Vor zwei Jahren habe ich mit der Entwicklung begonnen noch eins ein kostenloser Codegenerator von OpenAPI Specification v3 bis TypeScript ( verfügbar auf Github ). Zunächst wollte ich einfache und komplexe Datentypen in TypeScript effizient generieren und dabei verschiedene JSON- Schemafunktionen berücksichtigen, z. B. oneOf / anyOf / allOf usw. (Swaggers native Lösung hatte einige Probleme damit). Eine weitere Idee bestand darin, Schemata aus Spezifikationen für die Validierung auf der Vorder- und Rückseite sowie auf anderen Teilen des Systems zu verwenden.

Jetzt ist der Codegenerator relativ fertig - er befindet sich im MVP- Stadium. Es verfügt über viele Funktionen zum Generieren von Datentypen sowie über eine experimentelle Bibliothek zum Generieren von Front-End-Diensten (bisher für Angular). In diesem Artikel möchte ich die Entwicklungen zeigen und erläutern, wie sie helfen können, wenn Sie TypeScript und OpenAPI v3 verwenden. Unterwegs möchte ich einige Ideen und Überlegungen mitteilen, die sich in meinem Arbeitsprozess ergeben haben. Wenn Sie interessiert sind, können Sie die Hintergrundgeschichte lesen, die ich im Spoiler versteckt habe, um das Lesen des technischen Teils nicht zu erschweren.
Inhalt
- Hintergrund
- Beschreibung
- Installation und Verwendung
- Üben Sie die Verwendung eines Codegenerators
- Generierte Datentypen in Anwendungen verwenden
- Zerlegung von Stromkreisen innerhalb der OAS-Spezifikation
- Verschachtelte Zerlegung
- Automatisch generierte Services für die Arbeit mit der REST-API
- Warum ist das nötig?
- Service-Generierung
- Generierte Services verwenden
- Anstelle eines Nachwortes
Hintergrund
Zum Lesen erweitern (überspringen)Alles begann vor zwei Jahren - dann arbeitete ich für ein Unternehmen, das eine Data Mining-Plattform entwickelte, und war für das Frontend (hauptsächlich TypeScript + Angular) verantwortlich. Die Projektmerkmale waren komplexe Datenstrukturen mit einer großen Anzahl von Parametern (30 oder mehr) und nicht immer offensichtlichen Geschäftsbeziehungen zwischen ihnen. Das Unternehmen wuchs und die Softwareumgebung wurde häufig geändert. Das Frontend musste sich in den Nuancen auskennen, da einige Berechnungen im Frontend und im Backend dupliziert wurden. Das heißt, dies war der Fall, wenn die Verwendung von OpenAPI mehr als angemessen ist. Ich fand eine Zeit in der Firma, in der das Entwicklungsteam innerhalb weniger Monate eine einzige Spezifikation erwarb, die zu einer gemeinsamen Wissensbasis für die hintere, vordere und sogar die Kernabteilung wurde, die sich hinter der breiten Rückseite des Web-Backends verbarg. Die OpenAPI-Version wurde „zum Wachsen“ gewählt - damals noch recht jung v3.0
Dies war keine Spezifikation mehr in einer oder mehreren statischen YML / JSON-Dateien und nicht das Ergebnis von Annotatoren , sondern eine ganze Bibliothek von Komponenten, Methoden, Vorlagen und Eigenschaften, die gemäß dem DDD-Konzept der Plattform organisiert wurden. Die Bibliothek war in Verzeichnisse und Dateien unterteilt, und ein speziell zusammengestellter Sammler erstellte OAS-Dokumente für jeden Themenbereich. Ein experimenteller Weg war der Aufbau eines Workflows, der als Design-First bezeichnet werden konnte.
Es gibt einen guten Artikel im Blog des Unternehmens Yandex.Money, in dem es um Design First ging
Design First und die allgemeine Spezifikation halfen bei der Deaktivierung des Wissens, aber ein neues Problem wurde offensichtlich - die Beibehaltung der Relevanz des Codes. In der Spezifikation wurden mehrere Dutzend Methoden und Dutzende (und später Hunderte) von Entitäten beschrieben. Der Code musste jedoch manuell geschrieben werden: Datentypen, Dienste für die Arbeit mit REST usw. Ein oder zwei Sprints mit parallelen Geschichten haben das Bild stark verändert; Fügen Sie der Verschmelzung mehrerer Geschichten und des menschlichen Faktors Komplexität hinzu. Die Routine drohte bedeutend zu sein, und die Lösung schien offensichtlich: Sie müssen Code generieren. Schließlich enthielten die OAS-Spezifikationen bereits alles Notwendige, um sie nicht manuell erneut einzugeben. Aber es war nicht so einfach.
Das Frontend befindet sich ganz am Ende des Produktionszyklus, so dass ich schmerzhaftere Veränderungen verspürte als Kollegen aus anderen Abteilungen. Bei der Entwicklung der REST-API entschied die Backend-Umgebung, und selbst nach der Genehmigung von „Design First“ blieb die Trägheit bestehen. Für das Frontend schien alles weniger offensichtlich zu sein. Tatsächlich verstand ich das von Anfang an und begann, den Boden im Voraus zu untersuchen - als die Rede von einer „universellen“ Spezifikation gerade erst begann. Es war nicht die Rede davon, einen eigenen Codegenerator zu schreiben. Ich wollte nur etwas fertig finden.
Ich war enttäuscht Es gab zwei Probleme: Die OAS-Version 3.0, mit deren Unterstützung anscheinend niemand in Eile war, und die Qualität der Lösungen selbst - zu dieser Zeit (ich erinnere mich an sie vor zwei Jahren) gelang es mir, zwei relativ fertige Lösungen zu finden: von Swagger und von Microsoft (es scheint so ). In der ersten Phase befand sich die Unterstützung für OAS 3.0 in einer tiefen Beta. Der zweite funktionierte nur mit Version 2.x, es gab jedoch keine eindeutigen Vorhersagen. Übrigens konnte ich den Microsoft-Codegenerator auch bei einem Testdokument im Swagger 2.0-Format nicht starten. Die Lösung von Swagger funktionierte, aber ein mehr oder weniger kompliziertes Schema mit $ ref-Links verwandelte sich in einen unverständlichen "FEHLER!", Und rekursive Abhängigkeiten schickten es in eine Endlosschleife. Es gab Probleme mit primitiven Typen . Außerdem verstand ich nicht ganz, wie man mit automatisch generierten Diensten arbeitet - sie schienen nur für Shows gedacht zu sein, und ihre tatsächliche Verwendung verursachte mehr Probleme als sie lösten (meiner Meinung nach). Und schließlich war die Integration der JAR-Datei in eine NPM-orientierte CI / CD unpraktisch: Ich musste den erforderlichen Schnappschuss , der 13 Megabyte zu wiegen schien, manuell herunterladen und etwas damit anfangen. Im Allgemeinen machte ich eine Pause und beschloss zu beobachten, was als nächstes passiert.
Nach ungefähr fünf Monaten tauchte das Problem der Codegenerierung erneut auf. Ich musste einen Teil der Webanwendung neu schreiben und erweitern, und gleichzeitig wollte ich alte Services für die Arbeit mit der REST-API und den Datentypen überarbeiten. Die Bewertung der Komplexität war jedoch nicht optimistisch: von einer Mannwoche bis zwei - und dies gilt nur für REST-Services und Typbeschreibungen. Ich werde nicht sagen, dass es mich sehr deprimiert hat, aber trotzdem. Andererseits habe ich nie eine Lösung für die Codegenerierung gefunden und nicht gewartet, und die Implementierung würde kaum weniger Zeit in Anspruch nehmen. Das heißt, es gab keine Frage: Der Nutzen ist zweifelhaft, die Risiken sind groß. Niemand würde diese Idee unterstützen, und ich schlug nicht vor. In der Zwischenzeit näherten sich die Maiferien, und die Firma schuldete mir mehrere Tage für die Freistellung am Wochenende. Zwei Wochen lang bin ich von all den Arbeitserfahrungen nach Georgia geflüchtet, wo ich einmal fast ein Jahr lang gelebt habe.
Zwischen Partys und Festen musste ich etwas unternehmen und entschied mich, meine Entscheidung aufzuschreiben. Die Arbeit in Sommercafés in der Nähe von Vake Park war überraschend produktiv, und ich kehrte mit einem vorgefertigten Codegenerator für Datentypen zu Peter zurück. Dann „beendete“ ich für einen weiteren Monat die Gottesdienste an den Wochenenden, bevor er zur Arbeit bereit war.
Von Anfang an habe ich den Codegenerator geöffnet und in meiner Freizeit daran gearbeitet. Obwohl in der Tat schrieb er für einen Arbeitsentwurf. Ich werde nicht sagen, dass die Überarbeitung / Einarbeitung ohne Probleme verlief; und ich werde nicht sagen, dass sie bedeutend waren. Aber irgendwann bemerkte ich, dass ich die Redoc / Swagger-Dokumentation nicht mehr verwendete: Das Navigieren im Code war bequemer, vorausgesetzt, der Code ist immer aktuell und kommentiert. Bald „bewertete“ ich meine Leistungen, ohne sie in irgendeiner Weise weiterzuentwickeln, bis ein Kollege (vor einem halben Jahr bin ich zu einem anderen Unternehmen gegangen) mir riet, sie ernster zu nehmen (er hatte auch den Namen).
Ich hatte nicht genug Freizeit und brauchte mehrere Monate, um im Hintergrund fertig zu werden: Spielplatz , Testanwendung, Reorganisation des Projekts. Jetzt bin ich bereit, Feedback zu erhalten.
Beschreibung
Gegenwärtig umfasst die Lösung zur Codegenerierung drei NPM-Bibliotheken, die in den @ codegena- @codegena und sich in einem gemeinsamen Mono-Repository befinden :
Installation und Verwendung
Die praktischste Option ist die Verwendung in NodeJS-Skripten, die über die CLI ausgeführt werden. Zuerst müssen Sie die Abhängigkeiten installieren:
npm i @codegena/oapi3ts, @codegena/ng-api-service, @codegena/oapi3ts-cli
Erstellen Sie dann eine js-Datei (z. B. update-typings.js ) mit dem folgenden Code:
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings();
Und starten Sie es, indem Sie drei Parameter übergeben:
node ./update-typings.js --srcPath ./specs/todo-app-spec.json --destPath ./src/lib --separatedFiles true
In destPath werden Dateien generiert, und der Inhalt dieses Verzeichnisses im Projekt-Repository wird auf dieselbe Weise erstellt. Hier ist das Generierungsskript , und so wird es in NPM-Skripten ausgeführt. Wenn Sie möchten, können Sie es jedoch auch im Browser verwenden, wie im Spielplatz .
Üben Sie die Verwendung eines Codegenerators
Als nächstes möchte ich darüber sprechen, was wir als Ergebnis erhalten werden: Was ist die Idee, wie dies uns helfen wird. Eine visuelle Hilfe wird der Code der Demo-Anwendung sein. Es besteht aus zwei Teilen: einem Backend (auf dem NestJS- Framework) und einem Frontend (auf Angular ). Wenn Sie möchten, können Sie es auch lokal ausführen .
Auch wenn Sie mit Angular und / oder NestJS nicht vertraut sind, sollte dies keine Probleme verursachen: Die bereitgestellten Codebeispiele sollten von den meisten TypeScript-Entwicklern verstanden werden.
Obwohl die Anwendung maximal vereinfacht ist (z. B. speichert das Backend Daten in einer Sitzung und nicht in der Datenbank), habe ich versucht, den darin enthaltenen Datenfluss und die Merkmale der Hierarchie der Datentypen, die der tatsächlichen Anwendung inhärent sind, wiederherzustellen. Es ist zu etwa 80-85% fertig, aber das "Ende" kann sich verzögern, aber im Moment ist es wichtiger, darüber zu sprechen, was bereits da ist.
Generierte Datentypen in Anwendungen verwenden
Angenommen, wir haben eine OpenAPI-Spezifikation (zum Beispiel diese ), mit der wir arbeiten müssen. Es spielt keine Rolle, ob wir etwas von Grund auf neu erstellen oder unterstützen, es gibt eine wichtige Sache, mit der wir am ehesten beginnen - das Tippen. Wir werden entweder mit der Beschreibung der grundlegenden Datentypen beginnen oder Änderungen daran vornehmen. Die meisten Programmierer tun dies, um ihre zukünftige Entwicklung zu erleichtern. Sie müssen also nicht noch einmal in die Dokumentation schauen, sondern müssen die Parameterlisten beachten. und Sie können sicher sein, dass die IDE und / oder der Compiler einen Tippfehler bemerken.
Unsere Spezifikation kann den Abschnitt components.schemas enthalten oder nicht. In jedem Fall werden aber Parametersätze, Anfragen und Antworten beschrieben - und wir können sie verwenden. Betrachten Sie ein Beispiel:
@Controller('group') export class AppController {
Dies ist ein Controller- Fragment für das NestJS-Framework, dessen Parameter ( RewriteGroupParameters ), Anforderungshauptteil ( RewriteGroupRequest ) und RewriteGroupResponse<T> ( RewriteGroupResponse<T> ) RewriteGroupResponse<T> . Bereits in diesem Codefragment sehen wir die Vorteile des Tippens:
- Wenn wir den Namen des zerstörten Parameters
groupId stattdessen groupId , erhalten wir sofort einen Fehler im Editor.

- Wenn die Methode this.appService.rewriteGroup (groupId, body) typisierte Parameter enthält, können wir die Richtigkeit des übergebenen
body Parameters überprüfen . Und wenn sich das Eingabedatenformat der Controller-Methode oder der Service-Methode ändert, werden wir sofort darüber informiert. Mit Blick auf die RewriteGroupRequest ich fest, dass die Eingabemethode der RewriteGroupRequest einen anderen Datentyp als RewriteGroupRequest hat, in unserem Fall jedoch identisch ist. Wenn jedoch plötzlich die ToDoGroup geändert wird und ToDoGroup anstelle von ToDoGroupBlank akzeptiert wird, zeigen die IDE und der Compiler sofort die Stellen an, an denen Unstimmigkeiten ToDoGroupBlank sind:
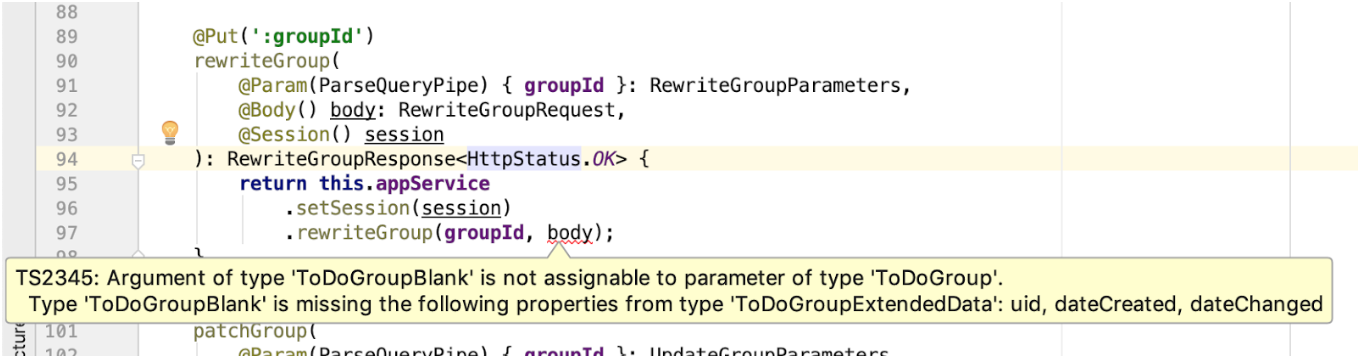
- Auf die gleiche Weise können wir die Einhaltung des zurückgegebenen Ergebnisses kontrollieren. Wenn sich der Status einer erfolgreichen Antwort plötzlich in der Spezifikation ändert und zu
202 statt zu 200 , werden wir dies ebenfalls herausfinden, da RewriteGroupResponse eine generische RewriteGroupResponse mit einem Aufzählungstyp ist :

Schauen wir uns nun ein Beispiel aus der Front-End-Anwendung an , die mit einer anderen API-Methode arbeitet :
protected initSelectedGroupData(truth: ComponentTruth): Observable<ComponentTruth> { return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) ); }
Gehen wir nicht weiter und analysieren den benutzerdefinierten RxJS-Operator pickResponseBody , sondern konzentrieren uns auf die Verfeinerung des GetGroupsResponse Typs. Wir verwenden es in einer Kette von RxJS-Operatoren, und der Operator, der darauf folgt, hat eine Eingabeoptimierung von ToDoGroup[] . Wenn dieser Code funktioniert, entsprechen die angegebenen Datentypen einander. Hier können wir auch die Typzuordnung steuern. Wenn sich das Antwortformat in unserer API plötzlich ändert, entgeht dies unserer Aufmerksamkeit nicht:
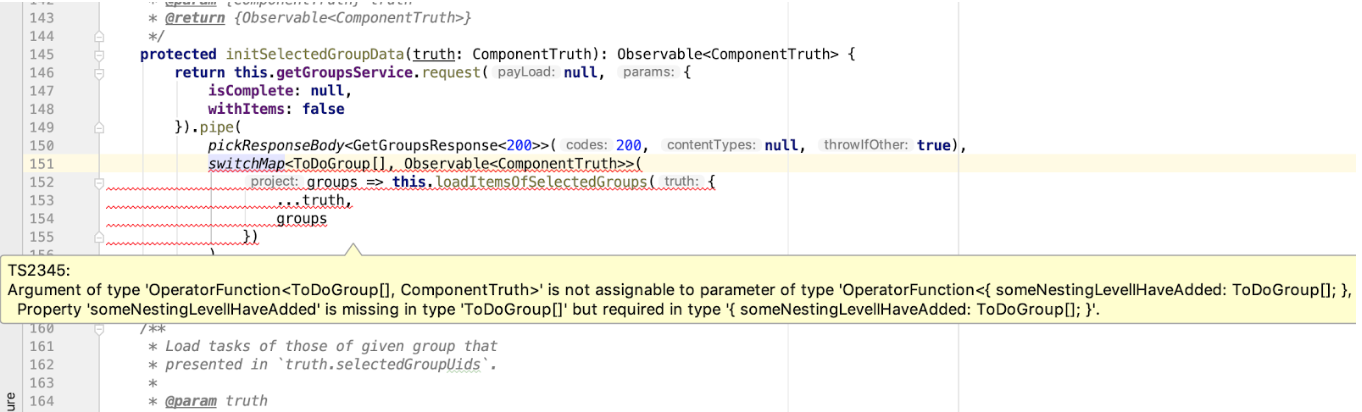
this.getGroupsService.request auch die Aufrufparameter von this.getGroupsService.request eingegeben. Dies ist jedoch das Thema der generierten Dienste.
In den obigen Beispielen sehen wir, dass die Eingabe von Anforderungen, Antworten und Parametern in verschiedenen Teilen des Systems verwendet werden kann - Frontend, Backend usw. Wenn sich das Backend und das Frontend im selben Mono-Repository befinden und eine kompatible Eco-Umgebung haben, können sie dieselbe gemeinsam genutzte Bibliothek mit dem generierten Code verwenden. Aber selbst wenn das Backend und das Frontend von verschiedenen Teams unterstützt werden und nichts gemeinsam haben, außer der öffentlichen OAS-Spezifikation, ist es für sie immer noch einfacher, ihren Code zu synchronisieren.
Zerlegung von Stromkreisen innerhalb der OAS-Spezifikation
Wahrscheinlich haben Sie in den vorherigen Beispielen auf die ToDoGroupBlank , ToDoGroup , mit denen RewriteGroupResponse und GetGroupsResponse . Tatsächlich ist RewriteGroupResponse nur ein generischer Alias für ToDoGroup , HttpErrorBadRequest usw. Es ist leicht zu erraten, dass sowohl ToDoGroup als auch HttpErrorBadRequest die Schemata aus dem Komponentenschemaspezifikationsabschnitt sind, auf die vom rewriteGroup-Endpunkt verwiesen wird (direkt oder über Vermittler ):
"responses": { "200": { "description": "Todo group saved", "content": { "application/json": { "schema": { "$ref": "#/components/schemas/ToDoGroup" } } } }, "400": { "$ref": "#/components/responses/errorBadRequest" }, "404": { "$ref": "#/components/responses/errorGroupNotFound" }, "409": { "$ref": "#/components/responses/errorConflict" }, "500": { "$ref": "#/components/responses/errorServer" } }
Dies ist die übliche Zerlegung von Datenstrukturen und ihr Prinzip ist dasselbe wie in anderen Programmiersprachen. Komponenten können wiederum auch zerlegt werden: Verweisen Sie auf andere Komponenten (auch rekursiv), verwenden Sie Kombinationen und andere JSON-Schema-Funktionen. Unabhängig von der Komplexität sollten sie jedoch korrekt in Beschreibungen von Datentypen konvertiert werden. Ich möchte zeigen, wie Sie die Zerlegung in OpenAPI verwenden können und wie der generierte Code aussehen wird.
Die Komponenten in einer gut entworfenen OAS-Spezifikation überschneiden sich mit dem DDD-Modell der Anwendungen, die es verwenden. Aber auch wenn die Spezifikation nicht perfekt ist, können Sie sich darauf verlassen und Ihr eigenes Datenmodell erstellen. Dies gibt Ihnen mehr Kontrolle über die Korrespondenz Ihrer Datentypen mit den Datentypen der integrierten Subsysteme.
Da unsere Anwendung eine Liste von Aufgaben ist, ist das Wesentliche die Aufgabe. Es ist logisch, es an erster Stelle in die Komponenten zu setzen, weil andere Entitäten und Endpunkte werden irgendwie damit verbunden sein. Aber vorher müssen Sie zwei Dinge verstehen:
- Wir beschreiben nicht nur die Abstraktion, sondern auch die Validierungsregeln. Je genauer und eindeutiger sie sind, desto besser.
- Wie jede Entität, die in einer Datenbank gespeichert ist, verfügt eine Aufgabe über zwei Arten von Eigenschaften: Dienst und vom Benutzer eingegeben.
Es stellt sich heraus, dass je nach Verwendungsszenario zwei Datenstrukturen vorliegen: die Aufgabe, die der Benutzer gerade erstellt hat, und die Aufgabe, die bereits in der Datenbank gespeichert ist. Im zweiten Fall hat es eine eindeutige UID, ein Erstellungsdatum, ein Änderungsdatum usw., und diese Daten müssen im Backend zugewiesen werden. Ich habe zwei Entitäten ( ToDoTaskBlank und ToDoTask ) so beschrieben, dass die erste eine Teilmenge der zweiten ist:
"components": { "ToDoTaskBlank": { "title": "Base part of data of item in todo's group", "description": "Data about group item needed for creation of it", "properties": { "groupUid": { "description": "An unique id of group that item belongs to", "$ref": "#/components/schemas/Uid" }, "title": { "description": "Short brief of task to be done", "type": "string", "minLength": 3, "maxLength": 64 }, "description": { "description": "Detailed description and context of the task. Allowed using of Common Markdown.", "type": ["string", "null"], "minLength": 10, "maxLength": 1024 }, "isDone": { "description": "Status of task: is done or not", "type": "boolean", "default": "false", "example": false }, "position": { "description": "Position of a task in group. Allows to track changing of state of a concrete item, including changing od position.", "type": "number", "min": 0, "max": 4096, "example": 0 }, "attachments": { "type": "array", "description": "Any material attached to the task: may be screenshots, photos, pdf- or doc- documents on something else", "items": { "$ref": "#/components/schemas/AttachmentMeta" }, "maxItems": 16, "example": [] } }, "required": [ "isDone", "title" ], "example": { "isDone": false, "title": "Book soccer field", "description": "The complainant agreed and recruited more members to play soccer." } }, "ToDoTask": { "title": "Item in todo's group", "description": "Describe data structure of an item in group of tasks", "allOf": [ { "$ref": "#/components/schemas/ToDoTaskBlank" }, { "type": "object", "properties": { "uid": { "description": "An unique id of task", "$ref": "#/components/schemas/Uid", "readOnly": true }, "dateCreated": { "description": "Date/time (ISO) when task was created", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" }, "dateChanged": { "description": "Date/time (ISO) when task was changed last time", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" } }, "required": [ "dateChanged", "dateCreated", "position", "uid" ] } ] } }
Am Ausgang erhalten wir zwei TypeScript-Schnittstellen, die erste wird von der zweiten übernommen :
export interface ToDoTaskBlank {
Jetzt haben wir die grundlegenden Beschreibungen der Task-Entität und verweisen auf sie im Code unserer Anwendung, wie dies in der Demo-Anwendung geschehen ist:
import { ToDoTask, ToDoTaskBlank, } from '@our-npm-scope/our-generated-lib'; export interface ToDoTaskTeaser extends ToDoTask { isInvalid?: boolean; isJustCreated?: boolean; isPending?: boolean; prevTempUid?: string; }
In diesem Beispiel haben wir eine neue Entität beschrieben, die ToDoTask die Eigenschaften hinzufügt, die uns auf der Front-End-Anwendungsseite fehlen. Das heißt, wir haben das resultierende Datenmodell unter Berücksichtigung lokaler Besonderheiten erweitert. Um dieses Modell herum wachsen nach und nach eine Reihe lokaler Tools und so etwas wie ein primitiver DTO:
export function downgradeTeaserToTask( taskTeaser: ToDoTaskTeaser ): ToDoTask { const task = { ...taskTeaser }; if (!task.description || !task.description.trim()) { delete task.description; } else { task.description = task.description.trim(); } delete task.isJustCreated; delete task.isPending; delete task.prevTempUid; return task; } export function downgradeTeaserToTaskBlank( taskTeaser: ToDoTaskTeaser ): ToDoTaskBlank { const task = downgradeTeaserToTask(taskTeaser) as any; delete task.dateChanged; delete task.dateCreated; delete task.uid; return task; }
Jemand zieht es vor, das Datenmodell integraler zu gestalten und Klassen zu verwenden. export class ToDoTaskTeaser implements ToDoTask {
Dies ist jedoch eine Frage des Stils, der Angemessenheit und der Entwicklung der Anwendungsarchitektur. Unabhängig von der Vorgehensweise können wir uns im Allgemeinen auf ein grundlegendes Datenmodell verlassen und mehr Kontrolle über die Konformität der Eingabe haben. Wenn aus irgendeinem Grund die uid von ToDoTask eine Zahl wird, kennen wir alle Teile des Codes, die aktualisiert werden müssen:

Verschachtelte Zerlegung
Jetzt haben wir die ToDoTask Oberfläche und können darauf verweisen. In ähnlicher Weise werden ToDoTaskGroup und ToDoTaskGroupBlank beschrieben und sie enthalten Eigenschaften der Typen ToDoTask bzw. ToDoTaskBlank . Aber jetzt werden wir die "Aufgabengruppe" in zwei und nicht in drei Komponenten aufteilen : Der Übersichtlichkeit halber werden wir das Delta in ToDoGroupExtendedData beschreiben . Daher möchte ich einen Ansatz demonstrieren, bei dem eine Komponente aus den beiden anderen erstellt wird:
"ToDoGroup": { "allOf": [ { "$ref": "#/components/schemas/ToDoGroupBlank" }, { "$ref": "#/components/schemas/ToDoGroupExtendedData" } ] }
Nach dem Start der Codegenerierung erhalten wir ein etwas anderes TypeScript-Konstrukt:
export type ToDoGroup = ToDoGroupBlank &
Da ToDoGroup keinen eigenen „Körper“ hat, hat der Codegenerator es vorgezogen, ihn in eine Vereinigung von Schnittstellen ToDoGroup . Wenn Sie jedoch den dritten Teil mit Ihrem eigenen (anonymen) Schema hinzufügen, wird das Ergebnis eine Schnittstelle mit zwei Vorfahren sein (es ist jedoch besser, dies nicht zu tun). ToDoGroupBlank Sie, dass die items ToDoGroupBlank der ToDoGroupBlank Schnittstelle als Array von ToDoTaskBlank und in ToDoGroupBlank für ToDoTask neu ToDoTask . Auf diese Weise kann der Codegenerator die recht komplexen Zerlegungsnuancen vom JSON-Schema auf TypeScipt übertragen.
import { ToDoTaskBlank } from './to-do-task-blank'; export interface ToDoGroupBlank {
import { ToDoTask } from './to-do-task'; export interface ToDoGroupExtendedData {
Gut und natürlich ToDoTaskBlank wir in ToDoTask / ToDoTaskBlank auch die Zerlegung verwenden. Möglicherweise haben Sie bemerkt, dass die Eigenschaft attachments als Array von Elementen des Typs AttachmentMeta beschrieben wird . Und diese Komponente wird wie folgt beschrieben:
"AttachmentMeta": { "description": "Common meta data model of any type of attachment", "oneOf": [ {"$ref": "#/components/schemas/AttachmentMetaImage"}, {"$ref": "#/components/schemas/AttachmentMetaDocument"}, {"$ref": "#/components/schemas/ExternalResource"} ] }
Das heißt, diese Komponente bezieht sich auf andere Komponenten. Da es kein eigenes Schema hat, wird es vom Codegenerator nicht in einen separaten Datentyp umgewandelt, um Entitäten nicht zu multiplizieren, sondern es wird eine anonyme Beschreibung des Aufzählungstyps erstellt:
attachments?: Array< | AttachmentMetaImage
Gleichzeitig werden für die Komponenten AttachmentMetaImage und AttachmentMetaDocument nicht anonyme Schnittstellen beschrieben, die mit diesen in die Dateien importiert werden:
import { AttachmentMetaDocument } from './attachment-meta-document'; import { AttachmentMetaImage } from './attachment-meta-image';
Aber auch in AttachmentMetaImage finden wir einen Link zu einer anderen gerenderten ImageOptions- Schnittstelle, die zweimal verwendet wird, einschließlich einer anonymen Schnittstelle (das Ergebnis der Konvertierung von additionalProperties ):
import { ImageOptions } from './image-options'; export interface AttachmentMetaImage {
Basierend auf den ToDoTask oder ToDoGroup integrieren wir mehrere Entitäten und eine Kette ihrer Geschäftsverbindungen in unseren Code, wodurch wir mehr Kontrolle über Änderungen im Over-System erhalten, die über unseren Code hinausgehen. Dies ist natürlich nicht in allen Fällen sinnvoll. Wenn Sie OpenAPI verwenden, erhalten Sie möglicherweise zusätzlich zur eigentlichen Dokumentation einen weiteren kleinen Bonus.
Automatisch generierte Services für die Arbeit mit der REST-API
Warum ist das nötig?
Wenn wir eine durchschnittliche statistische Front-End-Anwendung verwenden, die mit einer mehr oder weniger komplexen REST-API arbeitet, besteht ein erheblicher Teil ihres Codes aus Diensten (oder nur Funktionen) für den Zugriff auf die API. Sie umfassen:
- URL- und Parameterzuordnungen
- Validierung von Parametern, Anforderung und Antwort
- Datenextraktion und Notfallbehandlung
Es ist unangenehm, dass dies in vielerlei Hinsicht typisch ist und keine eindeutige Logik enthält. Nehmen wir ein Beispiel an - als allgemeine Übersicht kann die Arbeit mit der API erstellt werden:
Ein vereinfachtes schematisches Beispiel für die Arbeit mit der REST-API import _ from 'lodash'; import { Observable, fromFetch, throwError } from 'rxjs'; import { switchMap } from 'rxjs/operators';
Sie können eine Abstraktion auf hoher Ebene verwenden, um mit REST zu arbeiten. Je nach verwendetem Stapel kann dies Folgendes sein: Axios , Angular HttpClient oder eine andere ähnliche Lösung. Aber wahrscheinlich stimmt Ihr Code im Grunde mit diesem Beispiel überein. Es wird mit ziemlicher Sicherheit Folgendes umfassen:
- Dienste oder Funktionen für den Zugriff auf bestimmte Endpunkte (in unserem Beispiel die Funktion
getTasksFromServer ) - Codeteile, die das Ergebnis verarbeiten (Funktion
getRemainedTasks )
In einer Anwendung aus der realen Welt wird dieser Code komplizierter: Die Spezifikation der Demo-Anwendung beschreibt 5-6 Antwortoptionen . Häufig ist die REST-API so konzipiert, dass jeder Antwortstatus vom Server entsprechend behandelt werden muss. Aber selbst das Überprüfen der Eingabedaten wird während der Entwicklung der Anwendung schwieriger: Je länger die Unterstützung und Verarbeitung von Fehlerüberprüfungen dauert, desto mehr möchten Sie über die Engpässe im Datenverkehr in der Anwendung informiert werden.
An jedem Docking-Knoten von Softwareteilen können Fehler auftreten, deren frühzeitige Erkennung (sowie die Suche nach schwer zu diagnostizierenden Problemen) für Unternehmen sehr kostspielig sein kann. Daher wird es zusätzliche Klärungsprüfungen geben. Je größer die Codebasis und die Anzahl der behandelten Fälle ist, desto komplexer ist es, Änderungen vorzunehmen. Aber das Geschäft ist ein ständiger Wandel und es gibt kein Umgehen. Daher sollten wir uns im Voraus Gedanken machen, wie wir Änderungen vornehmen werden.
Zurück zum OpenAPI-Thema stellen wir fest, dass in den OAS-Spezifikationen möglicherweise genügend Informationen vorhanden sind, um:
- Beschreiben Sie alle erforderlichen Endpunkte in Form von Funktionen oder Diensten
- URL
— . , , / — 5, 10 200, . , , : , , , RxJS- pickResponseBody , , - ; tapResponse , side-effect (tap) HTTP-. , - . , , .
, — -, . , , , "" / API "-" "" . - , "" ( ), .
, REST API Angular. , , /. . , , . , , .. .
" " . Angular-, update-typings.js :
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings(); cliApp.createServices('angular');
, Angular- API . , - - , . , RewriteGroupService . ApiService , , , -:
, JSON Schema , . , , :
import { schema as domainSchema } from './schema.b4c655ec1635af1be28bd6';
, schema.b4c655ec1635af1be28bd6.ts , , .
, Angular-.
Angular-ApiModule :
import { ApiModule, API_ERROR_HANDLER } from '@codegena/ng-api-service'; import { CreateGroupItemService, GetGroupsService, GetGroupItemsService, UpdateFewItemsService } from '@codegena/todo-app-scheme'; @NgModule({ imports: [ ApiModule, // ... ], providers: [ RewriteGroupService, { provide: API_ERROR_HANDLER, useClass: ApiErrorHandlerService }, // ... ], // ... }) export class TodoAppModule { }
, [])( https://angular.io/guide/dependency-injection ):
@Injectable() export class TodoTasksStore { constructor( protected createGroupItemService: CreateGroupItemService, protected getGroupsService: GetGroupsService, protected getGroupItemsService: GetGroupItemsService, protected updateFewItemsService: UpdateFewItemsService ) {} }
— , request , :
return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) );
request Observable<HttpResponse<R> | HttpEvent<R>> , , . , , . , , , . RxJS- pickResponseBody .
, , , . API, . . , :
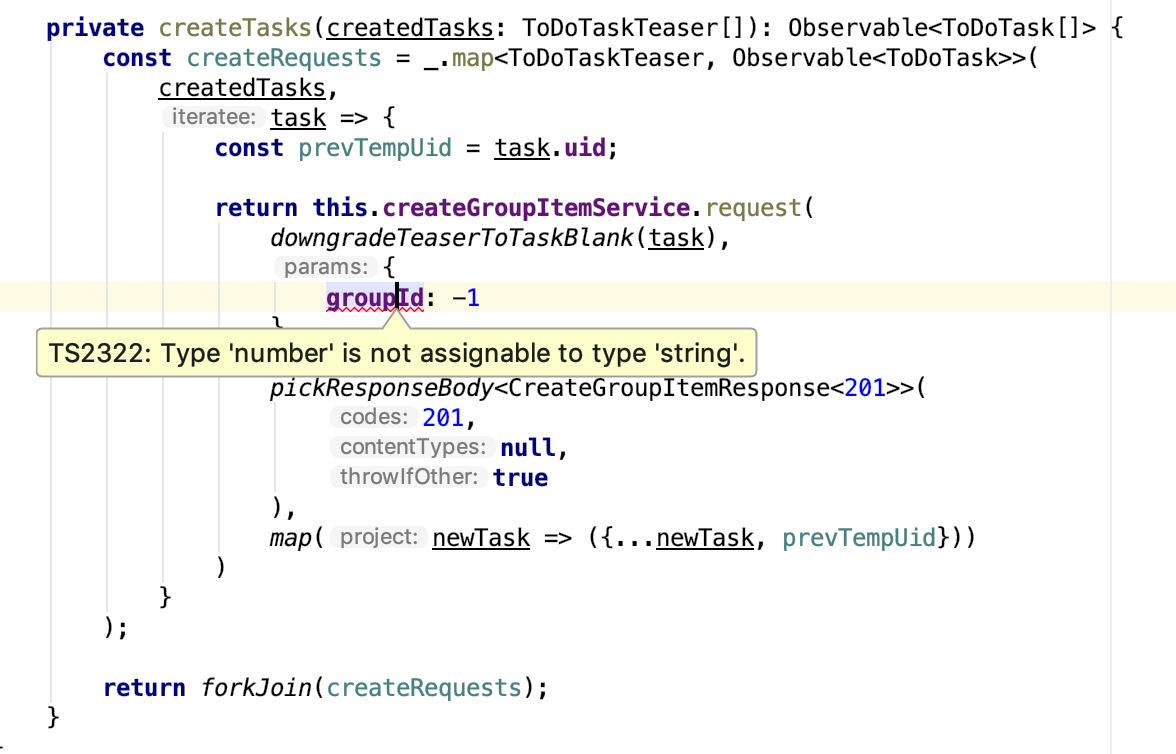
. JSON Schema . , "" - . , Sentry Kibana , . . , , .
, . , :)
Anstelle eines Nachwortes
, . -, " " — . , , , .
— , - / ( ). , — .
.