Hallo allerseits! Ich bin ein Backend-Entwickler und schreibe Microservices in Java + Spring. Ich arbeite in einem internen Produktentwicklungsteam von Tinkoff.

Unser Team wirft häufig die Frage nach der Abfrageoptimierung im DBMS auf. Sie möchten immer ein bisschen schneller sein, kommen aber mit gut gestalteten Indizes nicht immer zurecht - Sie müssen nach Problemumgehungen suchen. Während eines dieser Surfen im Internet auf der Suche nach sinnvollen Optimierungen bei der Arbeit mit der Datenbank fand ich einen unendlich nützlichen Blog von Marcus Vinand , Autor von SQL Performance Explained. Dies ist die sehr seltene Art von Blog, in dem Sie alle Artikel hintereinander lesen können.
Ich möchte für Sie einen kurzen Artikel von Marcus übersetzen. Es kann bis zu einem gewissen Grad als Manifest bezeichnet werden, das versucht, die Aufmerksamkeit auf das alte, aber immer noch relevante Problem der Leistung der Offset-Operation gemäß dem SQL-Standard zu lenken.
An einigen Stellen werde ich den Autor mit Erläuterungen und Anmerkungen ergänzen. Ich werde alle Stellen der Übersichtlichkeit halber mit "ca." bezeichnen.
Kleine Einführung
Ich denke, viele Leute wissen, wie problematisch und hemmend es ist, mit Paginal Selects durch Offset zu arbeiten. Aber wussten Sie, dass es ganz einfach durch ein produktiveres Design ersetzt werden kann?
Das Schlüsselwort offset weist die Datenbank an, die ersten n Einträge in der Anforderung zu überspringen. Die Datenbank muss diese ersten n Datensätze jedoch noch in der angegebenen Reihenfolge von der Festplatte lesen (Hinweis: Sortierung anwenden, wenn eine angegeben ist). Erst danach können Datensätze ab n + 1 zurückgegeben werden. Das Interessanteste ist, dass das Problem nicht in der konkreten Implementierung im DBMS liegt, sondern in der anfänglichen Definition gemäß der Norm:
... die Zeilen werden zuerst nach der <order by clause> sortiert und dann begrenzt, indem die in der <result offset clause> angegebene Anzahl von Zeilen von Anfang an weggelassen wird ...
-SQL: 2016, Teil 2, 4.15.3 Abgeleitete Tabellen (Anmerkung: jetzt der am häufigsten verwendete Standard)
Der entscheidende Punkt hierbei ist, dass der Offset einen einzigen Parameter benötigt - die Anzahl der zu überspringenden Datensätze - und das ist es. Nach dieser Definition kann ein DBMS nur alle Datensätze abrufen und dann unnötige verwerfen. Offensichtlich zwingt Sie eine solche Definition des Versatzes zu zusätzlicher Arbeit. Dabei spielt es keine Rolle, ob es sich um SQL oder NoSQL handelt.
Noch mehr Schmerz
Offset-Probleme enden nicht hier und hier ist der Grund. Was passiert in diesem Fall, wenn ein anderer Vorgang einen neuen Datensatz zwischen dem Lesen von zwei Datenseiten von der Festplatte einfügt?
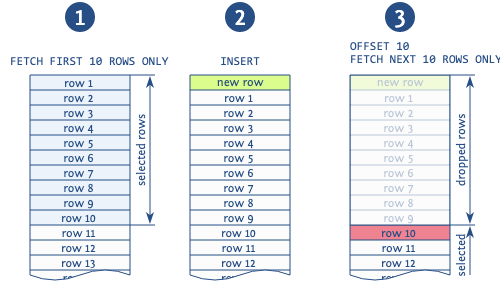
Wenn Offset verwendet wird, um Datensätze von vorherigen Seiten zu überspringen, werden beim Hinzufügen eines neuen Datensatzes zwischen den Vorgängen des Lesens verschiedener Seiten höchstwahrscheinlich Duplikate angezeigt (Hinweis: Dies ist möglich, wenn wir Seite für Seite mit dem Befehl order by construct lesen und dann in der Mitte unserer Ausgabe einen neuen Rekord bekommen).
Die Abbildung zeigt deutlich eine solche Situation. Die Basis liest die ersten 10 Datensätze, woraufhin ein neuer Datensatz eingefügt wird, der alle gelesenen Datensätze um 1 verschiebt. Dann nimmt die Basis eine neue Seite von den nächsten 10 Datensätzen und beginnt nicht ab dem 11., wie es sein sollte, sondern ab dem 10., wobei dieser Datensatz dupliziert wird. Es gibt andere Anomalien, die mit der Verwendung dieses Ausdrucks verbunden sind, aber dies ist die häufigste.
Wie wir bereits herausgefunden haben, handelt es sich hierbei nicht um Probleme eines bestimmten DBMS oder dessen Implementierung. Das Problem besteht darin, die Paginierung gemäß dem SQL-Standard zu bestimmen. Wir teilen dem DBMS mit, welche Seite abgerufen werden soll oder wie viele Datensätze übersprungen werden sollen. Die Basis ist einfach nicht in der Lage, eine solche Anfrage zu optimieren, da dafür zu wenig Informationen zur Verfügung stehen.
Es sollte auch klargestellt werden, dass es sich nicht um ein spezifisches Keyword-Problem handelt, sondern um die Abfragesemantik. Es gibt verschiedene Syntaxen, die in Bezug auf die Problematik identisch sind:
- Das Schlüsselwort offset, wie bereits erwähnt.
- Die Konstruktion der beiden Schlüsselwörter limit [offset] (obwohl limit selbst nicht so schlecht ist).
- Filtern nach unteren Grenzen basierend auf der Zeilennummerierung (z. B. row_number (), rownum usw.).
Alle diese Ausdrücke geben einfach an, wie viele Zeilen übersprungen werden sollen, ohne zusätzliche Informationen oder Kontext.
Später in diesem Artikel wird das Schlüsselwort offset als Verallgemeinerung all dieser Optionen verwendet.
Leben ohne OFFSET
Stellen Sie sich nun vor, wie unsere Welt ohne all diese Probleme aussehen würde. Es stellt sich heraus, dass das Leben ohne Versatz nicht so kompliziert ist: Sie können nur die Linien auswählen, die wir nicht gesehen haben (Anmerkung: das heißt, die, die nicht auf der letzten Seite waren), indem Sie die Bedingung in where verwenden.
In diesem Fall bauen wir auf der Tatsache auf, dass Selects in einer geordneten Menge ausgeführt werden (gute alte Reihenfolge von). Da wir einen geordneten Satz haben, können wir einen relativ einfachen Filter verwenden, um nur die Daten abzurufen, die sich hinter dem letzten Datensatz der vorherigen Seite befinden:
SELECT ... FROM ... WHERE ... AND id < ?last_seen_id ORDER BY id DESC FETCH FIRST 10 ROWS ONLY
Das ist das ganze Prinzip dieses Ansatzes. Natürlich macht das Sortieren nach mehreren Spalten mehr Spaß, aber die Idee ist dieselbe. Es ist wichtig anzumerken, dass diese Konstruktion für viele N o S Q L -Lösungen anwendbar ist.
Dieser Ansatz wird als Suchmethode oder Keyset-Paginierung bezeichnet. Es löst das Problem mit einem schwebenden Ergebnis (Anmerkung: die Situation beim Schreiben zwischen Seitenlesevorgängen, wie oben beschrieben) und natürlich, dass wir alle lieben, schneller und stabiler arbeiten als der klassische Offset. Die Stabilität liegt in der Tatsache, dass sich die Verarbeitungszeit für Abfragen nicht proportional zur Anzahl der angeforderten Tabellen erhöht (Hinweis: Wenn Sie mehr über die Arbeit verschiedener Ansätze zur Paginierung erfahren möchten, können Sie die Präsentation des Autors durchsehen . Dort finden Sie auch Vergleichsbenchmarks mit verschiedenen Methoden).
Einer der Folien zufolge ist die Schlüsselpagination natürlich nicht allmächtig - sie hat ihre eigenen Einschränkungen. Am wichtigsten ist, dass sie keine zufälligen Seiten lesen kann (Anmerkung: inkonsistent). Im Zeitalter des endlosen Scrollens (Hinweis: am Frontend) ist dies jedoch kein solches Problem. Die Angabe der Seitenzahl für einen Klick ist in jedem Fall eine schlechte Entscheidung bei der Entwicklung einer Benutzeroberfläche (Hinweis: Meinung des Autors des Artikels).
Was ist mit den Werkzeugen?
Die Schlüsselpagination ist häufig nicht geeignet, da diese Methode nicht instrumentell unterstützt wird. Die meisten Entwicklungswerkzeuge, einschließlich verschiedener Frameworks, lassen keine Wahl, auf welche Weise die Paginierung durchgeführt wird.
Erschwerend kommt hinzu, dass das beschriebene Verfahren eine durchgängige Unterstützung der eingesetzten Technologien erfordert - vom DBMS bis zur Ausführung der AJAX-Anfrage im Browser mit endlosem Scrolling. Anstatt nur die Seitenzahl anzugeben, müssen Sie jetzt einen Schlüsselsatz für alle Seiten gleichzeitig angeben.
Die Anzahl der Frameworks, die die Schlüsselpagination unterstützen, nimmt jedoch allmählich zu. Hier ist was im Moment ist:
(Hinweis: Einige Links wurden entfernt, da zum Zeitpunkt der Übersetzung einige Bibliotheken von 2017 bis 2018 nicht aktualisiert wurden. Bei Interesse können Sie sich die Quelle ansehen.)
In diesem Moment wird Ihre Hilfe benötigt. Wenn Sie ein Framework entwickeln oder unterstützen, das irgendwie Paginierung verwendet, dann bitte ich Sie dringend, native Unterstützung für die Schlüsselpaginierung zu leisten. Wenn Sie Fragen haben oder Hilfe benötigen, helfe ich Ihnen gerne weiter ( Forum , Twitter , Kontaktformular ) (Hinweis: Aufgrund meiner Erfahrungen mit Marcus kann ich sagen, dass er wirklich begeistert von der Verbreitung dieses Themas ist).
Wenn Sie vorgefertigte Lösungen verwenden, die Ihrer Meinung nach Unterstützung für die Schlüsselpagination verdienen, erstellen Sie eine Anfrage oder bieten Sie, wenn möglich, sogar eine vorgefertigte Lösung an. Sie können diesen Artikel auch im Link angeben.
Fazit
Der Grund, warum ein so einfacher und nützlicher Ansatz wie die Schlüsselpagination nicht weit verbreitet ist, liegt nicht darin, dass er bei der technischen Implementierung schwierig ist oder einen großen Aufwand erfordert. Der Hauptgrund ist, dass viele es gewohnt sind, Offset zu sehen und damit zu arbeiten - dieser Ansatz wird vom Standard selbst vorgegeben.
Infolgedessen denken nur wenige Menschen darüber nach, die Herangehensweise an die Paginierung zu ändern, und aus diesem Grund entwickelt sich die instrumentelle Unterstützung durch Frameworks und Bibliotheken schlecht. Wenn Sie also der Idee und dem Ziel einer unkomplizierten Paginierung nahe sind, helfen Sie, sie zu verbreiten!
Quelle: https://use-the-index-luke.com/no-offset
Gepostet von: Markus Winand