Wenn Sie das Training zu Auto-Encodern auf der keras.io-Website lesen, dann gibt es eine der ersten Meldungen in etwa: In der Praxis werden Auto-Encoder so gut wie nie verwendet, aber in Schulungen wird häufig darüber gesprochen, und die Leute kommen vorbei.
Ihr Hauptanspruch auf Ruhm beruht darauf, dass sie in vielen online verfügbaren Einführungskursen für maschinelles Lernen vorgestellt werden. Infolgedessen lieben viele Neulinge auf dem Gebiet absolut Autoencoder und können nicht genug von ihnen bekommen. Aus diesem Grund gibt es dieses Tutorial!
Nichtsdestotrotz ist eine der praktischen Aufgaben, für die sie auf sich selbst angewendet werden können, die Suche nach Anomalien, die ich persönlich im Rahmen des Abendprojekts benötigt habe.
Im Internet gibt es viele Tutorials zu Auto-Encodern, wofür noch eins schreiben? Nun, um ehrlich zu sein, gab es mehrere Gründe dafür:
- Es bestand das Gefühl, dass es sich bei den Tutorials tatsächlich um 3 oder 4 handelte, der Rest wurde in eigenen Worten umgeschrieben.
- Fast alles - auf dem leidenden MNIST'e mit Bildern 28x28;
- Meiner bescheidenen Meinung nach entwickeln sie keine Intuition darüber, wie dies alles funktionieren soll, sondern bieten einfach an, es zu wiederholen.
- Und der wichtigste Faktor - persönlich, als ich MNIST durch meinen eigenen Datensatz ersetzte - war, dass alles nicht mehr funktionierte .
Das Folgende beschreibt meinen Weg, auf dem Zapfen gestopft werden. Wenn Sie eines der vorgeschlagenen flachen (nicht-konvolutionellen) Modelle aus der Masse der Tutorials nehmen und es dumm kopieren, funktioniert überraschenderweise nichts. Der Zweck des Artikels besteht darin, zu verstehen, warum und, wie mir scheint, eine Art intuitives Verständnis dafür zu erlangen, wie dies alles funktioniert.
Ich bin kein Spezialist für maschinelles Lernen und verwende die Ansätze, die ich in der täglichen Arbeit gewohnt bin. Für erfahrene Datenwissenschaftler wird dieser ganze Artikel wahrscheinlich wild sein, aber für Anfänger, so scheint es mir, könnte sich etwas Neues ergeben.
Was für ein ProjektIn aller Kürze über das Projekt, obwohl der Artikel nicht über ihn ist. Es gibt einen ADS-B-Empfänger, der Daten von vorbeifliegenden Flugzeugen auffängt und diese, Flugzeuge, zur Basis koordiniert. Manchmal verhalten sich Flugzeuge ungewöhnlich - sie kreisen umher, um vor der Landung Treibstoff zu verbrennen, oder einfach private Flüge fliegen an Standardrouten (Korridoren) vorbei. Es ist interessant, von ungefähr tausend Flugzeugen pro Tag diejenigen zu isolieren, die sich nicht wie die anderen verhalten haben. Ich gebe uneingeschränkt zu, dass grundlegende Abweichungen einfacher berechnet werden können, aber ich wollte es versuchen die Magie neuronale Netze.
Fangen wir an. Ich habe einen Datensatz von 4000 Schwarzweißbildern (64 x 64 Pixel), der ungefähr so aussieht:

Nur einige Linien auf schwarzem Hintergrund, und im 64x64-Bild sind ca. 2% der Punkte ausgefüllt. Wenn man sich viele Bilder ansieht, stellt sich natürlich heraus, dass die meisten Linien ziemlich ähnlich sind.
Ich werde nicht näher darauf eingehen, wie der Datensatz geladen und verarbeitet wurde, da der Zweck des Artikels wiederum nicht darin besteht. Zeigen Sie einfach ein unheimliches Stück Code.
Hier ist zum Beispiel das erste mit keras.io vorgeschlagene Modell, an dem sie gearbeitet und auf mnist trainiert haben:
In meinem Fall ist das Modell folgendermaßen definiert:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64/10, activation='relu')) model.add(tf.keras.layers.Dense(64*64, activation="sigmoid")) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Es gibt geringfügige Unterschiede, die ich direkt im Modell abflache und neu formiere und die ich nicht 25 Mal, sondern nur 10 Mal "komprimiere". Dies sollte nichts beeinflussen.
Als Verlustfunktion - mittlerer quadratischer Fehler - ist der Optimierer nicht grundlegend, lassen Sie Adam. Im Folgenden trainieren wir 20 Epochen, 100 Schritte pro Epoche.
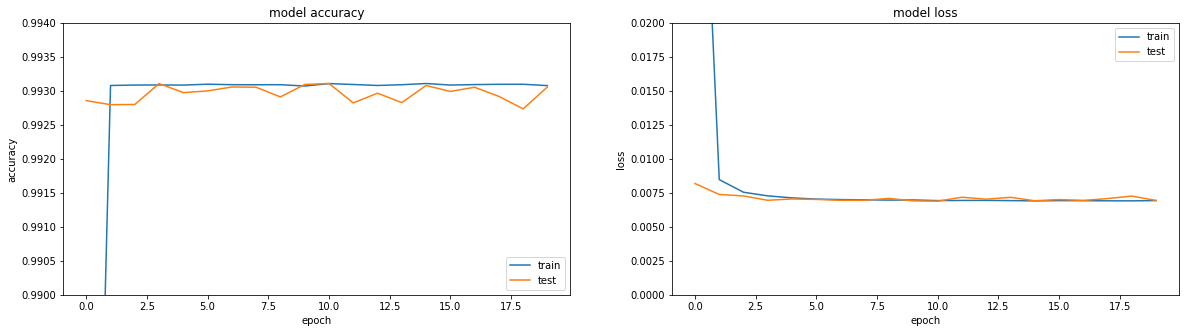
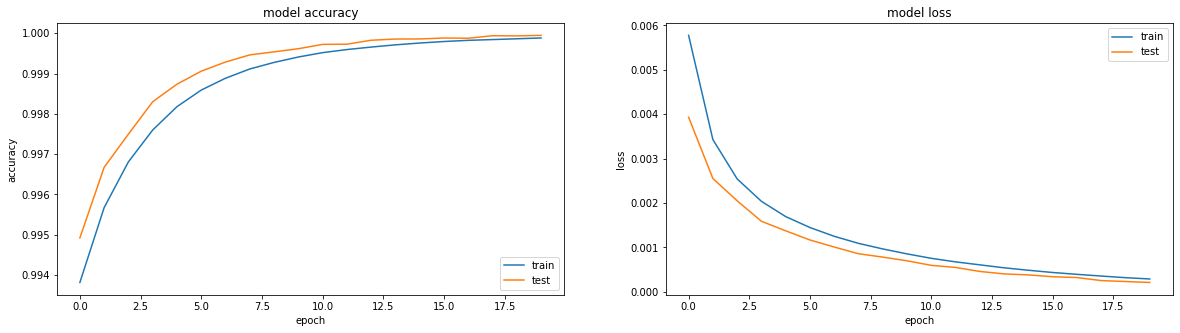
Wenn Sie sich die Metriken ansehen, steht alles in Flammen. Genauigkeit == 0,993. Wenn Sie sich die Trainingspläne ansehen - alles ist ein bisschen trauriger, wir erreichen ein Plateau in der Region der dritten Ära.
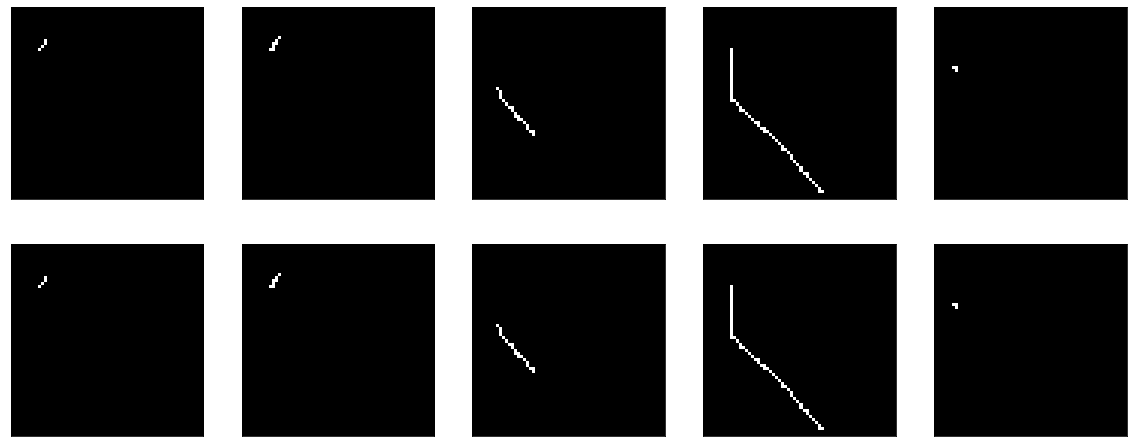
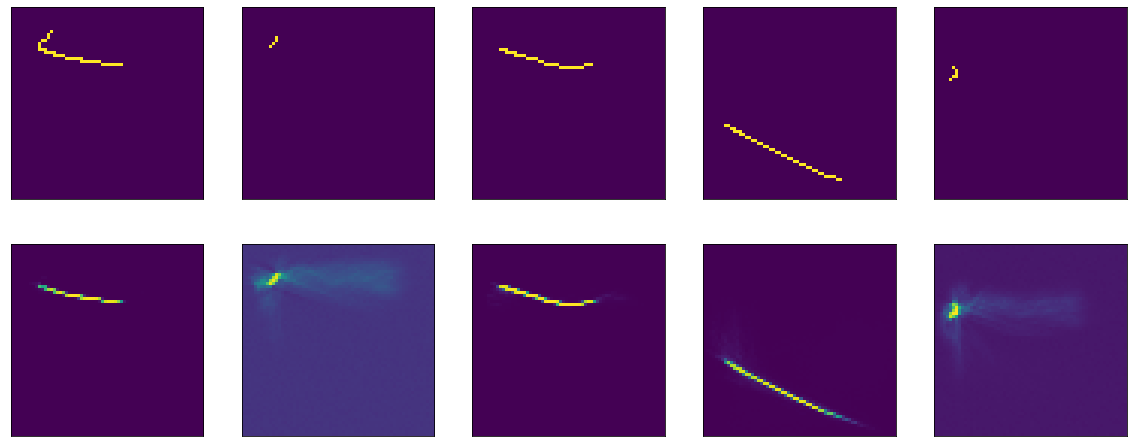
Wenn Sie sich das Ergebnis des Encoders direkt ansehen, erhalten Sie ein allgemein trauriges Bild (das Original ist oben und das Ergebnis der Codierung-Decodierung ist unten):

Wenn Sie herausfinden möchten, warum etwas nicht funktioniert, sollten Sie die gesamte Funktionalität in große Blöcke aufteilen und diese einzeln prüfen. Also lass es uns tun.
Im Original des Tutorials werden flache Daten an den Modelleingang geliefert und am Ausgang abgenommen. Warum überprüfe ich nicht meine Aktionen zum Abflachen und Umformen? Hier ist ein solches No-Op-Modell:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Ergebnis:
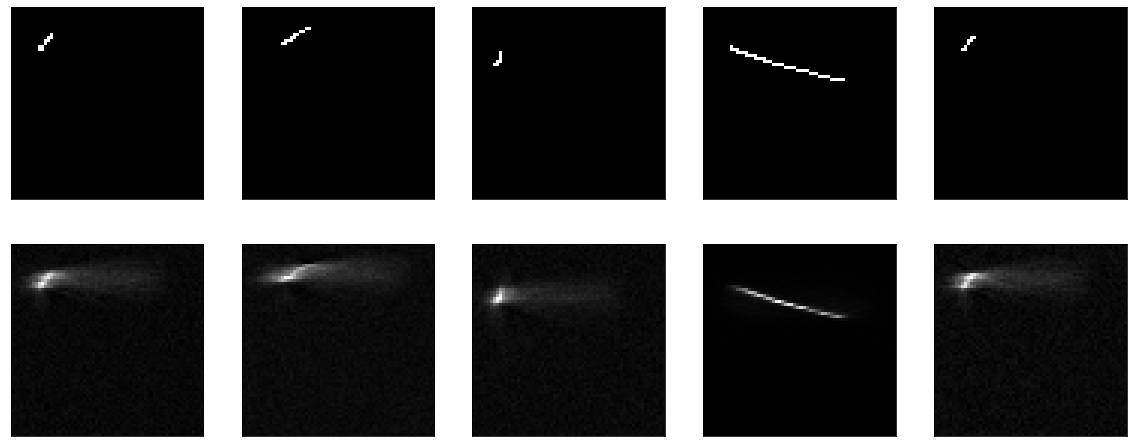
Hier gibt es nichts zu lehren. Gleichzeitig hat sich gezeigt, dass meine Visualisierungsfunktion auch funktioniert.
Versuchen Sie als nächstes, das Modell nicht no-op, sondern so dumm wie möglich zu machen - schneiden Sie einfach die Komprimierungsebene aus und lassen Sie eine Ebene so groß wie die Eingabe. Wie sie in allen Tutorials sagen, ist es sehr wichtig, dass Ihr Modell Funktionen lernt und nicht nur eine Identitätsfunktion. Genau das wollen wir erreichen, indem wir das resultierende Bild einfach an die Ausgabe weitergeben.
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation="sigmoid")) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Sie lernt etwas, Genauigkeit == 0,995 und stolpert wieder in ein Plateau.
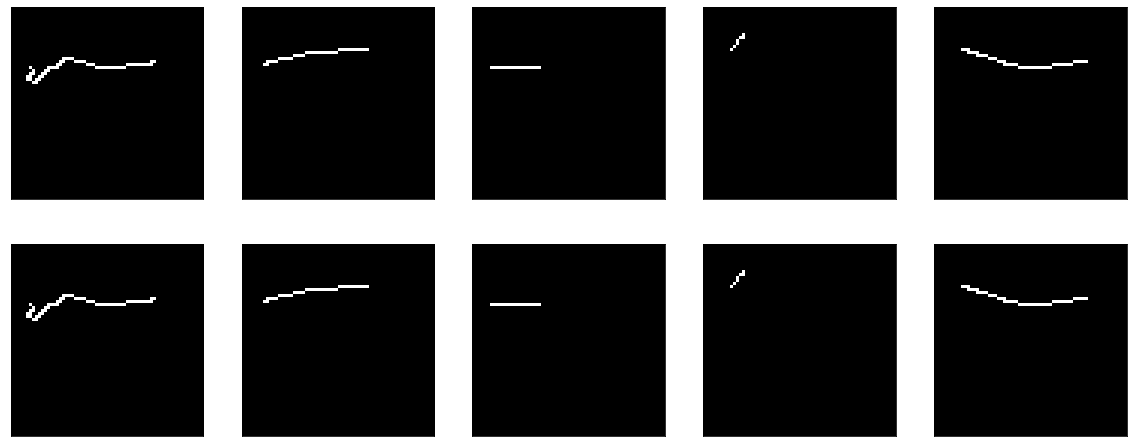
Aber im Allgemeinen ist klar, dass es nicht sehr gut funktioniert. Wie auch immer - was Sie dort lernen sollten, passieren Sie den Eingang zum Ausgang und das wars.
Wenn Sie die Keras-Dokumentation über dichte Schichten lesen, wird beschrieben, was sie tun: output = activation(dot(input, kernel) + bias)
Damit die Ausgabe mit der Eingabe übereinstimmt, sind zwei einfache Dinge ausreichend - Bias = 0 und Kernel - die Identitätsmatrix (es ist wichtig, die Matrix nicht mit Einheiten gefüllt zu lassen - dies sind sehr unterschiedliche Dinge). Glücklicherweise können sowohl dies als auch das ganz einfach aus der Dokumentation für dieselbe Dense .
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation = "sigmoid", use_bias=False, kernel_initializer = tf.keras.initializers.Identity())) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Weil Wir stellen das Gewicht sofort ein, dann können Sie nichts lernen - sofort ist es gut:
Aber wenn Sie mit dem Training beginnen, dann beginnt es auf den ersten Blick überraschend - das Modell beginnt mit einer Genauigkeit von == 1,0, aber es fällt schnell ab.
Bewerten Sie das Ergebnis vor dem Training: 8/Unknown - 1s 140ms/step - loss: 0.2488 - accuracy: 1.0000[0.24875330179929733, 1.0] . Schulung:
Epoch 1/20 100/100 [==============================] - 6s 56ms/step - loss: 0.1589 - accuracy: 0.9990 - val_loss: 0.0944 - val_accuracy: 0.9967 Epoch 2/20 100/100 [==============================] - 5s 51ms/step - loss: 0.0836 - accuracy: 0.9964 - val_loss: 0.0624 - val_accuracy: 0.9958 Epoch 3/20 100/100 [==============================] - 5s 50ms/step - loss: 0.0633 - accuracy: 0.9961 - val_loss: 0.0470 - val_accuracy: 0.9958 Epoch 4/20 100/100 [==============================] - 5s 48ms/step - loss: 0.0520 - accuracy: 0.9961 - val_loss: 0.0423 - val_accuracy: 0.9961 Epoch 5/20 100/100 [==============================] - 5s 48ms/step - loss: 0.0457 - accuracy: 0.9962 - val_loss: 0.0357 - val_accuracy: 0.9962
Ja, und es ist nicht sehr klar, wir haben bereits ein ideales Modell - das Bild kommt 1 zu 1 heraus und der Verlust (mittlerer quadratischer Fehler) zeigt fast 0,25.
Dies ist übrigens eine häufige Frage in den Foren - der Verlust sinkt, aber die Genauigkeit steigt nicht. Wie kann das sein?
Hier lohnt es sich, noch einmal die Definition der Dichten Ebene in Erinnerung zu rufen: output = activation(dot(input, kernel) + bias) und das darin erwähnte Wort Aktivierung, das ich oben so erfolgreich ignoriert habe. Mit Gewichten aus der Identitätsmatrix und ohne Verzerrung erhalten wir output = activation(input) .
Eigentlich ist die Aktivierungsfunktion in unserem Quellcode schon angegeben, Sigmoid, ich hab sie ziemlich doof kopiert und das wars. In den Tutorials wird empfohlen, es überall zu verwenden. Aber du musst es herausfinden.
Für den Anfang können Sie in der Dokumentation lesen, was sie darüber schreiben: The sigmoid activation: (1.0 / (1.0 + exp(-x))) . Das sagt mir persönlich nichts, denn ich bin kein einziges Mal Phantomo, um solche Grafiken in meinem Kopf zu erstellen.
Aber Sie können mit Stiften bauen:
import matplotlib.ticker as plticker range_tensor = tf.range(-4, 4, 0.01, dtype=tf.float32) fig, ax = plt.subplots(1,1) plt.plot(range_tensor.numpy(), tf.keras.activations.sigmoid(range_tensor).numpy()) ax.grid(which='major', linestyle='-', linewidth='0.5', color='red') ax.grid(which='minor', linestyle=':', linewidth='0.5', color='black') ax.yaxis.set_major_locator(plticker.MultipleLocator(base=0.5) ) plt.minorticks_on()
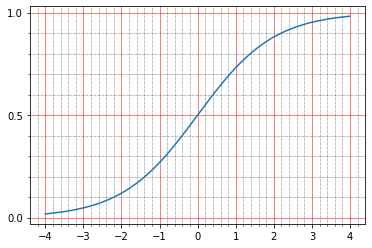
Und hier wird deutlich, dass das Sigma bei Null den Wert 0,5 annimmt und in der Einheit - etwa 0,73. Und die Punkte, die wir haben, sind entweder schwarz (0,0) oder weiß (1,0). Es zeigt sich also, dass der mittlere quadratische Fehler der Identitätsfunktion ungleich Null bleibt.
Sie können sich sogar die Stifte ansehen, hier ist eine Zeile vom resultierenden Bild:
array([0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.7310586, 0.7310586, 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 ], dtype=float32)
Und das ist alles in der Tat sehr cool, weil mehrere Fragen gleichzeitig auftauchen:
- Warum war dies in der obigen Visualisierung nicht sichtbar?
- warum dann genau == 1.0, weil die originalbilder 0 und 1 sind.
Mit der Visualisierung ist alles überraschend einfach. Um die Bilder anzuzeigen, habe ich matplotlib: plt.imshow(res_imgs[i][:, :, 0]) . Und wie üblich, wenn Sie zur Dokumentation gehen, wird alles dort geschrieben: The Normalize instance used to scale scalar data to the [0, 1] range before mapping to colors using cmap. By default, a linear scaling mapping the lowest value to 0 and the highest to 1 is used. The Normalize instance used to scale scalar data to the [0, 1] range before mapping to colors using cmap. By default, a linear scaling mapping the lowest value to 0 and the highest to 1 is used. Das heißt Die Bibliothek normalisierte meine 0,5 und 0,73 sorgfältig im Bereich von 0 bis 1. Ändern Sie den Code:
plt.imshow(res_imgs[i][:, :, 0], norm=matplotlib.colors.Normalize(0.0, 1.0))

Und hier ist die Frage mit Genauigkeit. Zunächst gehen wir aus Gewohnheit in die Dokumentation, lesen für tf.keras.metrics.Accuracy und dort scheint es, dass sie verständlich schreiben:
For example, if y_true is [1, 2, 3, 4] and y_pred is [0, 2, 3, 4] then the accuracy is 3/4 or .75.
In diesem Fall hätte unsere Genauigkeit 0 betragen müssen. Ich habe mich daher in der Quelle vergraben, und mir ist klar:
When you pass the strings 'accuracy' or 'acc', we convert this to one of `tf.keras.metrics.BinaryAccuracy`, `tf.keras.metrics.CategoricalAccuracy`, `tf.keras.metrics.SparseCategoricalAccuracy` based on the loss function used and the model output shape. We do a similar conversion for the strings 'crossentropy' and 'ce' as well.
Darüber hinaus ist in der Dokumentation auf der Website aus irgendeinem Grund dieser Absatz nicht in der Beschreibung von .compile .
Hier ist ein Code von https://github.com/tensorflow/tensorflow/blob/66c48046f169f3565d12e5fea263f6d731f9bfd2/tensorflow/python/keras/engine/compile_utils.py
y_t_rank = len(y_t.shape.as_list()) y_p_rank = len(y_p.shape.as_list()) y_t_last_dim = y_t.shape.as_list()[-1] y_p_last_dim = y_p.shape.as_list()[-1] is_binary = y_p_last_dim == 1 is_sparse_categorical = ( y_t_rank < y_p_rank or y_t_last_dim == 1 and y_p_last_dim > 1) if metric in ['accuracy', 'acc']: if is_binary: metric_obj = metrics_mod.binary_accuracy elif is_sparse_categorical: metric_obj = metrics_mod.sparse_categorical_accuracy else: metric_obj = metrics_mod.categorical_accuracy
y_t ist y_true oder die erwartete Ausgabe, y_p ist y_predicted oder das vorhergesagte Ergebnis.
Wir haben das Datenformat: shape=(64,64,1) , es stellt sich also heraus, dass Genauigkeit als binäre Genauigkeit betrachtet wird. Interesse für die Art und Weise, wie es betrachtet wird:
def binary_accuracy(y_true, y_pred, threshold=0.5): threshold = math_ops.cast(threshold, y_pred.dtype) y_pred = math_ops.cast(y_pred > threshold, y_pred.dtype) return K.mean(math_ops.equal(y_true, y_pred), axis=-1)
Es ist lustig, dass wir hier nur Glück haben - standardmäßig wird alles als Einheit betrachtet, die größer als 0,5 und kleiner als 0,5 ist - Null. Die Genauigkeit unseres Identitätsmodells ist also hundertprozentig, obwohl die Zahlen dort überhaupt nicht gleich sind. Nun, es ist klar, dass wir, wenn wir wirklich wollen, den Schwellenwert korrigieren und die Genauigkeit auf Null reduzieren können, nur dass dies nicht wirklich erforderlich ist. Dies ist eine Metrik, die sich nicht auf das Training auswirkt. Sie müssen lediglich verstehen, dass Sie sie auf tausend verschiedene Arten berechnen und ganz unterschiedliche Indikatoren erhalten können. Sie können beispielsweise verschiedene Metriken mit Stiften abrufen und unsere Daten darauf übertragen:
m = tf.keras.metrics.BinaryAccuracy() m.update_state(x_batch, res_imgs) print(m.result().numpy())
Wird uns 1.0 .
Und hier
m = tf.keras.metrics.Accuracy() m.update_state(x_batch, res_imgs) print(m.result().numpy())
Gibt uns 0.0 für die gleichen Daten.
Übrigens kann derselbe Code verwendet werden, um mit Verlustfunktionen zu spielen und zu verstehen, wie sie funktionieren. Wenn Sie die Tutorials zu Auto-Encodern lesen, empfehlen sie grundsätzlich die Verwendung einer von zwei Verlustfunktionen: entweder Mean Squared Error oder 'binary_crossentropy'. Sie können sie auch gleichzeitig anzeigen.
Ich erinnere Sie daran, dass ich für mse bereits evaluate :
8/Unknown - 2s 221ms/step - loss: 0.2488 - accuracy: 1.0000[0.24876083992421627, 1.0]
Das heißt Verlust == 0,2488. Mal sehen, warum das so ist. Mir persönlich scheint es das einfachste und verständlichste zu sein: Der Unterschied zwischen y_true und y_predict wird pixelweise subtrahiert, jedes Ergebnis wird quadriert und dann der Durchschnitt gesucht.
tf.keras.backend.mean(tf.math.squared_difference(x_batch[0], res_imgs[0]))
Und am Ausgang:
<tf.Tensor: shape=(), dtype=float32, numpy=0.24826494>
Hier ist die Intuition sehr einfach - die Mehrheit der leeren Pixel, das Modell erzeugt 0,5, sie erhalten 0,25 - Quadratdifferenz für sie.
Bei der binären Crossenttrtopie sind die Dinge etwas komplizierter, und es gibt ganze Artikel darüber, wie das funktioniert, aber persönlich war es für mich immer einfacher, die Quellen zu lesen, und dort sieht es ungefähr so aus:
if from_logits: return nn.sigmoid_cross_entropy_with_logits(labels=target, logits=output) if not isinstance(output, (ops.EagerTensor, variables_module.Variable)): output = _backtrack_identity(output) if output.op.type == 'Sigmoid':
Um ehrlich zu sein, habe ich mir sehr lange den Kopf über diese wenigen Codezeilen zerbrochen. Zunächst ist sofort klar, dass zwei Implementierungen funktionieren können: Entweder wird sigmoid_cross_entropy_with_logits aufgerufen, oder das letzte Zeilenpaar funktioniert. Der Unterschied besteht darin, dass sigmoid_cross_entropy_with_logits mit logits (wie der Name schon sagt, doh) und der Hauptcode mit Wahrscheinlichkeiten arbeitet.
Wer sind Logs? Wenn Sie eine Million verschiedener Artikel zu diesem Thema lesen, erwähnen sie mathematische Definitionen, Formeln und etwas anderes. In der Praxis scheint alles überraschend einfach (korrigiere mich, wenn ich falsch liege). Die Rohausgabe der Vorhersage sind Logits. Nun, oder logistische Quoten, die logarithmischen Quoten, die in logistischen und logistischen Papageien gemessen werden.
Es gibt einen kleinen Exkurs - warum gibt es Logarithmen?Quoten sind das Verhältnis der Anzahl der Ereignisse, die wir benötigen, zur Anzahl der Ereignisse, die wir nicht benötigen (im Gegensatz zur Wahrscheinlichkeit, die das Verhältnis der Ereignisse ist, die wir benötigen, zur Anzahl aller Ereignisse im Allgemeinen). Zum Beispiel - die Anzahl der Siege unserer Mannschaft an die Anzahl ihrer Niederlagen. Und es gibt ein Problem. Wenn wir das Beispiel mit den Siegen der Teams fortsetzen, kann unser Team in der Mitte des Verlierers sein und die Chance haben, 1/2 (eins zu zwei) zu gewinnen, und vielleicht sogar extrem viel zu verlieren - und die Chance haben, 1/100 zu gewinnen. Und in die entgegengesetzte Richtung - mittelhoch und 2/1, steiler als die höchsten Berge - und dann 100/1. Und es stellt sich heraus, dass die gesamte Bandbreite der Verliererteams durch Zahlen von 0 bis 1 und coole Teams - von 1 bis unendlich - beschrieben wird. Infolgedessen ist es unbequem zu vergleichen, es gibt keine Symmetrie, damit zu arbeiten ist im Allgemeinen für alle unbequem, Mathematik ist hässlich. Und wenn Sie den Logarithmus der Gewinnchancen nehmen, wird alles symmetrisch:
ln(1/2) == -0.69 ln(2/1) == 0.69 ln(1/100) == -4.6 ln(100/1) == 4.6
Im Fall von Tensorflow ist dies eher willkürlich, da die Ausgabe des Layers streng genommen keine logarithmischen Quoten ist, sondern bereits akzeptiert wird. Wenn der Rohwert zwischen -∞ und + ∞ liegt, werden die Protokolle erstellt. Dann können sie in Wahrscheinlichkeiten umgewandelt werden. Hierfür gibt es zwei Möglichkeiten: softmax und den Sonderfall Sigmoid. Softmax - Nehmen Sie einen Vektor von Logs und wandeln Sie sie in einen Vektor von Wahrscheinlichkeiten um, und zwar so, dass die Summe der Wahrscheinlichkeit aller Ereignisse darin 1 ergibt. Sigmoid (im Fall von tf) nimmt auch einen Vektor von Logs, wandelt jedoch jedes von ihnen unabhängig voneinander in Wahrscheinlichkeiten um vom Rest.
Sie können es so sehen. Es gibt Klassifizierungsaufgaben für mehrere Etiketten, es gibt Klassifizierungsaufgaben für mehrere Klassen. Multiclass - Dies ist, wenn Sie die Äpfel auf dem Bild oder Orangen und vielleicht sogar Ananas bestimmen müssen. Und multilabel ist, wenn es eine Obstvase auf dem Bild geben kann und Sie sagen müssen, dass sie Äpfel und Orangen enthält, aber keine Ananas. Wenn wir Multiklassen wollen, brauchen wir Softmax, wenn wir Multilabel wollen, brauchen wir Sigmoid.
Hier haben wir den Fall des Multilabels - es ist notwendig, dass jedes einzelne Pixel (Klasse) angibt, ob es installiert ist.
Zurück zum Tensorflow und warum es in der binären Crossentropie (zumindest in anderen Crossentropiefunktionen ist es ungefähr gleich) zwei globale Zweige gibt. Crossentropy funktioniert immer mit Wahrscheinlichkeiten. Wir werden später darüber sprechen. Dann gibt es einfach zwei Möglichkeiten: Entweder gehen Wahrscheinlichkeiten bereits in die Eingabe ein oder es kommen Logs in die Eingabe - und dann wird Sigmoid zuerst auf sie angewendet, um die Wahrscheinlichkeit zu ermitteln. Es hat sich herausgestellt, dass das Anwenden von Sigmoid und das Berechnen von Crossentropy besser ist als nur das Berechnen von Crossentropy aus Wahrscheinlichkeiten (die Quelle der Funktion sigmoid_cross_entropy_with_logits hat eine mathematische Schlussfolgerung, und für die Neugierigen können Sie Google 'Numerical Stability Cross Entropy' empfehlen, auch Tensorflow-Entwickler, die Wahrscheinlichkeit nicht zu überschreiten Crossentropy-Funktionen eingeben und unformatierte Protokolle zurückgeben. Nun, direkt im Code werden die Verlustfunktionen überprüft, wenn die letzte Schicht Sigmoid ist. Dann werden sie abgeschnitten und die Aktivierungseingabe anstelle der Ausgabe zur Berechnung sigmoid_cross_entropy_with_logits , wobei alles sigmoid_cross_entropy_with_logits wird, was in sigmoid_cross_entropy_with_logits berücksichtigt werden sigmoid_cross_entropy_with_logits .
Okay, hab's geklärt, jetzt binär_kreuztropie. Es gibt zwei beliebte „intuitive“ Erklärungen, die die Querentropie messen.
Formaler: Stellen Sie sich vor, dass es ein bestimmtes Modell gibt, das für n Klassen die Wahrscheinlichkeit ihres Auftretens kennt (y 0 , y 1 , ..., y n ). Und jetzt im Leben ist jede dieser Klassen k n- mal aufgetreten (k 1 , k 1 , ..., k n ). Die Wahrscheinlichkeit eines solchen Ereignisses ist das Produkt der Wahrscheinlichkeit für jede einzelne Klasse - (y 1 ^ k 1 ) (y 2 ^ k 2 ) ... (y n ^ k n ). Grundsätzlich - dies ist bereits eine normale Definition der Kreuzentropie - wird die Wahrscheinlichkeit eines Datensatzes als Wahrscheinlichkeit eines anderen Datensatzes ausgedrückt. Das Problem bei dieser Definition ist, dass sie sich als von 0 bis 1 herausstellt und oft sehr klein ist und es nicht bequem ist, solche Werte zu vergleichen.
Nimmt man den Logarithmus daraus, so ergibt sich k 1 log (y 1 ) + k 2 log (y 2 ) und so weiter. Der Wertebereich wird von -∞ bis 0. Multiplizieren Sie dies alles mit -1 / n - und der Bereich von 0 bis + ∞ ergibt sich außerdem aus es wird als die Summe der Werte für jede Klasse ausgedrückt, die Änderung in jeder Klasse spiegelt sich auf sehr vorhersehbare Weise im Gesamtwert wider.
Einfacher ausgedrückt: Die Kreuzentropie zeigt, wie viele zusätzliche Bits erforderlich sind, um die Stichprobe in Bezug auf das ursprüngliche Modell auszudrücken. Wenn wir da wären, um einen Logarithmus mit Basis 2 zu erstellen, würden wir direkt Bits gehen. Wir verwenden überall natürliche Logarithmen, daher zeigen sie die Anzahl der Nat's ( https://en.wikipedia.org/wiki/Nat_(unit )), nicht Bits.
Die binäre Kreuzentropie ist wiederum ein Sonderfall der gewöhnlichen Kreuzentropie, wenn die Anzahl der Klassen zwei beträgt. Dann haben wir genug Wissen über die Wahrscheinlichkeit des Auftretens einer Klasse - y 1 , und die Wahrscheinlichkeit des Auftretens der zweiten Klasse wird (1-y 1 ) sein.
Aber es scheint mir, ein wenig rutschte mich. Ich möchte Sie daran erinnern, dass wir beim letzten Versuch, einen Identitäts-Auto-Encoder zu erstellen, ein wunderschönes Bild und sogar eine Genauigkeit von 1,0 aufwiesen. Die Zahlen erwiesen sich jedoch als schrecklich. Im Interesse des Experiments können Sie noch ein paar Tests durchführen:
1) Die Aktivierung kann ganz entfernt werden, es wird eine saubere Identität geben
2) Sie können andere Aktivierungsfunktionen ausprobieren, zum Beispiel das gleiche Relu
Ohne Aktivierung:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, use_bias=False, kernel_initializer=tf.keras.initializers.Identity())) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Wir bekommen das perfekte Identitätsmodell:
model.evaluate(x=val.map(lambda x: (x,x)).batch(BATCH_SIZE, drop_remainder=True))
Übrigens führt Training zu nichts, denn Verlust == 0.0.
Jetzt mit relu. Sein Graph sieht so aus:
import matplotlib.ticker as plticker range_tensor = tf.range(-4, 4, 0.01, dtype=tf.float32) fig, ax = plt.subplots(1,1) plt.plot(range_tensor.numpy(), tf.keras.activations.relu(range_tensor).numpy()) ax.grid(which='major', linestyle='-', linewidth='0.5', color='red') ax.grid(which='minor', linestyle=':', linewidth='0.5', color='black') ax.yaxis.set_major_locator(plticker.MultipleLocator(base=1) ) plt.minorticks_on()
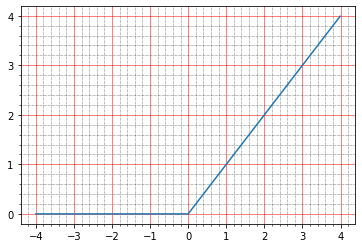
Unter null - null, über - y = x, d.h. Theoretisch sollten wir den gleichen Effekt erzielen wie ohne Aktivierung - ein ideales Modell.
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='relu', use_bias=False, kernel_initializer=tf.keras.initializers.Identity())) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1))) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"]) model.evaluate(x=val.map(lambda x: (x,x)).batch(BATCH_SIZE, drop_remainder=True))
Okay, wir haben das Identitätsmodell herausgefunden, auch wenn ein Teil der Theorie klarer wurde. Versuchen wir nun, dasselbe Modell so zu trainieren, dass es zur Identität wird.
Zum Spaß werde ich dieses Experiment mit drei Aktivierungsfunktionen durchführen. Zunächst - relu, weil es sich schon früher gezeigt hat (alles ist wie vorher, aber der kernel_initializer ist entfernt, also standardmäßig glorot_uniform ):
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='relu', use_bias=False)) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Es lernt wunderbar:
Das Ergebnis war ziemlich gut, Genauigkeit: 0,9999, Verlust (mse): 2e-04 nach 20 Epochen und Sie können weiter trainieren.

Als nächstes versuchen Sie es mit Sigmoid:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='sigmoid', use_bias=False)) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Ich habe bereits zuvor etwas Ähnliches gelehrt, mit dem einzigen Unterschied, dass die Vorurteile hier deaktiviert sind. Er studiert meeeely, geht auf ein Plateau in der Region der 50. Ära, Genauigkeit: 0,9970, Verlust: 0,01 nach 60 Epochen.
Das Ergebnis ist wieder nicht beeindruckend:
Nun, überprüfen Sie auch Tanh:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='tanh', use_bias=False)) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Das Ergebnis ist vergleichbar mit relu - Genauigkeit: 0,9999, Verlust: 6e-04 nach 20 Epochen, und Sie können weiter trainieren:
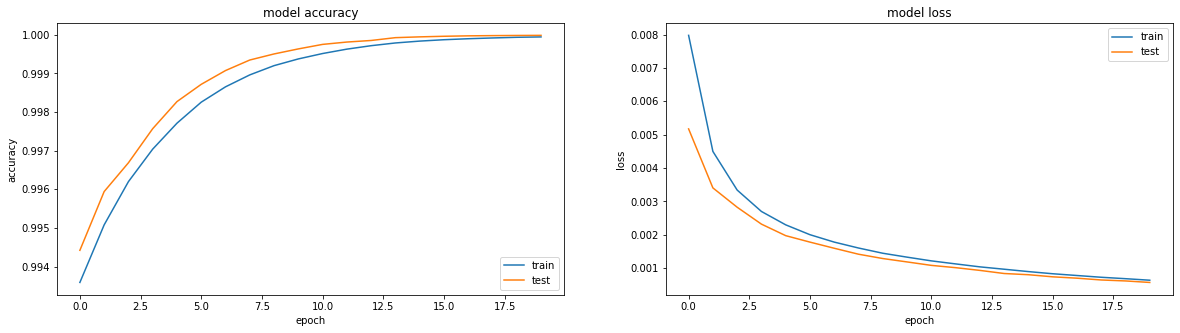

Tatsächlich quält mich die Frage, ob etwas getan werden kann, um Sigmoid zu einem vergleichbaren Ergebnis zu bringen. Ausschliesslich aus sportlichem Interesse.
Sie können beispielsweise versuchen, BatchNormalization hinzuzufügen:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='sigmoid', use_bias=False)) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Und dann passiert eine Art Magie. In der 13. Ära Genauigkeit: 1,0. Und die feurigen Ergebnisse:
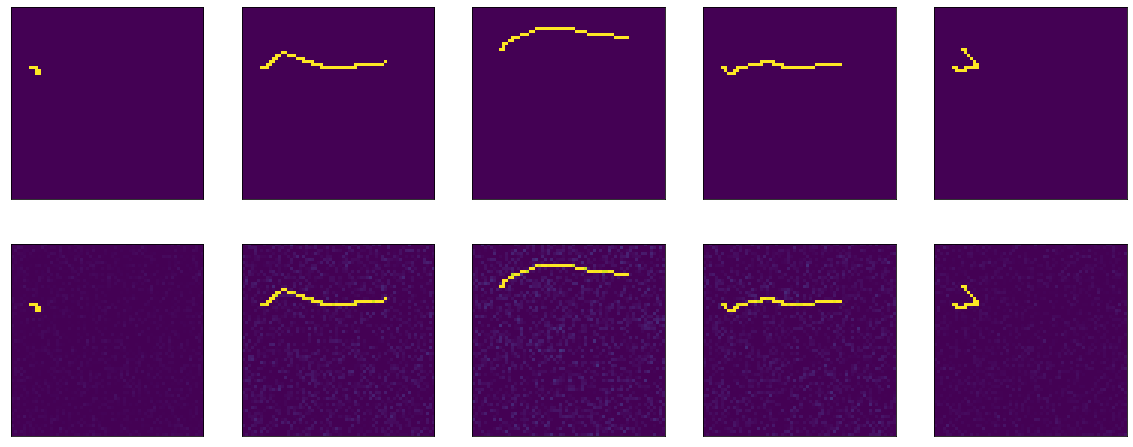
III ... auf diesem Klippenhänger beende ich den ersten Teil, weil der Text zu dumm ist und nicht klar ist, ob jemand ihn braucht oder nicht. Im zweiten Teil werde ich verstehen, was Magie passiert ist, mit verschiedenen Optimierern experimentieren, versuchen, einen ehrlichen Encoder-Decoder zu bauen, meinen Kopf auf den Tisch zu schlagen. Ich hoffe jemand war interessiert und hilfsbereit.