Wenn Sie
SQL-Abfragen schreiben,
ohne den zu implementierenden
Algorithmus zu analysieren , führt dies in der Regel nicht zu einer guten Leistung.
Solche Anfragen
möchten die Prozessorzeit „auffressen“ und aktiv Daten aus heiterem Himmel
lesen . Darüber hinaus handelt es sich nicht notwendigerweise um komplexe Abfragen. Je einfacher diese geschrieben sind, desto größer ist die Wahrscheinlichkeit, Probleme zu bekommen. Und wenn der JOIN-Operator ins Spiel kommt ...
Das Verknüpfen von Tabellen ist an sich weder schädlich noch nützlich - es ist nur ein Tool, aber Sie müssen in der Lage sein, es zu verwenden.
Übersichtsgruppierung
Nehmen Sie zunächst ein sehr einfaches Beispiel.
Es gibt ein "Wörterbuch" mit 100 Einträgen (zum Beispiel sind dies Regionen der Russischen Föderation):
CREATE TABLE tbl_dict AS SELECT generate_series(0, 100) k; ALTER TABLE tbl_dict ADD PRIMARY KEY(k);
... und anbei eine Tabelle mit verwandten „Fakten“ pro 100.000 Einträge:
CREATE TABLE tbl_fact AS SELECT (random() * 100)::integer k , (random() * 1000)::integer v FROM generate_series(1, 100000); CREATE INDEX ON tbl_fact(k);
Versuchen wir nun, die Summe der Werte für jede "Region" zu berechnen.
Wie man hört, steht es geschrieben
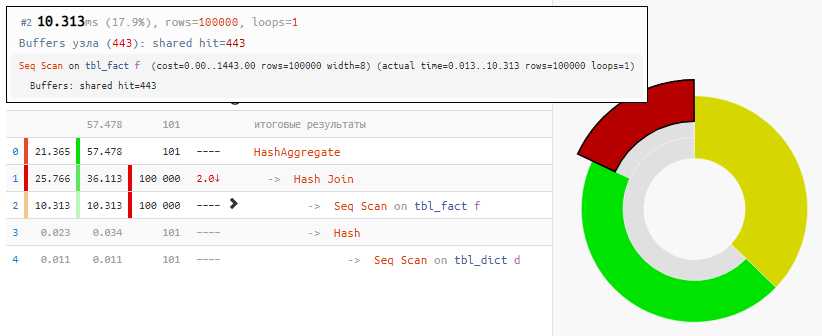
SELECT dk , sum(fv) FROM tbl_fact f NATURAL JOIN tbl_dict d GROUP BY 1;
Das Lesen der Daten selbst nahm nur 18% der Zeit in Anspruch, der Rest verarbeitete:
 [siehe EXPLAIN.TENSOR.RU]
[siehe EXPLAIN.TENSOR.RU]Und das alles, weil Hash Join und Hash Aggregate jeweils 100.000 Datensätze verarbeiten mussten, weil wir uns nach
dem Feld der verknüpften Tabelle gruppieren wollten .
Wir setzen Einfallsreichtum ein
Der Wert dieses Feldes entspricht jedoch dem Wert des Feldes in der aggregierten Tabelle! Das heißt, niemand stört uns,
die „Fakten“ zuerst zu gruppieren und erst dann eine Verbindung herzustellen :
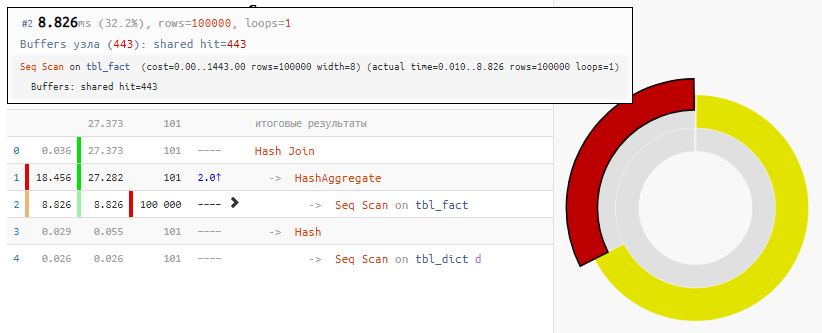
SELECT dk , f.sum FROM ( SELECT k , sum(v) FROM tbl_fact GROUP BY 1 ) f NATURAL JOIN tbl_dict d;
 [siehe EXPLAIN.TENSOR.RU]
[siehe EXPLAIN.TENSOR.RU]Natürlich ist die Methode nicht universell, aber für unseren Fall des "üblichen JOIN"
beträgt der Zeitgewinn bei minimaler Änderung der Anforderung das Zweifache - einfach aufgrund des "nullifizierten" Hash-Joins, der nur 100 Einträge anstelle von 100.000 Einträgen erhielt.
Ungleiche Bedingungen
Lassen Sie uns nun die Aufgabe verkomplizieren: Wir haben drei Tabellen, die durch einen Bezeichner verbunden sind - die Haupttabelle und zwei Hilfstabellen mit einigen Anwendungsdaten, nach denen wir filtern.
Eine kleine, aber sehr wichtige Bemerkung: Obwohl wir aufgrund der „angewandten“ Kenntnis der Zielaufgabe bereits wissen, dass die Bedingungen
auf der ersten Tabelle - fast immer (zur Sicherheit - 3: 4) und
auf der zweiten - sehr selten (1: 8) erfüllt sind )
Wir möchten aus der Haupt- und der ersten Hilfstabelle die
100 ersten Datensätze nach ID mit geraden Bezeichnerwerten auswählen, für die die
Bedingungen für alle Tabellen erfüllt sind . Alle Datensätze in den Tabellen, lassen Sie uns wieder bei 100K sein.
Skriptgenerator CREATE TABLE base( id integer PRIMARY KEY , val integer ); INSERT INTO base SELECT id , (random() * 1000)::integer FROM generate_series(1, 100000) id; CREATE TABLE ext1( id integer PRIMARY KEY , conda boolean ); INSERT INTO ext1 SELECT id , (random() * 4)::integer <> 0
Wie man hört, steht es geschrieben
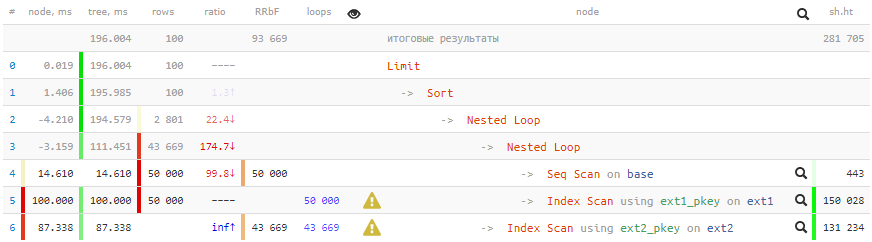
SELECT base.* , ext1.* FROM base NATURAL JOIN ext1 NATURAL JOIN ext2 WHERE id % 2 = 0 AND conda AND condb ORDER BY base.id LIMIT 100;
 [siehe EXPLAIN.TENSOR.RU]
[siehe EXPLAIN.TENSOR.RU]Negative Zeiten in Bezug aufEs sind so viele Zyklen durch einige Knoten gegangen, dass die Rundungsfehler einiger sogar in Minuspunkte getrieben wurden. Über ähnliche Artefakte in den Plänen werde ich auf
PGConf.Russia sprechen.
200 ms und mehr 2 GB gepumpte Daten - nicht sehr gut für 100 Datensätze!
Wir setzen Einfallsreichtum ein
Wir verwenden die folgenden Ansätze, um eine Beschleunigung zu erreichen:
- Zunächst verstehen wir, dass es für uns sinnvoll ist, alle Bedingungen für verknüpfte Tabellen nur dann zu überprüfen, wenn die Bedingungen für die Haupttabelle erfüllt sind (auch für id).
- Die Ausgabe sollte nach base.id sortiert sein, und dafür ist der Primärschlüssel dieser Tabelle perfekt für uns!
- Wir benötigen keine Daten von ext2 und werden nur zur Überprüfung des Zustands verwendet. Dies bedeutet, dass alle Arbeiten mit dieser Tabelle sicher aus dem JOIN in den WHERE-Teil entfernt werden können . Und verwenden Sie EXISTS zum Überprüfen, andernfalls, wenn es überhaupt keinen solchen Datensatz gibt?
- Wir müssen nur dann mindestens einige Daten von ext1 abrufen , wenn die verbleibenden Prüfungen von base und ext2 erfolgreich bestanden wurden . Das heißt, die Verbindung mit ext1 sollte nach allen Aktionen mit base / ext2 gehen, die mit LATERAL erreicht werden können.
- Damit der Abfrageplaner nicht versucht, die verschachtelte Überprüfung von ext2 in JOIN, die Unterabfrage "Unter FALL verstecken", umzuwandeln.
SELECT base.* , ext1.* FROM base , LATERAL(
 [siehe EXPLAIN.TENSOR.RU]
[siehe EXPLAIN.TENSOR.RU]Die Anfrage ist natürlich komplizierter geworden, aber
es lohnt sich
, dreizehn Mal in der Zeit und 350 Mal in "Völlerei" zu gewinnen!
Lassen Sie mich noch einmal daran erinnern, dass nicht alle Methoden angewendet werden und nicht immer, aber Wissen wird nicht überflüssig sein.Es wird auch interessant sein: