HighLoad ++ Moskau 2018, Kongresshalle. 9. November, 15:00 Uhr
Abstracts und Präsentation:
http://www.highload.ru/moscow/2018/abstracts/4066Yuri Nasretdinov (VKontakte): In dem Bericht wird über die Erfahrungen bei der Implementierung von ClickHouse in unserem Unternehmen berichtet - warum wir es benötigen, wie viele Daten wir speichern, wie wir es schreiben und so weiter.

Zusätzliche Ressourcen:
Verwenden von Clickhouse als Ersatz für ELK, Big Query und TimescaleDB Yuri Nasretdinov: - Hallo allerseits! Mein Name ist Yuri Nasretdinov, wie sie mich bereits vorgestellt haben. Ich arbeite bei VKontakte. Ich werde darüber sprechen, wie wir Daten von unserer Serverflotte (Zehntausende) in „ClickHouse“ einfügen.
Was sind Protokolle und warum werden sie gesammelt?
Worüber wir sprechen werden: Was wir getan haben, warum wir "ClickHouse" brauchten bzw. warum wir es ausgewählt haben, welche Art von Leistung kann man grob erhalten, ohne etwas speziell zu konfigurieren. Ich erzähle Ihnen mehr über Puffertabellen, über die Probleme, die wir damit hatten, und über unsere Lösungen, die wir aus Open Source entwickelt haben - KittenHouse und Lighthouse.
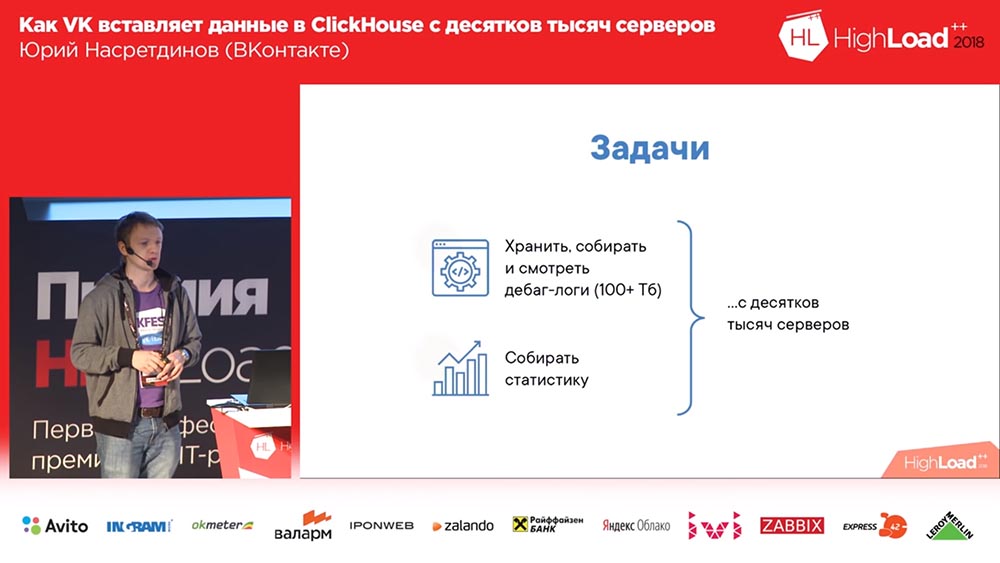
Warum mussten wir überhaupt etwas tun (auf VKontakte ist immer alles in Ordnung, oder?). Wir wollten Debug-Protokolle sammeln (und es gab Hunderte von Terabyte an Daten). Vielleicht ist es irgendwie bequemer, die Statistiken zu lesen. und wir haben Zehntausende von Servern, von denen aus all dies erledigt werden muss.
Warum haben wir uns entschieden? Wir hatten wahrscheinlich Lösungen zum Speichern von Protokollen. Hier - es gibt so ein öffentliches "Backend VK". Ich kann es nur empfehlen, sich anzumelden.

Was sind Protokolle? Dies ist eine Engine, die leere Arrays zurückgibt. Motoren in „VK“ sind das, was andere Microservices nennen. Und so ein Sticker lächelt (ziemlich viele Likes). Wie so Hör zu!

Womit können Protokolle im Allgemeinen gespeichert werden? Es ist unmöglich, den Khadup nicht zu erwähnen. Dann zum Beispiel Rsyslog (Speicherung in den Dateien dieser Protokolle). LSD Wer weiß, was LSD ist? Nein, nicht dieses LSD. Dateien werden ebenfalls gespeichert. ClickHouse ist eine seltsame Version.
Clickhouse und Wettbewerber: Anforderungen und Möglichkeiten
Was wollen wir Wir möchten, dass wir bei der Operation kein spezielles Dampfbad benötigen, damit es mit minimalem Setup möglichst sofort funktioniert. Wir wollen viel schreiben und schnell schreiben. Und wir wollen es alle Monate, Jahre, das heißt für eine lange Zeit behalten. Wir möchten vielleicht ein Problem lösen, mit dem sie zu uns gekommen sind. Sie sagten: "Hier funktioniert etwas nicht für uns", aber das war vor 3 Monaten. Und wir möchten es vor 3 Monaten sehen können ". Datenkomprimierung - es ist verständlich, warum dies von Vorteil ist - da der belegte Speicherplatz reduziert wird.

Und wir haben eine so interessante Anforderung: Wir schreiben manchmal die Ausgabe einiger Befehle (z. B. Protokolle), es können ganz ruhig mehr als 4 Kilobyte sein. Und wenn dieses Ding auf UDP funktioniert, muss es nicht ausgegeben werden ... es wird keinen "Overhead" für die Verbindung haben, und für eine große Anzahl von Servern wird dies ein Plus sein.

Mal sehen, was Open Source uns bietet. Erstens haben wir eine Logs Engine - das ist unsere Engine; Er weiß im Grunde alles, auch lange Zeilen können schreiben. Nun, die Daten werden nicht transparent komprimiert - wir können große Spalten selbst komprimieren, wenn wir möchten ... wir möchten natürlich nicht (wenn möglich). Das einzige Problem ist, dass er nur das preisgeben kann, was ihm in Erinnerung bleibt. Der Rest, um zu lesen, müssen Sie das Binlog dieser Engine erhalten und dementsprechend dauert es eine ganze Weile.

Was sind die anderen Optionen? Zum Beispiel Khadup. Benutzerfreundlichkeit ... Wer glaubt, dass die Hadoup einfach zu konfigurieren ist? Bei der Aufnahme gibt es natürlich keine Probleme. Beim Lesen stellen sich manchmal Fragen. Im Prinzip würde ich das höchstwahrscheinlich nicht sagen, besonders für die Protokolle. Langzeitspeicherung - natürlich, Datenkomprimierung - ja, lange Zeilen - es ist klar, dass Sie schreiben können. Aber um von einer großen Anzahl von Servern aufzunehmen ... Jedenfalls müssen wir etwas selbst tun!
Rsyslog. Tatsächlich haben wir es als Fallback verwendet, sodass ein Binlog ohne Speicherauszug gelesen werden kann, aber nicht in lange Zeilen geschrieben werden kann. Im Prinzip können nicht mehr als 4 Kilobyte geschrieben werden. Die Datenkomprimierung muss auf die gleiche Weise erfolgen. Das Lesen erfolgt aus Dateien.

Dann gibt es die "schlechte" Entwicklung von LSD. Das Gleiche ist im Wesentlichen das Gleiche wie „Rsyslog“: Es unterstützt lange Leitungen, weiß jedoch nicht, wie UDP verwendet wird, und aus diesem Grund müssen dort leider viele Dinge umgeschrieben werden. LSD muss erneut erstellt werden, damit Sie von Zehntausenden von Servern aufzeichnen können.

Oh hier! Eine lustige Option ist ElasticSearch. Nun, wie soll ich sagen? Beim Lesen ist alles in Ordnung, das heißt, er liest schnell, aber beim Schreiben nicht sehr gut. Erstens sind die Daten sehr schwach, wenn sie komprimiert werden. Höchstwahrscheinlich erfordert eine umfassende Suche umfangreichere Datenstrukturen als das ursprüngliche Volumen. Es ist schwer auszunutzen, es treten häufig Probleme auf. Und wieder ein Eintrag im "Elastic" - das müssen wir alle selbst machen.

Hier ClickHouse - natürlich die ideale Option. Die einzige Sache ist, dass die Aufzeichnung von Zehntausenden von Servern ein Problem darstellt. Aber sie ist mindestens eine, wir können versuchen, es irgendwie zu lösen. Der Rest des Berichts befasst sich mit diesem Problem. Welche Gesamtleistung von ClickHouse können Sie erwarten?
Wie werden wir einbetten? MergeTree
Wie viele von Ihnen haben noch nichts von ClickHouse gehört, wissen es nicht? Müssen Sie sagen, nicht notwendig? Sehr schnell. Der Einsatz dort ist 1-2 Gigabit pro Sekunde, Bursts von bis zu 10 Gigabit pro Sekunde können dieser Konfiguration tatsächlich widerstehen - es gibt zwei 6-Core-Xeons (das sind nicht einmal die leistungsstärksten), 256 Gigabyte RAM, 20 Terabyte pro Sekunde RAID (niemand konfiguriert, Standardeinstellungen). Alexey Milovidov, der Entwickler von ClickHouse, hat wahrscheinlich geweint, dass wir nichts konfiguriert haben (bei uns hat alles so funktioniert). Dementsprechend kann eine Abtastgeschwindigkeit von beispielsweise ungefähr 6 Milliarden Zeilen pro Sekunde erhalten werden, wenn die Daten gut komprimiert sind. Wenn Sie% auf einer Textzeile tun möchten - 100 Millionen Zeilen pro Sekunde, das heißt, es scheint sehr schnell.

Wie werden wir einbetten? Nun, das wissen Sie in "VK" - in PHP. Wir von jedem PHP-Mitarbeiter werden HTTP in "ClickHouse" einfügen, in die MergeTree-Platte für jeden Eintrag. Wer sieht das Problem in dieser Schaltung? Aus irgendeinem Grund hoben nicht alle ihre Hände. Sagen wir es Ihnen.
Erstens gibt es viele Server - dementsprechend gibt es viele Verbindungen (schlecht). In MergeTree ist es dann besser, Daten nicht mehr als einmal pro Sekunde einzufügen. Und wer weiß warum? Ok gut Ich werde Ihnen etwas mehr darüber erzählen. Eine weitere interessante Frage ist, dass wir sozusagen keine Analysen durchführen, keine Datenanreicherung vornehmen müssen, keine Zwischenserver benötigen und direkt in „ClickHouse“ eingebettet werden möchten (am besten - je gerader, desto besser).

Wie wird das Einfügen in MergeTree implementiert? Warum ist es besser, es nicht mehr als einmal pro Sekunde oder weniger einzufügen? Tatsache ist, dass „ClickHouse“ eine spaltenweise Datenbank ist und die Daten in aufsteigender Reihenfolge des Primärschlüssels sortiert. Beim Einfügen wird die Anzahl der Dateien anhand der Anzahl der Spalten erstellt, in denen die Daten in aufsteigender Reihenfolge des Primärschlüssels sortiert sind. (Es wird ein separates Verzeichnis erstellt.) eine Reihe von Dateien auf der Festplatte für jede Beilage). Dann geht die nächste Einfügung und im Hintergrund verschmelzen sie zu einer größeren "Partition". Da die Daten sortiert sind, können Sie zwei sortierte Dateien ohne großen Speicherverbrauch „jonglieren“.
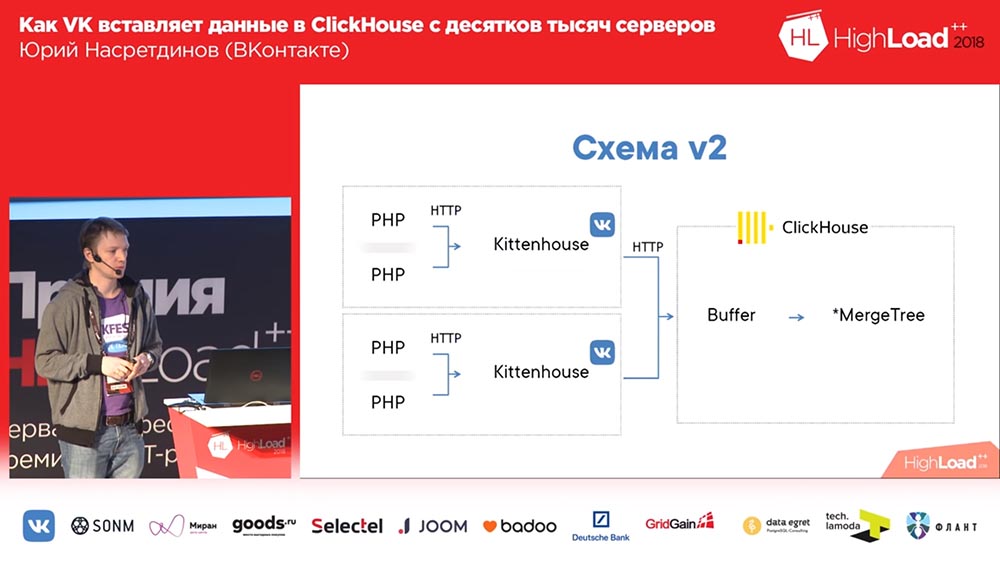
Wie Sie sich aber vorstellen können, endet ClickHouse schnell (oder Ihr Server), wenn Sie 10 Dateien für jede Einfügung schreiben. Es wird daher empfohlen, große Bündel einzufügen. Dementsprechend haben wir nie das erste Schema in der Produktion gestartet. Wir haben sofort eine gestartet, die hier die Nummer 2 hat:

Stellen Sie sich hier vor, dass es ungefähr tausend Server gibt, auf denen wir gestartet haben, es gibt nur PHP. Und auf jedem Server gibt es unseren lokalen Agenten, den wir "Kittenhouse" nennen, der eine Verbindung zu "ClickHouse" hält und alle paar Sekunden Daten einfügt. Es werden keine Daten in MergeTree eingefügt, sondern in die Spooler-Tabelle, die dazu dient, nicht sofort direkt in MergeTree einzufügen.
Mit Puffertabellen arbeiten
Was ist das? Puffertabellen sind ein Teil des Speichers, der gemischt wird (das heißt, Sie können sie häufig einfügen). Sie bestehen aus mehreren Teilen, und jedes Teil arbeitet als unabhängiger Puffer und wird unabhängig gespült (wenn sich viele Teile im Puffer befinden, werden viele Einfügungen pro Sekunde vorgenommen). Sie können aus diesen Tabellen lesen - dann lesen Sie die Vereinigung des Inhalts des Puffers und der übergeordneten Tabelle, aber in diesem Moment ist der Datensatz blockiert, daher ist es besser, nicht von dort zu lesen. Und sehr gutes QPS zeigen die Puffertabellen, dh bis zu 3.000 QPS haben Sie überhaupt keine Probleme beim Einfügen. Es ist klar, dass bei einem Stromausfall auf dem Server die Daten verloren gehen können, da sie nur im Speicher abgelegt wurden.

Gleichzeitig wird das Schema mit dem Puffer durch ALTER kompliziert, da Sie zuerst die alte Puffertabelle mit dem alten Schema löschen müssen (die Daten gehen nicht gleichzeitig verloren, da sie gelöscht werden, bevor die Tabelle gelöscht wird). Dann "ändern" Sie die benötigte Tabelle und erstellen die Puffertabelle erneut. Dementsprechend fließen Ihre Daten, obwohl es keine Puffertabelle gibt, nirgendwo hin, aber Sie können sie sogar lokal auf der Festplatte speichern.

Was ist Kittenhouse und wie funktioniert es?
Was ist KittenHouse? Dies ist ein Proxy. Ratet mal welche Sprache? Ich habe die meisten Hype-Themen in meinem Bericht gesammelt - das ist "Clickhouse", Go, vielleicht kann ich mich an etwas anderes erinnern. Ja, es ist in Go geschrieben, da ich nicht wirklich weiß, wie man in C schreibt, ich möchte nicht.

Dementsprechend hält es eine Verbindung mit jedem Server, der in den Speicher schreiben kann. Wenn wir beispielsweise Fehlerprotokolle in „Clickhouse“ schreiben, und „Clickhouse“ keine Zeit zum Einfügen von Daten hat (wenn schließlich zu viele geschrieben werden), schwellen wir nicht aus dem Speicher an - wir werfen den Rest einfach weg. Denn wenn wir mehrere Gigabit pro Sekunde an Fehlern schreiben, können wir wahrscheinlich einige werfen. Kittenhouse weiß wie. Außerdem weiß es, wie es zuverlässig liefert, das heißt, es schreibt auf eine Festplatte auf dem lokalen Computer und versucht von Zeit zu Zeit (dort, alle paar Sekunden), Daten aus dieser Datei zu liefern. Und zuerst haben wir das übliche Werte-Format verwendet - nicht irgendein Binärformat, sondern Textformat (wie in regulärem SQL).

Aber dann ist das passiert. Wir haben eine zuverlässige Übermittlung verwendet, Protokolle geschrieben und uns dann entschieden (es war ein so bedingtes Testcluster) ... Sie haben es für ein paar Stunden gelöscht und zurückgenommen, und das Einfügen wurde von Tausenden von Servern gestartet - es stellte sich heraus, dass Klickhouse immer noch einen „Thread on“ hatte connection “- dementsprechend führt die aktive Einfügung bei tausend Verbindungen zu einer durchschnittlichen Auslastung des Servers von etwa eineinhalb Tausend. Überraschenderweise akzeptierte der Server Anfragen, aber solche Daten wurden dennoch nach einiger Zeit eingefügt; aber es war sehr schwierig für den Server, es zu warten ...
Nginx hinzufügen
Eine solche Lösung für das Thread-per-Connection-Modell ist nginx. Wir haben nginx vor das Clickhouse gestellt, gleichzeitig den Abgleich auf zwei Replikate eingestellt (wir haben die Einfügungsgeschwindigkeit um das 2-fache erhöht, obwohl dies nicht der Fall sein sollte) und die Anzahl der Verbindungen zum Clickhouse, zum Upstream und entsprechend mehr begrenzt als in 50 Verbindungen scheint es keinen Sinn zu machen, einzufügen.

Dann stellten wir fest, dass dieses Schema im Allgemeinen Nachteile hat, weil wir hier einen Nginx haben. Dementsprechend verlieren wir Daten, wenn dieser Nginx trotz Vorhandensein von Replikaten festlegt, oder schreiben zumindest nirgendwo hin. Daher haben wir unseren Lastenausgleich durchgeführt. Wir haben auch verstanden, dass „Clickhouse“ immer noch für Protokolle geeignet ist, und der „Dämon“ begann auch, seine eigenen Protokolle in „Clickhouse“ zu schreiben - sehr praktisch, um ehrlich zu sein. Wir benutzen es immer noch für andere "Dämonen".

Dann entdeckten sie ein so interessantes Problem: Wenn Sie eine nicht ganz standardmäßige Methode zum Einfügen im SQL-Modus verwenden, wird ein vollwertiger AST SQL-basierter Parser erzwungen, der ziemlich langsam ist. Dementsprechend haben wir Einstellungen hinzugefügt, damit dies nie passiert. Wir haben Load Balancing und Health Checks durchgeführt, sodass wir nach dem Tod immer noch Daten hinterlassen. Wir haben genug Tische, so dass wir verschiedene „Clickhouse“ -Cluster benötigen. Und wir haben angefangen, über andere Verwendungszwecke nachzudenken. Beispielsweise wollten wir Protokolle von Nginx-Modulen schreiben, die nicht über unseren RPC kommunizieren können. Nun, ich möchte ihnen irgendwie beibringen, wie man sendet - zum Beispiel über UDP, um Ereignisse auf localhost zu empfangen und sie dann an das „Clickhouse“ zu senden.
Ein Schritt vor der Entscheidung
Das endgültige Schema sah nun so aus (die vierte Version dieses Schemas): Auf jedem Server vor dem Clickhouse befindet sich Nginx (außerdem auf demselben Server) und es werden lediglich Anforderungen an den lokalen Host weitergeleitet, wobei die Anzahl der Verbindungen auf 50 begrenzt ist. Und jetzt funktionierte dieses Schema bereits, es war ziemlich gut damit.

Wir haben ungefähr einen Monat so gelebt. Jeder war glücklich darüber, Tabellen hinzuzufügen, hinzuzufügen, hinzuzufügen ... Im Allgemeinen stellte sich heraus, dass die Art und Weise, wie wir Puffertabellen hinzufügten, nicht optimal war (sagen wir mal so). Wir haben 16 Stücke in jeder Tabelle und ein Blitzintervall für ein paar Sekunden gemacht; Wir hatten 20 Tische und 8 Beilagen pro Sekunde gingen zu jedem Tisch - und in diesem Moment begann das „Clickhouse“ ... die Aufzeichnungen begannen leer zu werden. Sie haben nicht einmal bestanden ... Nginx hatte standardmäßig eine so interessante Sache, dass, wenn die Verbindungen im Upstream endeten, es nur "502" für alle neuen Anfragen gibt.

Und hier bei uns (ich habe mir gerade die Protokolle in dem „Clickhouse“ angesehen, das ich mir angesehen habe) schlägt irgendwo ein halbes Prozent der Anfragen fehl. Entsprechend hoch war die Festplattenauslastung, es gab viele Zusammenschlüsse. Nun, was habe ich getan? Natürlich habe ich nicht verstanden, warum die Verbindung und der Upstream enden.
Ersetzen von Nginx durch Reverse Proxy
Ich entschied, dass wir dies selbst verwalten müssen, es nicht an nginx weitergeben - nginx weiß nicht, welche Tabellen sich im „Clickhouse“ befinden, und ersetzte nginx durch einen Reverse-Proxy, den ich auch geschrieben habe.
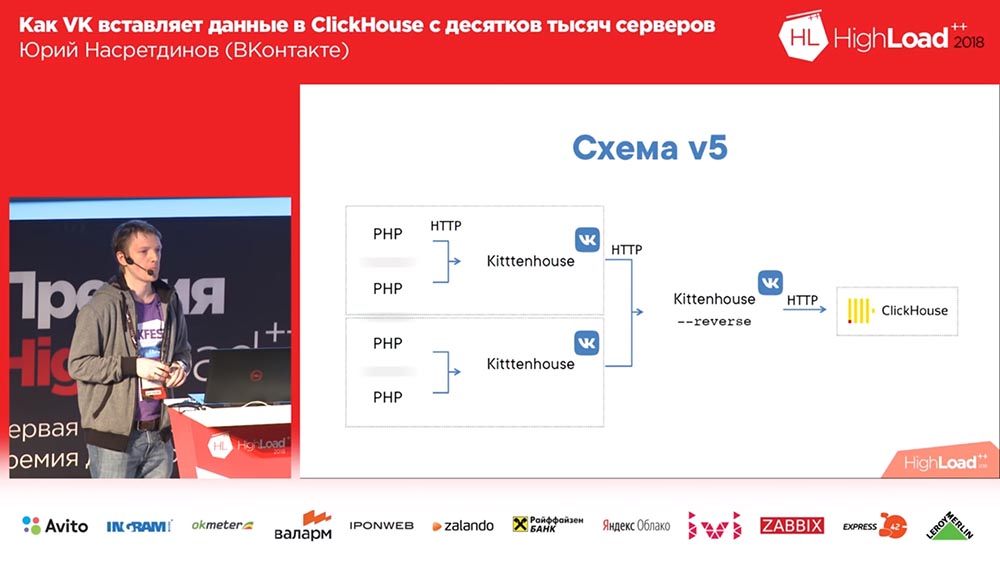
Was macht er Es funktioniert auf der Basis der fasthttp-Bibliothek "goosh", also fast so schnell wie Nginx. Sorry, Igor, wenn Sie hier sind (Anmerkung: Igor Sysoev ist ein russischer Programmierer, der den Nginx-Webserver erstellt hat). Er kann verstehen, um welche Art von Abfragen es sich handelt - EINFÜGEN oder AUSWÄHLEN -. Er verwaltet verschiedene Verbindungspools für verschiedene Arten von Abfragen.

Selbst wenn wir keine Zeit haben, um die Anforderungen abzuschließen, werden die "Auswahlen" bestanden und umgekehrt. Und es gruppiert die Daten in Puffertabellen - mit einem kleinen Puffer: Wenn es Fehler, Syntaxfehler usw. gab, so dass sie den Rest der Daten geringfügig beeinflussten, da wir beim Einfügen einfach in die Puffertabellen kleine “ bachi ”, und alle Fehler von Syntaxfehlern betrafen nur dieses kleine Stück; und hier werden sie bereits den großen Puffer beeinflussen. Klein ist 1 Megabyte, also nicht so klein.

Das Einfügen eines Synchron und im Wesentlichen das Ersetzen von Nginx funktioniert im Wesentlichen genauso wie zuvor - das Kittenhouse muss hierfür nicht lokal geändert werden. Und da es fasthttp verwendet, ist es sehr schnell - Sie können über Reverse-Proxys mehr als 100.000 Anfragen pro Sekunde für einzelne Einfügungen stellen. Theoretisch können Sie eine Zeile in einen Kittenhouse-Reverse-Proxy einfügen, was wir aber sicherlich nicht tun.

Das Schema begann so auszusehen: Kittenhouse, ein Reverse-Proxy, gruppiert viele Anforderungen in Tabellen und fügt sie wiederum in die Haupttabellen ein.
Killer - temporäre Lösung, Kitten - permanent
Es gab so ein interessantes Problem ... Hat jemand von euch FastTTP benutzt? Wer hat fasthttp bei POST-Anfragen verwendet? Wahrscheinlich hat sich dies nicht gelohnt, da der Anforderungshauptteil standardmäßig gepuffert wird und wir die Puffergröße auf 16 Megabyte festgelegt haben. Irgendwann war der Einsatz nicht mehr rechtzeitig, und von allen Zehntausenden von Servern gingen 16-Megabyte-Blöcke ein, die alle im Speicher zwischengespeichert waren, bevor sie an das Clickhouse weitergeleitet wurden. Entsprechend lief der Speicher aus, der Out-Of-Memory-Killer kam, tötete den Reverse-Proxy (oder „Clickhouse“, der theoretisch mehr „essen“ konnte als der Reverse-Proxy). Der Zyklus wurde wiederholt. Kein sehr schönes Problem. Dies ist uns allerdings erst nach wenigen Betriebsmonaten aufgefallen.
Was habe ich gemacht Auch hier möchte ich nicht wirklich verstehen, was genau passiert ist. Es scheint mir ziemlich offensichtlich, dass es keine Notwendigkeit gibt, in den Speicher zu puffern. Ich konnte fasthttp nicht patchen, obwohl ich es versucht habe. Aber ich habe einen Weg gefunden, es so zu machen, dass es nicht nötig ist, irgendetwas zu patchen, und mir eine eigene Methode in HTTP ausgedacht - KITTEN. Nun, es ist logisch - "VK", "Kätzchen" ... wie sonst?

Wenn eine Anfrage mit der Kitten-Methode an den Server gesendet wird, sollte der Server logischerweise mit "meow" antworten. Wenn er darauf antwortet, wird angenommen, dass er dieses Protokoll versteht, und dann fange ich die Verbindung ab (es gibt eine solche Methode in fasthttp), und die Verbindung geht in den "Raw" -Modus. Warum brauche ich das? Ich möchte steuern, wie das Lesen von TCP-Verbindungen erfolgt. TCP hat eine wunderbare Eigenschaft: Wenn niemand von dieser Seite liest, beginnt der Datensatz zu warten, und der Speicher wird nicht speziell dafür ausgegeben.
Und so lese ich irgendwo von 50 Klienten gleichzeitig (von fünfzig, weil fünfzig sicherlich genug sein sollten, auch wenn es von einem anderen DC kommt) ... Der Verbrauch ist mit diesem Ansatz mindestens 20 Mal gesunken, aber ich ehrlich Ich konnte nicht genau messen, wie viel, weil es schon sinnlos ist (es ist schon auf der Ebene der Fehler geworden). Das Protokoll ist binär, dh es gibt einen Tabellennamen und Daten. Da es keine http-Header gibt, habe ich keinen Web-Socket verwendet (ich muss nicht mit Browsern kommunizieren - ich habe ein Protokoll erstellt, das unseren Anforderungen entspricht). Und mit ihm war alles in Ordnung.
Puffertabelle ist traurig
Kürzlich sind wir auf ein weiteres interessantes Merkmal von Puffertabellen gestoßen. Und dieses Problem ist schon viel schmerzhafter als der Rest. : «», «», , (, 60 ); Alter … «», «», , «» – , - , «» . ? ?

, , , . , , , «» ( – , , ), … , «» ( - «» ) – , - : ( , ), «» , - , . , «», – .

(, ) – «» query_thread_log. , - . 840 (100 ). , (, , , ) «» (inserts). , «» – «» . , – , . Warum? , ! .

, ? «». .
«KitttenHouse»
, ? . ! : , , - . , .

, «», – , (, - ) , , – .

? . , , 10 , – -, , . , , , , – , «», 100 - – , , , . , . , .
, , . : , - , , , read only . ? . – - , - … ( , «», ClickHouse) ? ? , . . : , . , . .
. . , - ?.. «»? - … «»? , , . , . , .

– . , . , : , , ( ), – , .

Sequel Pro, «», . : «, -?» ? 2018-? , «» (MySQL) , «», ! «», – , .
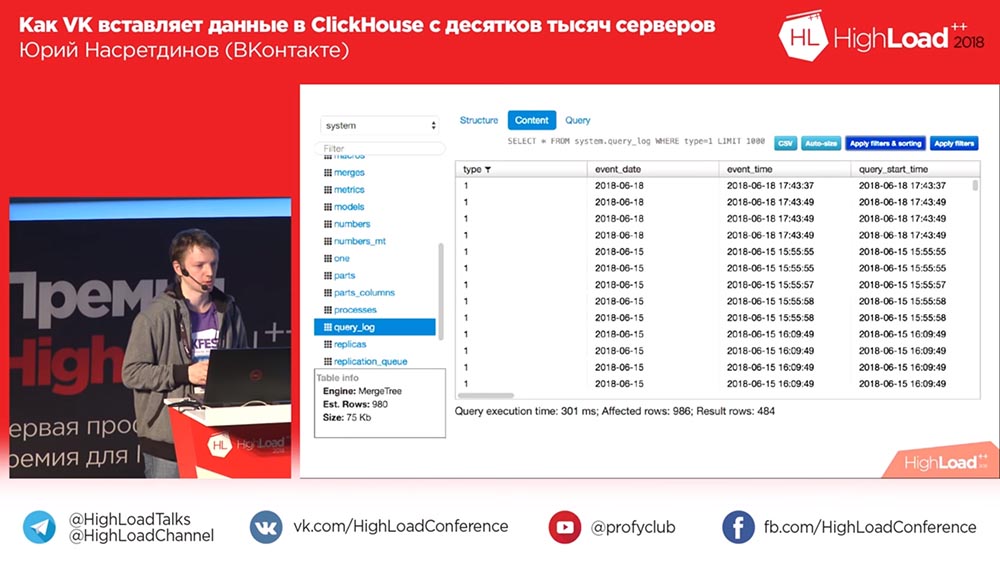
, , , , , , , , affected rows ( ), . .
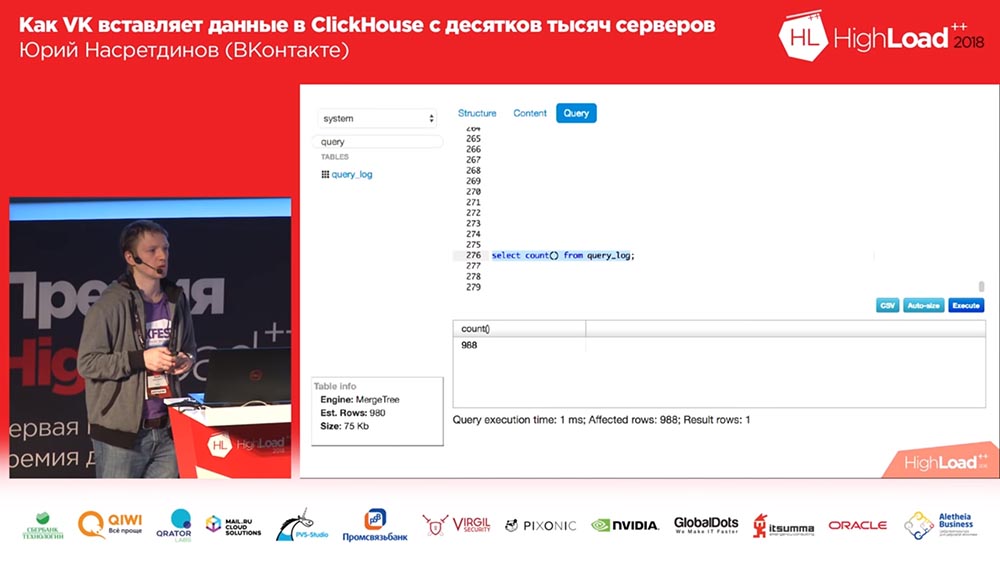
. «», . - - . .
«»
, «», , . , , – . , … , , .

TCP? , «» UDP. TCP… , , : «, ! , UDP». , TCP . , , – - ; , .
«» «» HighLoad Siberia, « »… , … , , . - , - , – , ( , , ).
. Vielen Dank! Github
. «» .
 :
: – , . , VHS.
( – ): – VHS, ?
 :
: – , «» – ! , 5 !
Fragen
Frage des Publikums (im Folgenden - H): - Guten Tag. Vielen Dank für den Bericht. Ich habe zwei Fragen. Ich beginne mit einem leichtfertigen: Beeinflusst die Anzahl der Buchstaben t im Namen „Kittenhouse“ in den Schemata (3, 4, 7 ...) die Zufriedenheit der Katzen?
UN: - Die Menge von was?
Z: - Die Buchstaben t. Es gibt drei t, irgendwo drei t.
UN: - Habe ich das wirklich korrigiert? Na klar tut es das! Das sind verschiedene Produkte - ich habe dich die ganze Zeit angelogen. Okay, ich mache Witze - das tut es nicht. Ah, hier! Nein, es ist dasselbe, ich bin versiegelt.
 Z:
Z: - Danke. Die zweite Frage ist ernst. Soweit ich weiß, befinden sich die Puffertabellen in „Clickhouse“ ausschließlich im Arbeitsspeicher, werden nicht auf der Festplatte zwischengespeichert und sind dementsprechend nicht persistent.
UN: - Ja.
Z: - Gleichzeitig wird auf Ihrem Client eine Pufferung auf der Festplatte durchgeführt, was eine gewisse Garantie für die Zustellung derselben Protokolle impliziert. Im Clickhouse ist dies jedoch nicht garantiert. Erklären Sie, wie die Garantie ausgeführt wird, aufgrund welcher Umstände? Dieser Mechanismus ist detaillierter
UN: - Ja, theoretisch gibt es keine Widersprüche, denn Sie können in der Realität eine Million verschiedene Wege erkennen, wenn das „Clickhouse“ abstürzt. Wenn das „Clickhouse“ abstürzt (wenn es nicht korrekt ausgeführt wird), können Sie grob gesagt Ihr Protokoll, das Sie notiert haben, zurückspulen und von dem Moment an beginnen, an dem alles in Ordnung war. Lass es uns vor einer Minute zurückspulen, das heißt, es wird angenommen, dass alles in einer Minute aufleuchtete.
Z: - Das heißt, das Kätzchenhaus hält das Fenster länger und kann es im Falle eines Sturzes erkennen und abwickeln?
UNO: - Aber das ist in der Theorie. In der Praxis tun wir dies nicht und die zuverlässige Lieferung erfolgt von null bis unendlich. Aber im Durchschnitt eins. Wir sind zufrieden, dass wir ein wenig verlieren, wenn das Clickhouse aus irgendeinem Grund abstürzt oder die Server neu starten. In allen anderen Fällen wird nichts passieren.
Z: - Hallo. Von Anfang an kam es mir so vor, als würden Sie UDP von Anfang an verwenden. Sie haben http, all das ... Und die meisten Probleme, die Sie beschrieben haben, wie ich es verstehe, wurden durch diese spezielle Lösung verursacht ...
UN: - Was verwenden wir TCP?
Z: - In der Tat ja.
UN: - Nein.
Z: - Mit fasthttp hattest du Probleme, mit der Verbindung hattest du Probleme. Wenn Sie nur UDP verwenden, sparen Sie sich Zeit. Nun, es würde Probleme mit langen Nachrichten oder etwas anderem geben ...
UN: - Womit?
 Z:
Z: - Bei langen Nachrichten, da es möglicherweise nicht in die MTU passt, noch etwas ... Nun, da können deine Probleme auftauchen. Die Frage ist: Warum ist es nicht UDP?
UN: - Ich glaube, dass die Autoren, die TCP / IP entwickelt haben, viel schlauer sind als ich und wissen, wie man Pakete besser serialisiert (so gehen sie), gleichzeitig das Sendefenster anpasst, das Netzwerk nicht überlastet und Feedback darüber gibt, was liest, zählt nicht von der anderen Seite ... Alle diese Probleme wären meiner Meinung nach auch in UDP, nur müsste ich noch mehr Code schreiben, als ich bereits geschrieben habe, um das Gleiche selbst zu implementieren, und höchstwahrscheinlich wäre es schlecht. Ich schreibe nicht mal gerne in C, nicht so wie dort ...
Z: - Einfach praktisch! Ok gesendet und erwarte nichts - du hast absolut asynchron. Eine Nachricht kam zurück, dass alles in Ordnung ist - das heißt, es ist gekommen; kam nicht - es bedeutet schlecht.
UN: - Ich brauche beides und ein anderes - Ich muss in der Lage sein, beides mit und ohne Zustellgarantie zu versenden. Dies sind zwei verschiedene Szenarien. Einige Protokolle brauche ich nicht zu verlieren oder nicht innerhalb der Vernunft zu verlieren.
Z: - Ich werde mir keine Zeit nehmen. Dies sollte länger diskutiert werden. Vielen Dank.
Moderator: - Wer hat Fragen - Stifte am Himmel!
 Z:
Z: - Hi, ich bin Sasha. Irgendwann in der Mitte des Berichts gab es das Gefühl, dass es zusätzlich zu TCP möglich war, eine fertige Lösung zu verwenden - eine Art „Kafka“.
UN: "Nun ... ich habe dir gesagt, dass ich keine Zwischenserver verwenden möchte, weil ... für Kafka - es stellt sich heraus, dass wir zehntausend Hosts haben; In der Tat haben wir mehr - Zehntausende von Hosts. Bei Kafka ohne Stellvertreter kann es auch weh tun. Darüber hinaus gibt es vor allem noch "Latenz", gibt die zusätzlichen Hosts, die Sie benötigen. Und ich will sie nicht haben - ich will ...
Z: - Aber am Ende hat es sich trotzdem herausgestellt.
UN: - Nein, es gibt keine Gastgeber! Alles funktioniert auf den Clickhouse-Hosts.
Z: - Aber was ist mit dem Kätzchenhaus, dessen Rückseite ist - wo wohnt er?
 UN:
UN: - Auf dem Host von Klickhouse schreibt er nichts auf die Festplatte.
Z: - Sagen wir mal.
Moderator: - Zufrieden Sie? Können wir ein Gehalt geben?
Z: - Ja, ja. Tatsächlich gibt es viele Krücken, um das Gleiche zu erreichen, und jetzt widerspricht die vorherige Antwort zum Thema TCP meiner Meinung nach dieser Situation. Es fühlt sich einfach so an, als könntest du alles auf deinem Knie in viel kürzerer Zeit machen.
UN: - Und warum wollte ich "Kafka" nicht verwenden, weil es im Telegramm "Clickhouse" ziemlich viele Beschwerden gab, dass zum Beispiel Nachrichten von "Kafka" verloren gingen. Nicht von Kafka selbst, sondern in die Integration von Kafka und Klikhaus; oder etwas hat dort keine Verbindung hergestellt. Grob gesagt wäre es dann für den Kunden notwendig, dass Kafka dann schreibt. Ich glaube nicht, dass eine einfachere und zuverlässigere Lösung erzielt werden würde.
Z: - Sag mir, warum hast du nicht einige Linien oder einen solchen gemeinsamen Bus ausprobiert? Da Sie sagen, dass es bei Ihnen möglich war, die Protokolle selbst asynchron durch die Warteschlange zu fahren und als Antwort auch asynchron durch die Warteschlange zu bekommen?
 UN:
UN: - Bitte schlagen Sie vor, welche Warteschlangen verwendet werden könnten.
Z: - Irgendwelche, auch ohne Garantie, dass sie in Ordnung sind. Beliebige Redis, RMQ ...
UN: - Ich habe das Gefühl, dass Redis höchstwahrscheinlich nicht in der Lage sein wird, ein solches Einfügungsvolumen selbst auf einem Host (im Sinne mehrerer Server) abzurufen, der das Clickhouse abruft. Ich kann dies nicht mit Beweisen bestätigen (ich habe es nicht bewertet), aber es scheint mir, dass Redis hier nicht die beste Lösung ist. Grundsätzlich können Sie dieses System als spontane Nachrichtenwarteschlange betrachten, die jedoch nur für "Clickhouse" gilt.
Moderator: - Yuri, vielen Dank. Ich schlage vor, die Fragen und Antworten dazu zu beenden und zu sagen, welche der Personen, die die Frage gestellt haben, uns ein Buch geben werden.
UN: - Ich möchte der ersten Person, die eine Frage gestellt hat, ein Buch geben.
Moderator: - Großartig! Großartig! Großartig! Vielen Dank!
Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Mögen Sie unsere Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden
Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen, ein
einzigartiges Analogon zu Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 Dollar oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2-mal billiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2 x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV ab 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
das Erstellen von Infrastruktur-Bldg. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?