Dies ist der zweite Teil des Artikels über Numba. Das erste war eine historische Einführung und eine kurze numba Bedienungsanleitung. Hier präsentiere ich einen leicht geänderten Aufgabencode aus dem Haskell-Artikel „ Schneller als C ++; langsamer als PHP “(vergleicht die Leistung von Implementierungen eines Algorithmus in verschiedenen Sprachen / Compilern) mit detaillierteren Benchmarks, Grafiken und Erklärungen. Ich sage sofort, dass ich den Artikel " Oh, dieses langsame C / C ++" gesehen habe. Wenn Sie diese Änderungen am C-Code vornehmen, ändert sich höchstwahrscheinlich das Bild ein wenig, aber selbst in diesem Fall kann der Python die Geschwindigkeit von C sogar in dieser Version überschreiten ist selbst bemerkenswert.

Ersetzte die Python-Liste durch ein numpy-Array (und dementsprechend v0[:] durch v0.copy() , da in numpy a[:] die view zurückgibt view anstatt zu kopieren).
Um die Art des Leistungsverhaltens zu verstehen, habe ich einen "Scan" nach der Anzahl der Elemente im Array durchgeführt.
Im Python-Code habe ich time.monotonic durch time.perf_counter , da dies genauer ist (1 gegenüber 1 ms für monoton).
Da numba jit compilation verwendet, sollte diese Kompilierung eines Tages stattfinden. Standardmäßig tritt es beim ersten Aufruf der Funktion auf und wirkt sich unweigerlich auf die Ergebnisse von Benchmarks aus (obwohl Sie dies möglicherweise nicht bemerken, wenn Sie sich die Zeit nach drei Starts nehmen), und es wird auch in der praktischen Anwendung empfunden. Es gibt verschiedene Möglichkeiten, mit diesem Phänomen umzugehen:
1) Ergebnisse der Cache-Kompilierung auf Festplatte:
@njit(cache=True) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
Die Kompilierung erfolgt dann beim ersten Aufruf des Programms und wird bei nachfolgenden Aufrufen von der Festplatte abgerufen.
2) Unterschrift angeben
Die Kompilierung erfolgt in dem Moment, in dem Python die Definition der Funktion analysiert und der erste Start bereits schnell erfolgt.
Die ursprüngliche Zeichenfolge wird übertragen (genauer gesagt, Bytes), aber die Zeichenfolgenunterstützung wurde kürzlich hinzugefügt, sodass die Signatur ziemlich monströs ist (siehe unten). Unterschriften sind in der Regel einfacher geschrieben:
@njit(nb.int64(nb.uint8[:], nb.uint8[:])) def lev_dist(s1, s2):
Dann müssen Sie aber vorher die Bytes in ein Numpy-Array konvertieren:
s1_py = [int(x) for x in b"a" * 15000] s1 = np.array(s1_py, dtype=np.uint8)
oder
s1 = np.full(15000, ord('a'), dtype=np.uint8)
Und Sie können die Bytes so lassen, wie sie sind, und die Signatur in dieser Form angeben:
@njit(nb.int64(nb.bytes(nb.uint8, nb.1d, nb.C), nb.bytes(nb.uint8, nb.1d, nb.C))) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
Die Ausführungsgeschwindigkeit für das Byte- und Numpy-Array von uint8 (in diesem Fall) ist gleich.
3) Cache vorheizen
s1 = b"a" * 15
Die Kompilierung erfolgt dann beim ersten Aufruf und der zweite ist bereits schnell.
C-Code (clang -O3 -march = native) #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> static long lev_dist (const char *s1, unsigned long m, const char *s2, unsigned long n) { // unsigned long m, n; unsigned long i, j; long *v0, *v1; long ret, *temp; /* Edge cases. */ if (m == 0) { return n; } else if (n == 0) { return m; } v0 = malloc (sizeof (long) * (n + 1)); v1 = malloc (sizeof (long) * (n + 1)); if (v0 == NULL || v1 == NULL) { fprintf (stderr, "failed to allocate memory\n"); exit (-1); } for (i = 0; i <= n; ++i) { v0[i] = i; } memcpy (v1, v0, sizeof(long) * (n + 1)); for (i = 0; i < m; ++i) { v1[0] = i + 1; for (j = 0; j < n; ++j) { const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1); const long del_cost = v0[j + 1] + 1; const long ins_cost = v1[j] + 1; #if !defined(__GNUC__) || defined(__llvm__) if (subst_cost < del_cost) { v1[j + 1] = subst_cost; } else { v1[j + 1] = del_cost; } #else v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost; #endif if (ins_cost < v1[j + 1]) { v1[j + 1] = ins_cost; } } temp = v0; v0 = v1; v1 = temp; } ret = v0[n]; free (v0); free (v1); return ret; } int main () { char s1[25001], s2[25001], s3[25001]; int lengths[] = {1000, 2000, 5000, 10000, 15000, 20000, 25000}; FILE *fout; fopen_s(&fout, "c.txt", "w"); for(int j = 0; j < sizeof(lengths)/sizeof(lengths[0]); j++){ int len = lengths[j]; int i; clock_t start_time, exec_time; for (i = 0; i < len; ++i) { s1[i] = 'a'; s2[i] = 'a'; s3[i] = 'b'; } s1[len] = s2[len] = s3[len] = '\0'; start_time = clock (); printf ("%ld\n", lev_dist (s1, len, s2, len)); printf ("%ld\n", lev_dist (s1, len, s3, len)); exec_time = clock () - start_time; fprintf(fout, "%d %.6f\n", len, ((double) exec_time) / CLOCKS_PER_SEC); fprintf (stderr, "Finished in %.3fs\n", ((double) exec_time) / CLOCKS_PER_SEC); } return 0; }
Der Vergleich wurde unter Windows (Windows 10 x 64, Python 3.7.3, Numba 0.45.1, Clang 9.0.0, Intel M5-6Y54 Skylake) und unter Linux (Debian 4.9.30, Python 3.7.4, Numba 0.45.1) durchgeführt. clang 9.0.0).
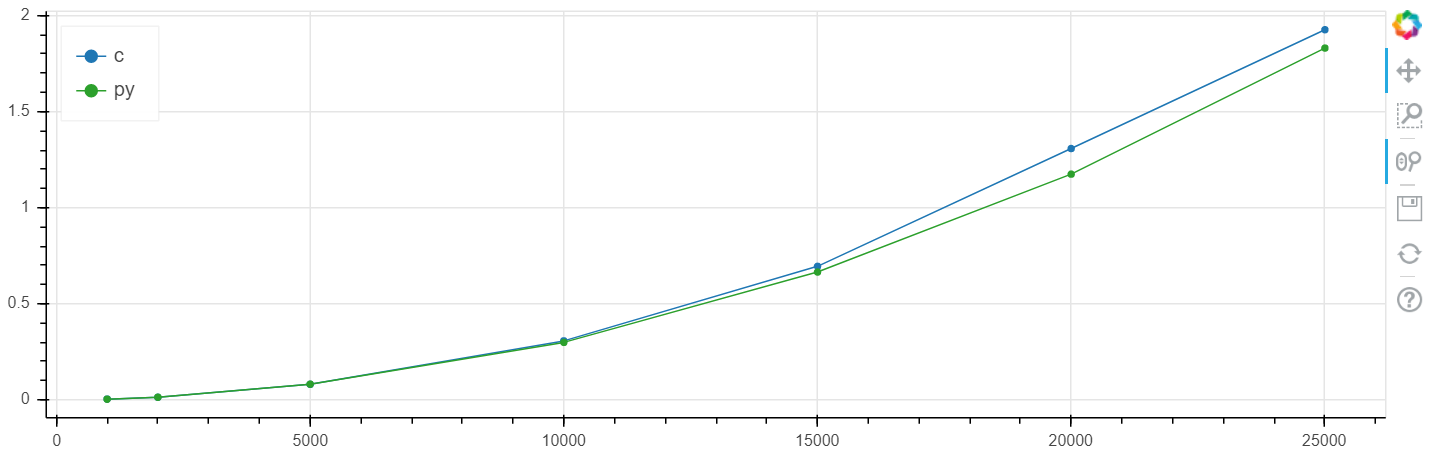
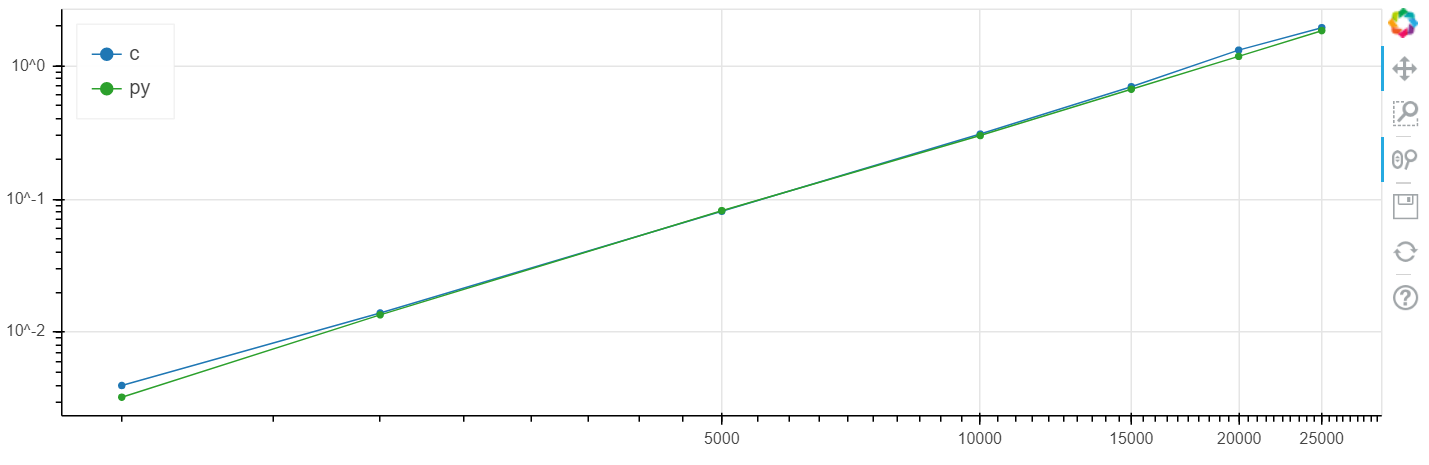
X ist die Größe des Arrays, y ist die Zeit in Sekunden.
Windows-Linearmaßstab:
Windows logarithmische Skala:
Lineare Linux-Skala:

Linux logarithmische Skala
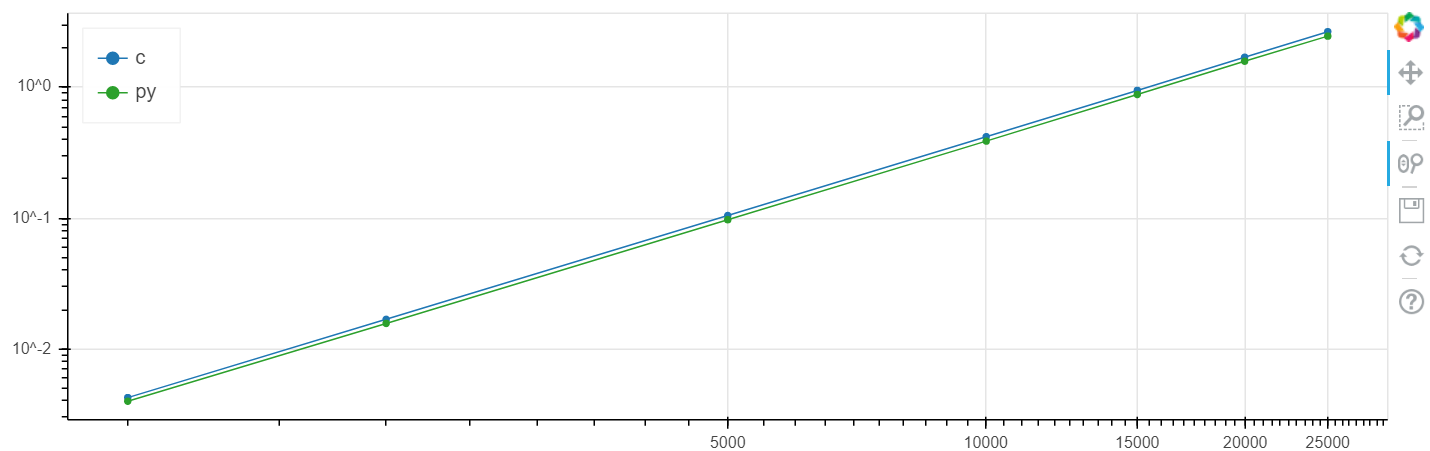
Bei diesem Problem wurde eine Erhöhung der Geschwindigkeit im Vergleich zum Klirren auf dem Niveau von mehreren Prozent erzielt, was im Allgemeinen höher ist als der statistische Fehler.
Ich habe diesen Vergleich wiederholt für verschiedene Aufgaben durchgeführt und wenn numba etwas beschleunigen kann, beschleunigt es es in der Regel auf eine Geschwindigkeit innerhalb der Fehlergrenze, die mit der Geschwindigkeit C übereinstimmt (ohne Verwendung von Assembler-Einfügungen).
Ich wiederhole, dass sich diese langsame C / C ++ - Situation ändern kann, wenn Sie den Code in C von Oh aus ändern.
Ich freue mich über Fragen und Anregungen in den Kommentaren.
PS Wenn Sie die Signatur von Arrays angeben, ist es besser, die Art und Weise des Wechsels von Zeilen / Spalten explizit festzulegen:
damit numba nicht 'C' (si) this oder 'A' (si / fortran auto-recognition) findet - aus irgendeinem Grund beeinträchtigt dies die Leistung auch für eindimensionale Arrays, dafür gibt es eine solche ursprüngliche Syntax: uint8[:,:] this A '(automatische Erkennung), nb.uint8[:, ::1] ist' C '(si), np.uint8[::1, :] ist' F '(fortran).
@njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2):