
Bei Serokell engagieren wir uns nicht nur für kommerzielle Projekte, sondern bemühen uns auch, die Welt zum Besseren zu verändern. Zum Beispiel arbeiten wir daran, das Hauptwerkzeug aller Haskelisten zu verbessern - den Glasgow Haskell Compiler (GHC). Wir konzentrierten uns auf die Erweiterung des Typensystems unter dem Einfluss von Richard Eisenbergs Arbeit "Abhängige Typen in Haskell: Theorie und Praxis".
In unserem Blog hat Vladislav bereits darüber gesprochen, warum Haskell keine abhängigen Typen hat und wie wir sie hinzufügen wollen. Wir haben beschlossen, diesen Beitrag ins Russische zu übersetzen, damit möglichst viele Entwickler abhängige Typen verwenden und einen weiteren Beitrag zur Entwicklung von Haskell als Sprache leisten können.
Aktueller Stand der Dinge
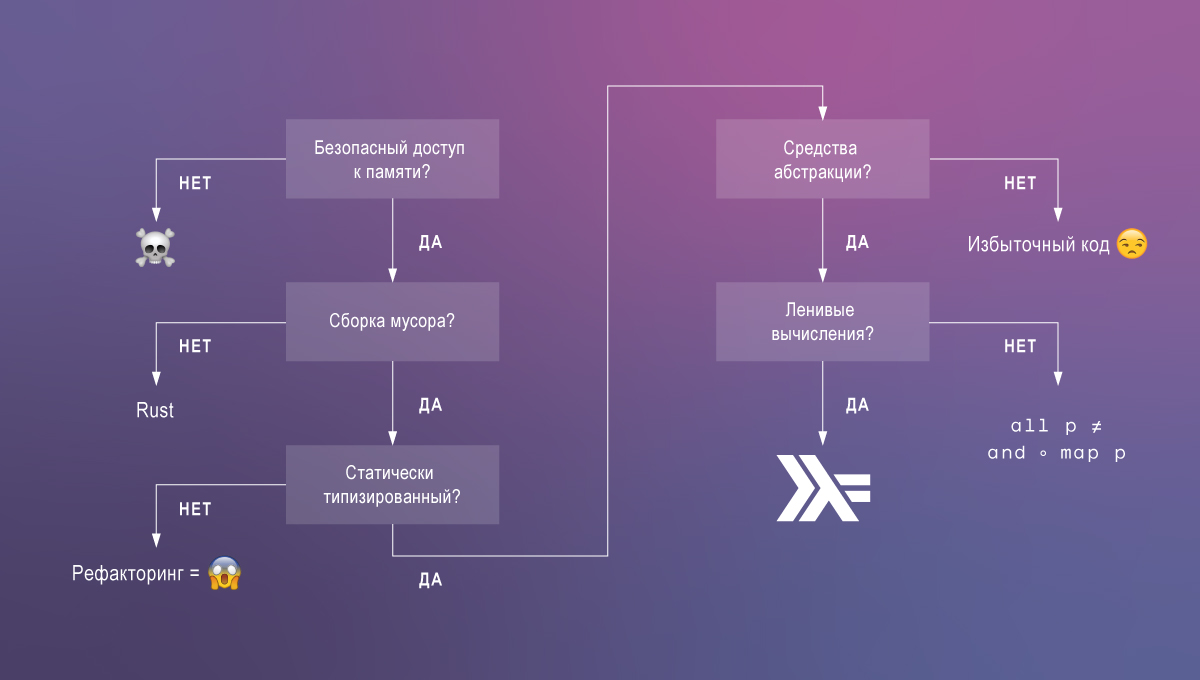
Abhängige Typen sind das, was ich in Haskell am meisten vermisse. Lassen Sie uns diskutieren, warum. Aus dem Code, den wir wollen:
- Leistung, dh Ausführungsgeschwindigkeit und geringer Speicherverbrauch;
- Wartbarkeit und Verständlichkeit;
- Richtigkeit durch die Methode der Kompilierung garantiert.
Mit vorhandenen Technologien ist es selten möglich, alle drei Merkmale zu erreichen, aber mit der Unterstützung von Haskell-abhängigen Typen wird die Aufgabe vereinfacht.
Haskell Standard: Ergonomie + Leistung
Haskell basiert auf einem einfachen System: einem polymorphen Lambda-Kalkül mit Lazy-Berechnungen, algebraischen Datentypen und Typklassen. Diese Kombination von Sprachfunktionen ermöglicht es uns, eleganten, unterstützten und gleichzeitig produktiven Code zu schreiben. Um diese Behauptung zu untermauern, vergleichen wir Haskell kurz mit populäreren Sprachen.
Sprachen mit unsicherem Speicherzugriff wie C führen zu den schwerwiegendsten Fehlern und Sicherheitslücken (z. B. Pufferüberlauf, Speicherlecks). Manchmal werden solche Sprachen benötigt, aber meistens ist ihre Verwendung eine Idee.
Sprachen für den sicheren Speicherzugriff bilden zwei Gruppen: diejenigen, die auf dem Garbage Collector basieren, und Rust. Rust scheint einzigartig darin zu sein, einen sicheren Speicherzugriff ohne Speicherbereinigung anzubieten. In dieser Gruppe werden auch Cyclone und andere Forschungssprachen nicht mehr unterstützt. Doch im Gegensatz zu ihnen ist Rust auf dem Weg zur Popularität. Der Nachteil ist, dass die Speicherverwaltung von Rust trotz Sicherheit nicht trivial und manuell ist. In Anwendungen, die die Verwendung des Garbage Collectors ermöglichen, ist es besser, die Entwickler mit anderen Aufgaben zu beschäftigen.
Es gibt noch Sprachen für Müllsammler, die wir basierend auf ihrem Typensystem in zwei Kategorien unterteilen werden.
Dynamisch typisierte (oder eher monotypisierte ) Sprachen wie JavaScript oder Clojure bieten keine statische Analyse und können daher nicht das gleiche Maß an Vertrauen in die Richtigkeit des Codes bieten (und nein, Tests können keine Typen ersetzen - Sie benötigen beide). !).
Statisch typisierte Sprachen wie Java oder Go haben oft ein sehr eingeschränktes Typensystem. Dies zwingt Programmierer, redundanten Code zu schreiben und unsichere Sprachfunktionen zu verwenden. Beispielsweise erzwingt das Fehlen generischer Typen in Go die Verwendung von Interface {} und das Casting von Laufzeittypen . Es gibt auch keine Trennung zwischen Berechnungen mit Nebenwirkungen (Eingabe, Ausgabe) und reinen Berechnungen.
Schließlich zeichnet sich Haskell unter Sprachen mit sicherem Speicherzugriff, einem Garbage Collector und einem leistungsstarken Typsystem durch Faulheit aus. Lazy Computing ist äußerst nützlich, um komponierbaren, modularen Code zu schreiben. Sie ermöglichen es, beliebige Teile von Ausdrücken, einschließlich Konstruktionen, die einen Kontrollfluss definieren, in Hilfsdefinitionen zu zerlegen.
Haskell scheint eine nahezu perfekte Sprache zu sein, bis Sie erkennen, wie weit es davon entfernt ist, sein volles Potenzial in Bezug auf die statische Verifikation im Vergleich zu Satzbeweiswerkzeugen wie Agda freizusetzen .
Als einfaches Beispiel für den Fall, dass das Haskell-Typensystem nicht leistungsfähig genug ist, betrachten Sie den Listenindizierungsoperator aus Prelude (oder das Indizieren eines Arrays aus einem primitive Paket):
(!!) :: [a] -> Int -> a indexArray :: Array a -> Int -> a
Nichts in diesen Typensignaturen spiegelt die Anforderung wider, dass der Index nicht negativ und kürzer als die Länge der Auflistung sein muss. Für Software mit hohen Zuverlässigkeitsanforderungen ist dies nicht akzeptabel.
Agda: Ergonomie + Korrektheit
Beweismittel für Theoreme (z. B. Coq ) sind Softwaretools, mit denen mithilfe eines Computers formale Beweise für mathematische Theoreme erstellt werden können. Für einen Mathematiker ist die Verwendung solcher Werkzeuge wie das Schreiben von Beweisen auf Papier. Der Unterschied in der beispiellosen Genauigkeit, die ein Computer benötigt, um die Gültigkeit solcher Beweise festzustellen.
Für den Programmierer ist das Mittel zum Beweisen der Theoreme jedoch nicht so verschieden vom Compiler für die esoterische Programmiersprache mit einem unglaublichen Typsystem (und möglicherweise einer integrierten Entwicklungsumgebung) und mittelmäßigem (oder sogar fehlendem) allem anderen. Ein Mittel, um Theoreme zu beweisen, sind in der Tat Programmiersprachen, deren Autoren ihre ganze Zeit damit verbracht haben, ein Schreibsystem zu entwickeln, und die vergessen haben, dass Programme noch ausgeführt werden müssen.
Der gehegte Traum verifizierter Softwareentwickler ist ein Mittel, um Theoreme zu beweisen, die eine gute Programmiersprache mit qualitativ hochwertigem Codegenerator und Laufzeit wären. In dieser Richtung experimentierten unter anderem die Macher von Idris . Dies ist jedoch eine Sprache mit strengen (energetischen) Berechnungen, und ihre Implementierung ist derzeit nicht stabil.
Unter allen Beweismitteln für die Theoreme sind die Haskelisten von Agda am beliebtesten. In vielerlei Hinsicht ähnelt es Haskell, verfügt jedoch über ein leistungsfähigeres Typensystem. Wir bei Serokell verwenden es, um die verschiedenen Eigenschaften unserer Programme zu beweisen. Meine Kollegin Dania Rogozin hat eine Reihe von Artikeln darüber geschrieben.
Hier ist ein Lookup- Funktionstyp ähnlich dem Haskell-Operator (!!) :
lookup : ∀ (xs : List A) → Fin (length xs) → A
Der erste Parameter hier ist vom Typ List A , der [a] in Haskell entspricht. Wir geben ihm jedoch den Namen xs , auf den er sich für den Rest der xs bezieht. In Haskell können wir auf Funktionsargumente nur im Hauptteil der Funktion auf der Termebene zugreifen:
(!!) :: [a] -> Int -> a
In Agda können wir uns jedoch auf diesen xs Wert auf der Typebene beziehen, was wir im zweiten lookup Parameter Fin (length xs) tun. Eine Funktion, die auf der Typebene auf ihren Parameter verweist, wird als abhängige Funktion bezeichnet und ist ein Beispiel für abhängige Typen.
Der zweite Parameter in der lookup ist vom Typ Fin n für n ~ length xs . Ein Wert vom Typ Fin n entspricht einer Zahl im Bereich [0, n) , sodass Fin (length xs) eine nicht negative Zahl ist, die kürzer als die Länge der Eingabeliste ist. Genau dies ist erforderlich, um einen gültigen Index eines Listenelements anzuzeigen. Grob gesagt besteht die lookup ["x","y","z"] 2 die Typprüfung, aber die lookup ["x","y","z"] 42 schlägt fehl.
Wenn es darum geht, Agda-Programme auszuführen, können wir sie in Haskell mit dem MAlonzo- Backend kompilieren. Die Leistung des generierten Codes ist jedoch unbefriedigend. Dies ist nicht MAlonzos Schuld: Er muss zahlreiche unsafeCoerce einfügen, damit der GHC Code unsafeCoerce , der bereits von Agda verifiziert wurde. Aber das gleiche unsafeCoerce verringert die Leistung (nach der Diskussion dieses Artikels stellte sich heraus, dass Leistungsprobleme durch andere Gründe verursacht wurden - Anmerkung des Autors) .
Dies bringt uns in eine schwierige Position: Wir müssen Agda für die Modellierung und formale Verifizierung verwenden und dann dieselbe Funktionalität auf Haskell erneut implementieren. Bei dieser Organisation von Workflows fungiert unser Agda-Code als computerüberprüfte Spezifikation. Dies ist besser als die Spezifikation in natürlicher Sprache, aber alles andere als ideal. Das Ziel ist, dass, wenn der Code kompiliert wird, er gemäß der Spezifikation funktioniert.
Haskell mit Erweiterungen: Korrektheit + Leistung

GHC strebt nach statischen Garantien für Sprachen mit abhängigen Typen und hat einen langen Weg zurückgelegt. Es wurden Erweiterungen hinzugefügt, um die Aussagekraft des Typensystems zu erhöhen. Ich habe angefangen, Haskell zu verwenden, als GHC 7.4 die neueste Version des Compilers war. Schon damals gab es die wichtigsten Erweiterungen für die erweiterte Programmierung auf RankNTypes : RankNTypes , GADTs , TypeFamilies , DataKinds und PolyKinds .
Dennoch gibt es in Haskell noch keine vollwertigen abhängigen Typen: weder abhängige Funktionen (Π-Typen) noch abhängige Paare (Σ-Typen). Auf der anderen Seite haben wir zumindest eine Kodierung für sie!
Aktuelle Praktiken sind wie folgt:
- Funktionen auf Typebene als private Typfamilien codieren,
- Funktionalisierung verwenden, um ungesättigte Funktionen zu ermöglichen,
- Überbrücken Sie die Lücke zwischen Begriffen und Typen mithilfe einzelner Typen.
Dies führt zu einer erheblichen Menge an redundantem Code, aber die singletons Bibliothek automatisiert ihre Generierung durch Template Haskell.
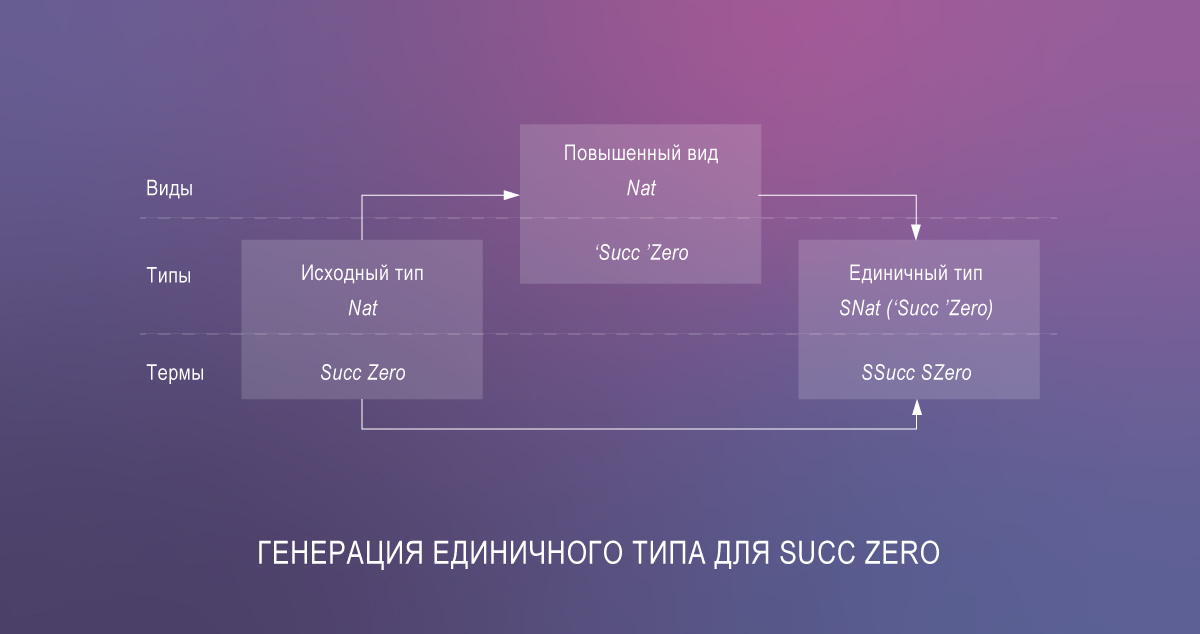
Die Wagemutigsten und Entschlossensten können jetzt also abhängige Typen in Haskell codieren. Zur Veranschaulichung ist hier eine Implementierung der lookup ähnlich der Variante auf Agda:
{-# OPTIONS -Wall -Wno-unticked-promoted-constructors -Wno-missing-signatures #-} {-# LANGUAGE LambdaCase, DataKinds, PolyKinds, TypeFamilies, GADTs, ScopedTypeVariables, EmptyCase, UndecidableInstances, TypeSynonymInstances, FlexibleInstances, TypeApplications, TemplateHaskell #-} module ListLookup where import Data.Singletons.TH import Data.Singletons.Prelude singletons [d| data N = Z | SN len :: [a] -> N len [] = Z len (_:xs) = S (len xs) |] data Fin n where FZ :: Fin (S n) FS :: Fin n -> Fin (S n) lookupS :: SingKind a => SList (xs :: [a]) -> Fin (Len xs) -> Demote a lookupS SNil = \case{} lookupS (SCons x xs) = \case FZ -> fromSing x FS i' -> lookupS xs i'
Und hier ist eine GHCi-Sitzung, die zeigt, dass Lookups zu große Indizes tatsächlich ablehnen:
GHCi, version 8.6.2: http://www.haskell.org/ghc/ :? for help [1 of 1] Compiling ListLookup ( ListLookup.hs, interpreted ) Ok, one module loaded. *ListLookup> :set -XTypeApplications -XDataKinds *ListLookup> lookupS (sing @["x", "y", "z"]) FZ "x" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS FZ) "y" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS (FS FZ)) "z" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ))) <interactive>:5:34: error: • Couldn't match type ''S n0' with ''Z' Expected type: Fin (Len '["x", "y", "z"]) Actual type: Fin ('S ('S ('S ('S n0)))) • In the second argument of 'lookupS', namely '(FS (FS (FS FZ)))' In the expression: lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ))) In an equation for 'it': it = lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ)))
Dieses Beispiel zeigt, dass Machbarkeit nicht praktikabel ist. Ich bin froh, dass Haskell über Sprachfähigkeiten für die Implementierung von lookupS , aber gleichzeitig bin ich besorgt über die unnötige Komplexität, die entsteht. Außerhalb von Forschungsprojekten würde ich einen solchen Codestil nicht empfehlen.
In diesem speziellen Fall könnten wir mit längenindexierten Vektoren das gleiche Ergebnis mit weniger Komplexität erzielen. Die direkte Code-Übersetzung von Agda zeigt jedoch besser die Probleme, die Sie unter anderen Umständen haben müssen.
Hier sind einige von ihnen:
- Die Typisierungsrelation
a :: t und die Zielrelation der Form t :: k unterschiedlich. 5 :: Integer ist in Begriffen wahr, aber nicht in Typen. "hi" :: Symbol ist in Typen wahr, aber nicht in Begriffen. Dies erfordert die Demote , um Ansichten und Typen zuzuordnen. - Die Standardbibliothek verwendet
Int als Darstellung von Listenindizes (und singletons verwendet Nat in erweiterten Definitionen). Int und Nat sind nicht induktive Typen. Obwohl sie effizienter sind als die unäre Codierung natürlicher Zahlen, funktionieren sie mit induktiven Definitionen wie Fin oder lookupS nicht sehr gut. Aus diesem Grund definieren wir die length als len . - Haskell hat keine eingebauten Mechanismen, um Funktionen auf die Ebene der Typen zu heben.
singletons kodieren sie als private Typfamilien und wenden Funktionalisierung an, um den Mangel an teilweiser Verwendung von Typfamilien zu umgehen. Diese Kodierung ist kompliziert. Außerdem mussten wir die len Definition in ein Template-Haskell-Zitat einfügen, damit die singletons ihr Gegenstück auf Len , Len generieren. - Es gibt keine eingebauten abhängigen Funktionen. Man muss Einheitentypen verwenden , um die Lücke zwischen Begriffen und Typen zu schließen. Anstelle der üblichen Liste übergeben wir die
SList an die Eingabe lookupS . Daher müssen wir mehrere Definitionen von Listen gleichzeitig berücksichtigen. Dies führt auch zu einem Overhead während der Programmausführung. Sie entstehen durch die Umrechnung zwischen toSing und Werten von Einheitentypen ( toSing , fromSing ) und durch die Übertragung des Umrechnungsverfahrens ( SingKind Restriktion).
Unbequemlichkeit ist das geringere Problem. Schlimmer noch, diese Sprachfunktionen sind unzuverlässig. Zum Beispiel habe ich bereits 2016 das Problem Nr. 12564 gemeldet, und es gibt auch Nr. 12088 desselben Jahres. Beide Probleme behindern die Implementierung fortgeschrittenerer Programme als Beispiele aus Lehrbüchern (z. B. Indexlisten). Diese GHC-Fehler sind immer noch nicht behoben, und der Grund, so scheint es mir, ist, dass die Entwickler einfach nicht genug Zeit haben. Die Anzahl der Personen, die aktiv am GHC arbeiten, ist überraschend gering, sodass sich einige Dinge nicht herumsprechen.
Zusammenfassung
Ich habe bereits erwähnt, dass wir alle drei Eigenschaften aus dem Code übernehmen möchten. Hier ist eine Tabelle, die den aktuellen Stand der Dinge veranschaulicht:
Strahlende Zukunft
Jede der drei verfügbaren Optionen hat ihre Nachteile. Wir können sie jedoch beheben:
- Nehmen Sie das Standard-Haskell und fügen Sie abhängige Typen direkt hinzu, anstatt umständliche Codierungen über
singletons . (Leichter gesagt als getan.) - Nehmen Sie Agda und implementieren Sie einen effizienten Codegenerator und RTS dafür. (Leichter gesagt als getan.)
- Nehmen Sie Haskell mit Erweiterungen, beheben Sie Fehler und fügen Sie weitere Erweiterungen hinzu, um die Codierung abhängiger Typen zu vereinfachen. (Leichter gesagt als getan.)
Die gute Nachricht ist, dass alle drei Optionen (gewissermaßen) an einem Punkt zusammenlaufen. Stellen Sie sich die kleinste Erweiterung von Haskell vor, die abhängige Typen hinzufügt und es Ihnen daher ermöglicht, die Richtigkeit des Codes durch die Art und Weise, wie er geschrieben wurde, zu gewährleisten. Agda-Code kann in diese Sprache ohne unsafeCoerce kompiliert (transponiert) werden. Und Haskell mit Erweiterungen ist gewissermaßen ein unvollendeter Prototyp dieser Sprache. Es muss etwas verbessert und etwas entfernt werden, aber am Ende werden wir das gewünschte Ergebnis erzielen.
singletons
Ein guter Indikator für den Fortschritt ist die Vereinfachung der singletons Bibliothek. Da abhängige Typen in Haskell implementiert sind, sind keine Problemumgehungen und keine spezielle Behandlung von in singletons implementierten Sonderfällen mehr erforderlich. Letztendlich wird die Notwendigkeit für dieses Paket vollständig verschwinden. Beispielsweise habe ich 2016 mit der Erweiterung -XTypeInType KProxy von SingKind und SomeSing . Diese Änderung wurde durch die Vereinigung von Typen und Typen ermöglicht. Vergleichen Sie alte und neue Definitionen:
class (kparam ~ 'KProxy) => SingKind (kparam :: KProxy k) where type DemoteRep kparam :: * fromSing :: SingKind (a :: k) -> DemoteRep kparam toSing :: DemoteRep kparam -> SomeSing kparam type Demote (a :: k) = DemoteRep ('KProxy :: KProxy k) data SomeSing (kproxy :: KProxy k) where SomeSing :: Sing (a :: k) -> SomeSing ('KProxy :: KProxy k)
In den alten Definitionen kommt k ausschließlich in Ansichtspositionen rechts von Anmerkungen der Form t :: k . Wir verwenden kparam :: KProxy k , um k auf Typen zu übertragen.
class SingKind k where type DemoteRep k :: * fromSing :: SingKind (a :: k) -> DemoteRep k toSing :: DemoteRep k -> SomeSing k type Demote (a :: k) = DemoteRep k data SomeSing k where SomeSing :: Sing (a :: k) -> SomeSing k
In den neuen Definitionen bewegt sich k frei zwischen Ansichts- und KProxy , sodass KProxy nicht mehr benötigt KProxy . Der Grund dafür ist, dass ab GHC 8.0 Typen und Typen in dieselbe syntaktische Kategorie fallen.
In Standard-Haskell gibt es drei völlig getrennte Welten: Begriffe, Typen und Ansichten. Wenn Sie sich den Quellcode von GHC 7.10 ansehen, sehen Sie einen separaten Parser für Ansichten und eine separate Prüfung . GHC 8.0 hat sie nicht mehr: Der Parser und die Validierung für Typen und Ansichten sind üblich.
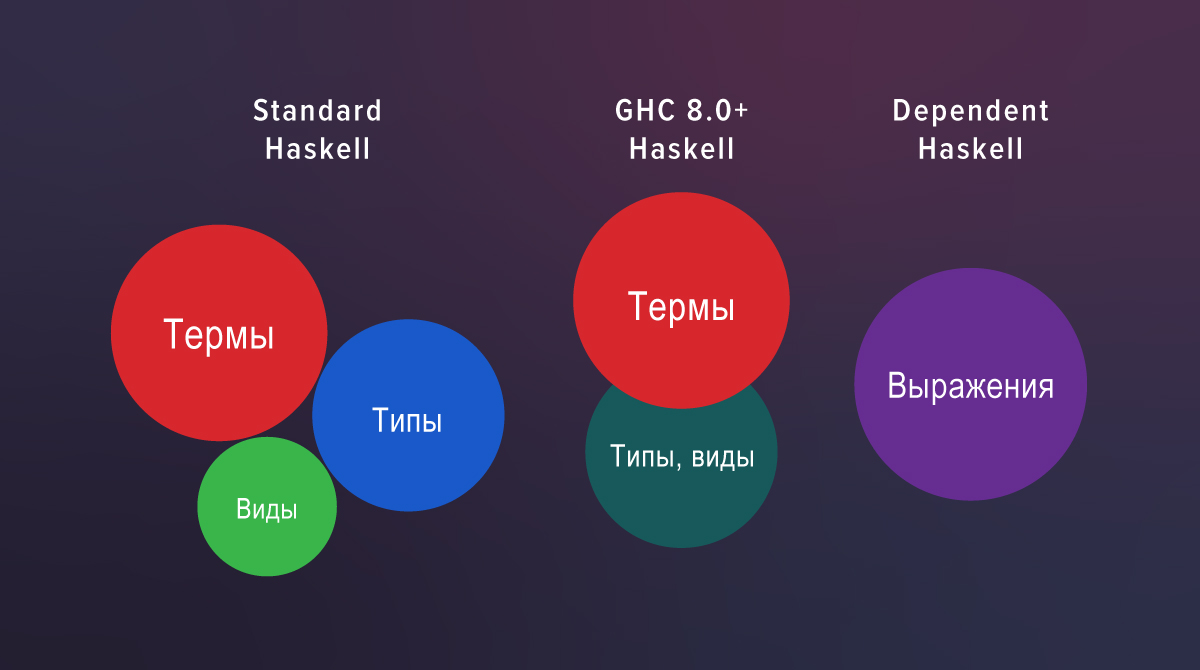
In Haskell mit Erweiterungen ist view genau die Rolle, in der sich der Typ befindet:
f :: T z -> ...
In GHC 8.0–8.4 gab es noch einige Unterschiede zwischen der Namensauflösung in Typen und Typen. Aber ich habe sie auf GHC 8.6 minimiert: Ich habe die StarIsType Erweiterung erstellt und die TypeInType Funktionalität in PolyKinds . Ich habe die verbleibenden Unterschiede als Warnung zu GHC 8.8 gemacht und sie in GHC 8.10 vollständig beseitigt (die Übersetzung dieses Absatzes wurde aktualisiert, im Original wird die geleistete Arbeit als zukünftige Aufgaben beschrieben - Anmerkung des Autors ).
Was ist der nächste Schritt? SingKind wir einen Blick auf SingKind in der neuesten Version von singletons :
class SingKind k where type Demote k = (r :: Type) | r -> k fromSing :: Sing (a :: k) -> Demote k toSing :: Demote k -> SomeSing k
Die Demote erforderlich, um die Abweichungen zwischen der Typisierungsrelation a :: t und der Demote der Form t :: k zu berücksichtigen. Am häufigsten (für algebraische Datentypen) ist Demote eine Identitätszuordnung:
type Demote Bool = Booltype Demote [a] = [Demote a]type Demote (Either ab) = Either (Demote a) (Demote b)
Demote (Either [Bool] Bool) = Either [Bool] Bool . Diese Beobachtung veranlasst uns, folgende Vereinfachung vorzunehmen:
class SingKind k where fromSing :: Sing (a :: k) -> k toSing :: k -> SomeSing k
Demote nicht erforderlich! Tatsächlich würde dies sowohl mit Either [Bool] Bool als auch mit anderen algebraischen Datentypen funktionieren. In der Praxis haben wir es jedoch mit nicht-algebraischen Datentypen zu tun: Integer, Natural , Char , Text und so weiter. Wenn sie als Spezies verwendet werden, sind sie nicht besiedelt: 1 :: Natural ist auf der Ebene der Begriffe wahr, aber nicht auf der Ebene der Typen. Aus diesem Grund haben wir es mit folgenden Definitionen zu tun:
type Demote Nat = Natural type Demote Symbol = Text
Die Lösung für dieses Problem besteht darin, primitive Typen zu erheben. Beispielsweise ist Text wie Text definiert:
Wenn wir ByteArray# und Int# richtig auf die Ebene der Typen erhöhen, können wir Text anstelle von Symbol . Wenn Sie dasselbe mit Natural und möglicherweise ein paar anderen Typen Demote , können Sie Demote loswerden, oder?
Leider nicht so. Oben habe ich den wichtigsten Datentyp ignoriert: Funktionen. Sie haben auch eine spezielle Demote Instanz:
type Demote (k1 ~> k2) = Demote k1 -> Demote k2 type a ~> b = TyFun ab -> Type data TyFun :: Type -> Type -> Type
~> Dies ist ein Typ, mit dem Funktionen auf Typebene in Singletons codiert werden, basierend auf privaten Typfamilien und Funktionalisierung .
Zunächst scheint es eine gute Idee zu sein, ~> und -> zu kombinieren, da beide den Typ (Typ) der Funktion bedeuten. Das Problem ist, dass -> in der Typposition und -> in der Ansichtsposition verschiedene Dinge bedeuten. Auf der Termebene sind alle Funktionen von a bis b vom Typ a -> b . Auf der Typebene sind nur Konstruktoren von a bis b vom Typ a -> b , aber sie sind keine Synonyme für Typen und keine Typfamilien. Um Typen ableiten zu können, geht GHC davon aus, dass f ~ g und a ~ b aus fa ~ gb folgen, was für Konstruktoren gilt, aber nicht für Funktionen - deshalb gibt es eine Einschränkung.
Daher müssen wir die Konstruktoren auf einen separaten Typ verschieben, um Funktionen auf die Ebene der Typen zu heben, aber um die Typinferenz beizubehalten. Wir nennen es a :-> b , denn es wird wirklich wahr sein, dass f ~ g und a ~ b aus fa ~ gb folgen. Andere Funktionen sind weiterhin vom Typ a -> b . Zum Beispiel Just :: a :-> Maybe a , aber gleichzeitig isJust :: Maybe a -> Bool .
Wenn Demote beendet ist, besteht der letzte Schritt darin, Sing selbst loszuwerden. Dazu brauchen wir einen neuen Quantifizierer, einen Hybrid zwischen forall und -> . Schauen wir uns die isJust-Funktion genauer an:
isJust :: forall a. Maybe a -> Bool isJust = \x -> case x of Nothing -> False Just _ -> True
Die Funktion isJust mit dem Typ a und dann mit dem Wert x :: Maybe a parametriert. Diese beiden Parameter haben unterschiedliche Eigenschaften:
- Ausdrücklich. Beim
isJust (Just "hello") wir x = Just "hello" explizit, und a = String wird implizit vom Compiler ausgegeben. Im modernen Haskell können wir auch die explizite Übergabe beider Parameter isJust @String (Just "hello") : isJust @String (Just "hello") . - Relevanz Der an die Eingabe an
isJust im Code übergebene Wert wird auch während der Ausführung des Programms übertragen: Wir führen einen Mustervergleich mit case , um isJust , dass es sich um Nothing oder Just . Daher wird der Wert als relevant angesehen. Der Typ wird jedoch gelöscht und kann nicht mit dem Muster verglichen werden: Die Funktion verarbeitet " Maybe Int , " Maybe String , " Maybe Bool usw. Daher wird es als irrelevant angesehen. Diese Eigenschaft wird auch als Parametrizität bezeichnet. - Sucht. In
forall a. t forall a. t , Typ t kann sich auf a beziehen und hängt daher von dem bestimmten bestandenen a . Zum Beispiel ist isJust @String vom Typ Maybe String -> Bool und isJust @Int vom Typ Maybe Int -> Bool . Dies bedeutet, dass forall ein abhängiger Quantifizierer ist. Beachten Sie den Unterschied zum value-Parameter: Es spielt keine Rolle, ob wir isJust Nothing oder isJust (Just …) Der Ergebnistyp ist immer Bool . Daher ist -> ein unabhängiger Quantifizierer.
Um Sing herauszunehmen, brauchen wir einen Quantifikator, der explizit und relevant ist, wie a -> b und gleichzeitig abhängig, wie forall (a :: k). t forall (a :: k). t . Bezeichne es als foreach (a :: k) -> t . Um SingI , führen wir auch einen implizit relevanten abhängigen Quantor ein, foreach (a :: k). t foreach (a :: k). t . Infolgedessen werden singletons nicht benötigt, da wir der Sprache nur abhängige Funktionen hinzugefügt haben.
Ein kurzer Blick auf Haskell mit abhängigen Typen
Mit dem Aufstieg der Funktionen auf die Ebene der Typen und des foreach Quantifizierers können wir lookupS wie folgt umschreiben:
data N = Z | SN len :: [a] -> N len [] = Z len (_:xs) = S (len xs) data Fin n where FZ :: Fin (S n) FS :: Fin n -> Fin (S n) lookupS :: foreach (xs :: [a]) -> Fin (len xs) -> a lookupS [] = \case{} lookupS (x:xs) = \case FZ -> x FS i' -> lookupS xs i'
Kurz gesagt, der Code tat es nicht, aber singletons ziemlich gut darin, redundanten Code zu verstecken. Der neue Code ist jedoch viel einfacher: Es gibt keine Demote , SingKind , SList , SNil , SCons fromSing . TemplateHaskell wird nicht verwendet, da wir jetzt die len Funktion direkt aufrufen können, anstatt die Len len zu erstellen. Die Leistung wird auch fromSing , da Sie keine Konvertierung von fromSing mehr durchführen müssen.
Wir müssen noch die length als len neu definieren, um ein induktiv definiertes N anstelle von Int . Vielleicht sollte dieses Problem im Rahmen des Hinzufügens abhängiger Typen zu Haskell nicht berücksichtigt werden, da Agda auch ein induktiv definiertes N in der lookup verwendet.
In einigen Aspekten ist Haskell mit abhängigen Typen sogar einfacher als Standard-Haskell. Dabei werden Typen und Typen zu einer einheitlichen Sprache zusammengefasst. Ich kann mir leicht vorstellen, Code in diesem Stil in einem kommerziellen Projekt zu schreiben, um die Korrektheit der Schlüsselkomponenten von Anwendungen formal zu beweisen. Viele Haskell-Bibliotheken bieten sicherere Schnittstellen ohne die Komplexität von singletons .
Dies wird nicht leicht zu erreichen sein. Wir sind mit vielen technischen Problemen konfrontiert, die alle Komponenten des GHC betreffen: Parser, Namensauflösung, Typprüfung und sogar die Kernsprache. Alles muss modifiziert oder sogar komplett neu gestaltet werden.
Thesaurus