Lange Zeit wollte ich einen Artikel über Numba schreiben und seine Geschwindigkeit mit Si vergleichen. Haskell-Artikel „ Schneller als C ++; langsamer als PHP “. In den Kommentaren zu diesem Artikel wurde die numba-Bibliothek erwähnt, mit der sich die Geschwindigkeit der Codeausführung in Python auf magische Weise der Geschwindigkeit in s annähern lässt. In diesem Artikel wird nach einem kurzen Rückblick auf numba (Teil 1) eine etwas detailliertere Analyse dieser Situation ( Teil 2 ) gegeben.

Der Hauptnachteil einer Python ist ihre Geschwindigkeit. Das Übertakten von Pythons mit unterschiedlichem Erfolg begann fast in den ersten Tagen seines Bestehens: Schuppen , Psyco , unbeladenes Flachwasser , Sittich , Theano , Nuitka , Pythran , Cython , Pypy , Numba .
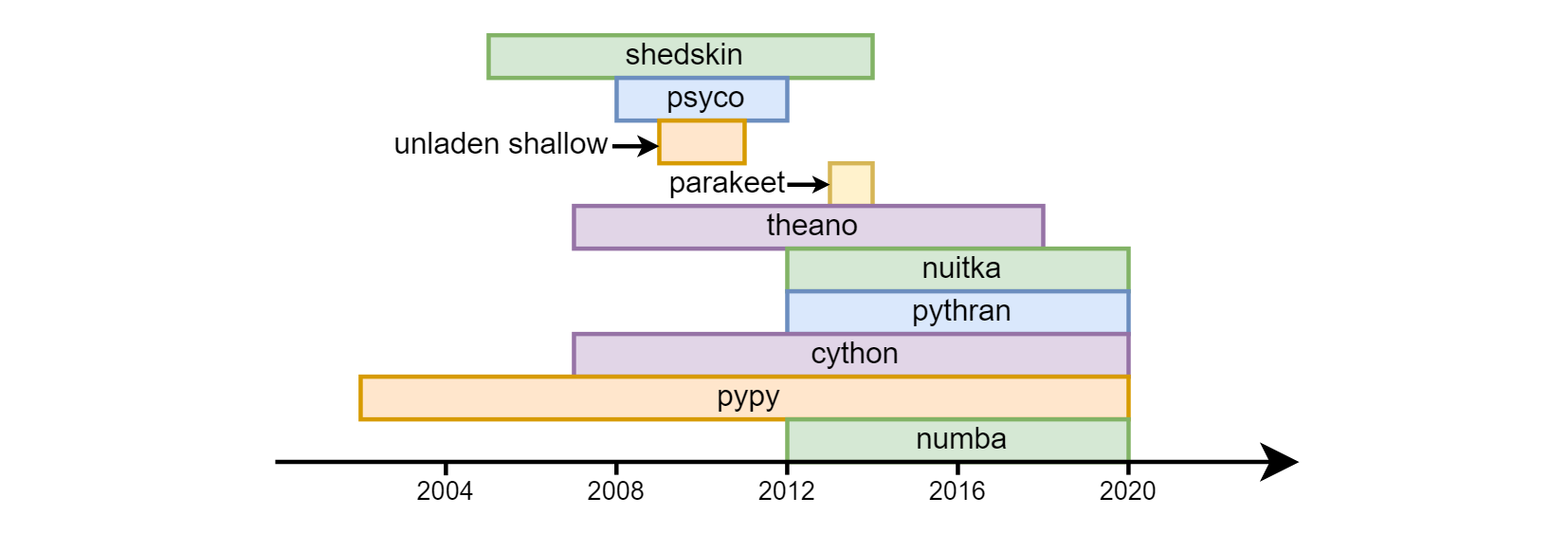
Bisher sind die letzten drei am gefragtesten. Cython (nicht zu verwechseln mit Cpython) - ist semantisch ganz anders als reguläres Python. In der Tat ist dies eine separate Sprache - eine Mischung aus C und Python. pypy (eine alternative Implementierung des Python-Übersetzers mit jit-Kompilierung) und numba (eine Bibliothek zur Code-Kompilierung in llvm) gingen unterschiedliche Wege. pypy erklärte zunächst die Unterstützung für alle Python-Konstrukte. In numba gingen sie davon aus, dass es am häufigsten cpu-gebundene mathematische Berechnungen erfordert, sie identifizierten den Teil der mit Berechnungen verbundenen Sprache und begannen, sie zu übertakten, wodurch die "Abdeckung" allmählich zunahm (zum Beispiel gab es bis vor kurzem keine Unterstützung für Leitungen) , jetzt ist sie erschienen). Dementsprechend wird nicht das gesamte Programm in numba übertaktet, sondern es werden separate Funktionen verwendet . Auf diese Weise können Sie hohe Geschwindigkeit und Abwärtskompatibilität mit Bibliotheken numba , die numba (noch) nicht unterstützt. Numpy wird (mit geringfügigen Einschränkungen) sowohl in pypy als auch in numba .
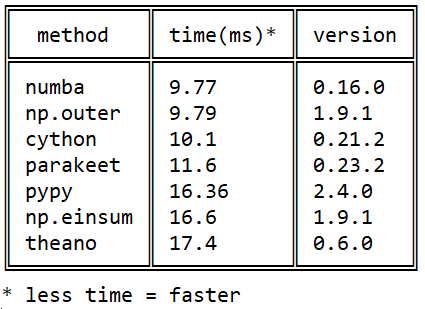 Meine Bekanntschaft mit Numba begann 2015 mit dieser Frage zum Stackoverflow über die Geschwindigkeit der Matrixmultiplikation in Python: Effizientes Außenprodukt in Python
Meine Bekanntschaft mit Numba begann 2015 mit dieser Frage zum Stackoverflow über die Geschwindigkeit der Matrixmultiplikation in Python: Effizientes Außenprodukt in Python
Seitdem sind viele Ereignisse in jeder der Bibliotheken aufgetreten, aber das Bild in Bezug auf numba / numba / pypy sich numba nicht geändert: numba überholt cython durch die Verwendung nativer Prozessoranweisungen ( cython kann nicht jit) und pypy - aufgrund einer effizienteren Ausführung von llvm-Bytecode .
Numba ist nützlich für mich bei der Arbeit (Verarbeitung hyperspektraler Bilder) und im Unterricht (numerische Integration, Lösen von Differentialgleichungen).
wie man einstellt
Vor ein paar Jahren gab es Probleme mit der Installation, jetzt wurde alles gelöst: Es lässt sich sowohl durch pip install numba als auch durch conda install numba gleich gut conda install numba . llvm wird automatisch angezogen und installiert.
wie man beschleunigt
Um eine Funktion zu beschleunigen, müssen Sie den njit-Dekorator eingeben, bevor Sie ihn definieren:
from numba import njit @njit def f(n): s = 0. for i in range(n): s += sqrt(i) return s
Beschleunigung von 40 mal.
Die Wurzel wird benötigt, da sonst numba die Summe des arithmetischen Verlaufs (!) Erkennt und in konstanter Zeit berechnet.
jit vs njit
Bisher war nur der @jit Modus (nicht @njit ) relevant. Der Punkt ist, dass Sie in diesem Modus Operationen verwenden können, die von numba nicht unterstützt werden: die numba mit hoher Geschwindigkeit erreicht die erste solche Operation, verlangsamt sich dann und dauert bis zum Ende der Funktionsausführung mit der üblichen Python-Geschwindigkeit an, auch wenn in der Funktion nichts mehr "Verbotenes" auftritt ( der sogenannte Objektmodus), der offensichtlich irrational ist. Jetzt geben @jit und nach auf. Es wird immer empfohlen, @njit (oder in voller Form @jit(nopython=True) ) zu verwenden. In diesem Modus schwört die Zahl mit Ausnahmen auf solche Stellen - es ist besser, sie neu zu schreiben, um nicht an Geschwindigkeit zu verlieren.
was kann beschleunigen
In übertakteten Funktionen kann nur ein Teil der Python- und Numba-Funktionalität verwendet werden. Alle Operatoren, Funktionen und Klassen sind in Bezug auf die Numba in zwei Teile unterteilt: die, die die Numba "versteht" und die, die sie "nicht versteht".
In der numba-Dokumentation gibt es zwei solcher Listen (mit Beispielen):
- eine Untergruppe der Python- Funktionen, die numbe und
- eine Untermenge der numpy- Funktion, die numbe kennt.
Aus den bemerkenswerten in diesen Listen:
- eine numba "versteht" Python-Listen mit einem schnellen (amortisierten O (1)) Zusatz zum Ende, den numpy "nicht versteht" (obwohl nur homogene aus Elementen desselben Typs),
- Numpy's Arrays, die nicht im Basis-Python enthalten sind. Versteht auch
- Tupel: Sie können, wie ein normaler Python, Elemente verschiedener Typen enthalten.
- wörterbücher: numba hat eine eigene Implementierung eines typisierten Wörterbuchs. Alle Schlüssel müssen vom selben Typ sein, genau wie die Werte. Das Python-Diktat kann nicht an numba übergeben werden, aber das numba
numba.typed.Dict kann in Python erstellt und nach / von numba übertragen werden (während es in Python etwas langsamer als Python arbeitet). - In letzter Zeit können str und bytes jedoch nur als Eingabeparameter noch nicht angelegt werden.
Sie versteht überhaupt keine anderen Bibliotheken (insbesondere scipy und pandas).
Aber selbst diese Untergruppe der Sprache, die sie versteht, reicht aus, um den größten Teil des Codes für wissenschaftliche Anwendungen zu übertakten, auf die sich numba in erster Linie konzentriert.
wichtig!
Von den übertakteten Funktionen können nur übertaktete und keine übertakteten Funktionen aufgerufen werden.
(obwohl übertaktete Funktionen von übertaktet und nicht übertaktet aufgerufen werden können).
Globals
In übertakteten Funktionen werden globale Variablen zu Konstanten: Ihr Wert wird beim Kompilieren der Funktion festgelegt ( Beispiel ). => Verwenden Sie keine globalen Variablen in übertakteten Funktionen (außer Konstanten).
Unterschriften
In der Zahl jeder Funktion werden eine oder mehrere Arten von Eingabe- und Ausgabeargumenten abgebildet, d.h. Unterschriften. Beim ersten Aufruf der Funktion wird die Signatur generiert und der entsprechende binäre Funktionscode automatisch übersetzt. Beim Starten mit anderen Argumenttypen werden neue Signaturen und neue Binärdateien erstellt (die alten bleiben erhalten). Somit erfolgt der "Exit to the Mode" in Bezug auf die Ausführungsgeschwindigkeit für jede Signatur, beginnend mit dem zweiten Durchlauf mit diesen Arten von Argumenten. Also auch nicht
- "Aufwärmen des Caches" durch Starten mit kleinen Eingabearrays oder
@jit(cache=True) das Argument @jit(cache=True) an, um den kompilierten Code mit seinem automatischen Laden bei nachfolgenden Programmstarts auf der Festplatte zu speichern (obwohl dieser erste Start in der heutigen Praxis noch etwas langsamer ist als die nachfolgenden, aber schneller als ohne cache=True ). .
Es gibt einen dritten Weg. Signaturen können manuell gesetzt werden:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y >>> f.signatures [(int16, int16)]
Wenn Sie eine Funktion mit der im Dekorator angegebenen Signatur ausführen, ist die erste Ausführung schnell: Die Kompilierung wird in dem Moment ausgeführt, in dem der Python die Definition der Funktion sieht, und nicht beim ersten Start. Es kann mehrere Signaturen geben, die Reihenfolge ihrer Reihenfolge ist wichtig.
Warnung: Diese letzte Methode ist nicht zukunftssicher. Die Autoren von numba warnen davor, dass sich die Syntax für die Angabe von Typen in Zukunft ändern könnte. @jit / @njit ohne Signaturen ist in dieser Hinsicht eine sicherere Option.
f.signatures erst dann signiert, wenn der Python davon erfährt, f.signatures nach dem ersten Funktionsaufruf oder wenn sie manuell festgelegt wurden.
Zusätzlich zu f.signatures Signaturen über f.inspect_types() Zusätzlich zu den Typen der Eingabeparameter zeigt diese Funktion die Typen der Ausgabeparameter sowie die Typen aller lokalen Variablen an.
Zusätzlich zu den Typen der Eingabe- und Ausgabeparameter können die Typen der lokalen Variablen manuell angegeben werden:
from numba import int16, int32 @njit(int32(int16, int16), locals={'z': int32}) def f(x, y): z = y + 10 return x + z
int
In numba haben Ganzzahlen keine lange Arithmetik wie in "einfachem" Python, aber es gibt Standardtypen mit verschiedenen Breiten von int8 bis int64 ( int64 in der Dokumentation). Es gibt auch die Typen int_ (sowie float_ ), mit denen Sie der Zahl die Möglichkeit geben, die (aus ihrer Sicht) optimale Feldbreite zu wählen.
Klassen
Es gibt generell Unterstützung für Klassen (@jitclass), aber bisher ist es experimentell, daher ist es besser, sie vorerst nicht zu verwenden (momentan ist es meiner Erfahrung nach mit ihnen viel langsamer als ohne sie).
benutzerdefinierte dtypes
Numba unterstützt eine bestimmte Alternative zu Klassen aus Arrays mit Numpy-Struktur oder, mit anderen Worten, benutzerdefinierten Datentypen. Sie arbeiten mit der gleichen Geschwindigkeit wie normale Numpy-Arrays. Sie lassen sich leichter indizieren (beispielsweise ist a['y2'] besser lesbar als a[3] ). Interessanterweise ist in numba im Gegensatz zu numpy ein prägnanteres a.y2 zusammen mit der üblichen Syntax a['y2'] . Aber im Allgemeinen lässt ihre Unterstützung in der Numba zu wünschen übrig, und einige Operationen, die sogar in der Numba offensichtlich sind, mit ihnen in der Numba werden ganz untrivial aufgezeichnet.
GPU
Es ist in der Lage, übertakteten Code auf der GPU und im Gegensatz zu demselben, zum Beispiel Pycuda oder Pytorch, nicht nur auf NVIDIA-, sondern auch auf AMD'sHNYH-Karten auszuführen. Damit ist bisher wenig zu tun. Hier ist ein Artikel zum Hub 2016 Dort wurde eine mit C vergleichbare Geschwindigkeit erhalten.
vorzeitige Kompilierung
Es gibt einen Modus für die normale (dh nicht jit) Kompilierung ( Dokumentation ) in der Numba, aber dieser Modus ist nicht der Hauptmodus, ich habe ihn nicht verstanden.
automatische Parallelisierung
Einige Aufgaben (z. B. das Multiplizieren einer Matrix mit einer Zahl) werden auf natürliche Weise parallelisiert. Es gibt jedoch Aufgaben, deren Umsetzung nicht parallelisiert werden kann. Mit dem @njit(parallel=True) Dekorator @njit(parallel=True) analysiert @njit(parallel=True) numba den Code der übertakteten Funktion, findet solche Abschnitte, von denen jeder für sich nicht parallelisiert werden kann, und führt sie gleichzeitig auf verschiedenen CPU-Kernen aus ( Dokumentation ). Bisher konnten Sie Funktionen nur manuell mithilfe von @vectorize ( Dokumentation ) parallelisieren, wodurch Codeänderungen erforderlich wurden.
In der Praxis sieht es so aus: add parallel=True , messen Sie die Geschwindigkeit, wenn wir Glück haben und es schneller geworden ist - wir lassen es, langsamer - wir entfernen es. (** Update Wie im Kommentar zum zweiten Teil des Artikels erwähnt, weist dieses Flag viele offene Fehler auf.)
GIL-Veröffentlichung
Funktionen, die mit @jit(nogil=True) dekoriert sind und in verschiedenen Threads ausgeführt werden, können parallel ausgeführt werden. Um Rennbedingungen zu vermeiden, müssen Sie die Thread-Synchronisierung verwenden.
die Dokumentation
Numbe fehlt noch eine vernünftige Dokumentation. Sie ist, aber nicht alles ist in ihr.
Optimierung
Es gibt eine gewisse Unvorhersehbarkeit bei der manuellen Optimierung von Code: Unpython-Code wird häufig schneller ausgeführt als Python.
Für diejenigen, die sich für das Thema interessieren, kann ich ein Video eines numba-Meisterkurses von der scipy 2017-Konferenz empfehlen (es gibt Quellcodes auf dem Github). Es ist sehr lang und teilweise veraltet (zum Beispiel, Strings werden bereits unterstützt), aber es hilft, sich einen Überblick zu verschaffen: Es enthält insbesondere Informationen zu Pythonic / Unpythonic, JIT (parallel = True) usw.
Im zweiten Teil betrachten wir die Verwendung von numba unter Verwendung des Codes aus dem am Anfang des Artikels erwähnten Artikel.