Wir beschäftigen uns weiterhin mit der Arbeit von GraalVM und dieses Mal haben wir eine Übersetzung des Artikels von Aleksandar Prokopec "Unter der Haube von GraalVM JIT-Optimierungen", der ursprünglich im Blog auf Medium veröffentlicht wurde . Der Artikel enthält einige interessante Links. Später werden wir versuchen, diese Artikel ebenfalls zu übersetzen.

Das letzte Mal bei Medium haben wir uns mit Java Streams API-Leistungsproblemen bei GraalVM verglichen mit Java HotSpot VM befasst. GraalVM zeichnet sich durch hohe Leistung aus, und in diesen Experimenten haben wir eine Beschleunigung von 1,7 auf das 5-fache erreicht. Die spezifischen Werte für die Leistungssteigerung hängen natürlich immer vom ausgeführten Code und den Ladedaten ab. Bevor Sie also eine Schlussfolgerung ziehen, sollten Sie versuchen, Ihren Code auf GraalVM selbst auszuführen.
In diesem Artikel werden wir uns eingehender mit GraalVM befassen und sehen, wie die JIT-Kompilierung abläuft.
JIT-Optimierungen in GraalVM
Schauen wir uns einige allgemeine Optimierungen an, die der GraalVM-Compiler verwendet. In diesem Artikel werden wir nur die interessantesten Optimierungen zusammen mit spezifischen Beispielen ihrer Arbeit ansprechen. Ein guter Überblick über die Optimierungen des GraalVM-Compilers finden Sie in der Arbeit „Optimale Erfassungsvorgänge durch aggressive JIT-Kompilierung“ .
Inlining
Wenn Sie die Assembly nicht vorzeitig berühren, führen die meisten JIT-Compiler in modernen virtuellen Maschinen eine interne Analyse durch. Dies bedeutet, dass zu jedem bestimmten Zeitpunkt eine Analyse einer Methode vorliegt. Aus diesem Grund ist die intraprocedurale Analyse viel schneller als die interprocedurale Analyse des gesamten Programms, für die in der für die Arbeit des JIT-Compilers vorgesehenen Zeit normalerweise keine Zeit zur Verfügung steht. In einem Compiler, der prozedurale Optimierungen verwendet (z. B. jeweils eine Methode optimieren), ist Inlining eine der wichtigsten grundlegenden Optimierungen. Inlining ist wichtig, da es die Methode effektiv erhöht, was bedeutet, dass der Compiler mehr Möglichkeiten zur gleichzeitigen Optimierung mehrerer Codeteile sieht, die in scheinbar nicht verwandten Methoden verwendet werden.
Nehmen Sie zum Beispiel die volleyballStars Methode aus einem vorherigen Artikel:
@Benchmark public double volleyballStars() { return Arrays.stream(people) .map(p -> new Person(p.hair, p.age + 1, p.height)) .filter(p -> p.height > 198) .filter(p -> p.age >= 18 && p.age <= 21) .mapToInt(p -> p.age) .average().getAsDouble(); }
In diesem Diagramm sehen wir Teile der Intermediate Representation (IR) dieser Methode in GraalVM, unmittelbar nach dem Parsen des entsprechenden Java-Bytecodes.

Sie können sich diese IR als eine Art abstrakten Syntaxbaum für Steroide vorstellen - dank ihr sind einige Optimierungen einfacher durchzuführen. Es spielt keine Rolle, wie diese IR funktioniert, aber wenn Sie dieses Thema genauer verstehen möchten, können Sie sich ein Dokument mit dem Titel "Graal IR: Eine erweiterbare deklarative Zwischendarstellung" ansehen.
Die Hauptschlussfolgerung hier ist, dass der Steuerfluss der Methode, der durch die gelben Knoten des Diagramms und die roten Linien angegeben wird, die Methoden der Stream Schnittstelle sequentiell ausführt: Stream.filter , Stream.mapToInt , IntStream.average . Der Compiler ist nicht in der Lage, die Methode zu vereinfachen, da er nicht genau weiß, was im Code dieser Methoden enthalten ist - und hier hilft Inlining!
Eine Transformation namens Inlining ist sehr verständlich: Sie sucht nur nach Orten, an denen Methoden aufgerufen werden, ersetzt diese durch den Text der entsprechenden Inline-Methode und bettet sie ein. Schauen wir uns das IR der volleyballStars Methode an, nachdem wir einen Teil der Methoden eingefügt haben. Hier wird nur der Teil IntStream.average , der auf den IntStream.average Aufruf folgt:

Das Diagramm zeigt, dass der Aufruf von getAsDouble (Knotennummer 71) aus dem IR verschwunden ist. Beachten Sie, dass die getAsDouble Methode des von IntStream.average (dem letzten Aufruf der volleyballStars Methode) zurückgegebenen getAsDouble Objekts im JDK wie folgt definiert ist:
public double getAsDouble() { if (!isPresent) { throw new NoSuchElementException("No value present"); } return value; }
Hier finden wir das Laden des isPresent Feldes (Knotennummer 190, LoadField ) und das Lesen des LoadField . Von der NoSuchElementException Ausnahme ist jedoch keine Spur mehr NoSuchElementException , und es gibt keinen Code mehr, der sie NoSuchElementException .
Dies liegt daran, dass der GraalVM-Compiler vermutet, dass die volleyballStars Methode niemals eine Ausnahme auslöst. Dieses Wissen ist normalerweise während der getAsDouble Kompilierung nicht verfügbar - es kann von vielen verschiedenen Stellen im Programm aufgerufen werden, und in anderen Fällen funktioniert die Ausnahme weiterhin. Bei einer bestimmten volleyballStars Methode ist es jedoch unwahrscheinlich, dass eine Ausnahme auftritt, da die Menge der potenziellen Volleyballsterne niemals leer ist. Aus diesem Grund entfernt GraalVM die Verzweigung und fügt FixedGuard - einen Knoten, der den Code im Falle eines Verstoßes gegen unsere Annahme FixedGuard . Dies ist ein ziemlich minimalistisches Beispiel, und im wirklichen Leben gibt es viel kompliziertere Fälle, in denen Inlining anderen Optimierungen hilft.
Wir wissen, dass der Programmaufrufbaum normalerweise sehr tief oder sogar endlos ist. Das Inlining muss also irgendwann gestoppt werden - es unterliegt ganz bestimmten Einschränkungen in Bezug auf Betriebszeit und Speichergröße. Wenn man das weiß, wird klar: Es ist sehr schwierig zu bestimmen, was und wann inline zu stellen ist.
Polymorphes Inlining
Inlining funktioniert nur, wenn der Compiler die bestimmte Methode ermitteln kann, auf die sich die Methodenaufrufoperation bezieht. In Java gibt es jedoch in der Regel viele indirekte Aufrufe für Methoden, deren Implementierungen in der Statik unbekannt sind und die zur Laufzeit mithilfe von Virtual Dispatch durchsucht werden.
Nehmen Sie zum Beispiel die IntStream.average Methode. Die typische Implementierung sieht folgendermaßen aus:
@Override public final OptionalDouble average() { long[] avg = collect( () -> new long[2], (ll, i) -> { ll[0]++; ll[1] += i; }, (ll, rr) -> { ll[0] += rr[0]; ll[1] += rr[1]; }); return avg[0] > 0 ? OptionalDouble.of((double) avg[1] / avg[0]) : OptionalDouble.empty(); }
Lassen Sie sich nicht von der scheinbaren Einfachheit des Codes täuschen! Diese Methode ist in Bezug auf das collect Anrufen definiert, und die Magie geschieht hier. Der Aufrufbaum dieser Methode (z. B. die Aufrufhierarchie) wächst schnell, je tiefer wir in das collect . Schauen Sie sich einfach dieses Diagramm an:
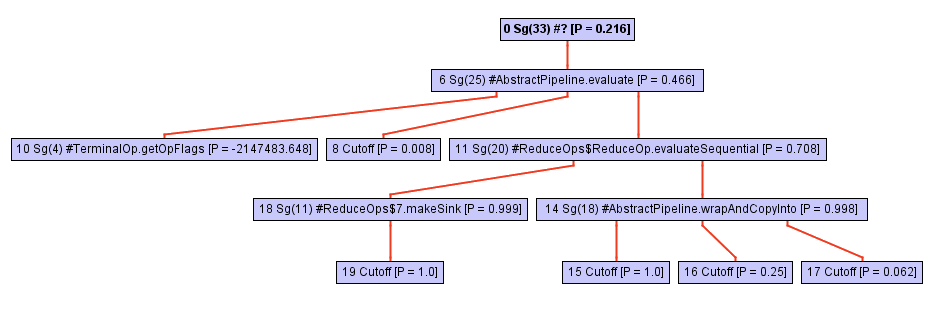
Ab einem bestimmten Zeitpunkt beim Durchlaufen des opWrapSink wird der Inliner mit dem opWrapSink Aufruf aus dem Java- opWrapSink Framework in Verbindung gebracht. opWrapSink ist eine abstrakte Methode:

abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
Normalerweise geht ein Inliner nicht weiter, da es sich um einen indirekten Aufruf handelt. Die Bestimmung einer bestimmten Methode erfolgt nur während der Ausführung des Programms, und jetzt weiß der Inlayner einfach nicht, woran er als nächstes arbeiten soll.
Im Fall von GraalVM passiert noch etwas anderes: Für jeden Peer mit indirekter Wahl wird ein Typprofil der Zielmethode gespeichert. Dieses Profil ist im Wesentlichen nur eine Tabelle, die wrapSink , wie oft die einzelnen wrapSink Implementierungen wrapSink . In unserem Fall kennt das Profil drei verschiedene Implementierungen in anonymen Klassen: ReferencePipeline$2 , ReferencePipeline$3 , ReferencePipeline$4 . Diese Implementierungen werden mit einer Wahrscheinlichkeit von 50%, 25% bzw. 25% aufgerufen.
0.500000: Ljava/util/stream/ReferencePipeline$2; 0.250000: Ljava/util/stream/ReferencePipeline$4; 0.250000: Ljava/util/stream/ReferencePipeline$3; notRecorded: 0.000000
Diese Informationen sind für den Compiler von unschätzbarem Wert. Sie ermöglichen es Ihnen, einen Typwechsel zu generieren - eine kurze switch , die den Typ der Methode zur Laufzeit überprüft und dann für jeden der oben genannten Fälle eine bestimmte Methode aufruft. Das folgende Bild zeigt einen Teil der Zwischenansicht, in der der Typschalter (drei if Knoten) mit einer Überprüfung angezeigt wird, ob der Empfängertyp eine Person aus ReferencePipeline$2 , ReferencePipeline$3 oder ReferencePipeline$4 . Jeder direkte Aufruf in der erfolgreichen Verzweigung jeder der InstanceOf Prüfungen kann jetzt inline erfolgen oder einige zusätzliche Optimierungen damit verbinden. Wenn keiner der Typen den Test besteht, wird der Code im Knoten Deopt deoptimiert (alternativ können Sie den virtuellen Versand ausführen).

Wenn Sie mehr über polymorphes Inlining erfahren möchten, empfehle ich die klassische Arbeit zu diesem Thema, "Inlining von virtuellen Methoden" .
Partielle Fluchtanalyse
Kehren wir zu unserem Volleyball-Beispiel zurück. Beachten Sie, dass keines der im Lambda zugewiesenen Person die an die map dem Geltungsbereich der volleyballStars Methode entgeht. Mit anderen Worten, zum Zeitpunkt des Endes der volleyballStars Methode gibt es keinen Speicherbereich, der auf Objekte vom Typ Person verweisen würde. Insbesondere wird der Datensatz des getHeight Werts nur für die getHeight verwendet.
Irgendwann während der Erstellung der volleyballStars Methode kommen wir zu dem in der folgenden Abbildung gezeigten IR. Der Block, der mit dem Begin Knoten -1621 beginnt, beginnt mit der Zuweisung des Person Objekts (im Alloc Knoten), das sowohl mit dem Wert des Alloc mit einem Inkrement von 1 als auch mit dem vorherigen Wert des height initialisiert wird. Das height zuvor im LoadField -1539-Knoten gelesen. Das Ergebnis der Zuordnung wird in AllocatedObject -2137 gekapselt und an den Methodenaufruf accept -1625 gesendet. Der Compiler kann im Moment nichts mehr tun - aus seiner Sicht ist das Objekt der volleyballStars Methode entkommen. ( Anmerkung des Übersetzers: „Ein Objekt weglaufen lassen“ wird im Englischen als „Escape“ bezeichnet, daher lautet der Name der Optimierung „Escape-Analyse“. )

Danach beschließt der Compiler, den Aufruf accept inline zu setzen - dies scheint sinnvoll. Als Ergebnis kommen wir zu folgendem IR:
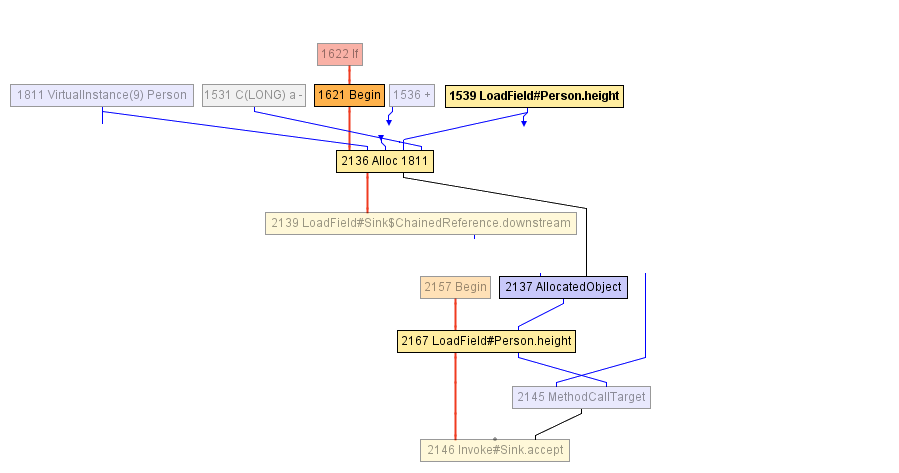
Und hier startet der JIT-Compiler eine partielle Escape-Analyse: Er stellt fest, dass AllocatedObject nur zum Lesen des height wird (Rückruf, height nur unter Filterbedingungen verwendet, prüfen Sie, ob die Höhe größer als 198 ist). Daher kann der Compiler den Wert des Felds height -2167 neu zuweisen, um direkt mit dem Knoten zu arbeiten, der zuvor in das Objekt Person (Knoten Alloc -2136). Dies ist unser LoadField -1539. Darüber hinaus wird der Alloc Knoten nicht an die Eingabe eines anderen Knotens weitergeleitet, sodass Sie ihn einfach löschen können - dies ist toter Code!
Diese Optimierung ist in der Tat der Hauptgrund, warum das volleyballStars Beispiel nach dem Wechsel zu GraalVM eine fünffache Beschleunigung erfahren hat. Auch wenn nicht alle Person benötigt werden und sofort nach der Erstellung verworfen werden, müssen sie dennoch auf dem Heap zugewiesen werden, ihr Speicher muss jedoch noch initialisiert werden. Mithilfe der partiellen Escape-Analyse können Sie Zuweisungen aufheben oder verschieben, indem Sie sie in die Codezweige verschieben, in denen Objekte wirklich weglaufen und die viel seltener vorkommen.
In einem Artikel mit dem Titel Partial Escape Analysis und Scalar Replacement for Java erhalten Sie ein tieferes Verständnis der partiellen Escape-Analyse.
Zusammenfassung
In diesem Artikel haben wir uns drei GraalVM-Optimierungen angesehen: Inlining, polymorphes Inlining und partielle Escape-Analyse. Es gibt noch viele weitere Optimierungen: Heraufstufen und Aufteilen von Zyklen, Duplizieren von Pfaden, Nummerieren von globalen Werten, Faltung von Konstanten, Entfernen von totem Code, spekulative Ausführung und so weiter.
Wenn Sie mehr über die Funktionsweise von GraalVM erfahren möchten, zögern Sie nicht, die Publikationsseite zu öffnen. Wenn Sie sicherstellen möchten, dass GraalVM Ihren Code beschleunigt, können Sie die Binärdateien herunterladen und selbst ausprobieren.
Vom Übersetzer: zusätzliche Materialien
JPoint und Joker sprechen auf Konferenzen häufig über GraalVM. So besuchten uns zuletzt im JPoint 2019 Thomas Würthinger (Research Director bei Oracle Labs, verantwortlich für GraalVM) und Oleg Shelaev, einer der beiden offiziellen Technologieevangelisten.
Sie können diese und andere Videos auf unserem YouTube-Kanal ansehen:
Wir erinnern Sie daran, dass der nächste JPoint vom 15. bis 16. Mai 2020 in Moskau stattfindet und Tickets bereits auf der offiziellen Website gekauft werden können .