.
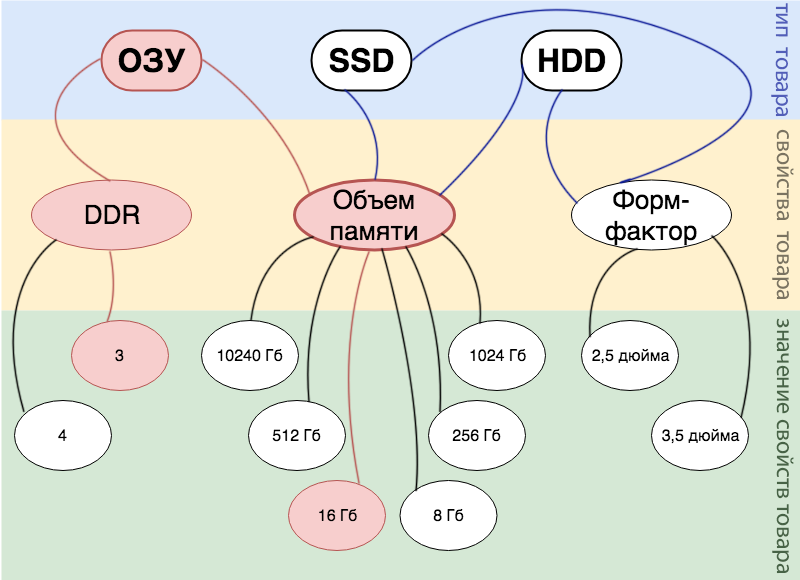
Zum Beispiel haben wir ein Produkt: 16 GB DDR 3 RAM . Im Diagramm kann dies wie folgt dargestellt werden:
Die Struktur und die Daten der Datenbank sind in der folgenden Abbildung deutlich sichtbar:
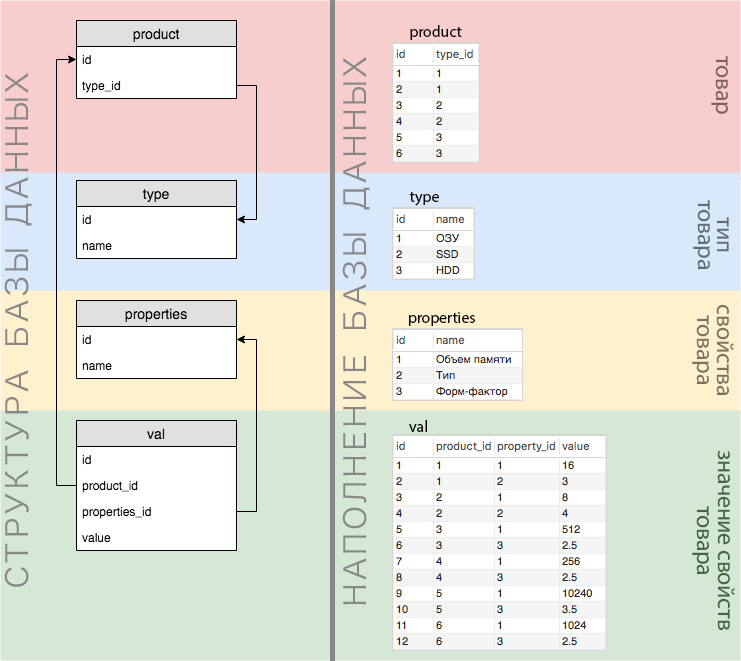
Wie aus dem Diagramm hervorgeht, werden alle Werte aller Eigenschaften in einer Wertetabelle gespeichert (in unserer vereinfachten Version haben übrigens alle Eigenschaften numerische Werte). Wenn wir also gleichzeitig mit einer UND-Verknüpfung nach mehreren Eigenschaften suchen möchten, erhalten wir eine leere Auswahl.
Ein Käufer sucht beispielsweise nach Produkten, die für eine solche Anforderung geeignet sind: Die Speicherkapazität sollte mehr als 10 GB betragen, und der Formfaktor sollte 2,5 Zoll betragen . Wenn wir wie unten gezeigt sql schreiben, erhalten wir eine leere Auswahl:
select * from product p inner join val v on v.product_id = p.id where (v.property_id = 1 and v.value > 10) AND (v.property_id = 3 and v.value = 2.5)
Da die Werte aller Eigenschaften in einer Tabelle gespeichert sind, müssen Sie für jede Eigenschaft, die durchsucht werden soll, den Tabellenwert verknüpfen, um nach mehreren Eigenschaften zu suchen. Es gibt jedoch eine Nuance: Join verbindet Tabellen "horizontal" (bis auf das Wort "Union" alle "vertikal"). Das folgende Beispiel zeigt:

Dieses Ergebnis passt nicht zu uns, wir möchten alle Werte in einer Spalte sehen. Verbinden Sie dazu die Wertetabelle 1-mal häufiger als die Eigenschaften, mit denen die Suche durchgeführt wird.

Wir sind kurz davor, eine SQL-Abfrage automatisch zu generieren. Schauen wir uns die Funktion an
whereWithJoin ($aliasJoin, $options, $aliasWhere, $where) , das die ganze Arbeit whereWithJoin ($aliasJoin, $options, $aliasWhere, $where) :
- $ aliasJoin - Ein Alias in der Basisvorlage , anstelle dessen der SQL-Teil mit Joins ersetzt wird.
- $ options - Ein Array mit Beschreibungen der Regeln zum Generieren des Join-Teils.
- $ aliasWhere - Ein Alias in der Basisvorlage, der stattdessen den where-SQL-Teil ersetzt.
- $ where ist eine Instanz der Where-Klasse.
Schauen wir uns ein Beispiel an: whereWithJoin('/*join*/', $options, '/*where*/', $wh) .
Erstellen Sie zunächst die Variable $ options : $options = ['v' => ['val', 'product_id', 'p.id']];
v ist der Alias der Tabelle. Wenn dieser Alias in $ wh gefunden wird , wird eine neue Wertetabelle durch einen Join verbunden (wobei product_id der Fremdschlüssel der Wertetabelle und p.id der Primärschlüssel für die Tabelle mit dem Alias p ist ), ein neuer Alias und dieser Alias werden dafür generiert wird v in wo ersetzen.
$ wh ist eine Instanz der Where-Klasse. Wir bilden die gleiche Anforderung: Der Speicher sollte mehr als 10 GB und der Formfaktor sollte 2,5 Zoll betragen.
$wh->linkAnd([ $wh->linkAnd([ ['v.property_id', '=', 1], ['v.value', '>', 10] ])->getRaw(),
Wenn Sie eine whereWithJoin() Anfrage erstellen, müssen Sie das Teil mit der Eigenschaft id und seinem Wert in Klammern whereWithJoin() Funktion whereWithJoin() dass der Tabellenalias in diesem Teil identisch ist.
$qr->sql("select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id /*join*/ /*where*/") ->whereWithJoin('/*join*/', $options, '/*where*/', $wh)
Wir sehen uns die generierte SQL-, Bindungs- und Abfrageausführungszeit an: $qr->debugInfo() :
[ [ 'type' => 'info', 'sql' => 'select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id inner JOIN val val_mIQWpnHhdQ ON val_mIQWpnHhdQ.product_id = p.id inner JOIN val val_J0uveMpwEM ON val_J0uveMpwEM.product_id = p.id WHERE ( val_mIQWpnHhdQ.property_id = :al_where_leV5QlmOZN and val_mIQWpnHhdQ.value > :al_where_ycleYAswIw ) and ( val_J0uveMpwEM.property_id = :al_where_dinxDraTOE and val_J0uveMpwEM.value = :al_where_wZJhUqs74i )', 'binds' => [ 'al_where_leV5QlmOZN' => 1, 'al_where_ycleYAswIw' => 10, 'al_where_dinxDraTOE' => 3, 'al_where_wZJhUqs74i' => 2.5 ], 'timeQuery' => 0.0384588241577 ] ]
$qr->rawData() :
[ [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 5, 'value' => 512 ], [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 6, 'value' => 2.5 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 7, 'value' => 256 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 8, 'value' => 2.5 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 11, 'value' => 1024 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 12, 'value' => 2.5 ] ]
$qr->aggregateData() :
[ 3 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 5 => ['val' => 512] ] ], 3 => [ 'name' => '-', 'values' => [ 6 => ['val' => 2.5] ] ] ] ], 4 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 7 => ['val' => 256] ] ], 3 => [ 'name' => '-', 'values' => [ 8 => ['val' => 2.5] ] ] ] ], 6 => [ 'type' => 'HDD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 11 => ['val' => 1024] ] ], 3 => [ 'name' => '-', 'values' => [ 12 => ['val' => 2.5] ] ] ] ] ]
, , whereWithJoin() , .
whereWithJoin() , , n , m . n m 1 id . , AND .
GitHub .