
In jüngerer Zeit haben wir darüber gesprochen, wie in Tarantool Cartridge geschriebene Anwendungen bereitgestellt werden . Der Vorgang endet jedoch nicht mit der Bereitstellung. Daher werden wir heute unsere Anwendung aktualisieren und verstehen, wie die Topologie, das Sharding und die Autorisierung verwaltet sowie die Konfiguration von Rollen geändert werden.
Neugierig bitte schneiden!
Wo haben wir aufgehört?
Beim letzten Mal haben wir die folgende Topologie konfiguriert:
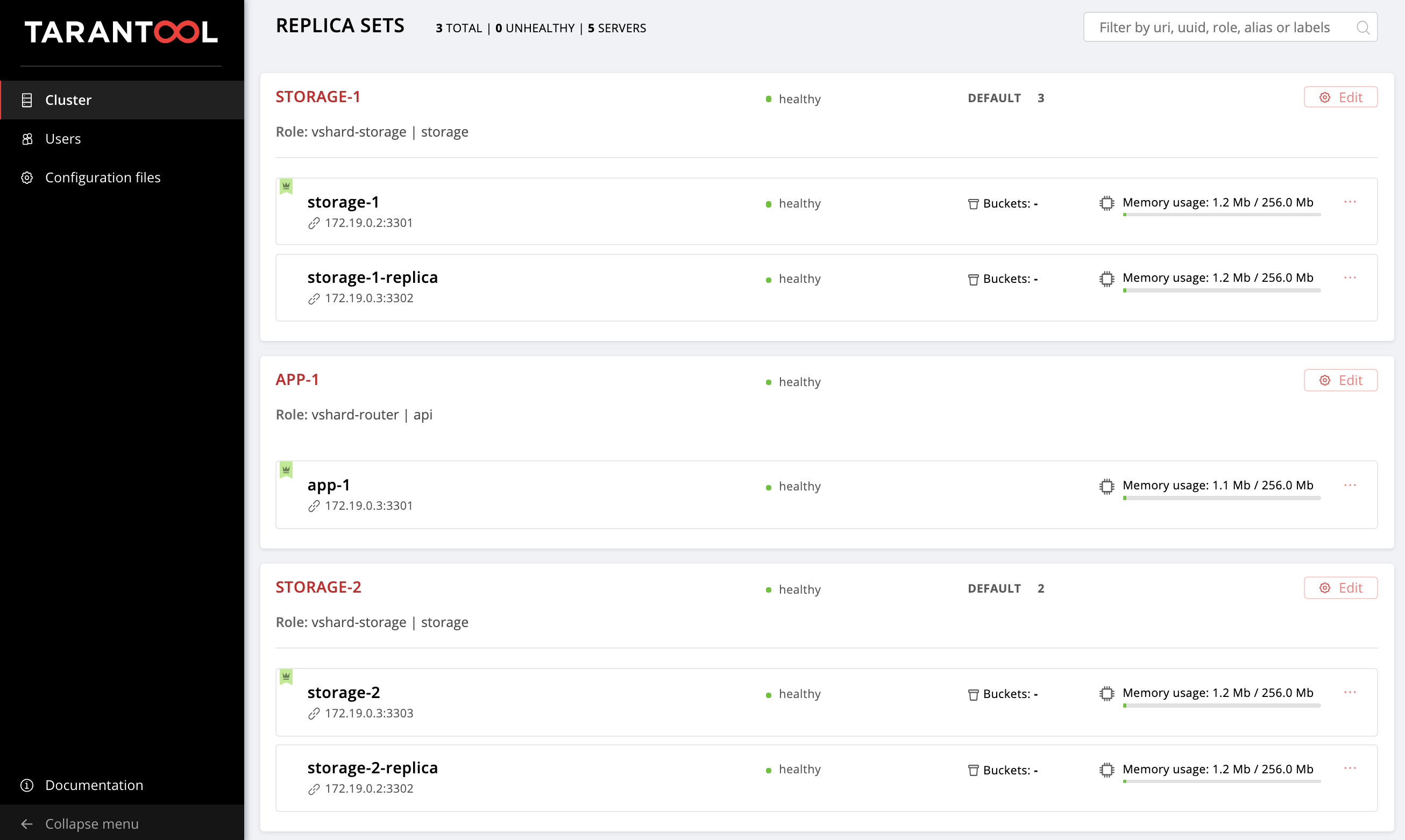
Das Beispiel- Repository konnte ein wenig geändert werden, neue Dateien wurden dort getting-started-app-2.0.0-0.rpm hosts.updated.2.yml getting-started-app-2.0.0-0.rpm und hosts.updated.2.yml . Sie müssen die neue Version nicht herunterladen, hosts.updated.2.yml können das Paket einfach über den Link herunterladen. hosts.updated.2.yml nur benötigt, damit Sie bei Problemen mit der Änderung des aktuellen Inventars einen Blick dorthin hosts.updated.2.yml können.
Wenn Sie alle Schritte des vorherigen Teils dieses Lernprogramms ausgeführt haben, befindet sich jetzt in Ihrer hosts.yml- hosts.yml eine Clusterkonfiguration mit zwei storage (im Repository ist dies hosts.updated.yml ).
Erhöhen Sie unsere virtuellen Maschinen:
$ vagrant up
Installieren Sie die neue Version der Ansible-Rollen-Tarantool-Kassette (die sich natürlich zum Besseren geändert hat):
$ ansible-galaxy install tarantool.cartridge,1.0.2
Also, die aktuelle Cluster-Konfiguration:
--- all: vars: # common cluster variables cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package cartridge_cluster_cookie: app-default-cookie # cluster cookie # common ssh options ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no' # INSTANCES hosts: storage-1: config: advertise_uri: '172.19.0.2:3301' http_port: 8181 app-1: config: advertise_uri: '172.19.0.3:3301' http_port: 8182 storage-1-replica: config: advertise_uri: '172.19.0.3:3302' http_port: 8183 storage-2: config: advertise_uri: '172.19.0.3:3303' http_port: 8184 storage-2-replica: config: advertise_uri: '172.19.0.2:3302' http_port: 8185 children: # GROUP INSTANCES BY MACHINES host1: vars: # first machine connection options ansible_host: 172.19.0.2 ansible_user: vagrant hosts: # instances to be started on the first machine storage-1: storage-2-replica: host2: vars: # second machine connection options ansible_host: 172.19.0.3 ansible_user: vagrant hosts: # instances to be started on the second machine app-1: storage-1-replica: storage-2: # GROUP INSTANCES BY REPLICA SETS replicaset_app_1: vars: # replica set configuration replicaset_alias: app-1 failover_priority: - app-1 # leader roles: - 'api' hosts: # replica set instances app-1: replicaset_storage_1: vars: # replica set configuration replicaset_alias: storage-1 weight: 3 failover_priority: - storage-1 # leader - storage-1-replica roles: - 'storage' hosts: # replica set instances storage-1: storage-1-replica: replicaset_storage_2: vars: # replicaset configuration replicaset_alias: storage-2 weight: 2 failover_priority: - storage-2 - storage-2-replica roles: - 'storage' hosts: # replicaset instances storage-2: storage-2-replica:
Gehen Sie zu http: // localhost: 8181 / admin / cluster / dashboard und vergewissern Sie sich, dass sich Ihr Cluster im richtigen Zustand befindet.
Alles ist wie beim letzten Mal: Wir werden diese Datei schrittweise ändern und beobachten, wie sich der Cluster ändert. Sie können sich die endgültige Version immer in hosts.updated.2.yml
Also los geht's!
Aktualisieren der Anwendung
Lassen Sie uns zunächst unsere Anwendung aktualisieren. getting-started-app-2.0.0-0.rpm Sie sicher, dass sich die Datei getting-started-app-2.0.0-0.rpm im aktuellen Verzeichnis befindet (falls nicht, laden Sie sie aus dem Repository herunter ).
Geben Sie den Pfad zur neuen Version des Pakets an:
--- all: vars: cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-2.0.0-0.rpm # <== cartridge_enable_tarantool_repo: false # <==
Wir haben cartridge_enable_tarantool_repo: false damit die Rolle das Repository nicht mit dem Tarantool-Paket verbindet, das wir bereits das letzte Mal installiert haben. Dies beschleunigt den Bereitstellungsprozess geringfügig, ist jedoch absolut nicht erforderlich.
Starten Sie das Playbook mit dem cartridge-instances Tag:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-instances
Und wir prüfen, ob das Paket aktualisiert wurde:
$ vagrant ssh vm1 [vagrant@svm1 ~]$ sudo yum list installed | grep getting-started-app
Überprüfen Sie, ob die Version 2.0.0 :
getting-started-app.x86_64 2.0.0-0 installed
Jetzt können Sie sicher mit der neuen Version der Anwendung experimentieren.
Scherben einschalten
Lassen Sie uns das Sharding aktivieren, damit wir später die Kontrolle über storage übernehmen können. Das geht ganz einfach. Fügen Sie die Variable cartridge_bootstrap_vshard Abschnitt all.vars :
--- all: vars: ... cartridge_cluster_cookie: app-default-cookie # cluster cookie cartridge_bootstrap_vshard: true # <== ... hosts: ... children: ...
Wir starten:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Beachten Sie, dass wir das cartridge-config Tag angegeben haben, um nur Aufgaben auszuführen, die an der Cluster-Konfiguration beteiligt sind.
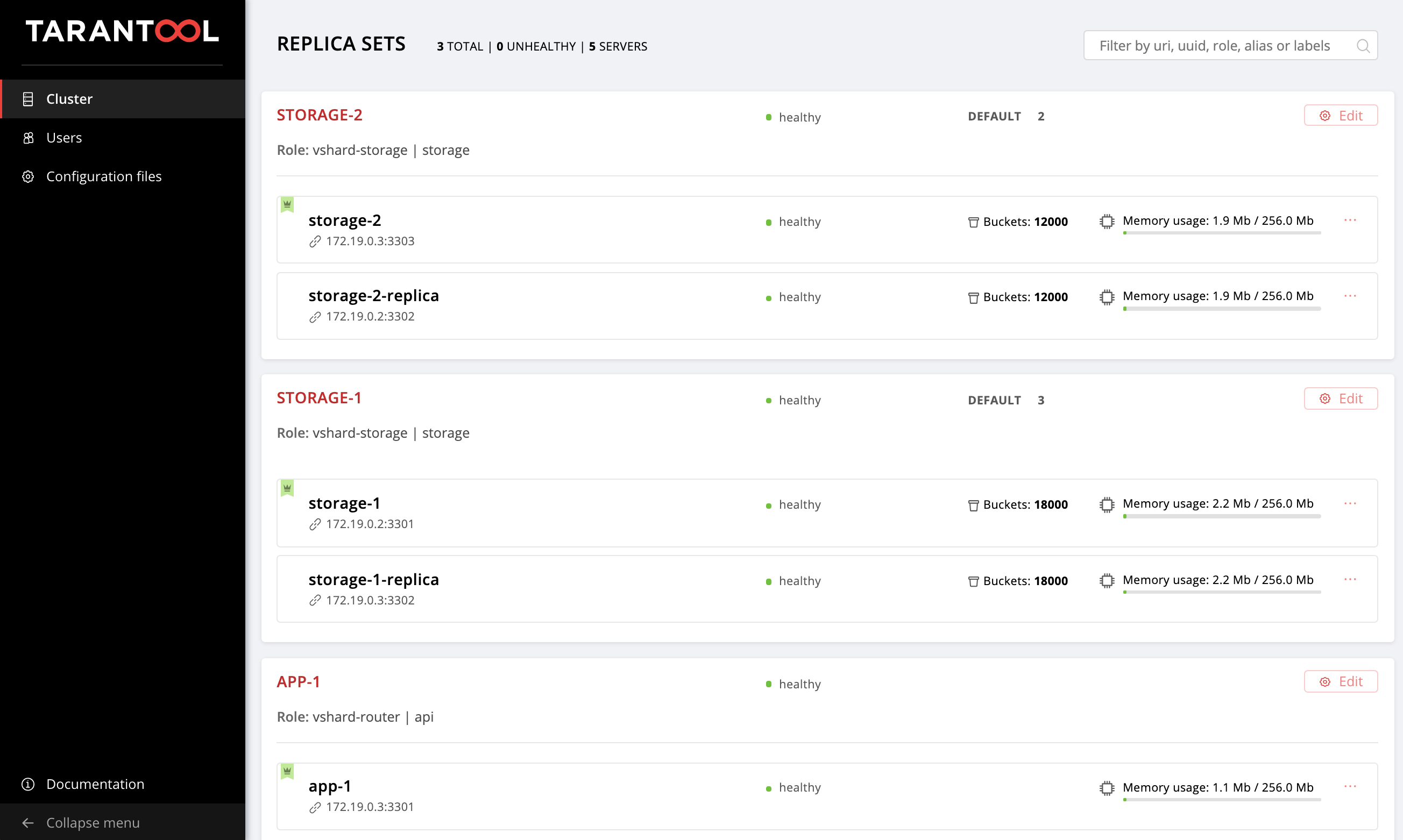
Öffnen Sie die Web-Benutzeroberfläche http: // localhost: 8181 / admin / cluster / dashboard, und stellen Sie sicher, dass unsere Buckets in einem Verhältnis von 2:3 auf die Speicherreplikatsätze verteilt sind.
Aktivieren Sie das automatische Failover
Und jetzt schalten wir den automatischen Failover-Modus ein, damit wir später herausfinden können, was es ist und wie es funktioniert.
Fügen Sie der Konfiguration das cartridge_failover Flag hinzu:
--- all: vars: ... cartridge_cluster_cookie: app-default-cookie # cluster cookie cartridge_bootstrap_vshard: true cartridge_failover: true # <== ... hosts: ... children: ...
Wir starten erneut die Cluster-Management-Aufgaben:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Nachdem Sie das Playbook erfolgreich abgeschlossen haben, können Sie zur Web-Benutzeroberfläche wechseln und sicherstellen, dass der Failover Schalter in der oberen rechten Ecke Failover ist. Um den automatischen Failover-Modus zu deaktivieren, ändern Sie einfach den Wert von cartridge_failover in false und führen Sie das Playbook erneut aus.
Es ist Zeit herauszufinden, um was für ein Regime es sich handelt und warum wir es aktiviert haben.
Wir beschäftigen uns mit Failover
Wahrscheinlich haben Sie die failover_priority bemerkt, die wir für jedes Replikatset angegeben haben. Mal sehen, was es ist.
Tarantool Cartridge bietet einen automatischen Failover-Modus. Jedes Replikatset verfügt über eine Führungslinie - die Instanz, in der es aufgezeichnet wird. Wenn dem Anführer etwas passiert, wird einer der Kommentare seine Rolle übernehmen. Welches? Sehen wir uns das storage-2 Replikatset genauer an:
--- all: ... children: ... replicaset_storage_2: vars: ... failover_priority: - storage-2 - storage-2-replica
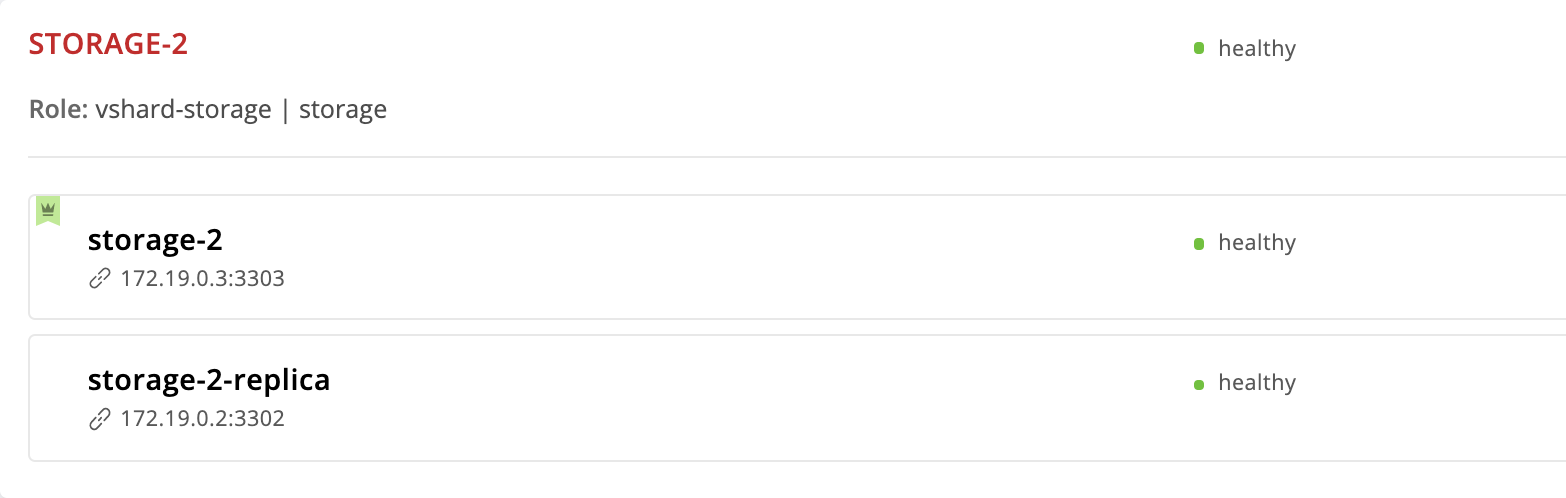
Die storage-2 Instanz haben wir zuerst in failover_priority . In der Web-Benutzeroberfläche wird es zuerst in der Liste der Replicaset-Instanzen angezeigt und mit einer grünen Krone markiert. Dies ist der Leader - die erste in failover_priority angegebene Instanz:
Nun wollen wir sehen, was passiert, wenn dem Leiter des Replikatsets etwas passiert. Wir gehen in die virtuelle Maschine und stoppen die storage-2 Instanz:
$ vagrant ssh vm2 [vagrant@vm2 ~]$ sudo systemctl stop getting-started-app@storage-2
Zurück zur Web-Benutzeroberfläche:

Die Krone bei der storage-2 Instanz wurde rot - dies bedeutet, dass der designierte Anführer nicht mehr gesund ist. Aber das storage-2-replica eine grüne Krone - diese Instanz hat die Führungsverantwortung übernommen, bis storage-2 wieder in Betrieb genommen wird. Dies ist ein automatisches Failover in Aktion.
Lassen Sie uns storage-2 wiederbeleben:
$ vagrant ssh vm2 [vagrant@vm2 ~]$ sudo systemctl start getting-started-app@storage-2
Alles kehrte auf den ersten Platz zurück:
Lassen Sie uns die Reihenfolge der Instanzen in der Priorität des Failovers ändern. Wir machen die storage-2-replica Instanz zu einer führenden Instanz und entfernen storage-2 im Allgemeinen aus der Liste:
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration ... failover_priority: - storage-2-replica # <== ...
Führen Sie cartridge-replicasets für Instanzen aus der Gruppe replicaset_storage_2 aus:
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Wir gehen zu http: // localhost: 8181 / admin / cluster / dashboard und stellen fest, dass sich der Anführer geändert hat:
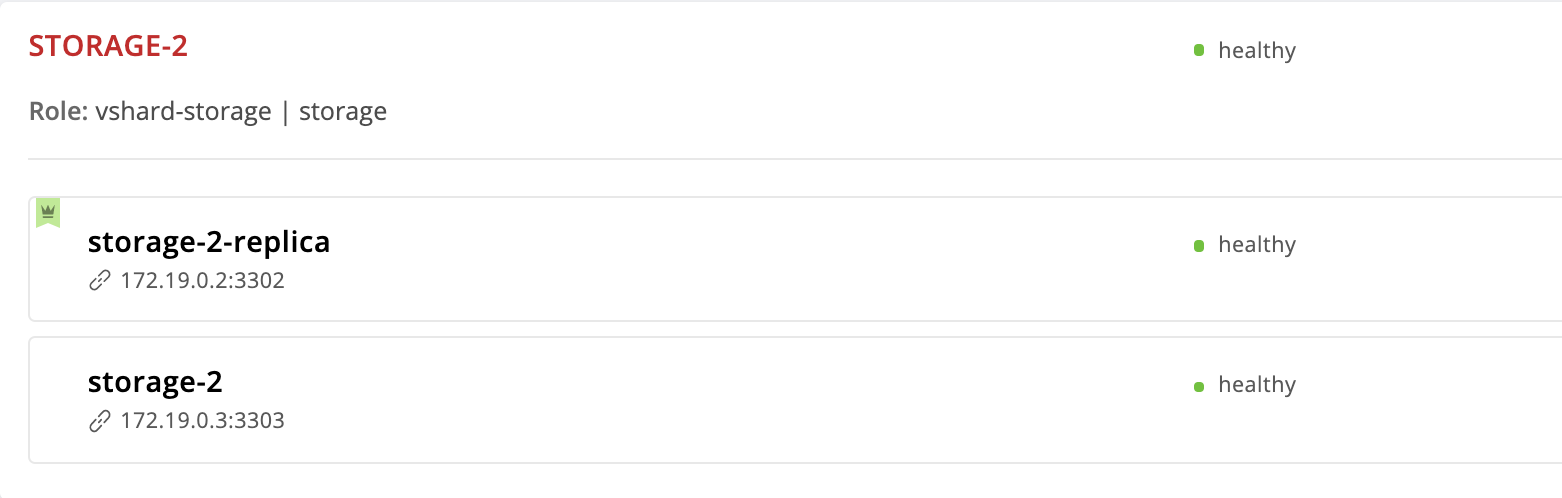
Aber wir haben die storage-2 Instanz aus der Konfiguration entfernt. Warum ist sie immer noch hier? Fakt ist, dass Cartridge, die den neuen Wert " failover_priority erhält failover_priority die Instanzen wie folgt organisiert: Die erste Instanz aus der Liste wird zum Leader, die übrigen angegebenen Instanzen folgen. Instanzen, die in failover_priority nicht erwähnt werden, werden von der UUID sortiert und an das Ende angehängt.
Exil-Instanz
Was aber, wenn wir die Instanz von der Topologie ausschließen wollen? Alles ist sehr einfach: Sie müssen die expelled Flagge übergeben. Lassen Sie uns die storage-2-replica Instanz ausschließen. Er ist jetzt der Anführer, also wird Cartridge uns das nicht erlauben. Aber wir haben keine Angst vor Schwierigkeiten und versuchen immer noch:
--- all: vars: ... hosts: storage-2-replica: config: advertise_uri: '172.19.0.2:3302' http_port: 8185 expelled: true # <== ...
Wir geben das cartridge-replicasets , da das Austreiben einer Instanz eine Topologieänderung darstellt:
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Führen Sie das Playbook aus und sehen Sie den Fehler:

Wie wir gerade gesehen haben, ist es mit Cartridge nicht gerechtfertigt, den aktuellen Replicaset-Leader aus der Topologie zu werfen. Dies ist sehr logisch, da die Replikation asynchron ist und der Ausschluss eines Leaders wahrscheinlich zu Datenverlust führt. Wir müssen einen anderen Anführer angeben und erst danach die Instanz ausschließen. Die Rolle wendet zuerst die neue Replicaset-Konfiguration an und behandelt dann die Ausnahme. Aus diesem Grund ändern wir die failover_priority und führen das Playbook erneut aus:
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration ... failover_priority: - storage-2 # <== ...
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Voila, die storage-2-replica Instanz ist aus der Topologie verschwunden!

Beachten Sie, dass das Instanzexil wirklich endgültig und unwiderruflich ist. Nach dem Entfernen der Instanz aus der Topologie stoppt unsere ansible Rolle den systemd-Dienst und löscht alle Dateien dieser Instanz.

Wenn Sie plötzlich Ihre Meinung ändern und feststellen, dass das storage-2 Replikatset noch eine zweite Instanz benötigt, können Sie es nicht wiederherstellen. Cartridge merkt sich die UUID aller Instanzen, die die Topologie verlassen haben, und lässt nicht zu, dass das Exil zurückkehrt. Sie können eine neue Instanz mit demselben Namen und derselben Konfiguration auslösen, diese hat jedoch offensichtlich eine andere UUID, sodass Cartridge die Verknüpfung zulässt.
Replicaset wird entfernt
Wir haben bereits herausgefunden, dass wir den Anführer des Replikatsets nicht ausweisen dürfen. Aber was ist, wenn wir das storage-2 Replikat dauerhaft entfernen möchten? Es gibt natürlich einen Ausweg.
Um keine Daten zu verlieren, müssen wir zuerst alle Buckets in storage-1 . Dazu setzen wir das Gewicht des storage-2 Replikats auf 0 :
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration replicaset_alias: storage-2 weight: 0 # <== ... ...
Starten Sie die Topologieverwaltung:
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Öffnen Sie die Web-Benutzeroberfläche http: // localhost: 8181 / admin / cluster / dashboard und beobachten Sie, wie alle Buckets in storage-1 fließen:

Wir setzen den storage-2 Anführer auf die ausgeschlossene Flagge und verabschieden uns von diesem Replikatsatz:
--- all: vars: ... hosts: ... storage-2: config: advertise_uri: '172.19.0.3:3303' http_port: 8184 expelled: true # <== ...
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-replicasets
Bitte beachten Sie, dass wir diesmal die limit Option nicht angegeben haben, da mindestens eine Instanz von allen, für die wir das Playbook gestartet haben, nicht als expelled markiert werden sollte.
Also kehrten wir zur ursprünglichen Topologie zurück:
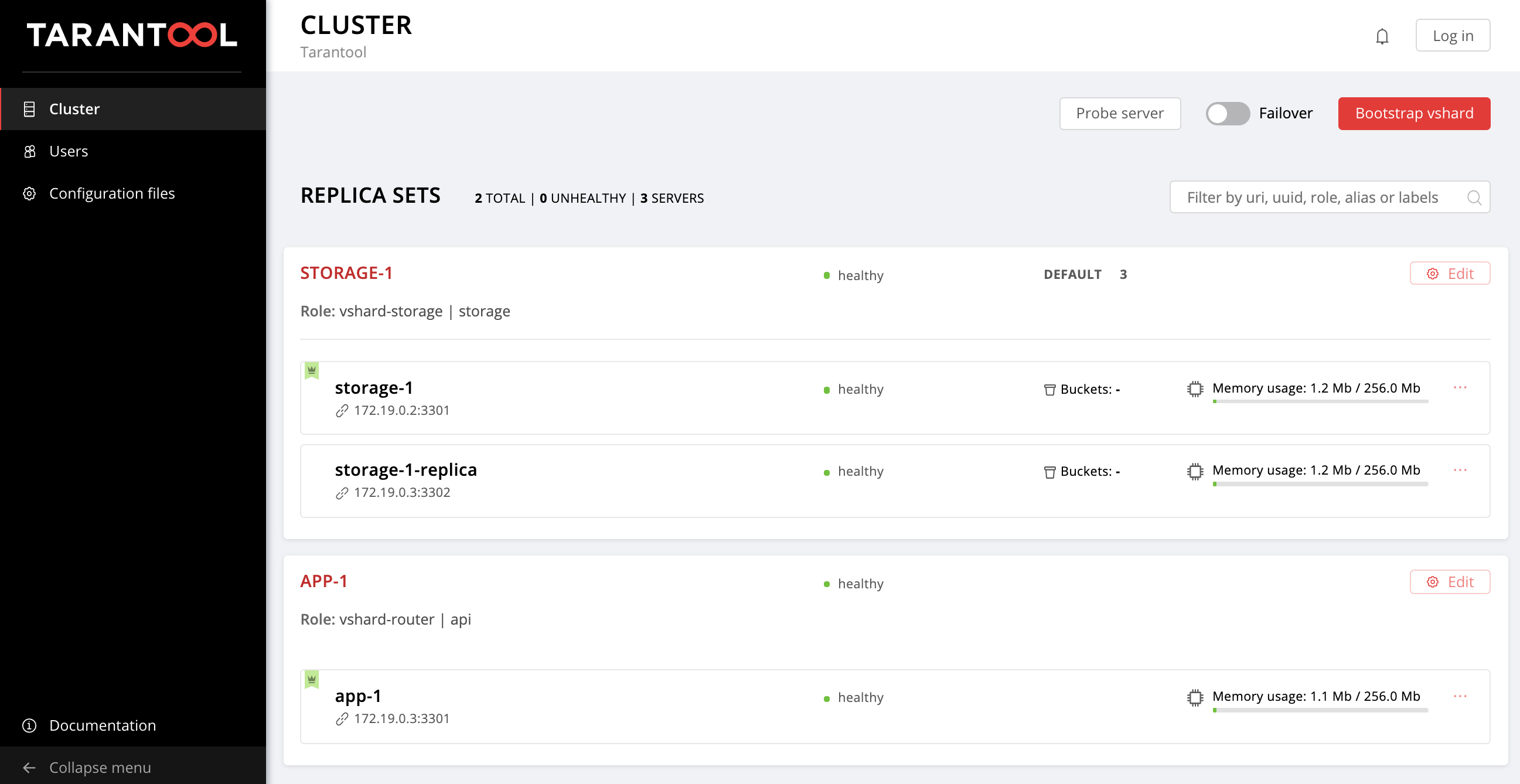
Einloggen
Ich möchte von der Verwaltung von Replikatsätzen ablenken und über Sicherheit nachdenken. Jetzt kann jeder nicht autorisierte Benutzer den Cluster über die Web-Benutzeroberfläche verwalten. Stimmen Sie zu, es sieht so lala aus.
Cartridge bietet die Möglichkeit, Ihr eigenes Autorisierungsmodul wie LDAP (oder was auch immer Sie dort haben) anzuschließen und es zu verwenden, um Benutzer und deren Zugriff auf die Anwendung zu verwalten. Wir werden jedoch das integrierte Autorisierungsmodul verwenden, das Cartridge standardmäßig verwendet. Mit diesem Modul können Sie grundlegende Vorgänge mit Benutzern ausführen (Löschen, Hinzufügen, Bearbeiten) und die Kennwortüberprüfungsfunktion implementieren.
Bitte beachten Sie, dass unsere ansible Rolle das Berechtigungs-Backend benötigt, um alle diese Funktionen zu implementieren.
Wir gehen also von der Theorie zur Praxis über. Machen Sie zunächst die Autorisierung obligatorisch, legen Sie die Sitzungsparameter fest und fügen Sie einen neuen Benutzer hinzu:
--- all: vars: ... # authorization cartridge_auth: # <== enabled: true # enable authorization cookie_max_age: 1000 cookie_renew_age: 100 users: # cartridge users to set up - username: dokshina password: cartridge-rullez fullname: Elizaveta Dokshina email: dokshina@example.com # deleted: true # uncomment to delete user ...
Die Berechtigungsverwaltung wird im Rahmen der cartridge-config . Wir geben dieses Tag an:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Unter http: // localhost: 8181 / admin / cluster / dashboard erwartet uns eine Überraschung:
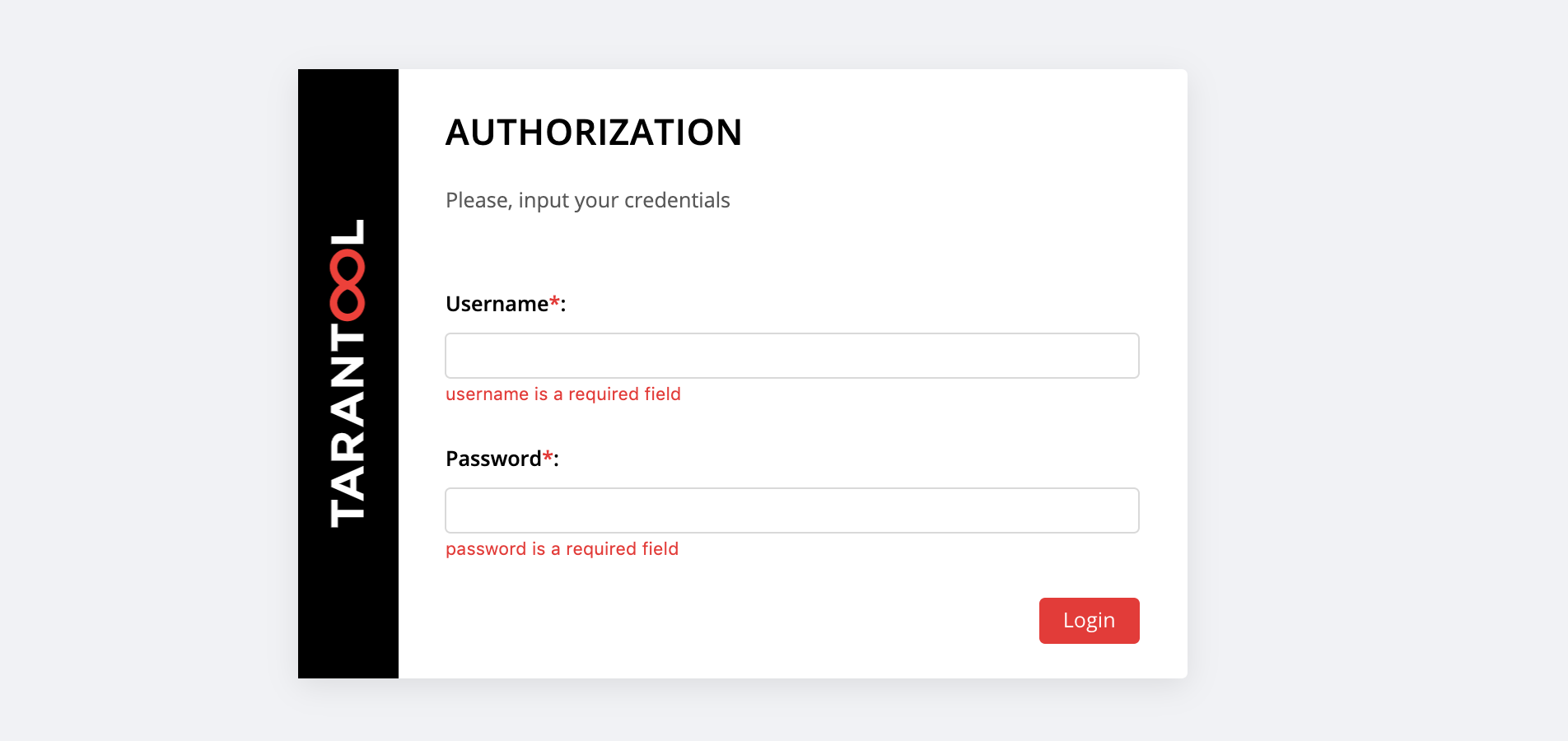
Sie können sich mit dem username und dem password unseres neuen Benutzers anmelden oder sich als admin - der Standardbenutzer - anmelden. Sein Passwort ist Cluster-Cookie, wir haben diesen Wert in der Variablen cartridge_cluster_cookie (dies ist ein app-default-cookie , den Sie nicht einsehen können).
Öffnen Sie nach einer erfolgreichen Anmeldung die Registerkarte Users , um sicherzustellen, dass alles gut gelaufen ist:

Experimentieren Sie mit dem Hinzufügen neuer Benutzer und dem Ändern ihrer Einstellungen. Um einen Benutzer zu löschen, geben Sie das deleted: true Flag für ihn an. Die Werte für email fullname und fullname werden von Cartridge in keiner Weise verwendet, Sie können sie jedoch zur Vereinfachung angeben.
Anwendungskonfiguration
Erinnern wir uns, wie alles begann.
Wir haben eine kleine Anwendung bereitgestellt, die Daten über Kunden und deren Bankkonten speichert. Wie Sie sich erinnern, hat diese Anwendung zwei Rollen: api und storage . Die storage die Datenspeicherung und implementiert das Sharding mithilfe der integrierten vshard-storage Rolle. Die zweite Rolle, api , implementiert einen HTTP-Server mit einer API für die Datenverwaltung. vshard-router ist eine weitere Standardrolle, vshard-router , angeschlossen, die das vshard-router steuert.
Daher stellen wir die erste Anfrage an die Anwendungs-API. Neuen Kunden hinzufügen:
$ curl -X POST -H "Content-Type: application/json" \ -d '{"customer_id":1, "name":"Elizaveta", "accounts":[{"account_id": 1}]}' \ http://localhost:8182/storage/customers/create
Als Antwort erhalten wir so etwas:
{"info":"Successfully created"}
Bitte beachten Sie, dass wir in der URL den 8082 app-1 , 8082 , da dieser diese API implementiert.
Jetzt aktualisieren wir den Kontostand unseres neuen Benutzers:
$ curl -X POST -H "Content-Type: application/json" \ -d "{\"account_id\": 1, \"amount\": \"1000\"}" \ http://localhost:8182/storage/customers/1/update_balance
In der Antwort sehen wir den aktualisierten Saldo:
{"balance":"1000.00"}
Super, alles funktioniert! Die API ist implementiert, Cartridge beschäftigt sich mit Daten-Sharding, wir haben bereits eine Failover-Priorität für Notfälle eingerichtet und sogar die Autorisierung aktiviert. Es ist Zeit, die Konfiguration der Anwendung vorzunehmen.
Die aktuelle Cluster-Konfiguration wird in einer verteilten Konfigurationsdatei gespeichert. Jede Instanz speichert eine Kopie dieser Datei, und Cartridge stellt die Synchronisation zwischen allen Knoten des Clusters sicher. In dieser Datei können wir die Konfiguration der Rollen unserer Anwendung festlegen. Cartridge übernimmt die Verteilung der neuen Konfiguration auf alle Instanzen.
Schauen wir uns den aktuellen Inhalt dieser Datei an. Gehen Sie zur Registerkarte Cofiguration files und klicken Sie auf die Schaltfläche Download :

In der heruntergeladenen config.yml config.yml finden wir eine leere Tabelle. Kein Wunder, denn wir haben noch keine Parameter angegeben:
--- [] ...
Tatsächlich ist die Konfigurationsdatei unseres Clusters nicht leer, sondern speichert die aktuelle Topologie, die Autorisierungseinstellungen und die Sharding-Einstellungen. Cartridge wird es jedoch nicht so einfach sein, diese Informationen weiterzugeben, sie sind für den internen Gebrauch bestimmt und werden daher in verborgenen Systembereichen gespeichert, die wir nicht bearbeiten können.
Jede Anwendungsrolle kann einen oder mehrere Konfigurationsabschnitte verwenden. Das Herunterladen einer neuen Konfiguration erfolgt in zwei Schritten: Zunächst überprüfen alle Rollen, ob sie bereit sind, neue Parameter zu akzeptieren. Wenn keine Einwände erhoben werden, werden die Änderungen übernommen. Wenn jemand dagegen ist, erfolgt ein Rollback.
Kehren wir zu unserer Bewerbung zurück. Die api Rolle verwendet den Abschnitt "Maximaler max-balance ", in dem der maximal zulässige Kontostand auf einem Kundenkonto gespeichert wird. Lassen Sie uns diesen Abschnitt konfigurieren, aber natürlich nicht manuell, sondern mithilfe unserer Ansible-Rolle.
Jetzt ist die Anwendungskonfiguration (oder vielmehr ein Teil davon, der uns zur Verfügung steht) eine leere Tabelle. Fügen Sie einen max-balance Abschnitt mit einem Wert von 100000 . Wir schreiben die Variable cartridge_app_config in unsere Inventardatei:
--- all: vars: ... # cluster-wide config cartridge_app_config: # <== max-balance: # section name body: 1000000 # section body # deleted: true # uncomment to delete section max-balance ...
Wir haben den Abschnittsnamen, max-balance und dessen Inhalt body . Der Inhalt eines Abschnitts kann nicht nur eine Zahl, sondern auch eine Tabelle oder eine Zeile sein, je nachdem, wie die Rolle geschrieben ist und welche Art von Wert Sie verwenden möchten.
Wir starten:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Und wir prüfen, ob sich das maximal zulässige Guthaben wirklich geändert hat:
$ curl -X POST -H "Content-Type: application/json" \ -d "{\"account_id\": 1, \"amount\": \"1000001\"}" \ http://localhost:8182/storage/customers/1/update_balance
Als Antwort erhalten wir einen Fehler, wie wir wollten:
{"info":"Error","error":"Maximum is 1000000"}
Sie können die Konfigurationsdatei auf der Registerkarte Konfigurationsdateien erneut herunterladen, um sicherzustellen, dass dort ein neuer Abschnitt angezeigt wird:
--- max-balance: 1000000 ...
Versuchen Sie, der Anwendungskonfiguration neue Abschnitte hinzuzufügen, deren Inhalt zu ändern oder sie vollständig zu löschen (dazu müssen Sie das Flag deleted: true in dem Abschnitt setzen).
Informationen zur Verwendung einer verteilten Konfiguration in Rollen finden Sie in der Dokumentation zu Tarantool Cartridge.
Denken Sie daran, vagrant halt aufzurufen, um die vagrant halt anzuhalten vagrant halt wenn Sie mit der Arbeit fertig sind.
Abschließend
Beim letzten Mal haben wir gelernt, wie verteilte Tarantool Cartridge-Anwendungen mithilfe einer speziellen Ansible-Rolle bereitgestellt werden. Heute haben wir die Anwendung aktualisiert und auch die Verwaltung von Topologie, Sharding, Autorisierung und Konfiguration der Anwendung gemeistert.
Hören Sie nicht damit auf, lernen Sie verschiedene Ansätze zum Schreiben von Ansible-Spielbüchern und verwenden Sie Ihre Anwendungen mit maximalem Komfort.
Wenn etwas für Sie nicht funktioniert oder wenn Sie Ideen zur Verbesserung unserer anonymen Rolle haben, können Sie gerne ein Ticket starten. Wir helfen Ihnen immer bei der Lösung Ihres Problems und freuen uns über interessante Angebote!