vorherige Kapitel
30. Lernkurveninterpretation: Große Abweichung
Angenommen, Ihre Fehlerkurve für ein Validierungsmuster sieht folgendermaßen aus:
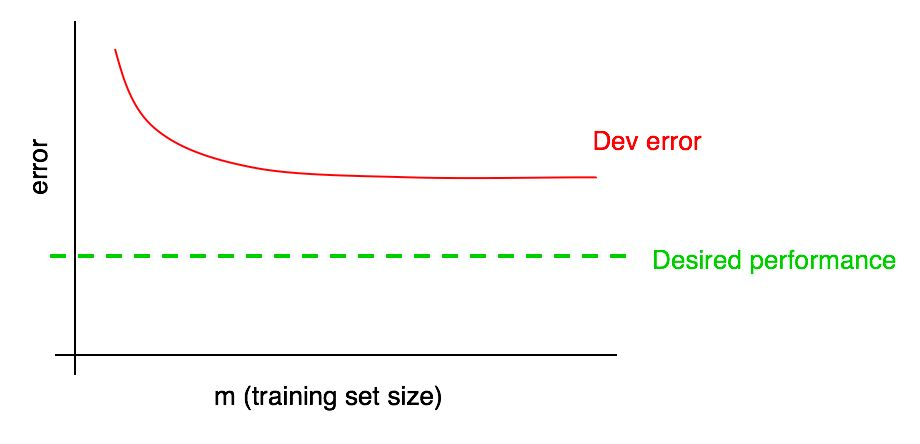
Wir haben bereits gesagt, dass es unwahrscheinlich ist, dass Sie das gewünschte Qualitätsniveau durch einfaches Hinzufügen von Daten erreichen, wenn ein Algorithmusfehler im Validierungsmuster ein Plateau erreicht.
Es ist jedoch schwer vorstellbar, wie die Extrapolation der Kurve der Abhängigkeit der Qualität des Algorithmus von der Validierungsstichprobe (Dev error) beim Hinzufügen von Daten aussehen wird. Und wenn die Validierungsstichprobe klein ist, ist die Beantwortung dieser Frage noch schwieriger, da die Kurve verrauscht sein kann (große Punktespreizung).
Angenommen, wir haben unserem Diagramm eine Kurve der Abhängigkeit der Größe des Fehlers von der Datenmenge der Testprobe hinzugefügt und das folgende Bild erhalten:
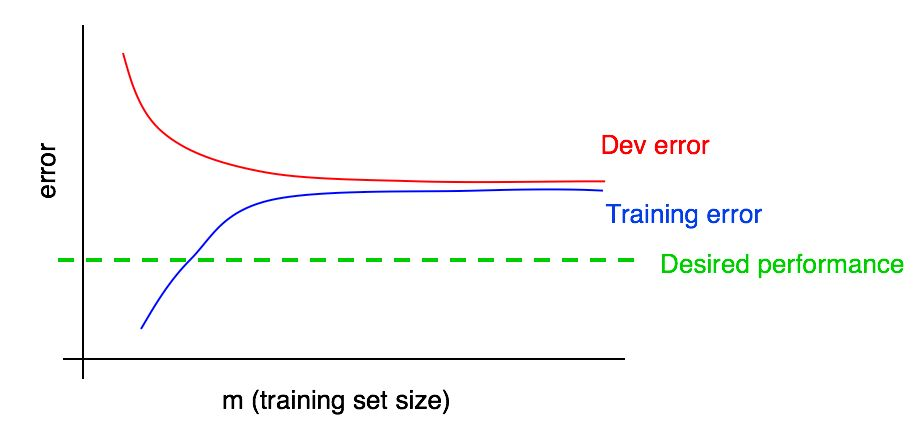
Wenn Sie sich diese beiden Kurven ansehen, können Sie absolut sicher sein, dass das Hinzufügen neuer Daten allein nicht den gewünschten Effekt erzielt (wodurch die Qualität des Algorithmus nicht erhöht werden kann). Wo kann diese Schlussfolgerung gezogen werden?
Erinnern wir uns an die folgenden zwei Punkte:
- Wenn wir dem Trainingssatz weitere Daten hinzufügen, kann der Algorithmusfehler im Trainingssatz nur zunehmen. Daher ändert sich die blaue Linie in unserem Diagramm entweder nicht oder schleicht sich nach oben und entfernt sich von der gewünschten Qualitätsstufe unseres Algorithmus (grüne Linie).
- Die rote Fehlerzeile im Validierungsmuster ist normalerweise höher als die blaue Fehlerzeile des Algorithmus im Trainingsmuster. Daher führt das Hinzufügen von Daten unter allen denkbaren Umständen nicht zu einer weiteren Verringerung der roten Linie und bringt sie nicht näher an die gewünschte Fehlerstufe. Dies ist nahezu unmöglich, da selbst der Fehler im Trainingsmuster höher ist als gewünscht.
Durch die Berücksichtigung beider Kurven der Abhängigkeit des Fehlers des Algorithmus von der Datenmenge in den Validierungs- und Trainingsstichproben in demselben Diagramm können Sie die Fehlerkurve des Lernalgorithmus sicherer aus der Datenmenge in der Validierungsstichprobe extrapolieren.
Angenommen, wir haben eine Schätzung der gewünschten Qualität des Algorithmus in Form einer optimalen Fehlerquote in unserem System. In diesem Fall sind die obigen Grafiken ein Beispiel für einen Standard- "Lehrbuch" -Fall, wie die Lernkurve mit einem hohen Grad an entfernbarer Verzerrung aussieht. Bei der größten Trainingsstichprobengröße, die vermutlich allen uns zur Verfügung stehenden Daten entspricht, besteht eine große Lücke zwischen dem Algorithmusfehler in der Trainingsstichprobe und der gewünschten Qualität des Algorithmus, was auf ein hohes Maß an vermiedener Verzerrung hinweist. Außerdem ist die Lücke zwischen dem Fehler in der Trainingsstichprobe und dem Fehler in der Validierungsstichprobe klein, was auf eine kleine Streuung hinweist.
Zuvor haben wir die Fehler von Algorithmen, die an Trainings- und Validierungsmustern trainiert wurden, nur ganz rechts über dem Diagramm diskutiert, was der Verwendung aller verfügbaren Trainingsdaten entspricht. Die Kurve der Abhängigkeiten des Fehlers von der Datenmenge aus der Trainingsstichprobe, die für verschiedene Größen der für das Training verwendeten Stichprobe konstruiert wurde, gibt uns ein vollständigeres Bild der Qualität des Algorithmus, der auf verschiedenen Größen der Trainingsstichprobe trainiert wurde.
31. Lernkurveninterpretation: Andere Fälle
Betrachten Sie die Lernkurve:
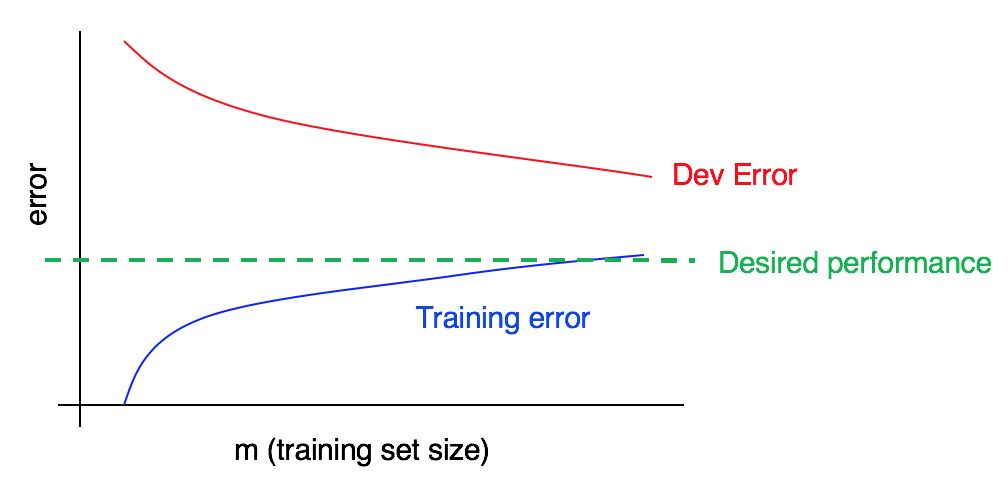
Gibt es eine hohe Verzerrung, eine hohe Analyse oder beides gleichzeitig?
Die blaue Fehlerkurve in den Trainingsdaten ist relativ niedrig, die rote Fehlerkurve in den Validierungsdaten ist signifikant höher als der blaue Fehler in den Trainingsdaten. Somit ist in diesem Fall die Vorspannung gering, aber die Spreizung ist groß. Das Hinzufügen weiterer Trainingsdaten kann dazu beitragen, die Lücke zwischen dem Fehler im Validierungsmuster und dem Fehler im Trainingsmuster zu schließen.
Betrachten Sie nun diese Tabelle:
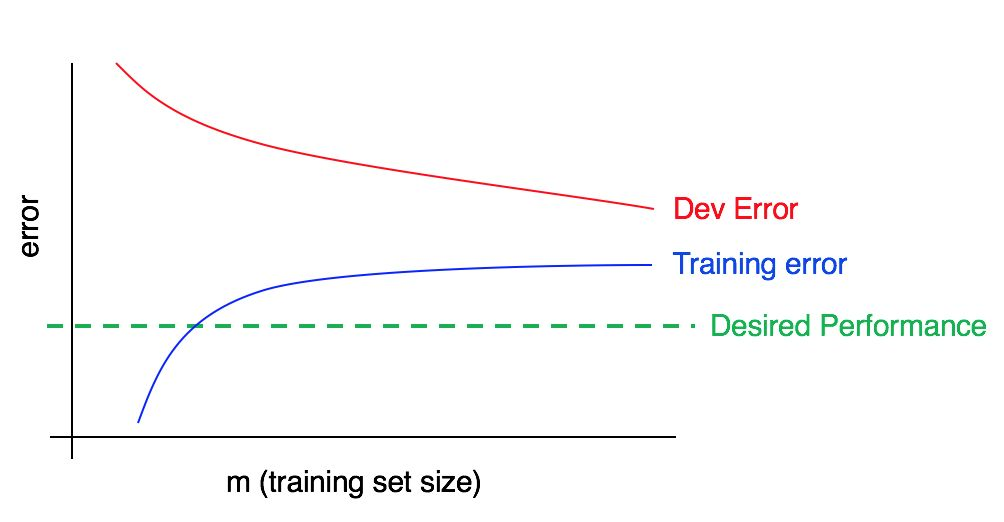
In diesem Fall ist der Fehler in der Trainingsstichprobe groß und deutlich höher als der Algorithmus, der dem gewünschten Qualitätsniveau entspricht. Der Fehler in der Validierungsstichprobe ist ebenfalls signifikant höher als der Fehler in der Trainingsstichprobe. Wir haben es also gleichzeitig mit großer Vorspannung und Streuung zu tun. Sie sollten nach Möglichkeiten suchen, Ihren Algorithmus zu reduzieren, zu versetzen und zu dispergieren.
32. Lernkurven aufbauen
Angenommen, Sie haben eine sehr kleine Stichprobe, bestehend aus nur 100 Beispielen. Sie trainieren Ihren Algorithmus mit einer zufällig ausgewählten Teilmenge von 10 Beispielen, dann von 20 Beispielen, dann von 30 usw. auf 100, wobei Sie die Anzahl der Beispiele mit einem Intervall von zehn Beispielen erhöhen. Mit diesen 10 Punkten erstellen Sie dann Ihre Lernkurve. Möglicherweise ist die Kurve bei kleineren Trainingsmustern verrauscht (Werte höher oder niedriger als erwartet).
Wenn Sie den Algorithmus mit nur 10 zufällig ausgewählten Beispielen trainieren, haben Sie möglicherweise kein Glück und dies ist ein besonders „schlechtes“ Trainingssubample mit einem größeren Anteil an mehrdeutigen / falsch markierten Beispielen. Umgekehrt können Sie auch auf ein besonders „gutes“ Trainingssubample stoßen. Das Vorhandensein eines kleinen Trainingsmusters impliziert, dass der Wert von Fehlern in den Validierungs- und Trainingsmustern zufälligen Schwankungen unterliegen kann.
Wenn die Daten, die für Ihre Anwendung mit maschinellem Lernen verwendet werden, stark auf eine Klasse ausgerichtet sind (wie beim Problem der Katzenklassifizierung, bei dem der Anteil der negativen Beispiele viel größer ist als der Anteil der positiven), oder wenn es sich um eine große Anzahl von Klassen handelt (z. B. Erkennung von 100 verschiedenen Tierarten), dann steigt auch die Chance, eine besonders „nicht repräsentative“ oder schlechte Trainingsstichprobe zu erhalten. Wenn beispielsweise 80% Ihrer Beispiele negative Beispiele sind (y = 0) und nur 20% positive Beispiele sind (y = 1), besteht eine gute Chance, dass eine Trainingsuntermenge von 10 Beispielen nur negative Beispiele enthält, in diesem Fall sehr Es ist schwierig, mit dem trainierten Algorithmus etwas Vernünftiges zu erreichen.
Wenn es aufgrund des Rauschens der Lernkurve in der Trainingsstichprobe schwierig ist, eine Bewertung der Trends vorzunehmen, kann man die folgenden zwei Lösungen vorschlagen:
Anstatt nur ein Modell für 10 Trainingsbeispiele zu trainieren, wählen Sie durch Ersetzen mehrere (z. B. 3 bis 10) verschiedene zufällige Trainingsunterproben aus der anfänglichen Stichprobe aus 100 Beispielen aus. Trainieren Sie das Modell an jedem von ihnen und berechnen Sie für jedes dieser Modelle den Fehler in der Validierungs- und Trainingsprobe. Zählen Sie den durchschnittlichen Fehler in den Trainings- und Validierungsmustern und zeichnen Sie ihn auf.
Anmerkung des Autors: Eine Stichprobe mit einem Ersatz bedeutet Folgendes: Wählen Sie zufällig die ersten 10 verschiedenen Beispiele aus 100 aus, um die erste Teilstichprobe für das Training zu bilden. Um das zweite Trainings-Teilmuster zu bilden, nehmen wir wiederum 10 Beispiele, jedoch ohne Berücksichtigung der im ersten Teilmuster ausgewählten (wiederum aus den gesamten hundert Beispielen). Daher kann in beiden Teilbeispielen ein bestimmtes Beispiel vorkommen. Dies unterscheidet eine Probe mit einer Ersetzung von einer Probe ohne Ersetzung, im Fall einer Probe ohne Ersetzung würde die zweite Trainingsunterprobe aus nur 90 Beispielen ausgewählt, die nicht in die erste Unterprobe fallen. In der Praxis sollte die Methode der Auswahl von Beispielen mit oder ohne Substitution nicht von großer Bedeutung sein, aber die Auswahl von Beispielen mit Substitution ist gängige Praxis.
Wenn Ihre Trainingsstichprobe auf eine der Klassen ausgerichtet ist oder viele Klassen enthält, wählen Sie eine „ausgewogene“ Unterstichprobe aus 10 Trainingsbeispielen, die zufällig aus 100 Stichproben ausgewählt wurden. Sie können beispielsweise sicher sein, dass 2/10 Beispiele positiv und 8/10 negativ sind. Zusammenfassend können Sie sicher sein, dass der Anteil der Beispiele jeder Klasse im beobachteten Datensatz so nahe wie möglich an ihrem Anteil an der anfänglichen Trainingsstichprobe liegt.
Ich würde mich mit keiner dieser Methoden beschäftigen, bis die grafische Darstellung von Fehlerkurven zu dem Schluss führt, dass diese Kurven übermäßig verrauscht sind, was es uns nicht erlaubt, verständliche Trends zu erkennen. Wenn Sie eine große Stichprobe von Schulungen haben - sagen wir etwa 10.000 Beispiele - und die Verteilung Ihrer Klassen nicht sehr voreingenommen ist, benötigen Sie diese Methoden möglicherweise nicht.
Schließlich kann das Erstellen einer Lernkurve aus rechnerischer Sicht teuer sein: Sie müssen beispielsweise zehn Modelle in den ersten 1000 Beispielen, im zweiten 2000 usw. trainieren, bis das letzte 10.000 Beispiele enthält. Das Modelltraining für kleine Datenmengen ist viel schneller als das Modelltraining für große Stichproben. Anstatt die Größen der Trainingsteilproben wie oben beschrieben auf einer linearen Skala (1000, 2000, 3000, ..., 10000) gleichmäßig zu verteilen, können Sie Modelle mit einer nichtlinearen Zunahme der Anzahl der Beispiele trainieren, z. B. 1000, 2000, 4000, 6000 und 10.000 Beispiele. Trotzdem sollte es Ihnen ein klares Verständnis für den Trend der Abhängigkeit der Qualität des Modells von der Anzahl der Trainingsbeispiele in den Lernkurven geben. Natürlich ist diese Technik nur relevant, wenn der Rechenaufwand für das Training zusätzlicher Modelle hoch ist.
Fortsetzung