In diesem Artikel wird das Projekt nginx-log-collector erläutert, in dem nginx-Protokolle gelesen und an den Clickhouse-Cluster gesendet werden. Normalerweise verwenden Sie für Protokolle ElasticSearch. Clickhouse benötigt weniger Ressourcen (Festplattenspeicher, RAM, CPU). Clickhouse zeichnet Daten schneller auf. Clickhouse komprimiert Daten und macht die Datenträgerdaten noch kompakter. Die Vorteile von ClickHouse sind auf zwei Folien aus dem Bericht ersichtlich: So fügt VK Daten in Zehntausende von Servern in ClickHouse ein.


Erstellen Sie ein Dashboard für Grafana, um die Protokollanalysen anzuzeigen.
Wen kümmert es, willkommen bei cat.
Installieren Sie nginx, grafana wie gewohnt.
Installieren Sie den Clickhouse-Cluster mit ansible-playbook von Denis Proskurin .
Erstellen von Datenbanken und Tabellen in Clickhouse
Diese Datei beschreibt SQL-Abfragen zum Erstellen einer Datenbank und von Tabellen für nginx-log-collector in Clickhouse.
Wir stellen jede Anfrage der Reihe nach auf jedem Server des Clickhouse-Clusters.
Wichtiger Hinweis. In dieser Zeile sollte logs_cluster durch Ihren Clusternamen aus der Datei clickhouse_remote_servers.xml zwischen "remote_servers" und "shard" ersetzt werden.
ENGINE = Distributed('logs_cluster', 'nginx', 'access_log_shard', rand())
Installation und Konfiguration von nginx-log-collector-rpm
Nginx-Log-Collector hat keine Drehzahl. Hier erstellen https://github.com/patsevanton/nginx-log-collector-rpm rpm dafür. RPM werden mit Fedora Copr erfasst
Installieren Sie das RPM-Paket nginx-log-collector-rpm
yum -y install yum-plugin-copr yum copr enable antonpatsev/nginx-log-collector-rpm yum -y install nginx-log-collector systemctl start nginx-log-collector
Bearbeiten Sie die Konfiguration /etc/nginx-log-collector/config.yaml:
....... upload: table: nginx.access_log dsn: http://ip---clickhouse:8123/ - tag: "nginx_error:" format: error # access | error buffer_size: 1048576 upload: table: nginx.error_log dsn: http://ip---clickhouse:8123/
Nginx-Setup
Allgemeine Nginx-Konfiguration:
user nginx; worker_processes auto;
Der virtuelle Host ist einer:
vhost1.conf:
upstream backend { server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; } server { listen 80; server_name vhost1; location / { proxy_pass http://backend; } }
Fügen Sie der Datei / etc / hosts virtuelle Hosts hinzu:
ip----nginx vhost1
HTTP Server Emulator
Als HTTP-Server-Emulator verwenden wir nodejs-stub-server von Maxim Ignatenko
Nodejs-Stub-Server hat keine U / min. Hier erstellen https://github.com/patsevanton/nodejs-stub-server rpm dafür. RPM werden mit Fedora Copr erfasst
Installieren Sie das nodejs-stub-server-Paket auf der Upstream-Nginx-RPM
yum -y install yum-plugin-copr yum copr enable antonpatsev/nodejs-stub-server yum -y install stub_http_server systemctl start stub_http_server
Belastungstest
Die Tests wurden mit dem Apache-Benchmark durchgeführt.
Installiere es:
yum install -y httpd-tools
Wir testen den Apache-Benchmark von 5 verschiedenen Servern aus:
while true; do ab -H "User-Agent: 1server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 2server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 3server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 4server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 5server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done
Grafana Setup
Auf der offiziellen Grafana-Website finden Sie kein Dashboard.
Deshalb werden wir es abgeben.
Mein gespeichertes Dashboard finden Sie hier .
Sie müssen auch eine Tabellenvariable mit dem Inhalt von nginx.access_log .
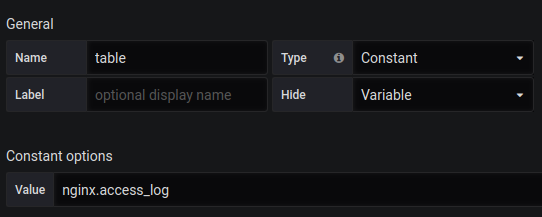
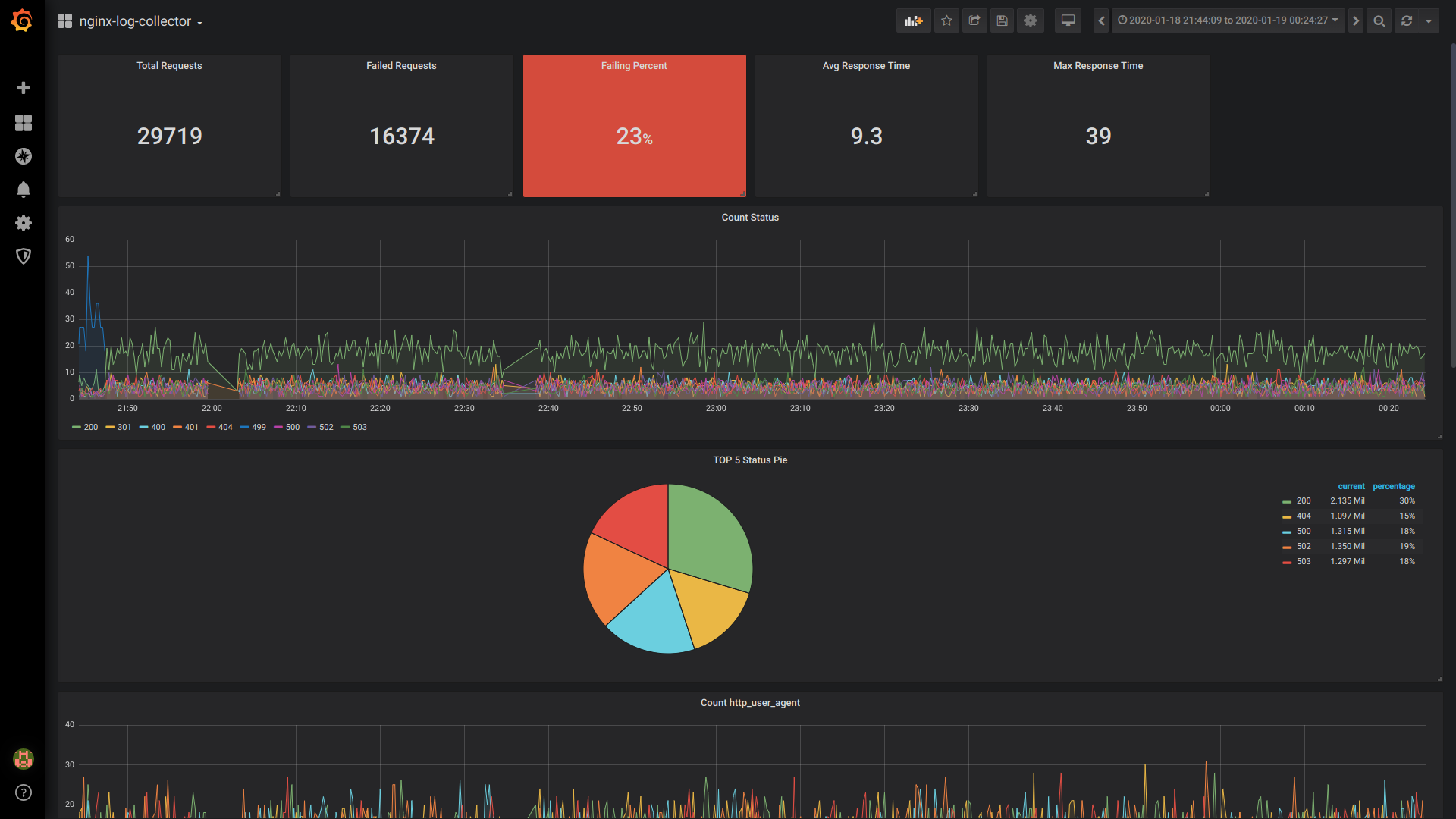
Singlestat Total Anfragen:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter GROUP BY t
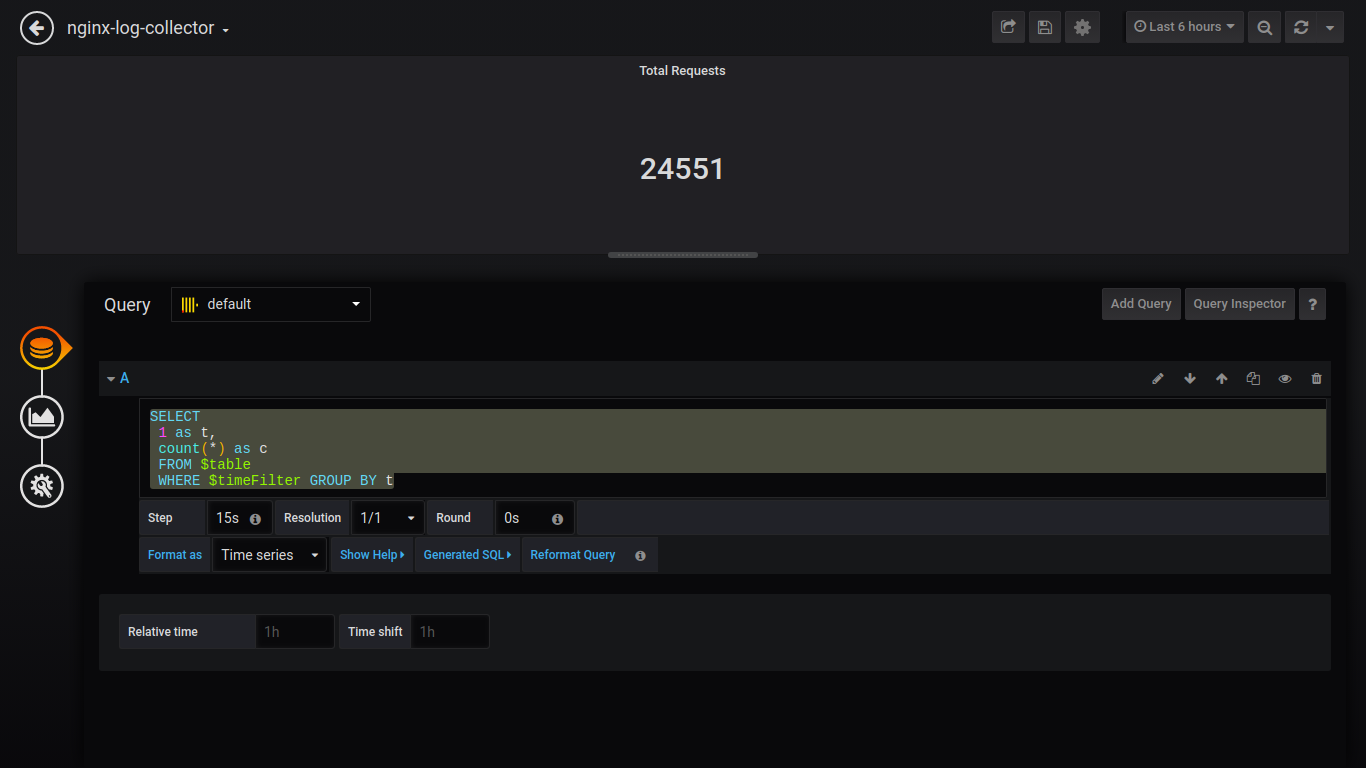
Einzelstatus fehlgeschlagene Anfragen:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter AND status NOT IN (200, 201, 401) GROUP BY t
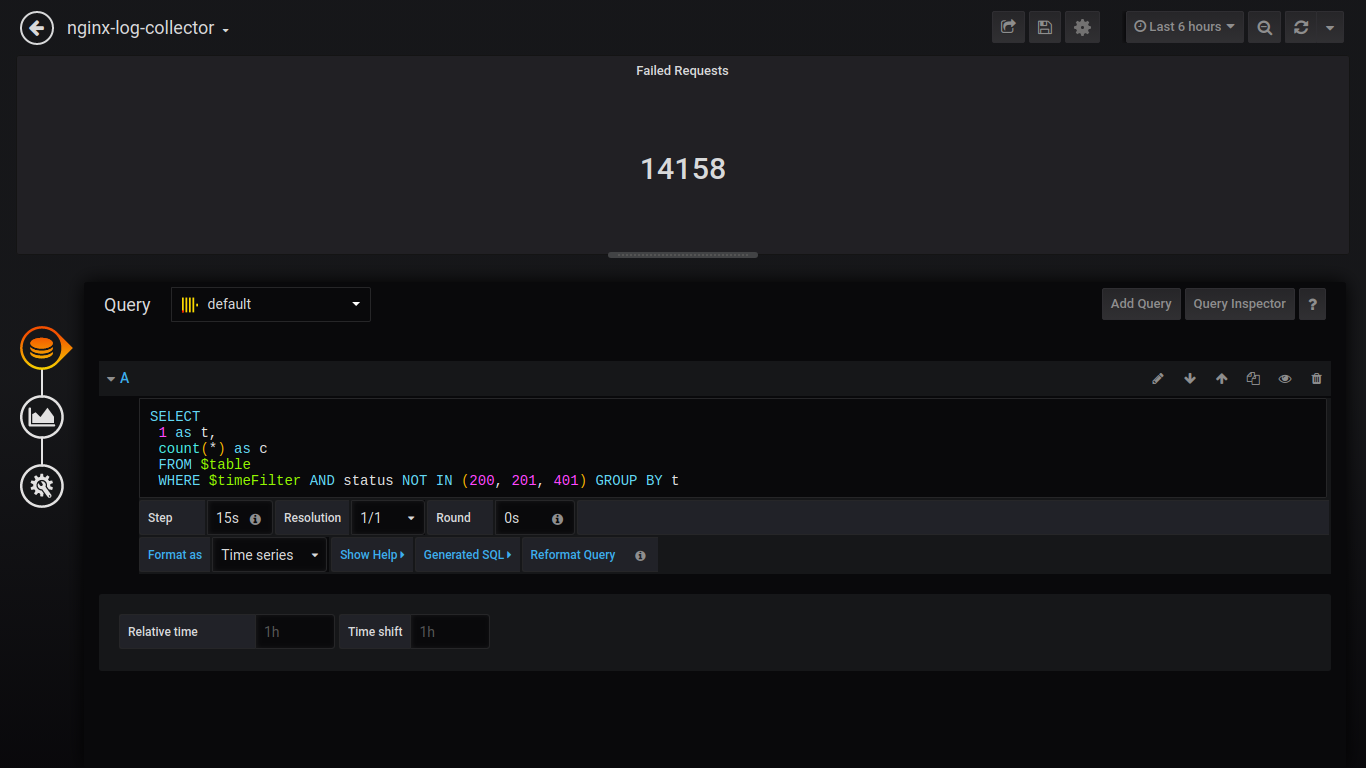
Prozent der fehlgeschlagenen Singlestat:
SELECT 1 as t, (sum(status = 500 or status = 499)/sum(status = 200 or status = 201 or status = 401))*100 FROM $table WHERE $timeFilter GROUP BY t
Singlestat Durchschn. Antwortzeit:
SELECT 1, avg(request_time) FROM $table WHERE $timeFilter GROUP BY 1
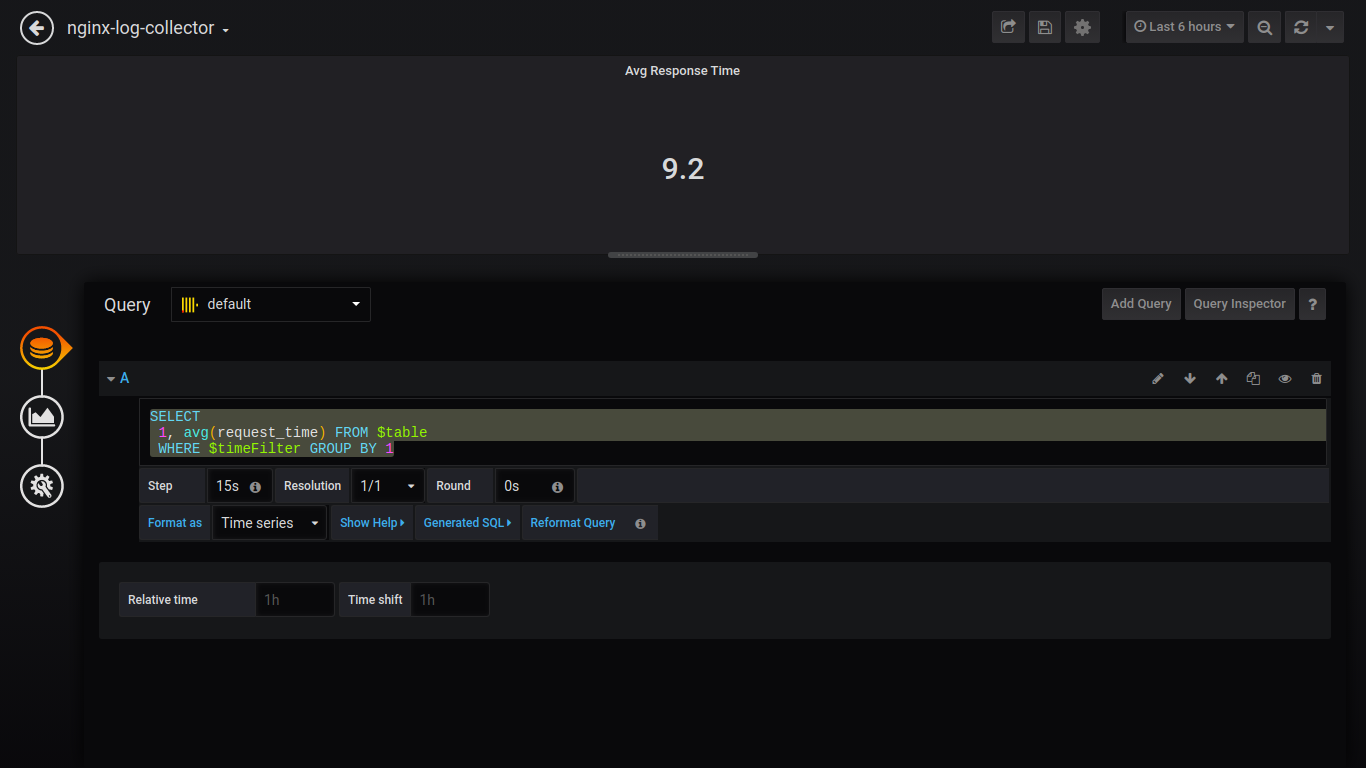
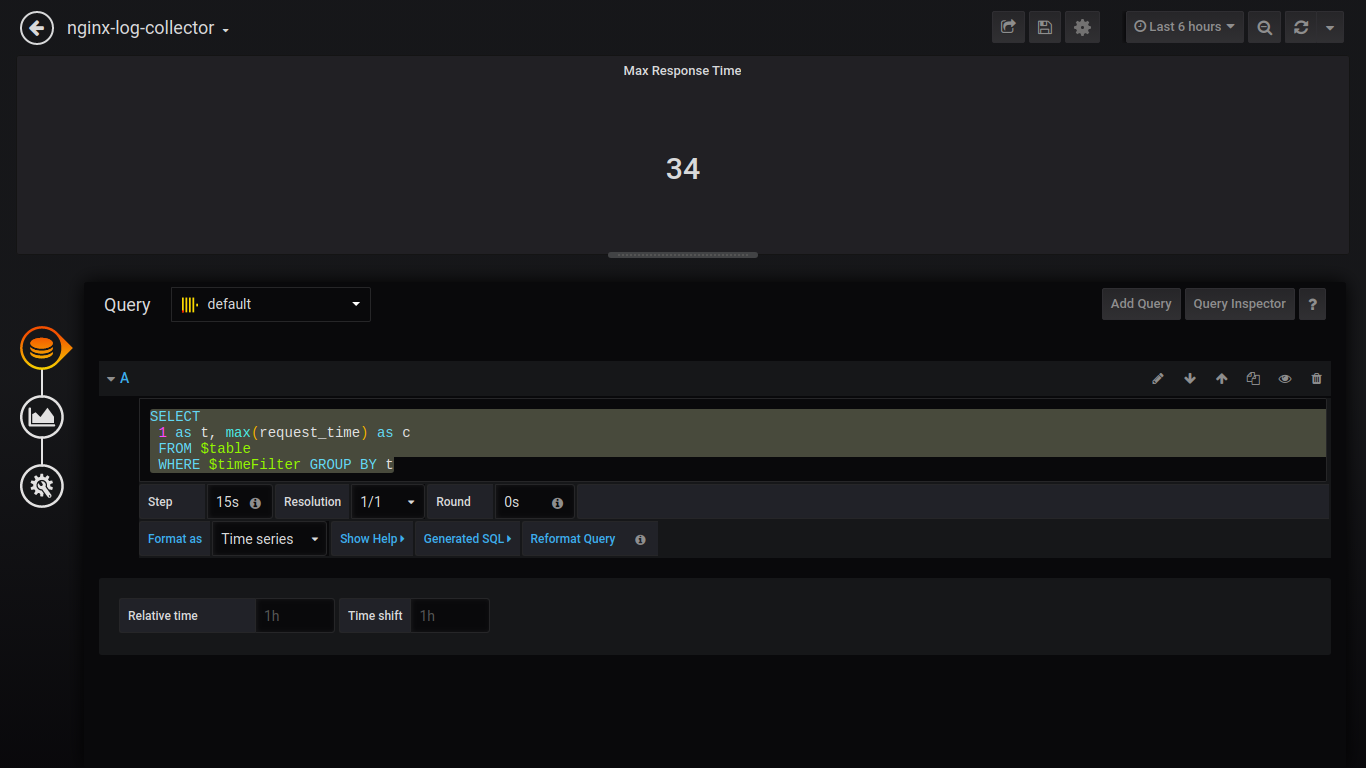
Singlestat Max Reaktionszeit:
SELECT 1 as t, max(request_time) as c FROM $table WHERE $timeFilter GROUP BY t
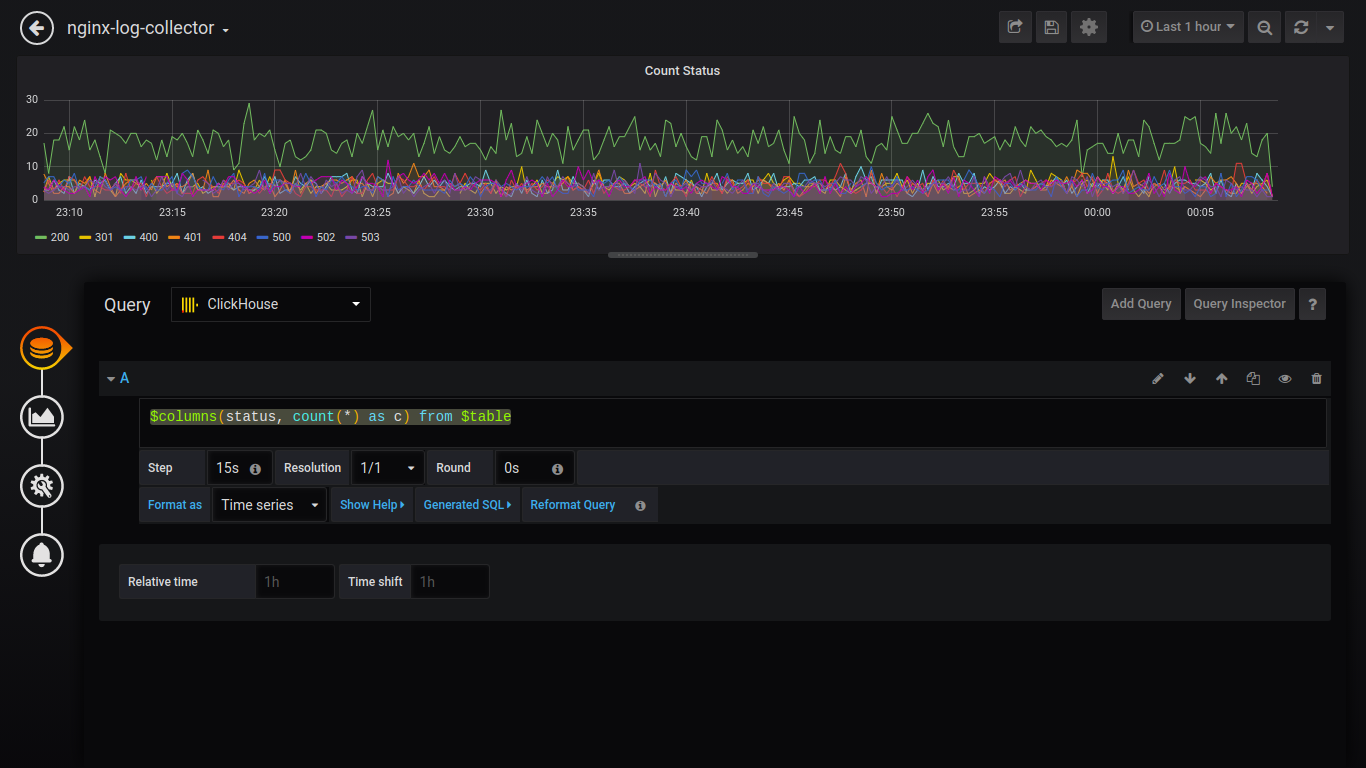
Zählstatus:
$columns(status, count(*) as c) from $table
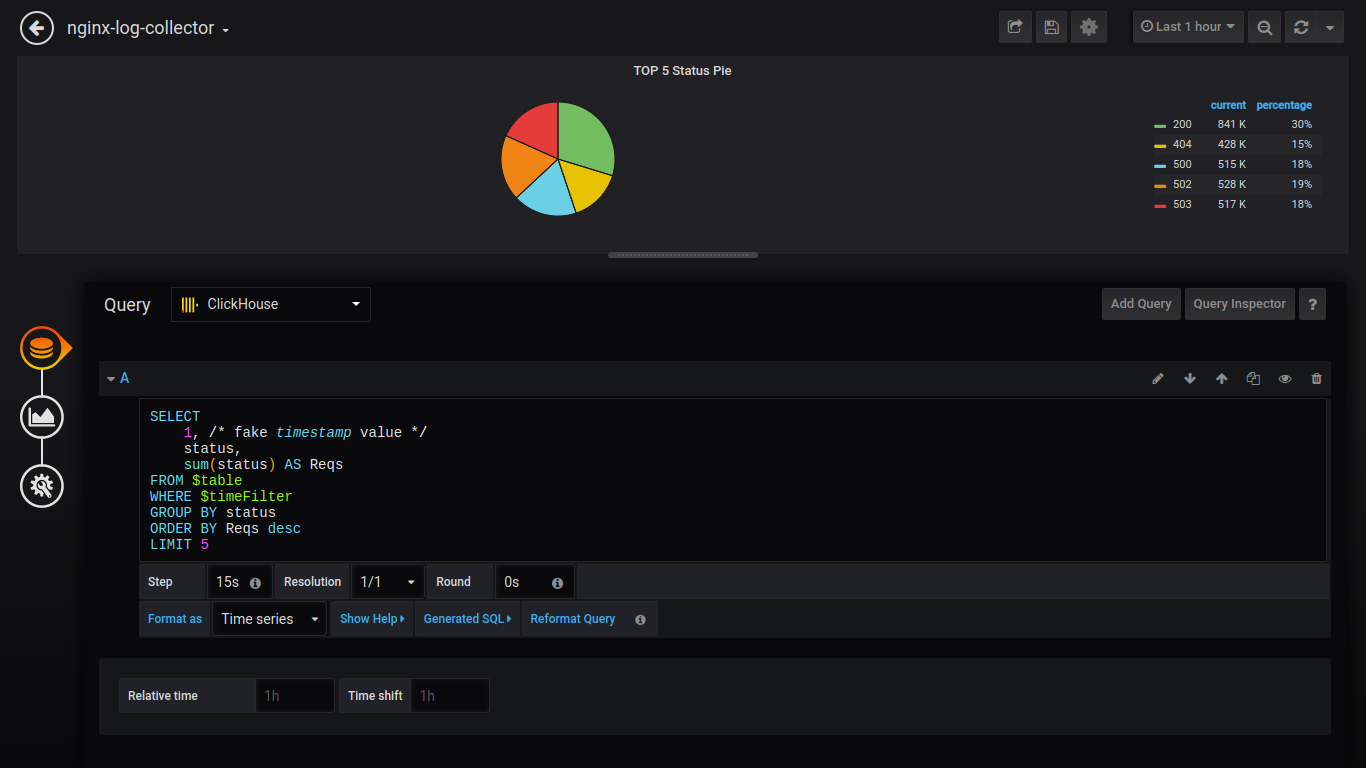
Um Daten als Torte auszugeben, müssen Sie das Plugin installieren und grafana neu starten.
grafana-cli plugins install grafana-piechart-panel service grafana-server restart
Torte TOP 5 Status:
SELECT 1, status, sum(status) AS Reqs FROM $table WHERE $timeFilter GROUP BY status ORDER BY Reqs desc LIMIT 5
Ich werde weiterhin Anfragen ohne Screenshots stellen:
Http_user_agent zählen:
$columns(http_user_agent, count(*) c) FROM $table
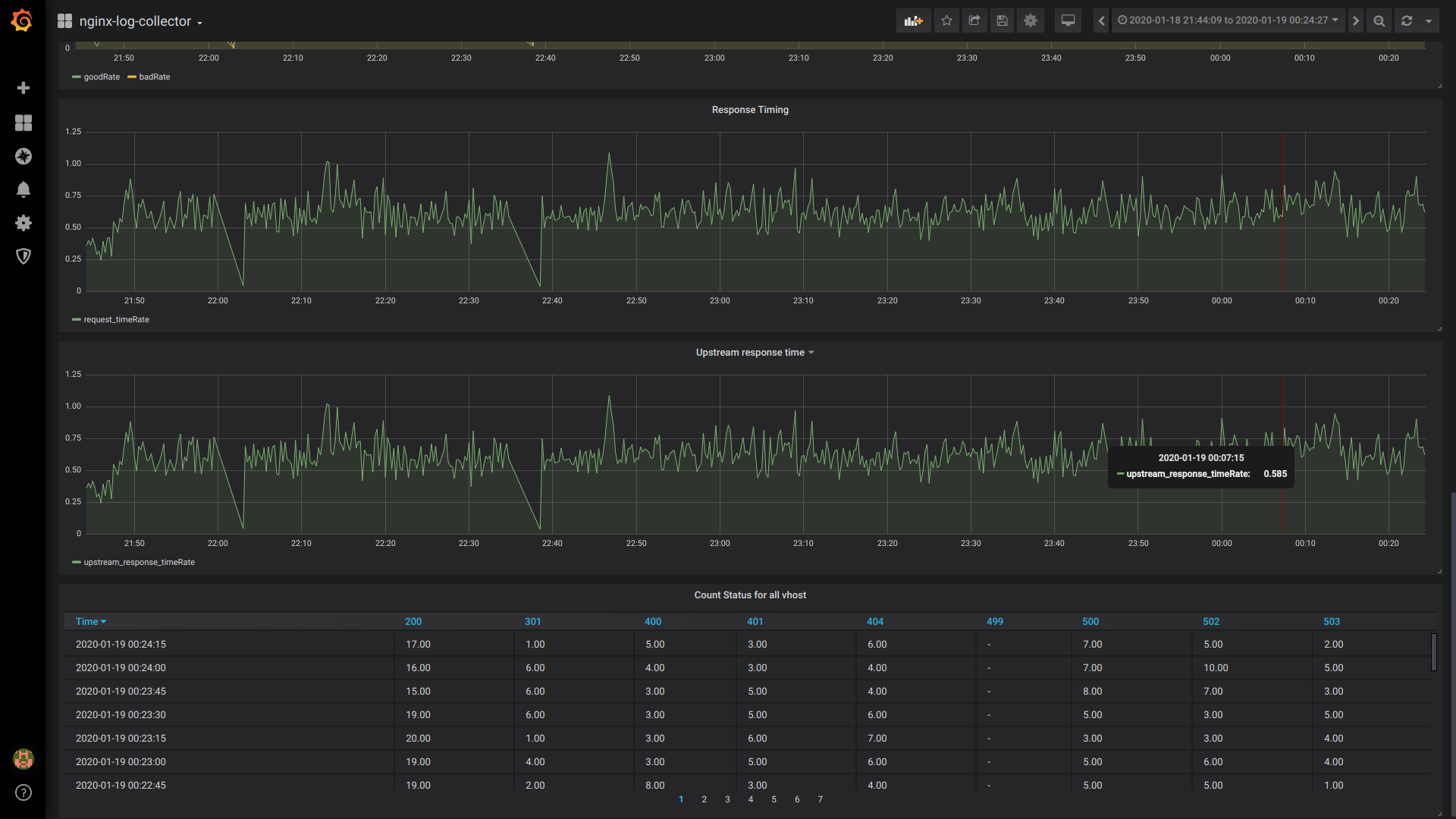
GoodRate / BadRate:
$rate(countIf(status = 200) AS good, countIf(status != 200) AS bad) FROM $table
Reaktionszeit:
$rate(avg(request_time) as request_time) FROM $table
Upstream-Reaktionszeit (Reaktionszeit des 1. Upstreams):
$rate(avg(arrayElement(upstream_response_time,1)) as upstream_response_time) FROM $table
Tabellenzählstatus für alle vhost:
$columns(status, count(*) as c) from $table
Gesamtansicht des Dashboards

Vergleich von avg () und quantile ()
avg ()

quantile ()

Fazit:
Hoffentlich beteiligt sich die Community an der Entwicklung / dem Testen und der Verwendung von nginx-log-collector.
Und jemand, der Nginx-Log-Collector implementiert, wird Ihnen sagen, wie viel er auf der Festplatte, im RAM und in der CPU gespart hat.
Telegrammkanäle:
Millisekunden:
Für wen Millisekunden wichtig sind, schreiben oder stimmen Sie bitte in dieser Ausgabe ab .