
In diesem Artikel möchte ich über mein Hobbyprojekt der Suche und Klassifizierung von Anzeigen für die Anmietung von Wohnungen aus dem sozialen Netzwerk VKontakte und die Erfahrung der Umstellung auf k8s sprechen.
Inhaltsverzeichnis
- Ein bisschen über das Projekt
- K8s stellt sich vor
- Vorbereitung für den Umzug
- K8s Konfigurationsentwicklung
- K8s Cluster-Bereitstellung
Ein bisschen über das Projekt
Im März 2017 startete ich einen Dienst zum Parsen und Klassifizieren von Anzeigen zur Vermietung von Wohnungen aus dem sozialen Netzwerk VKontakte.
Hier erfahren Sie ausführlicher, wie ich versucht habe, Anzeigen auf unterschiedliche Weise zu klassifizieren und mich schließlich für den lexikalischen Parser Yandex Tomita Parser entschieden habe.
Hier können Sie über die Architektur des Projekts zu Beginn seines Bestehens lesen und erfahren, welche Technologien und warum verwendet wurden.
Die Entwicklung der ersten Version des Dienstes dauerte etwa ein Jahr. Um jede Komponente des Dienstes bereitzustellen , habe ich Skripte in Ansible geschrieben . Von Zeit zu Zeit funktionierte der Service aufgrund von Fehlern im neu gestalteten Code oder falscher Konfiguration von Komponenten nicht.
Ungefähr im Juni 2019 wurde ein Fehler im Parser-Code festgestellt, aufgrund dessen keine neuen Ankündigungen gesammelt wurden. Anstelle einer weiteren Korrektur wurde beschlossen, diese vorübergehend zu deaktivieren.
Der Grund für die Wiederherstellung des Dienstes war das Studium der K8.
K8s stellt sich vor
k8s ist eine Open-Source-Software zur Automatisierung der Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen.
Die gesamte Service-Infrastruktur wird durch Konfigurationsdateien im yaml-Format (meistens) beschrieben.
Ich werde nicht über die interne Struktur von K8s sprechen, sondern nur einige Informationen über einige seiner Komponenten geben.
K8s Komponenten
- Pod ist die kleinste Einheit. Es kann mehrere Container enthalten, die auf demselben Knoten gestartet werden.
Behälter im Pod:
- ein gemeinsames Netzwerk haben und über 127.0.0.1:$containerPort aufeinander zugreifen können;
- Da es kein gemeinsames Dateisystem gibt, können Sie keine Dateien direkt von einem Container in einen anderen schreiben.
- Bereitstellung - Überwacht die Arbeit von Pod. Es kann die erforderliche Anzahl von Pod-Instanzen erhöhen, sie bei einem Ausfall neu starten und neue Pods bereitstellen.
- PersistentVolumeClaim - Data Warehouse. Standardmäßig funktioniert es mit dem lokalen Knotendateisystem. Wenn Sie also möchten, dass zwei verschiedene Pods auf verschiedenen Knoten ein gemeinsames Dateisystem haben, müssen Sie ein Netzwerkdateisystem wie Ceph verwenden .
- Service - Proxy-Anforderungen an und von Pod.
Servicetypen:
- LoadBalancer - für die Interaktion mit einem externen Netzwerk mit Lastausgleich zwischen mehreren Pods;
- NodePort (nur 30000-32767 Ports) - für die Interaktion mit einem externen Netzwerk ohne Lastausgleich;
- ClusterIp - für die Interaktion im lokalen Netzwerk des Clusters;
- ExternalName - für die Interaktion zwischen Pod und externen Diensten.
- ConfigMap - Speicherung von Configs.
Damit k8s den Pod mit neuen Konfigurationen neu starten kann, wenn sich ConfigMap ändert, sollten Sie die Version im Namen Ihrer ConfigMap angeben und bei jeder Änderung von ConfigMap ändern.
Gleiches gilt für Secret.
Konfigurationsbeispiel mit ConfigMapcontainers: - name: collect-consumer image: mrsuh/rent-collector:1.3.1 envFrom: - configMapRef: name: collector-configmap-1.1.0 - secretRef: name: collector-secrets-1.0.0
- Secret - Speicherung geheimer Konfigurationen (Passwörter, Schlüssel, Token).
- Label-Schlüssel-Wert-Paare, die k8s-Komponenten zugewiesen sind, z. B. Pod.
Zu Beginn der Bekanntschaft mit k8s ist die Verwendung von Labels möglicherweise nicht vollständig geklärt. Hier ist die Konfiguration, die die Grundprinzipien der Arbeit mit Labels erklärt:
Beispielkonfiguration mit Labels apiVersion: apps/v1 kind: Deployment # Deployment metadata: name: deployment-name # Deployment labels: app: deployment-label-app # Label Deployment spec: selector: matchLabels: app: pod-label-app # Label, Deployment Pods template: metadata: name: pod-name labels: app: pod-label-app # Label Pod spec: containers: - name: container-name image: mrsuh/rent-parser:1.0.0 ports: - containerPort: 9080 --- apiVersion: v1 kind: Service # Service metadata: name: service-name # Service labels: app: service-label-app # Label Service spec: selector: # Service matchLabels, Deployment, Labels app: pod-label-app # Label, Service , Pod ports: - protocol: TCP port: 9080 type: NodePort
Vorbereitung für den Umzug
Funktionsbeschnitt
Um den Service stabiler und vorhersehbarer zu machen, musste ich alle zusätzlichen Komponenten entfernen, die schlecht funktionierten, und die Hauptkomponenten ein wenig umschreiben.
Also habe ich mich entschieden abzulehnen:
- Parsing-Code für andere Sites als VK;
- Proxy-Komponente anfordern;
- Bestandteil von Benachrichtigungen über neue Ankündigungen in VKontakte und Telegramm.
Service-Komponenten
Nach all den Änderungen sah der Service von innen so aus:
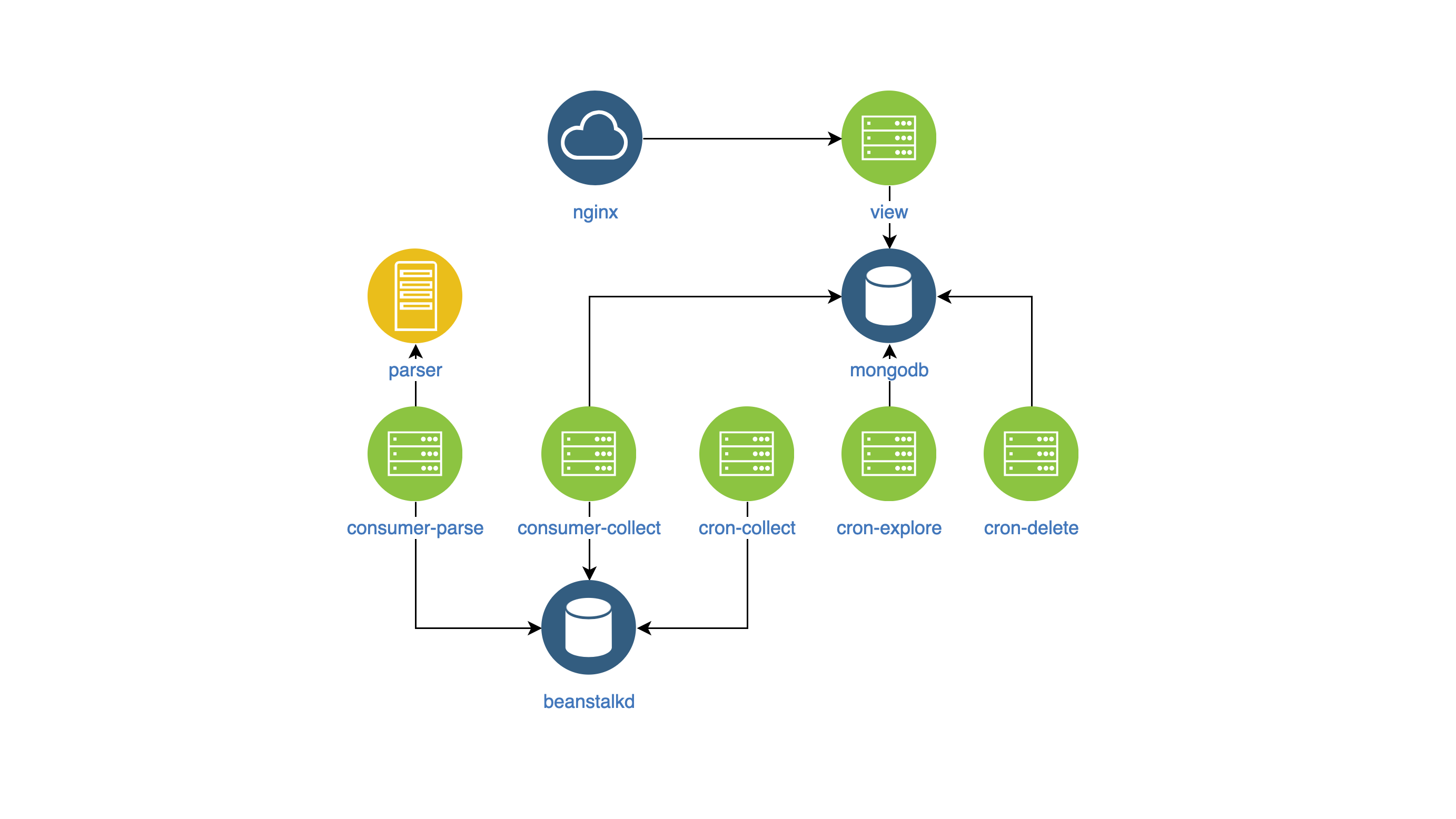
- Ansicht - Suche und Anzeige von Anzeigen auf der Website (NodeJS);
- Parser - Anzeigenklassifizierer (Go);
- Collector - Sammeln, Verarbeiten und Löschen von Anzeigen (PHP):
- cron-explore - ein Konsolenteam, das Gruppen auf VKontakte sucht, um Wohnungen zu vermieten;
- cron-collect - ein Konsolenbefehl, der an von cron-explore zusammengestellte Gruppen geht und die Anzeigen selbst sammelt;
- cron-delete - ein Konsolenbefehl, der abgelaufene Ansagen löscht;
- consumer-parse - der Queue-Handler, der Aufträge von cron-collect erhält. Anzeigen werden mithilfe der Parser-Komponente klassifiziert.
- consumer-collect - der Warteschlangen-Handler, der Jobs von consumer-parse erhält. Es filtert fehlerhafte und doppelte Anzeigen heraus.
Erstellen Sie Docker-Images
Um die Komponenten zu verwalten und sie in einem einzigen Stil zu überwachen, habe ich beschlossen:
- Komponentenkonfiguration in Umgebungsvariablen einfügen,
- Schreibe Logs in stdout.
In den Bildern selbst gibt es nichts Bestimmtes.
K8s Konfigurationsentwicklung
Also habe ich die Komponenten in die Docker-Images aufgenommen und mit der Entwicklung der k8s-Konfiguration begonnen.
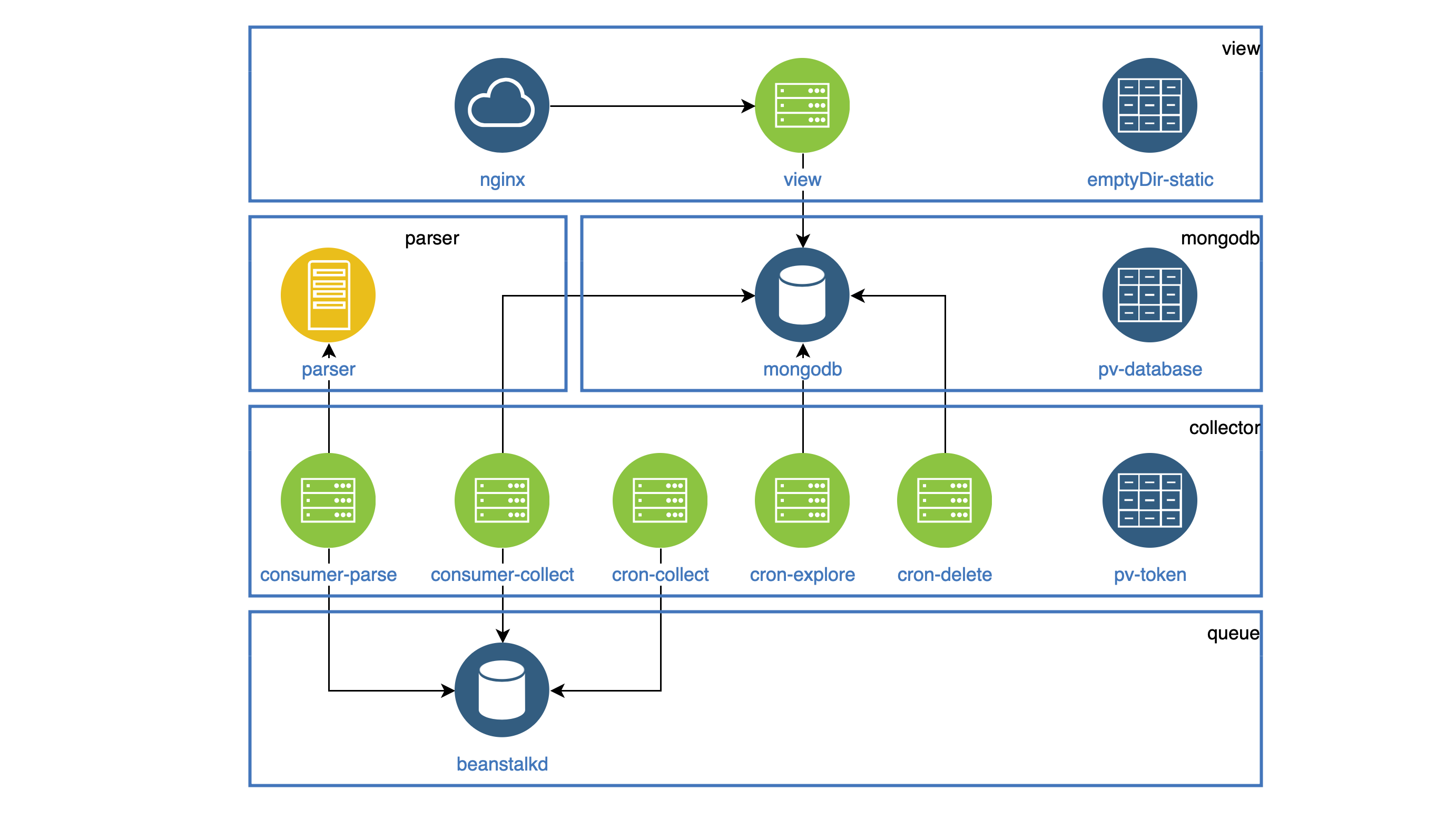
Alle Komponenten, die als Dämonen arbeiten, werden in der Bereitstellung hervorgehoben. Jeder Daemon muss innerhalb des Clusters erreichbar sein, damit jeder einen Service hat. Alle Aufgaben, die regelmäßig ausgeführt werden müssen, werden in CronJob ausgeführt.
Alle statischen Daten (Bilder, Js, CSS) werden im Ansichtscontainer gespeichert, und der Nginx-Container sollte sie verteilen. Beide Behälter befinden sich in einem Pod. Das Dateisystem im Pod wird nicht verfälscht, aber Sie können beim Starten des Pod alle statischen Daten in den Ordner emptyDir kopieren, der beiden Containern gemeinsam ist. Dieser Ordner wird für verschiedene Container freigegeben, jedoch nur innerhalb eines Pods.
Beispielkonfiguration mit emptyDir apiVersion: apps/v1 kind: Deployment metadata: name: view spec: selector: matchLabels: app: view replicas: 1 template: metadata: labels: app: view spec: volumes: - name: view-static emptyDir: {} containers: - name: nginx image: mrsuh/rent-nginx:1.0.0 - name: view image: mrsuh/rent-view:1.1.0 volumeMounts: - name: view-static mountPath: /var/www/html lifecycle: postStart: exec: command: ["/bin/sh", "-c", "cp -r /app/web/. /var/www/html"]
Die Kollektorkomponente wird in Deployment und CronJob verwendet.
Alle diese Komponenten greifen auf die VKontakte-API zu und müssen das gemeinsam genutzte Zugriffstoken irgendwo speichern.
Dazu habe ich PersistentVolumeClaim verwendet, das ich mit jedem Pod verbunden habe. Ein solcher Ordner wird für verschiedene Pods freigegeben, jedoch nur innerhalb eines Knotens.
Konfigurationsbeispiel mit PersistentVolumeClaim apiVersion: apps/v1 kind: Deployment metadata: name: collector spec: selector: matchLabels: app: collector replicas: 1 template: metadata: labels: app: collector spec: volumes: - name: collector-persistent-storage persistentVolumeClaim: claimName: collector-pv-claim containers: - name: collect-consumer image: mrsuh/rent-collector:1.3.1 volumeMounts: - name: collector-persistent-storage mountPath: /tokenStorage command: ["php"] args: ["bin/console", "app:consume", "--channel=collect"] - name: parse-consumer image: mrsuh/rent-collector:1.3.1 volumeMounts: - name: collector-persistent-storage mountPath: /tokenStorage command: ["php"] args: ["bin/console", "app:consume", "--channel=parse"]
PersistentVolumeClaim wird auch zum Speichern von Datenbankdaten verwendet. Als Ergebnis haben wir ein solches Schema erhalten (Pods einer Komponente werden in Blöcken gesammelt):
K8s Cluster-Bereitstellung
Zu Beginn habe ich den Cluster lokal mit Minikube bereitgestellt .
Natürlich gab es einige Fehler, deshalb haben mir die Teams sehr geholfen.
kubectl logs -f pod-name kubectl describe pod pod-name
Nachdem ich gelernt hatte, wie ein Cluster in Minikube bereitgestellt wird, war es für mich nicht schwierig, ihn in DigitalOcean bereitzustellen.
Abschließend kann ich sagen, dass der Service seit 2 Monaten stabil ist. Die vollständige Konfiguration finden Sie hier .