Dies ist nicht einmal ein Scherz, es scheint, dass dieses spezielle Bild die Essenz dieser Datenbanken am genauesten widerspiegelt, und am Ende wird klar sein, warum:

Laut DB-Engines Ranking sind Cassandra (im Folgenden CS) und HBase (HB) die beiden beliebtesten NoSQL-Säulenbasen.
Nach dem Willen des Schicksals arbeitet unser Datenlademanagement-Team bei der Sberbank
seit langer Zeit eng mit HB zusammen. In dieser Zeit haben wir seine Stärken und Schwächen sehr gut studiert und gelernt, wie man es kocht. Das ständige Vorhandensein einer Alternative in Form von CS ließ mich jedoch zweifeln: Haben wir die richtige Wahl getroffen? Darüber hinaus haben die Ergebnisse des von DataStax durchgeführten
Vergleichs ergeben, dass CS HB leicht mit einem fast vernichtenden Ergebnis besiegt. Auf der anderen Seite ist DataStax eine interessierte Person, und Sie sollten hier kein Wort verlieren. Außerdem war eine kleine Menge an Informationen über die Testbedingungen peinlich, sodass wir beschlossen, selbst herauszufinden, wer der König von BigData NoSql ist, und die Ergebnisse waren sehr interessant.
Bevor Sie jedoch zu den Ergebnissen der durchgeführten Tests übergehen, müssen Sie die wesentlichen Aspekte der Umgebungskonfigurationen beschreiben. Tatsache ist, dass CS im Datenverlust-Toleranzmodus verwendet werden kann. Das heißt In diesem Fall ist nur ein Server (Knoten) für die Daten eines bestimmten Schlüssels verantwortlich. Wenn dieser aus irgendeinem Grund ausfällt, geht der Wert dieses Schlüssels verloren. Für viele Aufgaben ist dies nicht kritisch, für den Bankensektor jedoch eher die Ausnahme als die Regel. In unserem Fall ist es wichtig, mehrere Kopien der Daten für eine zuverlässige Speicherung zu haben.
Daher wurde nur der CS-Modus der dreifachen Replikation in Betracht gezogen, d.h. Die Fallerstellung wurde mit den folgenden Parametern durchgeführt:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3};
Darüber hinaus gibt es zwei Möglichkeiten, um das erforderliche Konsistenzniveau sicherzustellen. Allgemeine Regel:
NW + NR> RF
Dies bedeutet, dass die Anzahl der Bestätigungen von den Knoten beim Schreiben (NW) plus die Anzahl der Bestätigungen von den Knoten beim Lesen (NR) größer sein muss als der Replikationsfaktor. In unserem Fall ist RF = 3 und daher sind die folgenden Optionen geeignet:
2 + 2> 3
3 + 1> 3
Da es für uns von grundlegender Bedeutung ist, die Daten so zuverlässig wie möglich zu halten, wurde ein 3 + 1-Schema gewählt. Zusätzlich arbeitet HB auf einer ähnlichen Basis, d.h. Ein solcher Vergleich wäre ehrlicher.
Es sollte beachtet werden, dass DataStax bei seinen Recherchen das Gegenteil getan hat: Sie haben RF = 1 sowohl für CS als auch für HB festgelegt (für letztere durch Ändern der HDFS-Einstellungen). Dies ist ein sehr wichtiger Aspekt, da die Auswirkungen auf die CS-Leistung in diesem Fall enorm sind. Das folgende Bild zeigt zum Beispiel den Anstieg der Zeit, die zum Laden von Daten in CS erforderlich ist:
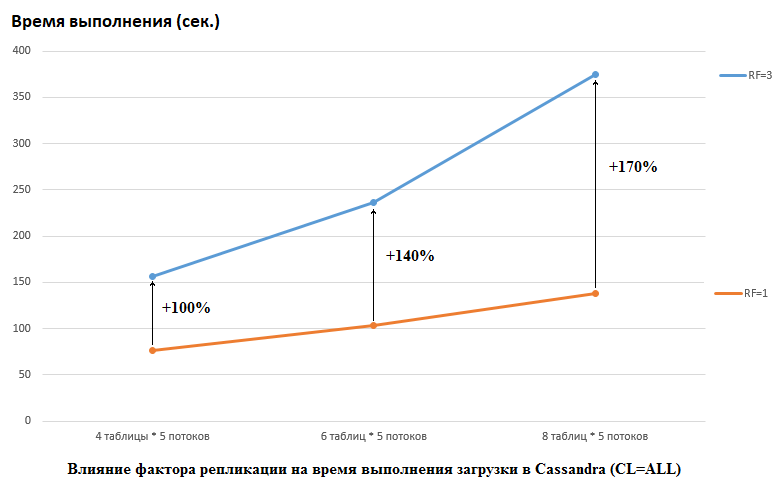
Hier sehen wir Folgendes: Je mehr konkurrierende Threads Daten schreiben, desto länger dauert es. Dies ist natürlich, aber es ist wichtig, dass die Verschlechterung der Leistung für RF = 3 signifikant höher ist. Mit anderen Worten, wenn wir in 4 Tabellen in jeweils 5 Streams schreiben (insgesamt 20), verliert RF = 3 ungefähr zweimal (150 Sekunden RF = 3 gegenüber 75 für RF = 1). Wenn wir jedoch die Last erhöhen, indem wir Daten in 8 Tabellen in jeweils 5 Streams laden (insgesamt 40), beträgt der Verlust von RF = 3 bereits das 2,7-fache (375 Sekunden gegenüber 138).
Vielleicht ist dies zum Teil das Geheimnis erfolgreicher DataStax-Tests für CS-Lasttests, denn für HB an unserem Stand hatte die Änderung des Replikationsfaktors von 2 auf 3 keine Auswirkung. Das heißt Discs sind in unserer Konfiguration nicht der Flaschenhals für HB. Es gibt jedoch viele andere Fallstricke, da unsere Version von HB leicht gepatcht und verdeckt war, die Umgebungen völlig anders sind usw. Es ist auch erwähnenswert, dass ich vielleicht nicht weiß, wie ich CS richtig vorbereiten soll, und dass es einige effektivere Möglichkeiten gibt, damit zu arbeiten, und ich hoffe, dass wir in den Kommentaren darauf aufmerksam werden. Aber das Wichtigste zuerst.
Alle Tests wurden an einem Eisencluster durchgeführt, der aus 4 Servern mit jeweils einer Konfiguration bestand:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 Threads.
Festplatten: 12 Stück SATA HDD
Java-Version: 1.8.0_111
CS Version: 3.11.5
Parameter cassandra.ymlnum_tokens: 256
hinted_handoff_enabled: true
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
hints_directory: / data10 / cassandra / hints
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
Authentifikator: AllowAllAuthenticator
authorizer: AllowAllAuthorizer
role_manager: CassandraRoleManager
role_validity_in_ms: 2000
permissions_validity_in_ms: 2000
credentials_validity_in_ms: 2000
Partitionierer: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
- / data1 / cassandra / data # Jedes dataN-Verzeichnis ist ein separates Laufwerk
- / data2 / cassandra / data
- / data3 / cassandra / data
- / data4 / cassandra / data
- / data5 / cassandra / data
- / data6 / cassandra / data
- / data7 / cassandra / data
- / data8 / cassandra / data
Commitlog-Verzeichnis: / data9 / cassandra / commitlog
cdc_enabled: false
disk_failure_policy: stop
commit_failure_policy: Stop
prepare_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
gespeichertes_caches_verzeichnis: / data10 / cassandra / saved_caches
commitlog_sync: periodisch
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
seed_provider:
- Klassenname: org.apache.cassandra.locator.SimpleSeedProvider
parameter:
- Samen: "*, *"
concurrent_reads: 256 # ausprobiert 64 - kein Unterschied bemerkt
concurrent_writes: 256 # ausprobiert 64 - kein Unterschied bemerkt
concurrent_counter_writes: 256 # versucht 64 - kein Unterschied bemerkt
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # versuchte 16 GB - war langsamer
memtable_allocation_type: heap_buffer
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: false
trickle_fsync_interval_in_kb: 10240
Speicherport: 7000
ssl_storage_port: 7001
listen_address: *
broadcast_address: *
listen_on_broadcast_address: true
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: true
native_transport_port: 9042
start_rpc: true
rpc_address: *
rpc_port: 9160
rpc_keepalive: wahr
rpc_server_type: sync
thrift_framed_transport_size_in_mb: 15
incremental_backups: false
snapshot_before_compaction: false
auto_snapshot: true
column_index_size_in_kb: 64
column_index_cache_size_in_kb: 2
concurrent_compactors: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: false
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: keine
client_encryption_options:
aktiviert: false
internode_compression: dc
inter_dc_tcp_nodelay: false
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
transparente_Daten_Verschlüsselungsoptionen:
aktiviert: false
tombstone_warn_threshold: 1000
tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: false
enable_materialized_views: true
enable_sasi_indexes: true
GC-Einstellungen:
### CMS-Einstellungen-XX: + UseParNewGC
-XX: + UseConcMarkSweepGC
-XX: + CMSParallelRemarkEnabled
-XX: SurvivorRatio = 8
-XX: MaxTenuringThreshold = 1
-XX: CMSInitiatingOccupancyFraction = 75
-XX: + UseCMSInitiatingOccupancyOnly
-XX: CMSWaitDuration = 10000
-XX: + CMSParallelInitialMarkEnabled
-XX: + CMSEdenChunksRecordAlways
-XX: + CMSClassUnloadingEnabled
Dem Speicher jvm.options wurden 16 GB zugewiesen (immer noch 32 GB ausprobiert, es wurde kein Unterschied festgestellt).
Das Erstellen von Tabellen wurde mit dem folgenden Befehl ausgeführt:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};
HB-Version: 1.2.0-cdh5.14.2 (in der Klasse org.apache.hadoop.hbase.regionserver.HRegion haben wir MetricsRegion ausgeschlossen, was zu GC mit mehr als 1000 Regionen auf RegionServer führte)
Nicht standardmäßige HBase-Optionenzookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 Minute (n)
hbase.client.scanner.timeout.period: 2 minute (n)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minute (n)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 Stunde (n)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 Tag (e)
HBase Service Advanced Configuration Snippet (Sicherheitsventil) für hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Java-Konfigurationsoptionen für HBase RegionServer:
-XX: + UseParNewGC -XX: + UseConcMarkSweepGC -XX: CMSInitiatingOccupancyFraction = 70 -XX: + CMSParallelRemarkEnabled -XX: ReservedCodeCacheSize = 256m
hbase.snapshot.master.timeoutMillis: 2 Minute (n)
hbase.snapshot.region.timeout: 2 minute (n)
hbase.snapshot.master.timeout.millis: 2 Minute (n)
HBase REST Server Maximale Protokollgröße: 100 MiB
Maximale Anzahl von HBase REST Server-Protokolldateisicherungen: 5
HBase Thrift Server Maximale Protokollgröße: 100 MiB
Maximale Anzahl von HBase Thrift Server-Protokolldateisicherungen: 5
Master Max Log Size: 100 MiB
Maximale Sicherung der Master-Protokolldatei: 5
RegionServer Max. Protokollgröße: 100 MiB
Maximale RegionServer-Protokolldateisicherungen: 5
HBase Active Master-Erkennungsfenster: 4 Minute (n)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 Millisekunden
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Maximale Prozessdateideskriptoren: 180.000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Region Mover-Themen: 6
Client Java Heap Größe in Bytes: 1 GiB
HBase REST Server-Standardgruppe: 3 GiB
HBase Thrift Server Standardgruppe: 3 GiB
Java-Heap-Größe des HBase-Masters in Bytes: 16 GiB
Java-Heap-Größe von HBase RegionServer in Bytes: 32 GiB
+ ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Tabellen erstellen:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns: t1 UniformSplit -c 64 -f vgl
alter 'ns: t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}Es gibt einen wichtigen Punkt: In der DataStax-Beschreibung ist nicht angegeben, wie viele Regionen zum Erstellen der HB-Tabellen verwendet wurden, obwohl dies für große Volumes von entscheidender Bedeutung ist. Daher wurde für die Tests die Zahl = 64 gewählt, wodurch bis zu 640 GB gespeichert werden können, d. H. mittelgroße Tabelle.
Zum Zeitpunkt des Tests verfügte HBase über 22.000 Tabellen und 67.000 Regionen (dies wäre für Version 1.2.0 tödlich, wenn nicht der oben erwähnte Patch).
Nun zum Code. Da nicht klar war, welche Konfigurationen für eine bestimmte Datenbank vorteilhafter sind, wurden die Tests in verschiedenen Kombinationen durchgeführt. Das heißt In einigen Tests wurde die Last gleichzeitig auf 4 Tabellen verteilt (alle 4 Knoten wurden für die Verbindung verwendet). In anderen Tests arbeiteten sie mit 8 verschiedenen Tischen. In einigen Fällen betrug die Chargengröße 100, in anderen 200 (Chargenparameter - siehe Code unten). Die Datengröße für value beträgt 10 Byte oder 100 Byte (dataSize). Insgesamt wurden jedes Mal 5 Millionen Datensätze in jede Tabelle geschrieben und abgezogen. Gleichzeitig wurden 5 Streams in jede Tabelle geschrieben / gelesen (Stream-Nummer ist thNum), von denen jeder seinen eigenen Schlüsselbereich verwendete (Anzahl = 1 Million):
if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("BEGIN BATCH "); for (int i = 0; i < batch; i++) { String value = RandomStringUtils.random(dataSize, true, true); sb.append("INSERT INTO ") .append(tableName) .append("(id, title) ") .append("VALUES (") .append(key) .append(", '") .append(value) .append("');"); key++; } sb.append("APPLY BATCH;"); final String query = sb.toString(); session.execute(query); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN ("); for (int i = 0; i < batch; i++) { sb = sb.append(key); if (i+1 < batch) sb.append(","); key++; } sb = sb.append(");"); final String query = sb.toString(); ResultSet rs = session.execute(query); } }
Dementsprechend wurde für HB eine ähnliche Funktionalität bereitgestellt:
Configuration conf = getConf(); HTable table = new HTable(conf, keyspace + ":" + tableName); table.setAutoFlush(false, false); List<Get> lGet = new ArrayList<>(); List<Put> lPut = new ArrayList<>(); byte[] cf = Bytes.toBytes("cf"); byte[] qf = Bytes.toBytes("value"); if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lPut.clear(); for (int i = 0; i < batch; i++) { Put p = new Put(makeHbaseRowKey(key)); String value = RandomStringUtils.random(dataSize, true, true); p.addColumn(cf, qf, value.getBytes()); lPut.add(p); key++; } table.put(lPut); table.flushCommits(); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lGet.clear(); for (int i = 0; i < batch; i++) { Get g = new Get(makeHbaseRowKey(key)); lGet.add(g); key++; } Result[] rs = table.get(lGet); } }
Da der Client für die gleichmäßige Verteilung der Daten in HB sorgen muss, sah die Key-Salting-Funktion folgendermaßen aus:
public static byte[] makeHbaseRowKey(long key) { byte[] nonSaltedRowKey = Bytes.toBytes(key); CRC32 crc32 = new CRC32(); crc32.update(nonSaltedRowKey); long crc32Value = crc32.getValue(); byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7); return ArrayUtils.addAll(salt, nonSaltedRowKey); }
Am interessantesten sind nun die Ergebnisse:

Das selbe wie ein Graph:
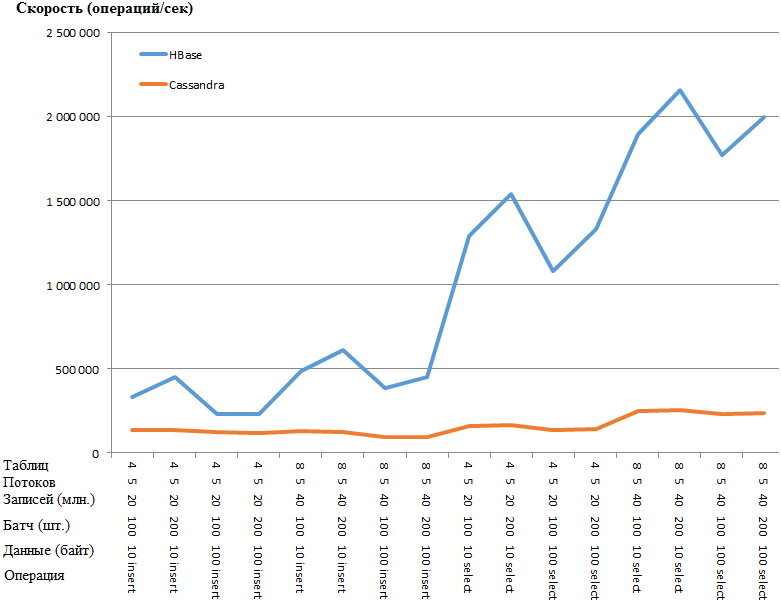
Der Vorteil von HB ist so erstaunlich, dass der Verdacht eines Engpasses in den CS-Einstellungen besteht. Googeln und Torsion der offensichtlichsten Parameter (wie concurrent_writes oder memtable_heap_space_in_mb) führten jedoch nicht zu einer Beschleunigung. Gleichzeitig sind die Protokolle sauber, schwören auf nichts.
Die Daten verteilen sich gleichmäßig auf die Knoten, die Statistiken aller Knoten sind ungefähr gleich.
Hier ist die Statistik in der Tabelle mit einem der KnotenTastenkürzel: ks
Read Count: 9383707
Leselatenz: 0.04287025042448576 ms
Anzahl schreiben: 15462012
Schreibwartezeit: 0.1350068438699957 ms
Ausstehende Flushes: 0
Tabelle: t1
SSTable-Anzahl: 16
Speicherplatz (live): 148,59 MiB
Speicherplatz (gesamt): 148,59 MiB
Von Snapshots belegter Speicherplatz (gesamt): 0 Byte
Ausgenutzter Heapspeicher (gesamt): 5,17 MiB
SSTabiles Kompressionsverhältnis: 0,5720989576459437
Anzahl der Partitionen (Schätzung): 3970323
Anzahl der Memtable-Zellen: 0
Speicherbare Datengröße: 0 Bytes
Speicher außerhalb des verwendeten Heapspeichers: 0 Byte
Anzahl der Memtable-Schalter: 5
Lokale Lesezählung: 2346045
Lokale Leselatenz: NaN ms
Lokale Schreibanzahl: 3865503
Lokale Schreibwartezeit: NaN ms
Ausstehende Spülungen: 0
Prozent repariert: 0.0
Bloom Filter falsch positiv: 25
Bloom Filter falsches Verhältnis: 0,00000
Verwendeter Bloom-Filterraum: 4,57 MiB
Bloom-Filter aus verwendetem Heap-Speicher: 4,57 MiB
Indexzusammenfassung aus verwendetem Heap-Speicher: 590,02 KiB
Komprimierungsmetadaten außerhalb des verwendeten Heapspeichers: 19,45 KiB
Komprimierte Partition, Mindestbytes: 36
Komprimierte Partition, maximale Bytes: 42
Mittlere Bytes der komprimierten Partition: 42
Durchschnittliche Anzahl lebender Zellen pro Schicht (letzte fünf Minuten): NaN
Maximale Anzahl lebender Zellen pro Schicht (letzte fünf Minuten): 0
Durchschnittliche Grabsteine pro Scheibe (letzte fünf Minuten): NaN
Maximale Grabsteine pro Scheibe (letzte fünf Minuten): 0
Verworfene Mutationen: 0 Bytes
Der Versuch, die Größe des Stapels zu reduzieren (bis zum Senden nacheinander), hatte keine Auswirkung, es wurde nur noch schlimmer. Es ist möglich, dass dies tatsächlich die maximale Leistung für CS ist, da die mit CS erzielten Ergebnisse mit denen für DataStax vergleichbar sind - etwa Hunderttausende von Vorgängen pro Sekunde. Wenn Sie sich die Ressourcennutzung ansehen, werden Sie außerdem feststellen, dass CS viel mehr CPU und Festplatten benötigt:
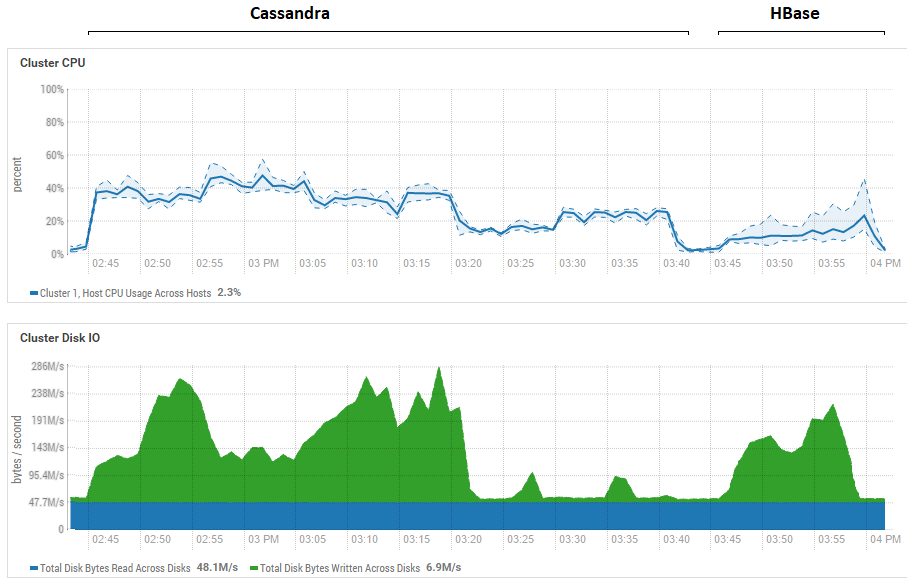 Die Abbildung zeigt die Auslastung während des Durchlaufs aller Tests hintereinander für beide Datenbanken.
Die Abbildung zeigt die Auslastung während des Durchlaufs aller Tests hintereinander für beide Datenbanken.In Bezug auf die leistungsstarken Lesevorteile von HB. Es ist ersichtlich, dass bei beiden Datenbanken die Festplattenauslastung während des Lesens äußerst gering ist (Lesetests sind der letzte Teil des Testzyklus für jede Datenbank, z. B. für CS von 15:20 bis 15:40 Uhr). Im Fall von HB ist der Grund klar: Die meisten Daten hängen im Speicher, im Memstore, und einige wurden im Blockcache zwischengespeichert. Was CS betrifft, ist nicht ganz klar, wie es funktioniert. Die Festplattenauslastung ist jedoch ebenfalls nicht sichtbar. Es wurde jedoch nur für den Fall versucht, den row_cache_size_in_mb = 2048-Cache einzuschalten und caching = {'keys': 'ALL', 'rows_per_partition': ' 2.000.000 '}, aber das machte es noch ein bisschen schlimmer.
Es lohnt sich auch noch einmal, einen signifikanten Punkt über die Anzahl der Regionen in HB zu sagen. In unserem Fall wurde der Wert 64 angezeigt.Wenn Sie ihn verringern und auf beispielsweise 4 einstellen, sinkt die Geschwindigkeit beim Lesen um das 2-fache. Der Grund ist, dass der Memstore schneller verstopft und die Dateien häufiger gelöscht werden und beim Lesen mehr Dateien verarbeitet werden müssen, was für HB eine recht komplizierte Operation ist. Unter realen Bedingungen kann dies durch Überlegen der Strategie der Voraufteilung und Verdichtung behoben werden. Insbesondere verwenden wir ein selbst erstelltes Dienstprogramm, das den Müll sammelt und HFiles ständig im Hintergrund komprimiert. Es ist möglich, dass für die DataStax-Tests im Allgemeinen 1 Region pro Tabelle zugewiesen wurde (was nicht korrekt ist), und dies würde etwas klarer machen, warum HB bei ihren Lesetests so viel verloren hat.
Die vorläufigen Schlussfolgerungen daraus sind wie folgt. Unter der Annahme, dass beim Testen keine groben Fehler gemacht wurden, ist Cassandra wie ein Koloss mit Lehmfüßen. Genauer gesagt, während sie auf einem Bein balanciert, wie auf dem Bild am Anfang des Artikels, zeigt sie relativ gute Ergebnisse, aber wenn sie unter den gleichen Bedingungen kämpft, verliert sie geradezu. Gleichzeitig haben wir unter Berücksichtigung der geringen CPU-Auslastung unserer Hardware gelernt, zwei RegionServer-HBs pro Host zu installieren und damit die Produktivität zu verdoppeln. Das heißt Unter Berücksichtigung der Ressourcennutzung ist die Situation für CS noch bedauerlicher.
Natürlich sind diese Tests sehr synthetisch und die Datenmenge, die hier verwendet wurde, ist relativ bescheiden. Es ist möglich, dass beim Umschalten auf Terabyte die Situation anders ist, aber wenn wir für HB Terabyte laden können, hat sich dies für CS als problematisch herausgestellt. Auch bei diesen Datenträgern wurde häufig eine OperationTimedOutException ausgelöst, obwohl die Parameter für die Antworterwartung im Vergleich zu den Standardwerten bereits um ein Vielfaches erhöht wurden.
Ich hoffe, dass wir durch gemeinsame Anstrengungen die CS-Engpässe finden und wenn wir es schaffen, sie zu beschleunigen, werde ich definitiv am Ende des Beitrags Informationen über die Endergebnisse hinzufügen.
UPD: Die folgenden Richtlinien wurden beim CS-Setup angewendet:
disk_optimization_strategy: drehen
MAX_HEAP_SIZE = "32G"
HEAP_NEWSIZE = "3200M"
-Xms32G
-Xmx32G
-XX: + UseG1GC
-XX: G1RSetUpdatingPauseTimePercent = 5
-XX: MaxGCPauseMillis = 500
-XX: InitiatingHeapOccupancyPercent = 70
-XX: ParallelGCThreads = 32
-XX: ConcGCThreads = 8Da dies bei den Betriebssystemeinstellungen ein ziemlich langer und komplizierter Vorgang ist (Root abrufen, Server neu starten usw.), wurden diese Empfehlungen nicht angewendet. Andererseits sind beide Datenbanken unter gleichen Bedingungen, sodass alles fair ist.
Im Codeteil wird ein Connector für alle Threads erstellt, die in die Tabelle schreiben:
connector = new CassandraConnector(); connector.connect(node, null, CL); session = connector.getSession(); session.getCluster().getConfiguration().getSocketOptions().setConnectTimeoutMillis(120000); KeyspaceRepository sr = new KeyspaceRepository(session); sr.useKeyspace(keyspace); prepared = session.prepare("insert into " + tableName + " (id, title) values (?, ?)");
Daten wurden verbindlich übermittelt:
for (Long key = count * thNum; key < count * (thNum + 1); key++) { String value = RandomStringUtils.random(dataSize, true, true); session.execute(prepared.bind(key, value)); }
Dies hatte keinen wesentlichen Einfluss auf die Aufnahmeleistung. Aus Gründen der Zuverlässigkeit habe ich den Ladevorgang mit dem YCSB-Tool gestartet, absolut das gleiche Ergebnis. Unten ist die Statistik für einen Thread (von 4):
2020-01-18 14: 41: 53: 180 315 Sek .: 10.000.000 Operationen; 21589,1 aktuelle Operationen / Sek .; [CLEANUP: Count = 100, Max = 2236415, Min = 1, Avg = 22356.39, 90 = 4, 99 = 24, 99.9 = 2236415, 99.99 = 2236415] [INSERT: Count = 119551, Max = 174463, Min = 273, Durchschn. = 2582,71, 90 = 3491, 99 = 16767, 99,9 = 99711, 99,99 = 171263]
[OVERALL], RunTime (ms), 315539
[OVERALL], Throughput (ops / sec), 31691.803548848162
[TOTAL_GCS_PS_Scavenge], Count, 161
[TOTAL_GC_TIME_PS_Scavenge], Zeit (ms), 2433
[TOTAL_GC_TIME _% _ PS_Scavenge], Zeit (%), 0,7710615803434757
[TOTAL_GCS_PS_MarkSweep], Count, 0
[TOTAL_GC_TIME_PS_MarkSweep], Zeit (ms), 0
[TOTAL_GC_TIME _% _ PS_MarkSweep], Zeit (%), 0.0
[TOTAL_GCs], Count, 161
[TOTAL_GC_TIME], Zeit (ms), 2433
[TOTAL_GC_TIME_%], Zeit (%), 0,7710615803434757
[EINFÜGEN], Operationen, 10.000.000
[INSERT], AverageLatency (us), 3114.2427012
[INSERT], MinLatency (us), 269
[EINFÜGEN], MaxLatency (us), 609279
[EINFÜGEN], 95thPercentileLatency (us), 5007
[INSERT], 99thPercentileLatency (us), 33439
[INSERT], Return = OK, 10000000
Hier sehen Sie, dass die Geschwindigkeit eines Streams ungefähr 32.000 Datensätze pro Sekunde beträgt, 4 Streams gearbeitet haben und 128.000.Anscheinend gibt es bei den aktuellen Einstellungen des Festplattensubsystems nichts mehr auszudrücken.
Über das Lesen interessanter. Dank der Ratschläge der Genossen konnte er radikal beschleunigen. Das Ablesen wurde nicht in 5, sondern in 100 Strömen durchgeführt. Eine Erhöhung auf 200 hatte keinen Effekt. Ebenfalls zum Builder hinzugefügt:
.withLoadBalancingPolicy (neue TokenAwarePolicy (DCAwareRoundRobinPolicy.builder (). build ())
Als Ergebnis ergab der Test früher 159 644 Operationen (5 Streams, 4 Tabellen, 100 Batch), jetzt:
100 Threads, 4 Tabellen, Batch = 1 (einzeln): 301 969 Ops
100 Threads, 4 Tabellen, Batch = 10: 447 608 Ops
100 Threads, 4 Tabellen, Batch = 100: 625 655 Ops
Da die Ergebnisse bei Chargen besser sind, habe ich ähnliche * Tests mit HB durchgeführt:
 * Da bei der Arbeit mit 400 Threads die zuvor verwendete Funktion RandomStringUtils die CPU zu 100% belastete, wurde sie durch einen schnelleren Generator ersetzt.
* Da bei der Arbeit mit 400 Threads die zuvor verwendete Funktion RandomStringUtils die CPU zu 100% belastete, wurde sie durch einen schnelleren Generator ersetzt.Daher führt eine Erhöhung der Anzahl der Threads beim Laden von Daten zu einer geringfügigen Erhöhung der HB-Leistung.
Was das Lesen betrifft, sind hier die Ergebnisse mehrerer Optionen. Auf Anforderung von
0x62ash wurde der Befehl flush vor dem Lesen ausgeführt, und es werden auch verschiedene andere Optionen zum Vergleich angegeben:
Memstore - Lesen aus dem Speicher, d.h. vor dem Spülen auf die Festplatte.
HFile + zip - Lesen von Dateien, die mit dem GZ-Algorithmus komprimiert wurden.
HFile + Upzip - Aus Dateien ohne Komprimierung lesen.
Eine interessante Funktion ist bemerkenswert - kleine Dateien (siehe Feld „Daten“, in das 10 Bytes geschrieben werden) werden langsamer verarbeitet, insbesondere wenn sie komprimiert sind. Dies ist natürlich nur bis zu einer bestimmten Größe möglich. Offensichtlich wird eine 5-GB-Datei nicht schneller als 10 MB verarbeitet. Dies zeigt jedoch deutlich, dass in all diesen Tests immer noch kein Feld für die Erforschung verschiedener Konfigurationen vorhanden ist.
Aus Interesse habe ich den YCSB-Code für die Arbeit mit HB-Chargen von 100 Stück korrigiert, um die Latenz und mehr zu messen. Unten ist das Ergebnis der Arbeit von 4 Kopien, die in ihre Tabellen mit jeweils 100 Threads geschrieben haben. Es stellte sich Folgendes heraus:
Eine Operation = 100 Datensätze[OVERALL], RunTime (ms), 1165415
[OVERALL], Durchsatz (ops / sec), 858.06343662987
[TOTAL_GCS_PS_Scavenge], Count, 798
[TOTAL_GC_TIME_PS_Scavenge], Zeit (ms), 7346
[TOTAL_GC_TIME _% _ PS_Scavenge], Time (%), 0.6303334005483026
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Zeit (ms), 74
[TOTAL_GC_TIME _% _ PS_MarkSweep], Zeit (%), 0,006349669431061038
[TOTAL_GCs], Count, 799
[TOTAL_GC_TIME], Zeit (ms), 7420
[TOTAL_GC_TIME_%], Time (%), 0.6366830699793635
[EINFÜGEN], Operationen, 1.000.000
[INSERT], AverageLatency (us), 115893.891644
[INSERT], MinLatency (us), 14528
[INSERT], MaxLatency (us), 1470463
[EINFÜGEN], 95thPercentileLatency (us), 248319
[EINFÜGEN], 99thPercentileLatency (us), 445951
[INSERT], Return = OK, 1,000,000
20/01/19 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation: Schließen von zookeeper sessionid = 0x36f98ad0a4ad8cc
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Sitzung: 0x36f98ad0a4ad8cc geschlossen
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread wurde heruntergefahren
[OVERALL], RunTime (ms), 1165806
[OVERALL], Durchsatz (ops / sec), 857.7756504941646
[TOTAL_GCS_PS_Scavenge], Count, 776
[TOTAL_GC_TIME_PS_Scavenge], Zeit (ms), 7517
[TOTAL_GC_TIME _% _ PS_Scavenge], Time (%), 0.6447899564764635
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Zeit (ms), 63
[TOTAL_GC_TIME _% _ PS_MarkSweep], Zeit (%), 0,005403986598113236
[TOTAL_GCs], Count, 777
[TOTAL_GC_TIME], Zeit (ms), 7580
[TOTAL_GC_TIME_%], Zeit (%), 0,6501939430745767
[EINFÜGEN], Operationen, 1.000.000
[INSERT], AverageLatency (us), 116042.207936
[INSERT], MinLatency (us), 14056
[INSERT], MaxLatency (us), 1462271
[EINFÜGEN], 95thPercentileLatency (us), 250239
[INSERT], 99thPercentileLatency (us), 446719
[INSERT], Return = OK, 1,000,000
20/01/19 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation: Schließen von zookeeper sessionid = 0x26f98ad07b6d67e
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Sitzung: 0x26f98ad07b6d67e geschlossen
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread wurde heruntergefahren
[OVERALL], RunTime (ms), 1165999
[OVERALL], Durchsatz (ops / sec), 857.63366863951
[TOTAL_GCS_PS_Scavenge], Count, 818
[TOTAL_GC_TIME_PS_Scavenge], Zeit (ms), 7557
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6481137633908777
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 79
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006775305982252128
[TOTAL_GCs], Count, 819
[TOTAL_GC_TIME], Time(ms), 7636
[TOTAL_GC_TIME_%], Time(%), 0.6548890693731299
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116172.212864
[INSERT], MinLatency(us), 7952
[INSERT], MaxLatency(us), 1458175
[INSERT], 95thPercentileLatency(us), 250879
[INSERT], 99thPercentileLatency(us), 446463
[INSERT], Return=OK, 1000000
20/01/19 13:19:17 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cd
20/01/19 13:19:17 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cd closed
20/01/19 13:19:17 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1166860
[OVERALL], Throughput(ops/sec), 857.000839860823
[TOTAL_GCS_PS_Scavenge], Count, 707
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7239
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6203829079752499
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 67
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0057419056270675145
[TOTAL_GCs], Count, 708
[TOTAL_GC_TIME], Time(ms), 7306
[TOTAL_GC_TIME_%], Time(%), 0.6261248136023173
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116230.849308
[INSERT], MinLatency(us), 7352
[INSERT], MaxLatency(us), 1443839
[INSERT], 95thPercentileLatency(us), 250623
[INSERT], 99thPercentileLatency(us), 447487
[INSERT], Return=OK, 1000000
, CS AverageLatency(us) 3114, HB AverageLatency(us) = 1162 (, 1 = 100 ).
— HBase. , SSD . , , , 4 , 400 , . : — . . ScyllaDB , …