 Viele Programmierer halten Quick Sort für den schnellsten Algorithmus überhaupt. Dies ist zum Teil richtig. Aber es funktioniert nur dann wirklich gut, wenn das Unterstützungselement richtig ausgewählt ist ( dann ist die Komplexität O (n log n) ). Ansonsten ist das asymptotische Verhalten ungefähr dasselbe wie das der Blase ( d. H. O (n 2 ) ).
Viele Programmierer halten Quick Sort für den schnellsten Algorithmus überhaupt. Dies ist zum Teil richtig. Aber es funktioniert nur dann wirklich gut, wenn das Unterstützungselement richtig ausgewählt ist ( dann ist die Komplexität O (n log n) ). Ansonsten ist das asymptotische Verhalten ungefähr dasselbe wie das der Blase ( d. H. O (n 2 ) ).
Wenn das Array bereits sortiert ist, arbeitet der Algorithmus trotzdem nicht schneller als O (n log n).
Auf dieser Grundlage habe ich beschlossen, einen eigenen Algorithmus zum Sortieren eines Arrays zu schreiben, das besser als quick_sort funktioniert. Wenn das Array bereits sortiert ist, führen Sie es nicht mehrmals aus, wie dies bei vielen Algorithmen der Fall ist.
"Es war Abend, es gab nichts zu tun" - Sergei Mikhalkov.
Anforderungen:
- Bester Fall O (n)
- Der durchschnittliche Fall von O (n log n)
- Schlimmster Fall O (n log n)
- Durchschnittlich schneller als schnelles Sortieren
Um das Thema zu verstehen, müssen Sie wissen: Lassen Sie uns jetzt alles in Ordnung bringen
Damit unser Algorithmus immer schnell arbeitet, muss das asymptotische Verhalten im Durchschnitt mindestens O (n log n) und bestenfalls O (n) betragen. Wir alle wissen sehr gut, dass die Einfügesortierung bestenfalls auf einmal funktioniert. Aber im schlimmsten Fall muss sie so oft durch das Array fahren, wie Elemente darin enthalten sind.
Vorläufige Informationen
Die Funktion zum Zusammenführen von zwei Arraysint* glue(int* a, int lenA, int* b, int lenB) { int lenC = lenA + lenB; int* c = new int[lenC];
Durch das Zusammenführen von zwei Arrays wird das Ergebnis auf dem angegebenen Wert gespeichert. void glueDelete(int*& arr, int*& a, int lenA, int*& b, int lenB) { if (lenA == 0) {
Eine Funktion zum Sortieren nach Einfügungen zwischen lo und hi void insertionSort(int*& arr, int lo, int hi) { for (int i = lo + 1; i <= hi; ++i) for (int j = i; j > 0 && arr[j - 1] > arr[j]; --j) swap(arr[j - 1], arr[j]); }
Die Grundidee des Algorithmus ist die sogenannte Suche nach Maximum (und Minimum). Wählen Sie bei jeder Iteration ein Element aus dem Array aus. Wenn es größer als das vorherige Maximum ist, fügen Sie dieses Element am Ende der Auswahl hinzu. Andernfalls fügen wir dieses Element am Anfang hinzu, wenn es kleiner als das vorherige Minimum ist. Andernfalls fügen Sie ein separates Array ein.
Die Eingabefunktion nimmt ein Array und die Anzahl der Elemente in diesem Array an
void FirstNewGeneratingSort(int*& arr, int len)
Um ein Sample aus dem Array (unsere Höhen und Tiefen) und anderen Elementen zu speichern, weisen wir Speicher zu
int* selection = new int[len << 1];
Wie Sie sehen, haben wir zweimal mehr Speicher für das Sample reserviert als für unser ursprüngliches Array. Dies geschieht für den Fall, dass wir ein Array sortiert haben und jedes nächste Element ein neues Maximum darstellt. Dann wird nur der zweite Teil des Sample-Arrays belegt. Oder umgekehrt (wenn in absteigender Reihenfolge sortiert).
Zum Abtasten benötigen Sie zuerst das anfängliche Minimum und Maximum. Wählen Sie einfach das erste und das zweite Element aus
if (arr[0] > arr[1]) swap(arr[0], arr[1]); selection[left--] = arr[0]; selection[right++] = arr[1];
Sampling selbst
for (int i = 2; i < len; ++i) { if (selection[right - 1] <= arr[i])
Jetzt haben wir eine sortierte Menge von Elementen und die "verbleibenden" Elemente, die wir noch sortieren müssen. Aber zuerst müssen Sie einige Speicher-Manipulationen durchführen.
Geben Sie nicht verwendeten Speicher frei
int selectionLen = right - left - 1;
Führe einen rekursiven Sortieraufruf für die verbleibenden Elemente durch und füge sie mit der Auswahl zusammen
FirstNewGeneratingSort(restElements, restLen); glueDelete(arr, selection, selectionLen, restElements, restLen);
All algorithm code (Nicht optimale Version) void FirstNewGeneratingSort(int*& arr, int len) { if (len < 2) return; int* selection = new int[len << 1]; int left = len - 1; int right = len; int* restElements = new int[len]; int restLen = 0; if (arr[0] > arr[1]) swap(arr[0], arr[1]); selection[left--] = arr[0]; selection[right++] = arr[1]; for (int i = 2; i < len; ++i) { if (selection[right - 1] <= arr[i])
Lassen Sie uns die Geschwindigkeit des Algorithmus im Vergleich zur schnellen Sortierung überprüfen
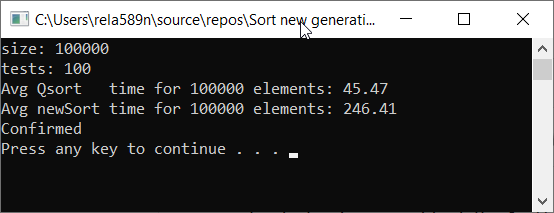
Wie Sie sehen können, ist dies überhaupt nicht das, was wir wollten. Fast 6 mal länger als QuickSort! Aber in diesem Zusammenhang ist es unangebracht, dies zu tun, da hier die Asymptotik eine Rolle spielt. Bei dieser Implementierung des Algorithmus sind im schlimmsten Fall das erste und das zweite Element minimal und maximal. Der Rest wird in ein separates Array kopiert.
Komplexität des Algorithmus:
- Schlimmster Fall: O (n 2 )
- Mittlerer Fall: O (n 2 )
- Bester Fall: O (n)
Hmm, das ist nicht besser als die gleiche Sortierung nach Beilagen. Ja, in der Tat können wir das maximale (minimale) Element sehr schnell finden, und der Rest fällt einfach nicht in die Auswahl.
Wir können versuchen, die Zusammenführungssortierung zu optimieren. Überprüfen Sie zunächst die Geschwindigkeit der üblichen Zusammenführungssortierung:
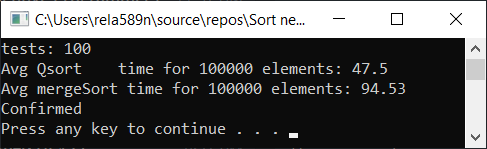
Sortierung mit Optimierung zusammenführen: void newGenerationMergeSort(int* a, int lo, int hi, int& minPortion) { if (hi <= lo) return; int mid = lo + (hi - lo) / 2; if (hi - lo <= minPortion) {
Eine Art Wrapper wird für die Benutzerfreundlichkeit benötigt.
void newMergeSort(int *arr, int length) { int portion = log2(length);
Testergebnis:
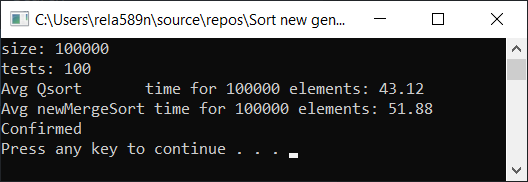
Ja, es wird eine Geschwindigkeitssteigerung beobachtet, diese Funktion arbeitet jedoch nicht so schnell wie Quick Sort. Außerdem können wir bei sortierten Arrays nicht über O (n) sprechen. Daher wird diese Option auch verworfen.
Optimierungsoptionen für die erste Option
Um sicherzustellen, dass die Komplexität nicht O (n 2 ) ist, können wir Elemente hinzufügen, die nicht wie zuvor in 1 Array in die Stichprobe fallen, sondern sie in 2 Arrays erweitern. Danach müssen Sie nur noch diese beiden Teile sortieren und mit unserem Beispiel zusammenführen. Als Ergebnis erhalten wir Komplexität gleich O (n log n)
Wie wir bereits bemerkt haben, kann das absolut maximale (minimale) Element in dem sortierten Array ziemlich schnell gefunden werden, und dies ist nicht sehr effektiv. Hier hilft uns die Einfügesortierung. Bei jeder Iteration der Auswahl prüfen wir, ob wir das Flow-Element in eine Menge der letzten, beispielsweise acht eingefügten Elemente einfügen können.
Wenn es jetzt nicht klar ist, sei nicht verärgert. Es sollte so sein. Jetzt wird im Code alles klar und die Fragen verschwinden.
Die Signatur ist dieselbe wie in der vorherigen Version
void newGenerationSort(int*& arr, int len)
Es sollte jedoch beachtet werden, dass diese Option einen Zeiger auf den ersten Parameter annimmt, für den die Operation delete [] aufgerufen werden kann (warum - wir werden später sehen). Das heißt, wenn wir Speicher zugewiesen haben, haben wir die Adresse des Beginns des Arrays für diesen Zeiger zugewiesen.
Vorbereitende Vorbereitung
In diesem Beispiel ist der sogenannte Aufholkoeffizient nur eine Konstante mit einem Wert von 8. Er gibt an, wie viele Maximalelemente wir versuchen, an ihrer Stelle ein neues „Unter-Maximum“ oder „Unter-Minimum“ einzufügen.
int localCatchUp = min(catchUp, len);
Erstellen Sie ein Array, um das Beispiel zu speichern
Wenn etwas nicht klar ist, lesen Sie die Erklärung in der ersten Version
int* selection = new int[len << 1];
Füllen Sie die ersten Elemente des Auswahlfelds aus
selection[left--] = arr[0]; for (int i = 1; i < localCatchUp; ++i) { selection[right++] = arr[i]; }
Ich möchte Sie daran erinnern, dass neue Tiefs links von der Mitte des Sample-Arrays und neue Hochs rechts davon liegen
Erstellen Sie Arrays, um nicht ausgewählte Elemente zu speichern
int restLen = len >> 1;
Das Wichtigste ist nun die richtige Auswahl der Elemente aus dem Quell-Array
Der Zyklus beginnt mit localCatchUp (da die vorherigen Elemente bereits in unser Beispiel als Werte eingegeben wurden, ab denen wir beginnen). Und es geht bis zum Ende. Am Ende werden also alle Elemente entweder in das Auswahlfeld oder in eines der Unterauswahlfelder verteilt.
Um zu überprüfen, ob wir ein Element in die Auswahl einfügen können, prüfen wir einfach, ob es mehr (oder gleich) zu dem Element ist, das 8 Positionen links (rechts - localCatchUp) liegt. Wenn dies der Fall ist, fügen wir es einfach in einem Durchgang durch diese Elemente an der gewünschten Position ein. Dies war für die rechte Seite, das heißt für die maximalen Elemente. Auf die gleiche Weise machen wir das Gegenteil für minimale. Wenn Sie es nicht auf beiden Seiten der Auswahl einfügen konnten, werfen wir es in eines der restlichen Arrays.
Die Schleife sieht ungefähr so aus:
for (int i = localCatchUp; i < len; ++i) { if (selection[right - localCatchUp] <= arr[i]) { selection[right] = arr[i]; for (int j = right; selection[j - 1] > selection[j]; --j) swap(selection[j - 1], selection[j]); ++right; continue; } if (selection[left + localCatchUp] >= arr[i]) { selection[left] = arr[i]; for (int j = left; selection[j] > selection[j + 1]; ++j) swap(selection[j], selection[j + 1]); --left; continue; } if (i & 1) {
Nochmal, was ist hier los? Zuerst versuchen wir, das Element in die Höhe zu treiben. Klappt nicht? - Wenn möglich, werfen Sie es auf die Tiefen. Wenn dies auch nicht möglich ist, legen Sie es in restFirst oder restSecond.
Der schwierigste Teil ist vorbei. Nach der Schleife haben wir nun ein sortiertes Array mit einer Auswahl (Elemente beginnen am Index [left + 1] und enden bei [right - 1] ) sowie restFirst- und restSecond-Arrays der Länge restFirstLen bzw. restSecondLen .
Wie im vorherigen Beispiel geben wir vor dem rekursiven Aufruf den Speicher aus dem Hauptarray frei (wir haben bereits alle seine Elemente gespeichert).
delete[] arr;
Unser Auswahlarray kann viele Zellen unbenutzten Speichers enthalten. Vor einem rekursiven Aufruf müssen Sie ihn freigeben.
Geben Sie nicht verwendeten Speicher frei
int selectionLen = right - left - 1;
Führen Sie jetzt unsere Sortierfunktion rekursiv für die Arrays restFirst und restSecond aus
Um zu verstehen, wie es funktioniert, müssen Sie zuerst den Code bis zum Ende betrachten. Im Moment müssen Sie nur glauben, dass nach rekursiven Aufrufen die Arrays restFirst und restSecond sortiert werden.
newGenerationSort(restFirst, restFirstLen); newGenerationSort(restSecond, restSecondLen);
Und schließlich müssen wir 3 Arrays zu dem resultierenden zusammenführen und es dem Zeigerarray zuweisen.
Sie könnten zuerst restFirst + restSecond in einem restFull- Array zusammenführen und dann selection + restFull zusammenführen . Dieser Algorithmus hat jedoch die Eigenschaft, dass das Auswahlarray höchstwahrscheinlich viel weniger Elemente enthält als alle anderen Arrays. Angenommen, die Auswahl enthält 100 Elemente, restFirst enthält 990 und restSecond enthält 1010. Um ein restFull- Array zu erstellen, müssen Sie 990 + 1010 = 2000 Kopiervorgänge ausführen. Dann zum Zusammenführen mit der Auswahl - weitere 2000 + 100 Exemplare. Insgesamt ist bei diesem Ansatz die Gesamtkopie 2000 + 2100 = 4100.
Wenden wir hier die Optimierung an. Führen Sie zuerst die Auswahl und restFirst in das Auswahlarray ein . Kopiervorgänge: 100 + 990 = 1090. Führen Sie als Nächstes die Arrays selection und restSecond zusammen und geben Sie weitere 1090 + 1010 = 2100 Kopien aus. Insgesamt werden 2100 + 1090 = 3190 freigegeben, was fast ein Viertel weniger ist als beim vorherigen Ansatz.
Die endgültige Zusammenführung von Arrays
int* part2; int part2Len; if (selectionLen < restFirstLen) { glueDelete(selection, restFirst, restFirstLen, selection, selectionLen);
Wie wir sehen, ist es für uns rentabler, die Auswahl mit restFirst zu verschmelzen, dann tun wir dies. Ansonsten verschmelzen wir wie in "restFull"
Der endgültige Code des Algorithmus: Jetzt mal testen
Der Hauptcode in Source.cpp: #include <iostream> #include <ctime> #include <vector> #include <algorithm> #include "time_utilities.h" #include "sort_utilities.h" using namespace std; using namespace rela589n; void printArr(int* arr, int len) { for (int i = 0; i < len; ++i) { cout << arr[i] << " "; } cout << endl; } bool arraysEqual(int* arr1, int* arr2, int len) { for (int i = 0; i < len; ++i) { if (arr1[i] != arr2[i]) { return false; } } return true; } int* createArray(int length) { int* a1 = new int[length]; for (int i = 0; i < length; i++) { a1[i] = rand(); //a1[i] = (i + 1) % (length / 4); } return a1; } int* array_copy(int* arr, int length) { int* a2 = new int[length]; for (int i = 0; i < length; i++) { a2[i] = arr[i]; } return a2; } void tester(int tests, int length) { double t1, t2; int** arrays1 = new int* [tests]; int** arrays2 = new int* [tests]; for (int t = 0; t < tests; ++t) { // int* arr1 = createArray(length); arrays1[t] = arr1; arrays2[t] = array_copy(arr1, length); } t1 = getCPUTime(); for (int t = 0; t < tests; ++t) { quickSort(arrays1[t], 0, length - 1); } t2 = getCPUTime(); cout << "Avg Qsort time for " << length << " elements: " << (t2 - t1) * 1000 / tests << endl; int portion = catchUp = 8; t1 = getCPUTime(); for (int t = 0; t < tests; ++t) { newGenerationSort(arrays2[t], length); } t2 = getCPUTime(); cout << "Avg newGenSort time for " << length << " elements: " << (t2 - t1) * 1000 / tests //<< " Catch up coef: "<< portion << endl; bool confirmed = true; // for (int t = 0; t < tests; ++t) { if (!arraysEqual(arrays1[t], arrays2[t], length)) { confirmed = false; break; } } if (confirmed) { cout << "Confirmed" << endl; } else { cout << "Review your code! Something wrong..." << endl; } } int main() { srand(time(NULL)); int length; double t1, t2; cout << "size: "; cin >> length; int t; cout << "tests: "; cin >> t; tester(t, length); system("pause"); return 0; }
Die Quick Sort-Implementierung, die beim Testen zum Vergleich verwendet wurde:Eine kleine Bemerkung: Ich habe diese spezielle Implementierung von quickSort verwendet, damit alles ehrlich war. Obwohl die Standardsortierung aus der Algorithmusbibliothek universell ist, arbeitet sie zweimal langsamer als die unten dargestellte.
getCPUTime - CPU Zeitmessung: #pragma once #if defined(_WIN32) #include <Windows.h> #elif defined(__unix__) || defined(__unix) || defined(unix) || (defined(__APPLE__) && defined(__MACH__)) #include <unistd.h> #include <sys/resource.h> #include <sys/times.h> #include <time.h> #else #error "Unable to define getCPUTime( ) for an unknown OS." #endif /** * Returns the amount of CPU time used by the current process, * in seconds, or -1.0 if an error occurred. */ double getCPUTime() { #if defined(_WIN32) /* Windows -------------------------------------------------- */ FILETIME createTime; FILETIME exitTime; FILETIME kernelTime; FILETIME userTime; if (GetProcessTimes(GetCurrentProcess(), &create;Time, &exit;Time, &kernel;Time, &user;Time) != -1) { SYSTEMTIME userSystemTime; if (FileTimeToSystemTime(&user;Time, &user;SystemTime) != -1) return (double)userSystemTime.wHour * 3600.0 + (double)userSystemTime.wMinute * 60.0 + (double)userSystemTime.wSecond + (double)userSystemTime.wMilliseconds / 1000.0; } #elif defined(__unix__) || defined(__unix) || defined(unix) || (defined(__APPLE__) && defined(__MACH__)) /* AIX, BSD, Cygwin, HP-UX, Linux, OSX, and Solaris --------- */ #if defined(_POSIX_TIMERS) && (_POSIX_TIMERS > 0) /* Prefer high-res POSIX timers, when available. */ { clockid_t id; struct timespec ts; #if _POSIX_CPUTIME > 0 /* Clock ids vary by OS. Query the id, if possible. */ if (clock_getcpuclockid(0, &id;) == -1) #endif #if defined(CLOCK_PROCESS_CPUTIME_ID) /* Use known clock id for AIX, Linux, or Solaris. */ id = CLOCK_PROCESS_CPUTIME_ID; #elif defined(CLOCK_VIRTUAL) /* Use known clock id for BSD or HP-UX. */ id = CLOCK_VIRTUAL; #else id = (clockid_t)-1; #endif if (id != (clockid_t)-1 && clock_gettime(id, &ts;) != -1) return (double)ts.tv_sec + (double)ts.tv_nsec / 1000000000.0; } #endif #if defined(RUSAGE_SELF) { struct rusage rusage; if (getrusage(RUSAGE_SELF, &rusage;) != -1) return (double)rusage.ru_utime.tv_sec + (double)rusage.ru_utime.tv_usec / 1000000.0; } #endif #if defined(_SC_CLK_TCK) { const double ticks = (double)sysconf(_SC_CLK_TCK); struct tms tms; if (times(&tms;) != (clock_t)-1) return (double)tms.tms_utime / ticks; } #endif #if defined(CLOCKS_PER_SEC) { clock_t cl = clock(); if (cl != (clock_t)-1) return (double)cl / (double)CLOCKS_PER_SEC; } #endif #endif return -1; /* Failed. */ }
Alle Tests wurden prozentual an der Maschine durchgeführt. Intel Core i3 7100u und 8 GB RAM
Komplett zufälliges Array Teilweise geordnetes Array a1[i] = (i + 1) % (length / 4);


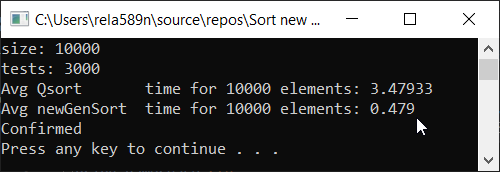
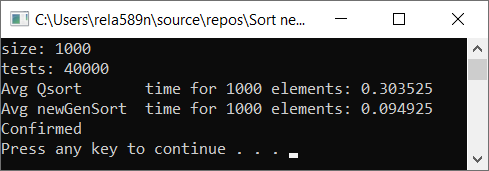
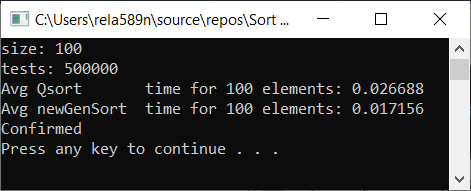
Schlussfolgerungen
Wie Sie sehen können, funktioniert der Algorithmus und funktioniert gut. Zumindest alles, was wir wollten, wurde erreicht. Auf Kosten der Stabilität bin ich mir nicht sicher, ob ich es nicht überprüft habe. Sie können es selbst überprüfen. Theoretisch sollte es aber sehr einfach zu erreichen sein. Stellen Sie einfach an einigen Stellen anstelle des Zeichens> ≥ oder so ein.