 Hier finden Sie eine aktualisierte Liste der schönsten Unicode- "Goodies" sowie der Pakete und Ressourcen
Hier finden Sie eine aktualisierte Liste der schönsten Unicode- "Goodies" sowie der Pakete und RessourcenUnicode ist großartig! Vor seinem Erscheinen war die internationale Kommunikation anstrengend: Jeder definierte seinen eigenen erweiterten Zeichensatz in der oberen Hälfte von ASCII (den sogenannten Codepages). Dies führte zu Konflikten. Man denke nur, dass die Deutschen mit den Koreanern verhandeln mussten, wo ist deren Codepage. Glücklicherweise erschien Unicode und führte einen gemeinsamen Standard ein. Unicode 8.0 umfasst mehr als 120.000 Zeichen aus über 129 Skripten. Sowohl moderne als auch alte und immer noch nicht entschlüsselt. Unicode unterstützt Text von links nach rechts und von rechts nach links, überlagert Zeichen und enthält eine Vielzahl von kulturellen, politischen, religiösen Symbolen und Emojis. Unicode ist erstaunlich menschlich und seine Fähigkeiten werden stark unterschätzt.
Inhalt
Kurze Einführung
Welche Zeichen sind in Unicode Standard enthalten?
Der Unicode-Standard definiert Codes für Zeichen in den wichtigsten modernen Sprachen. Dies sind europäische alphabetische Schriften, Schriften aus dem Nahen Osten von rechts nach links und viele asiatische Schriften.
Die Norm enthält auch Satzzeichen, diakritische Zeichen, mathematische Symbole, technische Symbole, Pfeile, Dingbats, Emojis usw. Sie enthält Codes für diakritische Zeichen, die Zeichen ändern, z. B. Tilden (~). Sie werden in Kombination mit einfachen Zeichen verwendet, um Zeichen mit Akzenten darzustellen (z. B. ñ). Im Allgemeinen bietet Unicode Version 9.0 Codes für 128.172 Zeichen aus Weltalphabeten, Ideogrammsätzen und Zeichensammlungen.
Die häufigsten Zeichen befinden sich in den ersten 64K-Codepunkten, einem Bereich des Codebereichs, der als mehrsprachige Hauptebene oder kurz BMP bezeichnet wird. Es stehen 16 weitere Ebenen zur Codierung anderer Zeichen mit über 850.000 nicht verwendeten Codepunkten zur Verfügung. Sie können nützlich sein, um zukünftigen Versionen des Standards neue Zeichen hinzuzufügen.
Der Unicode-Standard reserviert auch Codepunkte für den privaten Gebrauch. Anbieter oder Endbenutzer können sie in ihren eigenen Systemen für ihre Charaktere festlegen oder sie mit speziellen Schriftarten verwenden. Das BMP verfügt über 6400 Codepunkte für den privaten Gebrauch und weitere 131 068 zusätzliche Codepunkte für den privaten Gebrauch, wenn 6400 für bestimmte Anwendungen nicht ausreicht.
Unicode-Zeichenkodierungen
Zeichencodierungsstandards bestimmen nicht nur die Identität jedes Zeichens und seinen numerischen Wert oder Codepunkt, sondern auch, wie dieser Wert in Bits dargestellt wird.
Der Unicode-Standard definiert drei Codierungsformen, die die Übertragung derselben Daten ermöglichen: ein Byte, ein Wort und ein Doppelwort (d. H. 8, 16 oder 32 Bits pro Codeeinheit). Alle drei Formen codieren denselben gemeinsamen Zeichensatz und können effektiv ohne Datenverlust ineinander konvertiert werden. Das Unicode-Konsortium befürwortet uneingeschränkt die Verwendung einer dieser Kodierungsformen als vereinbarte Methode zur Implementierung des Unicode-Standards.
UTF-8 ist beliebt für HTML und ähnliche Protokolle. Mit UTF-8 können alle Unicode-Zeichen in eine Codierung mit variabler Bytelänge konvertiert werden. Der Vorteil besteht darin, dass Unicode-Zeichen, die dem bekannten ASCII-Satz entsprechen, dieselben Bytewerte wie ASCII haben und in UTF-8 konvertierte Unicode-Zeichen mit einer Vielzahl vorhandener Software ohne größere Softwaremodifikationen verwendet werden können.
UTF-16 ist in vielen Umgebungen beliebt, in denen ein Gleichgewicht zwischen effizientem Zugriff auf Zeichen und wirtschaftlichem Speicher erforderlich ist. Es ist recht kompakt und alle häufig verwendeten Zeichen sind in einem 16-Bit-Codeblock angeordnet, während alle anderen Zeichen über Paare von 16-Bit-Codeblöcken verfügbar sind.
UTF-32 ist nützlich, wenn die Speicherkapazität keine Rolle spielt, jedoch der Zugriff auf Zeichen in einem einzigen Code mit fester Breite erforderlich ist. Hier wird jedes Unicode-Zeichen in einem einzelnen 32-Bit-Codeblock codiert.
Alle drei Codierungsarten erfordern nicht mehr als 4 Bytes (oder 32 Bits) für jedes Zeichen.
Sprechen Sie über Zahlen
Der Unicode-Zeichensatz ist in 17 Hauptsegmente (Ebenen) unterteilt, die weiter in Blöcke unterteilt sind. In jeder Ebene gibt es einen Platz für 65 536 (2
16 ) Codepunkte, wodurch insgesamt 1.114.112 Codepunkte erstellt werden. Es gibt zwei Flugzeuge für den privaten Gebrauch (Nr. 16 und Nr. 17), die nach Ermessen der Unternehmen / Nutzer zugeteilt werden. Sie haben 131.072 Codepunkte.
Die erste Ebene wird als mehrsprachige Hauptebene oder BMP bezeichnet. Es enthält Codepunkte von U + 0000 bis U + FFFF, dh die am häufigsten verwendeten Zeichen. Die restlichen 16 Ebenen (U + 010000 → U + 10FFFF) werden zusätzlich oder astral genannt.
Ersatzpaare UTF-16
Symbole außerhalb der Hauptebene, wie ein Tetragramm, das die Mitte (U + 1D306) bedeutet, können in UTF-16 mit nur zwei 16-Bit-Codeeinheiten codiert werden: 0xD834 0xDF06. Dies wird als Ersatzpaar bezeichnet. Bitte beachten Sie, dass ein Ersatzpaar nur ein Zeichen darstellt.
Die erste Codeeinheit eines Ersatzpaares liegt immer im Bereich von 0xD800 bis 0xDBFF und wird als oberer Teil des Paares bezeichnet.
Die zweite Codeeinheit des Ersatzpaares liegt immer im Bereich von 0xDC00 bis 0xDFFF und wird als unterste der Paare bezeichnet.
Matthias Binens
Ersatzcode-Paar: Eine Darstellung eines abstrakten Symbols, bestehend aus einer Folge von zwei 16-Bit-Code-Einheiten, wobei der erste Wert des Paares die oberste Ersatzcode-Einheit und der zweite die untere Ersatzcode-Einheit ist. Ersatzpaare werden nur in UTF-16 verwendet.
Unicode 8.0 Kapitel 3.8 - Ersatzzeichen
Berechnung von Ersatzpaaren
Das Unicode-Zeichen "Pile of Shit" (U + 1F4A9) in UTF-16 muss als Ersatzpaar codiert werden, dh als zwei Ersatzzeichen. Verwenden Sie diesen Algorithmus (in JavaScript), um einen Codepunkt in ein Ersatzpaar umzuwandeln. Denken Sie daran, dass wir hexadezimale Notation verwenden.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 }; var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
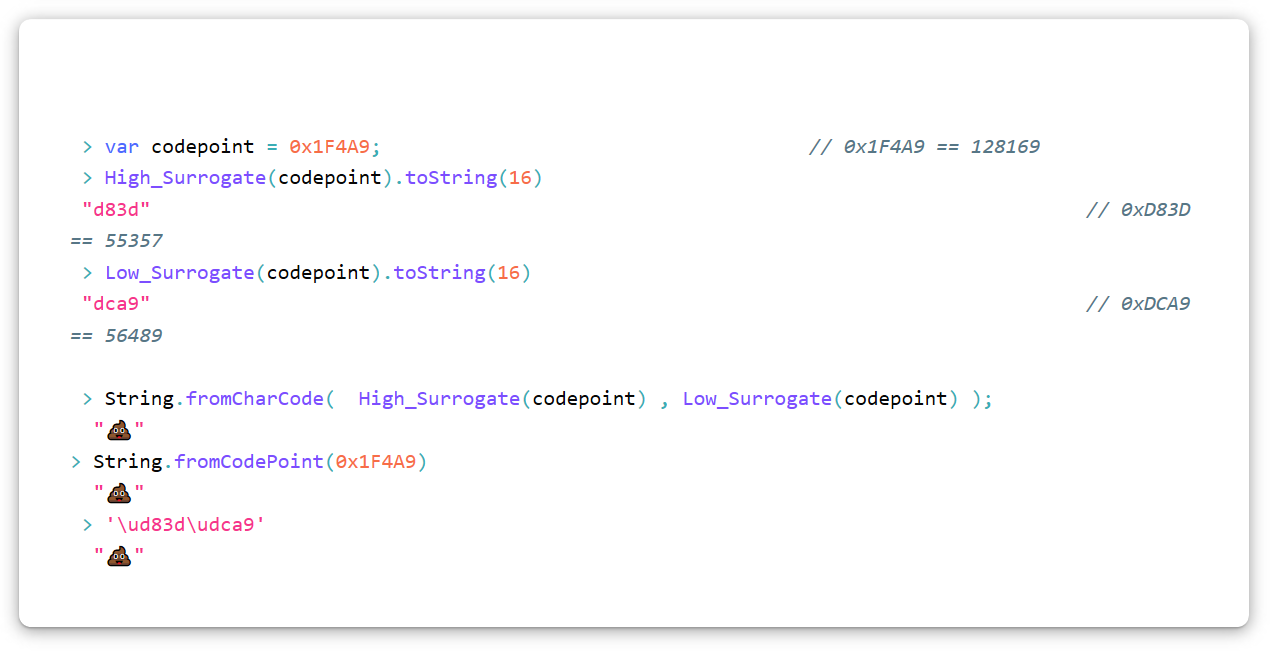
Zusammensetzung und Zersetzung
Unicode enthält einen Mechanismus zum Ändern der Form eines Zeichens, durch den die unterstützte Menge von Glyphen erheblich erweitert wird. Dies gilt für kombinierbare diakritische Zeichen. Sie werden nach dem Hauptcharakter eingefügt. Es können mehrere diakritische Zeichen auf dasselbe Zeichen angewendet werden. Unicode enthält auch vorkompilierte Versionen der meisten dieser Kombinationen für den normalen Gebrauch.
Einige Zeichenfolgen können auch als ein einzelnes Zeichen dargestellt werden, das als vorkomponiertes Zeichen oder als zusammengesetztes Zeichen bezeichnet wird. Beispielsweise kann das Zeichen [ü] als einziger Codepunkt U + 00FC oder als Basiszeichen U + 0075 (u) gefolgt vom nicht eigenständigen Zeichen U + 0308 (¨) codiert werden. Der Unicode-Standard codiert zusammengesetzte Zeichen, um die Kompatibilität mit gängigen Standards wie Latin 1 zu gewährleisten. Dazu gehören viele zusammengesetzte Zeichen wie [ü] und [ñ].
Zusammengesetzte Zeichen können aus Gründen der Konsistenz oder Analyse erweitert werden. Wenn Sie beispielsweise alphabetisch sortieren, kann das Symbol [ü] in [u] gefolgt vom nicht unabhängigen Symbol [¨] zerlegt werden. Nach einer solchen Zerlegung ist es einfacher, mit einer Folge von Zeichen zu arbeiten. Dies erleichtert das Sortieren in Sprachen, in denen sich Zeichenmodifikatoren nicht auf die alphabetische Reihenfolge auswirken. Der Unicode-Standard legt die
Zerlegungsreihenfolge für alle zusammengesetzten Zeichen fest. Es definiert auch Formen der Normalisierung, um eindeutige Darstellungen von Zeichen bereitzustellen.
Unicode-Mythen
Aus den Folien der Präsentation von Mark Davis "Mythen von Unicode".- Unicode ist nur 16-Bit-Code . - Einige Leute glauben fälschlicherweise, dass Unicode nur ein 16-Bit-Code ist, bei dem jedes Zeichen 16 Bit belegt, und daher gibt es 65.536 mögliche Zeichen. In der Tat ist dies nicht ganz richtig. Dies ist der häufigste Unicode-Mythos. Wenn Sie dies auch schon einmal dachten, lassen Sie sich nicht entmutigen.
- Sie können jeden Codepunkt verwenden, der nicht für Ihre Anforderungen verwendet wird . - Nein. Eines Tages wird dieser Ort durch ein anderes Symbol ersetzt. Verwenden Sie stattdessen Flugzeuge für den privaten Gebrauch oder Bereiche ohne Zeichen in jeder Ebene, in denen standardmäßig keine Zeichen vorhanden sind.
- Jeder Unicode-Codepunkt repräsentiert ein Zeichen . - Nein. Es gibt viele Punkte ohne Zeichen (FFFE, FFFF, 1FFFE usw.), außerdem Ersatzcodepunkte, private und nicht verwendete Codepunkte sowie Steuer- / Formatierungszeichen (RLM, ZWNJ usw.).
- Unicode hat keinen Speicherplatz mehr . - Wenn es linear gefüllt wäre, wäre es 2140 zu Ende gegangen. Der Platz füllt sich aber nicht linear. Zukunftspläne finden Sie hier .
- Alle Zeichen sind eins zu eins zugeordnet . - Nein. Die Optionen sind:
- Eins zu viele: (β → SS)
- Vor dem Hintergrund: (... Σ ← → ... ς und gleichzeitig ... ΣΤ ... ← → ... στ ...)
- Basierend auf dem Gebietsschema: (I ← → ı und gleichzeitig İ ← → i)
Unicode-Anwendungscodierungen
Quellcode
Liste der erstaunlichen Charaktere.
Das Teilen eines Dokuments kann die Bearbeitung schnell in einen schriftlichen Rap-Kampf verwandeln, der von einer zunehmend verwirrenden Anordnung von Managern von U + 202a bis U + 202e geführt wirdSonderzeichen
Das Unicode-Konsortium hat
ein allgemeines Interpunktionsdiagramm veröffentlicht, in dem Sie weitere Informationen finden.
Warten Sie ... was habe ich gerade gelesen?Variablenbezeichner können Leerzeichen enthalten!
Der Hangul-Platzhalter U + 3164 wird als breites Leerzeichen angezeigt. Wenn das Zeichen
beim Rendern eindeutig nicht
unterstützt wird, wird es als vollständig unsichtbar angezeigt (und beansprucht keinen Platz, d. H. "Breite Null"). Dies bedeutet, dass Sie niemals ein hässliches Zeichen als Ersatzzeichen ( ) sehen werden.
Ich bin mir noch nicht sicher, warum U + 3164 angewiesen ist, sich so zu verhalten. Interessanterweise wurde U + 3164 in Version 1.1 (1993) zu Unicode hinzugefügt - so hatten die Konsortialspezialisten viel Zeit, um darüber nachzudenken. Wie auch immer, hier sind ein paar Beispiele.
> var ᅟ = 'foo'; undefined > ᅟ 'foo' > var ㅤ= alert; undefined > var foo = 'bar' undefined > if ( foo ===ㅤ`baz` ){}
** Hinweis: ** Ich habe U + 3164-Rendering unter Ubuntu und OS X mit den folgenden Parametern getestet: `node`,` php`, `ruby`,` python3.5`, `scala`,` vim`, `cat` , `chrome` +` github gist '. Atom ist das einzige System, bei dem (fälschlicherweise) leere Felder angezeigt werden. Ich habe den Code in Emacs und Sublime noch nicht überprüft. Soweit ich weiß, weist das Unicode-Konsortium keine Zeichen oder Codepunkte neu zu oder benennt sie um, kann jedoch dazu überredet werden, die Eigenschaften von Zeichen wie ID_Start und ID_Continue zu ändern.Modifikatoren
Zero Width Combiner (ZWJ) ist ein nicht druckbares Zeichen in einem Computersatz komplexer Schriftarten, z. B. arabischer oder indischer Schriftarten. Wenn sie zwischen zwei Zeichen platziert werden, die sonst nicht verbunden wären, werden sie von ZWJ gezwungen, in kombinierter Form zu drucken.
Der Zero Width Disconnector (ZWNJ) ist ein nicht druckbares Zeichen in computergestützten Schreibsätzen mit Ligaturen. Wenn sie zwischen zwei Zeichen platziert werden, die ansonsten zu einer Ligatur verbunden wären, werden sie von ZWNJ gezwungen, in ihrer endgültigen bzw. ursprünglichen Form zu drucken. Fungiert als Leerzeichen, wird jedoch verwendet, wenn es wünschenswert ist, Wörter nahe beieinander zu halten oder ein Wort mit seinem Morphem zu kombinieren.
> 'a' "a" > 'a\u{0308}' "ä" > 'a\u{20DE}\u{0308}' "a⃞̈" > 'a\u{20DE}\u{0308}\u{20DD}' "a⃞̈⃝"
Großbuchstaben transformieren Kollisionen
Konvertierungskollisionen in Kleinbuchstaben
Macken und Fehlerbehebung
- Die Linienlänge wird normalerweise durch die Anzahl der Codepunkte bestimmt . Dies bedeutet, dass Ersatzpaare als zwei Zeichen betrachtet werden. Einem Symbol können mehrere diakritische Zeichen überlagert werden:
a + ̈ == ̈a . Dies erhöht die Länge der Zeichenfolge und erzeugt nur ein Zeichen.
- In ähnlicher Weise wird die String-Inversion häufig zu einer nicht trivialen Aufgabe . Auch hier sollten Ersatzpaare und diakritische Zeichen gemeinsam vertauscht werden. ES Reverser bietet eine ziemlich gute Lösung.
- Vergleiche zwischen Groß- und Kleinbuchstaben stimmen nicht immer überein . Sie können in solchen Beziehungen ausgedrückt werden:
- Eins zu viele: (ß → SS)
- Vor dem Hintergrund: (... Σ ← → ... ς und ... ΣΤ ... ← → ... στ ...)
- Basierend auf dem Gebietsschema: (I ← → ı und İ ← → i)
Ein bis viele Vergleiche
Die meisten der unten aufgeführten Zeichen drücken ihre Eins-zu-Viele-Zuordnungen in Großbuchstaben und andere in Kleinbuchstaben aus. Grundsätzlich kann die Liste in zwei Teile unterteilt werden.
Tolle Pakete und Bibliotheken
- PhantomScript -: ghost :: flashlight : Ausführen von unsichtbarem JavaScript und Social Engineering
- ESReverser - Unicode- basiertes JavaScript-String-Handling.
- mimic - Missbrauch von Unicode
- python-ftfy - Versucht, die maximale korrekte und vollständige Darstellung des in Unicode empfangenen Texts zu erstellen.
- vim-troll-stopper - Schützen Sie Ihren Code vor Unicode-Trollen.
Emoji
Unicode (diversity), . .
, , . — . :
, .
8.0 ( 2015 ) - . , ( , FitzpatrickSkinType.pdf). .
Unicode
, \u{1F466}\u{1F3FE} .

+

→


JavaScript (ES6)
, ID_START , . , ID_CONTINUE , .
CSS .
<!-- place this within the document head --> <meta charset="UTF-8" /> <div class="ಠ_ಠ">You do not have access to this page.</div> <div class="">Your changes have been saved successfully!</div>
.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }
HTML
HTML- , , .
, HTML .
:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }
:
TrueType OpenType UTF-8, 65 535 . 1,1 UTF-8, .
256 .

, () (CJK). , , « ».
. 17- .
:
- — - .
- — , .
- — .
- — , . .
- , — , . , .
- — , . , [Ä] [A] [¨].
- — .
- — , , . .
- — , .
- — .
: c codepoints.net .