Dieser Artikel ist eine Übersetzung meines Artikels auf Medium -
Erste Schritte mit Data Lake , der sich wahrscheinlich aufgrund seiner Einfachheit als recht beliebt erwies. Aus diesem Grund habe ich beschlossen, es in Russisch zu schreiben und ein wenig zu ergänzen, damit eine einfache Person, die kein Datenspezialist ist, versteht, was ein Data Warehouse (DW) ist und was ein Data Lake ist und wie sie miteinander auskommt .
Warum wollte ich über einen Datensee schreiben? Ich arbeite seit über 10 Jahren mit Daten und Analysen und arbeite jetzt definitiv mit Big Data bei Amazon Alexa AI in Cambridge, das sich in Boston befindet, obwohl ich selbst in Victoria auf Vancouver Island lebe und oft Boston, Seattle und Kanada besuche Vancouver und manchmal sogar in Moskau spreche ich auf Konferenzen. Außerdem schreibe ich von Zeit zu Zeit, aber ich schreibe hauptsächlich auf Englisch und habe bereits
mehrere Bücher geschrieben . Außerdem muss ich Analysetrends aus Nordamerika teilen und manchmal schreibe ich in
Telegrammen .
Ich habe immer mit Data Warehouses gearbeitet und seit 2015 eng mit Amazon Web Services zusammengearbeitet. Im Allgemeinen habe ich auf Cloud Analytics (AWS, Azure, GCP) umgestellt. Ich habe die Entwicklung der Analyselösungen seit 2007 beobachtet und sogar beim Teradat-Data-Warehouse-Anbieter gearbeitet und sie in Sberbank implementiert. Dann erschien Big Data mit Hadoop. Jeder begann zu sagen, dass die Ära der Speicher vorbei war und jetzt war alles auf Hadoop, und dann sprachen sie wieder über Data Lake, jetzt, wo das Data Warehouse sicher vorbei war. Aber zum Glück (vielleicht für jemanden und leider, der viel Geld mit der Einrichtung von Hadoop verdient hat), ist das Data Warehouse nicht verschwunden.
In diesem Artikel betrachten wir, was ein Data Lake ist. Dieser Artikel richtet sich an Personen, die wenig oder keine Erfahrung mit Data Warehousing haben.

Auf dem Bild ist der Bleder See einer meiner Lieblingsseen, obwohl ich nur einmal dort war, aber ich erinnere mich ein Leben lang daran. Aber wir werden über eine andere Art von See sprechen - Data Lake. Vielleicht haben viele von Ihnen schon mehr als einmal von diesem Begriff gehört, aber eine andere Definition wird niemanden verletzen.
Zuallererst sind hier die beliebtesten Definitionen eines Data Lake:
„Dateispeicherung aller Arten von Rohdaten, die jeder in der Organisation analysieren kann“ - Martin Fowler.
„Wenn Sie glauben, dass ein Daten-Display eine Flasche Wasser ist - gereinigt, verpackt und zur bequemen Verwendung verpackt - dann ist der Daten-See ein riesiges Wasserreservoir in seiner natürlichen Form. Benutzer, ich kann Wasser für mich selbst schöpfen, in die Tiefe tauchen, erforschen "- James Dixon.
Jetzt wissen wir sicher, dass es sich bei dem Data Lake um eine Analyse handelt. Dadurch können wir große Datenmengen in ihrer ursprünglichen Form speichern und haben den erforderlichen und bequemen Zugriff auf die Daten.
Ich mag es oft, Dinge zu vereinfachen, wenn ich einen komplexen Begriff in einfachen Worten wiedergeben kann, dann habe ich für mich selbst verstanden, wie es funktioniert und wofür es ist. Irgendwie habe ich mein iPhone in der Fotogalerie ausgewählt und es ist mir aufgegangen, so dass dies ein echter Datensee ist. Ich habe sogar eine Folie für Konferenzen erstellt:

Alles ist sehr einfach. Wir machen ein Foto auf dem Telefon, das Foto wird auf dem Telefon gespeichert und kann in iCloud (Dateispeicher in der Cloud) gespeichert werden. Das Telefon sammelt auch Metadaten des Fotos: was angezeigt wird, Geo-Tag, Zeit. Als Ergebnis können wir die praktische iPhone-Oberfläche verwenden, um unser Foto zu finden, und gleichzeitig sehen wir sogar Indikatoren. Wenn ich beispielsweise nach Fotos mit dem Wort Feuer suche, finde ich 3 Fotos mit dem Bild eines Feuers. Für mich ist es wie ein Business Intelligence-Tool, das sehr schnell und klar funktioniert.
Und natürlich sollten wir die Sicherheit (Autorisierung und Authentifizierung) nicht vergessen, sonst können unsere Daten leicht in den Open Access gelangen. Es gibt viele Neuigkeiten über große Unternehmen und Start-ups, bei denen die Daten aufgrund der Nachlässigkeit von Entwicklern und der Nichteinhaltung einfacher Regeln öffentlich zugänglich wurden.
Selbst ein so einfaches Bild hilft uns, sich vorzustellen, was ein Data Lake ist, seine Unterschiede zu einem herkömmlichen Data Warehouse und seine Hauptelemente:
- Das Laden von Daten (Ingestion) ist eine Schlüsselkomponente eines Datensees. Daten können auf zwei Arten in das Data Warehouse eingegeben werden: Batch (Download in Intervallen) und Streaming (Datenstrom).
- Der Dateispeicher ist die Hauptkomponente des Data Lake. Der Speicher muss einfach skalierbar, äußerst zuverlässig und kostengünstig sein. In AWS ist dies beispielsweise S3.
- Katalog und Suche - Um den Datensumpf zu vermeiden (in diesem Fall werden alle Daten in einem Stapel abgelegt, und es ist dann unmöglich, mit ihnen zu arbeiten), müssen wir eine Metadatenebene erstellen, um die Daten zu klassifizieren, damit Benutzer sie problemlos verwenden können Finden Sie die Daten, die sie für die Analyse benötigen. Darüber hinaus können Sie zusätzliche Suchlösungen wie ElasticSearch verwenden. Die Suche hilft dem Benutzer, über eine komfortable Oberfläche nach den gewünschten Daten zu suchen.
- Verarbeitung (Process) - Dieser Schritt ist für die Verarbeitung und Transformation von Daten verantwortlich. Wir können Daten transformieren, ihre Strukturen ändern, klarer und vieles mehr.
- Sicherheit - Es ist wichtig, viel Zeit mit dem Entwerfen einer Sicherheitslösung zu verbringen. Zum Beispiel Datenverschlüsselung beim Speichern, Verarbeiten und Laden. Es ist wichtig, Authentifizierungs- und Autorisierungsmethoden zu verwenden. Abschließend wird ein Audit-Tool benötigt.
Aus praktischer Sicht können wir einen Datensee mit drei Attributen charakterisieren:
- Sammeln und speichern Sie alles, was Sie möchten - der Data Lake enthält alle Daten, sowohl Rohdaten für einen beliebigen Zeitraum als auch verarbeitete / gelöschte Daten.
- Tiefenanalyse - Ein Datensee ermöglicht Benutzern das Erkunden und Analysieren von Daten.
- Flexibler Zugriff - Ein Datensee bietet flexiblen Zugriff für verschiedene Daten und verschiedene Szenarien.
Jetzt können wir über den Unterschied zwischen einem Data Warehouse und einem Data Lake sprechen. Die Leute fragen normalerweise:
- Aber was ist mit dem Data Warehouse?
- Ersetzen wir das Data Warehouse durch einen Data Lake oder erweitern wir es?
- Kann man auf einen Datensee verzichten?
Kurz gesagt, es gibt keine klare Antwort. Es hängt alles von der spezifischen Situation, den Teamfähigkeiten und dem Budget ab. Zum Beispiel die Migration eines Data Warehouse auf Oracle in AWS und die Erstellung eines Data Lake durch die Amazon-Tochter Woot -
Unsere Data Lake-Story: Wie Woot.com einen serverlosen Data Lake auf AWS erstellte .
Auf der anderen Seite gibt der Snowflake-Anbieter an, dass Sie sich nicht mehr mit einem Datensee befassen müssen, da seine Datenplattform (bis 2020 war es ein Data Warehouse) es Ihnen ermöglicht, sowohl einen Datensee als auch ein Data Warehouse zu kombinieren. Ich habe nicht viel mit Snowflake gearbeitet und es ist ein wirklich einzigartiges Produkt, das dies kann. Der Preis der Frage ist eine andere Frage.
Zusammenfassend ist meine persönliche Meinung, dass wir weiterhin ein Data Warehouse als Hauptdatenquelle für unsere Berichterstellung benötigen und alles speichern, was nicht in den Data Lake passt. Die gesamte Funktion von Analytics besteht darin, einen bequemen Geschäftszugang für die Entscheidungsfindung bereitzustellen. Auf jeden Fall arbeiten Geschäftsbenutzer effizienter mit einem Data Warehouse als mit einem Data Lake, beispielsweise in Amazon - es gibt Redshift (analytisches Data Warehouse) und Redshift Spectrum / Athena (SQL-Schnittstelle für Data Lake in S3 basierend auf Hive / Presto). Gleiches gilt für andere moderne analytische Data Warehouses.
Sehen wir uns eine typische Data Warehouse-Architektur an:
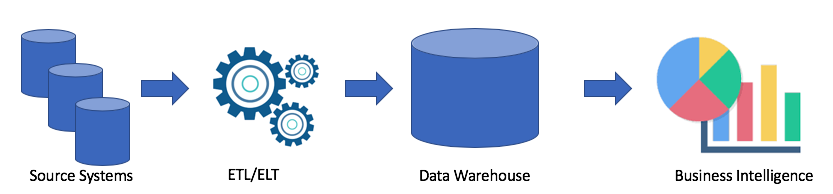
Dies ist eine klassische Lösung. Wir haben Quellsysteme, mit ETL / ELT kopieren wir Daten in das analytische Data Warehouse und verbinden die Lösung mit Business Intelligence (mein Lieblingstableau und Ihres?).
Diese Lösung hat folgende Nachteile:
- ETL / ELT-Vorgänge erfordern Zeit und Ressourcen.
- In der Regel ist der Speicher zum Speichern von Daten in einem analytischen Data Warehouse nicht billig (z. B. Redshift, BigQuery, Teradata), da wir einen ganzen Cluster kaufen müssen.
- Geschäftsbenutzer haben Zugriff auf bereinigte und häufig aggregierte Daten, und sie können keine Rohdaten abrufen.
Natürlich hängt alles von Ihrem Fall ab. Wenn Sie keine Probleme mit Ihrem Data Warehouse haben, brauchen Sie auf keinen Fall einen Data Lake. Wenn jedoch Probleme mit Platzmangel, Kapazität oder dem Preis des Problems eine Schlüsselrolle spielen, können Sie die Option eines Datensees in Betracht ziehen. Deshalb ist Data Lake sehr beliebt. Hier ist ein Beispiel für eine Data Lake-Architektur:

Mit dem Data-Lake-Ansatz laden wir Rohdaten in unseren Data-Lake (Batch oder Streaming) und verarbeiten sie dann nach Bedarf. Mit dem Data Lake können Geschäftsbenutzer ihre eigenen Datentransformationen (ETL / ELT) erstellen oder Daten in Business Intelligence-Lösungen analysieren (sofern Sie den richtigen Treiber haben).
Das Ziel jeder analytischen Lösung ist es, Geschäftsanwendern zu dienen. Deshalb müssen wir immer an den Anforderungen des Geschäfts arbeiten. (In Amazon ist dies eines der Prinzipien - rückwärts arbeiten).
Wenn wir sowohl mit dem Data Warehouse als auch mit dem Data Lake arbeiten, können wir beide Lösungen vergleichen:
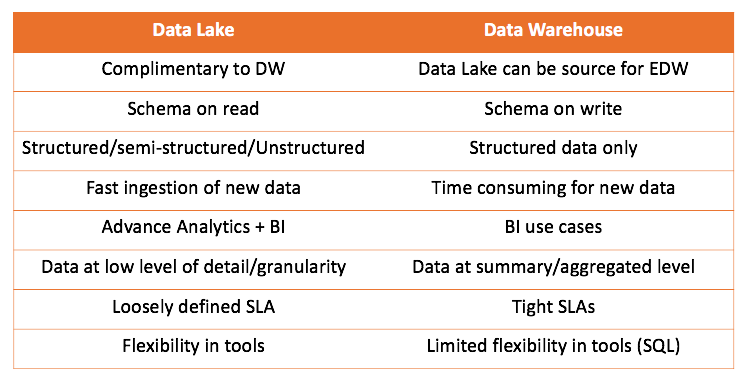
Die wichtigste Schlussfolgerung, die gezogen werden kann, ist, dass das Data Warehouse nicht mit dem Data Lake konkurriert, sondern ihn eher ergänzt. Aber es liegt an Ihnen, was für Ihren Fall richtig ist. Es ist immer interessant, es selbst zu versuchen und die richtigen Schlussfolgerungen zu ziehen.
Ich möchte auch über einen der Fälle sprechen, als ich anfing, den Data-Lake-Ansatz zu verwenden. Alles ist ziemlich alltäglich, ich habe versucht, das ELT-Tool (wir hatten Matillion ETL) und Amazon Redshift zu verwenden, meine Lösung hat funktioniert, aber sie passte nicht zu den Anforderungen.
Ich musste Webprotokolle erstellen, transformieren und aggregieren, um Daten für zwei Fälle bereitzustellen:
- Das Marketing-Team wollte die Aktivität von Bots für SEO analysieren
- Die IT wollte die Site-Metriken überwachen
Sehr einfache, sehr einfache Protokolle. Hier ist ein Beispiel:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188 192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57 "GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"
Eine Datei wog 1-4 Megabyte.
Aber es gab eine Schwierigkeit. Wir hatten 7 Domains auf der ganzen Welt und an einem Tag wurden 7.000.000 Dateien erstellt. Dies ist kein sehr großes Volumen, nur 50 Gigabyte. Die Größe unseres Redshift-Clusters war jedoch ebenfalls gering (4 Knoten). Das Herunterladen einer einzelnen Datei auf herkömmliche Weise dauerte ungefähr eine Minute. Das heißt, die Aufgabe wurde nicht in der Stirn gelöst. Und das war der Fall, als ich mich für den Data-Lake-Ansatz entschied. Die Lösung sah ungefähr so aus:
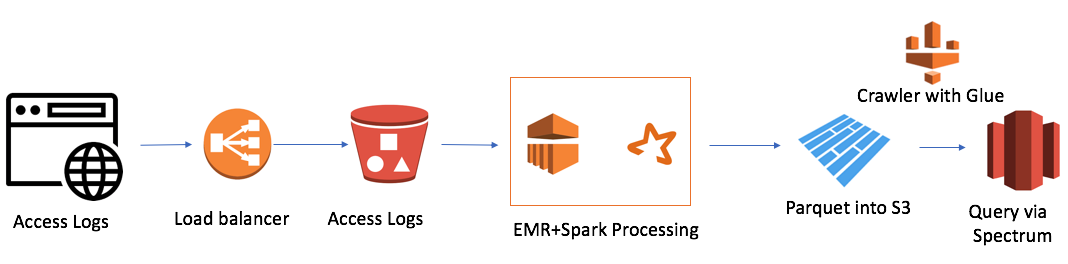
Es ist ganz einfach (ich möchte darauf hinweisen, dass der Vorteil der Arbeit in der Cloud die Einfachheit ist). Ich habe benutzt:
- AWS Elastic Map Reduce (Hadoop) als Rechenleistung
- AWS S3 als Dateispeicher mit der Möglichkeit, Daten zu verschlüsseln und den Zugriff einzuschränken
- Spark als InMemory Computing Power und PySpark zur Logik- und Datentransformation
- Parkett durch Spark
- AWS Glue Crawler als Sammlung von Metadaten zu neuen Daten und Partitionen
- Redshift Spectrum als SQL-Schnittstelle zum Datensee für bestehende Redshift-Benutzer
Der kleinste EMR + Spark-Cluster verarbeitete eine ganze Reihe von Dateien in 30 Minuten. Es gibt andere Fälle für AWS, insbesondere viele im Zusammenhang mit Alexa, wo es viele Daten gibt.
Zuletzt fand ich heraus, dass einer der Nachteile des Data Lake die DSGVO ist. Das Problem ist, wenn der Client ihn zum Löschen auffordert und sich die Daten in einer der Dateien befinden. Wir können die Datenbearbeitungssprache und die DELETE-Operation nicht wie in der Datenbank verwenden.
Hoffentlich hat der Artikel den Unterschied zwischen einem Data Warehouse und einem Data Lake verdeutlicht. Wenn es interessant war, kann ich meine Artikel oder den Artikel von Fachleuten, die ich lese, noch übersetzen. Sprechen Sie auch über die Lösungen, mit denen ich arbeite, und deren Architektur.