Einleitung
Das Verständnis, wie der Klassifikator den anfänglichen mehrdimensionalen Raum von Attributen in viele Zielklassen aufteilt, ist ein wichtiger Schritt zur Analyse eines Klassifizierungsproblems und zur Bewertung der durch maschinelles Lernen erzielten Lösung.
Moderne Ansätze zur Visualisierung von Entscheidungen von Klassifikatoren verwenden hauptsächlich entweder Streudiagramme, die nur Projektionen der ursprünglichen Trainingsmuster anzeigen können, aber nicht explizit die tatsächlichen Grenzen der Entscheidungsfindung darstellen, oder verwenden die interne Struktur des Klassifikators (z. B. kNN, SVM, Logistic Regression), für den es leicht ist, eine geometrische zu konstruieren Interpretation. Diese Methode eignet sich nicht zur Visualisierung beispielsweise eines neuronalen Netzklassifikators.
Der Artikel "Bildbasierte Visualisierung von Entscheidungsgrenzen von Klassifikatoren" (Rodrigues et al., 2018) schlägt eine effektive, schöne und ziemlich einfache alternative Methode zur Visualisierung von Klassifikatorlösungen vor, die die obigen Nachteile nicht aufweist. Das Verfahren ist nämlich für Klassifikatoren jeglicher Art geeignet und bildet die Grenzen der Entscheidungsfindung unter Verwendung von Bildern mit einer beliebigen Abtastrate.
Dieser Beitrag gibt einen kurzen Überblick über die wichtigsten Ideen und Ergebnisse des Originalartikels.
Methodenbeschreibung
Grundlage der Methode ist das Reverse Sampling (engl. Upsampling) aus der Bildebene  Dies wird durch eine Reihe von Pixeln im Merkmalsraum dargestellt
Dies wird durch eine Reihe von Pixeln im Merkmalsraum dargestellt  .
.
Die Methode erfordert zwei Zuordnungen  - direkte Projektion vom Merkmalsraum zur Bildebene und umgekehrt
- direkte Projektion vom Merkmalsraum zur Bildebene und umgekehrt  . Als solche Abbildungen werden LAMP (Joia et al. 2011) bzw. iLAMP (Amorim et al. 2012) verwendet.
. Als solche Abbildungen werden LAMP (Joia et al. 2011) bzw. iLAMP (Amorim et al. 2012) verwendet.
Gebäude
Um ein Bild zu erstellen, müssen Sie jedem Pixel eine Farbe zuweisen. Dafür für jedes Pixel  werde finden
werde finden  zeigt aus dem Quellhyperspace wo
zeigt aus dem Quellhyperspace wo  - Ein vom Benutzer angegebener Parameter. Lass das Pixel hat schon
- Ein vom Benutzer angegebener Parameter. Lass das Pixel hat schon  echte Prototypen aus dem Trainingsset. Dann eben wählen
echte Prototypen aus dem Trainingsset. Dann eben wählen  die verbleibenden Punkte von der Pixeloberfläche und finden Sie den Prototyp für sie durch die Rückprojektion
die verbleibenden Punkte von der Pixeloberfläche und finden Sie den Prototyp für sie durch die Rückprojektion  . Somit wird die Farbe jedes Pixels durch mindestens bestimmt Punkte des Quellraums, und das gesamte Bild wird übermalt.
. Somit wird die Farbe jedes Pixels durch mindestens bestimmt Punkte des Quellraums, und das gesamte Bild wird übermalt.
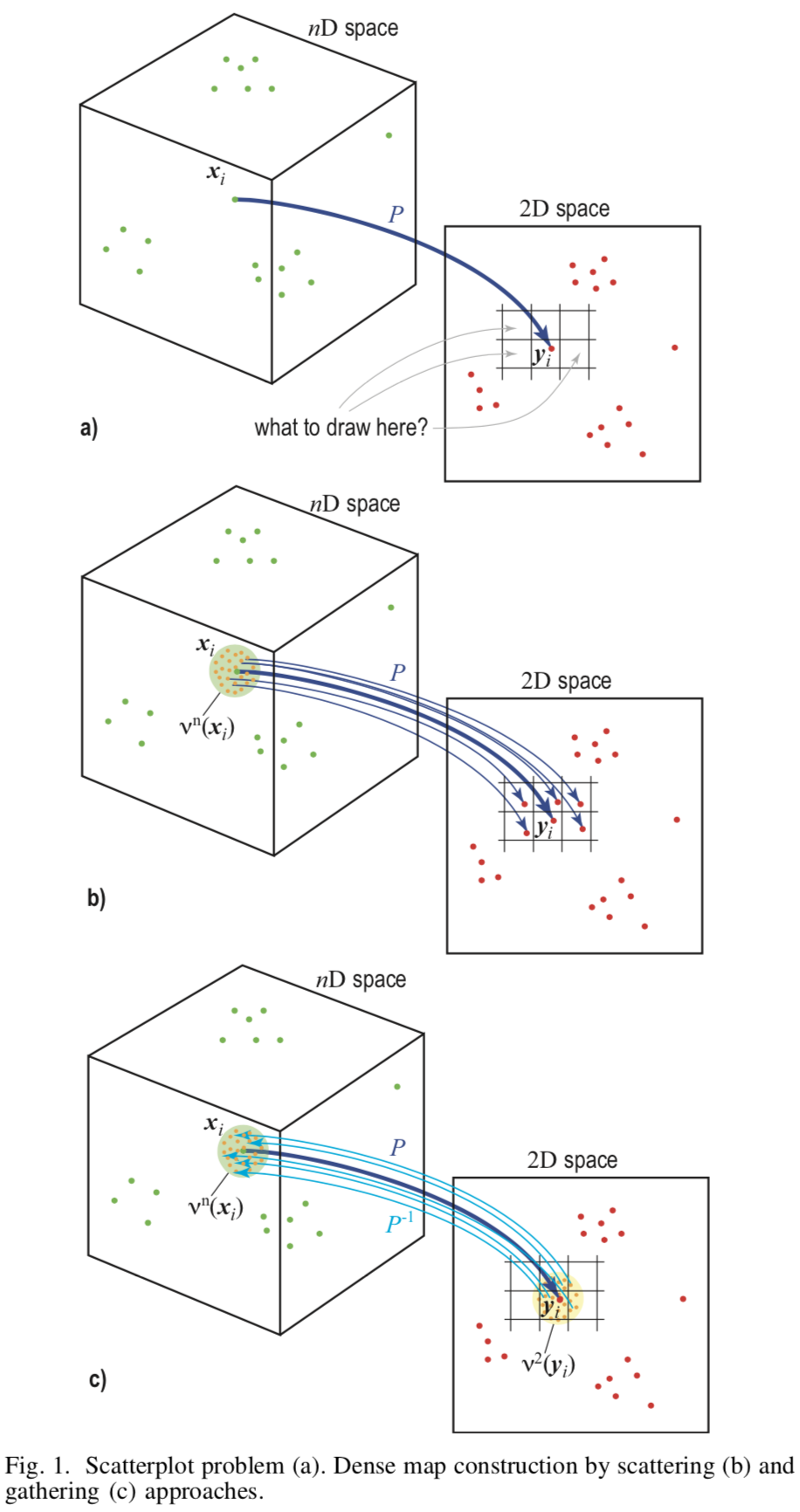
[Abb.1] Schematische Darstellung verschiedener Ansätze
Farbdefinition
Farbe  jedes Pixel mit Stimmenmehrheit für Klassenlabels der entsprechenden Vorbilder bestimmt.
jedes Pixel mit Stimmenmehrheit für Klassenlabels der entsprechenden Vorbilder bestimmt.
![d (y) = \ text {argmax} _ {k \ in C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]](https://habrastorage.org/getpro/habr/post_images/469/c8d/c50/469c8dc5021ee22be2190d80d4a8f9bd.svg)
wo  - viele von allen Klassen,
- viele von allen Klassen,  - Klassifikator.
- Klassifikator.
Jeder Klasse wird ein Ton zugeordnet  - Wenn die Projektion Punkte aus dem realen Sample und einen leicht veränderten Ton aufweist
- Wenn die Projektion Punkte aus dem realen Sample und einen leicht veränderten Ton aufweist  für Pixel, in denen es nur synthetische Punkte gibt.
für Pixel, in denen es nur synthetische Punkte gibt.
Verwirrung
Pixelmischung definieren (aus englischer Verwirrung)  - als Verhältnis der Anzahl der Etiketten der vorherrschenden Klasse zur Gesamtzahl der inversen Pixelbilder :
- als Verhältnis der Anzahl der Etiketten der vorherrschenden Klasse zur Gesamtzahl der inversen Pixelbilder :
![c (y) = \ frac {\ max_ {k \ in C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]} {| y |}](https://habrastorage.org/getpro/habr/post_images/62d/5e7/47f/62d5e747f958e587200665af682cbae9.svg)
Hoher Wert gibt die Konsistenz des Klassifikators an, während ein niedriger Wert eine Annäherung an die Teilungsgrenze signalisiert. Mischungsinformationen, die in Pixelsättigung codiert sind  - Je höher die Konsistenz, desto höher die Sättigung.
- Je höher die Konsistenz, desto höher die Sättigung.
Dichte
Obwohl ein Minimum generiert wurde Vorabbildpunkte für jedes Pixel, es kann Pixel geben, für die es viel mehr reale Punkte aus dem Trainingssatz gibt. Solche Pixel sollten beim Rendern berücksichtigt werden. Geben Sie dazu die Pixeldichte ein  als die Anzahl seiner inversen Bildpunkte aus . Man könnte diese Dichte direkt verwenden, um die Helligkeit eines Pixels zu bestimmen
als die Anzahl seiner inversen Bildpunkte aus . Man könnte diese Dichte direkt verwenden, um die Helligkeit eines Pixels zu bestimmen  , aber die Autoren des Artikels weisen darauf hin, dass dies nicht das gewünschte Ergebnis liefert, weil Einige Töne sind offensichtlich dunkler als andere. Daher wird durch einen normalisierten Dichteparameter eine ausgefeiltere Einstellung zur gleichen Zeit der Sättigung und Helligkeit verwendet.
, aber die Autoren des Artikels weisen darauf hin, dass dies nicht das gewünschte Ergebnis liefert, weil Einige Töne sind offensichtlich dunkler als andere. Daher wird durch einen normalisierten Dichteparameter eine ausgefeiltere Einstellung zur gleichen Zeit der Sättigung und Helligkeit verwendet.

Dann wenn ![\ hat {\ rho} \ in [0, 0.5]](https://habrastorage.org/getpro/habr/post_images/5f3/8f9/0c5/5f38f90c57fe8c26092278e6a36b55c7.svg) - Die Helligkeit hängt linear von den Parametern ab
- Die Helligkeit hängt linear von den Parametern ab ![[V_ {min} = 0,1, V_ {max} = 1]](https://habrastorage.org/getpro/habr/post_images/b1e/ef5/e22/b1eef5e220c553d3c437ee6ddb9f4f08.svg) . Bei
. Bei ![\ hat {\ rho} \ in [0.5, 1]](https://habrastorage.org/getpro/habr/post_images/4cc/04d/a79/4cc04da7997da643ef6671babba1ec57.svg) beginnt linear Sättigung aus zu wachsen
beginnt linear Sättigung aus zu wachsen  vorher
vorher  .
.
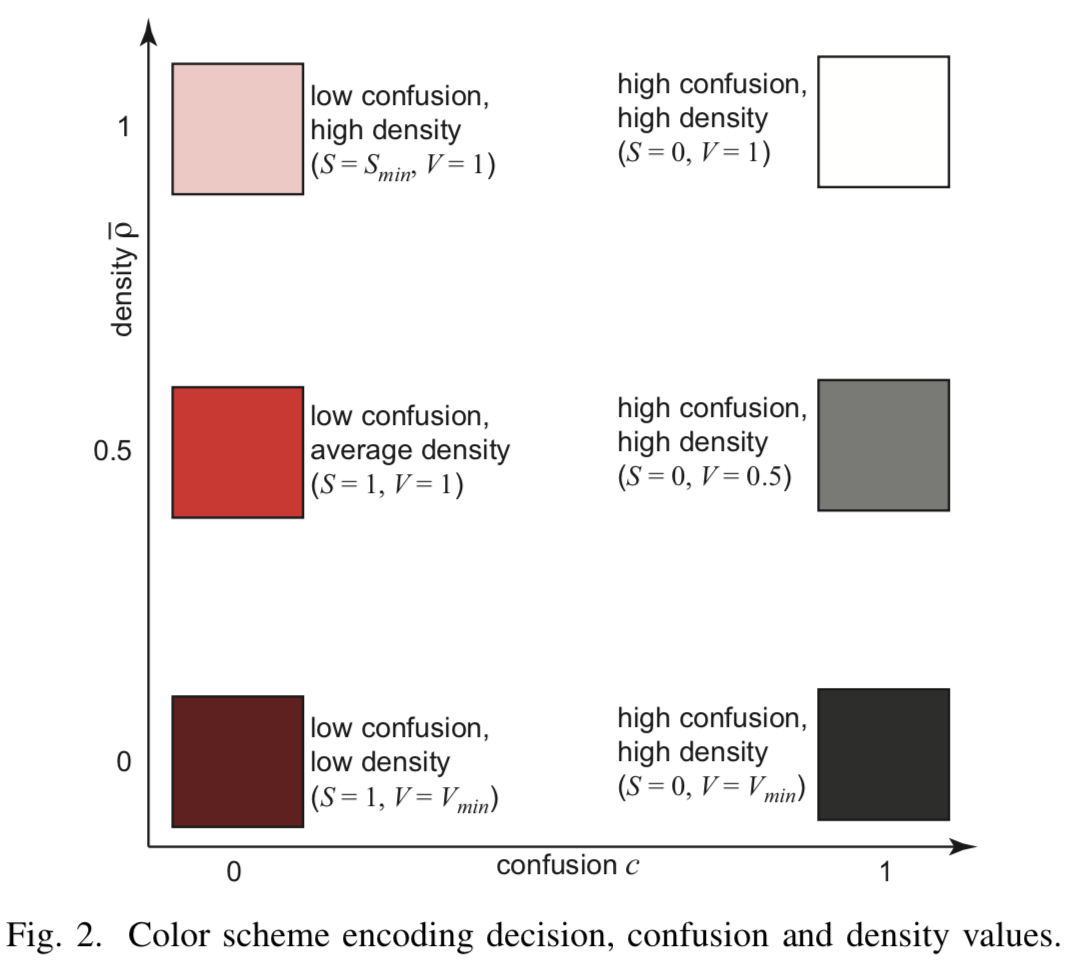
[Abb.2] Farbcodierung
Experimente und Ergebnisse
Für die Experimente wurden die Probleme der binären Klassifizierung am Satz von MNIST-Digitalbildern und der Multiklassifizierung am Bildsegmentierungsdatensatz, der 2310 Bilder enthält, die in 7 Klassen unterteilt sind, gelöst. Es gibt 19 Attribute für jedes Bild.
Bilderzeugungsergebnisse mit verschiedenen Auflösungseinstellungen  und die minimale Anzahl von Prototypen für den binären Klassifikator LogisticRegression on MNIST sind in Abbildung [3] dargestellt. Klassen werden durch eine gerade Linie mit hoher Genauigkeit getrennt und der Visualisierungsalgorithmus leistet hervorragende Arbeit. Mit zunehmender Auflösung lösen sich die Wolken der Quellpunkte unter den vielen erzeugten Punkten fast vollständig auf.
und die minimale Anzahl von Prototypen für den binären Klassifikator LogisticRegression on MNIST sind in Abbildung [3] dargestellt. Klassen werden durch eine gerade Linie mit hoher Genauigkeit getrennt und der Visualisierungsalgorithmus leistet hervorragende Arbeit. Mit zunehmender Auflösung lösen sich die Wolken der Quellpunkte unter den vielen erzeugten Punkten fast vollständig auf.
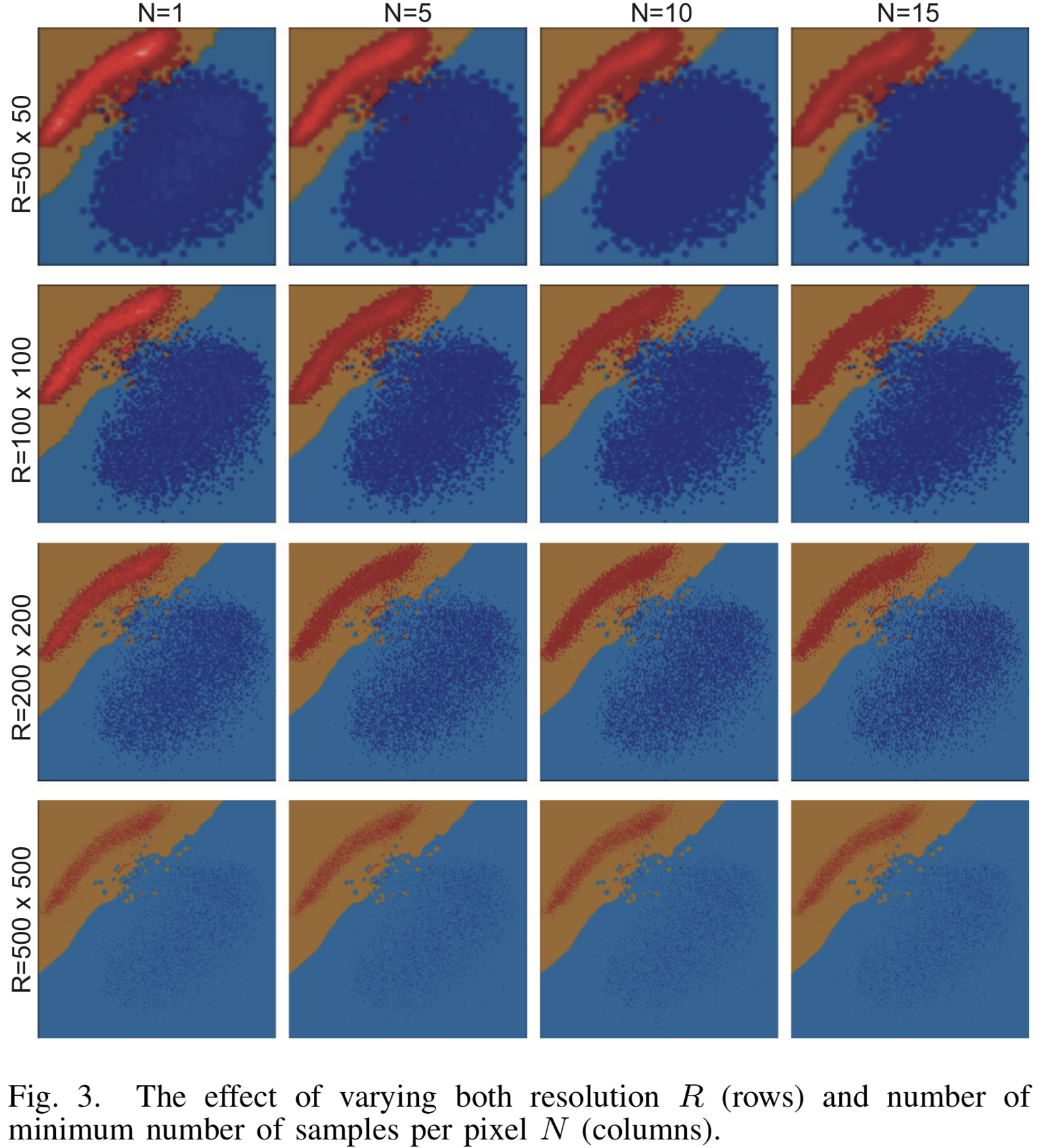
[Abb. 3] Das Visualisierungsergebnis für verschiedene Auflösungsparameter und die minimale Anzahl von Proben N für den LogisticRegression-Klassifizierer
Visualisierung wann  für drei verschiedene Klassifikatoren zur Mehrfachklassifizierung in der Abbildung [4]. Die Projektionen der Startpunkte sind stark gemischt und es ist nicht möglich, explizite Trenngrenzen an den Stellen zu konstruieren, an denen sich die Projektionen der Testfälle ansammeln. Abgesehen vom Hauptcluster wurden jedoch explizite Klassengrenzen erhalten, über die in normalen Projektionen keine Informationen angezeigt werden, sondern die nur mit Hilfe von synthetischen Punkten erhalten werden.
für drei verschiedene Klassifikatoren zur Mehrfachklassifizierung in der Abbildung [4]. Die Projektionen der Startpunkte sind stark gemischt und es ist nicht möglich, explizite Trenngrenzen an den Stellen zu konstruieren, an denen sich die Projektionen der Testfälle ansammeln. Abgesehen vom Hauptcluster wurden jedoch explizite Klassengrenzen erhalten, über die in normalen Projektionen keine Informationen angezeigt werden, sondern die nur mit Hilfe von synthetischen Punkten erhalten werden.
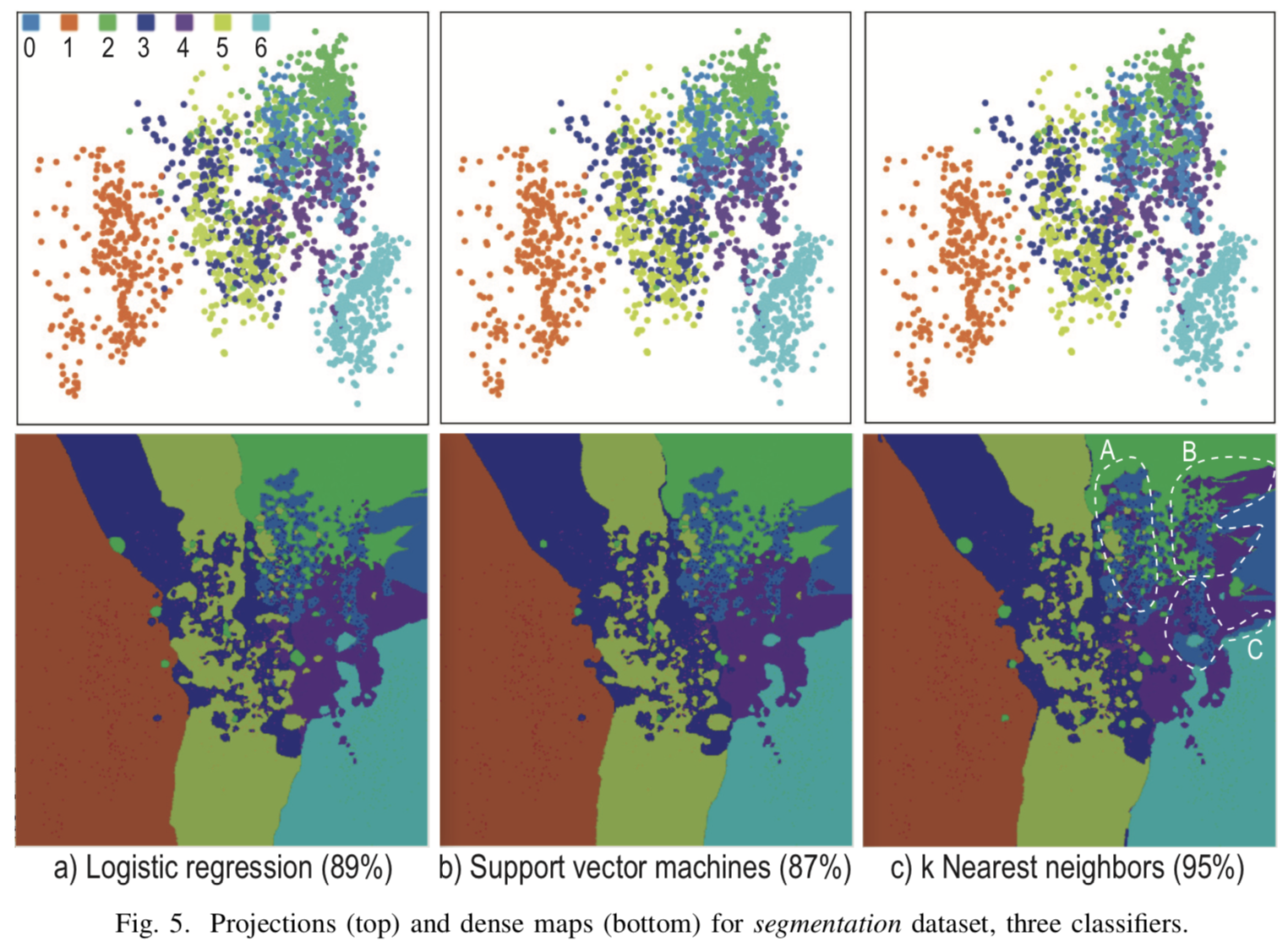
[Abb. 4] Das Ergebnis der Visualisierung von drei verschiedenen Klassifikatoren für k = 7, R = 500x500, N = 5
Fazit
Die Visualisierung von Klassengrenzen kann zur Erstellung und Fehlerbehebung eines entscheidenden Algorithmus, zur Auswahl von Hyperparametern, zur Bekämpfung von Umschulungen und zur Darstellung und Analyse der Ergebnisse verwendet werden.
Die von den Autoren des Originalartikels beschriebene Methode kann für alle Klassifizierungsprobleme verwendet werden, bei denen die Daten als ein Satz von Zeichen einer festen Dimension dargestellt werden können. Im Gegensatz zu anderen Visualisierungsalgorithmen kann dieser Ansatz für beliebige komplexe Klassifikatoren und für Datensätze mit einer beliebigen Anzahl von Beispielen verwendet werden, auch mit einem sehr kleinen, weil auch mit kleinen Der Algorithmus arbeitet stabil, ohne an Qualität zu verlieren.