In manchen Fällen müssen Sie den Benutzerzugriff auf einige Daten im Cube einschränken. Es scheint, dass es nichts Kompliziertes gibt: Installieren Sie die Zeilenfilter in Rollen, und Sie haben es geschafft, aber es gibt ein Problem: Der Filter schneidet die Daten in der Tabelle und es stellt sich heraus, dass Sie die Geschwindigkeit nur anhand der verfügbaren Zeilen sehen können, und wir brauchen die gesamte Geschwindigkeit, aber die Details sollten nur verfügbar sein für einige von ihnen.
Zum Beispiel sollte der Benutzer den Umsatz für alle Produkte mit der Möglichkeit der vollständigen Angabe sehen, aber gleichzeitig sollten Kunden nicht alle, sondern nur einige oder alle Kunden anzeigen, sondern in einigen Attributen (Feldern) teilweise verborgene Daten.
Um zu verhindern, dass der Benutzer den Umsatz in Bezug auf Kunden anzeigt, können Sie dies durch Formeln in Kennzahlen unterbinden und einen leeren Wert anzeigen, wenn der Benutzer versucht, den Umsatz eines bestimmten Kunden anzuzeigen. Eine dieser Optionen wird
hier beschrieben. Dies ist jedoch nicht der Fall. Wenn ein paar Dutzend Maßnahmen, dann schreiben Sie eine Formel in jedem von ihnen ... und wenn Sie vergessen? Aber Sie werden es sicherlich eines Tages vergessen ... Und wenn der Benutzer Daten von einer bestimmten Kundenkarte benötigt, kann er diese nicht sehen, ohne eine Filtermaßnahme zu wählen. Was zu tun
Wir mussten diese Anzeige erreichen:
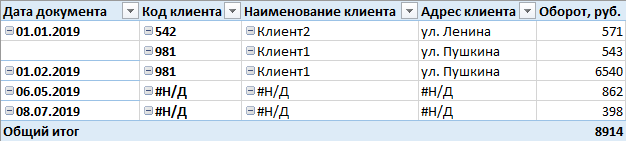
Das gesamte Prinzip, mit dem Sie ein ähnliches Ergebnis erzielen, basiert auf einem kleinen Trick und besteht darin, der Tabelle (in diesem Fall clients) synthetische Zeilen hinzuzufügen, sodass der Datensatz über dieselbe Entität mindestens einmal dupliziert wird - der erste enthält vollständige Informationen, und die zweite in den meisten Spalten ist mit einem Stecker vom Typ
# N / A gefüllt, aber die Bezeichner sind für beide Datensätze gleich. Mithilfe eines Filters in Rollen und einer speziellen Spalte, nach der gefiltert wird, lassen wir dem Benutzer außerdem bestimmte Zeilen zur Verfügung - entweder eine Zeile mit vollständig ausgefüllten Feldern oder mit Stubs. Und seitdem Da der Cube die Eigenschaft hat, sich wiederholende Daten zu "kollabieren" und dem Benutzer keine anderen Attribute mit eindeutigen Werten zur Verfügung stehen, werden in der resultierenden Tabelle alle Clients mit dem Code
# N / A in eine Zeile umgewandelt. Ich denke, dass zu diesem Zeitpunkt schon alles sehr klar ist, man kann nicht mehr lesen. Das Ergebnis steht im Titel des Artikels.
Aber wenn jemand Details braucht - ich habe sie.
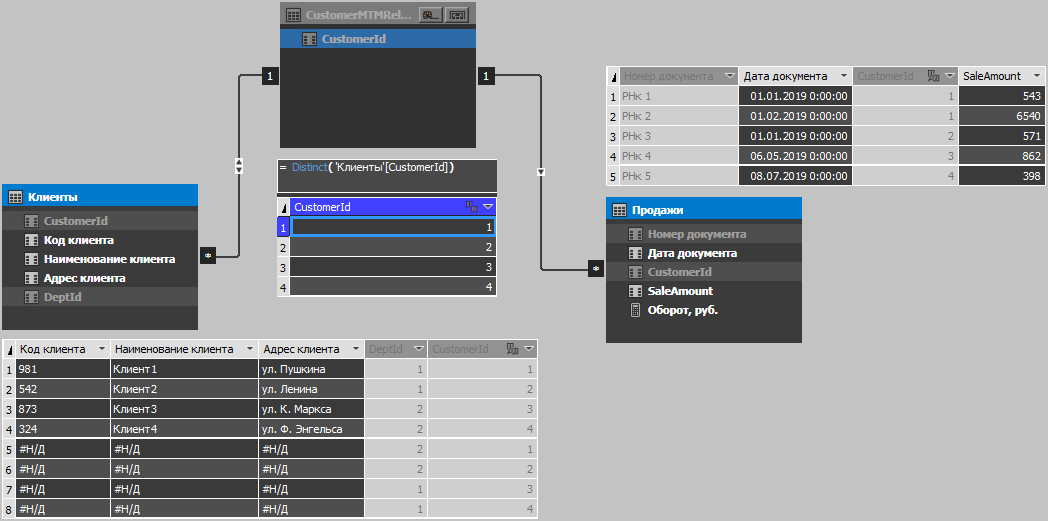
In Tabellenmodellen bis Version 1400 (einschließlich SQL 2017) können keine Viele-zu-Viele-Beziehungen erstellt werden. Bei Duplikaten benötigen wir jedoch eine solche Beziehung. Daher erstellen wir sie über eine Zwischentabelle, die nur eine Spalte mit eindeutigen Kunden-IDs enthält. Die Tabelle ist seitdem zunächst inkompressibel enthält nur eindeutige Werte, sodass Sie sie berechnen können, da wir in diesem Fall nichts gewinnen, wenn wir sie durch t-sql füllen (beachten Sie das Verarbeitungsprinzip und die Reihenfolge der Tabellenkomprimierung?). Nur aufgrund der Fähigkeit der Engine, doppelte Daten zu komprimieren, steigt die Datenmenge im Cube geringfügig an, und aufgrund des Filterns durch die Rolle verfügt die Benutzersitzung über einen reduzierten Satz von Datensätzen, d. H. Die endgültige Anzahl der Datensätze nach dem Filtern des Satzes bleibt unverändert ohne Duplikate. Machen Sie sich deshalb keine Sorgen, auch wenn die Tabelle anfangs groß genug ist. Das Hinzufügen von Duplikaten wirkt sich nicht wesentlich auf Leistung und Volumen aus (natürlich sind die Fälle unterschiedlich, aber in den meisten Fällen ist alles genau das).
Die folgende Abbildung zeigt das Cube-Modell und den Tabelleninhalt:
Fügen Sie beispielsweise einen einfachen Filter hinzu:

Das ist alles.
Ich möchte vor einer Besonderheit dieser Vorgehensweise warnen. Benutzer, die Administratoren auf dem SSAS-Server sind, gehen standardmäßig in den Cube und umgehen alle Arten von Rollen, auch wenn ihre Namen in diesen Rollen angegeben sind. Dies führt dazu, dass Rollenfilter nicht funktionieren und unter dem Administrator alle Duplikate sichtbar sind. Verzweifeln Sie jedoch nicht, es reicht aus, in der Verbindungszeichenfolge explizit anzugeben, welche Rolle verwendet werden soll, und alles passt. Außerdem müssen Sie beim Testen mehr als einmal zwischen den Rollen wechseln.
Wie Sie verstehen, können Sie mehrere Kombinationen desselben Datensatzes mit unterschiedlichem Füllgrad der Spalten mit realen Daten erstellen. Sie können auch eine separate ausgeblendete Tabelle im Cube erstellen, die über ADSI mit Konten gefüllt wird, und Benutzer auf verschiedene Domänengruppen verteilen. Diese Tabelle kann in Abhängigkeit von der Kombination der Benutzerzugehörigkeit in bestimmten Gruppen ausgefüllt werden. Wir schreiben die Links in den zeilenweisen Rollenfiltern zu dieser Tabelle, die es uns ermöglichen, die Messungen zu steuern, und wir können auch in Kennzahlen darauf verweisen, sodass bei Bedarf einige Kennzahlen die Leere anzeigen. Mit einer solchen Organisation wird eine Feinabstimmung der Zugriffsrechte auf Daten erzielt und alles an einem Ort gespeichert. Es gibt jedoch eine Nuance bei Kennzahlen: Wenn ein fortgeschrittener Benutzer selbst Abfragen in den Cube schreibt, hindert ihn nichts daran, seine Kennzahl ohne Lesezeichen zu verwenden, vorausgesetzt, er kennt die Namen der Basisspalten und die Formel ... Wenn gewünscht, können Sie dies jedoch hier tun Einschränkung, aber das ist ein anderes Thema.