Viele Leute haben lange Zeit aktiv oder aktiv das Modell der Speicherung und Veröffentlichung von
Dokumentation als Code verwendet oder danach gesucht. Dies bedeutet, dass sie dieselben Regeln, Tools und Verfahren auf die Dokumentation anwenden wie auf den Programmcode, um ihn beispielsweise im Repository zu speichern, Tests auszuführen, zu kompilieren und freizugeben in CI / CD. Dieser Ansatz ermöglicht es Ihnen, die Dokumentation mit dem Code, der Version und dem Nachverfolgen von Änderungen mithilfe bekannter Entwicklungstools auf dem neuesten Stand zu halten.
Gleichzeitig haben viele Unternehmen seit Jahren Wikis, in denen andere Teams und Mitarbeiter, beispielsweise Projektleiter, Zugriff auf Dokumentation haben. Was wäre, wenn Sie Speicher und Veröffentlichung in einer einzigen Ansicht zusammen mit HTML-Veröffentlichungsdocks in Confluence bereitstellen möchten? In diesem Artikel werde ich einen Überblick über die Lösungen für die Veröffentlichung von Dokumenten aus dem Repository in Confluence geben.
Ich habe selbst lange Zeit eine Lösung im Interface-Entwicklungsteam (RST-Sphinx + sphinxcontribbuilder-Bundle) aktiv genutzt und werde die anderen als Alternative vorstellen. Ich sage gleich, dass ich sie nicht in der Praxis ausprobiert habe, sondern nur die Konfiguration studiert habe.
Sphinx doc + sphinxcontribbuilder
Sphinx (nicht zu verwechseln mit dem gleichnamigen Suchindex) ist ein in Python geschriebener Dokumentationsgenerator, der von der Community aktiv verwendet wird und auch in anderen Umgebungen sehr gut funktioniert.
Wir werden nicht näher darauf eingehen, es einzurichten. Ich möchte nur darauf hinweisen, dass es aus der Verpackung heraus statisches HTML, man, pdf und eine Reihe anderer Formate erzeugen kann. Für die korrekte Zusammenstellung und Veröffentlichung im Repository müssen index.rst-Dateien vorhanden sein (Layout der Hauptseite). conf.py (Konfigurationsdatei) und Makefile (eine Datei, die den Vorgang des Generierens von Formaten beschreibt. Hier ist es durchaus möglich, sie in Docker zu nähen und
dort den Befehl
sphinx-build auszuführen.)
Standardmäßig kann Sphinx Docks aus leichtem * .rst-Markup (RestructuredText) generieren, aber wir haben die Möglichkeit hinzugefügt, Markdown (CommonMark-
Variante ) für diejenigen Entwickler zu schreiben, die es bequemer haben (die
m2r- Erweiterung, mit der MD in RST konvertiert wird, hat uns geholfen). .
Wir haben bereits die gesamte Umgebung für Sphinx eingerichtet und die Dokumentationsassembly wurde in einer separaten Phase in der Jenkins-
Pipeline erstellt. Daher haben wir die Erweiterung
sphinxcontrib.confluencebuilder verwendet , mit der Docks im nativen Format für Confluence
erfasst und anschließend veröffentlicht werden können. Confluence ist in diesem Fall neben HTML eines der Ausgabeformate der Dokumentation.

Damit dies funktioniert, müssen Sie die Erweiterungen in conf.py verbinden. Unten sehen Sie das Konfigurationsfragment.
extensions = [ 'sphinxcontrib.confluencebuilder', 'm2r' ] templates_path = ['_templates'] source_suffix = ['.rst', '.md'] master_doc = 'index' exclude_patterns = [ u'docs/warning-plate.rst', u'FEATURE.md', u'CHANGELOG.md', u'builder/README.md' ]
Und dann konfigurieren Sie die Erweiterung, es hat eine Reihe von Einstellungen:
confluence_publish = True
Der wichtige Punkt ist, dass auch wenn die Seite (Quelle in .rst) nicht in toc angegeben und nicht zu exclude_patterns hinzugefügt wird, sie weiterhin veröffentlicht wird, jedoch außerhalb der Hierarchie.
Die Namen der Seiten in Confluence entsprechen dem ersten Titel der Seite. Wenn Sie beispielsweise den Beispiel-Header in der Datei example.rst mit Gleichheitszeichen unterstrichen haben, wird er zum Namen der Seite in Confluence.
Die Hygieneregel, die ganz offensichtlich ist, aber dennoch: Erstellen Sie einen Bot mit Berechtigungsdaten, für die Sie Dokumente veröffentlichen, für die sie in Form von Umgebungsvariablen in Docker Compose übertragen werden können, die in Pipelines verwendet werden.
Natürlich gibt es Fallstricke. Erstens wird nicht alle RST-Syntax für die Veröffentlichung in Confluence unterstützt ((° □ °) ╯︵ ╯︵). Dies ist unpraktisch, wenn Sie HTML und Confluence aus einer Quelle zusammenstellen möchten. Anweisungen für Container und Listen werden nicht unterstützt, fast alle Anweisungsattribute, z. B. Hervorheben von Zeilen im Blockcode, Nummerieren im Inhaltsverzeichnis, Ausrichten und Breite für Listentabellen.
Die Liste der unterstützten Programme ist ziemlich gut .
Von den angenehmen Möglichkeiten werden Includes unterstützt, mit denen Sie Inhaltsfragmente zwischen verschiedenen Dokumenten wiederverwenden, automatisch Dokumente aus Code zusammenstellen, mathematische Formeln berechnen, Tickets und Filter von Jira zeichnen können (dazu müssen Sie in der Konfiguration auch einen Jira-Server registrieren), Kopfzeilen nummerieren und vieles mehr Ein weiteres
Update wurde buchstäblich am 3. Januar veröffentlicht.
Jira-Unterstützung erschien übrigens im Pandoc-Multikonverter, ab
Version 2.7.3 unterstützte
Pandoc das entsprechende Confluence-Wiki-Markup.
Für die Makros und Confluence-Elemente, die nicht unterstützt werden, gibt es einen fehlerhaften Hack. RST hat eine Direktive
... raw :: und ein Confluence-Attribut. Es akzeptiert Conf Markup. Wenn Sie wirklich ein Makro benötigen, können Sie es im Seitenbearbeitungsmodus in Confluence kopieren (der Quellcodemodus ist über das Symbol <> verfügbar) und füge dort den "raw" Code ein. Aber das habe ich dir nicht beigebracht.
.. raw:: confluence <ac:structured-macro ac:macro-id="c38bab13-b51e-4129-85ef-737eab8a1c47" ac:name="status" ac:schema-version=^_^quot quot^_^> <ac:parameter ac:name="colour">Green</ac:parameter> <ac:parameter ac:name="title">Is used</ac:parameter> </ac:structured-macro>
Das Ergebnis ist wie folgt:

Warum mussten wir die Veröffentlichung vom lokalen Repository auf die Testseite und nicht sofort auf "prod" konfigurieren? Tatsache ist, dass beim Veröffentlichen alle Seiten jedes Mal neu veröffentlicht werden und die manuell vorgenommenen Änderungen oder die Kommentare in der Zeile (inline) geschliffen werden. Aus diesem Grund haben wir beschlossen, das Dokument während der Bearbeitung auf einer separaten Seite zu veröffentlichen, z. B. im Dev-Modus, um veröffentlichte Versionen zur Überprüfung hinzuzufügen und Kommentare zu sammeln.
In CI wird die Publikation als separate Stufe in der Jenkins-Pipeline implementiert. Innerhalb dieser Stufe wird das Docker-Image in der Remote-Registrierung gestartet, die die Sphinx-Erstellung mit der gewünschten Konfiguration implementiert. Es ist besser, diesen Schritt sofort zu überspringen.
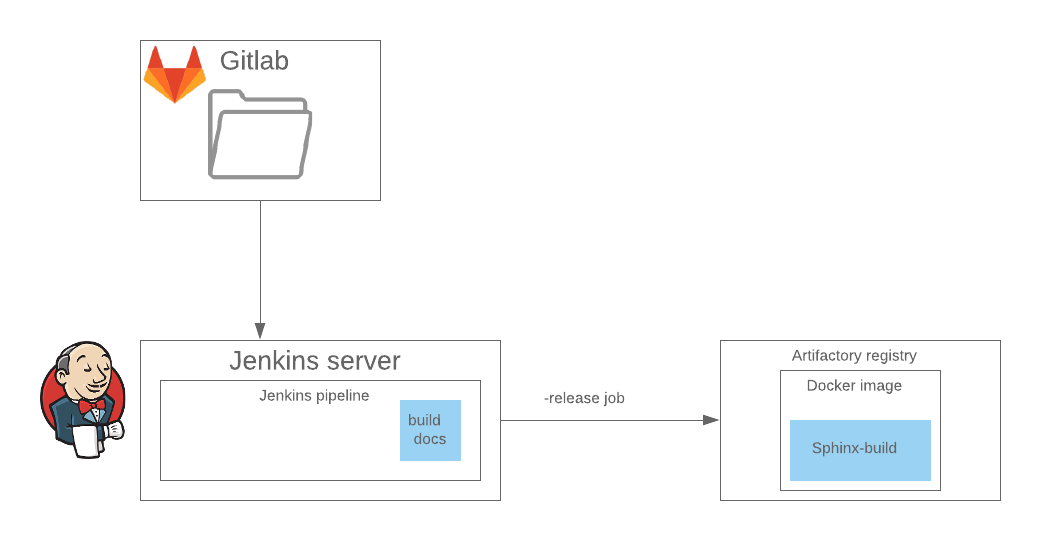
pipeline { agent { label "${AGENT_LABEL}" } stage("Documentation") { steps { ansiColor('xterm') { withCredentials([usernamePassword( credentialsId: "${DOCUMENTATION_BOT}", usernameVariable: 'CONFLUENCE_USERNAME', passwordVariable: 'CONFLUENCE_PASSWORD' )]) { sh "docker-compose -p $COMPOSE_ID run sphinx-doc confluence" } }} }
Innerhalb der Phase wird die
Sphinx-Doc-Konfluenz docker-compose-p release-branch-name gestartet. Jenkinsfile beschreibt wiederum die Abhängigkeiten und die Umgebung, in der der Schritt ausgeführt wird, den Prozess des Zusammenstellens und Aktualisierens der Informationen im Ziel. Von den bisherigen Tests gibt es nur eine Syntaxprüfung von .md und .rst mit doc8 und markdownlinter.
Eine weitere Nuance: Jedes Mal, wenn Sie ein Seitensubnetz veröffentlichen, aktualisiert Sphinx den gesamten Baum, jede Seite. Das heißt, auch wenn sich der Inhalt nicht geändert hat, wird eine Änderung erstellt. Wenn Sie Benachrichtigungen im Kanal konfiguriert haben, wird diese mit vielen Benachrichtigungen verstopft.
Noch ein paar Möglichkeiten
Foliant mit Confluence als Backend
Foliant-Dokumentationstool mit Mkdocs und vielen Präprozessoren unter der Haube und im Backend in Form von Confluence. Sie
können hier mehr darüber lesen. Kurz gesagt, es verwendet pandoc, um md in HTML zu konvertieren, und veröffentlicht es dann in Confluence. Sie müssen nur das Backend konfigurieren und pandoc in der Umgebung als Abhängigkeit installieren.
Günstige Unterschiede zur ersten Lösung: Es kann Inline-Kommentare an denselben Stellen wiederherstellen, an denen sie vor der Veröffentlichung der Seite waren. Sie können Seiten erstellen, indem Sie sie in der Konfiguration festlegen, ihre Namen bearbeiten und Inhalte in eine vorhandene Seite einfügen. Dazu müssen Sie die Einstellungen manuell vornehmen Blattanker auf Seite im Zusammenfluss.
Es funktioniert nur mit der Quelle auf Markdown.
Metro
Ein Multitool, das eine Vielzahl von Quellformaten in Confluence, von Google Docs bis Salesforce Quip, und auch in Markdown veröffentlicht.
Zum Veröffentlichen müssen Sie die Datei manifest.json in dem Ordner ablegen, in dem sich Ihre MD-Dateien befinden. Geben Sie den Ordner darin an, die Datei, die Sie veröffentlichen möchten, und geben Sie für jede Datei die Konfluenz-Seiten-ID an. Der Seitentitel ist die erste Überschrift in der Datei (#). Dieses Tool hat einige Perversionen mit Markdown-Markup. Beobachten Sie also die
Docks . Anhänge und Bilder müssen im selben Ordner abgelegt werden, und mit dem Tool können Sie auch die Verwendung des Inhaltsverzeichnisses direkt in der Konfiguration festlegen.
Edelstein md2conf
Ruby
Gem md2conf konvertiert Markdown in native für Confluence XHTML. Anschließend können Sie eine Rake-Aufgabe schreiben, die wiederum über Gitlab CI / Jenkins aufgerufen werden kann, um sie an den Master zu senden. Anschließend können Sie die Confluence-API aufrufen, um die Seite zu veröffentlichen. Um die Ruby-Umgebung nicht zu Ihnen zu bringen, verpacken Sie die Abhängigkeiten für diesen Edelstein in einen Container.
Hier wird beschrieben, wie Sie Anforderungen an die Confluence-API senden.
Es funktioniert nur mit der Quelle auf Markdown.
Ab auf Github gefunden
In der Community wurde bereits eine Reihe solcher Skripte oder Cli-Tools erstellt, aber ich habe nur mit md2conf experimentiert. Sie sind alle in zwei Gruppen unterteilt.
Diejenigen, die nur Formate konvertieren (md, asciidoc, rst -> confluence / xhtml):Das durchdachteste von ihnen, das ich gesehen habe, ist dieses (https://github.com/rogerwelin/markdown2confluence-server), das der Autor sofort in Dockerfile geschrieben hat und das das CLI-Tool als REST-Server auslöst. Dann können Sie ein Paket mit Konvertierungsanforderungen an das Tool senden .
Und für diejenigen, die die Anforderungen an die Confluence-API sofort selbst implementieren , muss nur der API-Schlüssel in der Konfiguration angegeben werden:
Wählen Sie eine der Optionen (abhängig von Ihrer Markup-Sprache und Ihrem Stack) und erfassen Sie Ihre Pipeline abhängig von den Aufgaben, denen Sie gegenüberstehen.
PS Wenn Sie in Kommentaren andere gefundene Lösungen für das Problem teilen, werde ich sehr dankbar sein.
Und wenn Sie mit mir über diese Themen sprechen möchten, kommen Sie am 18. Mai zur KnowledgeConf 2020 .