Hallo habr Mein Name ist Denis Kopyrin und ich möchte heute darüber sprechen, wie wir das Problem des Backups auf Abruf unter macOS gelöst haben. Eine interessante Aufgabe, der ich am Institut begegnete, entwickelte sich schließlich zu einem großen Forschungsprojekt über die Arbeit mit dem Dateisystem. Alle Details sind unter dem Schnitt.

Ich werde nicht von weitem anfangen, ich kann nur sagen, dass alles mit einem Projekt am Moskauer Institut für Physik und Technologie begann, das ich mit meinem Vorgesetzten an der Acronis-Basisabteilung entwickelt habe. Wir standen vor der Aufgabe, die Remote-Speicherung von Dateien zu organisieren bzw. den aktuellen Status ihrer Sicherungen beizubehalten.
Um die Datensicherheit zu gewährleisten, verwenden wir die macOS-Kernel-Erweiterung, die Informationen zu Ereignissen im System sammelt. KPI für Entwickler verfügt über eine KAUTH-API, die es Ihnen ermöglicht, Benachrichtigungen über das Öffnen und Schließen einer Datei zu erhalten - das ist alles. Wenn Sie KAUTH verwenden, müssen Sie die Datei beim Öffnen zum Schreiben vollständig speichern, da die Ereignisse zum Schreiben in die Datei den Entwicklern nicht zur Verfügung stehen. Solche Informationen reichten für unsere Aufgaben nicht aus. In der Tat müssen Sie genau wissen, wo der Benutzer (oder die Malware :) die neuen Daten in die Datei geschrieben hat, um eine Sicherungskopie der Daten dauerhaft zu ergänzen.
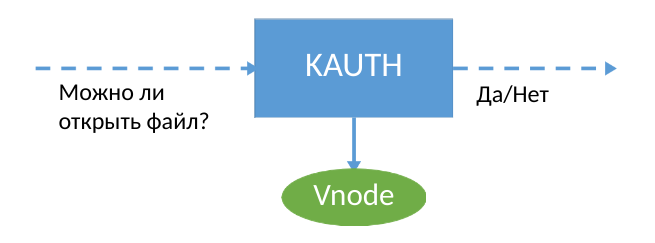
Aber welche Entwickler hatten Angst vor Betriebssystemeinschränkungen? Wenn Sie mit der Kernel-API keine Informationen über Schreibvorgänge abrufen können, müssen Sie einen eigenen Weg finden, um andere Kernel-Tools abzufangen.
Zunächst wollten wir den Kern und seine Strukturen nicht patchen. Stattdessen haben sie versucht, ein ganzes virtuelles Volume zu erstellen, mit dem wir alle Lese- und Schreibanforderungen abfangen können, die es durchlaufen. Aber es stellte sich heraus, dass macOS ein unangenehmes Merkmal ist: Das Betriebssystem glaubt, dass es nicht über 1, sondern über 2 USB-Sticks, zwei Festplatten usw. verfügt. Und aufgrund der Tatsache, dass sich das zweite Volume beim Arbeiten mit dem ersten ändert, funktioniert macOS bei Laufwerken nicht mehr richtig. Es gab so viele Probleme mit dieser Methode, dass ich darauf verzichten musste.
Suchen Sie nach einer anderen Lösung
Trotz der Einschränkungen von KAUTH können Sie mit diesem KPI vor allen Vorgängen über die Verwendung einer Datei für die Aufzeichnung benachrichtigt werden. Entwickler erhalten Zugriff auf die BSD-Dateiabstraktion im Kernel-vnode. Seltsamerweise stellte sich heraus, dass das Patchen von vnode einfacher ist als das Filtern von Volumes. Die vnode-Struktur enthält eine Tabelle mit Funktionen, die die Arbeit mit realen Dateien ermöglichen. Daher hatten wir die Idee, diese Tabelle zu ersetzen.
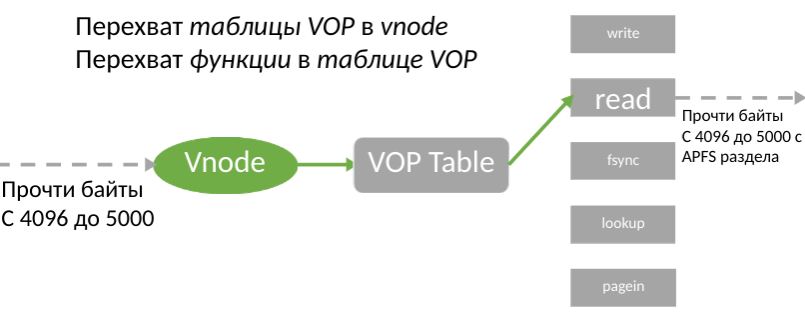
Die Idee wurde sofort als gute Idee angesehen, aber für ihre Umsetzung war es notwendig, die Tabelle selbst in der vnode-Struktur zu finden, da Apple ihren Standort nirgendwo dokumentiert. Dazu war es notwendig, den Maschinencode des Kernels zu studieren und auch herauszufinden, ob es möglich ist, auf diese Adresse zu schreiben, damit das System danach nicht abstirbt.
Wenn die Tabelle gefunden wird, kopieren wir sie einfach in den Speicher, setzen den Zeiger auf und fügen den Link zur neuen Tabelle in den vorhandenen vnode ein. Dadurch werden alle Vorgänge mit Dateien über unseren Treiber ausgeführt, und wir können alle Benutzeranforderungen, einschließlich Lesen und Schreiben, registrieren. Daher ist die Suche nach dem begehrten Tisch zu unserem Hauptziel geworden.
Da Apple dies nicht wirklich möchte, müssen Sie zur Lösung des Problems versuchen, die Position der Tabelle mithilfe von Heuristiken für die relative Position der Felder zu erraten, oder eine bereits bekannte Funktion verwenden, sie zerlegen und nach einem Offset aus diesen Informationen suchen.
So suchen Sie nach einem Offset: auf einfache WeiseDer einfachste Weg, um Tabellenversätze in vnode zu finden, ist eine Heuristik, die auf der Position von Feldern in einer Struktur basiert (
Link zu Github ).
struct vnode { ... int (**v_op)(void *); mount_t v_mount; ... }
Wir gehen davon aus, dass das von uns benötigte v_op-Feld genau 8 Bytes von v_mount entfernt ist. Der Wert der letzteren kann mit öffentlichen KPI erhalten werden (
Link zu Github ):
mount_t vnode_mount(vnode_t vp);
Wenn wir den Wert von v_mount kennen, werden wir nach einer „Nadel im Heuhaufen“ suchen - wir werden den Wert des Zeigers auf vnode 'vp' als uintptr_t *, den Wert von vnode_mount (vp) als uintptr_t wahrnehmen. Darauf folgen Iterationen auf den „angemessenen“ Wert von i, bis die Bedingung „Heuhaufen [i] == Nadel“ erfüllt ist. Und wenn die Annahme über die Position der Felder korrekt ist, ist der Versatz v_op i-1.
void* getVOPPtr(vnode_t vp) { auto haystack = (uintptr_t*) vp; auto needle = (uintptr_t) vnode_mount(vp); for (int i = 0; i < ATTEMPTCOUNT; i++) { if (haystack[i] == needle) { return haystack + (i - 1); } } return nullptr; }
So suchen Sie nach einem Versatz: DemontageTrotz seiner Einfachheit weist das erste Verfahren einen signifikanten Nachteil auf. Wenn Apple die Reihenfolge der Felder in der vnode-Struktur ändert, bricht die einfache Methode ab. Eine universellere, aber weniger triviale Methode ist das dynamische Zerlegen des Kernels.
Betrachten Sie zum Beispiel die disassemblierte Kernelfunktion VNOP_CREATE (
Link zu Github ) unter macOS 10.14.6. Hinweise, die uns interessieren, sind mit einem Pfeil -> gekennzeichnet.
_VNOP_CREATE:
1 push rbp
2 mov rbp, rsp
3 push r15
4 push r14
5 push r13
6 push r12
7 push rbx
8 sub rsp, 0x48
9 mov r15, r8
10 mov r12, rdx
11 mov r13, rsi
-> 12 mov rbx, rdi
13 lea rax, qword [___stack_chk_guard]
14 mov rax, qword [rax]
15 mov qword [rbp+-48], rax
-> 16 lea rax, qword [_vnop_create_desc] ; _vnop_create_desc
17 mov qword [rbp+-112], rax
18 mov qword [rbp+-104], rdi
19 mov qword [rbp+-96], rsi
20 mov qword [rbp+-88], rdx
21 mov qword [rbp+-80], rcx
22 mov qword [rbp+-72], r8
-> 23 mov rax, qword [rdi+0xd0]
-> 24 movsxd rcx, dword [_vnop_create_desc]
25 lea rdi, qword [rbp+-112]
-> 26 call qword [rax+rcx*8]
27 mov r14d, eax
28 test eax, eax
…. errno_t VNOP_CREATE(vnode_t dvp, vnode_t * vpp, struct componentname * cnp, struct vnode_attr * vap, vfs_context_t ctx) { int _err; struct vnop_create_args a; a.a_desc = &vnop;_create_desc; a.a_dvp = dvp; a.a_vpp = vpp; a.a_cnp = cnp; a.a_vap = vap; a.a_context = ctx; _err = (*dvp->v_op[vnop_create_desc.vdesc_offset])(&a;); …
Wir werden die Assembler-Anweisungen scannen, um die Verschiebung im VNode-DVP zu finden. Der „Zweck“ des Assembler-Codes besteht darin, eine Funktion aus der Tabelle v_op aufzurufen. Dazu muss der Prozessor die folgenden Schritte ausführen:
- Laden Sie dvp hoch, um sich zu registrieren
- Dereferenzieren, um v_op zu erhalten (Zeile 23)
- Holen Sie sich vnop_create_desc.vdesc_offset (Zeile 24)
- Rufe eine Funktion auf (Zeile 26)
Wenn bei den Schritten 2 bis 4 alles klar ist, treten beim ersten Schritt Schwierigkeiten auf. Wie kann ich nachvollziehen, in welches Register dvp geladen wurde? Dazu haben wir eine Methode zum Emulieren einer Funktion verwendet, die die Bewegungen des gewünschten Zeigers überwacht. Gemäß der System V x86_64-Aufrufkonvention wird das erste Argument im rdi-Register übergeben. Aus diesem Grund haben wir uns entschlossen, alle Register, die rdi enthalten, im Auge zu behalten. In meinem Beispiel sind dies die Register rbx und rdi. Außerdem kann eine Kopie des Registers auf dem Stapel gespeichert werden, der sich in der Debug-Version des Kernels befindet.
Wenn wir wissen, dass die Register rbx und rdi dvp speichern, finden wir heraus, dass Zeile 23 vnode dereferenziert, um v_op zu erhalten. Wir gehen also davon aus, dass die Verschiebung in der Struktur 0xd0 ist. Um die richtige Entscheidung zu bestätigen, scannen wir weiter und stellen sicher, dass die Funktion korrekt aufgerufen wird (Zeilen 24 und 26).
Diese Methode ist sicherer, hat aber leider auch Nachteile. Wir müssen uns auf die Tatsache verlassen, dass das Funktionsmuster (dh die 4 Schritte, über die wir oben gesprochen haben) dasselbe ist. Die Wahrscheinlichkeit, das Muster der Funktion zu ändern, ist jedoch um eine Größenordnung geringer als die Wahrscheinlichkeit, die Reihenfolge der Felder zu ändern. Also beschlossen wir, mit der zweiten Methode aufzuhören.
Ersetzen Sie die Zeiger in der Tabelle
Nachdem Sie v_op gefunden haben, stellt sich die Frage, wie Sie diesen Zeiger verwenden sollen. Es gibt zwei Möglichkeiten: Überschreiben Sie die Funktion in der Tabelle (dritter Pfeil im Bild) oder überschreiben Sie die Tabelle in vnode (zweiter Pfeil im Bild).
Auf den ersten Blick scheint die erste Option rentabler zu sein, da wir nur einen Zeiger ersetzen müssen. Dieser Ansatz weist jedoch zwei wesentliche Nachteile auf. Erstens ist die v_op-Tabelle für alle vnode eines bestimmten Dateisystems gleich (v_op für HFS +, v_op für APFS, ...). Daher ist das Filtern nach vnode erforderlich, was sehr teuer sein kann. Sie müssen bei jedem Schreibvorgang zusätzlichen vnode herausfiltern. Zweitens wird die Tabelle auf der schreibgeschützten Seite geschrieben. Diese Einschränkung kann umgangen werden, wenn Sie die Aufzeichnung über IOMappedWrite64 verwenden und Systemprüfungen umgehen. Wenn kext mit dem Dateisystemtreiber ausgeliefert wird, ist es schwierig, herauszufinden, wie der Patch entfernt werden kann.
Die zweite Option erweist sich als zielgerichteter und sicherer - der Interceptor wird nur für den erforderlichen vNode aufgerufen, und der vNode-Speicher ermöglicht zunächst Lese- / Schreibvorgänge. Da die gesamte Tabelle ersetzt wird, muss etwas mehr Speicher zugewiesen werden (80 Funktionen statt einer). Und da die Anzahl der Tabellen in der Regel der Anzahl der Dateisysteme entspricht, ist das Speicherlimit völlig vernachlässigbar.
Deshalb wendet kext die zweite Methode an, obwohl es auf den ersten Blick so aussieht, als wäre diese Option schlechter.
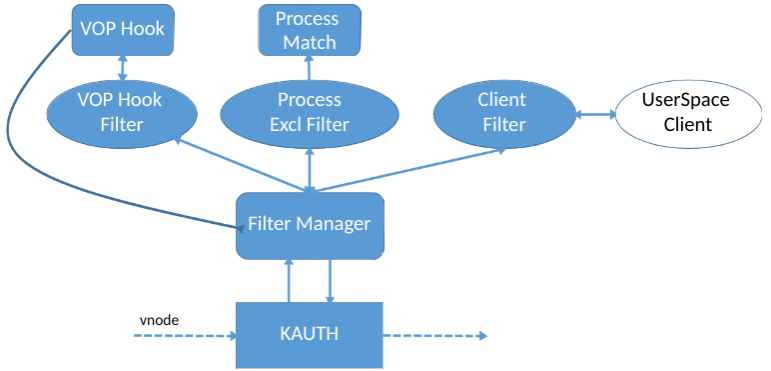
Infolgedessen arbeitet unser Fahrer wie folgt:
- Die KAUTH-API stellt vnode bereit
- Wir ersetzen die VNode-Tabelle. Bei Bedarf fangen wir Operationen nur für "interessante" Knoten ab, zum Beispiel für Benutzerdokumente
- Wenn wir abfangen, prüfen wir, welcher Prozess gerade aufgezeichnet wird, filtern wir „unsere“
- Wir senden eine synchrone UserSpace-Anfrage an den Client, der entscheidet, was genau gespeichert werden soll.
Was ist passiert?
Heute haben wir ein experimentelles Modul, das eine Erweiterung des macOS-Kernels ist und alle Änderungen am Dateisystem auf granularer Ebene berücksichtigt. Es ist erwähnenswert, dass Apple in macOS 10.15 ein neues Framework (
Link zu EndpointSecurity ) eingeführt hat, um Benachrichtigungen über Änderungen am Dateisystem zu erhalten, das für die Verwendung in Active Protection vorgesehen ist. Aus diesem Grund wurde die im Artikel beschriebene Lösung für veraltet erklärt.