Um Kubernetes vollständig zu beherrschen, müssen Sie die verschiedenen Möglichkeiten zur Skalierung von Clusterressourcen kennen: Laut
den Entwicklern des Systems ist dies eine der Hauptaufgaben von Kubernetes. Wir haben eine umfassende Überprüfung der Mechanismen der horizontalen und vertikalen automatischen Skalierung und Größenänderung von Clustern sowie Empfehlungen zu deren effektiver Verwendung vorbereitet.
Der
Artikel Kubernetes Autoscaling 101: Cluster Autoscaler, Horizontal Autoscaler und Vertical Pod Autoscaler wurde von einem Team übersetzt, das
Autoscaling in
Kubernetes aaS von Mail.ru implementiert hat
.Warum es wichtig ist, über Skalierung nachzudenken
Kubernetes ist ein Tool für Ressourcenverwaltung und Orchestrierung. Natürlich ist es schön, an coolen Bereitstellungs-, Überwachungs- und Pod-Verwaltungsfunktionen zu basteln (das Pod-Modul ist eine Gruppe von Containern, die als Antwort auf eine Anfrage gestartet werden).
Sie sollten jedoch über folgende Punkte nachdenken:
- Wie skaliere ich Module und Anwendungen?
- Wie können Container betriebsbereit und effizient gehalten werden?
- Wie kann man auf ständige Änderungen im Code und bei den Arbeitslasten der Benutzer reagieren?
Die Konfiguration von Kubernetes-Clustern zum Ausgleichen von Ressourcen und Leistung kann eine Herausforderung sein und erfordert Expertenwissen über die internen Funktionen von Kubernetes. Die Auslastung Ihrer Anwendung oder Dienste kann im Laufe des Tages oder sogar innerhalb einer Stunde schwanken, sodass der Ausgleich am besten als kontinuierlicher Prozess dargestellt wird.
Kubernetes Autoscale-Ebenen
Effektives Autoscaling erfordert die Koordination zwischen zwei Ebenen:
- Pod-Ebene, einschließlich horizontaler (Horizontal Pod Autoscaler, HPA) und vertikaler Auto-Skalierung (Vertical Pod Autoscaler, VPA). Dadurch werden die verfügbaren Ressourcen für Ihre Container skaliert.
- Die Clusterebene, die vom Cluster Autoscaler (CA) -System gesteuert wird, erhöht oder verringert die Anzahl der Knoten im Cluster.
Horizontales Auto-Scale-Modul (HPA)
Wie der Name schon sagt, skaliert HPA die Anzahl der Pod-Replikate. Als Auslöser für die Änderung der Anzahl der Replikate verwenden die meisten Entwickler die CPU- und Speicherlast. Sie können das System jedoch basierend auf
benutzerdefinierten Metriken , deren
Kombination oder sogar
externen Metriken skalieren.
Hoher HPA-Workflow:
- HPA überprüft kontinuierlich die während der Installation angegebenen Metrikwerte mit einem Standardintervall von 30 Sekunden.
- HPA versucht, die Anzahl der Module zu erhöhen, wenn der angegebene Schwellenwert erreicht ist.
- HPA aktualisiert die Anzahl der Replikate im Bereitstellungs- / Replikationscontroller.
- Der Bereitstellungs- / Replikationscontroller stellt dann alle erforderlichen Zusatzmodule bereit.
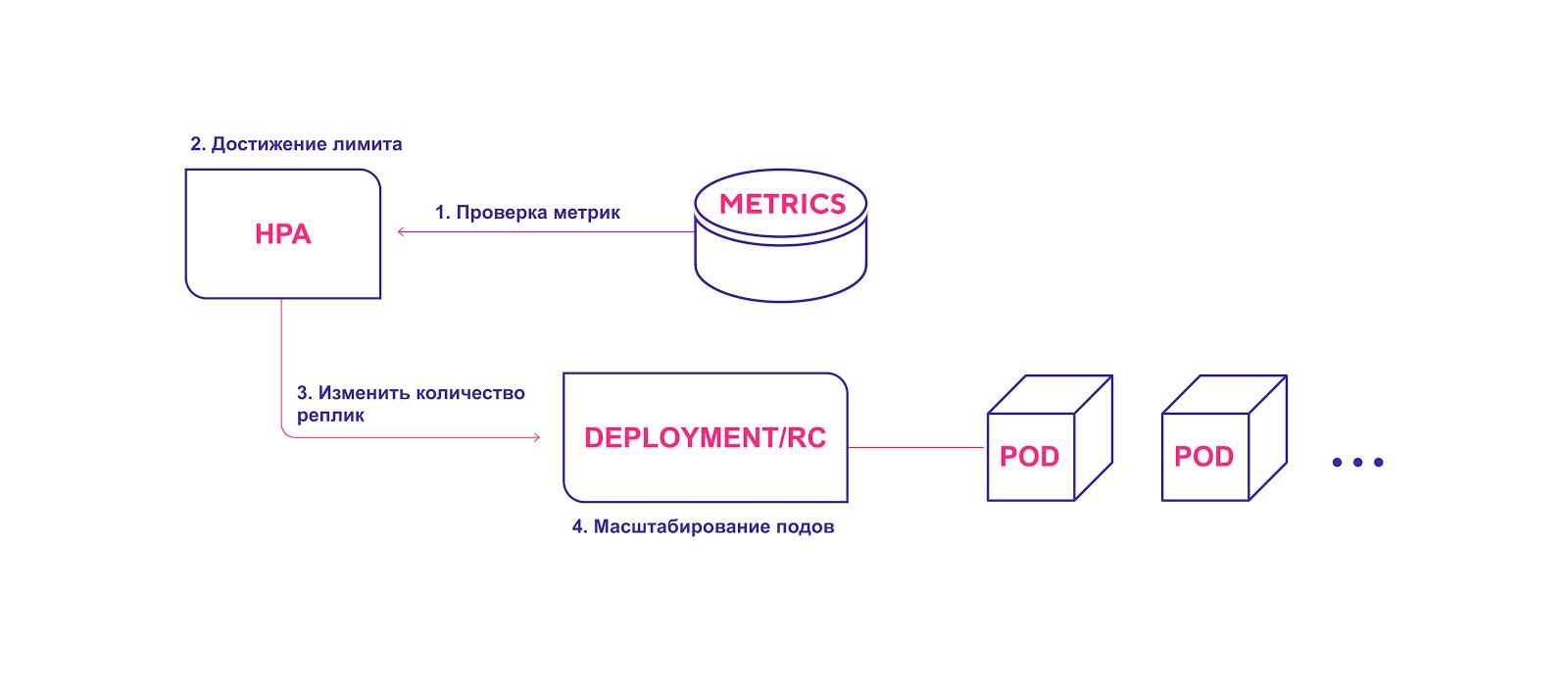 HPA startet den Modulbereitstellungsprozess, wenn der Schwellenwert für Metriken erreicht ist
HPA startet den Modulbereitstellungsprozess, wenn der Schwellenwert für Metriken erreicht istBeachten Sie bei der Verwendung von HPA Folgendes:
- Das standardmäßige HPA-Validierungsintervall beträgt 30 Sekunden. Sie wird im Controller-Manager mit dem Flag Horizontal-Pod-Autoscaler-Sync-Period gesetzt .
- Der relative Standardfehler beträgt 10%.
- Nach der letzten Erhöhung der Modulanzahl erwartet HPA, dass sich die Metriken innerhalb von drei Minuten stabilisieren. Dieses Intervall wird durch das Horizontal-Pod-Autoscaler-Upscale-Delay- Flag festgelegt.
- Nach der letzten Reduzierung der Modulanzahl rechnet die HPA mit einer Stabilisierung von fünf Minuten. Dieses Intervall wird durch das Horizontal-Pod-Autoscaler-Downscale-Delay- Flag festgelegt.
- HPA funktioniert am besten mit Bereitstellungsobjekten, nicht mit Replikationscontrollern. Die horizontale automatische Skalierung ist nicht kompatibel mit fortlaufenden Aktualisierungen, die Replikationscontroller direkt manipulieren. Bei der Bereitstellung hängt die Anzahl der Replikate direkt von den Bereitstellungsobjekten ab.
Vertikale automatische Skalierung von Pods
Vertical Auto Scale (VPA) weist vorhandenen Pods mehr (oder weniger) Prozessor- oder Speicherzeit zu. Es eignet sich für Pods mit oder ohne Stateful Stateless, ist aber hauptsächlich für Stateful Services gedacht. Sie können jedoch VPA für zustandslose Module anwenden, wenn Sie die Menge der ursprünglich zugewiesenen Ressourcen automatisch anpassen müssen.
VPA reagiert auch auf OOM-Ereignisse (zu wenig Speicher, zu wenig Speicher). Um die Prozessorzeit und die Speichergröße zu ändern, müssen Sie den Pod neu starten. Beim Neustart beachtet der VPA das
Pods Distribution Budget (PDB ), um die Mindestanzahl von Modulen zu gewährleisten.
Sie können die minimale und maximale Menge an Ressourcen für jedes Modul festlegen. Sie können also die maximale Größe des zugewiesenen Speichers auf 8 GB beschränken. Dies ist nützlich, wenn die aktuellen Knoten nur nicht mehr als 8 GB Speicher pro Container zuweisen können. Detaillierte Spezifikationen und Betriebsmechanismen sind im
offiziellen VPA-Wiki beschrieben .
Darüber hinaus verfügt VPA über eine interessante Empfehlungsfunktion (VPA Recommender). Es verfolgt die Ressourcennutzung und die OOM-Ereignisse aller Module, um basierend auf einem intelligenten Algorithmus unter Berücksichtigung historischer Metriken neue Werte für Speicher- und Prozessorzeit bereitzustellen. Es gibt auch eine API, die einen Pod-Deskriptor verwendet und die vorgeschlagenen Ressourcenwerte zurückgibt.
Es ist anzumerken, dass VPA Recommender das "Limit" der Ressourcen nicht überwacht. Dies kann dazu führen, dass das Modul Ressourcen innerhalb von Knoten monopolisiert. Es ist besser, einen Grenzwert auf Namespace-Ebene festzulegen, um eine enorme Verschwendung von Arbeitsspeicher oder Prozessorzeit zu vermeiden.
Übergeordnetes VPA-Schema:
- Der VPA überprüft kontinuierlich die während der Installation angegebenen Metrikwerte mit einem Standardintervall von 10 Sekunden.
- Wenn der angegebene Schwellenwert erreicht ist, versucht der VPA, die zugewiesene Menge an Ressourcen zu ändern.
- VPA aktualisiert die Ressourcenmenge im Deployment / Replication Controller.
- Wenn Sie die Module neu starten, werden alle neuen Ressourcen auf die erstellten Instanzen angewendet.
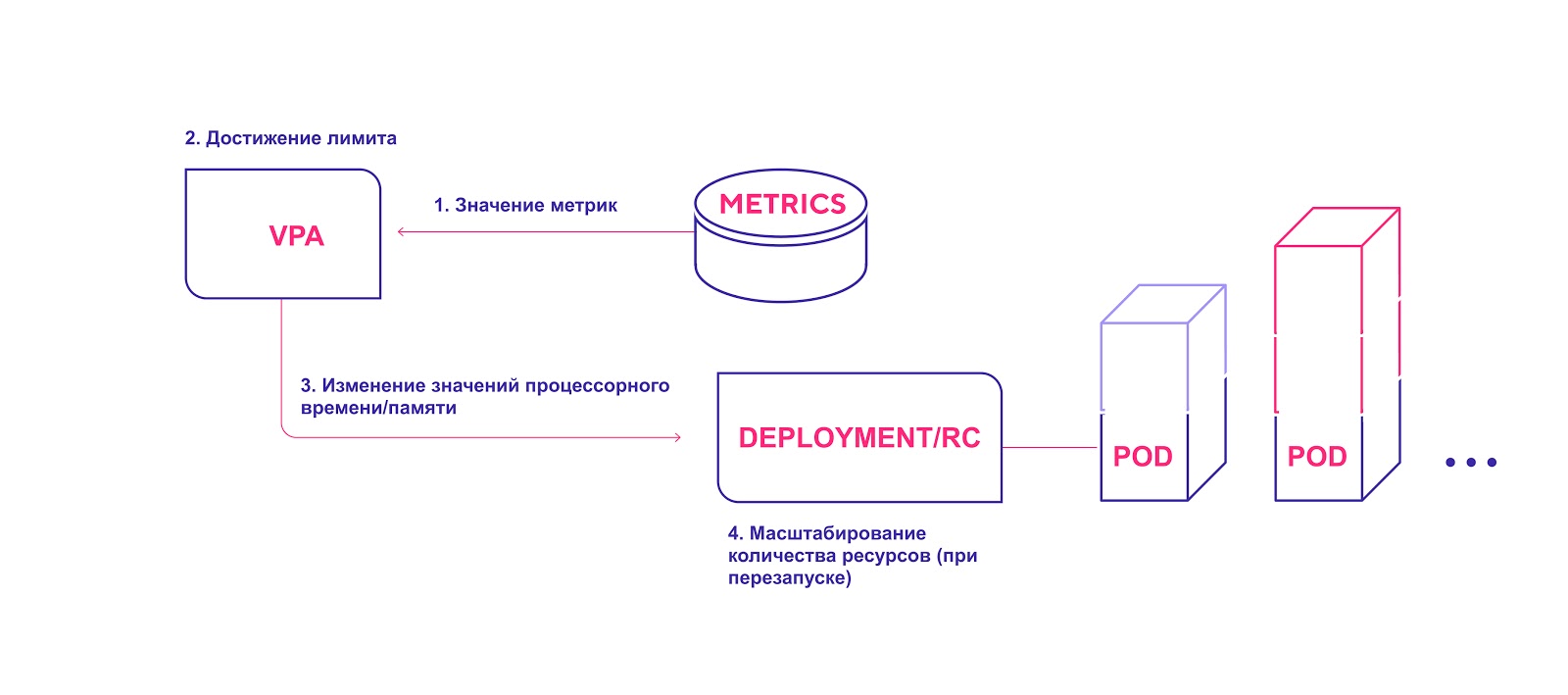 VPA fügt die erforderliche Menge an Ressourcen hinzu
VPA fügt die erforderliche Menge an Ressourcen hinzuBeachten Sie bei der Verwendung von VPA die folgenden Punkte:
- Das Skalieren erfordert einen obligatorischen Neustart des Pods. Dies ist erforderlich, um einen instabilen Betrieb nach Änderungen zu vermeiden. Aus Gründen der Zuverlässigkeit werden die Module basierend auf den neu zugewiesenen Ressourcen neu gestartet und auf die Knoten verteilt.
- VPA und HPA sind noch nicht miteinander kompatibel und können nicht mit denselben Pods arbeiten. Wenn Sie beide Skalierungsmechanismen in demselben Cluster verwenden, stellen Sie sicher, dass die Einstellungen nicht zulassen, dass sie für dieselben Objekte aktiviert werden.
- VPA konfiguriert Containeranforderungen für Ressourcen nur basierend auf der vorherigen und aktuellen Verwendung. Der Einsatz von Ressourcen ist nicht begrenzt. Es kann Probleme mit dem fehlerhaften Betrieb von Anwendungen geben, die immer mehr Ressourcen belegen. Dies führt dazu, dass Kubernetes diesen Pod ausschaltet.
- VPA befindet sich noch in einem frühen Entwicklungsstadium. Seien Sie darauf vorbereitet, dass das System in naher Zukunft einige Änderungen erfahren kann. Sie können die bekannten Einschränkungen und Entwicklungspläne nachlesen. Also, in den Plänen, die gemeinsame Arbeit von VPA und HPA sowie die Bereitstellung von Modulen zusammen mit einer vertikalen Auto-Scaling-Richtlinie für sie zu implementieren (zum Beispiel, ein spezielles Label "erfordert VPA").
Automatische Skalierung des Kubernetes-Clusters
Cluster Autoscaler (CA) ändert die Anzahl der Knoten basierend auf der Anzahl der wartenden Pods. Das System sucht regelmäßig nach ausstehenden Modulen und erhöht die Clustergröße, wenn mehr Ressourcen erforderlich sind und der Cluster die festgelegten Grenzwerte nicht überschreitet. Die Zertifizierungsstelle interagiert mit dem Cloud-Dienstanbieter, fordert zusätzliche Knoten von ihm an oder gibt die inaktiven frei. Die erste öffentlich verfügbare Version von CA wurde in Kubernetes 1.8 eingeführt.
Übergeordnetes Betriebsschema CA:
- Die Zertifizierungsstelle prüft im Standby-Modus mit einem Standardintervall von 10 Sekunden, ob Module vorhanden sind.
- Befinden sich ein oder mehrere Module aufgrund unzureichender Ressourcen im Cluster für ihre Verteilung im Standby-Zustand, wird versucht, einen oder mehrere zusätzliche Knoten vorzubereiten.
- Wenn der Cloud-Dienstanbieter den erforderlichen Knoten zuweist, tritt er dem Cluster bei und kann die Pod-Module bedienen.
- Kubernetes Scheduler verteilt ausstehende Module an einen neuen Host. Wenn danach einige Module noch im Standby-Zustand bleiben, wird der Vorgang wiederholt und dem Cluster werden neue Knoten hinzugefügt.
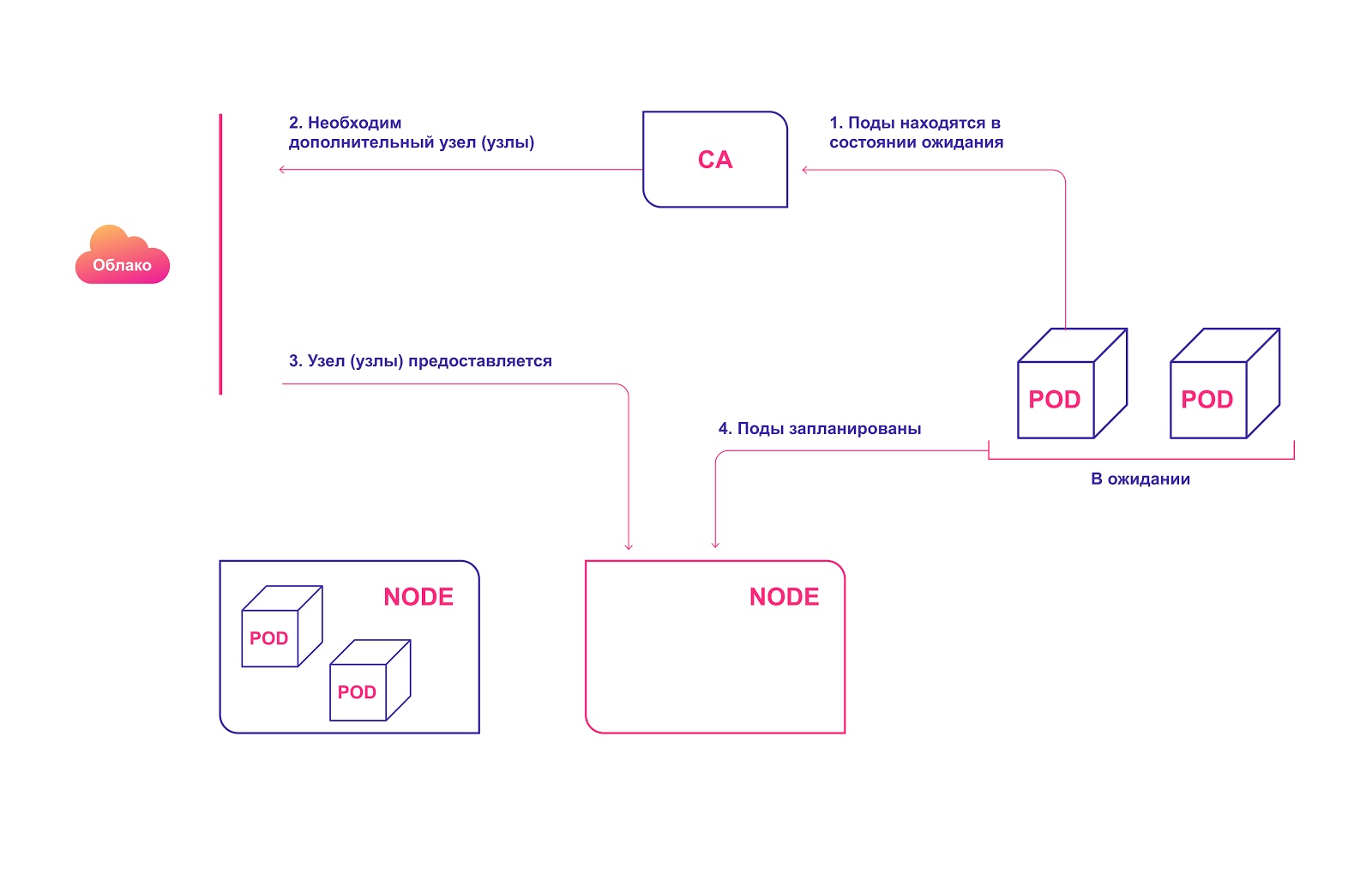 Automatische Zuordnung von Clusterknoten in der Cloud
Automatische Zuordnung von Clusterknoten in der CloudBeachten Sie bei der Verwendung von CA Folgendes:
- CA stellt sicher, dass alle Module im Cluster unabhängig von der Prozessorauslastung ausgeführt werden können. Außerdem versucht er sicherzustellen, dass sich keine unnötigen Knoten im Cluster befinden.
- Die CA registriert den Skalierungsbedarf nach ca. 30 Sekunden.
- Nachdem der Knoten nicht mehr benötigt wird, wartet die Zertifizierungsstelle standardmäßig 10 Minuten, bevor das System skaliert wird.
- Im Autoscale-System gibt es das Konzept der Expander. Dies sind verschiedene Strategien zum Auswählen einer Gruppe von Knoten, zu denen neue hinzugefügt werden.
- Verwenden Sie verantwortungsbewusst die Option cluster-autoscaler.kubernetes.io/safe-to-evict (true) . Wenn Sie viele Pods installieren oder wenn viele auf alle Knoten verteilt sind, können Sie den Cluster nicht mehr verkleinern.
- Verwenden Sie PodDisruptionBudgets , um das Entfernen von Pods zu verhindern, da ein Teil Ihrer Anwendung möglicherweise vollständig fehlschlägt.
Wie Kubernetes Autoscale-Systeme interagieren
Für eine perfekte Harmonie sollte die automatische Skalierung sowohl auf Pod-Ebene (HPA / VPA) als auch auf Cluster-Ebene angewendet werden. Sie interagieren relativ einfach miteinander:
- HPA oder VPA aktualisiert Pod-Replikate oder Ressourcen, die vorhandenen Pods zugewiesen sind.
- Wenn nicht genügend Knoten für die geplante Skalierung vorhanden sind, stellt CA das Vorhandensein von Pods im Ruhezustand fest.
- CA weist neue Knoten zu.
- Module werden auf neue Knoten verteilt.
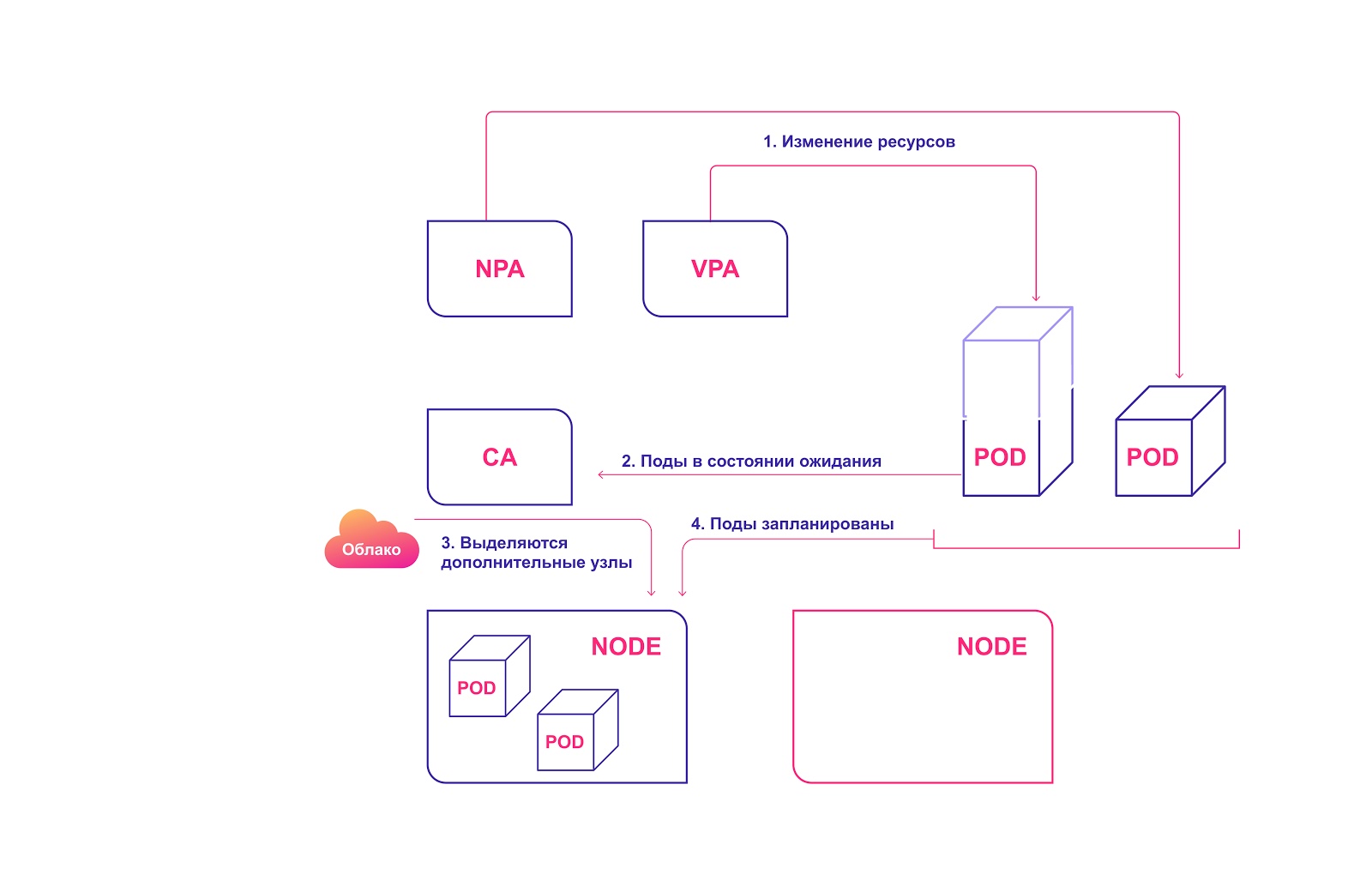 Kubernetes kollaboratives Skalierungssystem
Kubernetes kollaboratives SkalierungssystemHäufige Fehler bei der automatischen Skalierung von Kubernetes
Es gibt einige typische Probleme, auf die Entwickler stoßen, wenn sie versuchen, die automatische Skalierung anzuwenden.
HPA und VPA sind abhängig von Metriken und einigen historischen Daten. Wenn nicht genügend Ressourcen zugewiesen werden, werden die Module reduziert und können keine Metriken generieren. In diesem Fall findet keine automatische Skalierung statt.
Der Skalierungsvorgang selbst ist zeitkritisch. Wir möchten, dass Module und Cluster schnell skaliert werden können, bevor Benutzer Probleme oder Ausfälle bemerken. Daher sollte die durchschnittliche Skalierungszeit der Pods und des Clusters berücksichtigt werden.
Ideales Szenario - 4 Minuten:
- 30 Sekunden Aktualisierung der Zielmetriken: 30-60 Sekunden.
- 30 Sekunden HPA prüft metrische Werte: 30 Sekunden.
- Weniger als 2 Sekunden Die Pod-Module werden erstellt und in den Standby-Zustand versetzt: 1 Sekunde.
- Weniger als 2 Sekunden CA erkennt anstehende Module und sendet Anrufe, um Knoten vorzubereiten: 1 Sekunde.
- 3 Minuten Der Cloud-Anbieter weist Knoten zu. K8s wartet, bis sie bereit sind: bis zu 10 Minuten (abhängig von mehreren Faktoren).
Schlimmstes (realistischeres) Szenario - 12 Minuten:
- 30 Sekunden Aktualisierung der Zielmetriken
- 30 Sekunden HPA validiert metrische Werte.
- Weniger als 2 Sekunden Die Pod-Module werden erstellt und in den Standby-Zustand versetzt.
- Weniger als 2 Sekunden CA erkennt anstehende Module und sendet Anrufe, um Knoten vorzubereiten.
- 10 Minuten. Der Cloud-Anbieter weist Knoten zu. K8s wartet bis sie fertig sind. Die Wartezeit hängt von mehreren Faktoren ab, wie der Verzögerung des Lieferanten, der Verzögerung des Betriebssystems, der Arbeit der Hilfswerkzeuge.
Verwechseln Sie die Skalierungsmechanismen von Cloud-Anbietern nicht mit unserer Zertifizierungsstelle. Letzteres funktioniert innerhalb des Kubernetes-Clusters, während der Cloud-Provider-Mechanismus auf der Basis der Knotenzuweisung arbeitet. Er weiß nicht, was mit Ihren Pods oder Ihrer Anwendung passiert. Diese Systeme arbeiten parallel.
So verwalten Sie die Skalierung in Kubernetes
- Kubernetes ist ein Tool für Ressourcenverwaltung und Orchestrierung. Cluster-Pod- und Ressourcenverwaltungsvorgänge sind ein wichtiger Meilenstein bei der Entwicklung von Kubernetes.
- Erfahren Sie mehr über die Pod-Skalierbarkeitslogik für HPA und VPA.
- CA sollte nur verwendet werden, wenn Sie die Anforderungen Ihrer Schalen und Behälter genau kennen.
- Für eine optimale Cluster-Konfiguration müssen Sie verstehen, wie die verschiedenen Skalierungssysteme zusammenarbeiten.
- Berücksichtigen Sie bei der Bewertung der Skalierungszeiten die schlechtesten und besten Szenarien.