ClickHouse-Benutzer wissen bereits, dass der größte Vorteil die schnelle Verarbeitung von analytischen Abfragen ist. Behauptungen wie diese müssen jedoch durch zuverlässige Leistungstests bestätigt werden. Darüber möchten wir heute sprechen.
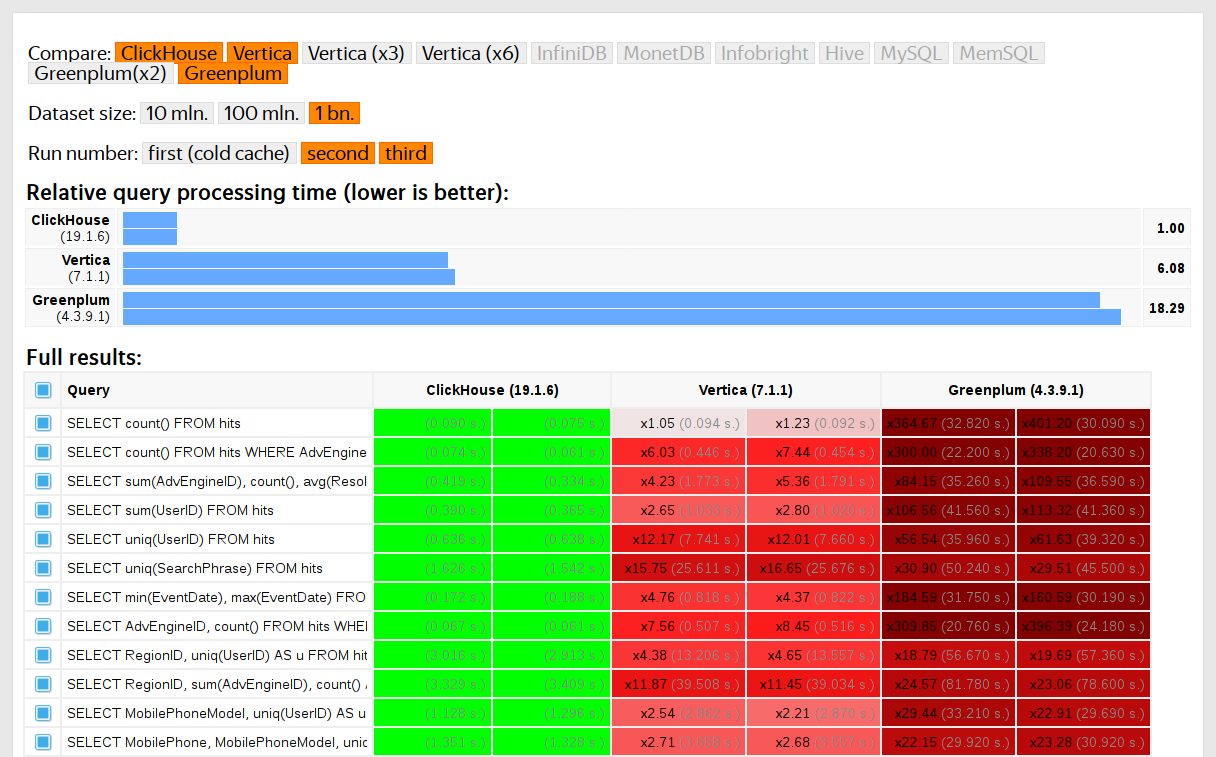
Wir haben 2013 begonnen, Tests durchzuführen, lange bevor das Produkt als Open Source verfügbar war. Unser Hauptanliegen war damals wie heute die Geschwindigkeit der Datenverarbeitung in Yandex.Metrica. Diese Daten werden seit Januar 2009 in ClickHouse gespeichert. Ein Teil der Daten wurde ab 2012 in eine Datenbank geschrieben und ein Teil von
OLAPServer und Metrage (Datenstrukturen, die zuvor von Yandex.Metrica verwendet wurden) konvertiert. Zum Testen haben wir die erste Teilmenge zufällig aus Daten für 1 Milliarde Seitenaufrufe ausgewählt. Yandex.Metrica hatte zu diesem Zeitpunkt noch keine Abfragen. Daher haben wir Abfragen ausgearbeitet, die uns interessierten. Dabei wurden alle möglichen Methoden zum Filtern, Aggregieren und Sortieren der Daten verwendet.
Die Leistung von ClickHouse wurde mit ähnlichen Systemen wie Vertica und MonetDB verglichen. Um Verzerrungen zu vermeiden, wurde der Test von einem Mitarbeiter durchgeführt, der nicht an der ClickHouse-Entwicklung teilgenommen hatte, und Sonderfälle im Code wurden erst dann optimiert, wenn alle Ergebnisse erzielt wurden. Wir haben den gleichen Ansatz verwendet, um einen Datensatz für Funktionstests zu erhalten.
Nachdem ClickHouse 2016 als Open Source veröffentlicht wurde, begannen die Leute, diese Tests in Frage zu stellen.
Mängel bei der Prüfung privater Daten
Unsere Leistungstests:
- Kann nicht unabhängig reproduziert werden, da private Daten verwendet werden, die nicht veröffentlicht werden können. Einige der Funktionstests stehen externen Benutzern aus dem gleichen Grund nicht zur Verfügung.
- Benötigen Sie weitere Entwicklung. Die Testreihe muss erheblich erweitert werden, um Leistungsänderungen in einzelnen Teilen des Systems einzugrenzen.
- Führen Sie die Ausführung nicht pro Festschreibung oder für einzelne Pull-Anforderungen aus. Externe Entwickler können ihren Code nicht auf Leistungsabweichungen überprüfen.
Wir könnten diese Probleme lösen, indem wir die alten Tests verwerfen und neue auf der Grundlage offener Daten schreiben, wie beispielsweise
Flugdaten für die USA und
Taxifahrten in New York . Oder wir könnten Benchmarks wie TPC-H, TPC-DS und
Star Schema Benchmark verwenden . Der Nachteil ist, dass sich diese Daten stark von den Yandex.Metrica-Daten unterscheiden und wir die Testabfragen lieber behalten möchten.
Warum es wichtig ist, echte Daten zu verwenden
Die Leistung sollte nur an realen Daten aus einer Produktionsumgebung getestet werden. Schauen wir uns einige Beispiele an.
Beispiel 1Angenommen, Sie füllen eine Datenbank mit gleichmäßig verteilten Pseudozufallszahlen. In diesem Fall funktioniert die Datenkomprimierung nicht, obwohl die Datenkomprimierung für analytische Datenbanken unerlässlich ist. Es gibt keine Patentlösung für die Herausforderung, den richtigen Komprimierungsalgorithmus auszuwählen und ihn auf die richtige Weise in das System zu integrieren, da die Datenkomprimierung einen Kompromiss zwischen der Geschwindigkeit der Komprimierung und Dekomprimierung und der potenziellen Komprimierungseffizienz erfordert. Systeme, die keine Daten komprimieren können, sind jedoch garantierte Verlierer. Wenn Ihre Tests gleichmäßig verteilte Pseudozufallszahlen verwenden, wird dieser Faktor ignoriert und die Ergebnisse werden verzerrt.
Fazit: Testdaten müssen ein realistisches Kompressionsverhältnis aufweisen.
Ich habe in
einem früheren Beitrag die Optimierung von ClickHouse-Datenkomprimierungsalgorithmen behandelt.
Beispiel 2Angenommen, wir interessieren uns für die Ausführungsgeschwindigkeit dieser SQL-Abfrage:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Dies ist eine typische Abfrage für Yandex.Metrica. Was beeinflusst die Verarbeitungsgeschwindigkeit?
- Wie GROUP BY ausgeführt wird.
- Welche Datenstruktur wird zur Berechnung der einheitlichen Aggregatfunktion verwendet?
- Wie viele verschiedene RegionIDs gibt es und wie viel RAM benötigt jeder Status der uniq-Funktion.
Ein weiterer wichtiger Faktor ist jedoch, dass die Datenmenge zwischen den Regionen ungleich verteilt ist. (Es folgt wahrscheinlich einem Potenzgesetz. Ich habe die Verteilung in ein Log-Log-Diagramm eingetragen, kann aber nicht sicher sagen.) Wenn dies der Fall ist, ist es wichtig, dass die Zustände der uniq-Aggregatfunktion mit weniger Werten verwendet werden sehr wenig Gedächtnis. Bei vielen verschiedenen Aggregationsschlüsseln zählt jedes einzelne Byte. Wie können wir generierte Daten mit all diesen Eigenschaften erhalten? Die naheliegende Lösung besteht darin, echte Daten zu verwenden.
Viele DBMS implementieren die HyperLogLog-Datenstruktur für eine Annäherung von COUNT (DISTINCT), aber keine von ihnen funktioniert sehr gut, da diese Datenstruktur eine feste Speichermenge verwendet. ClickHouse verfügt über eine Funktion, die abhängig von der Größe des Datensatzes
eine Kombination aus drei verschiedenen Datenstrukturen verwendet .
Fazit: Die Testdaten müssen die Verteilungseigenschaften der realen Daten gut genug wiedergeben, dh die Kardinalität (Anzahl der unterschiedlichen Werte pro Spalte) und die spaltenübergreifende Kardinalität (Anzahl der unterschiedlichen Werte, die über mehrere unterschiedliche Spalten hinweg gezählt werden).
Beispiel 3Anstatt die Leistung des ClickHouse-DBMS zu testen, nehmen wir etwas Einfacheres wie Hash-Tabellen. Für Hash-Tabellen ist es wichtig, die richtige Hash-Funktion zu wählen. Dies ist für std :: unordered_map nicht so wichtig, da es sich um eine auf Verkettung basierende Hash-Tabelle handelt und eine Primzahl als Array-Größe verwendet wird. Die Standard-Bibliotheksimplementierung in GCC und Clang verwendet eine einfache Hash-Funktion als Standard-Hash-Funktion für numerische Typen. Std :: unordered_map ist jedoch nicht die beste Wahl, wenn wir nach maximaler Geschwindigkeit suchen. Bei einer offenen Adressierungs-Hash-Tabelle können wir nicht nur eine Standard-Hash-Funktion verwenden. Die Wahl der richtigen Hash-Funktion wird zum entscheidenden Faktor.
Es ist einfach, Leistungstests für Hash-Tabellen mit zufälligen Daten zu finden, die die verwendeten Hash-Funktionen nicht berücksichtigen. Es gibt auch viele Hash-Funktionstests, die sich auf die Berechnungsgeschwindigkeit und bestimmte Qualitätskriterien konzentrieren, obwohl sie die verwendeten Datenstrukturen ignorieren. Fakt ist jedoch, dass Hash-Tabellen und HyperLogLog unterschiedliche Qualitätskriterien für Hash-Funktionen erfordern.
Weitere
Informationen hierzu finden Sie unter "Funktionsweise von Hash-Tabellen in ClickHouse" (Präsentation in Russisch). Die Informationen sind leicht veraltet, da sie keine
Schweizer Tabellen abdecken.
Herausforderung
Unser Ziel ist es, Daten zum Testen der Leistung zu erhalten, die dieselbe Struktur wie Yandex.Metrica-Daten haben, mit allen für Benchmarks wichtigen Eigenschaften, aber so, dass in diesen Daten keine Spuren von echten Website-Nutzern verbleiben. Mit anderen Worten, die Daten müssen anonymisiert sein und dennoch Folgendes bewahren:
- Kompressionsverhältnis.
- Kardinalität (die Anzahl der unterschiedlichen Werte).
- Gegenseitige Kardinalität zwischen mehreren verschiedenen Spalten.
- Eigenschaften von Wahrscheinlichkeitsverteilungen, die für die Datenmodellierung verwendet werden können (wenn wir beispielsweise glauben, dass Regionen nach einem Potenzgesetz verteilt sind, sollte der Exponent - der Verteilungsparameter - für künstliche Daten und für reale Daten ungefähr gleich sein).
Wie können wir eine ähnliche Komprimierungsrate für die Daten erhalten? Wenn LZ4 verwendet wird, müssen Teilzeichenfolgen in Binärdaten in ungefähr derselben Entfernung wiederholt werden und die Wiederholungen müssen ungefähr dieselbe Länge haben. Für ZSTD muss auch die Entropie pro Byte übereinstimmen.
Das ultimative Ziel ist es, ein öffentlich verfügbares Tool zu erstellen, mit dem jeder seine Datensätze zur Veröffentlichung anonymisieren kann. Dies würde es uns ermöglichen, die Leistung von Daten anderer Leute zu debuggen und zu testen, die unseren Produktionsdaten ähnlich sind. Wir möchten auch, dass die generierten Daten interessant sind.
Dies sind jedoch sehr lose definierte Anforderungen, und wir planen nicht, eine formale Problembeschreibung oder Spezifikation für diese Aufgabe zu verfassen.
Mögliche Lösungen
Ich möchte nicht, dass es so klingt, als sei dieses Problem besonders wichtig. Es wurde nie in die Planung einbezogen und niemand hatte die Absicht, daran zu arbeiten. Ich hatte nur gehofft, dass eines Tages eine Idee auftauchen würde, und plötzlich war ich gut gelaunt und konnte alles andere bis später aufschieben.
Explizite Wahrscheinlichkeitsmodelle
Die erste Idee besteht darin, für jede Spalte in der Tabelle eine Familie von Wahrscheinlichkeitsverteilungen zu finden, die diese modellieren, dann die Parameter basierend auf der Datenstatistik anzupassen (Modellanpassung) und die resultierende Verteilung zum Generieren neuer Daten zu verwenden. Ein Pseudozufallszahlengenerator mit einem vordefinierten Startwert könnte verwendet werden, um ein reproduzierbares Ergebnis zu erhalten.
Markov-Ketten könnten für Textfelder verwendet werden. Dies ist ein bekanntes Modell, das effektiv implementiert werden könnte.
Es wären jedoch einige Tricks erforderlich:
- Wir wollen die Kontinuität von Zeitreihen erhalten. Dies bedeutet, dass wir für einige Datentypen die Differenz zwischen benachbarten Werten und nicht den Wert selbst modellieren müssen.
- Um die "gemeinsame Kardinalität" von Spalten zu modellieren, müssen wir auch die Abhängigkeiten zwischen Spalten explizit berücksichtigen. Beispielsweise gibt es normalerweise nur sehr wenige IP-Adressen pro Benutzer-ID. Um eine IP-Adresse zu generieren, würden wir einen Hash-Wert der Benutzer-ID als Ausgangswert verwenden und auch eine kleine Menge anderer Pseudozufallsdaten hinzufügen.
- Wir sind uns nicht sicher, wie wir die Abhängigkeit ausdrücken sollen, dass derselbe Benutzer URLs mit übereinstimmenden Domains ungefähr zur selben Zeit besucht.
All dies kann in einem C ++ - "Skript" geschrieben werden, wobei die Distributionen und Abhängigkeiten fest codiert sind. Markov-Modelle werden jedoch aus einer Kombination von Statistiken mit Glätten und Hinzufügen von Rauschen erhalten. Ich habe angefangen, ein Skript wie dieses zu schreiben, aber nachdem ich explizite Modelle für zehn Spalten geschrieben hatte, wurde es unerträglich langweilig - und die "Treffer" -Tabelle in Yandex.Metrica hatte 2012 mehr als 100 Spalten.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Dieser Ansatz war ein Misserfolg. Wenn ich mich mehr angestrengt hätte, wäre das Skript vielleicht schon fertig.
Vorteile:
- Konzeptuelle Einfachheit.
Nachteile:
- Viel Arbeit erforderlich.
- Die Lösung gilt nur für einen Datentyp.
Und ich würde eine allgemeinere Lösung vorziehen, die sowohl für Yandex.Metrica-Daten als auch zum Verschleiern anderer Daten verwendet werden kann.
In jedem Fall könnte diese Lösung verbessert werden. Anstatt Modelle manuell auszuwählen, könnten wir einen Katalog von Modellen implementieren und die besten unter ihnen auswählen (beste Anpassung plus irgendeine Form der Regularisierung). Oder wir könnten Markov-Modelle für alle Arten von Feldern verwenden, nicht nur für Text. Abhängigkeiten zwischen Daten können auch automatisch extrahiert werden. Dazu müsste die
relative Entropie (relative Informationsmenge) zwischen den Spalten berechnet werden. Eine einfachere Alternative besteht darin, relative Kardinalitäten für jedes Spaltenpaar zu berechnen (so etwas wie "wie viele verschiedene Werte von A gibt es im Durchschnitt für einen festen Wert B"). Dies macht beispielsweise deutlich, dass URLDomain vollständig von der URL abhängt und nicht umgekehrt.
Aber ich habe diese Idee auch abgelehnt, weil zu viele Faktoren zu berücksichtigen sind und das Schreiben zu lange dauern würde.
Neuronale Netze
Wie ich bereits erwähnte, stand diese Aufgabe nicht ganz oben auf der Prioritätenliste - niemand dachte darüber nach, sie zu lösen. Aber wie es das Glück wollte, unterrichtete unser Kollege Ivan Puzirevsky an der Higher School of Economics. Er fragte mich, ob ich irgendwelche interessanten Probleme hätte, die für seine Studenten als geeignete Abschlussarbeitsthemen geeignet wären. Als ich ihm dieses anbot, versicherte er mir, dass es Potenzial habe. Also gab ich diese Herausforderung an einen netten Kerl "von der Straße" Sharif weiter (er musste allerdings eine NDA unterzeichnen, um auf die Daten zugreifen zu können).
Ich teilte ihm alle meine Ideen mit, betonte jedoch, dass es keine Einschränkungen für die Lösung des Problems gibt. Eine gute Option wäre, Ansätze auszuprobieren, über die ich nichts weiß, wie die Verwendung von LSTM zum Generieren eines Text-Dumps von Daten. Dies schien vielversprechend, nachdem der Artikel
Die unzumutbare Wirksamkeit wiederkehrender neuronaler Netze veröffentlicht wurde .
Die erste Herausforderung besteht darin, dass wir strukturierte Daten generieren müssen, nicht nur Text. Es war jedoch nicht klar, ob ein wiederkehrendes neuronales Netzwerk Daten mit der gewünschten Struktur erzeugen könnte. Es gibt zwei Möglichkeiten, dies zu lösen. Die erste Lösung besteht darin, separate Modelle zum Erzeugen der Struktur und des "Füllers" zu verwenden und nur das neuronale Netzwerk zum Erzeugen von Werten zu verwenden. Dieser Ansatz wurde jedoch verschoben und nie abgeschlossen. Die zweite Lösung besteht darin, einfach einen TSV-Dump als Text zu generieren. Erfahrungsgemäß stimmen einige Zeilen im Text nicht mit der Struktur überein, diese Zeilen können jedoch beim Laden der Daten verworfen werden.
Die zweite Herausforderung besteht darin, dass das wiederkehrende neuronale Netzwerk eine Folge von Daten erzeugt und daher Abhängigkeiten in Daten in der Reihenfolge der Folge folgen müssen. In unseren Daten kann sich die Reihenfolge der Spalten möglicherweise umgekehrt zu den Abhängigkeiten zwischen ihnen verhalten.
Wir haben nichts unternommen, um dieses Problem zu beheben.
Als der Sommer näher rückte, hatten wir das erste funktionierende Python-Skript, das Daten generierte. Die Datenqualität schien auf den ersten Blick anständig:

Wir sind jedoch auf einige Schwierigkeiten gestoßen:
- Die Größe des Modells beträgt etwa ein Gigabyte. Wir haben versucht, ein Modell für Daten mit einer Größe von mehreren Gigabyte zu erstellen (zunächst). Die Tatsache, dass das resultierende Modell so groß ist, gibt Anlass zur Sorge. Wäre es möglich, die realen Daten zu extrahieren, auf die es trainiert wurde? Unwahrscheinlich Aber ich weiß nicht viel über maschinelles Lernen und neuronale Netze, und ich habe den Python-Code dieses Entwicklers nicht gelesen. Wie kann ich also sicher sein? Zu der Zeit wurden mehrere Artikel veröffentlicht, in denen es darum ging, neuronale Netze ohne Qualitätsverlust zu komprimieren, die jedoch nicht implementiert wurden. Einerseits scheint dies kein ernstes Problem zu sein, da wir die Veröffentlichung des Modells ablehnen und nur die generierten Daten veröffentlichen können. Wenn andererseits eine Überanpassung auftritt, können die generierten Daten einen Teil der Quelldaten enthalten.
- Auf einem Computer mit einer einzelnen CPU beträgt die Datenerzeugungsgeschwindigkeit ungefähr 100 Zeilen pro Sekunde. Unser Ziel war es, mindestens eine Milliarde Zeilen zu generieren. Berechnungen ergaben, dass dies nicht vor dem Datum der Verteidigung der Dissertation abgeschlossen sein würde. Es war nicht sinnvoll, zusätzliche Hardware zu verwenden, da das Ziel darin bestand, ein Tool zur Datengenerierung zu entwickeln, das von jedem verwendet werden konnte.
Sharif versuchte, die Qualität der Daten durch einen Vergleich der Statistiken zu analysieren. Er berechnete unter anderem die Häufigkeit verschiedener Zeichen, die in den Quelldaten und in den generierten Daten vorkommen. Das Ergebnis war atemberaubend: Die häufigsten Zeichen waren Ð und Ñ.
Mach dir keine Sorgen um Sharif. Er hat seine These erfolgreich verteidigt und dann haben wir das Ganze glücklicherweise vergessen.
Mutation komprimierter Daten
Angenommen, die Problemanweisung wurde auf einen einzigen Punkt reduziert: Wir müssen Daten mit demselben Komprimierungsverhältnis wie die Quelldaten generieren und die Daten müssen mit derselben Geschwindigkeit dekomprimiert werden. Wie können wir das erreichen? Wir müssen komprimierte Datenbytes direkt bearbeiten! Auf diese Weise können wir die Daten ändern, ohne die Größe der komprimierten Daten zu ändern, und alles wird schnell funktionieren. Ich wollte diese Idee sofort ausprobieren, obwohl das Problem, mit dem sie sich befasst, nicht das gleiche ist, mit dem wir begonnen haben. Aber so ist es immer.
Wie bearbeiten wir eine komprimierte Datei? Nehmen wir an, wir interessieren uns nur für LZ4. LZ4-komprimierte Daten bestehen aus Folgen, die wiederum Zeichenfolgen aus nicht komprimierten Bytes (Literalen) sind, gefolgt von einer Übereinstimmungskopie:
- Literale (kopieren Sie die folgenden N Bytes so wie sie sind).
- Übereinstimmungen mit einer minimalen Wiederholungslänge von 4 (wiederholen Sie N Bytes, die sich in der Datei in einem Abstand von M befanden).
Quelldaten:
Hello world Hello .
Komprimierte Daten (beliebiges Beispiel):
literals 12 "Hello world " match 5 12 .
In der komprimierten Datei lassen wir "match" unverändert und ändern die Bytewerte in "literals". Als Ergebnis erhalten wir nach dem Dekomprimieren eine Datei, in der alle sich wiederholenden Sequenzen, die mindestens 4 Bytes lang sind, ebenfalls in der gleichen Entfernung wiederholt werden, aber aus einer anderen Menge von Bytes bestehen (im Grunde enthält die geänderte Datei keine einzige Byte, das aus der Quelldatei entnommen wurde).
Aber wie ändern wir die Bytes? Die Antwort ist nicht offensichtlich, da die Daten neben den Spaltentypen auch eine eigene interne, implizite Struktur haben, die wir beibehalten möchten. Beispielsweise wird Text häufig in UTF-8-Codierung gespeichert, und die generierten Daten sollen auch UTF-8-gültig sein. Ich habe eine einfache Heuristik entwickelt, bei der mehrere Kriterien erfüllt werden:
- Nullbytes und ASCII-Steuerzeichen bleiben unverändert.
- Einige Satzzeichen bleiben unverändert.
- ASCII wird in ASCII konvertiert und für alles andere bleibt das höchstwertige Bit erhalten (oder ein expliziter Satz von "if" -Anweisungen wird für verschiedene UTF-8-Längen geschrieben). In einer Byte-Klasse wird ein neuer Wert gleichmäßig zufällig ausgewählt.
- Fragmente wie
https:// bleiben erhalten, sonst sieht es etwas albern aus.
Der einzige Nachteil dieses Ansatzes besteht darin, dass das Datenmodell die Quelldaten selbst sind, das heißt, es kann nicht veröffentlicht werden. Das Modell eignet sich nur zum Generieren von Datenmengen, die nicht größer als die Quelle sind. Im Gegenteil, die bisherigen Ansätze liefern Modelle, mit denen Daten beliebiger Größe erzeugt werden können.
Beispiel für eine URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Die Ergebnisse waren positiv und die Daten waren interessant, aber etwas stimmte nicht. Die URLs behielten die gleiche Struktur, aber in einigen von ihnen war es zu einfach, "yandex" oder "avito" (ein beliebter Marktplatz in Russland) zu erkennen, sodass ich eine Heuristik erstellt habe, die einige der Bytes vertauscht.
Es gab auch andere Bedenken. Beispielsweise können vertrauliche Informationen möglicherweise in einer FixedString-Spalte in Binärdarstellung gespeichert sein und möglicherweise aus ASCII-Steuerzeichen und Satzzeichen bestehen, die ich beibehalten möchte. Datentypen habe ich jedoch nicht berücksichtigt.
Ein weiteres Problem ist, dass wenn eine Spalte Daten im Format "Länge, Wert" speichert (so werden Zeichenfolgenspalten gespeichert), wie kann ich sicherstellen, dass die Länge nach der Mutation korrekt bleibt? Als ich versuchte, das zu beheben, verlor ich sofort das Interesse.
Zufällige Permutationen
Leider wurde das Problem nicht gelöst. Wir haben ein paar Experimente durchgeführt, und es wurde noch schlimmer. Das einzige, was noch übrig war, war herumzusitzen, nichts zu tun und willkürlich im Internet zu surfen, da die Magie verschwunden war. Zum Glück bin ich auf eine Seite
gestoßen, die den Algorithmus zum Rendern des Todes der Hauptfigur im Spiel Wolfenstein 3D erklärt.

Die Animation ist wirklich gut gemacht - der Bildschirm füllt sich mit Blut. Der Artikel erklärt, dass dies tatsächlich eine pseudozufällige Permutation ist. Eine zufällige Permutation eines Satzes von Elementen ist eine zufällig ausgewählte bijektive (Eins-zu-Eins) Transformation des Satzes oder eine Abbildung, bei der jedes abgeleitete Element genau einem ursprünglichen Element entspricht (und umgekehrt). Mit anderen Worten, es ist eine Möglichkeit, alle Elemente eines Datensatzes nach dem Zufallsprinzip zu durchlaufen. Und genau das ist der im Bild gezeigte Vorgang: Jedes Pixel wird ohne Wiederholung in zufälliger Reihenfolge ausgefüllt. Wenn wir bei jedem Schritt nur ein zufälliges Pixel auswählen würden, würde es lange dauern, bis wir zum letzten Pixel gelangen.
Das Spiel verwendet einen sehr einfachen Algorithmus für die Pseudozufalls-Permutation, der als Linear Feedback Shift Register (
LFSR ) bezeichnet wird. Ähnlich wie Pseudozufallszahlengeneratoren können zufällige Permutationen oder vielmehr deren Familien kryptografisch stark sein, wenn sie durch einen Schlüssel parametrisiert werden. Genau das brauchen wir für die Datentransformation. Die Details könnten jedoch kniffliger sein. Beispielsweise scheint eine kryptografisch starke Verschlüsselung von N Bytes zu N Bytes mit einem vorbestimmten Schlüssel und einem Initialisierungsvektor für eine pseudozufällige Permutation eines Satzes von N-Byte-Zeichenfolgen zu funktionieren. In der Tat ist dies eine Eins-zu-Eins-Transformation und es scheint zufällig zu sein. Wenn wir jedoch für alle unsere Daten dieselbe Transformation verwenden, ist das Ergebnis möglicherweise für die Kryptoanalyse anfällig, da derselbe Initialisierungsvektor und derselbe Schlüsselwert mehrmals verwendet werden. Dies ähnelt der Funktionsweise des
elektronischen Codebuchs für eine Blockchiffre.
Was sind die möglichen Wege, um eine Pseudozufalls-Permutation zu erhalten? Wir können einfache Eins-zu-Eins-Transformationen durchführen und eine komplexe Funktion erstellen, die zufällig aussieht. Hier sind einige meiner Lieblings-Eins-zu-Eins-Transformationen:
- Multiplikation mit einer ungeraden Zahl (wie eine große Primzahl) in Zweierkomplementarithmetik.
- Xorshift:
x ^= x >> N - CRC-N, wobei N die Anzahl der Bits im Argument ist.
Beispielsweise werden drei Multiplikationen und zwei Xorshift-Operationen für den
Murmelhash- Finalizer verwendet. Diese Operation ist eine Pseudozufalls-Permutation. Ich sollte jedoch darauf hinweisen, dass Hash-Funktionen nicht eins zu eins sein müssen (sogar Hashes von N Bits zu N Bits).
Oder hier ist ein weiteres interessantes
Beispiel aus der elementaren Zahlentheorie von Jeff Preshings Website.
Wie können wir Pseudozufalls-Permutationen verwenden, um unser Problem zu lösen? Wir können sie verwenden, um alle numerischen Felder zu transformieren, damit wir die Kardinalitäten und gegenseitigen Kardinalitäten aller Feldkombinationen beibehalten können. Mit anderen Worten, COUNT (DISTINCT) gibt den gleichen Wert wie vor der Transformation zurück und außerdem mit jedem GROUP BY.
Es ist anzumerken, dass die Wahrung aller Kardinalitäten in gewisser Weise unserem Ziel der Datenanonymisierung widerspricht. Angenommen, jemand weiß, dass die Quelldaten für Websitesitzungen einen Benutzer enthalten, der Websites aus 10 verschiedenen Ländern besucht hat, und er möchte diesen Benutzer in den transformierten Daten finden. Die transformierten Daten zeigen auch, dass der Benutzer Websites aus 10 verschiedenen Ländern besucht hat, wodurch die Suche einfacher eingegrenzt werden kann. Selbst wenn sie herausfinden, in was der Benutzer umgewandelt wurde, ist dies nicht sehr nützlich, da alle anderen Daten ebenfalls umgewandelt wurden, sodass sie nicht herausfinden können, welche Websites der Benutzer besucht hat oder sonst etwas. Diese Regeln können jedoch in einer Kette angewendet werden. Wenn jemand beispielsweise weiß, dass die in unseren Daten am häufigsten vorkommende Website Yandex ist und Google an zweiter Stelle steht, kann er anhand des Rankings ermitteln, welche umgewandelten Website-IDs tatsächlich Yandex und Google bedeuten. Dies ist nicht überraschend, da wir mit einer informellen Problemstellung arbeiten und nur versuchen, ein Gleichgewicht zwischen Anonymisierung von Daten (Verbergen von Informationen) und Erhalt von Dateneigenschaften (Offenlegung von Informationen) zu finden. In diesem
Artikel erfahren Sie, wie Sie das Problem der Datenanonymisierung zuverlässiger angehen können.
Zusätzlich zur Beibehaltung der ursprünglichen Kardinalität der Werte möchte ich auch die Größenordnung der Werte beibehalten. Was ich meine ist, dass, wenn die Quelldaten Zahlen unter 10 enthielten, ich möchte, dass die transformierten Zahlen auch klein sind. Wie können wir das erreichen?
Beispielsweise können wir eine Reihe möglicher Werte in Größenklassen unterteilen und Permutationen innerhalb jeder Klasse separat durchführen (wobei die Größenklassen beibehalten werden). Der einfachste Weg, dies zu tun, besteht darin, die nächste Zweierpotenz oder die Position des höchstwertigen Bits in der Zahl als Größenklasse zu nehmen (dies sind die gleichen Werte). Die Zahlen 0 und 1 bleiben immer unverändert. Die Zahlen 2 und 3 bleiben manchmal unverändert (mit einer Wahrscheinlichkeit von 1/2) und werden manchmal ausgetauscht (mit einer Wahrscheinlichkeit von 1/2). Die Menge der Zahlen 1024. 2047 wird einer von 1024 zugeordnet! (Fakultäts-) Varianten und so weiter. Für signierte Nummern behalten wir das Schild.
Es ist auch zweifelhaft, ob wir eine Eins-zu-Eins-Funktion benötigen. Wir können wahrscheinlich nur eine kryptografisch starke Hash-Funktion verwenden. Die Transformation wird nicht eins zu eins sein, aber die Kardinalität wird in etwa gleich sein.
Wir benötigen jedoch eine kryptografisch starke zufällige Permutation, damit es schwierig ist, die ursprünglichen Daten aus den neu angeordneten Daten wiederherzustellen, ohne den Schlüssel zu kennen, wenn wir einen Schlüssel definieren und eine Permutation mit diesem Schlüssel ableiten.
Es gibt ein Problem: Ich weiß nicht nur nichts über neuronale Netze und maschinelles Lernen, sondern weiß auch nichts über Kryptographie. Das ist nur mein Mut. Ich las immer noch zufällige Webseiten und fand in
Hackers News einen Link zu einer Diskussion auf Fabien Sanglards Seite. Es gab einen Link zu einem
Blogbeitrag von Redis-Entwickler Salvatore Sanfilippo, in dem es darum ging, auf wunderbare Weise zufällige Permutationen zu erhalten, das sogenannte
Feistel-Netzwerk .
Das Feistel-Netzwerk ist iterativ und besteht aus Runden. Jede Runde ist eine bemerkenswerte Transformation, mit der Sie von jeder Funktion eine Eins-zu-Eins-Funktion erhalten. Schauen wir uns an, wie es funktioniert.
- Die Bits des Arguments sind in zwei Hälften unterteilt:
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - Die rechte Hälfte ersetzt die linke. An seine Stelle setzen wir das Ergebnis von XOR auf den Anfangswert der linken Hälfte und das Ergebnis der Funktion, die auf den Anfangswert der rechten Hälfte angewendet wird, wie folgt:
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
Es gibt auch die Behauptung, dass wir eine kryptografisch starke Pseudozufallsfunktion für F verwenden und mindestens viermal eine Feistel-Runde anwenden, um eine kryptografisch starke Pseudozufallspermutation zu erhalten.
Das ist wie ein Wunder: Wir nehmen eine Funktion, die zufälligen Müll basierend auf Daten erzeugt, fügen ihn in das Feistel-Netzwerk ein und wir haben jetzt eine Funktion, die zufälligen Müll basierend auf Daten erzeugt, aber dennoch umkehrbar ist!
Das Feistel-Netzwerk ist das Herzstück mehrerer Datenverschlüsselungsalgorithmen. Was wir tun werden, ist so etwas wie Verschlüsselung, nur dass es wirklich schlecht ist. Dafür gibt es zwei Gründe:
- Wir verschlüsseln einzelne Werte unabhängig und auf die gleiche Weise, ähnlich der Funktionsweise des elektronischen Codebuchs.
- Wir speichern Informationen über die Größenordnung (die nächste Potenz von zwei) und das Vorzeichen des Werts, was bedeutet, dass sich einige Werte überhaupt nicht ändern.
Auf diese Weise können wir numerische Felder verschleiern und dabei die Eigenschaften beibehalten, die wir benötigen. Beispielsweise sollte nach Verwendung von LZ4 das Komprimierungsverhältnis ungefähr gleich bleiben, da die doppelten Werte in den Quelldaten in den konvertierten Daten und in gleichen Abständen voneinander wiederholt werden.
Markov-Modelle
Textmodelle werden für die Datenkomprimierung, die Vorhersageeingabe, die Spracherkennung und die Erzeugung von Zufallszeichenfolgen verwendet. Ein Textmodell ist eine Wahrscheinlichkeitsverteilung aller möglichen Zeichenfolgen. Nehmen wir an, wir haben eine imaginäre Wahrscheinlichkeitsverteilung der Texte aller Bücher, die die Menschheit jemals schreiben könnte. Um eine Zeichenfolge zu generieren, nehmen wir einfach einen zufälligen Wert mit dieser Verteilung und geben die resultierende Zeichenfolge zurück (ein zufälliges Buch, das die Menschheit schreiben könnte). Aber wie ermitteln wir die Wahrscheinlichkeitsverteilung aller möglichen Zeichenketten?
Erstens würde dies zu viele Informationen erfordern. Es gibt 256 ^ 10 mögliche Zeichenfolgen mit einer Länge von 10 Byte, und das explizite Schreiben einer Tabelle mit der Wahrscheinlichkeit jeder Zeichenfolge würde sehr viel Speicherplatz erfordern. Zweitens haben wir nicht genügend Statistiken, um die Verteilung genau zu bewerten.
Aus diesem Grund verwenden wir als Textmodell eine Wahrscheinlichkeitsverteilung aus groben Statistiken. Zum Beispiel könnten wir die Wahrscheinlichkeit berechnen, dass jeder Buchstabe im Text vorkommt, und dann Zeichenfolgen generieren, indem wir jeden nächsten Buchstaben mit der gleichen Wahrscheinlichkeit auswählen. Dieses primitive Modell funktioniert, aber die Zeichenfolgen sind immer noch sehr unnatürlich.
Um das Modell leicht zu verbessern, können wir auch die bedingte Wahrscheinlichkeit des Auftretens des Buchstabens heranziehen, wenn N spezifischen Buchstaben vorangestellt sind. N ist eine voreingestellte Konstante. Nehmen wir an, N = 5 und wir berechnen die Wahrscheinlichkeit, dass der Buchstabe "e" nach den Buchstaben "compr" auftritt. Dieses Textmodell wird als Order-N-Markov-Modell bezeichnet.
P(cat a | cat) = 0.8
P(cat b | cat) = 0.05
P(cat c | cat) = 0.1
...Schauen wir uns auf der Website
von Hay Kranen an, wie Markov-Modelle funktionieren. Im Gegensatz zu neuronalen LSTM-Netzen verfügen die Modelle nur über genügend Speicher für einen kleinen Kontext von N mit fester Länge, sodass sie lustige, unsinnige Texte generieren. Markov-Modelle werden auch in primitiven Methoden zum Generieren von Spam verwendet. Die generierten Texte können leicht von echten unterschieden werden, indem Statistiken gezählt werden, die nicht zum Modell passen. Es gibt einen Vorteil: Markov-Modelle arbeiten viel schneller als neuronale Netze, genau das, was wir brauchen.
Beispiel für Titel (unsere Beispiele sind aufgrund der verwendeten Daten auf Türkisch):
Hyunday Butter'dan anket shluha - Politischer Leiter manşetleri | STALKER BOXER Çiftede Buch - Yanudistkarışmanlı Mı Kanal | League el Digitalika Haberler Haberleri - Haberlerisi - Hotels mit Centry'ler Neden babah.com
Wir können Statistiken aus den Quelldaten berechnen, ein Markov-Modell erstellen und damit neue Daten generieren. Beachten Sie, dass das Modell geglättet werden muss, um Informationen zu seltenen Kombinationen in den Quelldaten nicht preiszugeben. Dies ist jedoch kein Problem. Ich verwende eine Kombination von Modellen von 0 bis N. Wenn die Statistiken für das Modell der Ordnung N nicht ausreichen, wird stattdessen das Modell N - 1 verwendet.
Wir möchten jedoch weiterhin die Kardinalität der Daten bewahren. Mit anderen Worten, wenn die Quelldaten 123456 eindeutige URL-Werte hatten, sollte das Ergebnis ungefähr dieselbe Anzahl eindeutiger Werte haben. Wir können einen deterministisch initialisierten Zufallszahlengenerator verwenden, um dies zu erreichen. Am einfachsten ist es, eine Hash-Funktion zu verwenden und auf den ursprünglichen Wert anzuwenden. Mit anderen Worten, wir erhalten ein pseudozufälliges Ergebnis, das explizit durch den ursprünglichen Wert bestimmt wird.
Eine weitere Voraussetzung ist, dass die Quelldaten viele verschiedene URLs haben, die mit demselben Präfix beginnen, jedoch nicht identisch sind. Zum Beispiel:
https://www.yandex.ru/images/cats/?id=xxxxxx . Wir möchten, dass das Ergebnis auch URLs enthält, die alle mit demselben, aber einem anderen Präfix beginnen. Beispiel:
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . Als Zufallszahlengenerator zum Generieren des nächsten Zeichens unter Verwendung eines Markov-Modells nehmen wir eine Hash-Funktion aus einem sich bewegenden Fenster von 8 Bytes an der angegebenen Position (anstatt es aus der gesamten Zeichenfolge zu nehmen).
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ...Es stellt sich heraus, dass es genau das ist, was wir brauchen. Hier ist das Beispiel für Seitentitel:
PhotoFunia - Haber7 - Jetzt kaufen! Oynamak içinde şaşıracak haber, Oyunu Oynanılmaz • apród.hu kínálatában - RT Arabic
PhotoFunia - Kinobar.Net - apród: Ingyenes | Posti
PhotoFunia - Peg Perfeo - Castika, Sıradışı Deniz Lokoning Ihr Code, Vater Eminema.tv/
PhotoFunia - TUT.BY - Ihr Ayakkanın ve Son Dakika Spor,
PhotoFunia - Großfilm, Del Meireles offilim, Samsung DealeXtreme Değerler NEWSru.com.tv, Smotri.com Mobile yapmak Okey
PhotoFunia 5 | Galaxy, gt, dupăce anal bilgi yarak Ceza RE050A V-Stranç
PhotoFunia :: Miami olacaksını yerel Haberler Oyun Junges Video
PhotoFunia Monstelli'nin En İyi kisa.com.tr –Star Thunder Ekranı
PhotoFunia Seks - Politika, Ekonomi, Spor GTA SANAYİ VE
PhotoFunia Taker-Rating Star-Fernsehen Resmi Söylenen Yatağa każdy dzież wierzchnie
PhotoFunia TourIndex.Marketime Oyna Geldolları Mynet Spor, Magazin, Haberler und Haberleri ve Solvia, korkusuz Ev SahneTv
PhotoFunia todo in der Gratis Perky Parti'nin yapıyı bu fotogram
PhotoFunian Dünyasın takımız halles en kulları - TEZ
Ergebnisse
Nachdem ich vier Methoden ausprobiert hatte, hatte ich dieses Problem so satt, dass es Zeit war, einfach etwas auszuwählen, es zu einem brauchbaren Werkzeug zu machen und die Lösung anzukündigen. Ich habe die Lösung gewählt, die zufällige Permutationen und mit einem Schlüssel parametrisierte Markov-Modelle verwendet. Es ist als
Clickhouse-Obfuscator- Programm implementiert, das sehr einfach zu bedienen ist. Die Eingabe ist ein Tabellen-Dump in einem
beliebigen unterstützten Format (z. B. CSV oder JSONEachRow). Die Befehlszeilenparameter geben die Tabellenstruktur (Spaltennamen und -typen) und den geheimen Schlüssel (eine beliebige Zeichenfolge, die Sie unmittelbar nach der Verwendung vergessen können) an. Die Ausgabe entspricht der gleichen Anzahl von Zeilen mit verschleierten Daten.
Das Programm wird mit clickhouse-client installiert, ist unabhängig von Abhängigkeiten und kann auf fast allen Linux-Versionen verwendet werden. Sie können es auf jeden Datenbank-Dump anwenden, nicht nur auf ClickHouse. Beispielsweise können Sie Testdaten aus MySQL- oder PostgreSQL-Datenbanken generieren oder Entwicklungsdatenbanken erstellen, die Ihren Produktionsdatenbanken ähneln.
clickhouse-obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse-obfuscator --help
Natürlich ist nicht alles so geschnitten und getrocknet, weil die mit diesem Programm transformierten Daten fast vollständig umkehrbar sind. Die Frage ist, ob es möglich ist, die Rücktransformation durchzuführen, ohne den Schlüssel zu kennen. Wenn für die Umwandlung ein kryptografischer Algorithmus verwendet würde, wäre diese Operation so schwierig wie eine Brute-Force-Suche. Obwohl bei der Transformation einige kryptografische Grundelemente verwendet werden, werden sie nicht korrekt verwendet, und die Daten können mit bestimmten Analysemethoden analysiert werden. Um Probleme zu vermeiden, werden diese Probleme in der Dokumentation des Programms behandelt (greifen Sie mit
--help ).
Am Ende haben wir den Datensatz, den wir
für die Funktions- und Leistungstests benötigen
, und den von Yandex als Vizepräsident der Datenschutzbehörde genehmigten Veröffentlichung transformiert.
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzNicht-Yandex-Entwickler verwenden diese Daten für echte Leistungstests bei der Optimierung von Algorithmen in ClickHouse. Drittanbieter können uns ihre verschleierten Daten zur Verfügung stellen, damit wir ClickHouse für sie noch schneller machen können. Darüber hinaus haben wir einen unabhängigen offenen Benchmark für Hardware- und Cloud-Anbieter veröffentlicht:
clickhouse.yandex/benchmark_hardware.html