Alle reden von Entwicklungs- und Testprozessen, Mitarbeiterschulung und zunehmender Motivation, aber es gibt nur wenige Prozesse, bei denen eine Minute Ausfallzeit Platz kostet. Was ist zu tun, wenn Sie Finanztransaktionen unter einem engen SLA durchführen? Wie können Sie die Zuverlässigkeit und Fehlertoleranz Ihrer Systeme erhöhen und die Entwicklung und das Testen erläutern?

Die nächste HighLoad ++ Konferenz findet am 6. und 7. April 2020 in St. Petersburg statt. Details und Tickets
hier . 9. November, 18:00 Uhr. HighLoad ++ Moskau 2018, Delhi + Calcutta Hall. Abstracts und
Präsentation .
Evgeny Kuzovlev (im Folgenden als die EG bezeichnet): - Freunde, hallo! Ich heiße Kuzovlev Evgeny. Ich bin von EcommPay, eine spezielle Abteilung ist EcommPay IT, eine IT-Abteilung einer Unternehmensgruppe. Und heute werden wir über Ausfallzeiten sprechen - wie man sie vermeidet, wie man ihre Folgen minimiert, wenn man sie nicht vermeiden kann. Das Thema lautet: "Was tun, wenn eine Minute Ausfallzeit 100.000 US-Dollar kostet?" Für uns sind die Zahlen in der Zukunft vergleichbar.
Was macht EcommPay IT?
Wer sind wir Warum stehe ich vor dir? Warum darf ich Ihnen hier etwas sagen? Und worüber werden wir hier ausführlicher sprechen?

Die EcommPay-Unternehmensgruppe ist ein internationaler Erwerber. Wir verarbeiten Zahlungen weltweit - in Russland, Europa, Südostasien (auf der ganzen Welt). Wir haben 9 Büros mit insgesamt 500 Mitarbeitern, von denen etwas weniger als die Hälfte IT-Spezialisten sind. Alles, was wir tun, alles, womit wir Geld verdienen, haben wir selbst gemacht.
Wir haben alle unsere Produkte (und wir haben viele davon - im Bereich der großen IT-Produkte haben wir ungefähr 16 verschiedene Komponenten) selbst geschrieben. wir schreiben uns selbst, wir entwickeln uns. Und im Moment führen wir ungefähr eine Million Transaktionen pro Tag durch (Millionen - wahrscheinlich wird es richtig sein, das zu sagen). Wir sind ein junges Unternehmen genug - wir sind erst etwa sechs Jahre alt.
Vor 6 Jahren war es so ein Startup, als die Jungs mit dem Geschäft kamen. Sie waren durch eine Idee verbunden (es gab nichts anderes als eine Idee) und wir rannten los. Wie jedes Startup liefen wir schneller ... Für uns war Geschwindigkeit wichtiger als Qualität.
Irgendwann hörten wir auf: Wir stellten fest, dass wir nicht mehr mit dieser Geschwindigkeit und Qualität leben konnten, und wir mussten in erster Linie Qualität machen. Zu diesem Zeitpunkt haben wir beschlossen, eine neue Plattform zu schreiben, die richtig, skalierbar und zuverlässig ist. Sie haben angefangen, diese Plattform zu schreiben (sie haben angefangen zu investieren, zu entwickeln, zu testen), aber irgendwann haben sie gemerkt, dass Entwicklung und Testen kein neues Niveau an Servicequalität ermöglichen.
Sie stellen ein neues Produkt her, Sie stellen es für die Produktion bereit, aber irgendwo stimmt etwas nicht. Und heute werden wir darüber sprechen, wie wir ein neues qualitatives Niveau erreichen (wie wir es erlangt haben, über unsere Erfahrung), die Entwicklung und das Testen aus dem Bild herausnehmen; Wir werden darüber sprechen, was für eine Nutzung verfügbar ist - was die Nutzung für sich allein leisten kann, was sie zum Testen anbieten kann, um die Qualität zu beeinträchtigen.
Ausfallzeiten. Die Gebote der Ausbeutung.
Der wichtigste Eckpfeiler, über den wir heute sprechen werden, sind immer die Ausfallzeiten. Furchterregendes Wort. Wenn wir eine Ausfallzeit hatten, ist bei uns alles schlecht. Wir rennen, um zu erhöhen, die Administratoren halten den Server - Gott bewahre, es fällt nicht, wie in diesem Lied. Darüber werden wir heute sprechen.

Als wir begannen, unsere Herangehensweisen zu ändern, bildeten wir 4 Gebote. Sie sind auf meinen Folien dargestellt:
Diese Gebote sind einfach genug:

- Identifizieren Sie das Problem schnell.
- Werde es noch schneller los.
- Erklären Sie den Grund (später für Entwickler).
- Und Ansätze standardisieren.
Ich mache Sie auf Punkt 2 aufmerksam. Wir beseitigen das Problem, aber lösen es nicht. Zu entscheiden ist das zweite Mal. Das Wichtigste für uns ist, dass der Benutzer vor diesem Problem geschützt ist. Es wird in einer bestimmten isolierten Umgebung existieren, aber diese Umgebung wird nicht damit in Kontakt kommen. Tatsächlich werden wir diese vier Problemgruppen durchgehen (einige detaillierter, andere weniger detailliert). Ich werde Ihnen sagen, was wir verwenden, welche Art von Erfahrung wir beim Lösen haben.
Fehlerbehebung: wann und was tun mit ihnen?
Aber wir werden außer Betrieb gehen, wir beginnen mit Punkt 2 - wie kann das Problem schnell behoben werden? Es gibt ein Problem - wir müssen es beheben. "Was sollen wir damit machen?" Ist die Hauptfrage. Und als wir darüber nachdachten, wie wir das Problem beheben können, haben wir einige Anforderungen entwickelt, denen die Fehlerbehebung folgen sollte.

Um diese Anforderungen zu formulieren, haben wir uns die Frage gestellt: „Und wann haben wir Probleme?“. Wie sich herausstellte, treten die Probleme in vier Fällen auf:

- Hardware-Störung.
- Ausfall externer Dienste.
- Änderung der Softwareversion (gleiches Deployment).
- Explosives Lastwachstum.
Wir werden nicht über die ersten beiden reden. Eine Hardwarestörung ist ganz einfach zu beheben: Sie sollten alles duplizieren lassen. Wenn es sich um Datenträger handelt - Datenträger müssen in RAID zusammengestellt werden, wenn es sich um einen Server handelt - der Server muss dupliziert werden, wenn Sie über eine Netzwerkinfrastruktur verfügen - Sie müssen eine zweite Kopie der Netzwerkinfrastruktur erstellen, dh, Sie müssen sie kopieren und duplizieren. Und wenn bei Ihnen etwas ausfällt, wechseln Sie zu Kapazitätsreserven. Es ist schwer, hier mehr zu sagen.
Das zweite Problem ist der Ausfall externer Dienste. Für die meisten ist das System überhaupt kein Problem, aber für uns nicht. Da wir Zahlungen verarbeiten, sind wir ein solcher Aggregator, der zwischen dem Benutzer (der seine Kartendaten eingibt) und Banken, Zahlungssystemen ("Visa", "MasterCard", "World") derselben steht. Unsere externen Dienstleistungen (Zahlungssysteme, Banken) fallen tendenziell aus. Weder wir noch Sie (wenn Sie solche Dienste in Anspruch nehmen) können dies beeinflussen.
Was ist dann zu tun? Es gibt zwei Möglichkeiten. Wenn Sie können, müssen Sie diesen Dienst zunächst auf irgendeine Weise duplizieren. Wenn wir können, übertragen wir beispielsweise Verkehr von einem Dienst zu einem anderen: Wir verarbeiten beispielsweise Karten über die Sberbank, die Sberbank hat Probleme - wir übertragen Verkehr [bedingt] an Raiffeisen. Das zweite, was wir tun können, ist, das Versagen externer Dienste schnell zu bemerken, und deshalb werden wir im nächsten Teil des Berichts über die Reaktionsgeschwindigkeit sprechen.
Tatsächlich können wir von diesen vier speziell die Änderung von Softwareversionen beeinflussen, um Maßnahmen zu ergreifen, die zu einer Verbesserung im Kontext von Bereitstellungen und im Kontext von explosivem Lastwachstum führen. Eigentlich haben wir es geschafft. Hier nochmal eine kleine Bemerkung ...
Von diesen vier Problemen sind einige sofort gelöst, wenn Sie eine Wolke haben. Wenn Sie sich in den Microsoft Azhur, Ozone Clouds befinden und unsere Clouds von Yandex oder Mail verwenden, wird zumindest eine Hardwarefehlfunktion zu ihrem Problem, und im Kontext einer Hardwarefehlfunktion wird sofort alles zum Guten.
Wir sind ein kleines Unternehmen, das nicht dem Standard entspricht. Hier spricht jeder von Kubernets, von Wolken - wir haben weder Kubernets noch Wolken. Aber wir haben in vielen Rechenzentren Racks mit Eisen, und wir sind gezwungen, von diesem Eisen zu leben, wir sind gezwungen, für alles zu antworten. Deshalb werden wir uns in diesem Zusammenhang unterhalten. Also, über die Probleme. Die ersten beiden sind nicht in Klammern.
Softwareversion ändern. Grundlagen
Unsere Entwickler haben keinen Zugang zur Produktion. Warum so? Wir sind jedoch einfach von PCI DSS zertifiziert, und unsere Entwickler haben einfach nicht das Recht, in die "Prod" zu steigen. Das war's, Punkt. Absolut. Daher endet die Entwicklungsverantwortung genau zu dem Zeitpunkt, an dem die Entwicklung den Build an das Release übergeben hat.

Unsere zweite Basis, die wir haben und die uns auch sehr hilft, ist der Mangel an einzigartigem, undokumentiertem Wissen. Ich hoffe du machst das selbe. Denn wenn dies nicht der Fall ist, werden Sie Probleme haben. Probleme entstehen, wenn dieses einzigartige, undokumentierte Wissen nicht zur richtigen Zeit am richtigen Ort vorhanden ist. Angenommen, Sie haben eine Person, die weiß, wie man eine bestimmte Komponente einsetzt - es gibt keine Person, sie ist im Urlaub oder sie wurde krank - das ist alles, Sie haben Probleme.
Und die dritte Basis, zu der wir gekommen sind. Wir sind durch Schmerz, Blut und Tränen zu ihm gekommen - wir sind zu dem Schluss gekommen, dass jeder unserer Builds Fehler enthält, auch wenn er fehlerfrei ist. Wir haben das für uns selbst entschieden: Wenn wir etwas bereitstellen, wenn wir etwas in das Produkt rollen, haben wir einen Build mit Fehlern. Wir haben uns die Anforderungen gebildet, die unser System erfüllen muss.
Softwareversions-Änderungsanforderungen
Es gibt drei dieser Anforderungen:

- Wir müssen die Bereitstellung schnell zurücksetzen.
- Wir müssen die Auswirkungen einer nicht erfolgreichen Bereitstellung minimieren.
- Und wir müssen in der Lage sein, schnell parallel zu bleiben.
In dieser Reihenfolge! Warum? Denn vor allem bei der Bereitstellung der neuen Version ist die Geschwindigkeit unwichtig, aber es ist wichtig, dass Sie bei einem Fehler schnell ein Rollback durchführen und minimale Auswirkungen haben. Wenn Sie jedoch eine Reihe von Versionen in der Produktion haben, für die sich herausstellte, dass ein Fehler vorliegt (wie bei Schnee auf Ihrem Kopf gab es keine Bereitstellung, aber der Fehler ist enthalten), ist die Geschwindigkeit der nachfolgenden Bereitstellung für Sie wichtig. Was haben wir getan, um diese Anforderungen zu erfüllen? Wir haben auf eine solche Methodik zurückgegriffen:
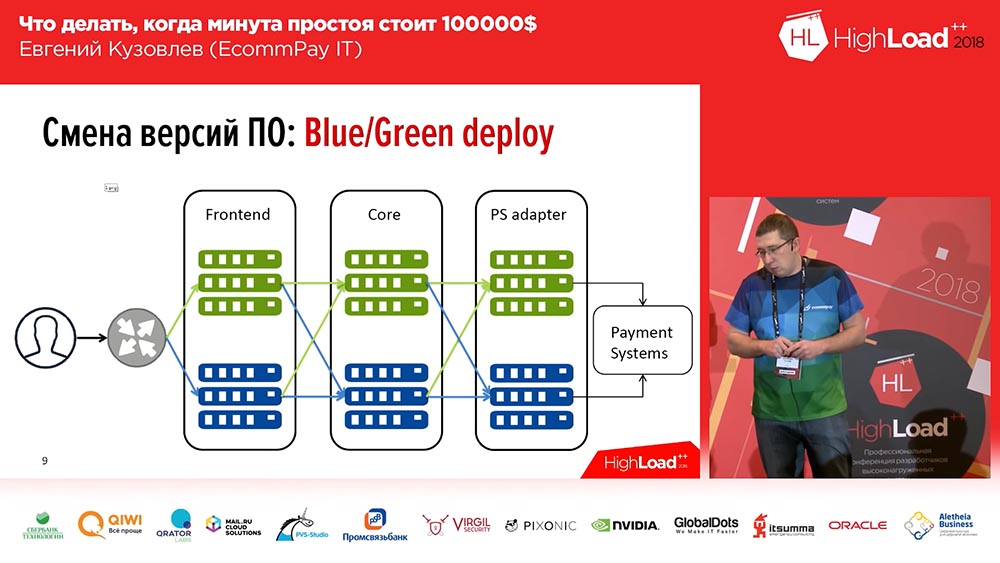
Es ist bekannt, dass wir nicht einmal erfunden haben - das ist Blue / Green Deploy. Was ist das? Sie benötigen eine Kopie für jede Servergruppe, auf der Ihre Anwendungen installiert sind. Die Kopie ist "warm": Es ist kein Datenverkehr vorhanden, dieser Datenverkehr kann jedoch jederzeit an diese Kopie gesendet werden. Diese Kopie enthält die vorherige Version. Und zum Zeitpunkt der Bereitstellung rollen Sie den Code in eine inaktive Kopie aus. Schalten Sie dann einen Teil des Datenverkehrs (oder alles) auf die neue Version um. Um den Verkehrsfluss von der alten auf die neue Version zu ändern, müssen Sie nur eine Aktion ausführen: Sie müssen den Balancer im Upstream ändern, die Richtung ändern - von einem Upstream zum anderen. Dies ist sehr praktisch und löst das Problem des schnellen Umschaltens und schnellen Rollbacks.
Hier lautet die Lösung für die zweite Frage Minimierung: Sie können nur einen Teil Ihres Datenverkehrs in eine neue Zeile mit einem neuen Code einfügen (beispielsweise 2%). Und diese 2% - sie sind nicht 100%! Wenn Sie während einer nicht erfolgreichen Bereitstellung 100% des Datenverkehrs verloren haben - dies ist beängstigend, wenn Sie 2% des Datenverkehrs verloren haben - ist dies unangenehm, aber es ist nicht beängstigend. Darüber hinaus werden Benutzer dies höchstwahrscheinlich nicht einmal bemerken, da in einigen Fällen (nicht allen) derselbe Benutzer durch Drücken von F5 zu einer anderen Arbeitsversion weitergeleitet wird.
Blau / Grün entfalten. Routing
Darüber hinaus ist nicht alles so einfach „Blue / Green Deploy“ ... Alle unsere Komponenten können in drei Gruppen unterteilt werden:
- Dies ist das Frontend (Zahlungsseiten, die unsere Kunden sehen);
- Verarbeitungskern;
- ein Adapter für die Arbeit mit Zahlungssystemen (Banken, MasterCard, Visa ...).
Und es gibt eine Nuance - die Nuance ist das Routing zwischen den Zeilen. Wenn Sie einfach 100% des Datenverkehrs schalten, haben Sie diese Probleme nicht. Wenn Sie jedoch 2% wechseln möchten, beginnen die Fragen: „Wie geht das?“ Das Einfachste auf der Stirn: Sie können Round Robin in Nginx nach dem Zufallsprinzip auswählen und haben 2% übrig, 98%. - nach rechts. Das ist aber nicht immer passend.
Hier interagiert der Benutzer beispielsweise in mehr als einer Anforderung mit dem System. Dies ist normal: 2, 3, 4, 5 Abfragen - Ihre Systeme sind möglicherweise identisch. Und wenn es für Sie wichtig ist, dass alle Benutzeranforderungen in die gleiche Zeile wie die erste Anforderung eingehen, oder (im zweiten Moment) alle Benutzeranforderungen nach dem Wechsel in eine neue Zeile eingehen (er könnte vor dem Wechsel früher mit dem System arbeiten), - dann passt diese zufällige Verteilung nicht zu dir. Dann gibt es folgende Möglichkeiten:

Die erste Option, die einfachste - basierend auf den Grundparametern des Clients (IP Hash). Sie haben eine IP und teilen diese von rechts nach links. Dann funktioniert der zweite von mir beschriebene Fall für Sie, wenn eine Bereitstellung stattgefunden hat, der Benutzer bereits mit Ihrem System arbeiten konnte und ab dem Zeitpunkt der Bereitstellung werden alle Anforderungen an eine neue Zeile weitergeleitet (z. B. an dieselbe).
Wenn dies aus irgendeinem Grund nicht zu Ihnen passt und Sie Anforderungen an die Leitung senden müssen, an die die primäre, vertraute Anforderung des Benutzers gesendet wurde, haben Sie zwei Möglichkeiten:
Die erste Option: Sie können bezahltes Nginx + nehmen. Es gibt einen Sticky-Session-Mechanismus, der auf erste Anforderung des Benutzers eine Sitzung für den Benutzer freigibt und an einen bestimmten Upstream bindet. Alle nachfolgenden Benutzeranforderungen während der gesamten Sitzungsdauer werden an den Upstream weitergeleitet, an dem die Sitzung eingerichtet wurde.
Das hat uns nicht gepasst, da wir schon Nginx Normal hatten. Nginx + zu wechseln ist nicht so teuer, es war nur ein bisschen schmerzhaft für uns und nicht sehr richtig. Zum Beispiel hat "Sticks Sessions" nicht funktioniert, weil "Sticks Sessions" keine Möglichkeit bieten, auf der Basis von "Eli-or" zu routen. Dort können Sie festlegen, was wir als "Sticky Sessions" bezeichnen, zum Beispiel nach IP oder nach IP und nach Cookie oder nach Post-Parameter, aber "Eli-or" ist dort schon komplizierter.
Daher kamen wir zur vierten Option. Wir haben Nginx auf "Steroide" angewendet (dies ist offen) - dies ist das gleiche Nginx, das zusätzlich das Einfügen von letzten Skripten unterstützt. Sie können ein letztes Skript schreiben, dieses "öffnen", und dieses letzte Skript wird ausgeführt, wenn eine Benutzeranforderung eintrifft.
Und wir haben in der Tat ein solches Skript geschrieben, uns "openrest" gesetzt und in diesem Skript 6 verschiedene Parameter für die Verkettung von "Or" sortiert. Abhängig von der Verfügbarkeit dieses oder jenes Parameters wissen wir, dass der Benutzer zu einer Seite oder zu einer anderen, zu einer Zeile oder zu einer anderen gekommen ist.
Blau / Grün entfalten. Vor- und Nachteile
Natürlich könnten Sie es wahrscheinlich etwas einfacher machen (verwenden Sie die gleichen "Sticky Sessions"), aber wir haben immer noch eine solche Nuance, dass nicht nur der Benutzer mit uns im Rahmen einer Abwicklung einer Transaktion interagiert ... Aber Zahlungssysteme interagieren auch mit uns: Nachdem wir die Transaktion bearbeitet haben (durch Senden einer Anfrage an das Zahlungssystem), erhalten wir einen Rückruf.
Und wenn wir in unserer Schaltung die IP-Adresse des Benutzers in allen Anfragen überspringen und Benutzer basierend auf der IP-Adresse trennen können, werden wir nicht dasselbe "Visa" sagen: "Leute, wir sind so ein Retro-Unternehmen, wir sind ein bisschen international (auf der Website und im Internet) Of Russia) ... Und bitte geben Sie die IP-Adresse des Benutzers in ein zusätzliches Feld ein, Ihr Protokoll ist standardisiert! “ Klares Geschäft, werden sie nicht zustimmen.

Deshalb passte es für uns nicht - wir machten openresty. Dementsprechend haben wir mit dem Routing folgendes erhalten:
Das Blue / Green Deploy hat die Vorteile, über die ich gesprochen habe, und die Nachteile.
Nachteil zwei:
- Sie müssen sich um das Routing kümmern.
- Der zweite Hauptnachteil sind die Kosten.
Sie benötigen doppelt so viele Server, Sie benötigen doppelt so viele Betriebsressourcen, Sie müssen doppelt so viel Aufwand aufwenden, um den gesamten Zoo zu warten.
Zu den Vorteilen gehört übrigens noch etwas, das ich noch nicht erwähnt habe: Sie haben eine Reserve für den Fall einer Ladungserhöhung. Wenn Sie einen explosiven Anstieg der Auslastung verzeichnen und eine große Anzahl von Benutzern auf Sie zugegriffen haben, fügen Sie einfach die zweite Zeile in die 50- bis 50-Verteilung ein - und Sie haben sofort 2 Server in Ihrem Cluster, bis Sie das Problem gelöst haben, dass Sie noch Server haben.
Wie erstelle ich eine schnelle Bereitstellung?
Wir haben darüber gesprochen, wie das Problem der Minimierung und des schnellen Rollbacks gelöst werden kann, aber die Frage bleibt: "Wie kann eine schnelle Bereitstellung erfolgen?"

Hier ist kurz und einfach.
- Sie müssen ein CD-System haben (Continuous Delivery) - ohne es nirgendwo. Wenn Sie einen Server haben, können Sie mit Stiften stecken bleiben. Wir haben natürlich ungefähr anderthalbtausend Server und 1.500 Griffe - wir können eine Abteilung in der Größe dieses Raums einrichten, um sie dann einzusetzen.
- Die Bereitstellung sollte parallel erfolgen. Wenn Sie eine konsistente Bereitstellung haben, ist alles schlecht. Ein Server ist normal, Sie werden den ganzen Tag anderthalbtausend Server bereitstellen.
- Auch dies ist zur Beschleunigung wahrscheinlich nicht mehr erforderlich. Beim Desploey baut man normalerweise das Projekt auf. Haben Sie ein Webprojekt, gibt es einen Front-End-Teil (Sie erstellen dort ein Webpaket, npm sammelt so etwas), und dieser Vorgang ist im Grunde kurzlebig - 5 Minuten, aber diese 5 Minuten können kritisch sein. Daher tun wir dies beispielsweise nicht: Wir haben diese 5 Minuten entfernt und Artefakte bereitgestellt.
Was ist ein Artefakt? Ein Artefakt ist ein zusammengebauter Bau, in dem das gesamte Montageteil bereits fertiggestellt wurde. Wir speichern dieses Artefakt in der Aufbewahrung von Artefakten. Wir haben zwei solcher Speicher gleichzeitig verwendet - es war Nexus und jetzt jFrog Artifactory.) Wir haben den Nexus ursprünglich verwendet, weil wir damit begonnen haben, diesen Ansatz in Java-Anwendungen zu üben (er passte gut dazu). Dann platzieren sie den Teil der von PHP geschriebenen Anwendungen dort; und der Nexus war nicht mehr geeignet, weshalb wir uns für jFrog Artefactory entschieden haben, das fast alles verfälschen kann. Wir sind sogar auf die Tatsache gekommen, dass wir in dieser Speicherung von Artefakten unsere eigenen Binärpakete speichern, die wir für Server sammeln.
Explosives Lastwachstum
Wir sprachen über das Ändern der Softwareversion. Das nächste, was wir haben, ist explosives Lastwachstum. Hier verstehe ich wohl, dass das explosive Wachsen der Ladung nicht ganz das Richtige ist ...
Wir haben ein neues System geschrieben - es ist serviceorientiert, modisch schön, überall Arbeiter, überall Warteschlangen, überall Asynchronität. Und in solchen Systemen können Daten unterschiedlich fließen. Bei der ersten Transaktion kann der 1., 3., 10. Mitarbeiter beteiligt sein, bei der zweiten Transaktion der 2., 4., 5. Mitarbeiter. Nehmen wir heute an, Sie haben morgens einen Datenstrom, der die ersten drei Worker verwendet, und abends ändert sich der Datenstrom dramatisch, und alle anderen drei Worker werden verwendet.
Und hier stellt sich heraus, dass Sie die Mitarbeiter irgendwie skalieren müssen, Ihre Dienste irgendwie skalieren müssen, aber gleichzeitig das Aufblasen von Ressourcen verhindern müssen.

Wir haben die Anforderungen für uns selbst festgelegt. : Service discovery, – , – . , , . «», «», .
? . 70 . «», «» , , . 100 «», 100 . . , – 24/7 , , , 70 , .
«», IP Scale-Nomad – ScaleNo, : . , : « ?» – , .
, , , , , – , . 3-5 – .

Wie funktioniert es ! : : , – , – , – .
, . 45 – . 2 , ( – , ). – , 5-10 , .
«», , «» . , , – . . № 2 – « ».
. ?
– « ?» ! . ?

!
, , . . , . « ». :

«» «», . «» . «» «» , , – «» «», – «» «» Telegraf.
New Relic. , . , . 1,5 , , : « ». , , . «-» , 15 «-». .
, – Debugger. «», , , «». Was ist das? , 15-30 , « » , .
, ( ) – , . , «» – , «» . – , , , .
?
? ?

- Response time / RPS – . , - .
- .
- .
- .
– «», «» . , - , . – ( ). - 5-10-15 – , ( ).
– :
– 6 , – . – RPS, RTS. – «». «» , - … , .
, – . OpenTracing – , , , ; . OpenTracing- , . , , . , , .

, 3 – . , , 20-30 .
, – .
, , , , . , .

? , : (, «»); , . , , … – -. , : « »?
… -, ( ) , . : – , , ( ). , - . ! . .
, .
, – , , , , , - . , , .

( – ), ELK Stack – . -, , ELK, , ELK. .
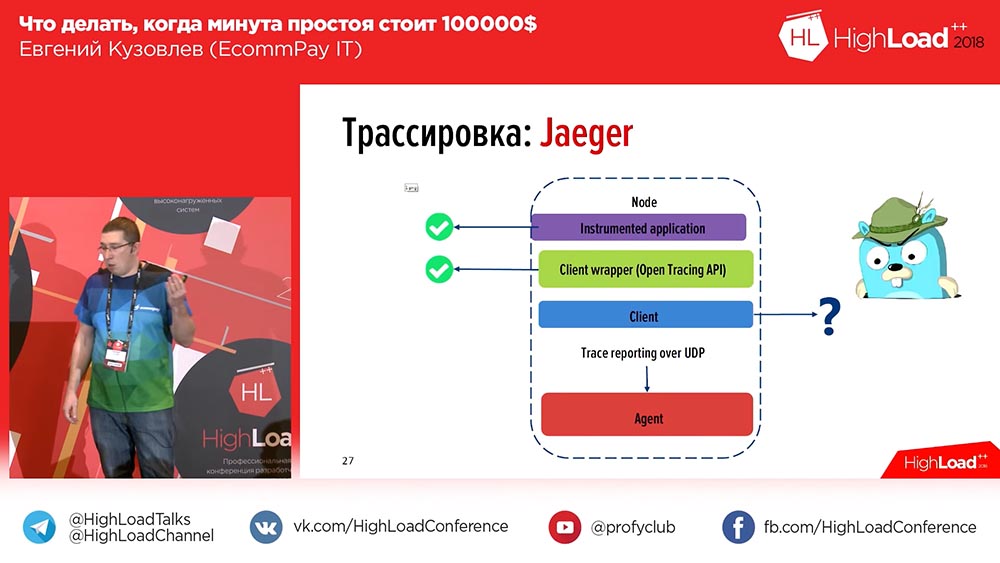
. , , , , «», id- ( ). . Warum? , , . , – OpenTracing, .
, , – «» (Zipkin) «» (Jaeger). «» – , «». «» , , , , . «» .
«»: , Api ( Api PHP , , – , ), . «», – , . ? :
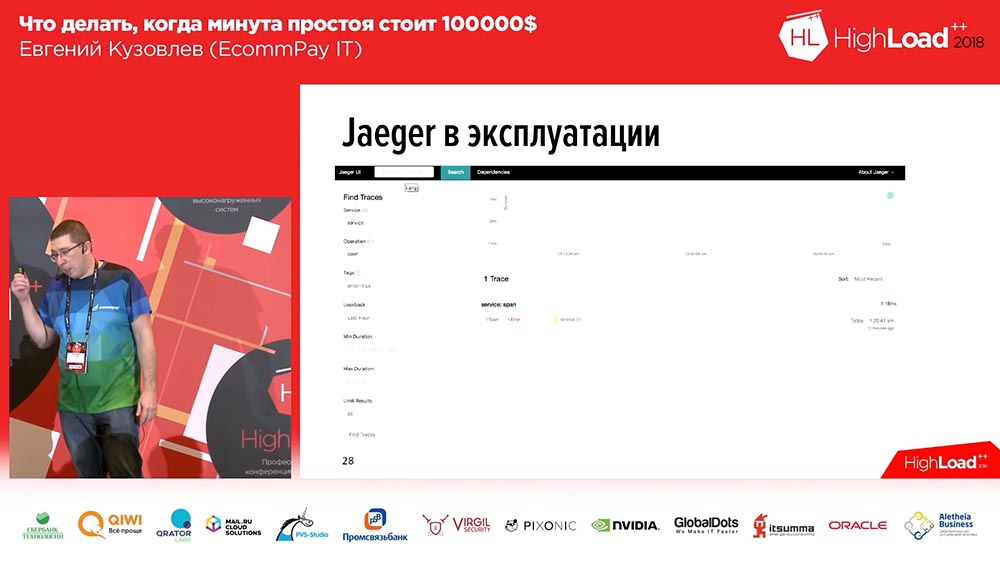
«» span'. , , (1-2-3 – , ). , . , Error. Error , . , span:

. , , . : – , , .
, . , . , «» PHP – , welcome to use, :

– OpenTracing Api, php-extention, . . , . : , extention up to you.
. – . ? :

«»? , ! «» , , , . ?

- . , . 60 , . , , – , .
- . , , RnD-. , (, ) , , .
- , – , . .
- Wir haben Toleranzen. Beispielsweise berücksichtigen wir keine Ausfallzeiten, wenn innerhalb von zwei Minuten 2% des Datenverkehrs verloren gehen. Dies fällt grundsätzlich nicht in unsere Statistik. Wenn mehr in Prozent oder Zeit, zählen wir bereits.
- Und wir schreiben immer post mortem. Was auch immer mit uns passiert, jede Situation, in der es sich am Produktionsstandort unangemessen verhielt, spiegelt sich im Potsortem wider. Ein Post-Mortem ist ein Dokument, in dem Sie aufschreiben, was mit Ihnen geschehen ist, den genauen Zeitpunkt, zu dem Sie das Problem behoben haben, und (dies ist ein obligatorischer Block!), Wie Sie verhindern, dass dies in Zukunft geschieht. Dies ist für die nachfolgende Analyse notwendig.
Was sind Ausfallzeiten zu beachten?

Was hat das alles gebracht?
Dies führte dazu, dass unser Stabilitätsindikator in den letzten 6 Monaten (wir hatten bestimmte Stabilitätsprobleme, dies passte weder unseren Kunden noch uns) 99,97 betrug. Wir können sagen, dass dies nicht sehr viel ist. Ja, wir haben etwas anzustreben. Etwa die Hälfte dieses Indikators ist sozusagen die Stabilität, nicht unsere, sondern unsere Webanwendungs-Firewall, die vor uns steht und als Service verwendet wird, für Kunden jedoch keine Rolle spielt.
Wir lernten nachts zu schlafen. Endlich! Vor sechs Monaten wussten wir nicht wie. Und zu diesem Ergebnis möchte ich noch eine Bemerkung machen. Letzte Nacht gab es einen wunderbaren Bericht über ein Kontrollsystem für Kernreaktoren. Wenn Leute, die dieses System geschrieben haben, mich hören, vergessen Sie bitte, was ich zu „2% ist keine Ausfallzeit“ gesagt habe. 2% sind für Sie Ausfallzeiten, auch wenn Sie zwei Minuten Zeit haben "!
Das ist alles! Deine Fragen.

Informationen zu Balancern und zur Datenbankmigration
Frage des Publikums (im Folgenden - B): - Guten Abend. Vielen Dank für einen solchen Admin-Bericht! Die Frage ist kurz zum Thema Ihrer Balancer. Sie haben erwähnt, dass Sie WAF haben, das heißt, wie ich es verstehe, Sie verwenden eine Art externen Balancer ...
: - Nein, wir nutzen unsere Dienste als Balancer. In diesem Fall ist WAF für uns ausschließlich ein DDoS-Schutztool.
F: - Könnten Sie ein paar Worte zu Balancern sagen?
EK: - Wie gesagt, das ist eine Gruppe von Servern in openresty. Wir haben jetzt 5 Gruppen von redundanten, die ausschließlich antworten ... das heißt, ein Server, auf dem ausschließlich OpenResty ausgeführt wird und der nur den Datenverkehr überwacht. Um zu verstehen, wie viel wir halten: Wir haben jetzt einen regelmäßigen Verkehrsfluss - das sind mehrere hundert Megabits. Sie schaffen es, sie fühlen sich gut, sie belasten nicht einmal.
F: - Auch eine einfache Frage. Es gibt eine blau / grüne Bereitstellung. Und was machen Sie zum Beispiel mit Migrationen aus der Datenbank?
EK: - Gute Frage! Schauen Sie, wir in der blau / grünen Bereitstellung haben separate Zeilen für jede Zeile. Das heißt, wenn wir über die Ereignislinien sprechen, die vom Arbeiter zum Arbeiter übertragen werden, gibt es separate Linien für die blaue Linie und die grüne Linie. Wenn wir über die Datenbank selbst sprechen, haben wir sie absichtlich eingegrenzt, da wir alles fast in eine Linie bringen könnten, wir haben nur einen Stapel von Transaktionen in der Datenbank. Und wir haben einen einzigen Transaktionsstapel für alle Zeilen. Bei einer Datenbank in diesem Kontext: Wir geben sie nicht für Blau und Grün frei, da beide Versionen des Codes wissen sollten, was mit der Transaktion geschieht.
Freunde, ich habe immer noch einen so kleinen Preis, der Sie anspornt - ein Buch. Und ich muss sie für die beste Frage geben.
F: - Hallo. Danke für den Bericht. Die Frage ist das. Sie überwachen Zahlungen, Sie überwachen Dienste, mit denen Sie kommunizieren ... Aber wie überwachen Sie, dass eine Person auf Ihre Zahlungsseite gelangt ist, eine Zahlung geleistet hat und das Projekt ihr Geld gutgeschrieben hat? Das heißt, wie können Sie überwachen, ob der Händler verfügbar ist, und Ihren Rückruf annehmen?
: - "Händler" ist für uns in diesem Fall genau die gleiche externe Dienstleistung wie das Zahlungssystem. Wir überwachen die Reaktionsgeschwindigkeit des "Kaufmanns".
Informationen zur Datenbankverschlüsselung
F: - Hallo. Ich habe eine kleine Frage. Sie haben vertrauliche PCI-DSS-Daten. Ich wollte wissen, wie Sie PANs in Warteschlangen speichern, in die Sie werfen müssen? Verwenden Sie eine Verschlüsselung? Und ab hier stellt sich die folgende zweite Frage: Auf PCI DSS muss die Datenbank bei Änderungen (Entlassung von Administratoren usw.) regelmäßig neu verschlüsselt werden - wie geschieht dies mit der Barrierefreiheit?

EK: - Wunderbare Frage! Erstens speichern wir keine PANs in den Warteschlangen. Wir haben grundsätzlich kein Recht, PAN im Klartext zu speichern. Daher verwenden wir einen speziellen Dienst (wir nennen ihn „Kademon“) - dies ist ein Dienst, der nur eines tut: Er empfängt eine Nachricht und sendet eine verschlüsselte Nachricht. Und wir speichern alles mit dieser verschlüsselten Nachricht. Dementsprechend liegt die Schlüssellänge für uns unter Kilobyte, so dass es direkt seriös und zuverlässig ist.
F: - Benötigen Sie jetzt 2 Kilobyte?
EK: - Es scheint, als wäre es gestern 256 gewesen ... Nun, wo sonst ?!
Dementsprechend ist dies der erste. Und zweitens unterstützt die vorhandene Lösung den Prozess der Neuverschlüsselung - es gibt zwei Paare von "Cakes" (Schlüsseln), die "Decks" zum Verschlüsseln geben (Schlüssel sind Schlüssel, dek sind Derivate von Schlüsseln, die verschlüsseln). Und im Falle der Einleitung des Verfahrens (es findet regelmäßig von 3 Monaten bis ± einigen Monaten statt) laden wir ein neues Paar „Kuchen“ hoch und lassen die Daten neu verschlüsseln. Wir haben separate Dienste, die alle Daten herausreißen und auf neue Weise verschlüsseln. Die Daten werden neben der Schlüsselkennung gespeichert, mit der sie verschlüsselt sind. Dementsprechend löschen wir den alten Schlüssel, sobald wir Daten mit neuen Schlüsseln verschlüsselt haben.
Manchmal müssen Sie manuell bezahlen ...
F: - Das heißt, wenn für eine Operation eine Rückgabe erfolgt ist, wird diese mit dem alten Schlüssel entschlüsselt?
EG: - Ja.
F: - Dann noch eine kleine Frage. Bei einem Ausfall, Sturz oder Vorfall muss die Transaktion im manuellen Modus verschoben werden. Es gibt so eine Situation.
EK: - Ja, das tut es.
F: - Woher bekommen Sie diese Daten? Oder gehst du selbst mit Stiften in diesen Laden?
EK: - Nein, natürlich - wir haben eine Art Backoffice-System, das eine Schnittstelle für unseren Support enthält. Wenn wir nicht wissen, in welchem Status sich die Transaktion befindet (z. B., obwohl das Zahlungssystem nicht mit einer Zeitüberschreitung geantwortet hat), wissen wir nicht von vornherein, dh, wir weisen den endgültigen Status nur mit vollem Vertrauen zu. In diesem Fall geben wir die Transaktion für die manuelle Verarbeitung in einen Sonderstatus. Sobald der Support morgens am nächsten Tag die Information erhält, dass solche Transaktionen im Zahlungssystem verbleiben, werden sie manuell in dieser Schnittstelle verarbeitet.

F: - Ich habe ein paar Fragen. Eine davon ist die Fortsetzung der PCI-DSS-Zone: Wie erhalten Sie ihre Loop-Protokolle? Eine solche Frage, weil der Entwickler alles in die Protokolle setzen könnte! Zweite Frage: Wie rollen Sie Hotfixes aus? Stifte in der Datenbank sind eine Option, aber möglicherweise gibt es kostenlose Hotfixes - wie wird dort vorgegangen? Und die dritte Frage bezieht sich wahrscheinlich auf RTO, RPO. Ihre Verfügbarkeit betrug 99,97, fast vier Neunen, aber meines Wissens haben Sie ein zweites Rechenzentrum, ein drittes Rechenzentrum und ein fünftes Rechenzentrum ... Wie gehen Sie mit ihrer Synchronisation, Replikation und allem anderen um?
EK: - Fangen wir mit dem ersten an. Die erste Frage zu den Protokollen war? Wenn wir Protokolle schreiben, haben wir eine Ebene, die alle vertraulichen Daten maskiert. Sie schaut auf die Maske und die Zusatzfelder. Dementsprechend werden unsere Protokolle mit bereits maskierten Daten und einer PCI-DSS-Schleife ausgegeben. Dies ist eine der regulären Aufgaben, die der Testabteilung zugewiesen sind. Sie sind verpflichtet, jede Aufgabe, einschließlich der von ihnen erstellten Protokolle, zu überprüfen. Dies ist eine der regulären Aufgaben bei der Codeüberprüfung, um zu überprüfen, ob der Entwickler etwas nicht geschrieben hat. Die spätere Überprüfung erfolgt regelmäßig durch die Informationssicherheitsabteilung etwa einmal pro Woche: Protokolle werden selektiv für den letzten Tag erstellt und von Testservern durch einen speziellen Scanner-Analysator geführt, um dies zu überprüfen.
Über Hotfixes. Dies ist in unserem Bereitstellungsplan enthalten. Wir haben einen separaten Punkt über Hotfixes. Wir glauben, dass wir Hotfixes rund um die Uhr bereitstellen, wenn wir sie benötigen. Sobald die Version zusammengestellt ist, sobald sie ausgeführt wird und sobald wir das Artefakt haben, rufen wir den Systemadministrator vom Support an und er wird es in dem Moment bereitstellen, in dem es notwendig ist.
Über die "vier Neunen". Die Nummer, die wir jetzt haben, wurde tatsächlich erreicht und wir haben sie in einem anderen Rechenzentrum gesucht. Jetzt haben wir ein zweites Rechenzentrum, und wir beginnen, zwischen ihnen zu routen, und die Frage des datenübergreifenden Replikationszentrums ist wirklich eine nicht triviale Frage. Wir haben versucht, es mit verschiedenen Mitteln rechtzeitig zu lösen: Wir haben versucht, dieselbe "Tarantel" zu verwenden - es hat bei uns nicht funktioniert, sage ich gleich. Daher kamen wir zu der Tatsache, dass wir die Reihenfolge der "Sensation" manuell vornehmen. Wir haben jede Anwendung tatsächlich im asynchronen Modus der notwendigen Synchronisation "change - done" - Laufwerke zwischen Rechenzentren.
F: - Wenn Sie eine zweite haben, warum nicht eine dritte? Weil noch niemand ein gespaltenes Gehirn hat ...
: - Und wir haben kein gespaltenes Gehirn. Da jede Anwendung einen Multimaster steuert, spielt es für uns keine Rolle, an welches Zentrum die Anfrage gerichtet wurde. Wir sind bereit für die Tatsache, dass wir im Falle eines Absturzes eines Rechenzentrums (wir legen darauf) und mitten in einer Benutzeranforderung, die auf ein zweites Rechenzentrum umgestellt wird, bereit sind, diesen Benutzer wirklich zu verlieren. aber es werden Einheiten sein, absolute Einheiten.
F: - Guten Abend. Danke für den Bericht. Sie haben über Ihren Debugger gesprochen, der einige Testtransaktionen in der Produktion steuert. Erzählen Sie uns doch etwas über Testtransaktionen! Wie tief geht es?
EG: - Es durchläuft den gesamten Zyklus des gesamten Bauteils. Es gibt keine Unterschiede zwischen der Testtransaktion und der Kampftransaktion für die Komponente. Und aus logischer Sicht handelt es sich nur um ein separates Projekt im System, bei dem nur Testtransaktionen verfolgt werden.
F: - Und wo schneidest du es ab? Also schickte Core ...
: - Wir stehen in diesem Fall für Testtransaktionen hinter "Kor" ... Wir haben so etwas wie Routing: "Kor" weiß, an welches Zahlungssystem gesendet werden soll - wir senden an ein gefälschtes Zahlungssystem, das einfach eine http-Antwort gibt und das ist alles .
F: - Bitte sagen Sie mir, hatten Sie den Antrag in einem großen Monolithen geschrieben oder haben Sie ihn auf einige Dienste oder sogar Mikrodienste zugeschnitten?
: - Wir haben keinen Monolithen, natürlich haben wir eine serviceorientierte Anwendung. Wir haben einen Witz, dass wir einen Service von Monolithen haben - sie sind wirklich ziemlich groß. Das Aufrufen von Microservices in dieser Sprache ändert nichts am Wort, aber dies sind die Services, in denen verteilte Maschinenarbeiter arbeiten.
Wenn der Dienst auf dem Server beeinträchtigt ist ...
F: - Dann habe ich folgende Frage. Selbst wenn es sich um einen Monolithen handelte, sagten Sie immer noch, dass Sie viele dieser Instant-Server haben, alle verarbeiten die Daten im Prinzip und die Frage lautet: „Wenn einer der Instant-Server oder die Anwendung kompromittiert ist, ist eine bestimmte Verbindung gefährdet Haben sie irgendeine Art von Zugangskontrolle? Welcher von ihnen kann was? An wen kann man sich wenden, für welche Daten?

EK: - Ja natürlich. Die Sicherheitsanforderungen sind sehr ernst. Erstens haben wir offenen Datenverkehr, und die Häfen sind nur die, auf denen wir den Verkehr im Voraus antizipieren. Wenn die Komponente über 5-4-3-2 mit der Datenbank kommuniziert (z. B. "Muskul"), sind nur 5-4-3-2 und andere Ports für diese geöffnet. Andere Verkehrsrichtungen sind nicht verfügbar. Außerdem müssen wir verstehen, dass wir in der Produktion ungefähr 10 verschiedene Sicherheitsschleifen haben. Und selbst wenn die Anwendung auf irgendeine Weise kompromittiert wurde, kann ein Angreifer nicht auf die Serververwaltungskonsole zugreifen, da dies eine weitere Netzwerksicherheitszone ist.
F: - Und in diesem Zusammenhang interessiert es mich mehr, wenn Sie Verträge mit Dienstleistungen abgeschlossen haben - was können sie tun, über welche „Aktionen“ sie miteinander in Kontakt treten können ... Und im normalen Ablauf fragen einige bestimmte Dienstleistungen welche eine Reihe, eine Liste von "Aktion" auf einem anderen. Sie scheinen sich in einer normalen Situation nicht an andere zu wenden, und sie haben andere Verantwortungsbereiche. Wenn einer von ihnen kompromittiert ist, kann er dann die "Aktion" dieses Dienstes ausführen?
EK: - Ich verstehe. Wenn im Normalfall mit einem anderen Server die Kommunikation generell erlaubt war, dann ja. Im Rahmen des SLA-Vertrags wird nicht überwacht, dass Ihnen nur die ersten 3 "Aktionen" und 4 "Aktionen" nicht gestattet sind. Dies ist für uns wahrscheinlich überflüssig, da wir im Prinzip ein 4-stufiges Schutzsystem für Stromkreise haben. Wir verteidigen lieber mit Konturen als auf der Ebene der Innenseiten.
So funktionieren Visa, MasterCard und Sberbank
F: - Ich möchte kurz erläutern, wie ein Benutzer von einem Rechenzentrum zu einem anderen gewechselt wird. Soweit ich weiß, arbeiten "Visa" und "MasterCard" mit dem binären Synchronprotokoll 8583, es gibt Mischungen. Und ich wollte wissen, jetzt meine ich Umstellung - geht es direkt um "Visa" und "MasterCard" oder um Zahlungssysteme, um Abwicklungen?
EK: - Es liegt an den Mischungen. Mixe haben wir in einem Rechenzentrum.
F: - Haben Sie grob gesagt einen Verbindungspunkt?
: - "Vise" und "MasterCard" - ja. Nur weil „Visa“ und „MasterCard“ ernsthafte Investitionen in die Infrastruktur erfordern, um separate Verträge abzuschließen und beispielsweise ein zweites Mix-Paar zu erhalten. Sie sind im Rahmen eines Rechenzentrums reserviert, aber wenn, Gott bewahre, das Rechenzentrum, in dem die Mischungen für die Verbindung mit "Visa" und "MasterCard" tot sind, dann haben wir eine Verbindung mit "Visa" und "MasterCard" verloren ...
F: - Wie können sie reserviert werden? Ich weiß, dass "Visa" grundsätzlich nur eine Verbindung zulässt!
EK: - Sie selbst liefern Ausrüstung. In jedem Fall haben wir Geräte erhalten, die intern redundant sind.
F: - Das heißt, das Rack von Connects Orange? ..
EG: - Ja.
F: - Aber wie in diesem Fall: Wenn Ihr Rechenzentrum verschwindet, sollten Sie es weiter verwenden? Oder hört der Verkehr einfach auf?
EG: - Nein. In diesem Fall schalten wir den Verkehr einfach auf einen anderen Kanal um, was für uns natürlich teurer und für die Kunden teurer wird. Der Verkehr wird aber nicht über unsere direkte Verbindung zum "Visa", "MasterCard", sondern über die herkömmliche "Sberbank" (sehr übertrieben) geführt.
Es tut mir sehr leid, wenn ich Sberbank-Mitarbeiter verletzt habe. Laut unserer Statistik fällt die Sberbank jedoch am häufigsten von russischen Banken ab. In weniger als einem Monat ist bei der Sberbank nichts abgefallen.

Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Mögen Sie unsere Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder Ihren Freunden Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen, ein einzigartiges Analogon zu Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 Dollar oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2-mal billiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben 2 x Intel TetraDeca-Core Xeon 2 x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV ab 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über das Erstellen von Infrastruktur-Bldg. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?