Hallo allerseits!
Möglicherweise kennen Sie bereits die Initiative "Maschinelles Lernen für das Gemeinwohl" (# ml4sg) der Open Data Science-Community. Enthusiasten nutzen in diesem Rahmen Methoden des maschinellen Lernens, um gesellschaftlich bedeutsame Probleme kostenlos zu lösen. Wir, das Lacmus-Projektteam (#proj_rescuer_la), sind mit der Implementierung moderner Deep Learning-Lösungen beschäftigt, um Menschen zu finden, die sich außerhalb des besiedelten Gebiets verlaufen haben: im Wald, auf dem Feld usw.

Nach groben Schätzungen verschwinden in Russland jedes Jahr mehr als einhunderttausend Menschen. Der greifbare Teil von ihnen sind Menschen, die sich weit von der menschlichen Behausung entfernt haben. Glücklicherweise werden einige der Verlorenen von ihnen selbst ausgewählt, und freiwillige Such- und Rettungsteams werden mobilisiert, um anderen zu helfen. Die berühmteste dieser Art ist vielleicht Lisa Alert, aber ich möchte darauf hinweisen, dass er nicht der einzige ist.
Die hauptsächlichen Suchmethoden im 21. Jahrhundert sind derzeit das Kämmen der Umgebung zu Fuß mit technischen Mitteln, die oft nicht komplizierter sind als eine Sirene oder ein summender Leuchtturm. Das Thema ist natürlich relevant und aktuell, und es gibt Anlass für viele Ideen, den wissenschaftlichen und technologischen Fortschritt bei der Suche nach Erfolgen zu nutzen. Einige von ihnen werden sogar in Form von Prototypen ausgeführt und bei speziell organisierten Wettbewerben getestet. Aber der Wald ist der Wald, und die tatsächlichen Suchbedingungen in Verbindung mit den begrenzten materiellen Ressourcen erschweren dieses Problem und sind immer noch weit von einer vollständigen Lösung entfernt.
In letzter Zeit verwenden Retter zunehmend unbemannte Luftfahrzeuge (UAVs), um große Gebiete des Territoriums zu überwachen und das Gelände aus einer Höhe von 40-50 m zu fotografieren. Mit einem Such- und Rettungsvorgang werden mehrere tausend Fotos erhalten, die Freiwillige bisher manuell durchsehen. Es ist klar, dass eine solche Verarbeitung langwierig und ineffizient ist. Nach zwei Stunden solcher Arbeit werden die Freiwilligen müde und können die Suche nicht fortsetzen, und schließlich hängt die Gesundheit und das Leben der Menschen von ihrer Geschwindigkeit ab.
Zusammen mit den Such- und Rettungsteams entwickeln wir ein Programm zur Suche nach vermissten Personen in Bildern, die mit UAVs aufgenommen wurden. Als Spezialisten für maschinelles Lernen bemühen wir uns, die Suche automatisch und schnell durchzuführen.

Unterschiede zu ähnlichen Lösungen
Es wäre unfair zu sagen, dass Lacmus das einzige Projekt ist, das in dieser Richtung entwickelt wird. Es scheint jedoch, dass sich nur wenige Menschen in enger Zusammenarbeit mit Rettungsteams entwickeln und sich auf ihre dringenden Bedürfnisse und Fähigkeiten konzentrieren. Vor einiger Zeit fand der Odyssey-Wettbewerb statt, bei dem verschiedene Teams an der Entwicklung der besten Lösung für die Suche und Rettung von Menschen, einschließlich der Verwendung von UAVs, teilnahmen. In der Anfangsphase der Entwicklung nahmen wir an diesem Wettbewerb nicht als Teilnehmer, sondern als Beobachter teil. Wenn ich die Wettbewerbsergebnisse, Informationen über ähnliche Projekte und unsere Erfahrung in der Kommunikation mit Teams wie Lisa Alert, Owl, Extreme vergleiche, möchte ich auf die Probleme eingehen, die vielen Analoga inhärent sind:
- Die Kosten für die Implementierung. Einige Teams des Odyssey-Wettbewerbs entwickeln ihre eigenen innovativen Drohnen und UAVs. Sie müssen jedoch verstehen, dass PSO in Russland in der Regel gemeinnützig betrieben wird und die Ausstattung von Drohnenbetreibern mit Maschinen im Wert von mehr als 1.000.000 Rubel zu teuer ist. Darüber hinaus ist es nicht genug, nur ein Flugzeug zu produzieren, es ist notwendig, seine Wartung zu etablieren. Für kleine Unternehmen ist es schwierig, Lösungen für das gleiche Geld wie für die harten chinesischen Wettbewerber anzubieten.
- Der kommerzielle Fokus vieler Lösungen. An Geschäftsprojekten ist nichts auszusetzen, aber die Suche nach Menschen, die sich im Wald verlaufen haben, ist eine ziemlich spezifische Aufgabe, in die nicht jede kommerzielle Entwicklung integriert werden kann. Sie können dort eine wunderbare Drohne bauen und ein Neuron anbringen, das Pflanzen erkennt, aber ein solches Projekt ist wahrscheinlich nicht nützlich, um Menschen im Wald durch freiwillige Suchteams zu finden: Hier brauchen Sie die billigste, aber effektive Lösung. Teure Mehrkanal-Kameras sind hier nicht geeignet. Nur RGB, nur Hardcore. Aus den gleichen Gründen verschwinden auch Wärmebildkameras, deren billige Modelle eine sehr niedrige Auflösung haben. (Und im Allgemeinen sind Wärmebildkameras hier unwirksam, weil eine im Wald gefrorene Person zu wenig Wärme abgibt.)
- Die in den bekannten Lösungen verwendeten beliebten neuronalen Netzwerkarchitekturen - YOLO, SSD, VGG - haben gute Qualitätsmetriken für öffentliche Datensätze wie ImageNet, funktionieren jedoch nicht gut für Bilder in unserem eher spezifischen Domänenbereich. (Über die Wahl der neuronalen Netzwerkarchitektur, bewährte Optionen und Funktionen, die am Ende verwendet werden - siehe unten).
- Fast niemand nutzt die Möglichkeiten, um Modelle für Inferenzen zu optimieren. In Suchbereichen besteht häufig keine Internetverbindung, sodass Sie die empfangenen Bilder lokal verarbeiten müssen. Die meisten Retter verwenden Laptops mit oder ohne GPUs mit geringem Stromverbrauch, auf denen neuronale Netze auf herkömmlichen CPUs ausgeführt werden. Es ist leicht zu berechnen, dass 1000 Bilder in etwa 3 Stunden verarbeitet werden, wenn durchschnittlich 10 Sekunden für die Verarbeitung eines einzelnen Bildes aufgewendet werden. Hier können wir sagen, dass jede Sekunde wichtig ist.
- Geschlossenheit bestehender Entwicklungen. Alle uns bekannten Lösungen sind geschlossen und geschützt. Aber das Problem ist zu komplex, um von einer kleinen Handvoll Menschen gelöst zu werden, und nicht von allen, die bereit sind, zu helfen. Aus diesem Grund entwickeln wir eine vollständig Open Source-Lösung: Es ist seltsam zu glauben, dass ein Thema, das so viele Freiwillige anzieht, die „auf dem Feld“ arbeiten, für IT-Spezialisten nicht gleichermaßen interessant sein wird.
- Fehlende Vertriebsfreiheit. Freiwillige gemeinnützige Organisationen sind häufig nicht zentralisiert, Arbeitsansätze und Anwendungen werden von Hand zu Hand übertragen, Software mit lizenzierten Kopien funktioniert hier nicht. Deshalb haben wir uns unter anderem für eine Open Source- und Open Distribution-Strategie entschieden, damit jeder unsere Lösung herunterladen und nutzen kann. Wir sind für Open Science und Open Source!
Datenaufbereitung
Es scheint, dass, wenn jede Suchoperation unter Verwendung von UAVs Tausende von Fotos bringt, das Array der gesammelten Daten riesig sein sollte - nehmen und trainieren. Nicht alles erwies sich als so einfach, weil:
- Es gibt keinen zentralen Speicher für markierte Daten. Bilder, die während des Suchvorgangs aufgenommen wurden, werden in Zukunft nicht mehr verwendet oder verarbeitet.
- Die erhaltenen Daten sind sehr unausgeglichen. In einer Aufnahme mit der gefundenen Person befinden sich mehrere tausend „leere“ Fotos. Da die Informationen zu den gescannten Bildern nirgendwo aufgezeichnet werden, muss ein großer Teil der Arbeit ein zweites Mal erledigt werden, und zwar durch die Bemühungen eines kleinen Teams, das keine „geschulten Augen“ hat.
- Jedes Bild für sich ist auch „unausgeglichen“: Die gewünschte Person nimmt einen winzigen Bruchteil des gesamten Bildbereichs ein. Offensichtlich sollte ein gutes neuronales Netzwerk nicht nur sagen können, dass eine Person ihrer Meinung nach im Bild vorhanden ist - es sollte einen bestimmten Ort umkreisen (d. H. Die Aufgabe des Erfassens von Objekten, nicht des Klassifizierens von Bildern). Andernfalls wird der Bediener zusätzliche Zeit und Energie aufwenden, um es zu betrachten, und das gewünschte Foto wird möglicherweise fälschlicherweise abgelehnt. Dazu muss das neuronale Netz jedoch aus den markierten Daten in Fotografien lernen, wo das gewünschte Objekt mit einer speziellen Software markiert wird. Niemand wird dies während eines Suchvorgangs tun - nicht vorher.
- Die Statistiken über die Posen, in denen sich die Personen befanden, die Jahreszeit, die Art des Geländes und andere Merkmale der Bilder werden nicht berücksichtigt. Solche Daten wären sehr nützlich, um "synthetische" Trainingsbilder mit inszenierten Fotografien, Bildbearbeitungsprogrammen oder generativen Modellen zu erstellen - aber um all dies zu nutzen, müssen Sie verstehen, wie ein Foto mit einer wirklich verlorenen Person aussieht. Bei der Rekonstruktion solcher Aufnahmen muss man sich nun auf die subjektive Erfahrung von Rettungsexperten verlassen.
- Neben technischen Schwierigkeiten sind rechtliche Hindernisse möglich, die das Eigentum an den erhaltenen Bildern einschränken. Oft bleiben unsere Anfragen nach Hilfe bei der Datenerfassung völlig unbeantwortet. Aufgrund des Fehlens solcher Daten, rechtlicher Probleme oder alltäglicher Faulheit - es ist unklar.
Somit werden wertvolle Informationen in keiner Weise zum Trainieren neuronaler Netze verwendet, sondern gehen verloren oder sind irgendwo auf Festplatten und Cloud-Speichern tot, anstatt das Volumen und die Qualität der Trainingsstichprobe zu verbessern. Wir schreiben einen Dienst, der es unter anderem ermöglicht, wertvolle Fotos zu uns hochzuladen (dazu auch unten), aber es gibt wie immer mehr Aufgaben als Menschen.
Darüber hinaus verfügt das Netzwerk bislang nur über sehr wenige gute (offene) Datensätze mit Bildern von UAVs. Der am besten geeignete ist der
Stanford Drone Dataset (SDD) . Es ist ein Foto aus einer Höhe über dem Universitätsgelände mit markierten Objekten der Klasse "Fußgänger", zusammen mit Radfahrern, Bussen und Autos. Trotz des ähnlichen Aufnahmewinkels haben die fotografierten Fußgänger und die Umwelt wenig mit dem zu tun, was auf unseren Bildern passiert. Die mit diesem Datensatz durchgeführten Experimente haben gezeigt, dass die Qualitätsmetriken der Detektoren, die mit unseren Daten darauf trainiert wurden, ein geringes Ergebnis zeigen. Infolgedessen verwenden wir SDD jetzt zum Trainieren des sogenannten Backbones, der Attribute der obersten Ebene extrahiert, und die extremen Ebenen müssen auf den Bildern unseres Domänenbereichs vervollständigt werden.
Aus diesem Grund haben wir lange Zeit mit verschiedenen Suchmaschinen und Rettungskräften kommuniziert und versucht zu verstehen, wie eine Person, die sich im Wald verirrt hat, auf einem Bild von oben aussieht. Als Ergebnis haben wir einzigartige Statistiken zu 24 Posen gesammelt, in denen am häufigsten vermisste Personen gefunden werden. Wir haben unseren eigenen Datensatz - Lacmus Drone Dataset (LaDD) - gefilmt und markiert, der in der ersten Version mehr als 400 Bilder enthielt. Das Shooting wurde hauptsächlich mit Hilfe von DJI Mavic Pro und Phantom aus einer Höhe von 50 - 100 Metern durchgeführt, die Auflösung der Bilder betrug 3000x4000, die durchschnittliche Personengröße 50x100 px. Im Moment haben wir bereits die vierte Version des Datensatzes mit 2.000 Bildern, sowohl real als auch "simuliert". Wir arbeiten weiter daran, den Datensatz aufzufüllen, und die fünfte Version steht vor der Tür.
Während wir unseren Datensatz auffüllen, müssen die Bilder nach Jahreszeiten getrennt werden. Tatsache ist, dass ein Modell, das in Winterfotos trainiert wurde, bessere Ergebnisse zeigt als ein Modell, das im gesamten Datensatz trainiert wurde, entweder im Sommer oder im Frühjahr separat. Möglicherweise werden Zeichen auf einem schneebedeckten Hintergrund besser extrahiert als auf lautem Gras.

Gleichzeitig steigt beim Training nur in Winterbildern die Anzahl der Fehlalarme (Fehlalarme). Anscheinend sind die Bilder verschiedener Jahreszeiten zu unterschiedliche Landschaften (Domänen) und das neuronale Netz kann sie nicht verallgemeinern. Dies bleibt abzuwarten, und wir sehen bisher zwei Möglichkeiten:
- Bilden Sie viele „kleine“ Gitter und lernen Sie sie separat für verschiedene Bereiche (eines für den Winter, eines für den Sommer ... Neben den Jahreszeiten können Sie auch nach Gebieten aufschlüsseln: zum Beispiel ein Modell für den Mittelstreifen und die Ebene, ein anderes für den Süden usw.) .
- Erhöhen Sie wiederholt unsere Daten und versuchen Sie, das Modell auf allen Domänen gleichzeitig zu trainieren. Basierend auf der Lösung eines ähnlichen Problems in einem Artikel von Yandex versuchen wir diese spezielle Option. Aus den bereits beschriebenen Gründen ist es schwierig, eine große Anzahl von echten Fotos mit verlorenen Personen zu sammeln. Vielleicht werden wir versuchen, anhand von „leeren“ Bildern realistische Bildungsbeispiele zu erstellen (es gibt viele davon). Vielleicht haben wir bald GANs.
Lernprozess
Die Art unserer Bilder unterscheidet sich erheblich von Bildern gängiger Datensätze wie ImageNet, COCO usw. Da die für solche Mengen entwickelten neuronalen Netze für unsere Aufgabe schlecht geeignet sein könnten, musste eine Studie über die Anwendbarkeit verschiedener Architekturen durchgeführt werden. Zu diesem Zweck haben wir Modelle verwendet, die auf ImageNet vorab trainiert wurden, sie auf dem Stanford Drone-Dataset erneut trainiert und anschließend die Backbones „eingefroren“. Die übrigen Teile der Detektoren wurden direkt auf unseren Bildern trainiert. Die besten Metriken sind in der Tabelle dargestellt:
Zusätzlich zu den Zahlen in der obigen Tabelle sollten Sie ein Merkmal von Lacmus Drone Dataset-Bildern wie ein großes Klassenungleichgewicht beachten: Das Verhältnis des Hintergrundbereichs zum Bereich des Rechtecks (Ankers) mit dem gewünschten Objekt beträgt mehrere Tausend. Beim Trainieren des Detektors treten zwei Probleme auf:
- Die meisten Regionen mit Hintergrundinformationen enthalten keine nützlichen Informationen.
- Regionen mit Objekten tragen aufgrund ihrer geringen Anzahl ebenfalls nicht wesentlich zum Training von Gewichten bei.
Um diese Probleme irgendwie zu umgehen, wurden verschiedene Trainingsschemata, Netzwerkeinstellungen und Trainingsbeispiele verwendet. Eine der von uns getesteten neuronalen Netzwerkarchitekturen, RetinaNet, zielt genau darauf ab, die negativen Auswirkungen eines großen Klassenungleichgewichts zu reduzieren. Die Erfinder von RetinaNet haben es entwickelt, um die Genauigkeit von einstufigen Detektoren (die das Bild mit einem dichten Netzwerk vordefinierter Rechteck-Anker abdecken und dann diejenigen verfeinern, die das Objekt am besten abdecken) im Vergleich zu qualitativ besseren, aber langsameren zweistufigen Detektoren (Studenten, die zuerst lernen, Kandidatenregionen zu finden) zu erhöhen , dann geben Sie ihre Position an). Aus Sicht der Autoren des Artikels über RetinaNet verlieren einstufige Detektoren gerade wegen des Ungleichgewichts, das durch eine große Anzahl von leeren Ankern verursacht wird. Vor dem Hintergrund dieses Vorteils haben wir uns für RetinaNet mit dem ResNet50-Backbone entschieden.
Die Architektur dieses Netzwerks
wurde 2017 eingeführt. Die Hauptfunktion von RetinaNet, mit der Sie die negativen Auswirkungen von Klassenungleichgewichten im Training bewältigen können, ist die ursprüngliche Funktion für den Verlust von Fokusverlusten:
Wobei
p die geschätzte Wahrscheinlichkeit des Inhalts im Bereich des gewünschten Objekts ist, die vom Modell geschätzt wird (um es einfach auszudrücken: die Ausgabe des neuronalen Netzwerks, wenn es auf das Intervall [0, 1] reduziert wird).
In anderen Domänenbereichen sollte die Verlustfunktion in der Regel gegen atypische Instanzen (harte Beispiele) resistent sein, bei denen es sich höchstwahrscheinlich um Ausreißer handelt. Ihr Einfluss auf das Krafttraining sollte verringert werden. Im Gegensatz dazu wird bei Focal Loss der Einfluss eines häufig auftretenden Hintergrunds (Lieferanten, einfache Beispiele) verringert, und selten gesehene Objekte haben den größten Einfluss beim Trainieren von RetinaNet-Gewichten. Dies geschieht aufgrund dieses Teils der Formel:
Koeffizient
im Exponenten bestimmt das "Gewicht" von harten Beispielen in der Totalverlustfunktion.
Während des RetinaNet-Trainingsprozesses wird die Verlustfunktion für alle berücksichtigten Ausrichtungen der Kandidatenbereiche (Anker) aus allen Bildskalierungsstufen berechnet. Insgesamt gibt es ungefähr 100.000 Bereiche für ein Bild, was sich stark von den Ansätzen der heuristischen Abtastung (RPN) oder der Suche nach seltenen Fällen (OHEM, SSD) mit einer geringen Anzahl von Bereichen (ungefähr 256) für jedes Minibatch unterscheidet. Der Fokusverlustwert wird als die Summe der Funktionswerte für alle Anker berechnet, normalisiert durch die Anzahl der Anker, die die gewünschten Objekte enthalten. Die Normalisierung wird nur für sie und nicht für die Gesamtzahl durchgeführt, da die überwiegende Mehrheit der Anker einen leicht identifizierbaren Hintergrund darstellt und wenig zur Gesamtverlustfunktion beiträgt.
Strukturell besteht RetinaNet aus einem Backbone und zwei zusätzlichen Subnetzdefinitionen für Klassifizierung und Box-Regression.
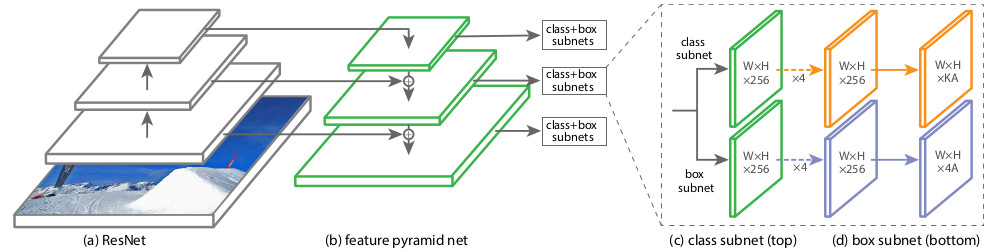
Als Backbone wird das sogenannte
Feature Pyramid Network (FPN) verwendet, das auf einem der gebräuchlichsten neuronalen Faltungsnetze (z. B. ResNet50) aufbaut. FPN hat zusätzliche laterale Ausgänge von verborgenen Schichten des Faltungsnetzwerks, wodurch Pyramidenebenen mit unterschiedlichen Maßstäben gebildet werden. Jede Ebene wird durch einen "Top-Down-Pfad" ergänzt, d.h. Informationen von höheren Ebenen, die kleiner sind, aber Informationen über Bereiche eines größeren Bereichs enthalten. Es sieht aus wie eine künstliche Vergrößerung (zum Beispiel durch einfaches Wiederholen der Elemente) einer "minimierten" Feature-Map auf die Größe der aktuellen Map, indem sie Element für Element hinzugefügt und sowohl auf niedrigere Ebenen der Pyramide als auch auf die Eingabe anderer Subnetze (d. H. In das Klassifizierungs-Subnetz und übertragen wird Box Regression Subnet). Auf diese Weise können Sie aus dem Originalbild eine Zeichenpyramide in verschiedenen Maßstäben auswählen, auf der sowohl große als auch kleine Objekte erkannt werden können. FPN wird in vielen Architekturen verwendet und verbessert die Erkennung von Objekten verschiedener Größen: RPN, DeepMask, Fast R-CNN, Mask R-CNN usw.
Weitere
Informationen zu FPN finden Sie im Originalartikel.
In unserem Netzwerk, wie im Original, FPN mit 5 Ebenen mit nummeriert
von
. Level
hat die Erlaubnis zu
mal kleiner als das Eingabebild (wir werden nicht auf Details eingehen, von welchen Punkten von ResNet sie kommen - dies wird das Bein brechen). Alle Ebenen der Pyramide haben die gleiche Anzahl von Kanälen C = 256 und die Anzahl der Anker A etwa 1000 (abhängig von der Größe der Bilder).
Anker haben Flächen von [16 x 16] bis [256 x 256] für jede Ebene der Pyramide von
vorher
dementsprechend mit einem Verschiebungsschritt (Schritte) [8 - 128] px. Mit dieser Größe können Sie kleine Objekte und Umgebungen analysieren. Wenn Sie beispielsweise die umgebende Realität eines Zweigs nicht berücksichtigen, ähnelt dieser einer lügenden Person.
Die ursprüngliche FPN verwendet drei Seitenverhältnisse der Anker (1: 2, 1: 1, 2: 1); RetinaNet aspect ratio [
]. 9- , / 16 400 px.
Classification Subnet . (Fully ConvNet, FCN), FPN. , :
- (W x H x C)
- 33
- ReLU
- 33 ( ) ,
- -
x A, K — . — Pedestrian.
Box Regression Subnet 4- . , FPN, Classification Subnet. , , (4 ) — :
, , IoU (Intersection over Union) > 0.5.
1, 0. .
( ) forward . 1k , 0,05. , threshold = 0,5.
RetinaNet
towardsdatascience .
, . OpenSource-, Github fizyr:
keras-retinanet , .
, , 20-30 . , :
Und auch ...
- Nvidia Jetson
- Corral Edge TPU
tensoflow 1.14 CPU AVX Intel nndl. AVX ( 2012 ) , Core 2 Duo!
Albumentations .
:
Produktion
docker
desktop- c , . Nvidia Cuda CuDNN TensorFlow — . , Python . - , . — Docker. web- . , docker-. GUI . GUI , , , , . Docker API, GUI, . , Docker , .
#
. 3 :
dotnext . «! - ! - ? », — ! GUI # AvaloniaUI, 64- Win10, Linux Mac.
AvaloniaUI — , . WPF, , . , 2D- , WPF. , WPF.
, SkiaSharp GTK ( Unix ). X11 . , , (!). .Net Core Bios', AvaloniaUI .
AvaloniaUI , , . , 2019 , . WPF C# — . ( electron), , .
 ...
..., , issue. , ,
,
.
.Für ein vollständiges Verständnis dieses Konzepts lohnt sich ein Blick auf die Präsentation von Nikita Tsukanov @kekekeks . Er ist der Entwickler dieses Frameworks, kennt es und .NET im Allgemeinen.Backend
Zusätzlich zur Desktop-Anwendung entwickeln wir eine mlOps-Infrastruktur, um Experimente durchzuführen und die beste neuronale Netzwerkarchitektur in der Cloud zu finden. Auf der Serverseite möchten wir:- Daten aggregieren und zentral speichern;
- den Lernprozess eines neuronalen Netzwerks automatisieren, eine Umgebung für die Forschung schaffen und anderen den Zugang dazu ermöglichen;
- Bereitstellung des Zugriffs auf die Cloud für Such- und Rettungsteams, damit diese bei Bedarf auch die gesammelten Daten verwenden können;
Die gesamte Systemarchitektur sieht ungefähr so aus:
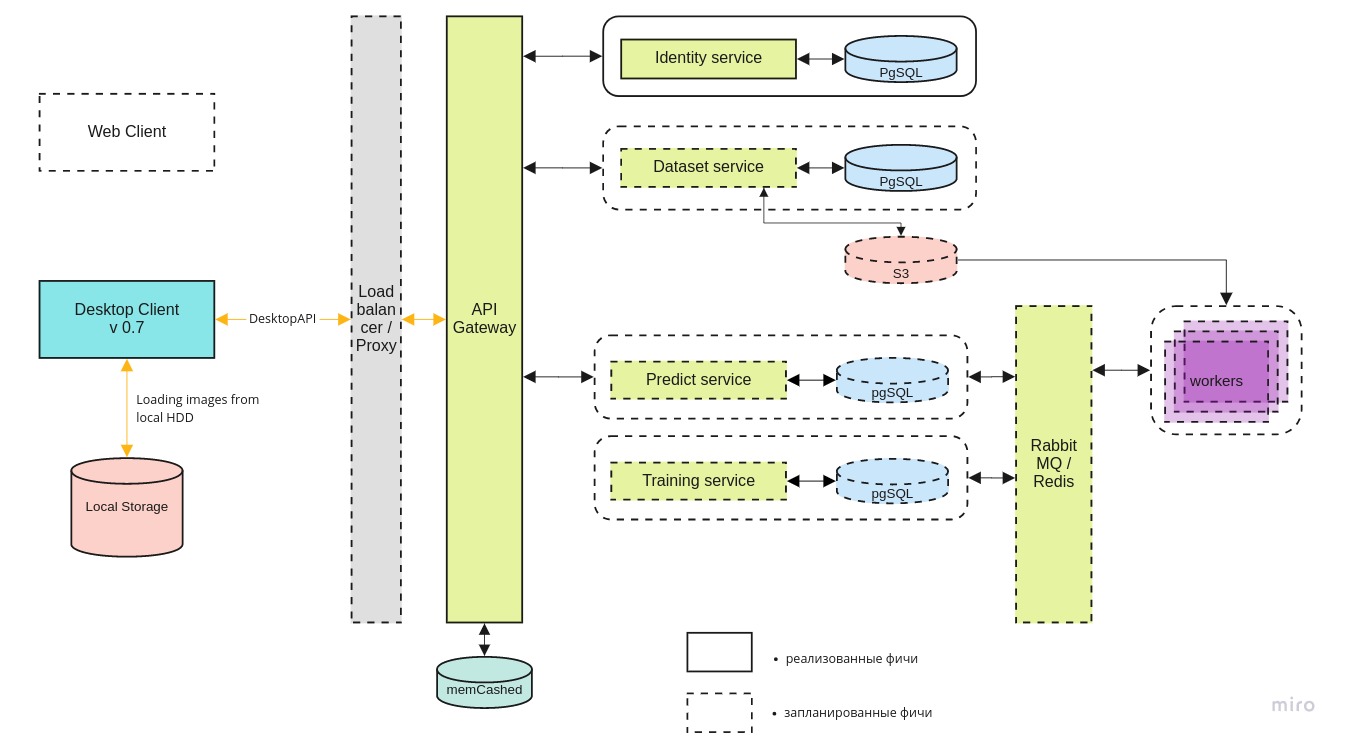 Der Desktop-Client
Der Desktop-Client kann sowohl mit der lokalen Version des Docker-Containers als auch mit der neuesten Version auf dem zentralen Server über die REST-API arbeiten.
Der Identitätsmikroservice ermöglicht nur autorisierten Benutzern den Zugriff auf den Server.
Der Dataset- Dienst dient zum Speichern der Bilder selbst und ihrer Kennzeichnung.
Mit dem Predict- Dienst können Sie eine große Anzahl von Bildern in Gegenwart eines breiten Kanals für Piloten schnell verarbeiten.
Ein Schulungsservice ist erforderlich, um neue Modelle zu testen und vorhandene Modelle zu aktualisieren, sobald neue Daten eintreffen.
Die Aufgabenwarteschlange wird mit RabbitMQ / Redis verwaltet.
Suche nach GPU-Funktionen
Trotz der Tatsache, dass die Schlussfolgerung des neuronalen Netzwerks auch auf einem einfachen Laptop funktionieren kann, wird eine GPU benötigt, um das Modell zu trainieren. Technisch kann man es auf der CPU trainieren, aber in der Praxis dauert es zu lange. Nicht alle Mitarbeiter des Teams verfügen über einen Computer, der für Deep Learning geeignet ist. Daher sind wir auf der Suche nach zentralen GPU-Funktionen.
Derzeit verhandeln wir mit
DTL und hoffen, dass sich die Zusammenarbeit weiterentwickelt. Die Einzigartigkeit von DTL-GPU-Servern ist die Verwendung von Immersionskühlung: Eintauchen von Racks in eine spezielle dielektrische Flüssigkeit. Es sieht so aus:

 (Anmerkung des Fotografen: Blau ist kein Cherenkov-Schein. Es ist ein solches Highlight in ihnen.)
(Anmerkung des Fotografen: Blau ist kein Cherenkov-Schein. Es ist ein solches Highlight in ihnen.)Lyrischer Exkurs. "Kennen Sie das neuronale Netz von Beeline?"
Ehrlich gesagt, ich möchte dieses (rutschige) Thema nicht wirklich anrühren, aber es berührt uns weiterhin, sodass es unmöglich ist, so zu tun, als wären wir im Tank. Ja, wir kennen das neuronale Netz von Beeline. Nach dem Feedback der mit uns kooperierenden Piloten funktioniert es schlechter als unsere Version und nur auf High-End-Plattformen. Laut den Entwicklern von Beeline ist das Projekt eingefroren und entwickelt sich derzeit nicht weiter. Unter dem Gesichtspunkt des gesunden Menschenverstands sind Nachrichten im Geiste von Beeline die ersten in Russland, die ein solches neuronales Netzwerk entwickelt haben, kaum wahr. Nur wenige Leute implementieren Architekturen, die von Labors wie Facebook Research oder Google Brain entworfen wurden, und erst recht keine eigenen. Meist geht es nur darum, eine öffentliche OpenSource-Bibliothek an die Bedürfnisse Ihres Fachgebiets anzupassen. Wie oft offene Bibliotheken in kommerzieller russischer Software verwendet werden, weiß jeder, der diese Software entwickelt. Zum größten Teil liegt nicht einmal eine Verletzung der Lizenz vor; Aber es ist zumindest hässlich, die Errungenschaften des internationalen OpenSource als Ganzes in seiner Entwicklung herauszulassen und lautstarke PR zu betreiben. Es scheint, dass unsere Erfolge auch genutzt wurden: Insbesondere in
unserer Gamification wurden unsere Fotos
beleuchtet. Vergleichen Sie mit dem „Winter“ -Foto aus dem Abschnitt über den Lacmus-Datensatz:

Es gibt andere Gründe zu der Annahme, dass die Angelegenheit hier nicht auf Daten beschränkt war.
Was für uns an erster Stelle schlecht ist, ist, dass das neuronale Netz von Beeline jetzt nicht mehr so stark verdreht ist, dass es unmöglich ist. Wenn es erwähnt wird, ist es unmöglich zu verstehen, ob es sich wirklich um sie, unsere Bewerbung oder allgemein um die Option eines anderen handelt. Unter den Bedingungen der Dezentralisierung, der schlechten JI-Kontrollierbarkeit und einer geringen Anzahl von Feedback-Kanälen wären Informationen über die Verbreitung und Qualität der Lacmus-Arbeit ebenso nützlich wie über ähnliche Entwicklungen - aber der Hype um Beeline überschattete alles.
Wir planen, die Situation vorerst weiter zu überwachen, aber unsere Bitte an die Community besteht darin, erstens „Beeline Neural Network“ zu sagen, wenn sie sich zu 100% sicher sind, dass dies der Fall ist, und zweitens Open-Source-Lizenzen zu lesen und ehrlich auf Urheberschaft hinzuweisen.
Zusammenfassung
In den letzten 2019 haben Mitglieder der Lacmus Foundation:
- Wir haben einen einzigartigen Datensatz erstellt und markiert, dessen neueste Version mehr als 2000 Bilder enthält.
- probierte eine Reihe verschiedener neuronaler Netzwerkarchitekturen aus und wählte die am besten geeignete aus;
- Wir haben die besten Hyperparameter des neuronalen Netzwerks ausgewählt und anhand unserer eigenen eindeutigen Daten trainiert, um eine möglichst genaue Erkennung zu erzielen.
- entwickelte eine plattformübergreifende Anwendung für UAV-Betreiber mit der Möglichkeit, offline zu arbeiten;
- die Arbeit unseres neuronalen Netzwerks für die Arbeit mit preiswerten und stromsparenden Laptops optimiert;
Derzeit liegen die besten Indikatoren für die LAPMUS-mAP-Metrik für neuronale Netze bei 94%. Unser Programm ist einsatzbereit für echte Such- und Rettungsaktionen und wurde in allgemeinen Läufen getestet. In offenen Bereichen vom Typ "Feld" und "Windschutz" wurden alle Test "verloren" gefunden. Bereits jetzt wird Lakmus von Rettungskräften eingesetzt und hilft bei der Suche nach Personen.
Außerdem haben wir von Open Data Science den Preis für das Projekt des Jahres erhalten:

In diesem Jahr planen wir:
- einen Partner für eine zuverlässige Hosting-Infrastruktur finden;
- Webinterface und mlOps implementieren;
- einen großen synthetischen Datensatz auf der UE4-Engine oder mit Hilfe von GANs bilden;
- Starten Sie bei Kaggle einen InClass-Wettbewerb für alle, die ihre DL / CV-Kenntnisse verbessern und nach den besten SOTA-Lösungen suchen möchten.
- Fügen Sie unserem Retinanet noch mehr Implementierungen von Backbones und Variationen dieser Architektur hinzu.
Es fehlen uns wirklich Mitarbeiter, um diese Pläne umzusetzen, und wir werden uns für alle freuen, ungeachtet des Niveaus und der Richtung der Ausbildung.
Wenn wir zusammen mindestens eine weitere Person retten können, werden alle Anstrengungen nicht umsonst sein.
Wie Sie dem Projekt helfen können
Wir sind ein OpenSource-Projekt und nehmen alle gerne an! Hier sind die Links zu unseren Github-Repositories:
Wenn Sie ein Entwickler sind und dem Projekt beitreten möchten, können Sie Perevozchikov Georgy Pavlovich,
gosha20777 in allen sozialen Netzwerken,
gosha20777@live.ru ,
schreiben oder dem Projekt über den Kanal
# ml4sg in Slack ODS beitreten (falls Sie dort sind).
Wir brauchen:
- ML-Entwickler
- C # / go / python-Entwickler;
- Frontarbeiter;
- Beckers;
- Nur aktive Leute jeglicher Richtung! Wir werden uns immer freuen, Sie zu sehen!
Wenn Sie nicht an der Entwicklung beteiligt sind, können Sie auch das Projekt unterstützen:
- Sie können uns beim Schreiben von Artikeln helfen.
- Sie können uns helfen, Benutzerdokumentation und ein Wiki zu schreiben (und Grammatikfehler dort zu korrigieren))
- Sie können in der Rolle eines Produktmanagers bleiben und Aufgaben in Trello erledigen.
- Sie können uns eine Idee anbieten;
- Sie können diesen Beitrag verteilen.
Über das Team
Projektleiter: Georgy Pavlovich Perevozchikov,
gosha20777 .
Eine unvollständige Liste der Beteiligten (in der Tat ist es viel größer, wenn Sie zu Unrecht vergessen wurden, sagen Sie mir, und wir werden hinzufügen):
- Die aktivsten ODS-Teilnehmer im Channel #proj_rescuer_la : Kseniia, balezz, ei-grad, Palladdiumm, sharov_am, dartov
- Projektteilnehmer außerhalb der ODS: Martynova Viktoriya Viktorovna (Projektorganisation, Datenerfassung und -kennzeichnung), Denis Petrovich Shurankov (Datenerfassungsorganisation), Daria Pavlovna Perevozchikova (markierte etwa 30% aller Fotos).
- UAV-Mitarbeiter des Liza-Alert-Teams, die bei der Erstellung des Datensatzes mitgewirkt haben: Partyzan, Vanteyich, Sevych, Kalifornien, Tarekon, Evgen, GB.
Besonderer Dank geht an:
- Für Programmierer von AvaloniaUI - dem besten .NET-Framework: worldbeater , kekekek , Larymar
- ODS-Administratoren für die Organisation der coolsten Community: Natekin, Sasha, Mephistopheies.
Dieser Artikel wurde zusammen mit
Balezz und
Gosha20777 Habrozhitelami geschrieben .
Jeder, um einfallsreich zu sein und sich nie zu verlaufen!
 Videodemonstration der Arbeit zum Nachtisch. Pre-Early-Alpha-Version. Für diejenigen, die bis zum Ende lesen. Februar 2019.
Videodemonstration der Arbeit zum Nachtisch. Pre-Early-Alpha-Version. Für diejenigen, die bis zum Ende lesen. Februar 2019.