Keras verfügt über zwei APIs zum schnellen Aufbau von sequenziellen und funktionalen Architekturen für neuronale Netzwerke. Wenn Sie mit der ersten Methode nur sequentielle Architekturen neuronaler Netzwerke erstellen können, können Sie mit der funktionalen API ein neuronales Netzwerk in Form eines willkürlich gerichteten azyklischen Graphen definieren, der viel mehr Möglichkeiten zum Erstellen komplexer Modelle bietet. Dieser Artikel ist eine Übersetzung des Functional API Feature Guide von der TensorFlow-Website.
Einleitung
Mit der funktionalen API können Sie Modelle flexibler als mit der sequenziellen API erstellen und Modelle mit nichtlinearer Topologie, Modelle mit gemeinsamen Ebenen und Modelle mit mehreren Eingaben oder Ausgaben verarbeiten.
Es basiert auf der Tatsache, dass das Deep-Learning-Modell normalerweise ein gerichteter azyklischer Graph (DAG) von Schichten ist
Functional API ist eine Reihe von Werkzeugen zum
Zeichnen von Layern .
Betrachten Sie das folgende Modell:
(Eingabe: 784-dimensionaler Vektor)
↧
[Dichte Schicht (64 Elemente, Aktivierung von relu)]
↧
[Dichte Schicht (64 Elemente, Aktivierung von relu)]
↧
[Dichte Schicht (10 Elemente, Aktivierung von Softmax)]
↧
(Ausgabe: Wahrscheinlichkeitsverteilung über 10 Klassen)
Dies ist eine einfache grafische Darstellung von 3 Ebenen.
Um dieses Modell mit der funktionalen API zu erstellen, müssen Sie zunächst einen Eingabeknoten erstellen:
from tensorflow import keras inputs = keras.Input(shape=(784,))
Hier geben wir einfach die Dimension unserer Daten an: 784-dimensionale Vektoren. Bitte beachten Sie, dass die Datenmenge immer weggelassen wird, wir geben nur die Dimension jedes Elements an. Um die für Bilder vorgesehene Größe "(32, 32, 3)" einzugeben, verwenden wir:
img_inputs = keras.Input(shape=(32, 32, 3))
Die zurückgegebenen
inputs enthalten Informationen zu Größe und Typ der Daten, die Sie in Ihr Modell übertragen möchten:
inputs.shape
TensorShape([None, 784])
inputs.dtype
tf.float32
Sie erstellen einen neuen Knoten im Layerdiagramm, indem Sie den Layer für dieses
inputs aufrufen:
from tensorflow.keras import layers dense = layers.Dense(64, activation='relu') x = dense(inputs)
Das Aufrufen einer Ebene ähnelt dem Zeichnen eines Pfeils von der „Eingabe“ in die von uns erstellte Ebene. Wir übergeben die Eingabe an die
dense Ebene und erhalten
x .
Fügen wir unserem Layerdiagramm einige weitere Layer hinzu:
x = layers.Dense(64, activation='relu')(x) outputs = layers.Dense(10, activation='softmax')(x)
Jetzt können wir ein
Model erstellen, indem wir seine Ein- und Ausgänge im Layerdiagramm angeben:
model = keras.Model(inputs=inputs, outputs=outputs)
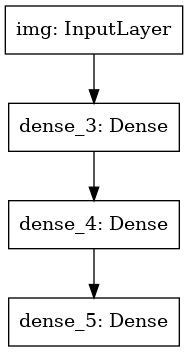
Schauen wir uns noch einmal den gesamten Prozess der Modelldefinition an:
inputs = keras.Input(shape=(784,), name='img') x = layers.Dense(64, activation='relu')(inputs) x = layers.Dense(64, activation='relu')(x) outputs = layers.Dense(10, activation='softmax')(x) model = keras.Model(inputs=inputs, outputs=outputs, name='mnist_model')
Mal sehen, wie die Modellzusammenfassung aussieht:
model.summary()
Model: "mnist_model" _________________________________________________________________ Layer (type) Output Shape Param
Wir können das Modell auch als Grafik zeichnen:
keras.utils.plot_model(model, 'my_first_model.png')
Und leiten Sie optional die Dimensionen der Eingabe und Ausgabe jeder Ebene im erstellten Diagramm ab:
keras.utils.plot_model(model, 'my_first_model_with_shape_info.png', show_shapes=True)
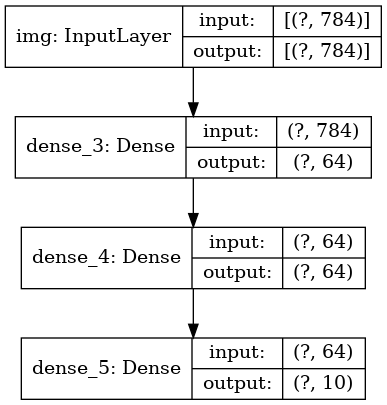
Dieses Bild und der von uns geschriebene Code sind identisch. In der Codeversion werden die Bindungspfeile einfach durch Aufrufoperationen ersetzt.
Das „Layerdiagramm“ ist ein sehr intuitives mentales Abbild für das Deep Learning-Modell, und mit der funktionalen API können Modelle erstellt werden, die dieses mentale Abbild genau widerspiegeln.
Schulung, Bewertung und Abschluss
Lernen, Bewerten und Ableiten von Arbeit für Modelle, die mit der funktionalen API wie in sequentiellen Modellen erstellt wurden.
Überlegen Sie sich eine kurze Demo.
Hier laden wir den MNIST-Bilddatensatz, konvertieren ihn in Vektoren, trainieren das Modell anhand der Daten (während wir die Qualität der Arbeit an der Testprobe überwachen) und bewerten schließlich unser Modell anhand der Testdaten:
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() x_train = x_train.reshape(60000, 784).astype('float32') / 255 x_test = x_test.reshape(10000, 784).astype('float32') / 255 model.compile(loss='sparse_categorical_crossentropy', optimizer=keras.optimizers.RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.2) test_scores = model.evaluate(x_test, y_test, verbose=2) print('Test loss:', test_scores[0]) print('Test accuracy:', test_scores[1])
Speichern und Serialisieren
Das Speichern und Serialisieren von Modellen, die mit der Functional API erstellt wurden, funktioniert genauso wie bei sequentiellen Modellen.
Die Standardmethode zum Speichern eines Funktionsmodells ist der Aufruf von
model.save( ), mit dem Sie das gesamte Modell in einer Datei speichern können.
Sie können später dasselbe Modell aus dieser Datei wiederherstellen, auch wenn Sie keinen Zugriff mehr auf den Code haben, der das Modell erstellt hat.
Diese Datei enthält:
- Modellarchitektur
- Modellgewichte (die während des Trainings erhalten wurden)
- Modellschulungskonfiguration (was Sie beim
compile ) - Der Optimierer und sein Zustand, falls vorhanden (dies ermöglicht es Ihnen, das Training an der Stelle fortzusetzen, an der Sie aufgehört haben)
model.save('path_to_my_model.h5') del model
Verwenden desselben Layerdiagramms zum Definieren mehrerer Modelle
In der funktionalen API werden Modelle erstellt, indem Eingabe- und Ausgabedaten in einem Layerdiagramm angegeben werden. Dies bedeutet, dass ein einzelnes Layer-Diagramm zum Generieren mehrerer Modelle verwendet werden kann.
Im folgenden Beispiel verwenden wir denselben Ebenenstapel, um zwei Modelle zu erstellen:
ein
(encoder) , das Eingabebilder in 16-dimensionale Vektoren konvertiert, und ein End-to-End-
(autoencoder) -
(autoencoder) für das Training.
encoder_input = keras.Input(shape=(28, 28, 1), name='img') x = layers.Conv2D(16, 3, activation='relu')(encoder_input) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.MaxPooling2D(3)(x) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.Conv2D(16, 3, activation='relu')(x) encoder_output = layers.GlobalMaxPooling2D()(x) encoder = keras.Model(encoder_input, encoder_output, name='encoder') encoder.summary() x = layers.Reshape((4, 4, 1))(encoder_output) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) x = layers.Conv2DTranspose(32, 3, activation='relu')(x) x = layers.UpSampling2D(3)(x) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x) autoencoder = keras.Model(encoder_input, decoder_output, name='autoencoder') autoencoder.summary()
Bitte beachten Sie, dass wir die Dekodierungsarchitektur streng symmetrisch zur Kodierungsarchitektur machen, so dass wir die Dimension der Ausgabedaten mit den Eingabedaten
(28, 28, 1) . Die
Conv2D Ebene ist
Conv2D zur
Conv2D Ebene und die
Conv2D Ebene ist
Conv2D zur
MaxPooling2D Ebene.
Modelle können als Ebenen bezeichnet werden
Sie können jedes Modell so verwenden, als wäre es eine Ebene, und es bei der
Input oder bei der Ausgabe einer anderen Ebene aufrufen.
Beachten Sie, dass Sie beim Aufrufen eines Modells nicht nur dessen Architektur, sondern auch dessen Gewichte wiederverwenden. Lassen Sie es uns in Aktion sehen. Im Folgenden sehen Sie ein weiteres Beispiel für einen Auto-Encoder, wenn ein Encoder-Modell oder ein Decoder-Modell erstellt und in zwei Aufrufen verbunden wird, um ein Auto-Encoder-Modell zu erhalten:
encoder_input = keras.Input(shape=(28, 28, 1), name='original_img') x = layers.Conv2D(16, 3, activation='relu')(encoder_input) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.MaxPooling2D(3)(x) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.Conv2D(16, 3, activation='relu')(x) encoder_output = layers.GlobalMaxPooling2D()(x) encoder = keras.Model(encoder_input, encoder_output, name='encoder') encoder.summary() decoder_input = keras.Input(shape=(16,), name='encoded_img') x = layers.Reshape((4, 4, 1))(decoder_input) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) x = layers.Conv2DTranspose(32, 3, activation='relu')(x) x = layers.UpSampling2D(3)(x) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x) decoder = keras.Model(decoder_input, decoder_output, name='decoder') decoder.summary() autoencoder_input = keras.Input(shape=(28, 28, 1), name='img') encoded_img = encoder(autoencoder_input) decoded_img = decoder(encoded_img) autoencoder = keras.Model(autoencoder_input, decoded_img, name='autoencoder') autoencoder.summary()
Wie Sie sehen, kann ein Modell verschachtelt sein: Ein Modell kann ein Untermodell enthalten (da das Modell als Ebene betrachtet werden kann).
Ein häufiger Anwendungsfall für das Verschachteln von Modellen ist das Zusammensetzen.
Im Folgenden wird beispielhaft beschrieben, wie eine Reihe von Modellen zu einem Modell kombiniert wird, bei dem die Prognosen gemittelt werden:
def get_model(): inputs = keras.Input(shape=(128,)) outputs = layers.Dense(1, activation='sigmoid')(inputs) return keras.Model(inputs, outputs) model1 = get_model() model2 = get_model() model3 = get_model() inputs = keras.Input(shape=(128,)) y1 = model1(inputs) y2 = model2(inputs) y3 = model3(inputs) outputs = layers.average([y1, y2, y3]) ensemble_model = keras.Model(inputs=inputs, outputs=outputs)
Bearbeiten komplexer Diagrammtopologien
Modelle mit mehreren Ein- und Ausgängen
Die Funktions-API vereinfacht die Manipulation mehrerer Ein- und Ausgänge. Dies ist mit der Sequential API nicht möglich.
Hier ist ein einfaches Beispiel.
Angenommen, Sie erstellen ein System, um Kundenanwendungen nach Priorität zu klassifizieren und an die richtige Abteilung zu senden.
Ihr Modell verfügt über 3 Eingänge:
- Anwendungskopfzeile (Texteingabe)
- Textinhalt der Anwendung (Texteingabe)
- Vom Benutzer hinzugefügte Tags (kategoriale Eingabe)
Das Modell wird 2 Ausgänge haben:
- Prioritätspunktzahl zwischen 0 und 1 (skalare Sigmoid-Ausgabe)
- Die Abteilung, die den Antrag bearbeiten muss (Softmax-Ausgabe für viele Abteilungen)
Lassen Sie uns mit der Functional API ein Modell in mehreren Zeilen erstellen.
num_tags = 12
Zeichnen wir einen Modellgraphen:
keras.utils.plot_model(model, 'multi_input_and_output_model.png', show_shapes=True)
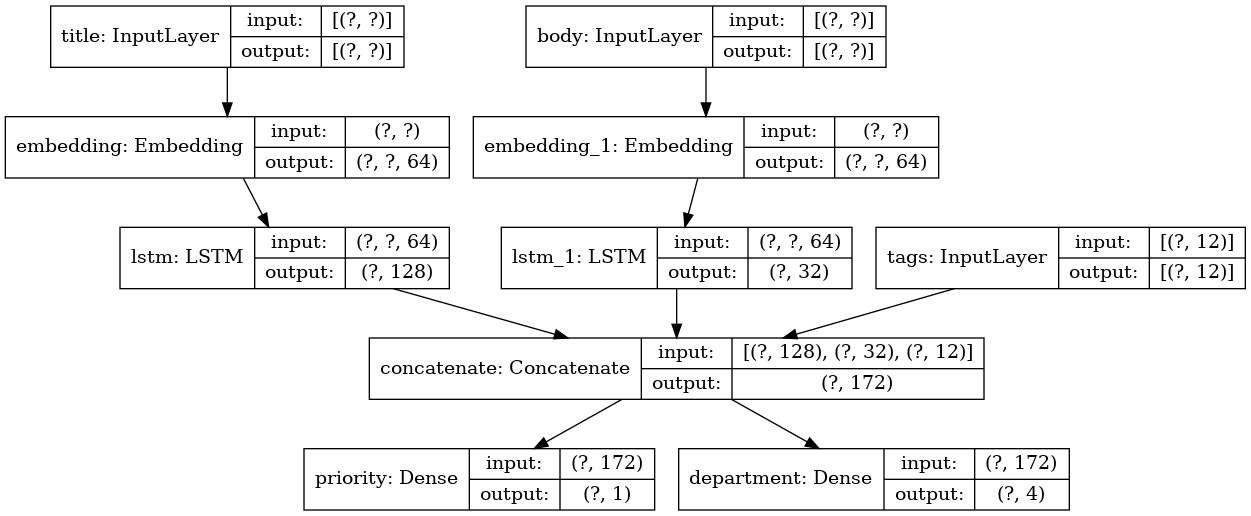
Bei der Kompilierung dieses Modells können wir jedem Ausgang unterschiedliche Verlustfunktionen zuweisen.
Sie können sogar jeder Verlustfunktion ein anderes Gewicht zuweisen, um ihren Beitrag zur gesamten Lernverlustfunktion zu variieren.
model.compile(optimizer=keras.optimizers.RMSprop(1e-3), loss=['binary_crossentropy', 'categorical_crossentropy'], loss_weights=[1., 0.2])
Da wir unseren Ausgabe-Layern Namen gegeben haben, können wir auch Verlustfunktionen angeben:
model.compile(optimizer=keras.optimizers.RMSprop(1e-3), loss={'priority': 'binary_crossentropy', 'department': 'categorical_crossentropy'}, loss_weights=[1., 0.2])
Wir können das Modell trainieren, indem wir Listen von Numpy-Arrays von Eingabedaten und Labels übergeben:
import numpy as np
Wenn Sie fit mit einem
Dataset Objekt aufrufen, sollten entweder ein Tupel von Listen wie
([title_data, body_data, tags_data], [priority_targets, dept_targets]) oder ein Tupel von Wörterbüchern
({'title': title_data, 'body': body_data, 'tags': tags_data}, {'priority': priority_targets, 'department': dept_targets}) zurückgegeben werden
({'title': title_data, 'body': body_data, 'tags': tags_data}, {'priority': priority_targets, 'department': dept_targets}) .
Trainings-Resnet-Modell
Neben Modellen mit mehreren Ein- und Ausgängen vereinfacht die funktionale API die Manipulation von Topologien mit nichtlinearer Konnektivität, d. H. Modellen, in denen Layer nicht in Reihe geschaltet sind. Solche Modelle können auch nicht mit der Sequential API implementiert werden (wie der Name schon sagt).
Ein häufiger Anwendungsfall hierfür sind Restverbindungen.
Erstellen wir ein ResNet-Schulungsmodell für CIFAR10, um dies zu demonstrieren.
inputs = keras.Input(shape=(32, 32, 3), name='img') x = layers.Conv2D(32, 3, activation='relu')(inputs) x = layers.Conv2D(64, 3, activation='relu')(x) block_1_output = layers.MaxPooling2D(3)(x) x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_1_output) x = layers.Conv2D(64, 3, activation='relu', padding='same')(x) block_2_output = layers.add([x, block_1_output]) x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_2_output) x = layers.Conv2D(64, 3, activation='relu', padding='same')(x) block_3_output = layers.add([x, block_2_output]) x = layers.Conv2D(64, 3, activation='relu')(block_3_output) x = layers.GlobalAveragePooling2D()(x) x = layers.Dense(256, activation='relu')(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(10, activation='softmax')(x) model = keras.Model(inputs, outputs, name='toy_resnet') model.summary()
Zeichnen wir einen Modellgraphen:
keras.utils.plot_model(model, 'mini_resnet.png', show_shapes=True)

Und lehre sie:
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) model.compile(optimizer=keras.optimizers.RMSprop(1e-3), loss='categorical_crossentropy', metrics=['acc']) model.fit(x_train, y_train, batch_size=64, epochs=1, validation_split=0.2)
Layer-Sharing
Eine weitere gute Verwendung der funktionalen API sind Modelle, die gemeinsame Ebenen verwenden. Gemeinsame Ebenen sind Instanzen von Ebenen, die im selben Modell wiederverwendet werden: Sie untersuchen Features, die sich auf mehrere Pfade in einem Ebenendiagramm beziehen.
Gemeinsame Ebenen werden häufig zum Codieren von Eingabedaten verwendet, die aus denselben Bereichen stammen (z. B. aus zwei verschiedenen Textteilen mit demselben Wörterbuch), da sie den Informationsaustausch zwischen diesen verschiedenen Daten ermöglichen, wodurch solche Modelle mit weniger Daten trainiert werden können. Wenn an einem der Eingänge ein bestimmtes Wort erscheint, erleichtert dies die Verarbeitung an allen Eingängen, die die allgemeine Ebene durchlaufen.
Um einen Layer in der funktionalen API freizugeben, rufen Sie einfach dieselbe Instanz des Layers mehrmals auf. Beispielsweise wird hier die
Embedding für zwei Texteingaben freigegeben:
Knoten in einem Layerdiagramm abrufen und wiederverwenden
Da das Layer-Diagramm, das Sie in der funktionalen API bearbeiten, eine statische Datenstruktur ist, können Sie darauf zugreifen und es überprüfen. So bauen wir Funktionsmodelle zum Beispiel in Form von Bildern.
Dies bedeutet auch, dass wir auf die Aktivierungen der Zwischenebenen („Knoten“ im Diagramm) zugreifen und diese an anderen Stellen verwenden können. Dies ist beispielsweise zum Extrahieren von Merkmalen äußerst nützlich!
Schauen wir uns ein Beispiel an. Dies ist ein VGG19-Modell mit auf ImageNet vorab trainierten Skalen:
from tensorflow.keras.applications import VGG19 vgg19 = VGG19()
Und dies sind Zwischenmodellaktivierungen, die durch Abfragen der Diagrammdatenstruktur erhalten werden:
features_list = [layer.output for layer in vgg19.layers]
Mit diesen Features können wir ein neues Feature-Extraktionsmodell erstellen, das Aktivierungswerte auf mittlerer Ebene zurückgibt - und das alles in drei Zeilen
feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list) img = np.random.random((1, 224, 224, 3)).astype('float32') extracted_features = feat_extraction_model(img)
Dies ist praktisch, wenn wie in anderen Fällen eine Übertragung im neuralen Stil implementiert wird.
Erweiterung der API durch das Schreiben von benutzerdefinierten Layern
tf.keras verfügt über eine breite Palette an eingebauten Layern. Hier einige Beispiele:
Faltungsebenen:
Conv1D ,
Conv2D ,
Conv3D ,
Conv2DTranspose usw.
MaxPooling1D Schichten:
MaxPooling1D ,
MaxPooling2D ,
MaxPooling3D ,
AveragePooling1D usw.
RNN-Schichten:
GRU ,
LSTM ,
ConvLSTM2D usw.
BatchNormalization ,
Dropout ,
Embedding usw.
Wenn Sie nicht gefunden haben, was Sie benötigen, können Sie die API ganz einfach erweitern, indem Sie eine eigene Ebene erstellen.
Alle Ebenen sind Unterklassen der
Layer Klasse und implementieren Folgendes:
Die
call , die die von der Ebene ausgeführten Berechnungen definiert.
Die
build , mit der die
__init__ erstellt werden (beachten Sie, dass dies nur eine Stilkonvention ist; Sie können Gewichte auch in
__init__ erstellen).
Hier ist eine einfache Implementierung der
Dense Ebene:
class CustomDense(layers.Layer): def __init__(self, units=32): super(CustomDense, self).__init__() self.units = units def build(self, input_shape): self.w = self.add_weight(shape=(input_shape[-1], self.units), initializer='random_normal', trainable=True) self.b = self.add_weight(shape=(self.units,), initializer='random_normal', trainable=True) def call(self, inputs): return tf.matmul(inputs, self.w) + self.b inputs = keras.Input((4,)) outputs = CustomDense(10)(inputs) model = keras.Model(inputs, outputs)
Wenn Ihre benutzerdefinierte Ebene die Serialisierung unterstützen soll, müssen Sie auch die Methode
get_config definieren, die die Konstruktorargumente der
get_config zurückgibt:
class CustomDense(layers.Layer): def __init__(self, units=32): super(CustomDense, self).__init__() self.units = units def build(self, input_shape): self.w = self.add_weight(shape=(input_shape[-1], self.units), initializer='random_normal', trainable=True) self.b = self.add_weight(shape=(self.units,), initializer='random_normal', trainable=True) def call(self, inputs): return tf.matmul(inputs, self.w) + self.b def get_config(self): return {'units': self.units} inputs = keras.Input((4,)) outputs = CustomDense(10)(inputs) model = keras.Model(inputs, outputs) config = model.get_config() new_model = keras.Model.from_config( config, custom_objects={'CustomDense': CustomDense})
Optional können Sie auch die
from_config (cls, config) implementieren, die in Anbetracht ihres Konfigurationswörterbuchs für die
from_config (cls, config) der
from_config (cls, config) verantwortlich ist. Die Standardimplementierung
from_config sieht
from_config aus:
def from_config(cls, config): return cls(**config)
Wann ist die funktionale API zu verwenden?
Wie kann man feststellen, wann es besser ist, mit der funktionalen API ein neues Modell zu erstellen oder einfach direkt eine Unterklasse des
Model zu erstellen?
Im Allgemeinen ist die Funktions-API übergeordneter und benutzerfreundlicher. Sie verfügt über eine Reihe von Funktionen, die von untergeordneten Modellen nicht unterstützt werden.
Durch das Unterklassen des Modells erhalten Sie jedoch eine große Flexibilität beim Erstellen von Modellen, die nicht einfach als gerichtete azyklische Diagramme von Layern beschrieben werden können (Sie können beispielsweise Tree-RNN nicht mit der funktionalen API implementieren, sondern müssen das
Model direkt in Unterklassen unterteilen).
Stärken der funktionalen API:
Die unten aufgeführten Eigenschaften gelten alle für sequenzielle Modelle (die auch Datenstrukturen sind), aber sie gelten für Modelle mit Unterklassen (die Python-Code und keine Datenstrukturen sind).
Die Funktions-API erzeugt kürzeren Code.
Kein
super(MyClass, self).__init__(...) , kein
def call(self, ...): etc.
Vergleichen Sie:
inputs = keras.Input(shape=(32,)) x = layers.Dense(64, activation='relu')(inputs) outputs = layers.Dense(10)(x) mlp = keras.Model(inputs, outputs)
Mit untergeordneter Version:
class MLP(keras.Model): def __init__(self, **kwargs): super(MLP, self).__init__(**kwargs) self.dense_1 = layers.Dense(64, activation='relu') self.dense_2 = layers.Dense(10) def call(self, inputs): x = self.dense_1(inputs) return self.dense_2(x)
Ihr Modell wird so validiert, wie es geschrieben wurde.
In der funktionalen API werden Eingabespezifikationen (Form und D-Typ) im Voraus erstellt (über "Eingabe"), und jedes Mal, wenn Sie den Layer aufrufen, überprüft der Layer, ob die an ihn übergebenen Spezifikationen mit seinen Annahmen übereinstimmen. Ist dies nicht der Fall, erhalten Sie eine nützliche Fehlermeldung .
Dadurch wird sichergestellt, dass jedes Modell, das Sie mit der funktionalen API erstellen, gestartet wird. Das gesamte Debugging (nicht im Zusammenhang mit dem Konvergenz-Debugging) erfolgt statisch während der Modellkonstruktion und nicht zur Laufzeit. Dies ähnelt der Typprüfung im Compiler.
Ihr Funktionsmodell kann grafisch dargestellt und getestet werden.
Sie können das Modell in Form eines Diagramms zeichnen und auf einfache Weise auf die Zwischenknoten des Diagramms zugreifen, um beispielsweise die Aktivierung der Zwischenebenen zu extrahieren und wiederzuverwenden, wie wir im vorherigen Beispiel gesehen haben:
features_list = [layer.output for layer in vgg19.layers] feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
Da das Funktionsmodell eher eine Datenstruktur als ein Teil des Codes ist, kann es sicher serialisiert und als einzelne Datei gespeichert werden, mit der Sie genau dasselbe Modell ohne Zugriff auf den Quellcode neu erstellen können.
Funktionsschwächen der API
Dynamische Architekturen werden nicht unterstützt.
Die funktionale API verarbeitet Modelle als DAG-Layer. Dies gilt für die meisten Deep-Learning-Architekturen, jedoch nicht für alle: Beispielsweise erfüllen rekursive Netzwerke oder Tree-RNNs diese Annahme nicht und können nicht in der funktionalen API implementiert werden.
Manchmal muss man einfach alles von Grund auf neu schreiben.
Wenn Sie erweiterte Architekturen schreiben, möchten Sie möglicherweise etwas tun, das über das Definieren von DAG-Layern hinausgeht: Sie können beispielsweise mehrere benutzerdefinierte Trainings- und Ausgabemethoden für eine Instanz Ihres Modells verwenden. Dies erfordert eine Unterklasse.
Kombinieren und Kombinieren verschiedener API-Stile
Es ist wichtig zu beachten, dass die Auswahl zwischen der funktionalen API oder der Unterklasse des Modells keine binäre Lösung ist, die Sie auf eine Kategorie von Modellen beschränkt.
Alle Modelle in der tf.keras-API können miteinander interagieren, sei es sequentielle Modelle, funktionale Modelle oder von Grund auf neu geschriebene Modelle / Ebenen mit Unterklassen.Sie können immer das Funktionsmodell oder das sequentielle Modell als Teil des untergeordneten Modells / Layers verwenden: units = 32 timesteps = 10 input_dim = 5
, Layer Model Functional API
call :
call(self, inputs, **kwargs) inputs (. ),
**kwargs ( ).
call(self, inputs, training=None, **kwargs) training , .
call(self, inputs, mask=None, **kwargs) mask ( RNN, ).
call(self, inputs, training=None, mask=None, **kwargs) — .
Wenn Sie die Methode "get_config" auf Ihrem benutzerdefinierten Layer oder Modell implementieren, werden die von Ihnen erstellten Funktionsmodelle serialisierbar und geklont.Unten sehen Sie ein kleines Beispiel, in dem wir benutzerdefinierte RNN verwenden, die von Grund auf neu geschrieben wurden. Funktionsmodelle: units = 32 timesteps = 10 input_dim = 5 batch_size = 16 class CustomRNN(layers.Layer): def __init__(self): super(CustomRNN, self).__init__() self.units = units self.projection_1 = layers.Dense(units=units, activation='tanh') self.projection_2 = layers.Dense(units=units, activation='tanh') self.classifier = layers.Dense(1, activation='sigmoid') def call(self, inputs): outputs = [] state = tf.zeros(shape=(inputs.shape[0], self.units)) for t in range(inputs.shape[1]): x = inputs[:, t, :] h = self.projection_1(x) y = h + self.projection_2(state) state = y outputs.append(y) features = tf.stack(outputs, axis=1) return self.classifier(features)
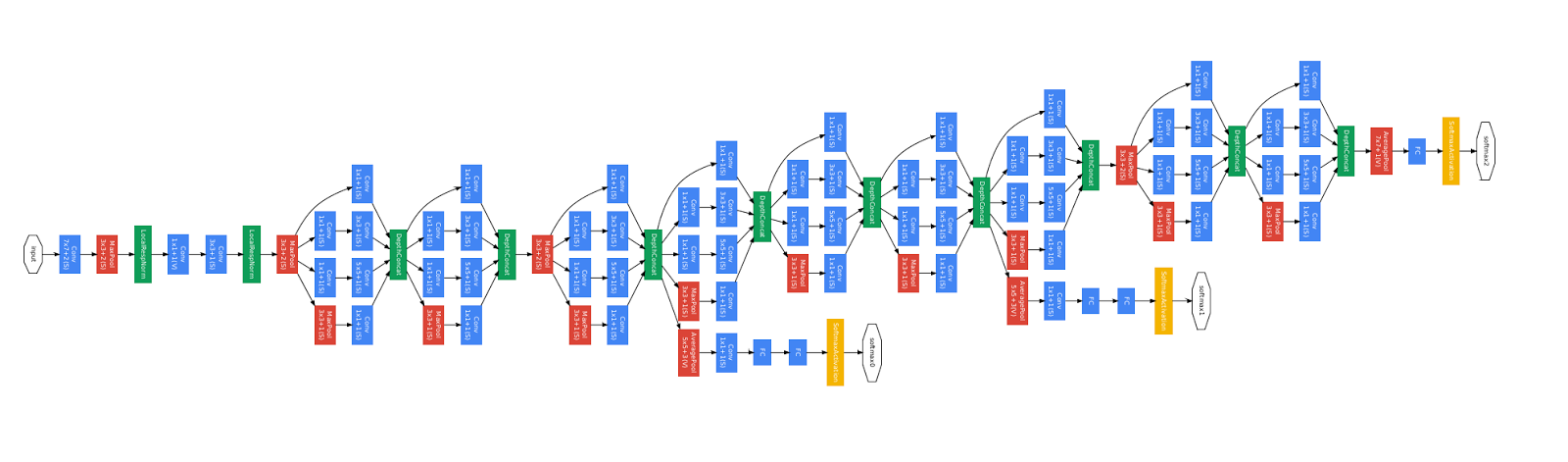
Damit ist unser Functional API Guide abgeschlossen!Jetzt haben Sie eine Reihe leistungsstarker Tools zur Verfügung, mit denen Sie Deep-Learning-Modelle erstellen können.Nach der Überprüfung wird die Übersetzung auch auf Tensorflow.org angezeigt. Wenn Sie an der Übersetzung der Dokumentation der Tensorflow.org-Website ins Russische teilnehmen möchten, wenden Sie sich bitte an eine Person oder einen Kommentar. Korrekturen oder Kommentare sind willkommen. Zur Veranschaulichung haben wir das Bild des GoogLeNet-Modells verwendet, das auch ein gerichteter azyklischer Graph ist.