gRPC ist ein Open Source Framework für Remote Procedure Calls. In Yandex.Market wird gRPC als bequemere Alternative zu REST verwendet. Sergey Fedoseenkov, der den Tool-Entwicklungsdienst für Market-Partner leitet, teilte seine Erfahrungen mit der Verwendung von gRPC als Protokoll für die Erstellung von Integrationen zwischen Java- und C ++ - Diensten. In diesem Bericht erfahren Sie, wie Sie häufige Probleme vermeiden, wenn Sie mit der Verwendung von gRPC nach REST beginnen, wie Sie Fehler zurückgeben, die Ablaufverfolgung implementieren, Abfragen debuggen und Clientaufrufe testen.
Am Ende gibt es eine inoffizielle Aufzeichnung des Berichts.
- Zunächst möchte ich Ihnen einige Fakten zu Yandex.Market vorstellen, die als Teil des Berichts nützlich sein werden. Erste Tatsache: Wir schreiben Dienstleistungen in verschiedenen Sprachen. Dies stellt Kundenanforderungen an Dienstleistungen.
Und wenn wir einen Service in Java haben, wäre es schön, wenn der Client dafür zum Beispiel auch ein Plus oder ein kleines wäre.

Alle Dienste, die wir haben, sind unabhängig, es gibt keine geplanten großen Releases des gesamten Marktes. Microservices werden eigenständig freigegeben, und Abwärtskompatibilität ist uns hier wichtig, damit das Protokoll dies unterstützt.
Die dritte Tatsache: Wir haben sowohl synchrone als auch asynchrone Integration. In dem Bericht werde ich hauptsächlich über Synchron sprechen.
Was haben wir benutzt? Die Basis unserer Integrationen sind jetzt natürlich REST oder REST-ähnliche Services, die XML / JSON über HTTP 1.1 austauschen. Es gibt auch XML-RPC - wir verwenden es hauptsächlich bei der Integration in Python-Code, dh Python verfügt über einen integrierten XML-RPC-Server. Es ist praktisch genug, um es dort bereitzustellen, und wir unterstützen es.
Wir hatten einmal CORBA. Zum Glück haben wir es aufgegeben. Jetzt meistens REST und XML / JSON über HTTP.

Synchrone Integrationen haben Probleme mit vorhandenen Protokollen. Wir stoßen auf solche Probleme und versuchen, sie mit gRPC zu behandeln. Was sind diese Probleme? Wie gesagt, ich möchte Kunden in verschiedenen Sprachen haben. Es ist ratsam, dass sie immer noch nicht von uns selbst geschrieben werden müssen. Und im Allgemeinen wäre es cool, wenn der Client sowohl synchron als auch asynchron sein könnte - abhängig von den Zielen des Benutzers des Dienstes.
Ich möchte auch das Protokoll, das wir verwenden, um die Abwärtskompatibilität gut genug zu unterstützen: Dies ist bei parallelen unabhängigen Releases sehr wichtig. Alle unsere Releases sind abwärtskompatibel, wir brechen das Feedback nicht. Wenn Sie es kaputt gemacht haben, ist dies ein Fehler und Sie müssen es nur so schnell wie möglich beheben.
Ein kohärenter Ansatz für die Fehlerbehandlung ist ebenfalls erforderlich: Jeder, der REST-Services bereitgestellt hat, weiß, dass Sie nicht nur den HTTP-Status verwenden können. Sie erlauben in der Regel keine detaillierte Beschreibung des Problems, Sie müssen einige ihrer Status, ihre Details eingeben. In REST-Services führt jeder seine eigene Implementierung dieser Fehler ein, jedes Mal, wenn Sie anders damit arbeiten müssen. Dies ist nicht immer bequem.
Ich hätte auch gerne ein Timeout-Management auf der Client-Seite. Auch hier haben diejenigen, die mit HTTP arbeiten, Verständnis dafür, dass der Client nicht mehr auf den Abschluss der Anforderung wartet, wenn auf der Clientseite eine Zeitüberschreitung festgelegt wird und diese abläuft, der Server jedoch nichts darüber weiß und die Ausführung fortsetzt. Darüber hinaus gibt es in der Mitte verschiedene Proxys, die globale Timeouts festlegen. Und der Client kann einfach nichts über sie wissen und konfigurieren ist nicht immer trivial.
Und schließlich das Problem der Dokumentation. Es ist nicht immer klar, woher die Dokumentation für REST-Ressourcen oder für bestimmte Methoden stammt, welche Parameter sie akzeptieren, welche Stelle übertragen werden kann und wie diese Dokumentation mit den Verbrauchern des Dienstes kommuniziert wird. Es ist klar, dass es Swagger gibt, aber auch damit ist nicht alles trivial.
gRPC Theorie
Ich möchte über den theoretischen Teil von gRPC sprechen - was ist das, was sind die Ideen. Und dann werden wir weiter üben.

Im Allgemeinen ist gRPC eine abstrakte Spezifikation. Es beschreibt einen abstrakten RPC (Remote Procedure Call), dh einen Remote Procedure Call mit bestimmten Eigenschaften. Jetzt werden wir sie auflisten. Die erste Eigenschaft ist die Unterstützung von Einzelanrufen und Streaming. Das heißt, alle Dienste, die diese Spezifikation implementieren, unterstützen beide Optionen. Das nächste Element ist die Verfügbarkeit von Metadaten, dh, dass Sie zusammen mit der Nutzlast eine Art von Metadaten übergeben können - bedingt Header. Und - Unterstützung für die Stornierung einer Anfrage und Timeouts aus der Box.
Es wird auch davon ausgegangen, dass die Beschreibung der Nachrichten und der Dienste selbst über eine bestimmte Schnittstellendefinitionssprache oder IDL erfolgt. Die Spezifikation beschreibt auch das Wire-Protokoll über HTTP / 2, dh, gRPC geht davon aus, dass es nur über HTTP / 2 funktioniert.

In den meisten Fällen wird eine typische gRPC-Implementierung verwendet. Wir benutzen es auch, und jetzt werden wir es sehen. Das Protoformat wird als IDL verwendet. Mit dem gRPC-Plugin für den Protocompiler können Sie die Quellen der generierten Dienste aus der Protobeschreibung abrufen. Und es gibt Laufzeitbibliotheken in verschiedenen Sprachen - Java, C ++, Python. Im Allgemeinen werden fast alle gängigen Sprachen unterstützt, für die Laufzeitbibliotheken existieren. Und als Nachrichten, die zwischen Diensten ausgetauscht werden, wird eine Protonachricht verwendet, stilisierte Nachrichten gemäß dem Protobuf-Schema.

Ich möchte ein wenig auf einige Besonderheiten eingehen. Hier sind sie. Starke Typisierung, dh eine Protonachricht, ist eine stark typisierte Nachricht. Diejenigen, die einmal mit protobuf gearbeitet haben, wissen, dass Sie dort Felder in Ihrer Nachricht mit Typen beschreiben können. Typen bestehen sowohl aus primitiven als auch aus String-Byte-Arrays. Sie können skalar sein, können Vektor sein. Tatsächlich können Nachrichten als ein Feld andere Nachrichten enthalten, was sehr praktisch ist, im Allgemeinen kann jedes Modell dargestellt werden.

Informationen zur Abwärtskompatibilität Ich möchte darauf hinweisen, dass Proto IDL ein Format ist, in dem die Abwärtskompatibilität standardmäßig eingerichtet ist, dh es wurde mit einem Rückstand an Abwärtskompatibilität konzipiert, und Google hat eine Version von Proto3 veröffentlicht, die im Vergleich zu Proto2 die Abwärtskompatibilität weiter verbessert. Darüber hinaus gibt es eine Vielzahl von Spezifikationen, wie und was geändert werden kann, damit die Abwärtskompatibilität in einigen nicht trivialen Fällen erhalten bleibt.
Es gibt die Möglichkeit von Standardwerten, Sie können neue Felder hinzufügen und der Verbraucher muss tatsächlich nichts ändern. Alle Felder in proto3 sind optional und können beispielsweise gelöscht werden, und der Zugriff auf das entfernte Feld verursacht keine Fehler auf dem Client.

Eine weitere gRPC-Funktion besteht darin, dass der Client und der Server mithilfe des Protocompilers und des gRPC-Plugins basierend auf der Protobeschreibung generiert werden. Es besteht die Möglichkeit, zu dem Zeitpunkt, an dem der Code geschrieben wird, auszuwählen, welcher Client verwendet wird. Wählen Sie also einen asynchronen oder synchronen Client, je nachdem, welchen Code Sie schreiben. Ein asynchroner Client eignet sich beispielsweise sehr gut für reaktiven Code. Und diese Gelegenheit ist für jede Sprache. Das heißt, sobald Sie eine Protobeschreibung geschrieben haben, können Sie einen Client für jede Sprache generieren, und Sie müssen sie nicht mehr separat entwickeln. Sie können die Schnittstelle für Ihren Dienst einfach als Protobeschreibung verteilen. Jeder Verbraucher kann einen Kunden für sich selbst generieren.

Über die Stornierung der Anfrage und Fristen möchte ich darauf hinweisen, dass die Anfrage auf dem Server und auf dem Client storniert werden kann. Wenn wir das alles verstehen, müssen wir die Anfrage nicht weiter bearbeiten, dann können wir sie stornieren. Auf Anfrage kann ein Timeout eingestellt werden. In gRPC verwenden die meisten Laufzeitbibliotheken eine Frist als Zeitlimitbegriff. Tatsächlich ist es aber dasselbe. Dies ist die Zeit, zu der die Anforderung abgeschlossen werden sollte.
Und das Interessanteste ist, dass der Server sowohl über das Abbrechen der Anforderung als auch über das Ablaufen des Timeouts informiert werden kann und die Ausführung der Anforderung auf seiner Seite beendet. Das ist sehr cool, es scheint mir, dass es nirgendwo anders viel gibt.
In Bezug auf die Dokumentation wollte ich festhalten, dass dies regulärer Code ist, da das Protoformat in der IDL für gRPC verwendet wird. Dort können Sie Kommentare schreiben, auch sehr ausführliche. Und Sie müssen verstehen, dass Ihre Benutzer, um sich in Ihren Service integrieren zu können, dieses Protoformat bei sich zu Hause haben müssen. Es wird ihnen zusammen mit Kommentaren angezeigt und sie werden nicht woanders liegen. Es ist sehr bequem. Und Sie können diese Beschreibung erweitern, das heißt, sie ist so praktisch, dass die Dokumentation neben dem Code steht, ähnlich wie sie neben den Methoden in Form von Javadoc oder anderen Kommentaren stehen kann.
gRPC unary call. Übe
Gehen wir weiter, schauen wir uns ein wenig Übung an. Das grundlegendste Beispiel für die Verwendung von gRPC ist der sogenannte unäre Anruf oder Einzelanruf. Dies ist ein klassisches Schema. Wir senden eine Anfrage an den Server und erhalten eine Antwort vom Server. Es sieht so aus, als ob dies in HTTP funktioniert.

Betrachten Sie das Beispiel des Echo-Dienstes, den wir ausführen. Der Server wird in Plus geschrieben, der Client in Java. Hier wurde die klassische Ausgleichsschaltung verwendet. Das heißt, der Client wendet sich an den Balancer. Anschließend wählt der Balancer bereits ein bestimmtes Backend für die Verarbeitung der Anforderung aus.
Ich wollte aufpassen - da gRPC über HTTP / 2 funktioniert, wird eine TCP-Verbindung verwendet. Und weiter gehen verschiedene Ströme durch. Hier können Sie sehen, dass die Verbindung zwischen dem Client und dem Balancer einmal hergestellt wird und dauerhaft besteht. Anschließend verteilt der Balancer die Last für jeden Aufruf auf verschiedene Backends. Wenn Sie schauen, passiert es so und so, wenn die Nachrichten verteilt werden.

Hier ist ein Beispielcode für unsere Protodatei. Sie können feststellen, dass wir zuerst die Nachricht beschreiben, das heißt, wir haben EchoRequest und EchoResponse. Es gibt nur ein Zeichenfolgenfeld, in dem die Nachricht gespeichert wird.
Im zweiten Schritt beschreiben wir unser Vorgehen. Die Eingabeprozedur akzeptiert EchoRequest, gibt EchoResponse als Ergebnis zurück, alles ist ziemlich trivial. Dies ist die Beschreibung des gRPC-Dienstes und der Nachrichten, die verfolgt werden.

Mal sehen, wie das zum Beispiel bei Pluspunkten läuft. Der Zusammenbau erfolgt in drei Schritten. In der ersten Phase besteht unsere Aufgabe darin, Nachrichtenquellen zu generieren. Hier machen wir das mit diesem Team. Wir rufen den Proto-Compiler auf, übergeben die Proto-Datei an die Eingabe und geben an, wo die Ausgabedateien abgelegt werden sollen.
Die zweite Mannschaft. Auf die gleiche Weise generieren wir auch Dienstleistungen. Der einzige Unterschied zum vorherigen Befehl besteht darin, dass wir das Plugin übergeben und basierend auf der Beschreibung, die im Protoformat vorliegt, Dienste generieren.
Der dritte Schritt - wir sammeln all dies in einem Binar, damit unser Server gestartet werden kann.
Ein zusätzliches Flag wird an den Linker übergeben und heißt grpc ++ _ reflection. Ich möchte darauf hinweisen, dass der gRPC-Server über eine solche Funktion verfügt, die Serverreflexion. Hier können Sie herausfinden, welche Art von Diensten, RPC-Aufrufen und Nachrichten der Dienst hat. Standardmäßig ist es deaktiviert, und Sie können nur dann auf den Dienst zugreifen, wenn Sie über ein Protoformat verfügen. Zum Debuggen ist es beispielsweise sehr praktisch, ohne das vorhandene Protoformat den Server mit der Reflektionsfunktion einzuschalten und sofort Informationen zu erhalten.
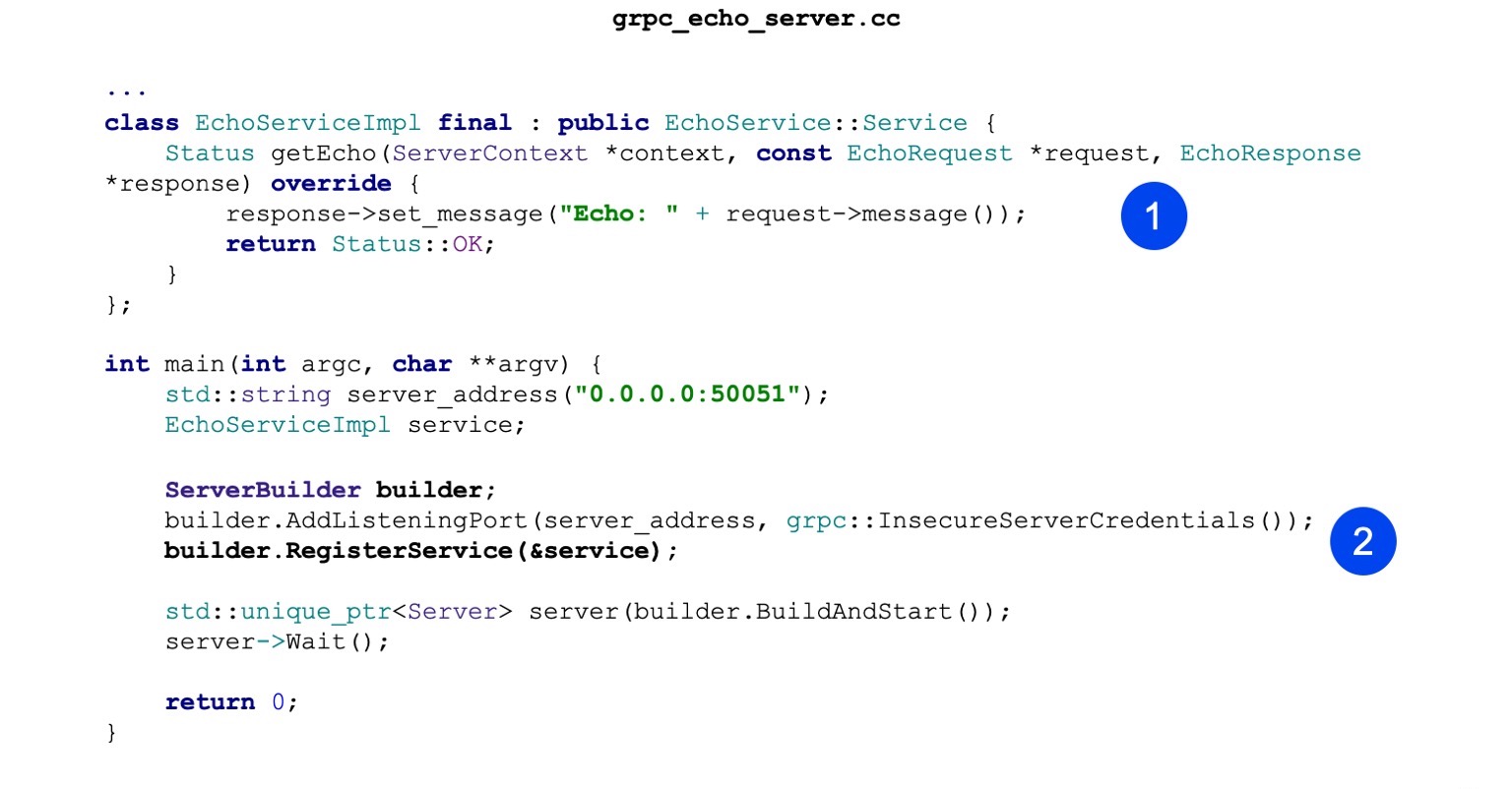
Betrachten wir nun die Implementierung. Die Implementierung ist ebenfalls minimalistisch. Das heißt, unsere Hauptaufgabe ist es, den erzeugten Echo-Dienst zu implementieren. Es gibt eine getEcho-Methode. Es werden nur Nachrichten generiert und zurückgesendet. Status OK - Erfolgsstatus.
Als nächstes erstellen wir ServerBuilder, registrieren unseren Service darin, den wir etwas höher gebaut haben.

Jetzt fangen wir einfach an und warten auf eingehende Anfragen.

Nun sehen wir uns den Client in Java an. Wir sammeln gradle. Unsere Aufgabe ist es, zuerst das protobuf-Plugin zu verbinden.
Es gibt eine Reihe grundlegender Abhängigkeiten, die wir für unseren Service ziehen müssen. Sie werden in der Kompilierungsphase benötigt.
Ich möchte auch erwähnen, dass es eine Laufzeitbibliothek gibt. Für Java wird netty als Server und Client verwendet, es unterstützt HTTP / 2, es ist sehr praktisch und leistungsstark.
Als nächstes konfigurieren wir den Protocompiler. Der Compiler selbst muss nicht lokal für Java installiert werden, sondern kann aus Artefakten entnommen werden.
Gleiches gilt für Plugins. Für Java ist dies lokal nicht erforderlich. Sie können ein Artefakt ziehen. Und es ist wichtig, es einfach so zu konfigurieren, dass es für alle Shuffles auch aufgerufen wird, sodass Stubs generiert werden.
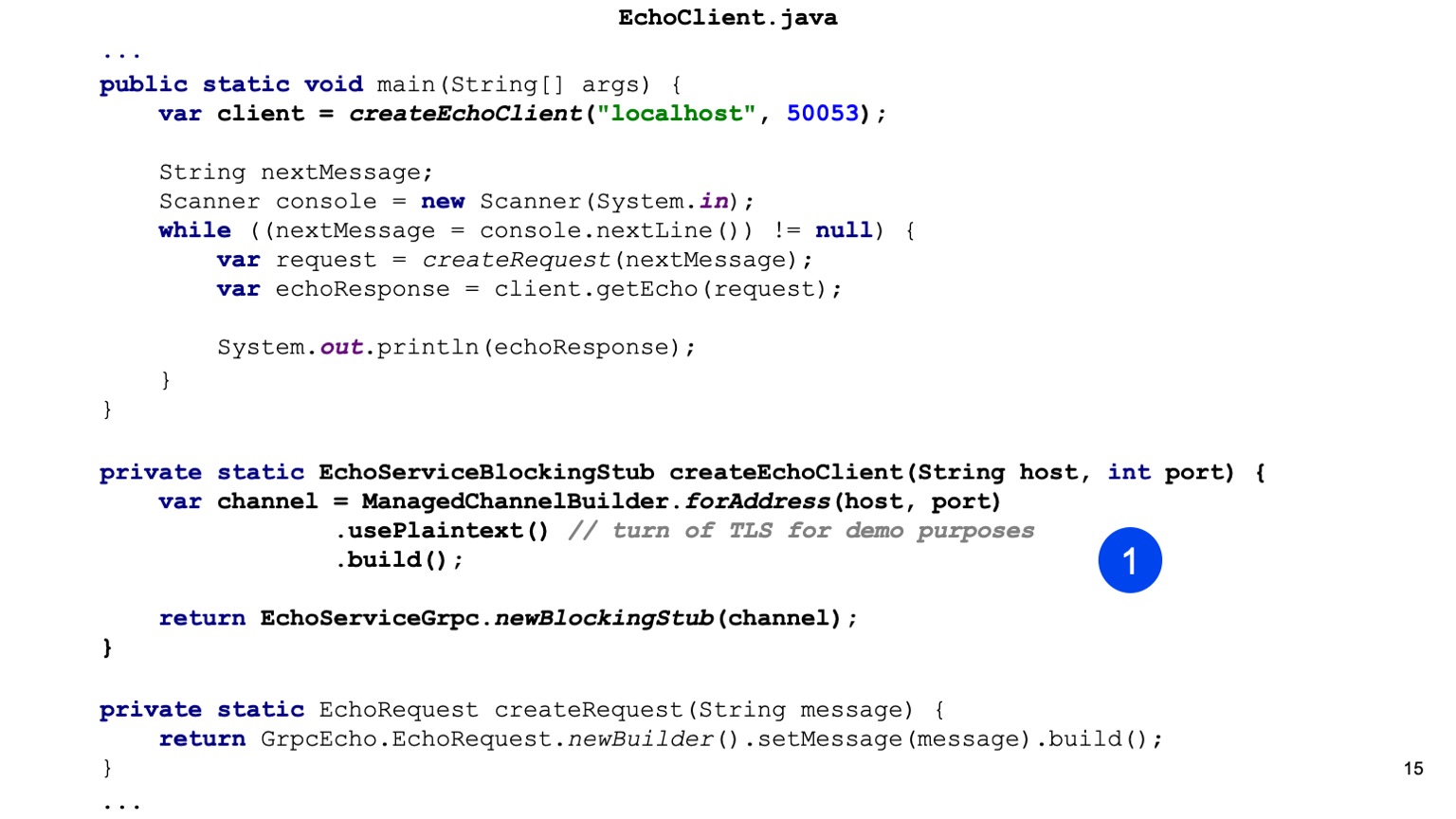
Kommen wir zum Java-Code. Hier sind wir die Ersten, die den Stub unseres Dienstes erstellen. Das ist unsere Aufgabe für Java, Channel bereitzustellen. Es gibt einen ChannelBuilder in der Laufzeitbibliothek, mit dem wir diesen Channel erstellen können. Hier haben wir der Einfachheit halber den einfachen Text manuell aktiviert, aber HTTP2 und gRPC verschlüsseln standardmäßig alles und verwenden TLS.
Wir haben einen Stub unseres Clients, hier wird ein synchroner Client generiert. Auf die gleiche Weise können Sie einen asynchronen Client generieren, es gibt andere Optionen.
Als nächstes erstellen wir unsere Protobuff-Anfrage, das heißt, wir konstruieren eine Protobuff-Nachricht.
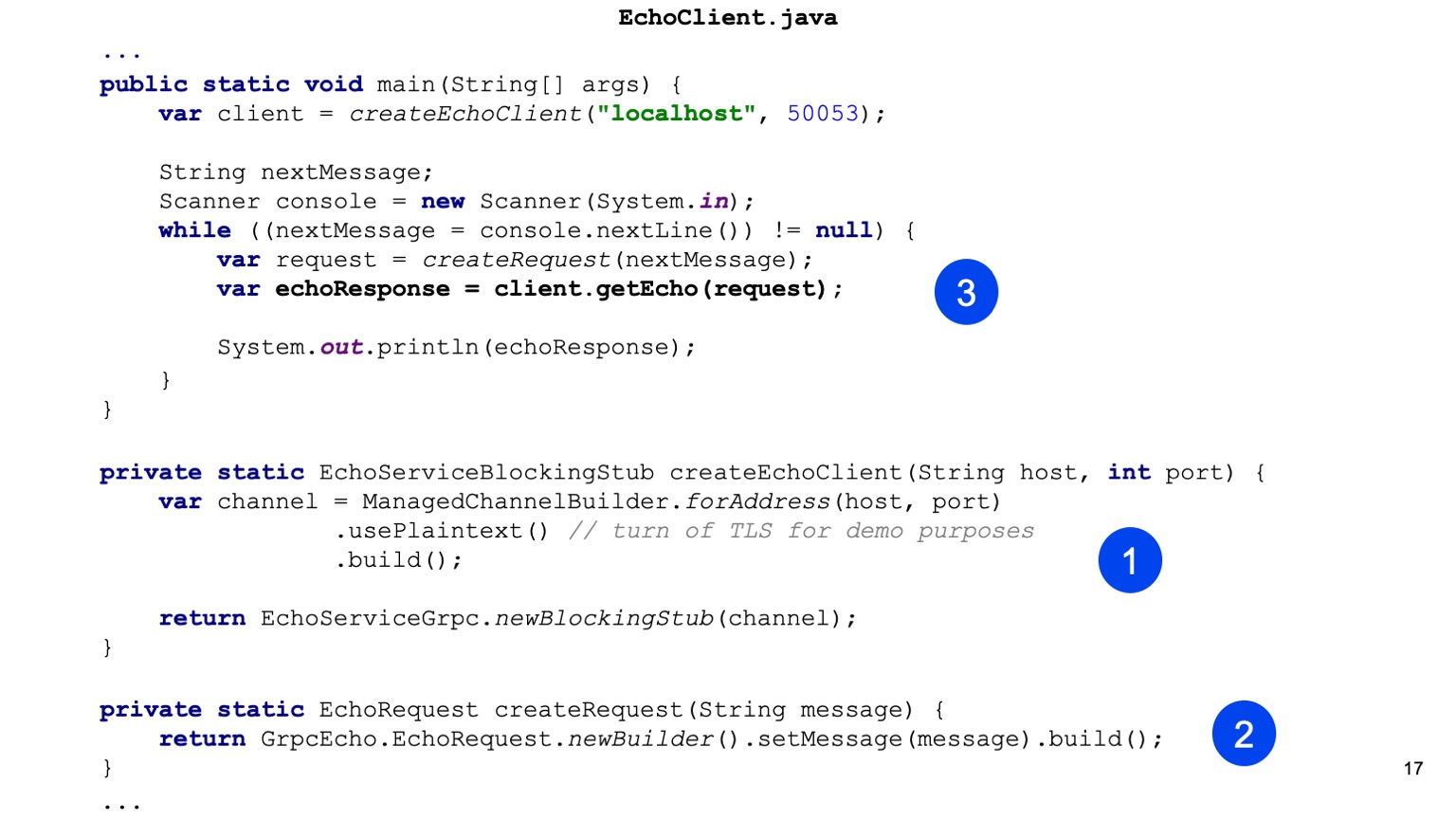
Das ist alles, senden Sie es, auf unserem Client rufen wir getEcho auf und drucken das Ergebnis aus. Alles ist einfach. Wie Sie sehen, wird eine Menge Code benötigt, und die Integration wird erstellt.
gRPC-Streaming. Übe
Schauen wir uns jetzt eine etwas fortgeschrittenere Sache an, das ist Streaming. Ich werde Ihnen erklären, wie es funktioniert, und später werde ich Ihnen erklären, wie Sie es verwenden.

Der Streaming-Client-Server sieht architektonisch ungefähr gleich aus. Das heißt, wir haben eine beständige Verbindung zwischen dem Client und dem Balancer. Dann beginnen die Differenzen. Das Wesentliche beim Streaming ist, dass der Client an ein endgültiges Backend angeschlossen ist und die Verbindung über gespeichert wird. Das heißt, es geht so weiter. Und so. An dieser Stelle möchte ich gesondert darauf hinweisen, dass die Verwendung eines Balancers für das Streaming nicht typisch ist. Sie müssen also verstehen, dass Streaming-Anforderungen sehr langlebig sein können. Das heißt, Sie können sie für eine lange Zeit öffnen und Nachrichten austauschen. Und diese Nachrichten werden durch den Balancer geleitet, gehen aber in der Tat immer zum gleichen Backend. Und es ist nicht ganz klar, warum es überhaupt gebraucht wird.
Eine gängige Praxis besteht darin, dass die Dienstermittlung verwendet wird, wenn ein Dienst beispielsweise nur Streaming oder hauptsächlich Streaming ist. GRPC verfügt über einen Erweiterungspunkt, an dem die Serviceerkennung eingebettet werden kann.

Was brauchen wir, um Streaming-Dienste zu implementieren? Wir haben das gleiche Protoformat. Wir fügen einen weiteren RPC hinzu. Hier können Sie feststellen, dass wir vor der Anforderung und vor der Antwort zwei Schlüsselwörter hinzugefügt haben. Daher deklarieren wir die Streams EchoRequest und EchoResponse.

Das Interessantere beginnt. Unsere Zusammenstellung ändert sich in keiner Weise, damit Streaming-Dienste funktionieren. Unsere nächste Aufgabe ist es, unsere neue Methode in unserem Echo-Dienst zu überschreiben, der mit Streams funktioniert. Beim Server ist das alles etwas einfacher. Das heißt, wir können ständig aus dem Stream lesen und etwas beantworten. Wir können asynchron antworten. Das heißt, sie sind unabhängig, Stream zum Schreiben und Stream zum Lesen, und hier ist für ein einfaches Szenario alles einfach.

Hier ist jetzt die Lektüre, hier ist die Aufnahme.

Bei Java-Clients sind die Dinge etwas komplizierter. Dort können Sie keine synchrone API verwenden, das heißt, sie funktioniert nur nicht mit Streams. Und dort wird die asynchrone API verwendet. Das heißt, unsere Aufgabe ist es, das Observer-Template zu implementieren. Dort gibt es eine StreamObserver-Schnittstelle. Es enthält drei Methoden: onNext, onCompleted und onError. Der Einfachheit halber habe ich hier nur onNext implementiert. Es zuckt nur, wenn die Antwort vom Server kommt.

Hier habe ich gerade eine Warteschlange für den Nachrichtenaustausch zwischen Threads eingerichtet.

Was ist der unterschied Anstelle von blockingStub machen wir einfach newStub. Dies ist eine asynchrone Implementierung, die nur mit Observer funktioniert. Tatsächlich können Sie unitäre Anrufe bei Observer tätigen, was jedoch nicht so praktisch ist. Zumindest nutzen wir es nicht so aktiv.
Als nächstes konstruieren wir unseren Observer.
Und wir machen unseren RPC-Aufruf. Wir übergeben den ResponseObserver an die Eingabe und geben am Ausgang den RequestObserver an uns aus. Außerdem können wir über RequestObserver Anrufe tätigen und so Nachrichten an den Server senden. Und unser ResponseObserver zuckt und verarbeitet Nachrichten.
Hier ist ein Beispiel. Wir telefonieren nur. Rufen Sie onNext an, übergeben Sie dort Request.
Weiter von der Warteschlange warten wir, bis der Server antwortet und druckt.

Ich möchte darauf hinweisen, dass unsere Aufgabe hier als Verantwortlicher für die Implementierung des Streamings darin besteht, das Schließen dieses RequestObservers korrekt zu handhaben. Das heißt, im Fehlerfall müssen wir die onError-Methode aufrufen. Wenn wir glauben, dass der Stream geschlossen werden kann, müssen wir bei erfolgreichem Abschluss die onCompleted-Methode aufrufen.

Wir ziehen weiter. Was sind die Streaming-Anwendungen? Dies ist eine fortgeschrittenere Sache, nicht die Tatsache, dass es für jeden direkt nützlich ist, sondern wird manchmal verwendet. Das heißt, das erste ist das Herunterladen und Hochladen einiger großer Datenmengen. Der Server oder Client kann in einigen Abschnitten Daten produzieren. Diese Teile sind möglicherweise bereits auf dem Client oder auf dem Server gruppiert. Das heißt, Sie können hier bereits zusätzliche Optimierungen vornehmen.
Das Streaming-Schema eignet sich auch gut für Server-Push. Sie müssen verstehen, dass ich bei bidirektionalem Streaming die extremste Option in Betracht gezogen habe. Und vielleicht in eine Richtung streamen. Zum Beispiel von Client zu Server oder von Server zu Client. Wenn ein Server mit einem Client verbunden ist, können wir eine Verbindung zu einem Server herstellen, der Pushies an uns sendet. Hierzu müssen wir keine regelmäßigen Abfragen durchführen.
Der nächste Vorteil des Streamings ist die Bindung an einen Computer. Wie ich bereits sagte, wird eine End-to-End-Verbindung für alle Nachrichten im Stream hergestellt, und diese Verbindung wird an einen Computer gebunden, und es wird definitiv nirgendwo gewechselt. Daher ist es zum einen möglich, etwas zu vereinfachen, eine Art Interserver-Synchronisation durchzuführen, und zum anderen können Sie auch Transaktionen durchführen.
Und bidirektionales Streaming, nur ein Beispiel, das ich gezeigt habe, ist die Möglichkeit, einige meiner eigenen Protokolle zu erstellen. Interessant genug, was. Wir haben interne Warteschlangen in Yandex, die nur bidirektionales Streaming verwenden. Und wenn plötzlich jemand solche Aufgaben hat, dann eine gute Gelegenheit, sie zu nutzen.
Ich möchte auch aufpassen, ich habe früher über Metadaten gesprochen. . . , - , , . . gRPC .
, gRPC.

, . - . gRPC . , , , , , . , runtime- . , . , OK, runtime- .
, Java . . google.rpc.Status 3 : , . , . , . — , , .
error details, , . : , , , stack traces, . , .
— , HTTP , ? . BadRequest . , , error details, .
. , , BadRequest - ( ), - error detail. , , , - . , .

. . , , , . - - , - - , , . . , , Zipkin. , HTTP , — metadata. .
, . , - , , , .
runtime-, - , . Java ClientInterceptor ServerInterceptor. , , . , , , , , - . , - API - . , , , , - . , gRPC, , - . , , - , , , .

- . -. Java . , , - . - , .

. gRPC — . HTTP/2 . - , ? : , . . , gRPC grpc_cli, curl. , . , -, . , gRPC , .
, evans. , CLI: , , , . , . - , , , , , .
- UI — , Postman, — BloomRPC. Postman . Postman, , , . , BloomRPC , .
- , . , , grpc_cli. . , . , , . , . , - - . — .

, , gRPC. . - , - , . Swagger. , HTTP/1 . OpenAPI , . . , HTTP/2, Swagger — .
WSDL — , . . Swagger, , . . -.
, , , , JAX-RS, Java . .
Twirp. ? Go, . . , , Go , gRPC Twirp. ? , gRPC — , , , IDL . proto- , gRPC-. protoc, , .
Twirp . proto- , HTTP/1.1 , JSON. , Twirp Go. , , Java Jetty. , .

? gRPC — REST . , , , , HTTP/2 balancer. service discovery, . gRPC , . .
gRPC — , . CLI, UI. , .
, gRPC. inter-process-. , sidecar pattern. , . , . , -. - , , -. . , , , , - .
, . gRPC . , . , unary-. , .
:
—
C gRPC — , . , , , .
—
Awesome gRPC — GitHub . , , , . . — , .
, . .
. Vielen Dank!